分析 5种分布式事务方案,还是选了阿里的 Seata(原理 + 实战)
好长时间没发文了,最近着实是有点忙,当爹的第 43 天,身心疲惫。这又赶上年底,公司冲 KPI 强制技术部加班到十点,晚上孩子隔两三个小时一醒,基本没睡囫囵觉的机会,天天处于迷糊的状态,孩子还时不时起一些奇奇怪怪的疹子,总让人担惊受怕的。
本就不多的写文章时间又被无限分割,哎~ 打工人真是太难了。
本来不知道写点啥,正好手头有个新项目试着用阿里的 Seata 中间件做分布式事务,那就做一个实践分享吧!
介绍 Seata 之前在简单回顾一下分布式事务的基本概念。
分布式事务的产生
我们先看看百度上对于分布式事务的定义:分布式事务是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上。

额~ 有点抽象,简单的画个图好理解一下,拿下单减库存、扣余额来说举例:
当系统的体量很小时,单体架构完全可以满足现有业务需求,所有的业务共用一个数据库,整个下单流程或许只用在一个方法里同一个事务下操作数据库即可。此时做到所有操作要么全部提交 或 要么全部回滚很容易。

分库分表、SOA
可随着业务量的不断增长,单体架构渐渐扛不住巨大的流量,此时就需要对数据库、表做 分库分表处理,将应用 SOA 服务化拆分。也就产生了订单中心、用户中心、库存中心等,由此带来的问题就是业务间相互隔离,每个业务都维护着自己的数据库,数据的交换只能进行 RPC 调用。
当用户再次下单时,需同时对订单库 order、库存库 storage、用户库 account 进行操作,可此时我们只能保证自己本地的数据一致性,无法保证调用其他服务的操作是否成功,所以为了保证整个下单流程的数据一致性,就需要分布式事务介入。

Seata 优势
实现分布式事务的方案比较多,常见的比如基于 XA 协议的 2PC、3PC,基于业务层的 TCC,还有应用消息队列 + 消息表实现的最终一致性方案,还有今天要说的 Seata 中间件,下边看看各个方案的优缺点。
2PC
基于 XA 协议实现的分布式事务,XA 协议中分为两部分:事务管理器和本地资源管理器。其中本地资源管理器往往由数据库实现,比如 Oracle、MYSQL 这些数据库都实现了 XA 接口,而事务管理器则作为一个全局的调度者。
两阶段提交(2PC),对业务侵⼊很小,它最⼤的优势就是对使⽤⽅透明,用户可以像使⽤本地事务⼀样使⽤基于 XA 协议的分布式事务,能够严格保障事务 ACID 特性。

可 2PC的缺点也是显而易见,它是一个强一致性的同步阻塞协议,事务执⾏过程中需要将所需资源全部锁定,也就是俗称的 刚性事务。所以它比较适⽤于执⾏时间确定的短事务,整体性能比较差。
一旦事务协调者宕机或者发生网络抖动,会让参与者一直处于锁定资源的状态或者只有一部分参与者提交成功,导致数据的不一致。因此,在⾼并发性能⾄上的场景中,基于 XA 协议的分布式事务并不是最佳选择。

3PC
三段提交(3PC)是二阶段提交(2PC)的一种改进版本 ,为解决两阶段提交协议的阻塞问题,上边提到两段提交,当协调者崩溃时,参与者不能做出最后的选择,就会一直保持阻塞锁定资源。
2PC 中只有协调者有超时机制,3PC 在协调者和参与者中都引入了超时机制,协调者出现故障后,参与者就不会一直阻塞。而且在第一阶段和第二阶段中又插入了一个准备阶段(如下图,看着有点啰嗦),保证了在最后提交阶段之前各参与节点的状态是一致的。

虽然 3PC 用超时机制,解决了协调者故障后参与者的阻塞问题,但与此同时却多了一次网络通信,性能上反而变得更差,也不太推荐。
TCC
所谓的 TCC 编程模式,也是两阶段提交的一个变种,不同的是 TCC 为在业务层编写代码实现的两阶段提交。TCC 分别指 Try、Confirm、Cancel ,一个业务操作要对应的写这三个方法。
以下单扣库存为例,Try 阶段去占库存,Confirm 阶段则实际扣库存,如果库存扣减失败 Cancel 阶段进行回滚,释放库存。
TCC 不存在资源阻塞的问题,因为每个方法都直接进行事务的提交,一旦出现异常通过则 Cancel 来进行回滚补偿,这也就是常说的补偿性事务。
原本一个方法,现在却需要三个方法来支持,可以看到 TCC 对业务的侵入性很强,而且这种模式并不能很好地被复用,会导致开发量激增。还要考虑到网络波动等原因,为保证请求一定送达都会有重试机制,所以考虑到接口的幂等性。
消息事务(最终一致性)
消息事务其实就是基于消息中间件的两阶段提交,将本地事务和发消息放在同一个事务里,保证本地操作和发送消息同时成功。
下单扣库存原理图:

- 订单系统向
MQ发送一条预备扣减库存消息,MQ保存预备消息并返回成功ACK - 接收到预备消息执行成功
ACK,订单系统执行本地下单操作,为防止消息发送成功而本地事务失败,订单系统会实现MQ的回调接口,其内不断的检查本地事务是否执行成功,如果失败则rollback回滚预备消息;成功则对消息进行最终commit提交。 - 库存系统消费扣减库存消息,执行本地事务,如果扣减失败,消息会重新投,一旦超出重试次数,则本地表持久化失败消息,并启动定时任务做补偿。
基于消息中间件的两阶段提交方案,通常用在高并发场景下使用,牺牲数据的强一致性换取性能的大幅提升,不过实现这种方式的成本和复杂度是比较高的,还要看实际业务情况。
Seata
Seata 也是从两段提交演变而来的一种分布式事务解决方案,提供了 AT、TCC、SAGA 和 XA 等事务模式,这里重点介绍 AT模式。
既然 Seata 是两段提交,那我们看看它在每个阶段都做了点啥?下边我们还以下单扣库存、扣余额举例。

先介绍 Seata 分布式事务的几种角色:
Transaction Coordinator(TC): 全局事务协调者,用来协调全局事务和各个分支事务(不同服务)的状态, 驱动全局事务和各个分支事务的回滚或提交。Transaction Manager: 事务管理者,业务层中用来开启/提交/回滚一个整体事务(在调用服务的方法中用注解开启事务)。Resource Manager(RM): 资源管理者,一般指业务数据库代表了一个分支事务(Branch Transaction),管理分支事务与TC进行协调注册分支事务并且汇报分支事务的状态,驱动分支事务的提交或回滚。
Seata 实现分布式事务,设计了一个关键角色
UNDO_LOG(回滚日志记录表),我们在每个应用分布式事务的业务库中创建这张表,这个表的核心作用就是,将业务数据在更新前后的数据镜像组织成回滚日志,备份在UNDO_LOG表中,以便业务异常能随时回滚。
第一个阶段
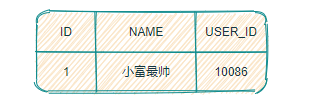
比如:下边我们更新 user 表的 name 字段。
update user set name = '小富最帅' where name = '程序员内点事'
首先 Seata 的 JDBC 数据源代理通过对业务 SQL 解析,提取 SQL 的元数据,也就是得到 SQL 的类型(UPDATE),表(user),条件(where name = '程序员内点事')等相关的信息。
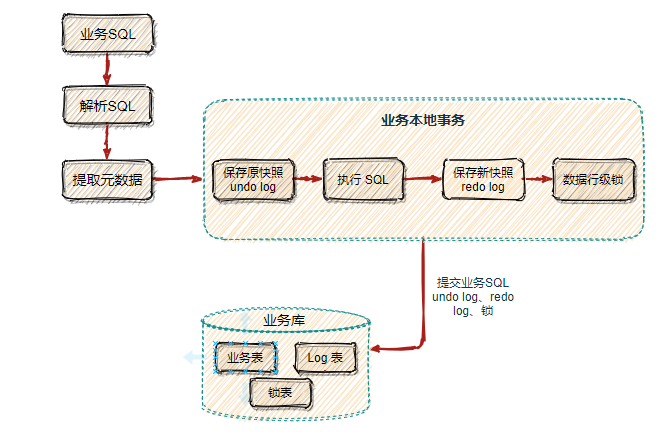
先查询数据前镜像,根据解析得到的条件信息,生成查询语句,定位一条数据。
select name from user where name = '程序员内点事'

紧接着执行业务 SQL,根据前镜像数据主键查询出后镜像数据
select name from user where id = 1
把业务数据在更新前后的数据镜像组织成回滚日志,将业务数据的更新和回滚日志在同一个本地事务中提交,分别插入到业务表和 UNDO_LOG 表中。
回滚记录数据格式如下:包括 afterImage 前镜像、beforeImage 后镜像、 branchId 分支事务ID、xid 全局事务ID
{
"branchId":641789253,
"xid":"xid:xxx",
"undoItems":[
{
"afterImage":{
"rows":[
{
"fields":[
{
"name":"id",
"type":4,
"value":1
}
]
}
],
"tableName":"product"
},
"beforeImage":{
"rows":[
{
"fields":[
{
"name":"id",
"type":4,
"value":1
}
]
}
],
"tableName":"product"
},
"sqlType":"UPDATE"
}
]
}
这样就可以保证,任何提交的业务数据的更新一定有相应的回滚日志。
在本地事务提交前,各分支事务需向
全局事务协调者TC 注册分支 (Branch Id) ,为要修改的记录申请 全局锁 ,要为这条数据加锁,利用SELECT FOR UPDATE语句。而如果一直拿不到锁那就需要回滚本地事务。TM 开启事务后会生成全局唯一的XID,会在各个调用的服务间进行传递。
有了这样的机制,本地事务分支(Branch Transaction)便可以在全局事务的第一阶段提交,并马上释放本地事务锁定的资源。相比于传统的 XA 事务在第二阶段释放资源,Seata 降低了锁范围提高效率,即使第二阶段发生异常需要回滚,也可以快速 从UNDO_LOG 表中找到对应回滚数据并反解析成 SQL 来达到回滚补偿。
最后本地事务提交,业务数据的更新和前面生成的 UNDO LOG 数据一并提交,并将本地事务提交的结果上报给全局事务协调者 TC。
第二个阶段
第二阶段是根据各分支的决议做提交或回滚:
如果决议是全局提交,此时各分支事务已提交并成功,这时 全局事务协调者(TC) 会向分支发送第二阶段的请求。收到 TC 的分支提交请求,该请求会被放入一个异步任务队列中,并马上返回提交成功结果给 TC。异步队列中会异步和批量地根据 Branch ID 查找并删除相应 UNDO LOG 回滚记录。

如果决议是全局回滚,过程比全局提交麻烦一点,RM 服务方收到 TC 全局协调者发来的回滚请求,通过 XID 和 Branch ID 找到相应的回滚日志记录,通过回滚记录生成反向的更新 SQL 并执行,以完成分支的回滚。
注意:这里删除回滚日志记录操作,一定是在本地业务事务执行之后

上边说了几种分布式事务各自的优缺点,下边实践一下分布式事务中间 Seata 感受一下。
Seata 实践
Seata 是一个需独立部署的中间件,所以先搭 Seata Server,这里以最新的 seata-server-1.4.0 版本为例,下载地址:https://seata.io/en-us/blog/download.html
解压后的文件我们只需要关心 \seata\conf 目录下的 file.conf 和 registry.conf 文件。
Seata Server
file.conf
file.conf 文件用于配置持久化事务日志的模式,目前提供 file、db、redis 三种方式。
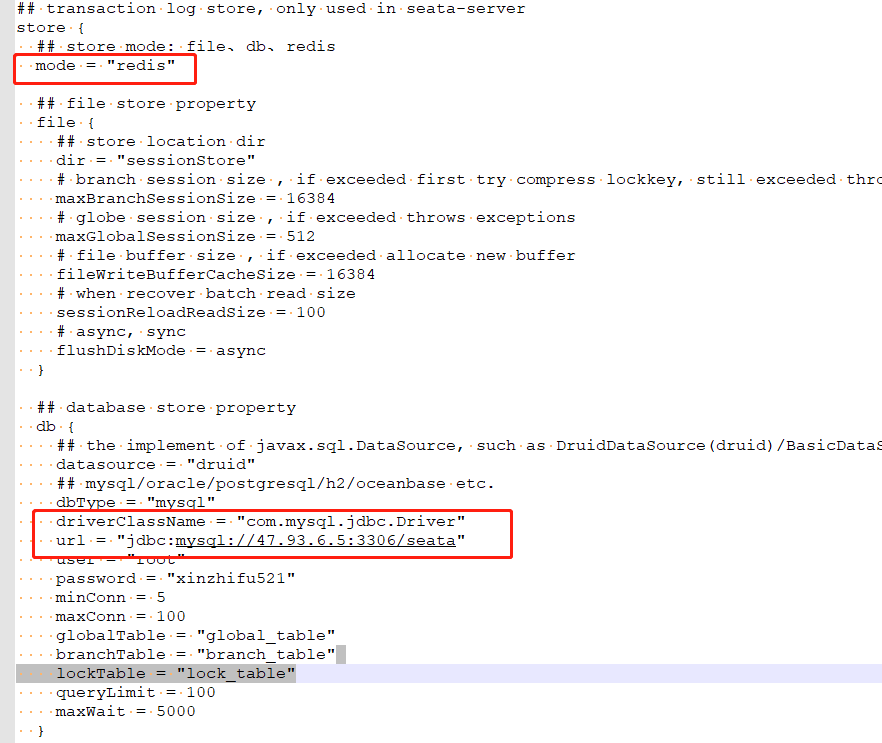
注意:在选择 db 方式后,需要在对应数据库创建 globalTable(持久化全局事务)、branchTable(持久化各提交分支的事务)、 lockTable(持久化各分支锁定资源事务)三张表。
-- the table to store GlobalSession data
-- 持久化全局事务
CREATE TABLE IF NOT EXISTS `global_table`
(
`xid` VARCHAR(128) NOT NULL,
`transaction_id` BIGINT,
`status` TINYINT NOT NULL,
`application_id` VARCHAR(32),
`transaction_service_group` VARCHAR(32),
`transaction_name` VARCHAR(128),
`timeout` INT,
`begin_time` BIGINT,
`application_data` VARCHAR(2000),
`gmt_create` DATETIME,
`gmt_modified` DATETIME,
PRIMARY KEY (`xid`),
KEY `idx_gmt_modified_status` (`gmt_modified`, `status`),
KEY `idx_transaction_id` (`transaction_id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8;
-- the table to store BranchSession data
-- 持久化各提交分支的事务
CREATE TABLE IF NOT EXISTS `branch_table`
(
`branch_id` BIGINT NOT NULL,
`xid` VARCHAR(128) NOT NULL,
`transaction_id` BIGINT,
`resource_group_id` VARCHAR(32),
`resource_id` VARCHAR(256),
`branch_type` VARCHAR(8),
`status` TINYINT,
`client_id` VARCHAR(64),
`application_data` VARCHAR(2000),
`gmt_create` DATETIME(6),
`gmt_modified` DATETIME(6),
PRIMARY KEY (`branch_id`),
KEY `idx_xid` (`xid`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8;
-- the table to store lock data
-- 持久化每个分支锁表事务
CREATE TABLE IF NOT EXISTS `lock_table`
(
`row_key` VARCHAR(128) NOT NULL,
`xid` VARCHAR(96),
`transaction_id` BIGINT,
`branch_id` BIGINT NOT NULL,
`resource_id` VARCHAR(256),
`table_name` VARCHAR(32),
`pk` VARCHAR(36),
`gmt_create` DATETIME,
`gmt_modified` DATETIME,
PRIMARY KEY (`row_key`),
KEY `idx_branch_id` (`branch_id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8;
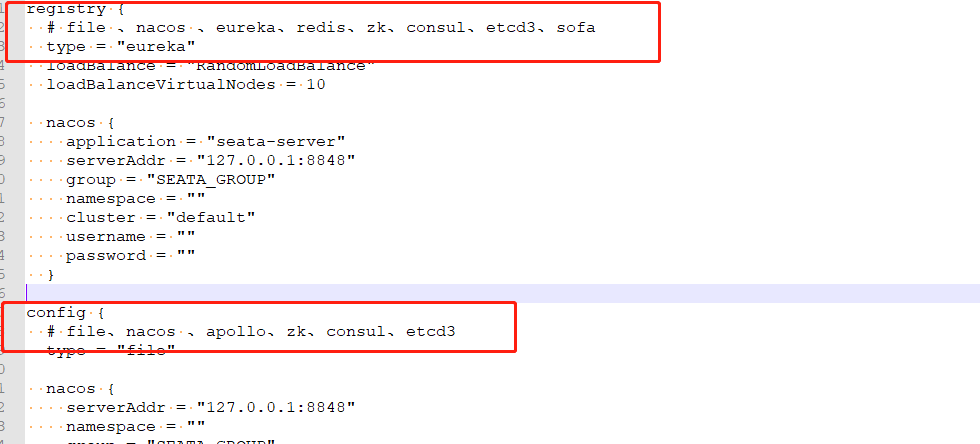
registry.conf
registry.conf 文件设置 注册中心 和 配置中心:
目前注册中心支持 nacos 、eureka、redis、zk、consul、etcd3、sofa 七种,这里我使用的 eureka作为注册中心 ; 配置中心支持 nacos 、apollo、zk、consul、etcd3 五种方式。
配置完以后在 \seata\bin 目录下启动 seata-server 即可,到这 Seata 的服务端就搭建好了。
Seata Client
Seata Server 环境搭建完,接下来我们新建三个服务 order-server(下单服务)、storage-server(扣减库存服务)、account-server(账户金额服务),分别服务注册到 eureka。
每个服务的大体核心配置如下:
spring:
application:
name: storage-server
cloud:
alibaba:
seata:
tx-service-group: my_test_tx_group
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://47.93.6.1:3306/seat-storage
username: root
password: root
# eureka 注册中心
eureka:
client:
serviceUrl:
defaultZone: http://${eureka.instance.hostname}:8761/eureka/
instance:
hostname: 47.93.6.5
prefer-ip-address: true
业务大致流程:用户发起下单请求,本地 order 订单服务创建订单记录,并通过 RPC 远程调用 storage 扣减库存服务和 account 扣账户余额服务,只有三个服务同时执行成功,才是一个完整的下单流程。如果某个服执行失败,则其他服务全部回滚。
Seata 对业务代码的侵入性非常小,代码中使用只需用 @GlobalTransactional 注解开启一个全局事务即可。
@Override
@GlobalTransactional(name = "create-order", rollbackFor = Exception.class)
public void create(Order order) {
String xid = RootContext.getXID();
LOGGER.info("------->交易开始");
//本地方法
orderDao.create(order);
//远程方法 扣减库存
storageApi.decrease(order.getProductId(), order.getCount());
//远程方法 扣减账户余额
LOGGER.info("------->扣减账户开始order中");
accountApi.decrease(order.getUserId(), order.getMoney());
LOGGER.info("------->扣减账户结束order中");
LOGGER.info("------->交易结束");
LOGGER.info("全局事务 xid: {}", xid);
}
前边说过 Seata AT 模式实现分布式事务,必须在相关的业务库中创建 undo_log 表来存数据回滚日志,表结构如下:
-- for AT mode you must to init this sql for you business database. the seata server not need it.
CREATE TABLE IF NOT EXISTS `undo_log`
(
`id` BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT 'increment id',
`branch_id` BIGINT(20) NOT NULL COMMENT 'branch transaction id',
`xid` VARCHAR(100) NOT NULL COMMENT 'global transaction id',
`context` VARCHAR(128) NOT NULL COMMENT 'undo_log context,such as serialization',
`rollback_info` LONGBLOB NOT NULL COMMENT 'rollback info',
`log_status` INT(11) NOT NULL COMMENT '0:normal status,1:defense status',
`log_created` DATETIME NOT NULL COMMENT 'create datetime',
`log_modified` DATETIME NOT NULL COMMENT 'modify datetime',
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`)
) ENGINE = InnoDB
AUTO_INCREMENT = 1
DEFAULT CHARSET = utf8 COMMENT ='AT transaction mode undo table';
到这环境搭建的工作就完事了,完整案例会在后边贴出
GitHub地址,就不在这占用篇幅了。
测试 Seata
项目中的服务调用过程如下图:
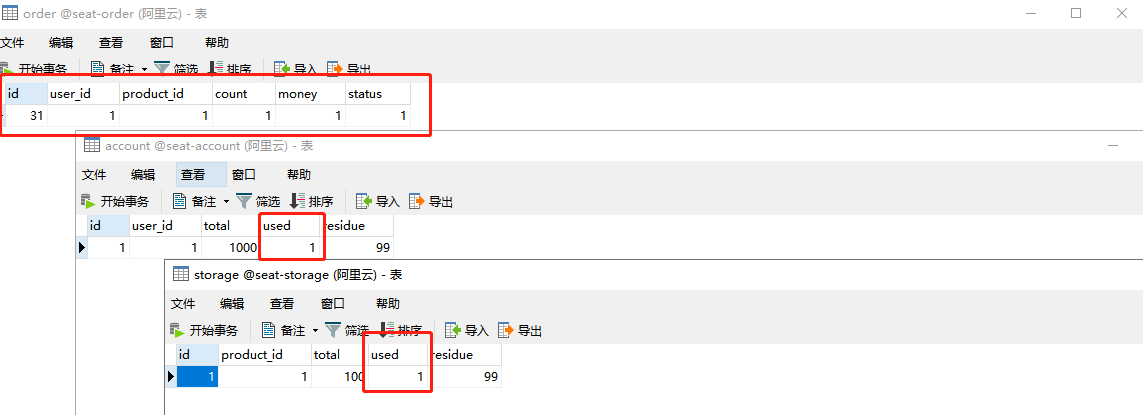
启动各个服务后,我们直接请求下单接口看看效果,只要 order 订单表创建记录成功,storage 库存表 used 字段数量递增、account 余额表 used 字段数量递增则表示下单流程成功。
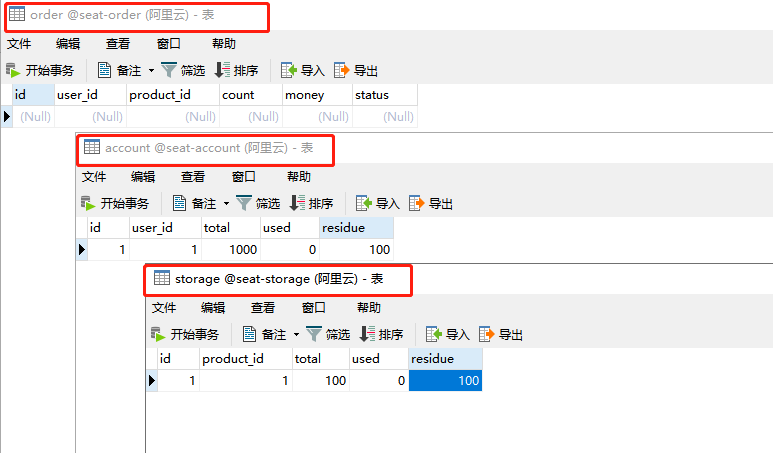
请求后正向流程是没问题的,数据和预想的一样
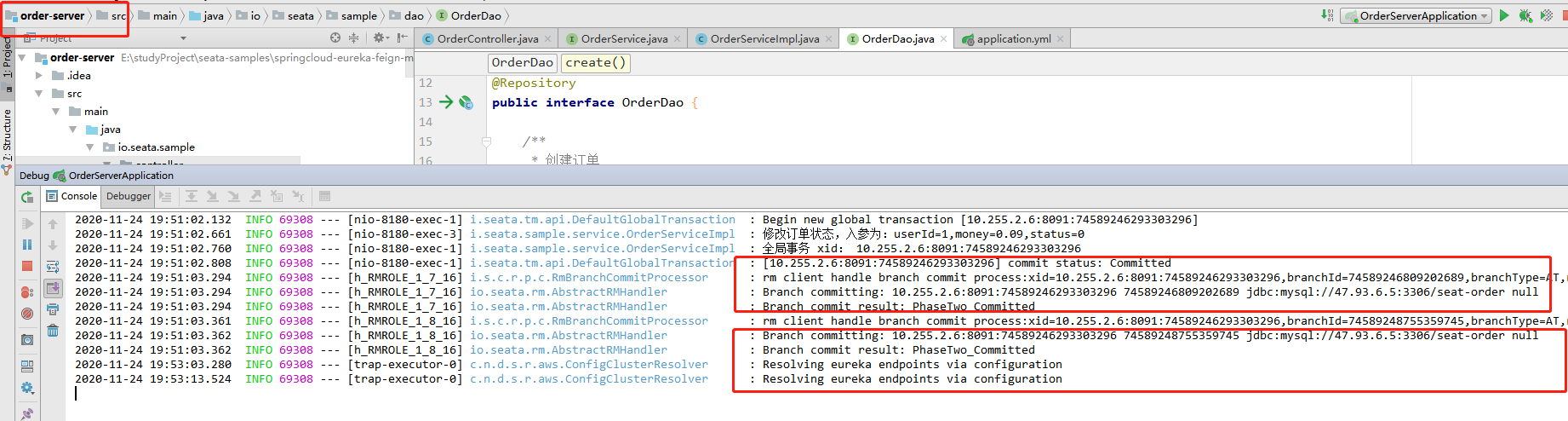
而且发现 TM 事务管理者 order-server 服务的控制台也打印出了两阶段提交的日志
那么再看看如果其中一个服务异常,会不会正常回滚呢?在 account-server 服务中模拟超时异常,看能否实现全局事务回滚。
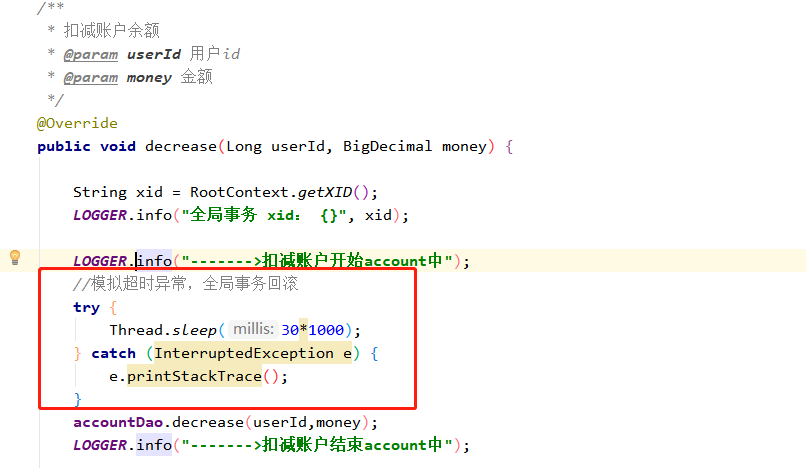
发现数据全没执行成功,说明全局事务回滚也成功了

那看一下 undo_log 回滚记录表的变化情况,由于 Seata 删除回滚日志的速度很快,所以要想在表中看见回滚日志,必须要在某一个服务上打断点才看的更明显。

总结
上边简单介绍了 2PC、3PC、TCC、MQ、Seata 这五种分布式事务解决方案,还详细的实践了 Seata 中间件。但不管我们选哪一种方案,在项目中应用都要谨慎再谨慎,除特定的数据强一致性场景外,能不用尽量就不要用,因为无论它们性能如何优越,一旦项目套上分布式事务,整体效率会几倍的下降,在高并发情况下弊端尤为明显。
本案例 github 地址:https://github.com/chengxy-nds/Springboot-Notebook/tree/master/springboot-seata-transaction
如果有一丝收获,欢迎 点赞、转发 ,您的认可是我最大的动力。
整理了几百本各类技术电子书,有需要的同学可以,关注公号回复 [ 666 ] 自取。还有想要加技术群的可以加我好友,和大佬侃技术、不定期内推,一起学起来。
分析 5种分布式事务方案,还是选了阿里的 Seata(原理 + 实战)的更多相关文章
- 对比7种分布式事务方案,还是偏爱阿里开源的Seata,真香!(原理+实战)
前言 这是<Spring Cloud 进阶>专栏的第六篇文章,往期文章如下: 五十五张图告诉你微服务的灵魂摆渡者Nacos究竟有多强? openFeign夺命连环9问,这谁受得了? 阿里面 ...
- Dubbo学习系列之十五(Seata分布式事务方案TCC模式)
上篇的续集. 工具: Idea201902/JDK11/Gradle5.6.2/Mysql8.0.11/Lombok0.27/Postman7.5.0/SpringBoot2.1.9/Nacos1.1 ...
- Dubbo学习系列之十四(Seata分布式事务方案AT模式)
一直说写有关最新技术的文章,但前面似乎都有点偏了,只能说算主流技术,今天这个主题,我觉得应该名副其实.分布式微服务的深水区并不是单个微服务的设计,而是服务间的数据一致性问题!解决了这个问题,才算是把分 ...
- ebay分布式事务方案中文版
http://cailin.iteye.com/blog/2268428 不使用分布式事务实现目的 -- ibm https://www.ibm.com/developerworks/cn/clou ...
- [转帖]深度剖析一站式分布式事务方案 Seata-Server
深度剖析一站式分布式事务方案 Seata-Server https://www.jianshu.com/p/940e2cfab67e 金融级分布式架构关注 22019.04.10 16:59:14字数 ...
- 分布式事务与Seate框架(3)——Seata的AT模式实现原理
前言 在上两篇博文(分布式事务与Seate框架(1)--分布式事务理论.分布式事务与Seate框架(2)--Seata实践)中已经介绍并实践过Seata AT模式,这里一些例子与概念来自这两篇(特别是 ...
- 分布式事务与Seate框架(2)——Seata实践
前言 在上一篇博文(分布式事务与Seate框架(1)--分布式事务理论)中了解了足够的分布式事务的理论知识后,到了实践部分,在工作中虽然用到了Seata,但是自己却并没有完全实践过,所以自己私下花点时 ...
- AOP事务解决方案和分布式事务方案
http://www.cnblogs.com/jianxuanbing/p/7242254.html http://www.cnblogs.com/jianxuanbing/p/7199457.htm ...
- 分布式服务化系统一致性(分布式事务、ACID、BASE、CAP)原理与解决方案
https://blog.csdn.net/rickiyeat/article/details/70224722
随机推荐
- html2canvas.js——HTML转Canvas工具
我们经常会遇上动态生成海报的需求,而在Web前端中,生成图片非Canvas莫属.但是在实际工作当中,为了追求效率,我们会不可避免地去使用一些JS插件,而html2canvas.js就是一款优秀的插件, ...
- 应用LORAWAN技术的好处是什么
LoRaWAN现在一种非常流行的LPWA通信标准,在ISM(工业.科学.医疗)频段使用未经许可的无线电频谱,频率约为900MHz到430MHz(世界各地的标准各不相同). 物联网连接环境除了智能家庭联 ...
- EBAZ4205学习资源整理
EBAZ4205是一块矿机的控制板,芯片是ZYNQ7010,某鱼上应该不超过30元就能买一块,垃圾佬狂喜 经过不复杂的操作就能进行正常开发,由于货量比较大现在已经有很多大佬写了很多很多好的资料,这里我 ...
- From delete library to run の 初见Django篇
一.虚拟环境简介 1.什么是虚拟环境? 虚拟环境是用于依赖项管理和项目隔离的python工具,允许python的第三方库安装在本地特定项目的隔离目录中,而不是全局安装. 2.虚拟环境的组成 ① 安装了 ...
- python造一个计算器
正则表达式之简易计算器 关注公众号"轻松学编程"了解更多. 需求:使用正则表达式完成一个简易计算器. 功能:能够计算简单的表达式. 如:12((1+2)/(2+3)+1)*5.1- ...
- 2020 年TI 杯大学生电子设计竞赛E题总结(放大器非线性失真研究装置)
2020年TI杯大学生电子设计竞赛E题总结(放大器非线性失真研究装置) 摘要:E题的竞赛内容主要是参赛者自己搭建一个晶体管放大器,能够产生不失真.顶部失真.底部失真.双向失真和交越失真五种波形,并分别 ...
- AWS SDK 使用说明
AWS 的Python SDK包名为 boto3, 可以使用命令pip install boto3安装使用 BOTO3中的基本概念 boto3提供了两个级别的接口来访问AWS服务:High Level ...
- SQL2005数据库可疑的解决方法
sqlserver数据库标注为可疑的解决办法 一般引起可疑的原因是突然断电,服务器死机,强制关机导致正在运行的数据库文件损坏,需要进行修复.方法一:USE MASTER GOSP_CONFIGURE ...
- TRUNCATE 有约束的表
在有外键约束的情况下,truncate 表时,会报错, 我们可以设置外键检测为flase,执行完truncate命令后,再启用 SET foreign_key_checks = 0;TRUNCATE ...
- 在windows下安装node-sass失败,提示\node-sass: Command failed,解决方案
执行命令 yarn add node-sass@4.7.2 --dev --registry=https://registry.npm.taobao.org :报错 出现这个问题的原因一般是网络问题, ...