spark streaming 整合 kafka(一)
转载:https://www.iteblog.com/archives/1322.html
Apache Kafka是一个分布式的消息发布-订阅系统。可以说,任何实时大数据处理工具缺少与Kafka整合都是不完整的。本文将介绍如何使用Spark Streaming从Kafka中接收数据,这里将会介绍两种方法:(1)、使用Receivers和Kafka高层次的API;(2)、使用Direct API,这是使用低层次的KafkaAPI,并没有使用到Receivers,是Spark 1.3.0中开始引入的。这两种方法有不同的编程模型,性能特点和语义担保。下文将会一一介绍。
1、基于reciver的方式
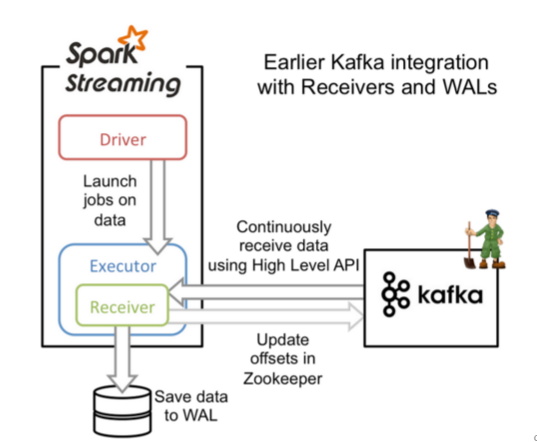
然而,在默认的配置下,这种方法在失败的情况下会丢失数据,为了保证零数据丢失,你可以在Spark Streaming中使用WAL日志,这是在Spark 1.2.0才引入的功能,这使得我们可以将接收到的数据保存到WAL中(WAL日志可以存储在HDFS上),所以在失败的时候,我们可以从WAL中恢复,而不至于丢失数据。
1、引入依赖(依据版本需要进行更改)。
对于Scala和Java项目,你可以在你的pom.xml文件引入以下依赖:
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka_2.10</artifactId> <version>1.3.0</version></dependency> |
如果你是使用SBT,可以这么引入:
libraryDependencies += "org.apache.spark" % "spark-streaming-kafka_2.10" % "1.3.0" |
2、编程
在Streaming程序中,引入KafkaUtils,并创建一个输入DStream:
import org.apache.spark.streaming.kafka._val kafkaStream = KafkaUtils.createStream(streamingContext, [ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume]) |
在创建DStream的时候,你也可以指定数据的Key和Value类型,并指定相应的解码类。
1、Kafka中Topic的分区和Spark Streaming生成的RDD中分区不是一个概念。所以,在
KafkaUtils.createStream()增加特定主题分区数仅仅是增加一个receiver中消费Topic的线程数。并不增加Spark并行处理数据的数量;
2、对于不同的Group和tpoic我们可以使用多个receivers创建不同的DStreams来并行接收数据;
3、如果你启用了WAL,这些接收到的数据将会被持久化到日志中,因此,我们需要将storage level 设置为StorageLevel.MEMORY_AND_DISK_SER ,也就是:
KafkaUtils.createStream(..., StorageLevel.MEMORY_AND_DISK_SER) |
3、部署
对应任何的Spark 应用,我们都是用spark-submit来启动你的应用程序,对于Scala和Java用户,如果你使用的是SBT或者是Maven,你可以将spark-streaming-kafka_2.10及其依赖打包进应用程序的Jar文件中,并确保spark-core_2.10和 spark-streaming_2.10标记为provided,因为它们在Spark 安装包中已经存在:
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.10</artifactId> <version>1.3.0</version> <scope>provided</scope></dependency><dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.10</artifactId> <version>1.3.0</version> <scope>provided</scope></dependency> |
然后使用spark-submit来启动你的应用程序。
[iteblog@ spark]$ spark-1.3.0-bin-2.6.0/bin/spark-submit --master yarn-cluster --class iteblog.KafkaTest --jars lib/spark-streaming-kafka_2.10-1.3.0.jar, lib/spark-streaming_2.10-1.3.0.jar, lib/kafka_2.10-0.8.1.1.jar,lib/zkclient-0.3.jar, lib/metrics-core-2.2.0.jar ./iteblog-1.0-SNAPSHOT.jar |
下面是一个完整的例子:
object KafkaWordCount { def main(args: Array[String]) { if (args.length < 4) { System.err.println("Usage: KafkaWordCount <zkQuorum> <group> <topics> <numThreads>") System.exit(1) } StreamingExamples.setStreamingLogLevels() val Array(zkQuorum, group, topics, numThreads) = args val sparkConf = new SparkConf().setAppName("KafkaWordCount") val ssc = new StreamingContext(sparkConf, Seconds(2)) ssc.checkpoint("checkpoint") val topicMap = topics.split(",").map((_,numThreads.toInt)).toMap val lines = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap).map(_._2) val words = lines.flatMap(_.split(" ")) val wordCounts = words.map(x => (x, 1L)) .reduceByKeyAndWindow(_ + _, _ - _, Minutes(10), Seconds(2), 2) wordCounts.print() ssc.start() ssc.awaitTermination() }} |
spark streaming 整合 kafka(一)的更多相关文章
- Spark学习之路(十六)—— Spark Streaming 整合 Kafka
一.版本说明 Spark针对Kafka的不同版本,提供了两套整合方案:spark-streaming-kafka-0-8和spark-streaming-kafka-0-10,其主要区别如下: s ...
- Spark 系列(十六)—— Spark Streaming 整合 Kafka
一.版本说明 Spark 针对 Kafka 的不同版本,提供了两套整合方案:spark-streaming-kafka-0-8 和 spark-streaming-kafka-0-10,其主要区别如下 ...
- Spark之 Spark Streaming整合kafka(并演示reduceByKeyAndWindow、updateStateByKey算子使用)
Kafka0.8版本基于receiver接受器去接受kafka topic中的数据(并演示reduceByKeyAndWindow的使用) 依赖 <dependency> <grou ...
- spark streaming 整合kafka(二)
转载:https://www.iteblog.com/archives/1326.html 和基于Receiver接收数据不一样,这种方式定期地从Kafka的topic+partition中查询最新的 ...
- Spark之 Spark Streaming整合kafka(Java实现版本)
pom依赖 <properties> <scala.version>2.11.8</scala.version> <hadoop.version>2.7 ...
- spark streaming整合kafka
版本说明:spark:2.2.0: kafka:0.10.0.0 object StreamingDemo { def main(args: Array[String]): Unit = { Logg ...
- Spark Streaming 整合 Kafka
一:通过设置检查点,实现单词计数的累加功能 object StatefulKafkaWCnt { /** * 第一个参数:聚合的key,就是单词 * 第二个参数:当前批次产生批次该单词在每一个分区出现 ...
- Spark Streaming和Kafka整合保证数据零丢失
当我们正确地部署好Spark Streaming,我们就可以使用Spark Streaming提供的零数据丢失机制.为了体验这个关键的特性,你需要满足以下几个先决条件: 1.输入的数据来自可靠的数据源 ...
- Spark Streaming和Kafka整合是如何保证数据零丢失
转载:https://www.iteblog.com/archives/1591.html 当我们正确地部署好Spark Streaming,我们就可以使用Spark Streaming提供的零数据丢 ...
随机推荐
- java动态加载配置文件(申明:来源于网络)
java动态加载配置文件 地址:http://blog.csdn.net/longvs/article/details/9361449
- 怎么将APE转MP3,APE转MP3的方法
怎样实现APE转MP3的问题呢?很多时候我们从网上所下载的音乐格式,可能并不是我们所需要的音乐格式.如APE音乐格式,那么当我们下载了自己并不需要的APE音乐格式我们应该如何将其转换为自己需要的MP3 ...
- 构造方法 this super
1 构造方法 1.1 构造方法Constructor概述创建对象要明确属性值,此时需要用到构造方法,即对象创建时要执行的方法,用来给对象的属性进行初始化.在new对象时,知道其执行的构造方法是什么,就 ...
- mysql报错Ignoring the redo log due to missing MLOG_CHECKPOINT between
mysql报错Ignoring the redo log due to missing MLOG_CHECKPOINT between mysql版本:5.7.19 系统版本:centos7.3 由于 ...
- 【UML】NO.46.EBook.5.UML.1.006-【UML 大战需求分析】- 用例图(Use Case Diagram)
1.0.0 Summary Tittle:[UML]NO.46.EBook.1.UML.1.006-[UML 大战需求分析]- 用例图(Use Case Diagram) Style:DesignPa ...
- JMeter-标的上架调整与完成
问题:利随本青,按日的返回的参数不正确 各种计息方式的上标,新做产品的上架 散标各种计息方式的上架,新做产品的上架 修改后B环境上架 修改后C环境上架 [制作提案(担保机构)-提交18] loan.d ...
- #WEB安全基础 : HTTP协议 | 0x7 学会使用wireshark分析数据包
wireshark是开源,免费,跨平台的抓包分析工具 我们可以通过wireshark学习HTTP报文和进行抓包分析,在CTF中的流量分析需要用到抓包 1.下载和安装 这是wireshark的官网 ht ...
- word之高级
1.更正拼写和语法错误. 2.取消自动编号. 3.添加删除水印. 4.段落设置首行缩进2个字符. 需要先选中需要设置的段落 5.文字覆盖. insert键切换插入与改写功能.修改word状态栏上的改写 ...
- Java访问修饰符(访问控制符)
Java 通过修饰符来控制类.属性和方法的访问权限和其他功能,通常放在语句的最前端.例如: public class className { // body of class } private bo ...
- Mysql模糊查询like效率,以及更高效的写法
在使用msyql进行模糊查询的时候,很自然的会用到like语句,通常情况下,在数据量小的时候,不容易看出查询的效率,但在数据量达到百万级,千万级的时候,查询的效率就很容易显现出来.这个时候查询的效率就 ...