高可用Hadoop平台-Hue In Hadoop
1.概述
前面一篇博客《高可用Hadoop平台-Ganglia安装部署》,为大家介绍了Ganglia在Hadoop中的集成,今天为大家介绍另一款工具——Hue,该工具功能比较丰富,下面是今天为大家分享的内容目录:
- Hue简述
- Hue In Hadoop
- 截图预览
本文所使用的环境是Apache Hadoop-2.6版本,下面开始今天的内容分享。
2.Hue简述
Hue是一个开源的Apache Hadoop UI系统,由Cloudera Desktop演化而来,最后Cloudera公司将其贡献给Apache基金会的Hadoop社区,它是基于Python Web框架Django实现的。通过使用Hue我们可以在浏览器端的Web控制台上与Hadoop集群进行交互来分析处理数据,例如操作HDFS上的数据,运行MapReduce Job,执行Hive的SQL语句,浏览HBase数据库等等。
Hue在数据库方面,默认使用的是SQLite数据库来管理自身的数据,包括用户认证和授权,另外,可以自定义为MySQL数据库、Postgresql数据库、以及Oracle数据库。其自身的功能包含有:
- 对HDFS的访问,通过浏览器来查阅HDFS的数据。
- Hive编辑器:可以编写HQL和运行HQL脚本,以及查看运行结果等相关Hive功能。
- 提供Solr搜索应用,并对应相应的可视化数据视图以及DashBoard。
- 提供Impala的应用进行数据交互查询。
- 最新的版本集成了Spark编辑器和DashBoard
- 支持Pig编辑器,并能够运行编写的脚本任务。
- Oozie调度器,可以通过DashBoard来提交和监控Workflow、Coordinator以及Bundle。
- 支持HBase对数据的查询修改以及可视化。
- 支持对Metastore的浏览,可以访问Hive的元数据以及对应的HCatalog。
- 另外,还有对Job的支持,Sqoop,ZooKeeper以及DB(MySQL,SQLite,Oracle等)的支持。
下面就通过集成部署,来预览相关功能。
3.Hue In Hadoop
本文所使用的Hadoop环境是基于Apache社区版的Hadoop2.6,在集成到Hadoop上,Hue的部署过程是有点复杂的。Hue在CDH上是可以轻松的集成的,我们在使用CDH的那套管理系统是,可以非常容易的添加Hue的相关服务。然而,在实际业务场景中,往往Hadoop集群使用的并非都是CDH版的,在Cloudera公司使用将其贡献给Apache基金会后,在Hadoop的集成也有了较好的改善,下面就为大家介绍如何去集成到Apache的社区版Hadoop上。
3.1基础软件
在集成Hue工具时,我们需要去下载对应的源码,该系统是开源免费的,可以在GitHub上下载到对应的源码,下载地址如下所示:
git@github.com:cloudera/hue.git
我们使用Git命令将其克隆下来,命令如下所示:
git clone git@github.com:cloudera/hue.git
然后,我们在Hadoop账号下安装Hue需要的依赖环境,命令如下所示:
sudo yum install krb5-devel cyrus-sasl-gssapi cyrus-sasl-deve libxml2-devel libxslt-devel mysql mysql-devel openldap-devel python-devel python-simplejson sqlite-devel
等待其安装完毕。
3.2编译部署
在基础环境准备完成后,我们开始对Hue的源码进行编译,编译的时候,Python的版本需要是2.6+以上,不然在编译的时候会出现错误,编译命令如下所示:
[hadoop@nna ~]$ cd hue
[hadoop@nna ~]$ make apps
等待其编译完成,在编译的过程中有可能会出现错误,在出现错误时Shell控制台会提示对应的错误信息,大家可以根据错误信息的提示来解决对应的问题,在编译完成后,我们接下来需要对其做对应的配置,Hue的默认配置是启动本地的Web服务,这个我们需要对其修改,供外网或者内网去访问其Web服务地址,我们在Hue的根目录下的desktop/conf文件夹下加pseudo-distributed.ini文件,然后我们对新增的文件添加如下内容:
vi pseudo-distributed.ini
[desktop]
http_host=10.211.55.28
http_port=
[hadoop]
[[hdfs_clusters]]
[[[default]]]
fs_defaultfs=hdfs://cluster1
logical_name=cluster1
webhdfs_url=http://10.211.55.26:50070/webhdfs/v1
hadoop_conf_dir=/home/hadoop/hadoop-2.6./etc/hadoop
[beeswax]
hive_server_host=10.211.55.17
hive_server_port=
# hive_conf_dir=/home/hive/warehouse
[hbase]
hbase_clusters=(cluster1|10.211.55.26:)
hbase_conf_dir=/home/hadoop/hbase-1.0./conf
关于Hue的详细和更多配置需要,大家可以参考官方给的知道文档,连接地址如下 所示:
http://cloudera.github.io/hue/docs-3.8.0/manual.html
这里,Hue的集成就完成了,下面可以输入启动命令来查看,命令如下所示:
[hadoop@nna ~]$ /root/hue-3.7./build/env/bin/supervisor &
启动信息如下所示:
下面,在浏览器中输入对应的访问地址,这里我配置的Port是8000,在第一次访问时,需要输入用户名和密码来创建一个Administrator,这里需要在一步的时候需要注意下。
4.截图预览
下面附上Hue的相应的截图预览,如下图所示:



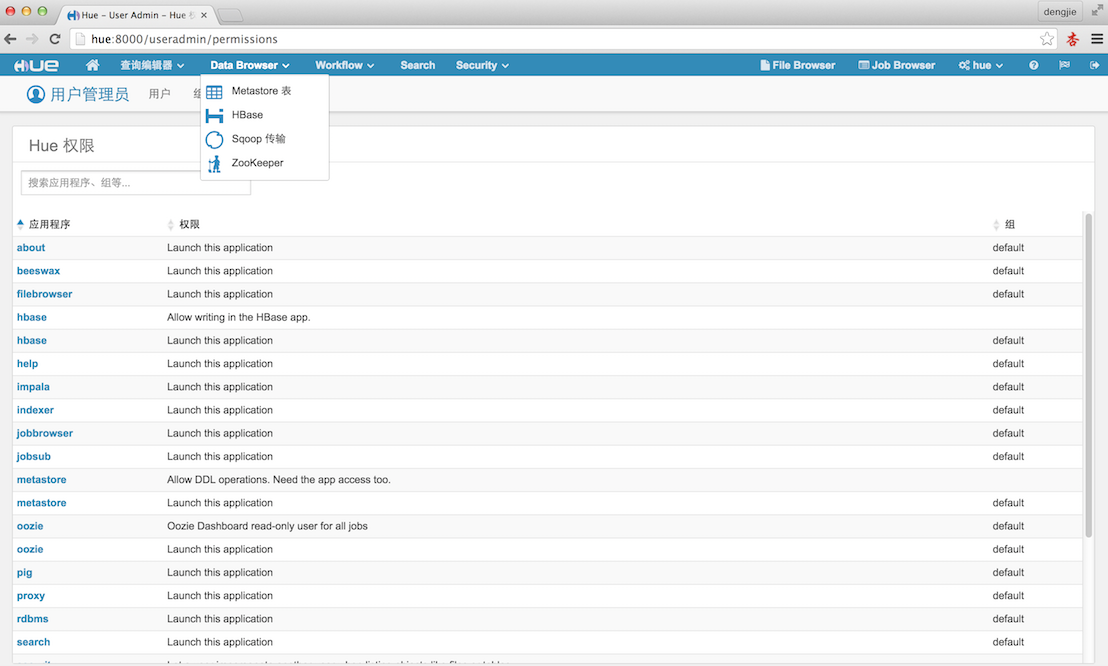

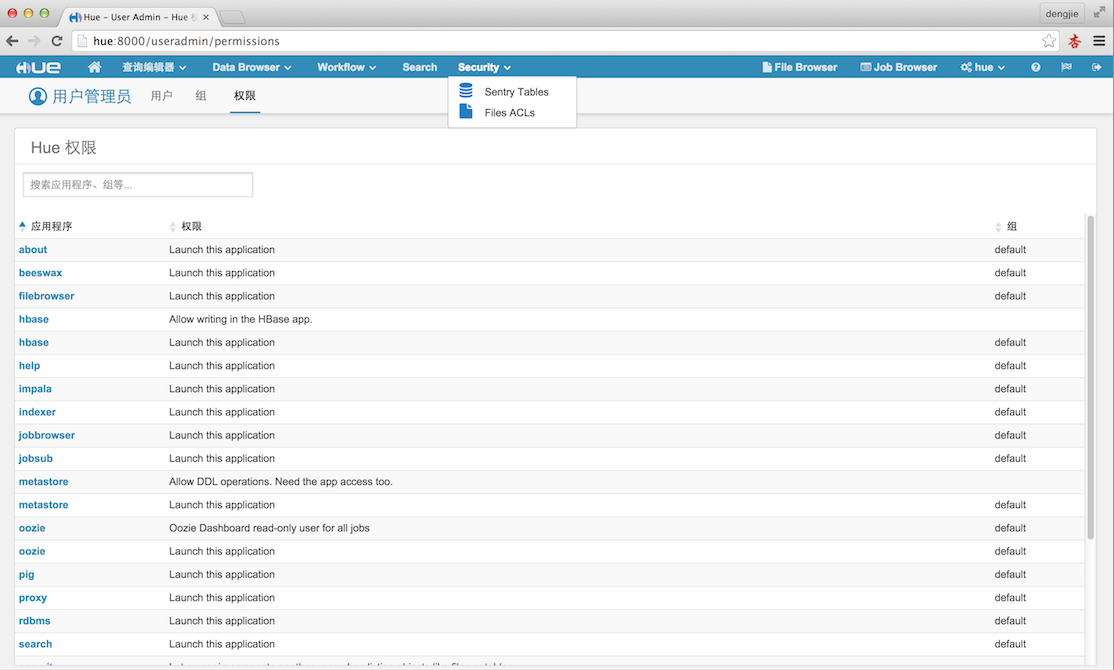
5.总结
在编译的时候,大家需要注意Hue的依赖环境,由于我们的Hadoop集群不是CDH版本的,所以在集成Hue的服务不能像CDH上那么轻松。在Apache的Hadoop社区版上集成部署,会需要对应的环境,若是缺少依赖,在编译的时候是会发生错误的。所以,这里需要特别留心注意,出错后,一般都会有提示信息的,大家可以根据提示检查定位出错误原因。
6.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
高可用Hadoop平台-Hue In Hadoop的更多相关文章
- 看我如何快速学习.Net(高可用数据采集平台)
最近文章:高可用数据采集平台(如何玩转3门语言php+.net+aauto).高并发数据采集的架构应用(Redis的应用) 项目文档:关键词匹配项目深入研究(二)- 分表思想的引入 吐槽:本人也是非常 ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- 高可用数据采集平台(如何玩转3门语言php+.net+aauto)
同类文章:高并发数据采集的架构应用(Redis的应用) 吐槽下:本人主程是PHP,团队里面也没有精通.net的人才,为了解决这个平台方案,还是费了一部分劲. 新年了,希望有个新的开始.技术+团队管理都 ...
- Hadoop记录-Hadoop NameNode 高可用 (High Availability) 实现解析
Hadoop NameNode 高可用 (High Availability) 实现解析 NameNode 高可用整体架构概述 在 Hadoop 1.0 时代,Hadoop 的两大核心组件 HDF ...
- hadoop 集群HA高可用搭建以及问题解决方案
hadoop 集群HA高可用搭建 目录大纲 1. hadoop HA原理 2. hadoop HA特点 3. Zookeeper 配置 4. 安装Hadoop集群 5. Hadoop HA配置 搭建环 ...
- Hadoop NameNode 高可用 (High Availability) 实现解析
转载自:http://reb12345reb.iteye.com/blog/2306818 在 Hadoop 的整个生态系统中,HDFS NameNode 处于核心地位,NameNode 的可用性直接 ...
- Hadoop NameNode 高可用 (High Availability) 实现解析[转]
NameNode 高可用整体架构概述 在 Hadoop 1.0 时代,Hadoop 的两大核心组件 HDFS NameNode 和 JobTracker 都存在着单点问题,这其中以 NameNode ...
- 【转载】Hadoop NameNode 高可用 (High Availability) 实现解析
转载:https://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-name-node/ NameNode 高可用整体架构概述 在 Had ...
- hadoop高可用安装和原理详解
本篇主要从hdfs的namenode和resourcemanager的高可用进行安装和原理的阐述. 一.HA安装 1.基本环境准备 1.1.1.centos7虚拟机安装,详情见VMware安装Cent ...
- Hadoop平台配置汇总
Hadoop平台配置汇总 @(Hadoop) Hadoop hadoop-env.sh和yarn-env.sh中export log和pid的dir即可和JAVA_HOME. core-site.xm ...
随机推荐
- 解决 ora-28001 密码过期的处理办法
转载自:https://blog.csdn.net/pengyouchuan/article/details/12905623 操作步骤: $sqlplus / as sysdba ALTER PRO ...
- [c#.net]未能加载文件或程序集“”或它的某一个依赖项。系统找不到指定的文件
问题是这样嘀: 项目采用了三层架构和工厂模式,并借鉴了PetShop的架构,因为这个项目也是采用分布式的数据库,目前只有三个数据库,主要出于提高访问性能考虑. 原来是按照网上对PetShop的介绍来给 ...
- Android 多线程编程
Android 多线程编程 //1.多线程 进程:操作系统的多道程序 线程:同一个程序的多条路径 //2.创建多线程程序 创建一个类extends Thread 重写run方法 在main方法中创建对 ...
- Python踩坑之 sys.argv[-1]代表什么
平台:win10+python 3.7.0 一.sys说明: sys.argv这个函数是我们写python脚本中最常用的一个函数. sys是Python的一个「标准库」,也就是官方出的「模块」,是「S ...
- Win7 VS2015编译wxWidgets-3.1.0
下载 https://www.wxwidgets.org/downloads/ 打开SLN工程 D:\CPPLibs\wxWidgets-3.1.0\build\msw\wx_vc14.sln 编译 ...
- fcitx4.2.0自定义中文标点符号
+fcitx 定制标点 http://forum.ubuntu.com.cn/viewtopic.PHP?t=376701&p=2755636 下载punc.mb.gz放到~/.config/ ...
- 用Dockerfile创建镜像--自动化部署tomcat+mysql+mycat
https://www.jianshu.com/p/a14b34386b41
- ScriptOJ-safeGet#99
const safeGet = (data, path) => { if(!path) return undefined; const pathArr = path.split('.'); le ...
- redis知识点杂记
最近梳理了一下redis的基本知识.本文会从redis的简单使用.redis的数据类型.redis持久化三个方面做简单阐述和总结. 一.Redis基本操作 1.key的规则 不能使用\n空格.其他都可 ...
- 制作Visual Studio 2019 (VS 2019) 离线安装包
与制作Visual Studio 2017的离线安装包(https://www.cnblogs.com/danzhang/p/6534341.html)类似,可以使用--layout的参数在安装前先下 ...