Faster RCNN代码理解(Python)
转自http://www.infocool.net/kb/Python/201611/209696.html#原文地址
第一步,准备
从train_faster_rcnn_alt_opt.py入:
- 初始化参数:args = parse_args() 采用的是Python的argparse
主要有–net_name,–gpu,–cfg等(在cfg中只是修改了几个参数,其他大部分参数在congig.py中,涉及到训练整个网络)。 - cfg_from_file(args.cfg_file) 这里便是代用config中的函数cfg_from_file来读取前面cfg文件中的参数,同时调用_merge_a_into_b函数把所有的参数整合,其中__C = edict() cfg = __C cfg是一个词典(edict)数据结构。
- faster rcnn采用的是多进程,mp_queue是进程间用于通讯的数据结构
import multiprocessing as mp
mp_queue = mp.Queue()同时solvers, max_iters, rpn_test_prototxt = get_solvers(args.net_name)得到solver参数
接下来便进入了训练的各个阶段。
第二步,Stage 1 RPN, init from ImageNet model
cfg.TRAIN.SNAPSHOT_INFIX = 'stage1'
mp_kwargs = dict(
queue=mp_queue,
imdb_name=args.imdb_name,
init_model=args.pretrained_model,
solver=solvers[0],
max_iters=max_iters[0],
cfg=cfg)
p = mp.Process(target=train_rpn, kwargs=mp_kwargs)
p.start()
rpn_stage1_out = mp_queue.get()
p.join()可以看到第一个步骤是用ImageNet的模型M0来Finetuning RPN网络得到模型M1。以训练为例,这里的args参数都在脚本 experiments/scrips/faster_rcnn_alt_opt.sh中找到。主要关注train_rpn函数。
对于train_rpn函数,主要分一下几步:
1.在config参数的基础上改动参数,以适合当前任务,主要有
cfg.TRAIN.HAS_RPN = True
cfg.TRAIN.BBOX_REG = False # applies only to Fast R-CNN bbox regression
cfg.TRAIN.PROPOSAL_METHOD = 'gt'这里,关注proposal method 使用的是gt,后面会使用到gt_roidb函数,重要。
2. 初始化化caffe
3. 准备roidb和imdb
主要涉及到的函数get_roidb
在get_roidb函数中调用factory中的get_imdb根据__sets[name]中的key(一个lambda表达式)转到pascol_voc类。class pascal_voc(imdb)在初始化自己的时候,先调用父类的初始化方法,例如:
{
year:’2007’
image _set:’trainval’
devkit _path:’data/VOCdevkit2007’
data _path:’data /VOCdevkit2007/VOC2007’
classes:(…)_如果想要训练自己的数据,需要修改这里_
class _to _ind:{…} _一个将类名转换成下标的字典 _ 建立索引0,1,2....
image _ext:’.jpg’
image _index: [‘000001’,’000003’,……]_根据trainval.txt获取到的image索引_
roidb _handler: <Method gt_roidb >
salt: <Object uuid >
comp _id:’comp4’
config:{…}
}注意,在这里,并没有读入任何数据,只是建立了图片的索引。
imdb.set_proposal_method(cfg.TRAIN.PROPOSAL_METHOD)- 1
设置proposal方法,接上面,设置为gt,这里只是设置了生成的方法,第一次调用发生在下一句,roidb = get_training_roidb(imdb) –> append_flipped_images()时的这行代码:“boxes = self.roidb[i][‘boxes’].copy()”,其中get_training_roidb位于train.py,主要实现图片的水平翻转,并添加回去。实际是该函数调用了imdb. append_flipped_images也就是在这个函数,调用了pascal_voc中的gt_roidb,转而调用了同一个文件中的_load_pascal_annotation,该函数根据图片的索引,到Annotations这个文件夹下去找相应的xml标注数据,然后加载所有的bounding box对象,xml的解析到此结束,接下来是roidb中的几个类成员的赋值:
- boxes 一个二维数组,每一行存储 xmin ymin xmax ymax
- gt _classes存储了每个box所对应的类索引(类数组在初始化函数中声明)
- gt _overlap是一个二维数组,共有num _classes(即类的个数)行,每一行对应的box的类索引处值为1,其余皆为0,后来被转成了稀疏矩阵
- seg _areas存储着某个box的面积
- flipped 为false 代表该图片还未被翻转(后来在train.py里会将翻转的图片加进去,用该变量用于区分
最后将这些成员变量组装成roidb返回。
在get_training_roidb函数中还调用了roidb中的prepare_roidb函数,这个函数就是用来准备imdb 的roidb,给roidb中的字典添加一些属性,比如image(图像的索引),width,height,通过前面的gt _overla属性,得到max_classes和max_overlaps.
至此,
return roidb,imdb4. 设置输出路径,output_dir = get_output_dir(imdb),函数在config中,用来保存中间生成的caffemodule等
5.正式开始训练
model_paths = train_net(solver, roidb, output_dir,
pretrained_model=init_model,
max_iters=max_iters)调用train中的train_net函数,其中,首先filter_roidb,判断roidb中的每个entry是否合理,合理定义为至少有一个前景box或背景box,roidb全是groudtruth时,因为box与对应的类的重合度(overlaps)显然为1,也就是说roidb起码要有一个标记类。如果roidb包含了一些proposal,overlaps在[BG_THRESH_LO, BG_THRESH_HI]之间的都将被认为是背景,大于FG_THRESH才被认为是前景,roidb 至少要有一个前景或背景,否则将被过滤掉。将没用的roidb过滤掉以后,返回的就是filtered_roidb。在train文件中,需要关注的是SolverWrapper类。详细见train.py,在这个类里面,引入了caffe SGDSlover,最后一句self.solver.net.layers[0].set_roidb(roidb)将roidb设置进layer(0)(在这里就是ROILayer)调用ayer.py中的set_roidb方法,为layer(0)设置roidb,同时打乱顺序。最后train_model。在这里,就需要去实例化每个层,在这个阶段,首先就会实现ROIlayer,详细参考layer中的setup,在训练时roilayer的forward函数,在第一个层,只需要进行数据拷贝,在不同的阶段根据prototxt文件定义的网络结构拷贝数据,blobs = self._get_next_minibatch()这个函数读取图片数据(调用get_minibatch函数,这个函数在minibatch中,主要作用是为faster rcnn做实际的数据准备,在读取数据的时候,分出了boxes,gt_boxes,im_info(宽高缩放)等)。
第一个层,对于stage1_rpn_train.pt文件中,该layer只有3个top blob:’data’、’im_info’、’gt_boxes’。
对于stage1_fast_rcnn_train.pt文件中,该layer有6个top blob:top: ‘data’、’rois’、’labels’、’bbox_targets’、’bbox_inside_weights’、’bbox_outside_weights’,这些数据准备都在minibatch中。至此后数据便在caffe中流动了,直到训练结束。
画出网络的结构 这里只截取了一部分:
值得注意的是在rpn-data层使用的是AnchorTargetLayer,该层使用python实现的,往后再介绍。
6.保存最后得到的权重参数
rpn_stage1_out = mp_queue.get()至此,第一阶段完成,在后面的任务开始时,如果有需要,会在这个输出的地址找这一阶段得到的权重文件。
第三步,Stage 1 RPN, generate proposals
这一步就是调用上一步训练得到的模型M1来生成proposal P1,在这一步只产生proposal,参数:
mp_kwargs = dict(
queue=mp_queue,
imdb_name=args.imdb_name,
rpn_model_path=str(rpn_stage1_out['model_path']),
cfg=cfg,
rpn_test_prototxt=rpn_test_prototxt)
p = mp.Process(target=rpn_generate, kwargs=mp_kwargs)
p.start()
rpn_stage1_out['proposal_path'] = mp_queue.get()['proposal_path']
p.join()1.关注rpn_generate函数
前面和上面讲到的train_rpn基本相同,从rpn_proposals = imdb_proposals(rpn_net, imdb)开始,imdb_proposals函数在rpn.generate.py文件中,rpn_proposals是一个列表的列表,每个子列表。对于imdb_proposals,使用im = cv2.imread(imdb.image_path_at(i))读入图片数据,调用 im_proposals生成单张图片的rpn proposals,以及得分。这里,im_proposals函数会调用网络的forward,从而得到想要的boxes和scores,这里需要好好理解blobs_out = net.forward(data,im_info)中net forward和layer forward间的调用关系。
在这里,也会有proposal,同样会使用python实现的ProposalLayer,这个函数也在rpn文件夹内,后面再补充。
boxes = blobs_out['rois'][:, 1:].copy() / scale
scores = blobs_out['scores'].copy()
return boxes, scores至此,得到imdb proposal
2.保存得到的proposal文件
queue.put({'proposal_path': rpn_proposals_path})
rpn_stage1_out['proposal_path'] = mp_queue.get()['proposal_path']至此,Stage 1 RPN, generate proposals结束
第四步,Stage 1 Fast R-CNN using RPN proposals, init from ImageNet model
参数:
cfg.TRAIN.SNAPSHOT_INFIX = 'stage1'
mp_kwargs = dict(
queue=mp_queue,
imdb_name=args.imdb_name,
init_model=args.pretrained_model,
solver=solvers[1],
max_iters=max_iters[1],
cfg=cfg,
rpn_file=rpn_stage1_out['proposal_path'])
p = mp.Process(target=train_fast_rcnn, kwargs=mp_kwargs)
p.start()
fast_rcnn_stage1_out = mp_queue.get()
p.join()这一步,用上一步生成的proposal,以及imagenet模型M0来训练fast-rcnn模型M2。
关注train_fast_rcnn
同样地,会设置参数,这里注意cfg.TRAIN.PROPOSAL_METHOD = ‘rpn’ 不同于前面,后面调用的将是rpn_roidb。cfg.TRAIN.IMS_PER_BATCH = 2,每个mini-batch包含两张图片,以及它们proposal的roi区域。且在这一步是有rpn_file的(后面和rpn_roidb函数使用有关)。其他的和前面差不多。提一下,这里在train_net的时候,会调用add_bbox_regression_targets位于roidb中,主要是添加bbox回归目标,即添加roidb的‘bbox_targets’属性,同时根据cfg中的参数设定,求取bbox_targets的mean和std,因为需要训练class-specific regressors在这里就会涉及到bbox_overlaps函数,放在util.bbox中。
要注意的是在这一步get_roidb时,如前所说,使用的是rpn_roidb,会调用imdb. create_roidb_from_box_list该方法功能是从box_list中读取每张图的boxes,而这个box_list就是从上一步保存的proposal文件中读取出来的,然后做一定的处理,详细见代码,重点是在最后会返回roidb,rpn_roidb中的gt_overlaps是rpn_file中的box与gt_roidb中box的gt_overlaps等计算IoU等处理后得到的,而不像gt_roidb()方法生成的gt_roidb中的gt_overlaps全部为1.0。同时使用了imdb.merge_roidb,类imdb的静态方法【这里不太懂,需要再学习下】,把rpn_roidb和gt_roidb归并为一个roidb,在这里,需要具体去了解合并的基本原理。
第五步,Stage 2 RPN, init from stage 1 Fast R-CNN model
参数:
cfg.TRAIN.SNAPSHOT_INFIX = 'stage2'
mp_kwargs = dict(
queue=mp_queue,
imdb_name=args.imdb_name,
init_model=str(fast_rcnn_stage1_out['model_path']),
solver=solvers[2],
max_iters=max_iters[2],
cfg=cfg)
p = mp.Process(target=train_rpn, kwargs=mp_kwargs)
rpn_stage2_out = mp_queue.get()这部分就是利用模型M2练rpn网络,这一次与stage1的rpn网络不通,这一次conv层的参数都是不动的,只做前向计算,训练得到模型M3,这属于微调了rpn网络。
第六步,Stage 2 RPN, generate proposals
参数:
mp_kwargs = dict(
queue=mp_queue,
imdb_name=args.imdb_name,
rpn_model_path=str(rpn_stage2_out['model_path']),
cfg=cfg,
rpn_test_prototxt=rpn_test_prototxt)
p = mp.Process(target=rpn_generate, kwargs=mp_kwargs)
p.start()
rpn_stage2_out['proposal_path'] = mp_queue.get()['proposal_path']
p.join()这一步,基于上一步得到的M3模型,产生proposal P2,网络结构和前面产生proposal P1的一样。
第七步,Stage 2 Fast R-CNN, init from stage 2 RPN R-CNN model
参数:
cfg.TRAIN.SNAPSHOT_INFIX = 'stage2'
mp_kwargs = dict(
queue=mp_queue,
imdb_name=args.imdb_name,
init_model=str(rpn_stage2_out['model_path']),
solver=solvers[3],
max_iters=max_iters[3],
cfg=cfg,
rpn_file=rpn_stage2_out['proposal_path'])
p = mp.Process(target=train_fast_rcnn, kwargs=mp_kwargs)
p.start()
fast_rcnn_stage2_out = mp_queue.get()
p.join()这一步基于模型M3和P2训练fast rcnn得到最终模型M4,这一步,conv层和rpn都是参数固定,只是训练了rcnn层(也就是全连接层),与stage1不同,stage1只是固定了rpn层,其他层还是有训练。模型结构与stage1相同:
第八步,输出最后模型
final_path = os.path.join(
os.path.dirname(fast_rcnn_stage2_out['model_path']),
args.net_name + '_faster_rcnn_final.caffemodel')
print 'cp {} -> {}'.format(
fast_rcnn_stage2_out['model_path'], final_path)
shutil.copy(fast_rcnn_stage2_out['model_path'], final_path)
print 'Final model: {}'.format(final_path)只是对上一步模型输出的一个拷贝。
至此,整个faster-rcnn的训练过程就结束了。
AnchorTargetLayer和ProposalLayer
前面说过还有这两个层没有说明,一个是anchortarget layer一个是proposal layer,下面逐一简要分析。
class AnchorTargetLayer(caffe.Layer)首先是读取参数,在prototxt,实际上只读取了param_str: “‘feat_stride’: 16”,这是个很重要的参数,目前我的理解是滑块滑动的大小,对于识别物体的大小很有用,比如小物体的识别,需要把这个参数减小等。
首先 setup部分,
anchor_scales = layer_params.get('scales', (8, 16, 32))
self._anchors = generate_anchors(scales=np.array(anchor_scales))调用generate_anchors方法生成最初始的9个anchor该函数位于generate_anchors.py 主要功能是生成多尺度,多宽高比的anchors,8,16,32其实就是scales:[2^3 2^4 2^5],base_size为16,具体是怎么实现的可以查阅源代码。_ratio_enum()部分生成三种宽高比 1:2,1:1,2:1的anchor如下图所示:(以下参考 另外一篇博客)
_scale_enum()部分,生成三种尺寸的anchor,以_ratio_enum()部分生成的anchor[0 0 15 15]为例,扩展了三种尺度 128*128,256*256,512*512,如下图所示:
另外一个函数就是forward()。
在faster rcnn中会根据不同图的输入,得到不同的feature map,height, width = bottom[0].data.shape[-2:]首先得到conv5的高宽,以及gt box gt_boxes = bottom[1].data,图片信息im_info = bottom[2].data[0, :],然后计算偏移量,shift_x = np.arange(0, width) * self._feat_stride,在这里,你会发现,例如你得到的fm是H=61,W=36,然后你乘以16,得到的图形大概就是1000*600,其实这个16大概就是网络的缩放比例。接下来就是生成anchor,以及对anchor做一定的筛选,详见代码。
另外一个需要理解的就是proposal layer,这个只是在测试的时候用,许多东西和AnchorTargetLayer类似,不详细介绍,可以查看代码。主要看看forward函数,函数算法介绍在注释部分写的很详细:
# Algorithm:
# for each (H, W) location i
# generate A anchor boxes centered on cell i
# apply predicted bbox deltas at cell i to each of the A anchors
# clip predicted boxes to image
# remove predicted boxes with either height or width < threshold
# sort all (proposal, score) pairs by score from highest to lowest
# take top pre_nms_topN proposals before NMS
# apply NMS with threshold 0.7 to remaining proposals
# take after_nms_topN proposals after NMS
# return the top proposals (-> RoIs top, scores top)在这个函数中会引用NMS方法。
代码文件夹说明
tools
在tools文件夹中,是我们直接调用的最外层的封装文件。其中主要包含的文件为:
- _init_paths.py :用来初始化路径的,也就是之后的路径会join(path,*)
- compress_net.py:用来压缩参数的,使用了SVD来进行压缩,这里可以发现,作者对于fc6层和fc7层进行了压缩,也就是两个全连接层。
- demo.py :通常,我们会直接调用这个函数,如果要测试自己的模型和数据,这里需要修改。这里调用了fast_rcnn中的test、config、nums_wrapper函数。vis_detections用来做检测,parse_args用来进行参数设置,以及damo和主函数。
- eval_recall.py:评估函数
- reval.py:re-evaluate,这里调用了fast_rcnn以及dataset中的函数。其中,from_mats函数和from_dets函数分别loadmat文件和pkl文件。
- rpn_genetate.py:这个函数调用了rpn中的genetate函数,之后我们会对rpn层做具体的介绍。这里,主要是一个封装调用的过程,我们在这里调用配置的参数、设置rpn的test参数,以及输入输出等操作。
- test_net.py:测试fast rcnn网络。主要就是一些参数配置。
- train_faster_rcnn_alt_opt.py:训练faster rcnn网络使用交替的训练,这里就是根据faster rcnn文章中的具体实现。可以在主函数中看到,其包括的步骤为:
- RPN 1,使用imagenet model进行初始化参数,生成proposal,这里存储在mp_kwargs
- fast rcnn 1,使用 imagenet model 进行初始化参数,使用刚刚生成的proposal进行fast rcnn的训练
- RPN 2使用 fast rcnn 中的参数进行初始化(这里要注意哦),并生成proposal
- fast rcnn 2,使用RPN 2 中的 model进行初始化参数
- 值得注意的是:在我们训练时,我们可以在get_solvers中的max_iters中设置迭代次数,在不确定网络是否可以调通时,减少迭代次数可以减少测试时间。
- 我们在训练faster rcnn网络时,就是调用这个文件训练的
- train_net.py:使用fast rcnn,训练自己数据集的网络模型
- train_svms.py:使用最原始的RCNN网络训练post-hoc SVMs
RPN
这里我们主要看lib/rpn文件夹下的代码。这里主要介绍了rpn的模型,其中,包含的主要文件如下:
- generate_anchors.py: 生成多尺度和多比例的锚点。这里由generate_anthors函数主要完成,可以看到,使用了 3 个尺度( 128, 256, and 512)以及 3 个比例(1:1,1:2,2:1)。一个锚点由w, h, x_ctr, y_ctr固定,也就是宽、高、x center和y center固定。
- proposal_layer.py:这个函数是用来将RPN的输出转变为object proposals的。作者新增了ProposalLayer类,这个类中,重新了set_up和forward函数,其中forward实现了:生成锚点box、对于每个锚点提供box的参数细节、将预测框切成图像、删除宽、高小于阈值的框、将所有的(proposal, score) 对排序、获取 pre_nms_topN proposals、获取NMS 、获取 after_nms_topN proposals。(注:NMS,nonmaximum suppression,非极大值抑制)
- anchor_target_layer.py:生成每个锚点的训练目标和标签,将其分类为1 (object), 0 (not object) , -1 (ignore).当label>0,也就是有object时,将会进行box的回归。其中,forward函数功能:在每一个cell中,生成9个锚点,提供这9个锚点的细节信息,过滤掉超过图像的锚点,测量同GT的overlap。
- proposal_target_layer.py:对于每一个object proposal 生成训练的目标和标签,分类标签从0-k,对于标签>0的box进行回归。(注意,同anchor_target_layer.py不同,两者一个是生成anchor,一个是生成proposal)
- generate.py:使用一个rpn生成object proposals。
作者就是通过以上这些文件生成rpn的。
nms
lib/nms文件夹下是非极大值抑制,这部分大家应该已经非常熟悉了,其Python版本的核心函数为py_cpu_nms.py,具体实现以及注释如下:
def py_cpu_nms(dets, thresh):
"""Pure Python NMS baseline."""
#x1、y1、x2、y2、以及score赋值
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = dets[:, 4]
#每一个op的面积
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
#order是按照score排序的
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
#计算相交的面积
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
#计算:重叠面积/(面积1+面积2-重叠面积)
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= thresh)[0]
order = order[inds + 1]
4 Faster RCNN
Faster R-CNN统一的网络结构如下图所示,可以简单看作RPN网络+Fast R-CNN网络。
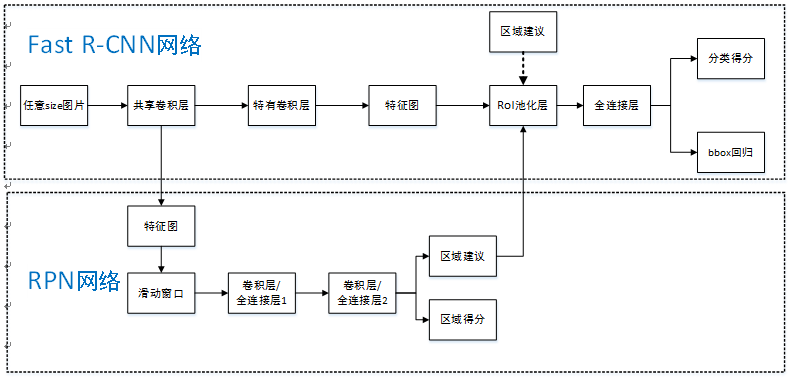
原理步骤如下:
首先向CNN网络【ZF或VGG-16】输入任意大小图片;
经过CNN网络前向传播至最后共享的卷积层,一方面得到供RPN网络输入的特征图,另一方面继续前向传播至特有卷积层,产生更高维特征图;
供RPN网络输入的特征图经过RPN网络得到区域建议和区域得分,并对区域得分采用非极大值抑制【阈值为0.7】,输出其Top-N【文中为300】得分的区域建议给RoI池化层;
第2步得到的高维特征图和第3步输出的区域建议同时输入RoI池化层,提取对应区域建议的特征;
第4步得到的区域建议特征通过全连接层后,输出该区域的分类得分以及回归后的bounding-box。
4.1 单个RPN网络结构
单个RPN网络结构如下:
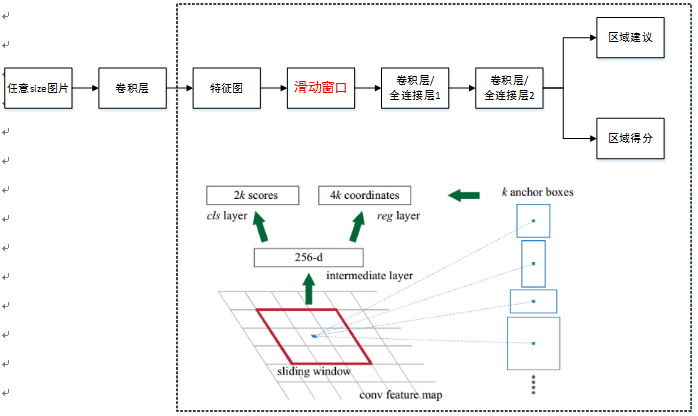
注意: 上图中卷积层/全连接层表示卷积层或者全连接层,作者在论文中表示这两层实际上是全连接层,但是网络在所有滑窗位置共享全连接层,可以很自然地用n×n卷积核【论文中设计为3×3】跟随两个并行的1×1卷积核实现
RPN的作用:RPN在CNN卷积层后增加滑动窗口操作以及两个卷积层完成区域建议功能,第一个卷积层将特征图每个滑窗位置编码成一个特征向量,第二个卷积层对应每个滑窗位置输出k个区域得分和k个回归后的区域建议,并对得分区域进行非极大值抑制后输出得分Top-N【文中为300】区域,告诉检测网络应该注意哪些区域,本质上实现了Selective Search、EdgeBoxes等方法的功能。
4.2 RPN层的具体流程
首先套用ImageNet上常用的图像分类网络,本文中试验了两种网络:ZF或VGG-16,利用这两种网络的部分卷积层产生原始图像的特征图;
对于1中特征图,用n×n【论文中设计为3×3,n=3看起来很小,但是要考虑到这是非常高层的feature map,其size本身也没有多大,因此9个矩形中,每个矩形窗框都是可以感知到很大范围的】的滑动窗口在特征图上滑动扫描【代替了从原始图滑窗获取特征】,每个滑窗位置通过卷积层1映射到一个低维的特征向量【ZF网络:256维;VGG-16网络:512维,低维是相对于特征图大小W×H,typically~60×40=2400】后采用ReLU,并为每个滑窗位置考虑k种【论文中k=9】可能的参考窗口【论文中称为anchors,见下解释】,这就意味着每个滑窗位置会同时预测最多9个区域建议【超出边界的不考虑】,对于一个W×H的特征图,就会产生W×H×k个区域建议;
步骤2中的低维特征向量输入两个并行连接的卷积层2:reg窗口回归层【位置精修】和cls窗口分类层,分别用于回归区域建议产生bounding-box【超出图像边界的裁剪到图像边缘位置】和对区域建议是否为前景或背景打分,这里由于每个滑窗位置产生k个区域建议,所以reg层有4k个输出来编码【平移缩放参数】k个区域建议的坐标,cls层有2k个得分估计k个区域建议为前景或者背景的概率。
4.3 Anchor
Anchors是一组大小固定的参考窗口:三种尺度{ 1282,2562,51221282,2562,5122 }×三种长宽比{1:1,1:2,2:1},如下图所示,表示RPN网络中对特征图滑窗时每个滑窗位置所对应的原图区域中9种可能的大小,相当于模板,对任意图像任意滑窗位置都是这9中模板。继而根据图像大小计算滑窗中心点对应原图区域的中心点,通过中心点和size就可以得到滑窗位置和原图位置的映射关系,由此原图位置并根据与Ground Truth重复率贴上正负标签,让RPN学习该Anchors是否有物体即可。对于每个滑窗位置,产生k=9个anchor对于一个大小为W*H的卷积feature map,总共会产生WHk个anchor。
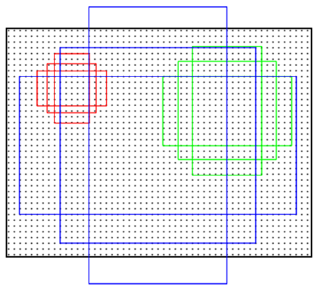
平移不变性
Anchors这种方法具有平移不变性,就是说在图像中平移了物体,窗口建议也会跟着平移。同时这种方式也减少了整个模型的size,输出层 512×(4+2)×9=2.8×104512×(4+2)×9=2.8×104 个参数【512是前一层特征维度,(4+2)×9是9个Anchors的前景背景得分和平移缩放参数】,而MultiBox有 1536×(4+1)×800=6.1×106个1536×(4+1)×800=6.1×106个 参数,而较小的参数可以在小数据集上减少过拟合风险。
当然,在RPN网络中我们只需要找到大致的地方,无论是位置还是尺寸,后面的工作都可以完成,这样的话采用小网络进行简单的学习【估计和猜差不多,反正有50%概率】,还不如用深度网络【还可以实现卷积共享】,固定尺度变化,固定长宽比变化,固定采样方式来大致判断是否是物体以及所对应的位置并降低任务复杂度。
4.4 多尺度多长宽比率
有两种方法解决多尺度多长宽比问题:
图像金字塔:对伸缩到不同size的输入图像进行特征提取,虽然有效但是费时.
feature map上使用多尺度(和/或长宽比)的滑窗:例如,DPM分别使用不同大小的filter来训练不同长宽比的模型。若这种方法用来解决多尺度问题,可以认为是“filter金字塔(pyramid of filters)”
4.5 训练过程
4.5.1 RPN网络训练过程
RPN网络被ImageNet网络【ZF或VGG-16】进行了有监督预训练,利用其训练好的网络参数初始化; 用标准差0.01均值为0的高斯分布对新增的层随机初始化。
4.5.2 Fast R-CNN网络预训练
同样使用mageNet网络【ZF或VGG-16】进行了有监督预训练,利用其训练好的网络参数初始化。
4.5.3 RPN网络微调训练
PASCAL VOC 数据集中既有物体类别标签,也有物体位置标签; 正样本仅表示前景,负样本仅表示背景; 回归操作仅针对正样本进行; 训练时弃用所有超出图像边界的anchors,否则在训练过程中会产生较大难以处理的修正误差项,导致训练过程无法收敛; 对去掉超出边界后的anchors集采用非极大值抑制,最终一张图有2000个anchors用于训练【详细见下】; 对于ZF网络微调所有层,对VGG-16网络仅微调conv3_1及conv3_1以上的层,以便节省内存。
SGD mini-batch采样方式: 同Fast R-CNN网络,采取 image-centric 方式采样,即采用层次采样,先对图像取样,再对anchors取样,同一图像的anchors共享计算和内存。每个mini-batch包含从一张图中随机提取的256个anchors,正负样本比例为1:1【当然可以对一张图所有anchors进行优化,但由于负样本过多最终模型会对正样本预测准确率很低】来计算一个mini-batch的损失函数,如果一张图中不够128个正样本,拿负样本补凑齐。
训练超参数选择: 在PASCAL VOC数据集上前60k次迭代学习率为0.001,后20k次迭代学习率为0.0001;动量设置为0.9,权重衰减设置为0.0005。
多任务目标函数【分类损失+回归损失】具体如下:
i为一个anchor在一个mini-batch中的下标pipi 是anchor i为一个object的预测可能性
p⋆ipi⋆ 为ground-truth标签。如果这个anchor是positive的,则ground-truth标签 p⋆ipi⋆ 为1,否则为0。
titi 表示表示正样本anchor到预测区域bounding box的4个参数化坐标,【以anchor为基准的变换】
t⋆iti⋆ 是这个positive anchor对应的ground-truth box。【以anchor为基准的变换】
LclsLcls 分类的损失(classification loss),是一个二值分类器(是object或者不是)的softmax loss。其公式为 Lcls(pi,p⋆i)=−log[pi∗p⋆i+(1−p⋆i)(1−pi)]Lcls(pi,pi⋆)=−log[pi∗pi⋆+(1−pi⋆)(1−pi)]
LregLreg 回归损失(regression loss),Lreg(ti,t⋆i)=R(ti−t⋆i)Lreg(ti,ti⋆)=R(ti−ti⋆) 【两种变换之差越小越好】,其中R是Fast R-CNN中定义的robust ross function (smooth L1)。p⋆iLregpi⋆Lreg表示回归损失只有在positive anchor( p⋆i=1pi⋆=1 )的时候才会被激活。cls与reg层的输出分别包含{pipi}和{ titi }。R函数的定义为: smoothL1(x)=0.5x2if∣x∣<1otherwise∣x∣−0.5smoothL1(x)=0.5x2if∣x∣<1otherwise∣x∣−0.5
λ参数用来权衡分类损失 LclsLcls 和回归损失 LregLreg ,默认值λ=10【文中实验表明 λ从1变化到100对mAP影响不超过1%】;
NclsNcls 和 NregNreg 分别用来标准化分类损失项 LclsLcls 和回归损失项 LregLreg,默认用mini-batch size=256设置 NclsNcls,用anchor位置数目~2400初始化 NregNreg,文中也说明标准化操作并不是必须的,可以简化省略。
4.5.4 RPN网络、Fast R-CNN网络联合训练
训练网络结构示意图如下所示:
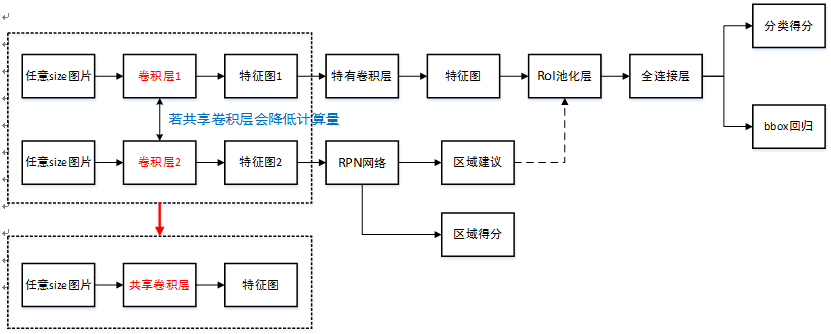
如上图所示,RPN网络、Fast R-CNN网络联合训练是为了让两个网络共享卷积层,降低计算量。
文中通过4步训练算法,交替优化学习至共享特征:
进行上面RPN网络预训练,和以区域建议为目的的RPN网络end-to-end微调训练。
进行上面Fast R-CNN网络预训练,用第①步中得到的区域建议进行以检测为目的的Fast R-CNN网络end-to-end微调训练【此时无共享卷积层】。
使用第2步中微调后的Fast R-CNN网络重新初始化RPN网络,固定共享卷积层【即设置学习率为0,不更新】,仅微调RPN网络独有的层【此时共享卷积层】。
固定第3步中共享卷积层,利用第③步中得到的区域建议,仅微调Fast R-CNN独有的层,至此形成统一网络如上图所示。
4.6 相关解释
**RPN网络中bounding-box回归怎么理解?同Fast R-CNN中的bounding-box回归相比有什么区别? **
对于bounding-box回归,采用以下公式:
- t
- t∗t∗
其中,x,y,w,h表示窗口中心坐标和窗口的宽度和高度,变量x,xaxa 和 x∗x∗ 分别表示预测窗口、anchor窗口和Ground Truth的坐标【y,w,h同理】,因此这可以被认为是一个从anchor窗口到附近Ground Truth的bounding-box 回归;
RPN网络中bounding-box回归的实质其实就是计算出预测窗口。这里以anchor窗口为基准,计算Ground Truth对其的平移缩放变化参数,以及预测窗口【可能第一次迭代就是anchor】对其的平移缩放参数,因为是以anchor窗口为基准,所以只要使这两组参数越接近,以此构建目标函数求最小值,那预测窗口就越接近Ground Truth,达到回归的目的;
文中提到, Fast R-CNN中基于RoI的bounding-box回归所输入的特征是在特征图上对任意size的RoIs进行Pool操作提取的,所有size RoI共享回归参数,而在Faster R-CNN中,用来bounding-box回归所输入的特征是在特征图上相同的空间size【3×3】上提取的,为了解决不同尺度变化的问题,同时训练和学习了k个不同的回归器,依次对应为上述9种anchors,这k个回归量并不分享权重。因此尽管特征提取上空间是固定的【3×3】,但由于anchors的设计,仍能够预测不同size的窗口。
文中提到了三种共享特征网络的训练方式?
交替训练,训练RPN,得到的区域建议来训练Fast R-CNN网络进行微调;此时网络用来初始化RPN网络,迭代此过程【文中所有实验采用】;
近似联合训练: 如上图所示,合并两个网络进行训练,前向计算产生的区域建议被固定以训练Fast R-CNN;反向计算到共享卷积层时RPN网络损失和Fast R-CNN网络损失叠加进行优化,但此时把区域建议【Fast R-CNN输入,需要计算梯度并更新】当成固定值看待,忽视了Fast R-CNN一个输入:区域建议的导数,则无法更新训练,所以称之为近似联合训练。实验发现,这种方法得到和交替训练相近的结果,还能减少20%~25%的训练时间,公开的python代码中使用这种方法;
联合训练 需要RoI池化层对区域建议可微,需要RoI变形层实现,具体请参考这片paper:Instance-aware Semantic Segmentation via Multi-task Network Cascades。
图像Scale细节问题?
文中提到训练和检测RPN、Fast R-CNN都使用单一尺度,统一缩放图像短边至600像素; 在缩放的图像上,对于ZF网络和VGG-16网络的最后卷积层总共的步长是16像素,因此在缩放前典型的PASCAL图像上大约是10像素【~500×375;600/16=375/10】。
Faster R-CNN中三种尺度怎么解释:
原始尺度:原始输入的大小,不受任何限制,不影响性能;
归一化尺度:输入特征提取网络的大小,在测试时设置,源码中opts.test_scale=600。anchor在这个尺度上设定,这个参数和anchor的相对大小决定了想要检测的目标范围;
网络输入尺度:输入特征检测网络的大小,在训练时设置,源码中为224×224。
理清文中anchors的数目
文中提到对于1000×600的一张图像,大约有20000(~60×40×9)个anchors,忽略超出边界的anchors剩下6000个anchors,利用非极大值抑制去掉重叠区域,剩2000个区域建议用于训练; 测试时在2000个区域建议中选择Top-N【文中为300】个区域建议用于Fast R-CNN检测。
参考博客
http://shartoo.github.io/RCNN-series/Faster RCNN代码理解(Python)的更多相关文章
- Faster rcnn代码理解(4)
上一篇我们说完了AnchorTargetLayer层,然后我将Faster rcnn中的其他层看了,这里把ROIPoolingLayer层说一下: 我先说一下它的实现原理:RPN生成的roi区域大小是 ...
- Faster rcnn代码理解(2)
接着上篇的博客,咱们继续看一下Faster RCNN的代码- 上次大致讲完了Faster rcnn在训练时是如何获取imdb和roidb文件的,主要都在train_rpn()的get_roidb()函 ...
- Faster rcnn代码理解(1)
这段时间看了不少论文,回头看看,感觉还是有必要将Faster rcnn的源码理解一下,毕竟后来很多方法都和它有相近之处,同时理解该框架也有助于以后自己修改和编写自己的框架.好的开始吧- 这里我们跟着F ...
- Faster rcnn代码理解(3)
紧接着之前的博客,我们继续来看faster rcnn中的AnchorTargetLayer层: 该层定义在lib>rpn>中,见该层定义: 首先说一下这一层的目的是输出在特征图上所有点的a ...
- 原 CNN--卷积神经网络从R-CNN到Faster R-CNN的理解(CIFAR10分类代码)
1. 什么是CNN 卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Netwo ...
- Faster R-CNN代码例子
主要参考文章:1,从编程实现角度学习Faster R-CNN(附极简实现) 经常是做到一半发现收敛情况不理想,然后又回去看看这篇文章的细节. 另外两篇: 2,Faster R-CNN学习总结 ...
- 对Faster R-CNN的理解(1)
目标检测是一种基于目标几何和统计特征的图像分割,最新的进展一般是通过R-CNN(基于区域的卷积神经网络)来实现的,其中最重要的方法之一是Faster R-CNN. 1. 总体结构 Faster R-C ...
- Rcnn/Faster Rcnn/Faster Rcnn的理解
基于候选区域的目标检测器 1. 滑动窗口检测器 根据滑动窗口从图像中剪切图像块-->将剪切的图像块warp成固定大小-->cnn网络提取特征-->SVM和regressor进行分类 ...
- Faster RCNN代码解析
1.faster_rcnn_end2end训练 1.1训练入口及配置 def train(): cfg.GPU_ID = 0 cfg_file = "../experiments/cfgs/ ...
随机推荐
- linux-shell-命令总结
第一种方法执行: 第二种方法执行: 第三种方法执行: 第四种方法:执行 第三种和第四种方法都是在新的进程里执行程序 函数方法 方法就是一个命令,命令写在字符串的第一个位置 type:可以接外部命令 ...
- 全景3d
Three.js Tour.js Run.js 3D Css3 酷家乐:https://www.kujiale.com/ 爱空间:http://bj.ikongjian.com/?utm_source ...
- 移动app rem
(function (doc, win) { var docEl = doc.documentElement, resizeEvt = 'orientationchange' in window ? ...
- scenario testing
我们的APP“吃了么”是专为爱美食的人打造的,典型的用户自然是那些喜欢美食的“吃货”们,当然也可以为想要快速找到周边餐馆的童鞋提供便利.还有一种典型的用户就是喜欢自己烹调食物的人. 我们整理出来了下面 ...
- PolarCode
什么是polar code极化码 为了实现可靠的信号传输,编码学家在过去的半个多世纪提出多种纠错码技术如里所码(RS码).卷积码,Turbo码等,并在各种通信系统中取得了广泛的应用.但是以往所有实用的 ...
- 关于本科毕业论文《Laguerre小波在数值积分与微分方程数值解中的应用》存在的问题与小结
本科的毕业设计<Laguerre小波在数值积分与微分方程数值解中的应用>是通过Laguerre小波函数来近似表达某个需要求积分或解微分方程的函数,将原函数很难求得函数用小波函数表达出来,这 ...
- 【目标跟踪】相关滤波算法之MOSSE
简要 2010年David S. Bolme等人在CVPR上发表了<Visual Object Tracking using Adaptive Correlation Filters>一文 ...
- 请求数据传入(SpringMVC)
1. 请求处理方法签名 Spring MVC 通过分析处理方法的签名,HTTP请求信息绑定到处理方法的相应人参中. Spring MVC 对控制器处理方法签名的限制是很宽松的,几乎可以按喜欢的任 ...
- FTP Download File By Some Order List
@Echo Off REM -- Define File Filter, i.e. files with extension .RBSet FindStrArgs=/E /C:".asp&q ...
- [转帖]TMD为你揭秘中国互联网下半场所有秘密
https://www.iyiou.com/p/35099.html 李安说,<比利.林恩的中场战事>是“一个成长的故事”.中国互联网也行至中场,下半场如何走,成长的方向在哪里,成当下关键 ...