[01-01] 示例:用Java爬取新闻
1、分析url
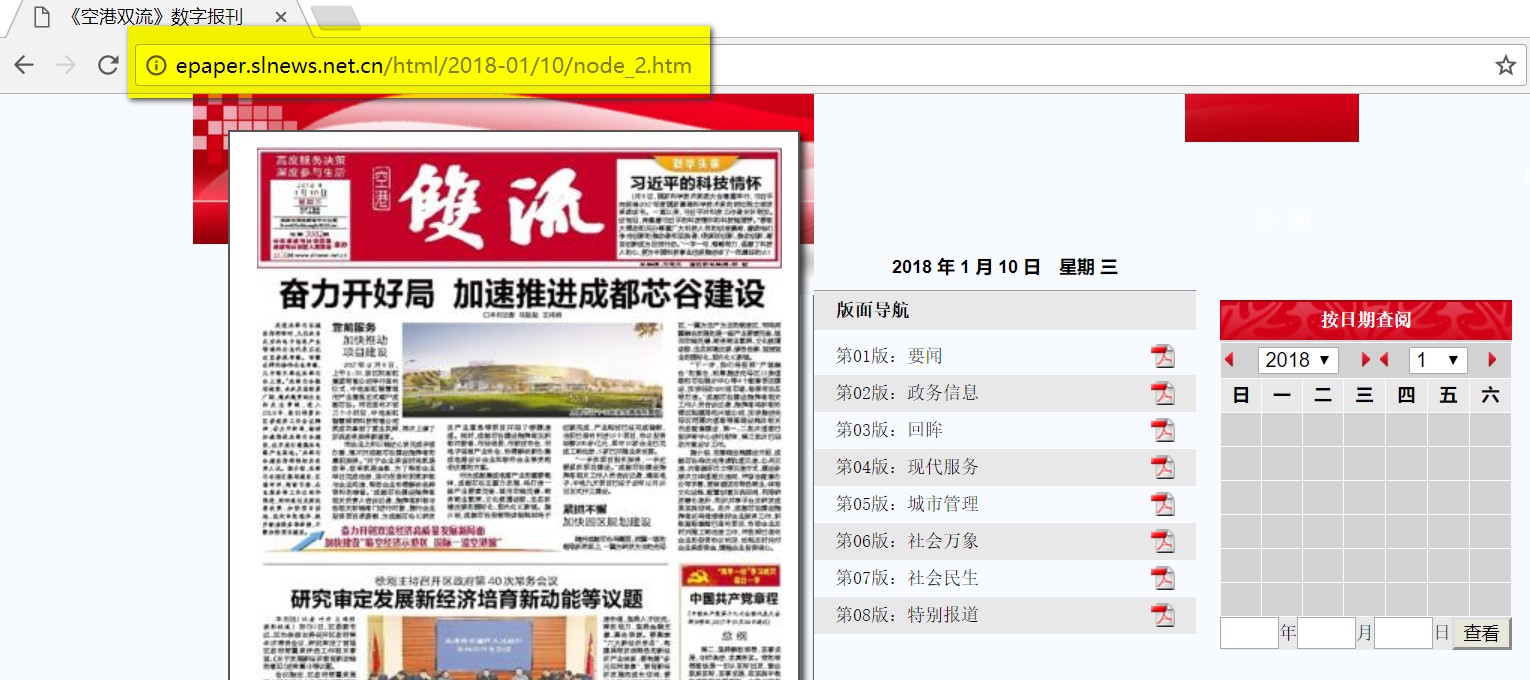
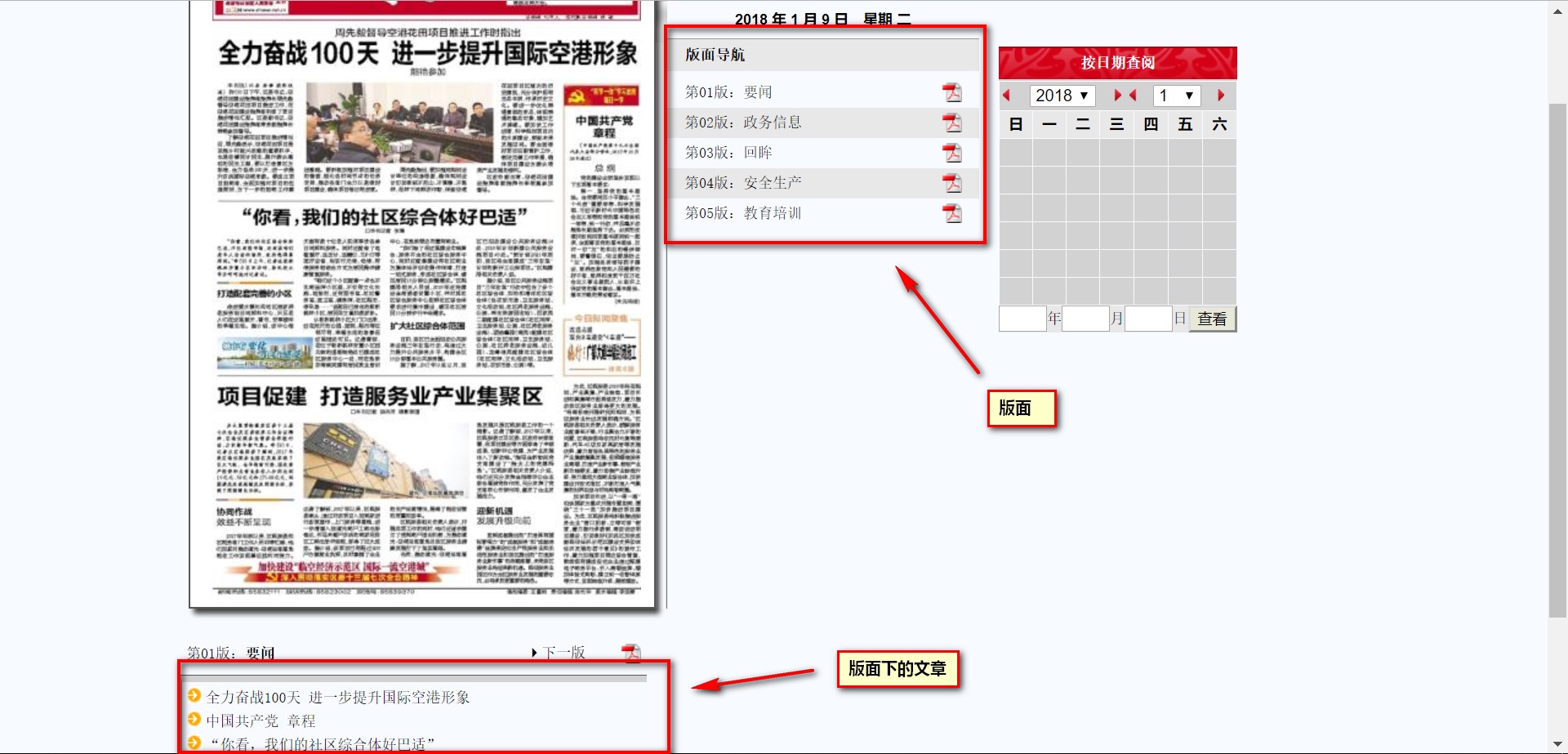
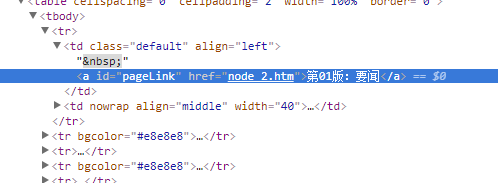

- 先得到所有版面的url
- 访问版面网页并抓取其中的所有文章的url
- 最后访问文章url就可以得到新闻网页内容了
2、代码部分
public class CrawlerUtil {
/**
* 获取主网页的内容
*
* @param url 网页url
* @param requestMethod 请求方式
* @param refer post内容
* @return 网页内容
*/
public static String sendHttpRequest(String url, RequestMethod requestMethod, String refer) {
refer = refer == null || "".equals(refer) ? null : refer;
StringBuffer buffer = new StringBuffer();
try {
//建立连接
URL requestUrl = new URL(url);
HttpURLConnection connection = (HttpURLConnection) requestUrl.openConnection();
connection.setRequestMethod(requestMethod.getValue());
switch (requestMethod) {
case GET:
connection.connect();
break;
case POST:
if (refer != null) {
OutputStream out = connection.getOutputStream();
out.write((refer.getBytes("UTF-8")));
out.close();
}
break;
default:
break;
}
//获取网页内容
InputStream in = connection.getInputStream();
InputStreamReader inputStreamReader = new InputStreamReader(in, "UTF-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
String str = null;
while ((str = bufferedReader.readLine()) != null) {
buffer.append(str);
}
//关闭资源
bufferedReader.close();
inputStreamReader.close();
in.close();
in = null;
connection.disconnect();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return buffer.toString();
}
}public class CrawlerUtil {
/**
* 获取主网页的内容
*
* @param url 网页url
* @param requestMethod 请求方式
* @param refer post内容
* @return 网页内容
*/
public static String sendHttpRequest(String url, RequestMethod requestMethod, String refer) {
refer = refer == null || "".equals(refer) ? null : refer;
StringBuffer buffer = new StringBuffer();
try {
//建立连接
URL requestUrl = new URL(url);
HttpURLConnection connection = (HttpURLConnection) requestUrl.openConnection();
connection.setRequestMethod(requestMethod.getValue());
switch (requestMethod) {
case GET:
connection.connect();
break;
case POST:
if (refer != null) {
OutputStream out = connection.getOutputStream();
out.write((refer.getBytes("UTF-8")));
out.close();
}
break;
default:
break;
}
//获取网页内容
InputStream in = connection.getInputStream();
InputStreamReader inputStreamReader = new InputStreamReader(in, "UTF-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
String str = null;
while ((str = bufferedReader.readLine()) != null) {
buffer.append(str);
}
//关闭资源
bufferedReader.close();
inputStreamReader.close();
in.close();
in = null;
connection.disconnect();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return buffer.toString();
}
}
/**
* 双流新闻网地址
*/
private static final String NEWS_URL = "http://epaper.slnews.net.cn/html/%s/%s.htm";
/**
* 获取特定日期的新闻网的版面地址url
* <p>
* 默认不填写factor参数的话,则url为第一版面链接,填入factor值node_2
* </p>
*
* @param date 日期
* @param factor 板面,形式为node_?
* 文章,形式为content_?
* @return 新闻网地址url
*/
public static String takePageUrl(Date date, String factor) {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM/dd");
factor = factor == null ? "node_2" : factor;
return String.format(NEWS_URL, format.format(date), factor);
}/**
* 双流新闻网地址
*/
private static final String NEWS_URL = "http://epaper.slnews.net.cn/html/%s/%s.htm";
/**
* 获取特定日期的新闻网的版面地址url
* <p>
* 默认不填写factor参数的话,则url为第一版面链接,填入factor值node_2
* </p>
*
* @param date 日期
* @param factor 板面,形式为node_?
* 文章,形式为content_?
* @return 新闻网地址url
*/
public static String takePageUrl(Date date, String factor) {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM/dd");
factor = factor == null ? "node_2" : factor;
return String.format(NEWS_URL, format.format(date), factor);
}
/**
* 获取内容匹配的元素集合
*
* @param content 网页内容
* @param reg 匹配正则
* @return 元素集合
*/
private static List<String> takeElementList(String content, String reg) {
log.debug("start take elements from content by Reg");
List<String> list = new ArrayList<String>();
//定义正则规则
Pattern pattern = Pattern.compile(reg);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
String element = matcher.group(1);
list.add(element);
log.debug(element);
}
log.debug("take elements end");
return list;
}/**
* 获取内容匹配的元素集合
*
* @param content 网页内容
* @param reg 匹配正则
* @return 元素集合
*/
private static List<String> takeElementList(String content, String reg) {
log.debug("start take elements from content by Reg");
List<String> list = new ArrayList<String>();
//定义正则规则
Pattern pattern = Pattern.compile(reg);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
String element = matcher.group(1);
list.add(element);
log.debug(element);
}
log.debug("take elements end");
return list;
}
/**
* 获取特定日期新闻网的版面链接元素
*
* @param date 日期
* @return 版面链接的元素集合
*/
public static List<String> takeNodeUrlEleList(Date date) {
String url = takePageUrl(date, null);
String content = CrawlerUtil.sendHttpRequest(url, RequestMethod.GET, null);
String reg = "<a id=pageLink href=.*?(node_\\d+?)\\.htm>.*?<\\/a>";
return takeElementList(content, reg);
}
/**
* 获取指定日期指定版面的所有文章链接元素集合
*
* @param date 日期
* @param node 版面元素,格式为node_?
* @return 文章链接的元素集合
*/
public static List<String> takeNewsUrlEleList(Date date, String node) {
String url = takePageUrl(date, node);
String content = CrawlerUtil.sendHttpRequest(url, RequestMethod.GET, null);
String reg = "<a href=.*?(content_\\d+?)\\.htm>";
return takeElementList(content, reg);
}/**
* 获取特定日期新闻网的版面链接元素
*
* @param date 日期
* @return 版面链接的元素集合
*/
public static List<String> takeNodeUrlEleList(Date date) {
String url = takePageUrl(date, null);
String content = CrawlerUtil.sendHttpRequest(url, RequestMethod.GET, null);
String reg = "<a id=pageLink href=.*?(node_\\d+?)\\.htm>.*?<\\/a>";
return takeElementList(content, reg);
}
/**
* 获取指定日期指定版面的所有文章链接元素集合
*
* @param date 日期
* @param node 版面元素,格式为node_?
* @return 文章链接的元素集合
*/
public static List<String> takeNewsUrlEleList(Date date, String node) {
String url = takePageUrl(date, node);
String content = CrawlerUtil.sendHttpRequest(url, RequestMethod.GET, null);
String reg = "<a href=.*?(content_\\d+?)\\.htm>";
return takeElementList(content, reg);
}
/**
* 抓取指定日期新闻页面内容集合
*
* @param date 日期
* @return 新闻页面内容
*/
public static List<String> takeNewsPageList(Date date) {
log.info("start crawl news page content. date:" + date);
List<String> newsList = new ArrayList<String>();
List<String> nodeEleList = NewsCrawler.takeNodeUrlEleList(date);
for (String nodeEle : nodeEleList) {
List<String> newsEleList = NewsCrawler.takeNewsUrlEleList(date, nodeEle);
for (String newsEle : newsEleList) {
String url = NewsCrawler.takePageUrl(date, newsEle);
String content = CrawlerUtil.sendHttpRequest(url, RequestMethod.GET, null);
newsList.add(content);
}
}
log.info("crawl news page content end. page amount:" + newsList.size());
return newsList;
}/**
* 抓取指定日期新闻页面内容集合
*
* @param date 日期
* @return 新闻页面内容
*/
public static List<String> takeNewsPageList(Date date) {
log.info("start crawl news page content. date:" + date);
List<String> newsList = new ArrayList<String>();
List<String> nodeEleList = NewsCrawler.takeNodeUrlEleList(date);
for (String nodeEle : nodeEleList) {
List<String> newsEleList = NewsCrawler.takeNewsUrlEleList(date, nodeEle);
for (String newsEle : newsEleList) {
String url = NewsCrawler.takePageUrl(date, newsEle);
String content = CrawlerUtil.sendHttpRequest(url, RequestMethod.GET, null);
newsList.add(content);
}
}
log.info("crawl news page content end. page amount:" + newsList.size());
return newsList;
}
[01-01] 示例:用Java爬取新闻的更多相关文章
- MinerHtmlThread.java 爬取页面线程
MinerHtmlThread.java 爬取页面线程 package com.iteye.injavawetrust.miner; import org.apache.commons.logging ...
- MinerConfig.java 爬取配置类
MinerConfig.java 爬取配置类 package com.iteye.injavawetrust.miner; import java.util.List; /** * 爬取配置类 * @ ...
- Java爬取网络博客文章
前言 近期本人在某云上购买了个人域名,本想着以后购买与服务器搭建自己的个人网站,由于需要筹备的太多,暂时先搁置了,想着先借用GitHub Pages搭建一个静态的站,搭建的过程其实也曲折,主要是域名地 ...
- Java爬取校内论坛新帖
Java爬取校内论坛新帖 为了保持消息灵通,博主没事会上上校内论坛看看新帖,作为爬虫爱好者,博主萌生了写个爬虫自动下载的想法. 嗯,这次就选Java. 第三方库准备 Jsoup Jsoup是一款比较好 ...
- Java爬取B站弹幕 —— Python云图Wordcloud生成弹幕词云
一 . Java爬取B站弹幕 弹幕的存储位置 如何通过B站视频AV号找到弹幕对应的xml文件号 首先爬取视频网页,将对应视频网页源码获得 就可以找到该视频的av号aid=8678034 还有弹幕序号, ...
- java爬取网页内容 简单例子(2)——附jsoup的select用法详解
[背景] 在上一篇博文java爬取网页内容 简单例子(1)——使用正则表达式 里面,介绍了如何使用正则表达式去解析网页的内容,虽然该正则表达式比较通用,但繁琐,代码量多,现实中想要想出一条简单的正则表 ...
- java爬取并下载酷狗TOP500歌曲
是这样的,之前买车送的垃圾记录仪不能用了,这两天狠心买了好点的记录仪,带导航.音乐.蓝牙.4G等功能,寻思,既然有这些功能就利用起来,用4G听歌有点奢侈,就准备去酷狗下点歌听,居然都是需要办会员才能下 ...
- Java爬取并下载酷狗音乐
本文方法及代码仅供学习,仅供学习. 案例: 下载酷狗TOP500歌曲,代码用到的代码库包含:Jsoup.HttpClient.fastJson等. 正文: 1.分析是否可以获取到TOP500歌单 打开 ...
- Java爬取先知论坛文章
Java爬取先知论坛文章 0x00 前言 上篇文章写了部分爬虫代码,这里给出一个完整的爬取先知论坛文章代码. 0x01 代码实现 pom.xml加入依赖: <dependencies> & ...
随机推荐
- Sharepoint 2013 Gatherer 数据库的架构版本低于此 Gatherer 应用程序支持的向后兼容的最低架构版本
管理中心 ->升级和迁移 ->查看数据库状态 解决方法: 开始-运行(以管理员身份运行),输入如下命令. cd C:\Program Files\Common Files\Microso ...
- Angular基础(六) DI
一.依赖注入 a) 如果模块A需要依赖模块B,通常的做法是在A中导入B,import{B} from ‘B’,但有一些场合需要解除这种直接依赖,比如单元测试时需要mock一个B对象.还有时要创建B ...
- 《Inside C#》笔记(十二) 委托与事件
C#的委托与C++的函数指针类似,但委托是类型安全的,意味着指针始终会指向有效的函数.委托的使用主要有两种:回调和事件. 一 将委托作为回调函数 在需要给一个函数传递一个函数指针,随后通过函数指针调用 ...
- Android Stuido代码混淆
一.Android Studio 代码混淆基本配置首先我们要在build.gradle里设置 miifyEnabled 里改为true,表示可以混淆 proguardFiles getDefaultP ...
- 开始记录 Windows Phone 生涯
已经快接近三年没有更新博客了,最近打算把博客这块从新建设起来. 由于工作原因,现在已经很久没有接触过Android了.目前工作是全力 Windows Phone,并且也已经工作一年半了,以后会陆续把之 ...
- dmesg七种用法
dmesg 命令的使用范例 ‘dmesg’命令设备故障的诊断是非常重要的.在‘dmesg’命令的帮助下进行硬件的连接或断开连接操作时,我们可以看到硬件的检测或者断开连接的信息.‘dmesg’命令在多数 ...
- 平板电脑安装Ubuntu教程
平板电脑安装Ubuntu教程-以V975w为例,Z3735系列CPU通用 最近尝试在昂达V975w平板电脑和intel stick中安装ubuntu,经过分析,发现存在一个非常大的坑.但因为这个坑,此 ...
- maven(三):maven项目结构及其运行机制
在上一篇中讲了如何创建maven项目,现在回到那个项目 项目结构 src/main/java:java代码目录 src/main/resources:资源目录,比如spring.xml文件,prope ...
- 利用PCA进行故障监测
利用PCA进行故障监测,传统的统计指标有两种:Hotelling-T2和平方预测误差(Squared prediction error, SPE).T2统计量反映了每个主成分在变化趋势和幅值上偏离模型 ...
- 开发测试技巧|辅助开发调试:goolge浏览器利用F12在控制台输入脚本实现表单自动填充
一个开发测试技巧的指引和截图,利用google浏览器的F12调试和Console执行,注入JavaScript脚本实现表单的自动填充和测试. 原文链接: http://www.lookdaima.co ...