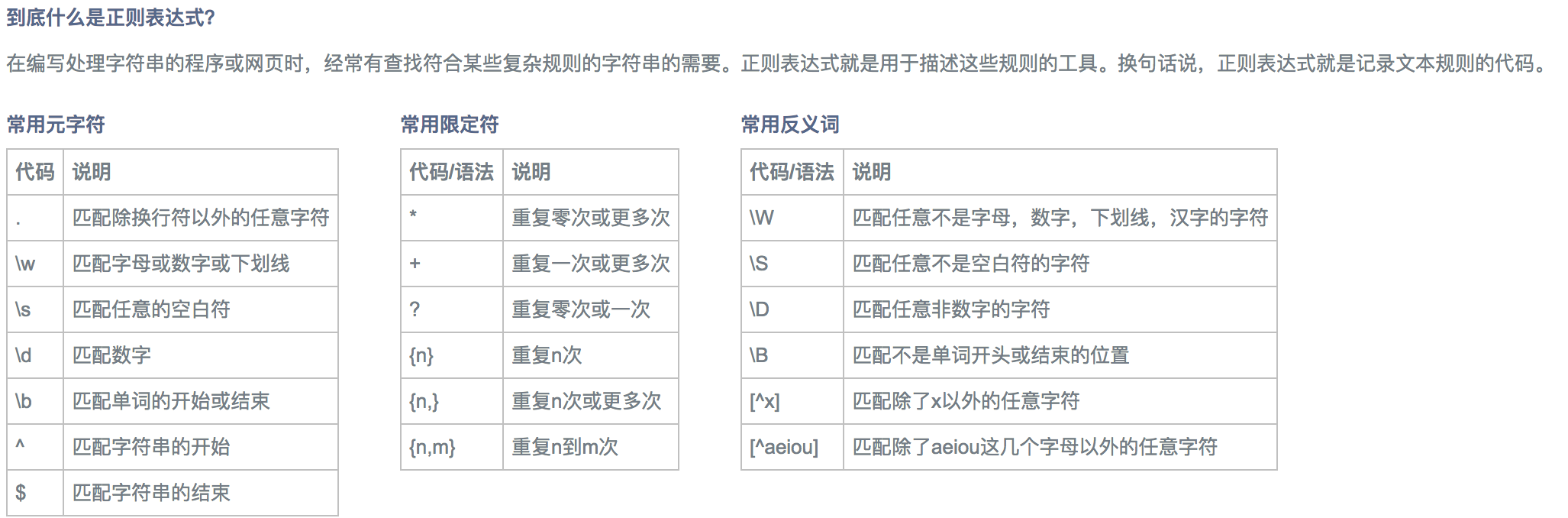
python之刷博客访问量
通过写刷访问量学习正则匹配
说明信息
说明:仅仅是为了熟悉正则表达式以及网页结构,并不赞成刷访问量操作。
1.刷访问量第一版
1.1 确定网页url结构,构造匹配模式串
首先是要确定刷的网页。第一版实现了爬取博客园的网页。下面为模式匹配的规则,该规则需要根据网页的url结构进行适当的调整。通过查看得到当前的博客园的结构如下图所示:
因此通过构造匹配串如下所示:pr=r'href="http://www.cnblogs.com/zpfbuaa/p/(\d+)'
rr=re.compile(pr)正则表达式的规则如下图简单介绍:
另外附上正则表达式在线测试工具。快速跳转至测试工具

1.2 获取代理ip列表以及user_agent_list初始构造
获取代理ip地址以及端口号。下面推荐代理ip网页,当时最近发现好像出问题了。不过这些高匿的ip代理提供商有不少免费的ip可供使用,需要的就是将这些ip和port整理起来。
下面所给的方法需要根据不同的ip提供商的网页结构进行修改。比如有些ip提供商的网页并不是table结构的,或者结构比较复杂。因此进行正则匹配,以及分析网页结构(神奇的F12)是非常必要的。
同时为了避免多个相同用户端进行请求,则初始化构造一个user_agent_list用来之后网页访问中的头部信息构造。
user_agent_list = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
]
接下来进行代理ip列表的获取。同时统计出代理ip地址的总个数。
需要注意下面的正则表达式需要根据网页结构的不同来进行相应的改变
def Get_proxy_ip():
global proxy_list
global totalnum
proxy_list = []
headers = {
'Host': 'www.xicidaili.com',
'User-Agent':'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Accept': r'application/json, text/javascript, */*; q=0.01',
'Referer': r'http://www.xicidaili.com/',
}
req = urllib2.Request(r'http://www.xicidaili.com/nn/', headers=headers)
response = urllib2.urlopen(req)
html = response.read().decode('utf-8')
ip_list = re.findall(r'\d+\.\d+\.\d+\.\d+',html)
port_list = re.findall(r'<td>\d+</td>',html)
for i in range(len(ip_list)):
totalnum+=1
ip = ip_list[i]
port = re.sub(r'<td>|</td>', '', port_list[i])
proxy = '%s:%s' %(ip,port)
proxy_list.append(proxy)
headers = {
'Host': 'www.xicidaili.com',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Accept': r'application/json, text/javascript, */*; q=0.01',
'Referer': r'http://www.xicidaili.com/',
}
req = urllib2.Request(r'http://www.xicidaili.com/nn/5', headers=headers)
response = urllib2.urlopen(req)
html = response.read().decode('utf-8')
ip_list = re.findall(r'\d+\.\d+\.\d+\.\d+', html)
port_list = re.findall(r'<td>\d+</td>', html)
for i in range(len(ip_list)):
totalnum+=1
ip = ip_list[i]
port = re.sub(r'<td>|</td>', '', port_list[i])
proxy = '%s:%s' % (ip, port)
proxy_list.append(proxy)
return proxy_list
1.3 构造url博文列表
对于博客园的博文url列表的构造有不同的方法,其中一个为:将当前网页上的url进行筛选,得到所有满足条件的博文,然后将博文的url存储起来,以待后续的访问使用。
下面针对我的博客进行简单举例说明:
首先确定第一级网页url:
yeurl=['http://www.cnblogs.com/zpfbuaa/p/?page=1',
'http://www.cnblogs.com/zpfbuaa/p/?page=2',
'http://www.cnblogs.com/zpfbuaa/p/?page=3']这里设置的yeurl是作为第一级网页,然后从这个列表中得到所有的博文url(也就是需要读取上述网页结构,进行匹配操作)。
接下来进行循环,针对每一个yeurl里面的网页进行读取筛选操作。如下代码块所示:
def main():
list1=[]
list2=[]
global l
global totalblog
global ip_list
pr=r'href="http://www.cnblogs.com/zpfbuaa/p/(\d+)'
rr=re.compile(pr)
yeurl=['http://www.cnblogs.com/zpfbuaa/p/?page=1','http://www.cnblogs.com/zpfbuaa/p/?page=2','http://www.cnblogs.com/zpfbuaa/p/?page=3']
for i in yeurl:
req=urllib2.Request(i)
# proxy_ip = random.choice(proxyIP.proxy_list) # 在proxy_list中随机取一个ip
# print proxy_ip
# proxy_support = urllib2.ProxyHandler(proxy_ip)
# opener = urllib2.build_opener(proxy_support, urllib2.HTTPHandler)
req.add_header("User-Agent","Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0)")
cn=urllib2.urlopen(req)
f=cn.read()
list2=re.findall(rr,f)
list1=list1+list2
cn.close()
for o in list1:
totalblog=totalblog+1
url='http://www.cnblogs.com/zpfbuaa/p/'+o+".html"
l.append(url)
Get_proxy_ip()
print totalnum
- 上述的list1表示博文的编号,如上如中的/p/6995410, 此时的list1中存储的都是类似6995410的key
- req.add_header 添加头部信息,使用库urllib2进行网页的请求打开等操作
1.4 进行网页访问操作
前面已经构造了代理ip的列表、用户请求信息列表、下面的函数传递的参数为博文的url,这里的博文url在之前也已经构造好保存在l这个list中了。
这里使用随机选取代理ip以及用户请求信息列表,并且为了避免尝试打开网页导致过长的时间等待,设置超时时间为timeout=3,单位为秒。顺便统计出一共刷网页的次数以及打印出当前访问的网页url地址。
代码如下所示:
def su(url):
proxy_ip = random.choice(proxy_list)
user_agent = random.choice(user_agent_list)
print proxy_ip
print user_agent
proxy_support = urllib2.ProxyHandler({'http': proxy_ip})
opener = urllib2.build_opener(proxy_support, urllib2.HTTPHandler)
urllib2.install_opener(opener)
req = urllib2.Request(url)
req.add_header("User-Agent", user_agent)
try:
c = urllib2.urlopen(req, timeout=3)
except Exception as e:
print('******打开失败!******')
else:
global count
count +=1
print('OK!总计成功%s次!'%count)
print "当前刷的网址为"
print url
sem.release()
设置线程数目最大量为5,打印博客列表中的数目信息。遍历保存博文url的列表l然后针对每一个其中的url这里为变量i,将其传递至函数su,并开启线程进行博客访问操作。
if __name__ == "__main__":
main()
print "开始刷访问量!"
print "共计博客个数为 "
print totalblog
maxThread=5
sem=threading.BoundedSemaphore(maxThread)
while 1:
for i in l:
sem.acquire()
T=threading.Thread(target=su,args=(i,))
T.start()
1.5 刷访问量第一版代码
# coding=utf-8
import urllib2
import re
import sys
import time
import threading
import request
import random
l=[]
iparray=[]
global totalnum
totalnum = 0
global proxy_list
proxy_list=[]
global count
count = 0
totalblog=0
user_agent_list = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
]
def Get_proxy_ip():
global proxy_list
global totalnum
proxy_list = []
headers = {
'Host': 'www.xicidaili.com',
'User-Agent':'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Accept': r'application/json, text/javascript, */*; q=0.01',
'Referer': r'http://www.xicidaili.com/',
}
req = urllib2.Request(r'http://www.xicidaili.com/nn/', headers=headers)
response = urllib2.urlopen(req)
html = response.read().decode('utf-8')
ip_list = re.findall(r'\d+\.\d+\.\d+\.\d+',html)
port_list = re.findall(r'<td>\d+</td>',html)
for i in range(len(ip_list)):
totalnum+=1
ip = ip_list[i]
port = re.sub(r'<td>|</td>', '', port_list[i])
proxy = '%s:%s' %(ip,port)
proxy_list.append(proxy)
headers = {
'Host': 'www.xicidaili.com',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Accept': r'application/json, text/javascript, */*; q=0.01',
'Referer': r'http://www.xicidaili.com/',
}
req = urllib2.Request(r'http://www.xicidaili.com/nn/5', headers=headers)
response = urllib2.urlopen(req)
html = response.read().decode('utf-8')
ip_list = re.findall(r'\d+\.\d+\.\d+\.\d+', html)
port_list = re.findall(r'<td>\d+</td>', html)
for i in range(len(ip_list)):
totalnum+=1
ip = ip_list[i]
port = re.sub(r'<td>|</td>', '', port_list[i])
proxy = '%s:%s' % (ip, port)
proxy_list.append(proxy)
return proxy_list
def main():
list1=[]
list2=[]
global l
global totalblog
global ip_list
pr=r'href="http://www.cnblogs.com/zpfbuaa/p/(\d+)'
rr=re.compile(pr)
yeurl=['http://www.cnblogs.com/zpfbuaa/p/?page=1','http://www.cnblogs.com/zpfbuaa/p/?page=2','http://www.cnblogs.com/zpfbuaa/p/?page=3']
for i in yeurl:
req=urllib2.Request(i)
# proxy_ip = random.choice(proxyIP.proxy_list) # 在proxy_list中随机取一个ip
# print proxy_ip
# proxy_support = urllib2.ProxyHandler(proxy_ip)
# opener = urllib2.build_opener(proxy_support, urllib2.HTTPHandler)
req.add_header("User-Agent","Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0)")
cn=urllib2.urlopen(req)
f=cn.read()
list2=re.findall(rr,f)
list1=list1+list2
cn.close()
for o in list1:
totalblog=totalblog+1
url='http://www.cnblogs.com/zpfbuaa/p/'+o+".html"
l.append(url)
Get_proxy_ip()
print totalnum
def su(url):
proxy_ip = random.choice(proxy_list)
user_agent = random.choice(user_agent_list)
print proxy_ip
print user_agent
proxy_support = urllib2.ProxyHandler({'http': proxy_ip})
opener = urllib2.build_opener(proxy_support, urllib2.HTTPHandler)
urllib2.install_opener(opener)
req = urllib2.Request(url)
req.add_header("User-Agent", user_agent)
try:
c = urllib2.urlopen(req, timeout=3)
except Exception as e:
print('******打开失败!******')
else:
global count
count +=1
print('OK!总计成功%s次!'%count)
print "当前刷的网址为"
print url
sem.release()
if __name__ == "__main__":
main()
print "开始刷访问量!"
print "共计博客个数为 "
print totalblog
maxThread=5
sem=threading.BoundedSemaphore(maxThread)
while 1:
for i in l:
sem.acquire()
T=threading.Thread(target=su,args=(i,))
T.start()
2.刷访问量完整第二版
2.1 增加代理IP获取数量
之前的函数
def get_proxy_ip()可以从网址http://www.xicidaili.com/nn/中得到代理ip,但是这样的局限性较大。本版本添加新的代理ip地址,通过函数def get_proxy_ip2实现,以及函数def get_proxy_ip3。这样做的目的是熟悉一下python中的正则表达式,另外顺便稍微改一下版本而已。具体函数见最后的完整代码。
2.2 增加自动删除不可用代理ip
之前设置了过期时间,每当使用某个代理ip进行连接时,一旦产生超时,只是打印出产生异常而不进行处理,本次修改为将不可用的代理ip进行删除。也许这样做不是很好,尤其是在代理ip地址很少的时候,可能很快就用完了代理ip。因此这里可能作为一个改进的地方。
2.3 增加博客列表
这里的变化仅仅是提升第一级网页构造。利用网页url结构以及循环,构造出第一级网页的url列表。然后遍历每个网页进行博文url的搜索和筛选保存操作。具体实现见最后的完整代码。
2.4 改版完整代码
# coding=utf-8
import urllib2
import re
import threading
import random
proxy_list = []
total_proxy = 0
blog_list = []
total_blog = 0
total_visit = 0
total_remove = 0
user_agent_list = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
]
# request_list = ['http://www.xicidaili.com/nn/','http://www.xicidaili.com/nn/4','http://www.xicidaili.com/nn/5']
def get_proxy_ip():
global proxy_list
global total_proxy
request_list = []
headers = {
'Host': 'www.xicidaili.com',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Accept': r'application/json, text/javascript, */*; q=0.01',
'Referer': r'http://www.xicidaili.com/',
}
for i in range(11, 21):
request_item = "http://www.xicidaili.com/nn/" + str(i)
request_list.append(request_item)
for req_id in request_list:
req = urllib2.Request(req_id, headers=headers)
response = urllib2.urlopen(req)
html = response.read().decode('utf-8')
ip_list = re.findall(r'\d+\.\d+\.\d+\.\d+', html)
port_list = re.findall(r'<td>\d+</td>', html)
for i in range(len(ip_list)):
total_proxy += 1
ip = ip_list[i]
port = re.sub(r'<td>|</td>', '', port_list[i])
proxy = '%s:%s' % (ip, port)
proxy_list.append(proxy)
return proxy_list
def get_proxy_ip2():
global proxy_list
global total_proxy
request_list = []
headers = {
'Host': 'http://www.66ip.cn/',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Accept': r'application/json, text/javascript, */*; q=0.01',
'Referer': r'http://www.66ip.cn/',
}
for i in range(1, 50):
request_item = "http://www.66ip.cn/" + str(i) + ".html"
request_list.append(request_item)
for req_id in request_list:
req = urllib2.Request(req_id, headers=headers)
response = urllib2.urlopen(req)
html = response.read().decode('utf-8')
ip_list = re.findall(r'\d+\.\d+\.\d+\.\d+', html)
port_list = re.findall(r'<td>\d+</td>', html)
for i in range(len(ip_list)):
total_proxy += 1
ip = ip_list[i]
port = re.sub(r'<td>|</td>', '', port_list[i])
proxy = '%s:%s' % (ip, port)
proxy_list.append(proxy)
return proxy_list
def get_proxy_ip3():
global proxy_list
global total_proxy
request_list = []
headers = {
# 'Host': 'http://www.youdaili.net/',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
# 'Accept': r'application/json, text/javascript, */*; q=0.01',
# 'Referer': r'http://www.youdaili.net/',
}
# for i in range(2, 6):
# request_item = "http://www.youdaili.net/Daili/QQ/36811_" + str(i) + ".html"
first = "http://www.youdaili.net/Daili/guowai/"
req = urllib2.Request(first, headers=headers)
response = urllib2.urlopen(req)
html = response.read().decode('utf-8')
request_id = re.findall(r'href="http://www.youdaili.net/Daili/guowai/(\d+).html', html)
print request_id
for item in request_id:
request_item = "http://www.youdaili.net/Daili/guowai/" + str(item) + ".html"
request_list.append(request_item)
print request_list
# request_item="http://www.youdaili.net/Daili/guowai/4821.html"
# request_list.append(request_item)
# for i in range(2, 6):
# request_item = "http://www.youdaili.net/Daili/QQ/36811_" + str(i) + ".html"
# request_list.append(request_item)
for req_id in request_list:
req = urllib2.Request(req_id, headers=headers)
response = urllib2.urlopen(req)
html = response.read().decode('utf-8')
ip_list = re.findall(r'\d+\.\d+\.\d+\.\d+', html)
port_list = re.findall(r':+\d*@HTTP#', html)
for i in range(len(ip_list) - 20):
total_proxy += 1
ip = ip_list[i]
print port_list[i]
tmp = re.sub(r':', '', port_list[i])
port = re.sub(r'@HTTP#', '', tmp)
proxy = '%s:%s' % (ip, port)
print port
proxy_list.append(proxy)
print proxy_list
return proxy_list
def create_blog_list():
list1 = []
list2 = []
global blog_list
global total_blog
pr = r'href="http://www.cnblogs.com/zpfbuaa/p/(\d+)'
rr = re.compile(pr)
my_blog = []
# my_blog = ['http://www.cnblogs.com/zpfbuaa/p/?page=1', 'http://www.cnblogs.com/zpfbuaa/p/?page=2',
# 'http://www.cnblogs.com/zpfbuaa/p/?page=3']
for i in range(1, 25):
blogitem = "http://www.cnblogs.com/zpfbuaa/p/?page=" + str(i)
my_blog.append(blogitem)
for item in my_blog:
req = urllib2.Request(item)
# proxy_ip = random.choice(proxyIP.proxy_list) # 在proxy_list中随机取一个ip
# print proxy_ip
# proxy_support = urllib2.ProxyHandler(proxy_ip)
# opener = urllib2.build_opener(proxy_support, urllib2.HTTPHandler)
req.add_header("User-Agent", "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0)")
cn = urllib2.urlopen(req)
f = cn.read()
list2 = re.findall(rr, f)
list1 = list1 + list2
cn.close()
for blog_key in list1:
total_blog = total_blog + 1
url = 'http://www.cnblogs.com/zpfbuaa/p/' + blog_key + ".html"
blog_list.append(url)
def main():
create_blog_list()
# get_proxy_ip()
# get_proxy_ip2()
get_proxy_ip3()
def sorry_to_visit_you(url):
global total_visit
global proxy_list
global total_proxy
global total_remove
proxy_ip = random.choice(proxy_list)
user_agent = random.choice(user_agent_list)
print proxy_ip
print user_agent
proxy_support = urllib2.ProxyHandler({'http': proxy_ip})
opener = urllib2.build_opener(proxy_support, urllib2.HTTPHandler)
urllib2.install_opener(opener)
req = urllib2.Request(url)
req.add_header("User-Agent", user_agent)
try:
c = urllib2.urlopen(req, timeout=10)
except Exception as e:
proxy_list.remove(proxy_ip)
total_proxy -= 1
total_remove += 1
print "删除ip"
print proxy_ip
print "当前移除代理ip个数为:%d" % total_remove
print('******打开失败!******')
else:
total_visit += 1
print('OK!总计成功%d次!' % total_visit)
print "当前刷的网址为%s" % url
print "当前剩余代理ip个数为:%d" % total_proxy
sem.release()
if __name__ == "__main__":
main()
print "开始刷访问量!"
print "共计代理总数为%s个!" % total_proxy
print "共计博客个数为%s个!" % total_blog
max_thread = 5
sem = threading.BoundedSemaphore(max_thread)
while 1:
for blog_url in blog_list:
sem.acquire()
T = threading.Thread(target=sorry_to_visit_you, args=(blog_url,))
T.start()
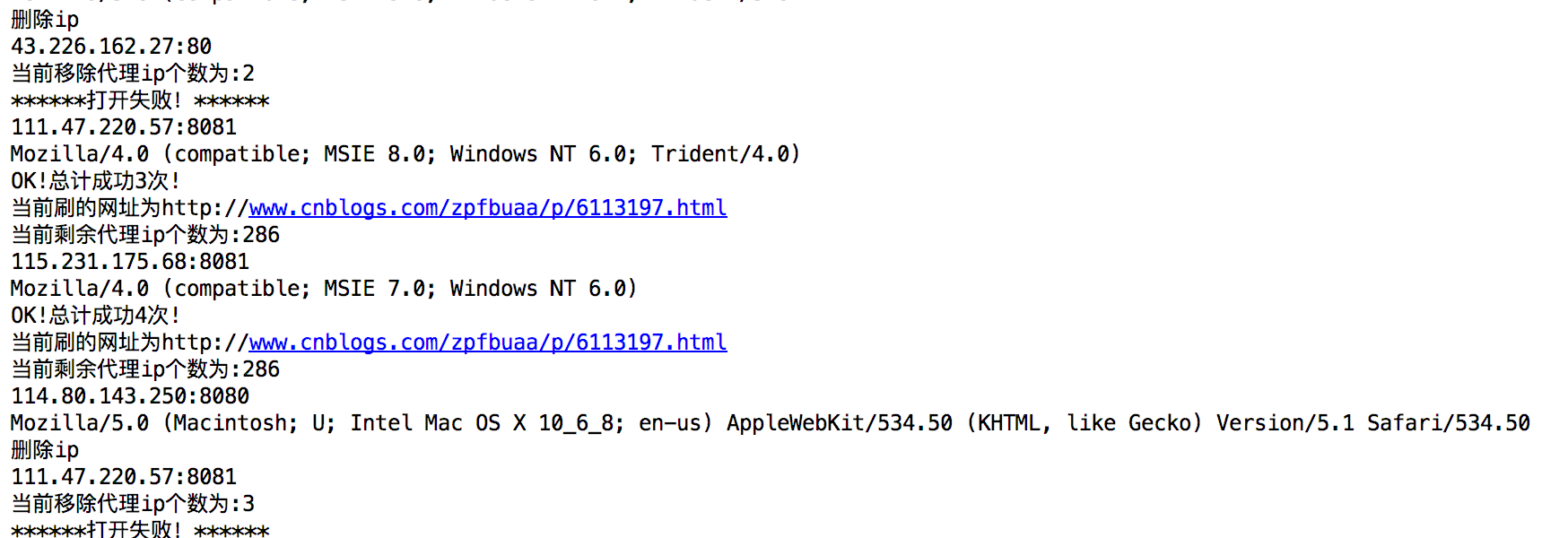
2.5 运行截图

python之刷博客访问量的更多相关文章
- Python 自动刷博客浏览量
哈哈,今天的话题有点那什么了哈.咱们应该秉承学习技术的角度来看,那么就开始今天的话题吧. 思路来源 今天很偶然的一个机会,听到别人在谈论现在的"刷量"行为,于是就激发了我的好奇心. ...
- 有哪些关于 Python 的技术博客?
Python是一种动态解释型的编程语言,它可以在Windows.UNIX.MAC等多种操作系统以及Java..NET开发平台上使用.不过包含的内容很多,加上各种标准库.拓展库,乱花渐欲迷人眼.因此如何 ...
- python爬取博客圆首页文章链接+标题
新人一枚,初来乍到,请多关照 来到博客园,不知道写点啥,那就去瞄一瞄大家都在干什么好了. 使用python 爬取博客园首页文章链接和标题. 首先当然是环境了,爬虫在window10系统下,python ...
- Python网络数据采集(1):博客访问量统计
前言 Python中能够爬虫的包还有很多,但requests号称是“让HTTP服务人类”...口气不小,但的确也很好用. 本文是博客里爬虫的第一篇,实现一个很简单的功能:获取自己博客主页里的访问量. ...
- Python爬虫小实践:爬取任意CSDN博客所有文章的文字内容(或可改写为保存其他的元素),间接增加博客访问量
Python并不是我的主业,当初学Python主要是为了学爬虫,以为自己觉得能够从网上爬东西是一件非常神奇又是一件非常有用的事情,因为我们可以获取一些方面的数据或者其他的东西,反正各有用处. 这两天闲 ...
- (最新)使用爬虫刷CSDN博客访问量——亲测有效
说明:该篇博客是博主一字一码编写的,实属不易,请尊重原创,谢谢大家! 1.概述 前言:前两天刚写了第一篇博客https://blog.csdn.net/qq_41782425/article/deta ...
- python requests、xpath爬虫增加博客访问量
这是一个分析IP代理网站,通过代理网站提供的ip去访问CSDN博客,达到以不同ip访同一博客的目的,以娱乐为主,大家可以去玩一下. 首先,准备工作,设置User-Agent: #1.headers h ...
- [Python爬虫]cnblogs博客备份工具(可扩展成并行)
并发爬虫小练习. 直接粘贴到本地,命名为.py文件即可运行,运行时的参数为你想要爬取的用户.默认是本博客. 输出是以用户名命名的目录,目录内便是博客内容. 仅供学习python的多线程编程方法,后续会 ...
- 本人在CSDN上的技术博客访问量突破了10万次,特此截图留念
从 2011-11-16在CSDN开博至今,将近三年. 在近三年的时间里,本博的访问量于2014-07-01突破了10万次,单篇博文<软件开发高手须掌握的4大SQL精髓 ...
随机推荐
- 【并查集】Connectivity @ABC049&ARC065/upcexam6492
Connectivity 时间限制: 1 Sec 内存限制: 128 MB 题目描述 There are N cities. There are also K roads and L railway ...
- 3、css初识
前端内容就分三部分html.css.javascript(js),对一个网页来说html相当于是一个裸体的人,css相当于给这个人穿上了衣服,javascript相当于给这个人赋予动作行为,今天我们要 ...
- 如何给webbrowser指定IE版本
void Button1Click(object sender, EventArgs e) { RegistryKey rk = Registry.LocalMachine; ...
- mysql YEARWEEK(date[,mode]) 函数 查询上周数据 以及本周数据
通常使用下边sql即可(如果数据库设置了周一为一周起始的话): 查询上周数据(addtime为datetime格式) SELECT id,addtime FROM mall_order WHERE ...
- reStructuredText语法简单说明
reStructuredText 是扩展名为.rst的纯文本文件,含义为"重新构建的文本"",也被简称为:RST或reST. 官方网址: http://docutils. ...
- (原)faster rcnn的tensorflow代码的理解
转载请注明出处: https://www.cnblogs.com/darkknightzh/p/10043864.html 参考网址: 论文:https://arxiv.org/abs/1506.01 ...
- SQL DML 数据操纵语句
前言 DML(Data Manipulation Language)语句:数据操纵语句,用于添加.删除.更新和查询数据库记录,并检查数据完整性.常用的语句关键字主要包括 insert.delete.u ...
- HDU 5095--Linearization of the kernel functions in SVM【模拟】
Linearization of the kernel functions in SVM Time Limit: 2000/1000 MS (Java/Others) Memory Limit: ...
- 记一次redis病毒分析笔记
起因 偶然间发现redis里有一个陌生key:tightsoft,它的值是:*/1 * * * * root curl -fsSL https://pastebin.com/raw/xbY7p5Tb| ...
- [moosefs] storage class
chapter 1 moosefs 3.1 storage class 功能的介绍 1.1 什么是storage class 在moosefs中,storage class允许指定文件的chunks存 ...