flink:StreamGraph转换为JobGraph
1 转换基本流程
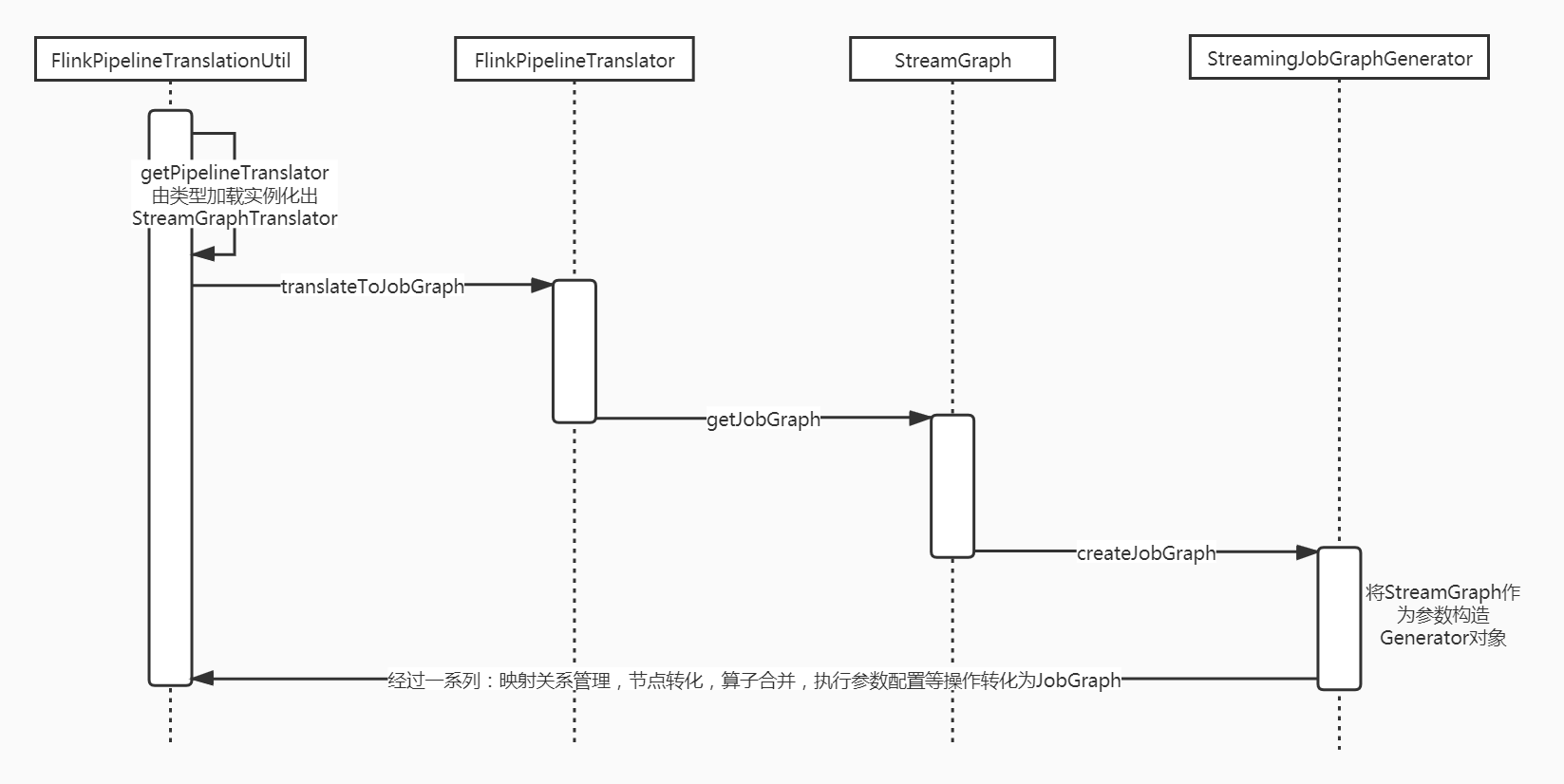
2 简单来看可以分为两部分:
第一部分是通过一些util、translator、generator等类将职责进行解耦、托管和分离,期间涉及FlinkPipelineTranslationUtil、FlinkPipelineTranslator/StreamGraphTranslator、StreamingJobGraphGenerator等。
第二部分最终转换的操作落在StreamingJobGraphGenerator中,涉及StreamGraph、StreamEdge、StreamConfig、JobGraph、JobVertex等,下面主要关注点在第二步:
3 StreamingJobGraphGenerator的构造方法和成员变量
唯一构造方法:
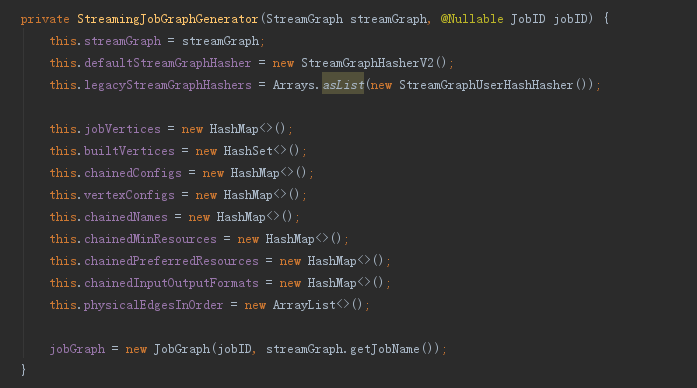
将StreamGraph对象作为参数传递进来,并初始化一个JobGraph空壳和一系列的成员变量(主要是map,需要保持各种对应关系),用于存储转换的中间态

从命名不难看出各个map的作用,核心套路大多是用节点id或者节点的hash值映射节点
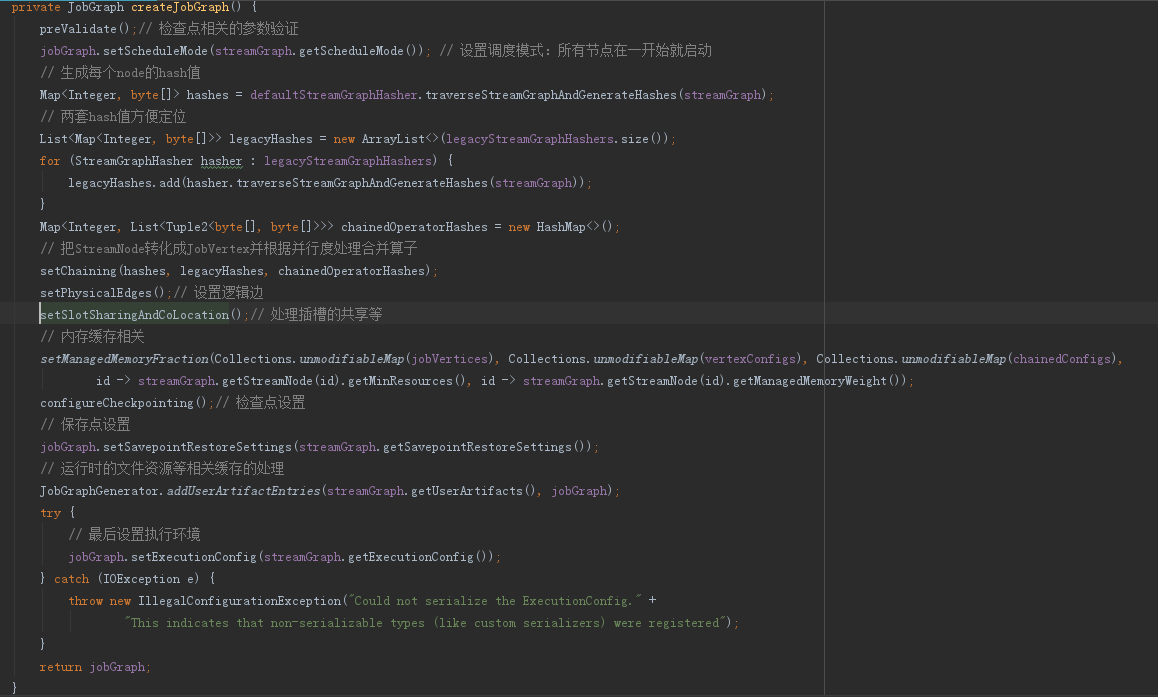
4 StreamingJobGraphGenerator.createJobGraph方法
主要要弄清楚StreamNode转化成JobVertex、算子合并、边上下游关系转换的核心逻辑
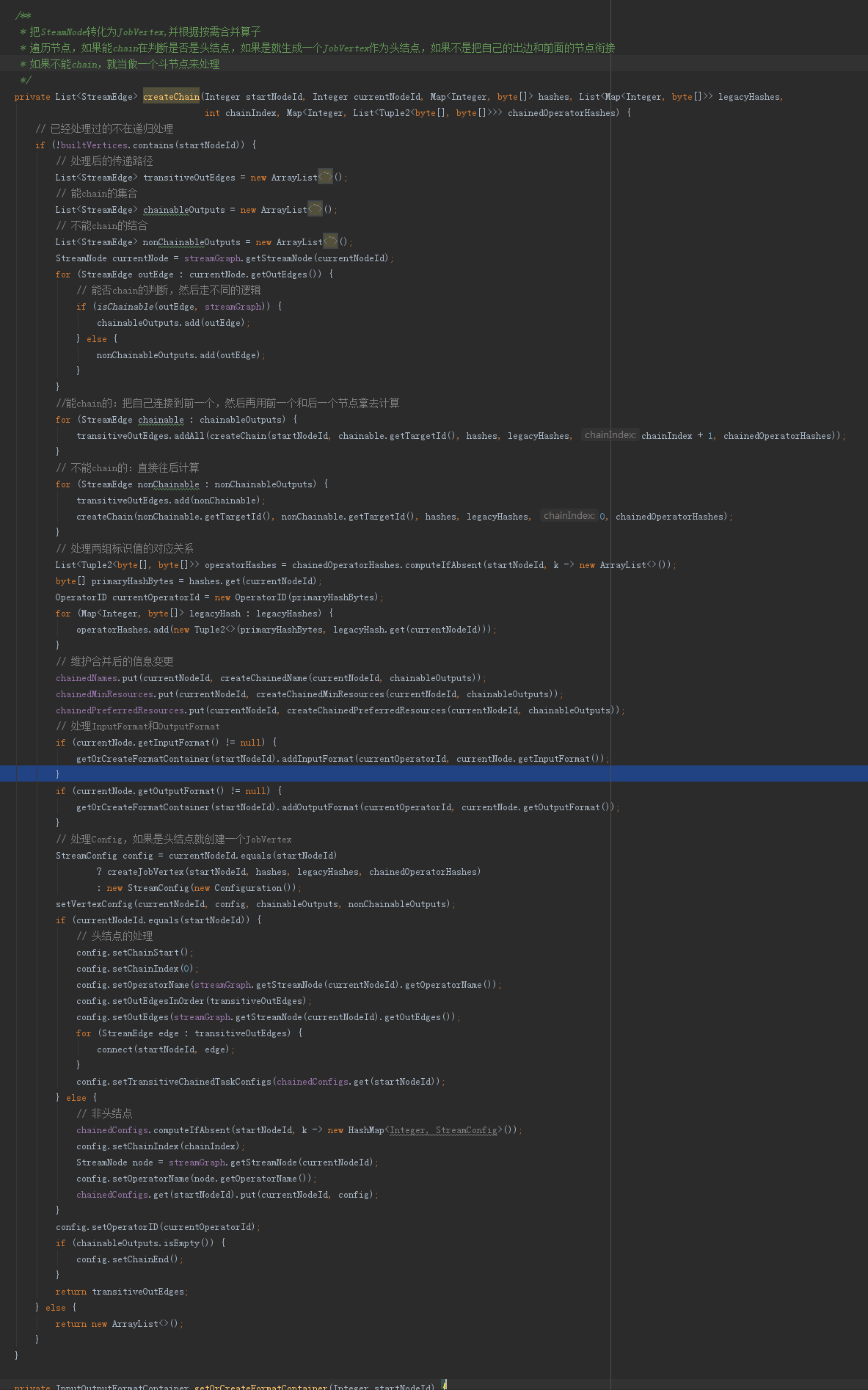
4.1 StreamingJobGraphGenerator.createChain方法
这里主要是把SteamNode转化为JobVertex,并根据按需合并算子
步骤:
a、在调用时遍历节点,并通过builtVertices保存已经处理过的节点
b,判断outEdge能不能chain,分门别类放到不同的List集合中待处理
c、对于能chain的节点,就把自己衔接到前一个上面去,把衔接的路径存储下来,然后再把衔接的前一个和自己的后一个再递归调用拿去计算
d、对于不能chain的节点,就作为一个头节点来单独处理掉
e、然后维护单个/合并后的关系,包括合并后的命名、资源、格式化方式等
f、处理转换逻辑,如果是头就创建个JobVertex返回StreamConfig,如果不是就创建个StreamConfig
4.2 StreamingJobGraphGenerator.isChainable方法
决定StreamEdge两边能否chian的逻辑:

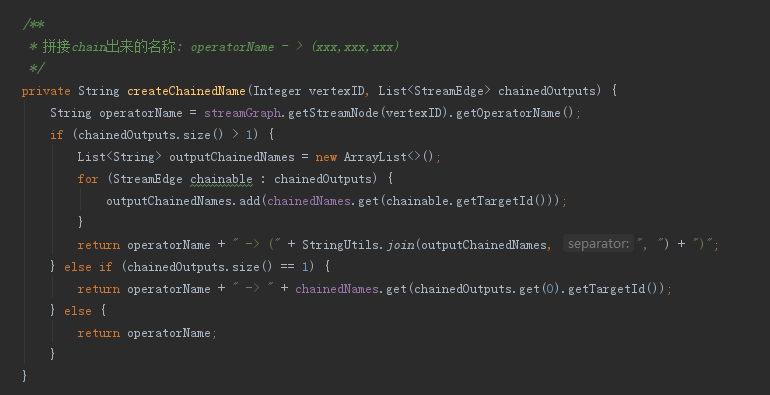
4.3 StreamingJobGraphGenerator.createChainedName方法
这个是处理合并后的命名,在日志中或者生成的图中可以看到
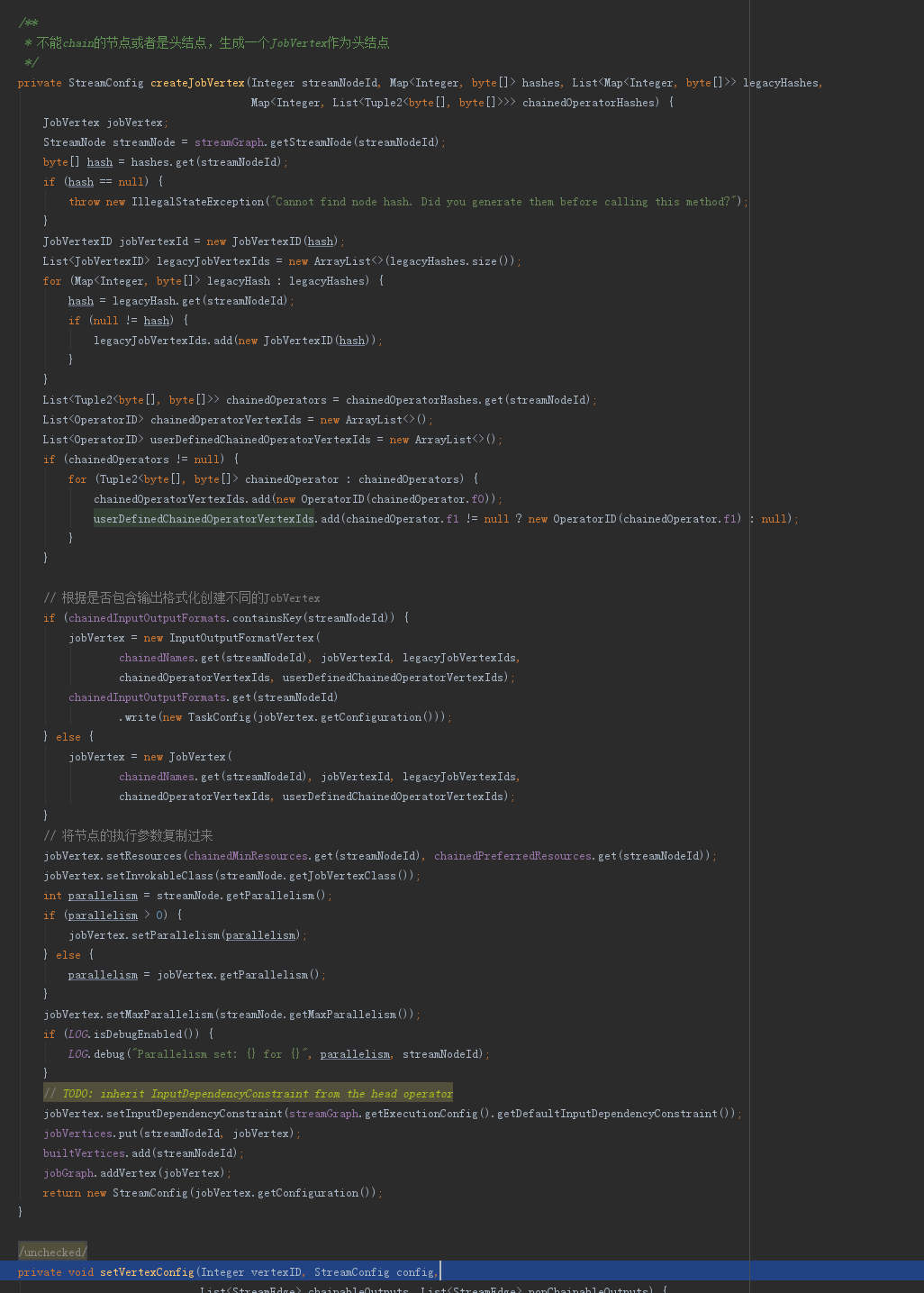
4.4 StreamingJobGraphGenerator.createJobVertex方法
这里是StreamNode转变为JobVertex的真正实现,其实也很简单,第一步根据节点的输出new出不同类型的JobVertex,第二步把StreamNode的执行参数复制过来,第三步把自己和相关的映射关系填充到jobGraph和相应的map中去
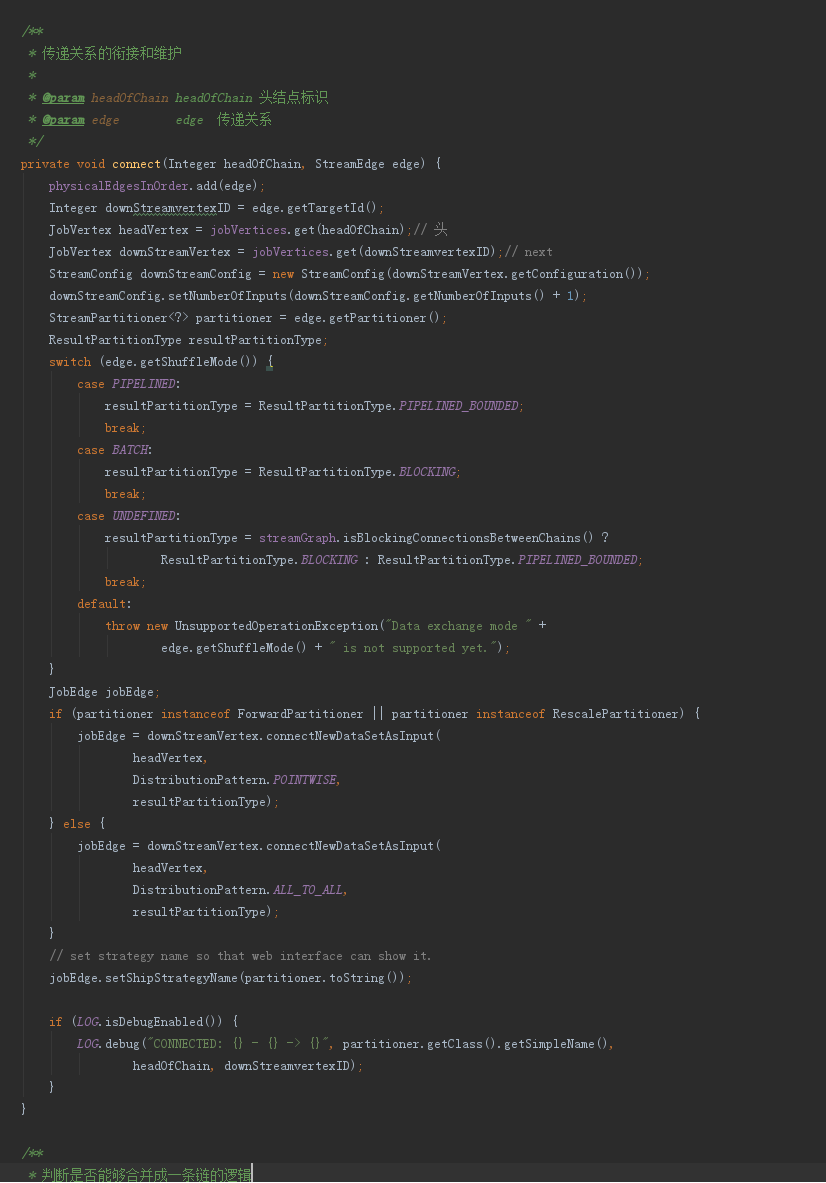
4.5 StreamingJobGraphGenerator.connect方法
5 总的来看由于在StreamGraph中已经构建好了DAG的关系和映射,此过程中最核心的逻辑就是在createChain合并算子的过程。
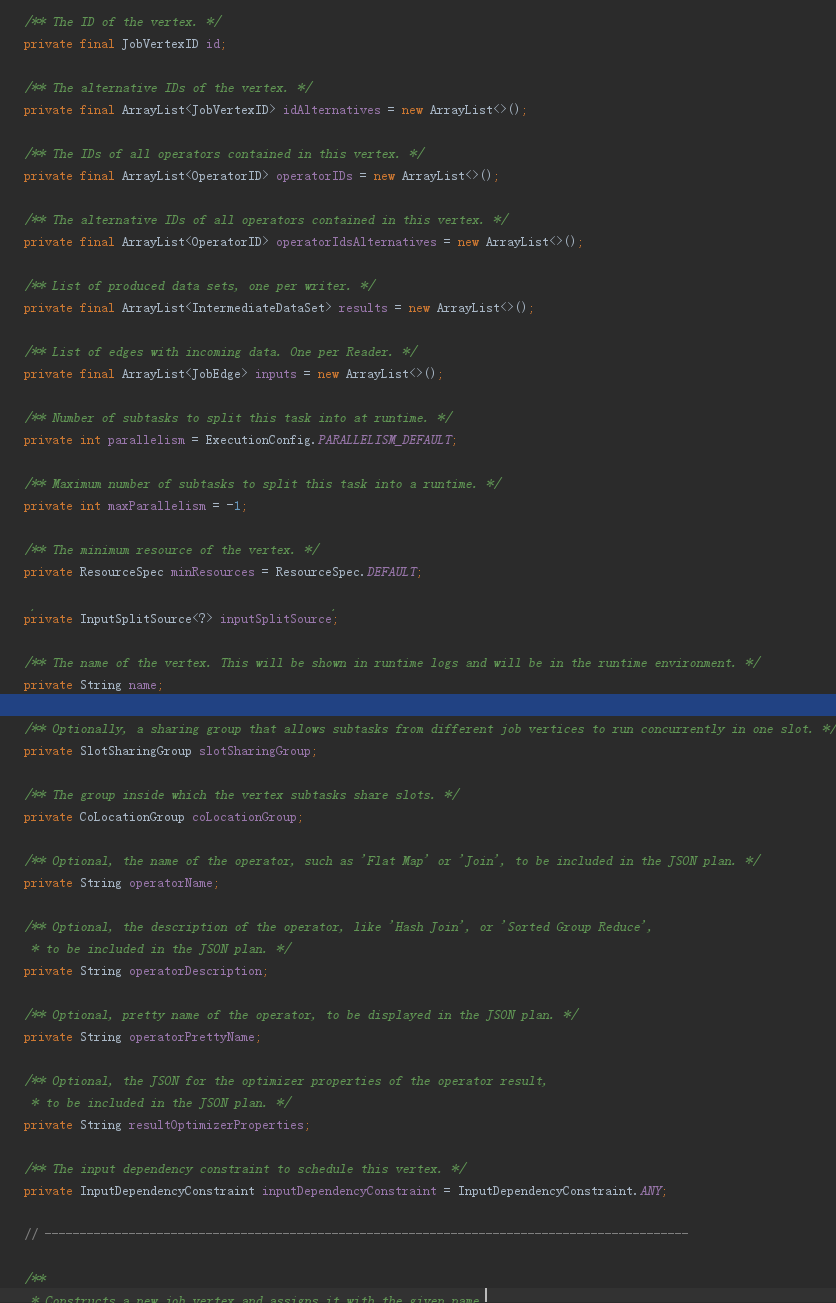
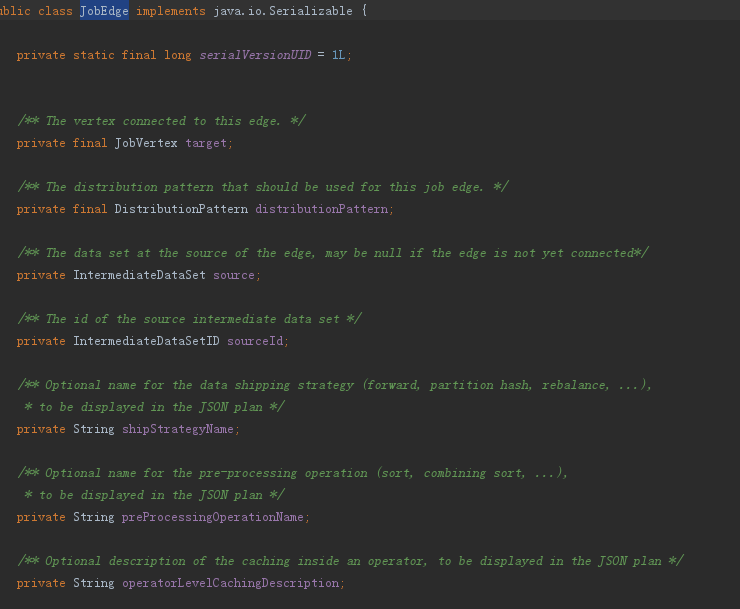
6、下面是JobGraph、JobVertex和JobEdge的主要属性,可以对比StreamGraph、StreamNode和StreamEdge来理解

flink:StreamGraph转换为JobGraph的更多相关文章
- 追源索骥:透过源码看懂Flink核心框架的执行流程
li,ol.inline>li{display:inline-block;padding-right:5px;padding-left:5px}dl{margin-bottom:20px}dt, ...
- flink学习笔记:DataSream API
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- flink学习笔记-flink实战
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink学习笔记-支持的数据类型
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink 灵魂两百问,这谁顶得住?
Flink 学习 https://github.com/zhisheng17/flink-learning 麻烦路过的各位亲给这个项目点个 star,太不易了,写了这么多,算是对我坚持下来的一种鼓励吧 ...
- Flink源码分析 - 剖析一个简单的Flink程序
本篇文章首发于头条号Flink程序是如何执行的?通过源码来剖析一个简单的Flink程序,欢迎关注头条号和微信公众号"大数据技术和人工智能"(微信搜索bigdata_ai_tech) ...
- 透过源码看懂Flink核心框架的执行流程
前言 Flink是大数据处理领域最近很火的一个开源的分布式.高性能的流式处理框架,其对数据的处理可以达到毫秒级别.本文以一个来自官网的WordCount例子为引,全面阐述flink的核心架构及执行流程 ...
- [源码解析] 当 Java Stream 遇见 Flink
[源码解析] 当 Java Stream 遇见 Flink 目录 [源码解析] 当 Java Stream 遇见 Flink 0x00 摘要 0x01 领域 1.1 Flink 1.2 Java St ...
- Flink源码阅读(1.7.2)
目录 Client提交任务 flink的图结构 StreamGraph OptimizedPlan JobGraph ExecutionGraph flink部署与执行模型 Single Job Jo ...
随机推荐
- 微信小程序UI自动化:实践之后的记录01-选择工具/框架
目录 1. 前言 2. 工具/框架/库选择 2.1 miniprogram-automator官方介绍(摘自官方哈) 小程序自动化 特性 2.2 minium官方介绍 特性 3. 如何选择 4. 对应 ...
- 原生JS结合cookie实现商品评分组件
开发思路如下: 1.利用JS直接操作DOM的方式开发商品评分组件,主要实现功能有:显示评价评分的样式以及将用户操作后对应的数据返回到主页面 2.主页面引入商品评分组件的js文件并根据规定格式的数据,生 ...
- Java学习的第二十天
1.类是单继承的,类是多继承的.. 接口只能继承接口 标识接口没有任何的属性和方法 2.今天没有问题 3.明天学习综合实例和第八章开头部分
- mysql 快速清除数据表数据
mysql> truncate tables; 例如: mysql> truncate email_managements;
- jetson-reference编译出现的问题记录
问题一: 显示gcc版本过高,需要安装低版本的gcc.g++ sudo apt-get install -y gcc-4.9 sudo apt-get install -y g++-4.9 cd /u ...
- python开发基础(二)运算符以及数据类型之tuple(元组)
# encoding: utf-8 # module builtins # from (built-in) # by generator 1.147 """ Built- ...
- Spark编程练习题
import org.apache.spark.sql.SparkSessionval spark = SparkSession.builder().appName("Spark SQL b ...
- LSV又新增13个地质图!量测对比分析全都能搞定
对于地质工作者来说,地质图是个十分重要的参考资料.随着国家解密的地质资料越来越多,能够有效的把各种地质资料结合起来,进而提高地质工作者的作业效率,是十分有意义的. LSV(LocaSpaceViewe ...
- centos常用指令之-卸载
卸载centos自带java: rpm -qa|grep java // 查询javax相关 xxxxxxxxxxxxxx # 卸载1.2方式 # 1 yum -y remove java xxxxx ...
- Failed connect to mirrors.cloud.aliyuncs.com:80
在yum insatall 安装是报错 Failed connect to mirrors.cloud.aliyuncs.com:80; Connection refused 解决方法: cd /et ...