hdu2196 Compute
Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)
Total Submission(s): 4646 Accepted Submission(s): 2345
net and want to know the maximum distance Si for which i-th computer needs to send signal (i.e. length of cable to the most distant computer). You need to provide this information.
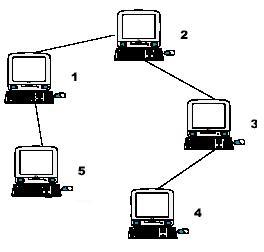
Hint: the example input is corresponding to this graph. And from the graph, you can see that the computer 4 is farthest one from 1, so S1 = 3. Computer 4 and 5 are the farthest ones from 2, so S2 = 2. Computer 5 is the farthest one from 3, so S3 = 3. we also
get S4 = 4, S5 = 4.
and length of cable used for connection. Total length of cable does not exceed 10^9. Numbers in lines of input are separated by a space.
1 1
2 1
3 1
1 1
2
3
4
4
#include<iostream>
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<math.h>
#include<vector>
#include<map>
#include<set>
#include<queue>
#include<stack>
#include<string>
#include<algorithm>
using namespace std;
typedef long long ll;
#define inf 99999999
#define maxn 10060
struct node{
int len,to,next;
}e[2*maxn];
int first[maxn],vis[maxn],dist1[maxn],dist2[maxn],ans[maxn];//dist1[i]表示最大路,dist2[i]表示次大路,dist1id[i]表示得到最大路的叶子节点编号,dist2id[i]表示得到次大路的叶子节点编号
int dist1id[maxn],dist2id[maxn];
void dfs(int u)
{
int i,j,t1,t2,flag;
t1=t2=0;
vis[u]=1;
flag=0;
for(i=first[u];i!=-1;i=e[i].next){
int v=e[i].to;
if(vis[v])continue;
flag=1;
dfs(v);
int t=e[i].len+dist1[v];
if(t>=dist1[u]){
dist2[u]=dist1[u];
dist1[u]=t;
dist2id[u]=dist1id[u];
dist1id[u]=dist1id[v];
}
else if(t>dist2[u]){
dist2[u]=t;
dist2id[u]=dist1id[v];
}
}
if(flag==0){
dist1[u]=dist2[u]=0;
dist1id[u]=dist2id[u]=u;return;
}
}
void dfs1(int u)
{
int i,j,t,t1,t2;
t1=t2=0;
vis[u]=1;
for(i=first[u];i!=-1;i=e[i].next){
int v=e[i].to;
if(vis[v])continue;
if(dist1id[u]==dist1id[v]){ //这里先看一下父亲节点所求出的最大路的叶子节点编号是不是和当前节点相同
int t=e[i].len+dist2[u];
if(t>=dist1[v]){
dist2[v]=dist1[v];
dist2id[v]=dist1id[v];
dist1[v]=t;
dist1id[v]=dist2id[u];
}
else if(t>dist2[v]){
dist2[v]=t;
dist2id[v]=dist2id[u];
} //要随时更新dist1[i],这里dist1[i]已经不仅是子树范围了,而是全部范围
}
else{
int t=e[i].len+dist1[u];
if(t>=dist1[v]){
dist2[v]=dist1[v];
dist2id[v]=dist1id[v];
dist1[v]=t;
dist1id[v]=dist1id[u];
}
else if(t>dist2[v]){
dist2[v]=t;
dist2id[v]=dist1id[u];
}
}
dfs1(v);
}
}
int main()
{
int n,m,i,j,c,d;
while(scanf("%d",&n)!=EOF)
{
memset(first,-1,sizeof(first));
int tot=0;
for(i=2;i<=n;i++){
scanf("%d%d",&c,&d);
int u,v;
u=i;v=c;
tot++;
e[tot].next=first[u];e[tot].to=v;e[tot].len=d;
first[u]=tot;
tot++;
e[tot].next=first[v];e[tot].to=u;e[tot].len=d;
first[v]=tot;
}
memset(vis,0,sizeof(vis));
memset(dist1,0,sizeof(dist1));
memset(dist2,0,sizeof(dist2));
memset(dist1id,0,sizeof(dist1id));
memset(dist2id,0,sizeof(dist2id));
dfs(1);
memset(vis,0,sizeof(vis));
dfs1(1);
for(i=1;i<=n;i++){
printf("%d\n",dist1[i]);
}
}
return 0;
}hdu2196 Compute的更多相关文章
- C#中DataTable中的Compute方法使用收集
原文: C#中DataTable中的Compute方法使用收集 Compute函数的参数就两个:Expression,和Filter. Expresstion是计算表达式,关于Expression的详 ...
- Compute Resource Consolidation Pattern 计算资源整合模式
Consolidate multiple tasks or operations into a single computational unit. This pattern can increase ...
- 学习OpenStack之(6):Neutron 深入学习之 OVS + GRE 之 Compute node 篇
0.环境 硬件环境见上一篇博客:学习OpenStack之(5):在Mac上部署Juno版本OpenStack 四节点环境 OpenStack网络配置:一个tenant, 2个虚机 Type drive ...
- openstack-lanch an instance and nova compute log analysis
1. how to launch an instance: [root@localhost ~(keystone_admin)]# nova flavor-list+----+-----------+ ...
- 【原创翻译】初识Unity中的Compute Shader
一直以来都想试着自己翻译一些东西,现在发现翻译真的很不容易,如果你直接把作者的原文按照英文的思维翻译过来,你会发现中国人读起来很是别扭,但是如果你想完全利用中国人的语言方式来翻译,又怕自己理解的不到位 ...
- Many2one类型的fields Compute得到的值 搜索
v8 默认情况下compute的值不存储于数据库中,在高级搜索中也不可以进行搜索 想要对这种类型的值搜索,需要在field的定义中添加search参数,在search的函数中编写搜索逻辑. 例子: r ...
- A trip through the Graphics Pipeline 2011_13 Compute Shaders, UAV, atomic, structured buffer
Welcome back to what’s going to be the last “official” part of this series – I’ll do more GPU-relate ...
- DataTable.Compute()用法
DataTable.Compute()用法 2010-04-07 11:28 一.DataTable.Compute()方法說明如下 作用: 计算用来传递筛选条件的当前行上的给定表达 ...
- 转:DataTable的Compute方法的应用
转自:http://www.cnblogs.com/hfliyi/archive/2013/01/08/2851944.html 项目中遇到计算平均值.标准偏差.平均值+标准偏差.平均值+2倍标准偏差 ...
随机推荐
- 剑指offer 面试题5:替换空格
题目描述 请实现一个函数,将一个字符串中的每个空格替换成"%20".例如,当字符串为We Are Happy. 则经过替换之后的字符串为We%20Are%20Happy. 编程思想 ...
- Shiro的认证与授权
shiro实战教程 一.权限管理 1.1什么是权限管理 基本上涉及到用户参与的系统都需要进行权限管理,权限管理属于系统安全的范畴,权限管理实现对用户访问系统的控制,按照安全规则或者安全策略控制用户可以 ...
- [oracle] exp-00091
产生原因: 在数据库的服务器端和客户端字符集不同的情况下,导出(dump)数据库表时,会产生这个错误.虽然产生这个错误,但好像对导入没有影响. 解决办法: 查看服务器端字符集: 打开SQLPLUS,执 ...
- 国人之光:大数据分析神器Apache Kylin
一.简介 Apache Kylin是一个开源的.分布式的分析型数据仓库,提供Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由 eBay 开发并贡献 ...
- Pandas的数据分组-aggregate聚合
在对数据进行分组之后,可以对分组后的数据进行聚合处理统计. agg函数,agg的形参是一个函数会对分组后每列都应用这个函数. import pandas as pd import numpy as n ...
- Jmeter的Cookie管理器调试与参数化
默认系统都是需要登录,才能操作其它接口,所以需要添加一个HTTP Cookie 管理器,默认Cookie管理器是关闭的,需要修改jmeter配置文件jmeter.properties,该文件在jme ...
- OPTIONS的预请求(Preflighted Request)
OPTIONS的预请求(Preflighted Request) Ajax 请求中出现OPTIONS(Request Method: OPTIONS)_qiao-CSDN博客 https://blog ...
- pip freeze 需求文件requirements.txt的创建及使用 虚拟环境
总结: 1.输出安装的包信息,并在另一个环境快速安装 Generate output suitable for a requirements file. $ pip freeze docutils== ...
- .Net 5 C# 泛型(Generics)
这里有个目录 什么是泛型? 后记 什么是泛型? 我们试试实现这个需求,给一个对象,然后返回 另一个同样的对象,先不管这个实用性,我们实现看看 首先是int型 private int Get(int a ...
- 编译安装 codeblocks 20.03 mips64el
期末考试要用哦,不然谁会愿意去踩这么多坑. qaq 龙梦 Fedora28 中有 codeblocks 17.12,但是 Ctrl-v 粘贴会闪退,导致压根不能用.Bing了一下发现这其实是 code ...