使用Pandas_UDF快速改造Pandas代码
1. Pandas_UDF介绍
PySpark和Pandas之间改进性能和互操作性的其核心思想是将Apache Arrow作为序列化格式,以减少PySpark和Pandas之间的开销。
Pandas_UDF是在PySpark2.3中新引入的API,由Spark使用Arrow传输数据,使用Pandas处理数据。Pandas_UDF是使用关键字pandas_udf作为装饰器或包装函数来定义的,不需要额外的配置。目前,有两种类型的Pandas_UDF,分别是Scalar(标量映射)和Grouped Map(分组映射)。
1.1 Scalar
Scalar Pandas UDF用于向量化标量操作。常常与select和withColumn等函数一起使用。其中调用的Python函数需要使用pandas.Series作为输入并返回一个具有相同长度的pandas.Series。具体执行流程是,Spark将列分成批,并将每个批作为数据的子集进行函数的调用,进而执行panda UDF,最后将结果连接在一起。
下面的示例展示如何创建一个scalar panda UDF,计算两列的乘积:
- import pandas as pd
- from pyspark.sql.functions import col, pandas_udf
- from pyspark.sql.types import LongType
- # 声明函数并创建UDF
- def multiply_func(a, b):
- return a * b
- multiply = pandas_udf(multiply_func, returnType=LongType())
- x = pd.Series([1, 2, 3])
- df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
- # Execute function as a Spark vectorized UDF
- df.select(multiply(col("x"), col("x"))).show()
- # +-------------------+
- # |multiply_func(x, x)|
- # +-------------------+
- # | 1|
- # | 4|
- # | 9|
- # +-------------------+
1.2 Grouped Map
Grouped map(分组映射)panda_udf与groupBy().apply()一起使用,后者实现了“split-apply-combine”模式。“split-apply-combine”包括三个步骤:
- 使用DataFrame.groupBy将数据分成多个组。
- 对每个分组应用一个函数。函数的输入和输出都是pandas.DataFrame。输入数据包含每个组的所有行和列。
- 将结果合并到一个新的DataFrame中。
要使用groupBy().apply(),需要定义以下内容:
- 定义每个分组的Python计算函数,这里可以使用pandas包或者Python自带方法。
- 一个StructType对象或字符串,它定义输出DataFrame的格式,包括输出特征以及特征类型。
需要注意的是,StructType对象中的Dataframe特征顺序需要与分组中的Python计算函数返回特征顺序保持一致。
此外,在应用该函数之前,分组中的所有数据都会加载到内存,这可能导致内存不足抛出异常。
下面的例子展示了如何使用groupby().apply() 对分组中的每个值减去分组平均值。
- from pyspark.sql.functions import pandas_udf, PandasUDFType
- df = spark.createDataFrame(
- [(1, 1.0), (1, 2.0), (2, 3.0), (2, 5.0), (2, 10.0)],
- ("id", "v"))
- @pandas_udf("id long, v double", PandasUDFType.GROUPED_MAP)
- def subtract_mean(pdf):
- # pdf is a pandas.DataFrame
- v = pdf.v
- return pdf.assign(v=v - v.mean())
- df.groupby("id").apply(subtract_mean).show()
- # +---+----+
- # | id| v|
- # +---+----+
- # | 1|-0.5|
- # | 1| 0.5|
- # | 2|-3.0|
- # | 2|-1.0|
- # | 2| 4.0|
- # +---+----+
1.3 Grouped Aggregate
Grouped aggregate Panda UDF类似于Spark聚合函数。Grouped aggregate Panda UDF常常与groupBy().agg()和pyspark.sql.window一起使用。它定义了来自一个或多个的聚合。级数到标量值,其中每个pandas.Series表示组或窗口中的一列。 需要注意的是,这种类型的UDF不支持部分聚合,组或窗口的所有数据都将加载到内存中。此外,目前只支持Grouped aggregate Pandas UDFs的无界窗口。 下面的例子展示了如何使用这种类型的UDF来计算groupBy和窗口操作的平均值:
- from pyspark.sql.functions import pandas_udf, PandasUDFType
- from pyspark.sql import Window
- df = spark.createDataFrame(
- [(1, 1.0), (1, 2.0), (2, 3.0), (2, 5.0), (2, 10.0)],
- ("id", "v"))
- @pandas_udf("double", PandasUDFType.GROUPED_AGG)
- def mean_udf(v):
- return v.mean()
- df.groupby("id").agg(mean_udf(df['v'])).show()
- # +---+-----------+
- # | id|mean_udf(v)|
- # +---+-----------+
- # | 1| 1.5|
- # | 2| 6.0|
- # +---+-----------+
- w = Window \
- .partitionBy('id') \
- .rowsBetween(Window.unboundedPreceding, Window.unboundedFollowing)
- df.withColumn('mean_v', mean_udf(df['v']).over(w)).show()
- # +---+----+------+
- # | id| v|mean_v|
- # +---+----+------+
- # | 1| 1.0| 1.5|
- # | 1| 2.0| 1.5|
- # | 2| 3.0| 6.0|
- # | 2| 5.0| 6.0|
- # | 2|10.0| 6.0|
- # +---+----+------+
2. 快速使用Pandas_UDF
需要注意的是schema变量里的字段名称为pandas_dfs() 返回的spark dataframe中的字段,字段对应的格式为符合spark的格式。
这里,由于pandas_dfs()功能只是选择若干特征,所以没有涉及到字段变化,具体的字段格式在进入pandas_dfs()之前已通过printSchema()打印。如果在pandas_dfs()中使用了pandas的reset_index()方法,且保存index,那么需要在schema变量中第一个字段处添加'index'字段及对应类型(下段代码注释内容)
- import pandas as pd
- from pyspark.sql.types import *
- from pyspark.sql import SparkSession
- from pyspark.sql.functions import pandas_udf, PandasUDFType
- spark = SparkSession.builder.appName("demo3").config("spark.some.config.option", "some-value").getOrCreate()
- df3 = spark.createDataFrame(
- [(18862669710, '/未知类型', 'IM传文件', 'QQ接收文件', 39.0, '2018-03-08 21:45:45', 178111558222, 1781115582),
- (18862669710, '/未知类型', 'IM传文件', 'QQ接收文件', 39.0, '2018-03-08 21:45:45', 178111558222, 1781115582),
- (18862228190, '/移动终端', '移动终端应用', '移动腾讯视频', 292.0, '2018-03-08 21:45:45', 178111558212, 1781115582),
- (18862669710, '/未知类型', '访问网站', '搜索引擎', 52.0, '2018-03-08 21:45:46', 178111558222, 1781115582)],
- ('online_account', 'terminal_type', 'action_type', 'app', 'access_seconds', 'datetime', 'outid', 'class'))
- def compute(x):
- result = x[
- ['online_account', 'terminal_type', 'action_type', 'app', 'access_seconds', 'datetime', 'outid', 'class', 'start_time', 'end_time']]
- return result
- schema = StructType([
- # StructField("index", DoubleType()),
- StructField("online_account", LongType()),
- StructField("terminal_type", StringType()),
- StructField("action_type", StringType()),
- StructField("app", StringType()),
- StructField("access_seconds", DoubleType()),
- StructField("datetime", StringType()),
- StructField("outid", LongType()),
- StructField("class", LongType()),
- StructField("end_time", TimestampType()),
- StructField("start_time", TimestampType()),
- ])
- @pandas_udf(schema, functionType=PandasUDFType.GROUPED_MAP)
- def g(df):
- print('ok')
- mid = df.groupby(['online_account']).apply(lambda x: compute(x))
- result = pd.DataFrame(mid)
- # result.reset_index(inplace=True, drop=False)
- # return result
- df3 = df3.withColumn("end_time", df3['datetime'].cast(TimestampType()))
- df3 = df3.withColumn('end_time_convert_seconds', df3['end_time'].cast('long').cast('int'))
- time_diff = df3.end_time_convert_seconds - df3.access_seconds
- df3 = df3.withColumn('start_time', time_diff.cast('int').cast(TimestampType()))
- df3 = df3.drop('end_time_convert_seconds')
- df3.printSchema()
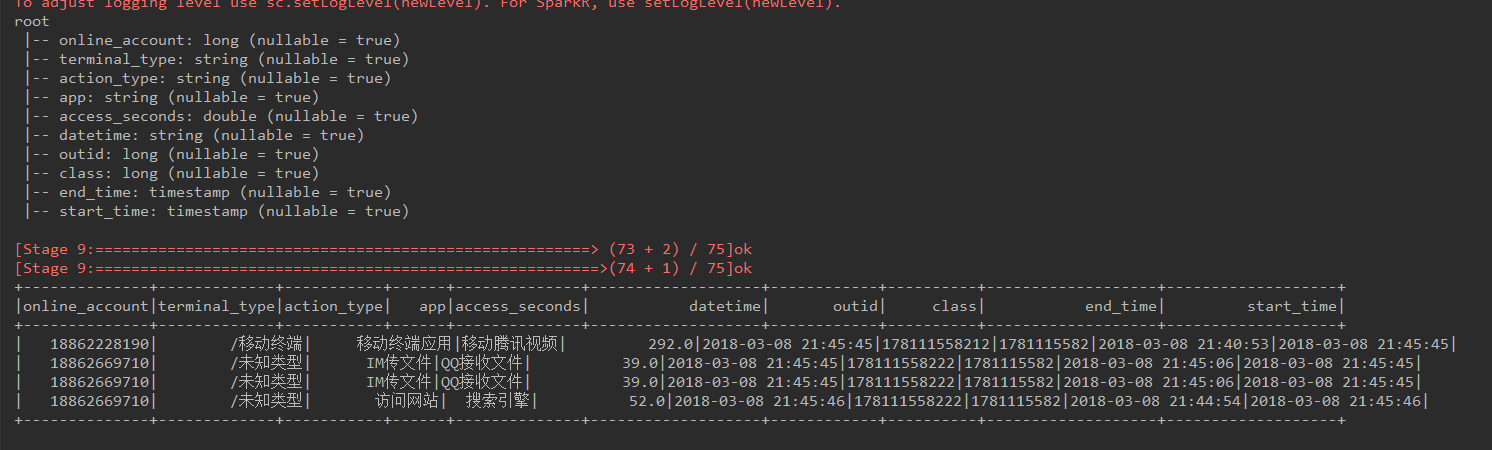
- aa = df3.groupby(['online_account']).apply(g)
- aa.show()
3. 优化Pandas_UDF代码
在上一小节中,我们是通过Spark方法进行特征的处理,然后对处理好的数据应用@pandas_udf装饰器调用自定义函数。但这样看起来有些凌乱,因此可以把这些Spark操作都写入pandas_udf方法中。
注意:上小节中存在一个字段没有正确对应的bug,而pandas_udf方法返回的特征顺序要与schema中的字段顺序保持一致!
- import pandas as pd
- from pyspark.sql.types import *
- from pyspark.sql import SparkSession
- from pyspark.sql.functions import pandas_udf, PandasUDFType
- spark = SparkSession.builder.appName("demo3").config("spark.some.config.option", "some-value").getOrCreate()
- df3 = spark.createDataFrame(
- [(18862669710, '/未知类型', 'IM传文件', 'QQ接收文件', 39.0, '2018-03-08 21:45:45', 178111558222, 1781115582),
- (18862669710, '/未知类型', 'IM传文件', 'QQ接收文件', 39.0, '2018-03-08 21:45:45', 178111558222, 1781115582),
- (18862228190, '/移动终端', '移动终端应用', '移动腾讯视频', 292.0, '2018-03-08 21:45:45', 178111558212, 1781115582),
- (18862669710, '/未知类型', '访问网站', '搜索引擎', 52.0, '2018-03-08 21:45:46', 178111558222, 1781115582)],
- ('online_account', 'terminal_type', 'action_type', 'app', 'access_seconds', 'datetime', 'outid', 'class'))
- def compute(x):
- x['end_time'] = pd.to_datetime(x['datetime'], errors='coerce', format='%Y-%m-%d')
- x['end_time_convert_seconds'] = pd.to_timedelta(x['end_time']).dt.total_seconds().astype(int)
- x['start_time'] = pd.to_datetime(x['end_time_convert_seconds'] - x['access_seconds'], unit='s')
- x = x.sort_values(by=['start_time'], ascending=True)
- result = x[['online_account', 'terminal_type', 'action_type', 'app', 'access_seconds', 'datetime', 'outid', 'class','start_time', 'end_time']]
- return result
- schema = StructType([
- StructField("online_account", LongType()),
- StructField("terminal_type", StringType()),
- StructField("action_type", StringType()),
- StructField("app", StringType()),
- StructField("access_seconds", DoubleType()),
- StructField("datetime", StringType()),
- StructField("outid", LongType()),
- StructField("class", LongType()),
- StructField("start_time", TimestampType()),
- StructField("end_time", TimestampType()),
- ])
- @pandas_udf(schema, functionType=PandasUDFType.GROUPED_MAP)
- def g(df):
- print('ok')
- mid = df.groupby(['online_account']).apply(lambda x: compute(x))
- result = pd.DataFrame(mid)
- return result
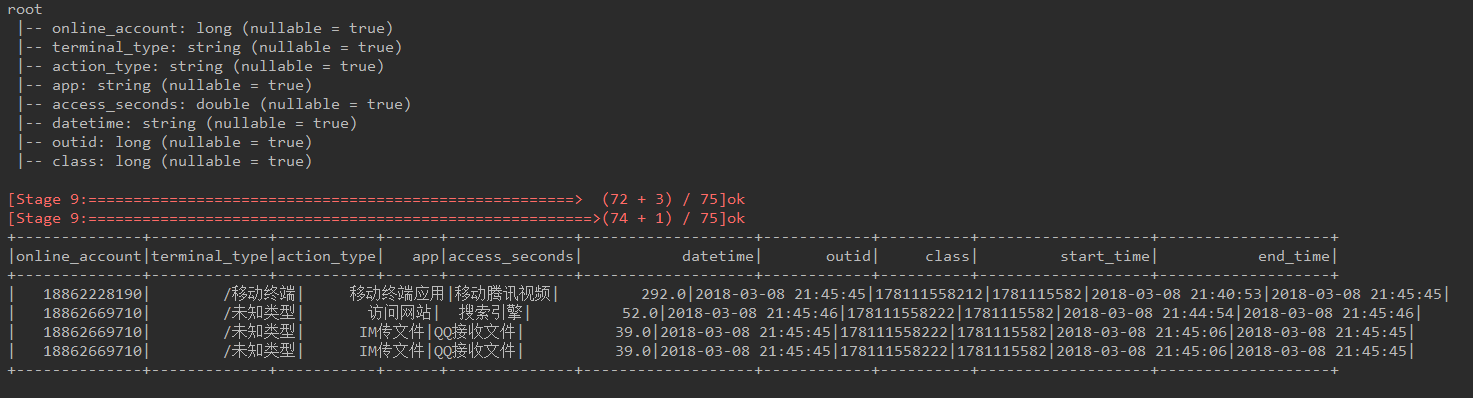
- df3.printSchema()
- aa = df3.groupby(['online_account']).apply(g)
- aa.show()
4. Pandas_UDF与toPandas的区别
- @pandas_udf 创建一个向量化的用户定义函数(UDF),利用了panda的矢量化特性,是udf的一种更快的替代方案,因此适用于分布式数据集。
- toPandas将分布式spark数据集转换为pandas数据集,对pandas数据集进行本地化,并且所有数据都驻留在驱动程序内存中,因此此方法仅在预期生成的pandas DataFrame较小的情况下使用。
换句话说,@pandas_udf使用panda API来处理分布式数据集,而toPandas()将分布式数据集转换为本地数据,然后使用pandas进行处理。
5. 参考文献
[1] PySpark Usage Guide for Pandas with Apache Arrow
[2] pyspark.sql.functions.pandas_udf
使用Pandas_UDF快速改造Pandas代码的更多相关文章
- 快速上手pandas(上)
pandas is a fast, powerful, flexible and easy to use open source data analysis and manipulation to ...
- eclipse快速收缩展开代码
快速折叠所有代码和展开所有代码都是CTRL+SHIFT+/
- Visual Studio使用正则表达式快速统计总共代码行数
原文:Visual Studio使用正则表达式快速统计总共代码行数 按CTRL+SHIFT+F,勾上支持正则表达式,然后输入搜索内容: <span style="font-family ...
- Emmet 快速编写html代码
简介 快速编写HTML代码 语法简单,语法类似css选择器,30分钟内你就可以搞定它.开发商为sublime.atom.brackets.hbuilder.webstrom等编辑器或IDE提供对应的插 ...
- js分析 快速定位 js 代码, 还原被混淆压缩的 js 代码
-1.目录 0.参考 1.页面表现 2. 慢镜头观察:低速网络请求 3. 从头到尾调试:Fiddler 拦截 index.html 并添加 debugger; 4. 快速定位 js 代码 5. 还原被 ...
- VsCode中使用Emmet神器快速编写HTML代码
一.Emmet简述 Emmet (前身为 Zen Coding) 是一个能大幅度提高前端开发效率的一个工具. 在前端开发的过程中,一大部分的工作是写 HTML.CSS 代码.特别是手动编写 HTML ...
- 使用Emmet 快速生成HTML代码
在前端开发的过程中,一个最繁琐的工作就是写 HTML.CSS 代码.数量繁多的标签.属性.尖括号.标签闭合等,让前端们甚是苦恼.于是,我向大家推荐 Emmet,它提供了一套非常简单的语法规则,书写起来 ...
- [UE4]使用UnrealVS扩展快速编译C++代码
一.如果UE4 编辑器已经打开,则VS中的重新生成项目将不能使用,一定要关了UE4 编辑器才可以.一般不是有VS自身的编译UE4的C++代码 二.epic提供了UnrealVS扩展,可以快速编译C++ ...
- eclipse快速复制一行代码(向下/向上)快捷键修改设置
eclipse快速复制一行代码(向下/向上)快捷键修改设置 2015年10月05日 17:46:57 xiaoguanglgc 阅读数:20906 标签: eclipse快速复制一行快捷键冲突英特尔 ...
随机推荐
- Flutter 依赖的那些事儿
Flutter 里面有2种库一样的东西, Package -creating a pure Dart component. like a new Widget. 这种是纯Dart,相当于你自己写的组件 ...
- java代码代替xml实现图片
1.使用StateListDrawable替换selector public static StateListDrawable getSelector(Drawable normalDrawable, ...
- CRM原型
https://files.cnblogs.com/files/wcLT/CRM.zip
- 洗礼灵魂,修炼python(53)--爬虫篇—urllib模块
urllib 1.简介: urllib 模块是python的最基础的爬虫模块,其核心功能就是模仿web浏览器等客户端,去请求相应的资源,并返回一个类文件对象.urllib 支持各种 web 协议,例如 ...
- 关于SQL Server将一列的多行内容拼接成一行,合并显示在另外表中
select '['+title_a+','+title_b +']' from A for xml path('') SELECT *, (select '['+title_a+','+titl ...
- sqlserver 将 “用 特定字符 分隔的一个字段” 拆分成多个字段,然后两个表之间数据更新
将源TXT文件sourceFile_table.txt导入数据库,生成新表dbo.sourceFile_table.新增字段lon.lat.shi.xian 源表dbo.sourceFile_tabl ...
- SVN与Git比较的优缺点差异
目录: SVN与Git比较(一)集中式vs分布式 SVN与Git比较(二)版本库与工作区 SVN与Git比较(三)全局版本号和全球版本号 SVN与Git比较(四)部分检出 SVN与Git比较(五)更新 ...
- 【PAT】B1071 小赌怡情(15 分)
水题一道,直接贴代码 #include<cstdio> #include<string.h> int main(){ //玩家的筹码数.以及 int T,K;scanf(&qu ...
- 【hexo】01安装
什么是 Hexo? Hexo 是一个快速.简洁且高效的博客框架.Hexo 使用 Markdown(或其他渲染引擎)解析文章,在几秒内,即可利用靓丽的主题生成静态网页. 安装前提 安装 Hexo 相当简 ...
- February 3rd, 2018 Week 5th Saturday
Life takes on the meaning that you give it. 你赋予生活什么,生活就是什么样子. I always wonder why on earth I am here ...