Self-Attention与Transformer
直观理解与模型整体结构
先来看一个翻译的例子“I arrived at the bank after crossing the river” 这里面的bank指的是银行还是河岸呢,这就需要我们联系上下文,当我们看到river之后就应该知道这里bank很大概率指的是河岸。在RNN中我们就需要一步步的顺序处理从bank到river的所有词语,而当它们相距较远时RNN的效果常常较差,且由于其顺序性处理效率也较低。Self-Attention则利用了Attention机制,计算每个单词与其他所有单词之间的关联,在这句话里,当翻译bank一词时,river一词就有较高的Attention score。利用这些Attention score就可以得到一个加权的表示,然后再放到一个前馈神经网络中得到新的表示,这一表示很好的考虑到上下文的信息。如下图所示,encoder读入输入数据,利用层层叠加的Self-Attention机制对每一个词得到新的考虑了上下文信息的表征。Decoder也利用类似的Self-Attention机制,但它不仅仅看之前产生的输出的文字,而且还要attend encoder的输出。以上步骤如下动图所示:

Transformer模型的整体结构如下图所示
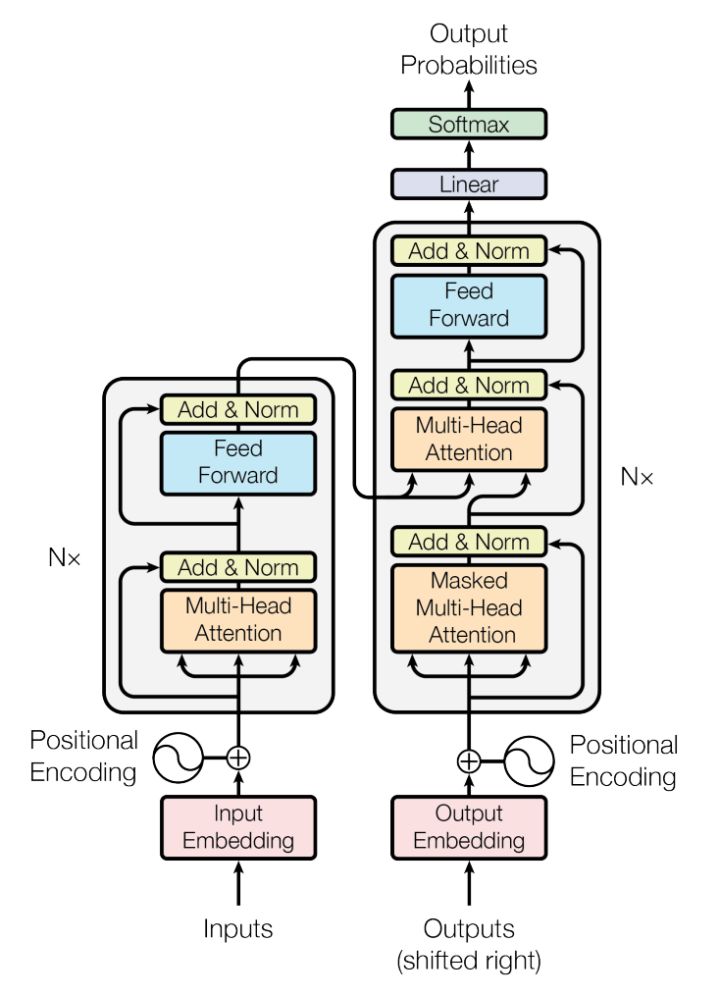
这里面Multi-head Attention其实就是多个Self-Attention结构的结合,每个head学习到在不同表示空间中的特征,如下图所示,两个head学习到的Attention侧重点可能略有不同,这样给了模型更大的容量。

Self-Attention详解
了解了模型大致原理,我们可以详细的看一下究竟Self-Attention结构是怎样的。其基本结构如下

对于self-attention来讲,Q(Query), K(Key), V(Value)三个矩阵均来自同一输入,首先我们要计算Q与K之间的点乘,然后为了防止其结果过大,起到了缩放的作用,会除以一个尺度标度 ,其中
为一个query和key向量的维度。再利用Softmax操作将其结果归一化为概率分布,然后再乘以矩阵V就得到权重求和的表示。该操作可以表示为
假如我们要翻译一个词组Thinking Machines,其中Thinking的输入的embedding vector用 表示,Machines的embedding vector用
表示。
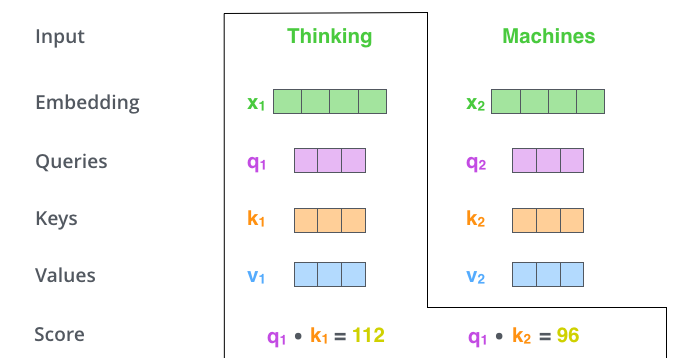
当我们处理Thinking这个词时,我们需要计算句子中所有词与它的Attention Score,这就像将当前词作为搜索的query,去和句子中所有词(包含该词本身)的key去匹配,看看相关度有多高。我们用 代表Thinking对应的query vector,
及
分别代表Thinking以及Machines对应的key vector,则计算Thinking的attention score的时候我们需要计算
与
的点乘,同理,我们计算Machines的attention score的时候需要计算
与
的点乘。如上图中所示我们分别得到了
与
的点乘积,然后我们进行尺度缩放与softmax归一化,如下图所示:
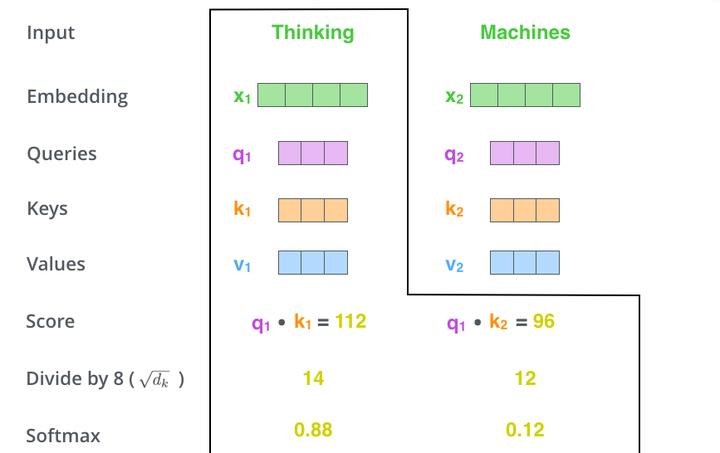
显然,当前单词与其自身的attention score一般最大,其他单词根据与当前单词重要程度有相应的score。然后我们在用这些attention score与value vector相乘,得到加权的向量。
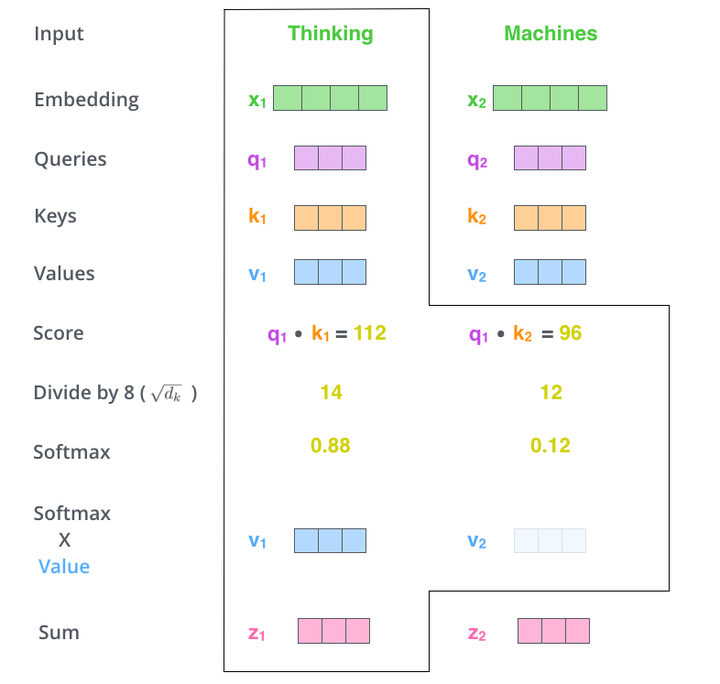
如果将输入的所有向量合并为矩阵形式,则所有query, key, value向量也可以合并为矩阵形式表示
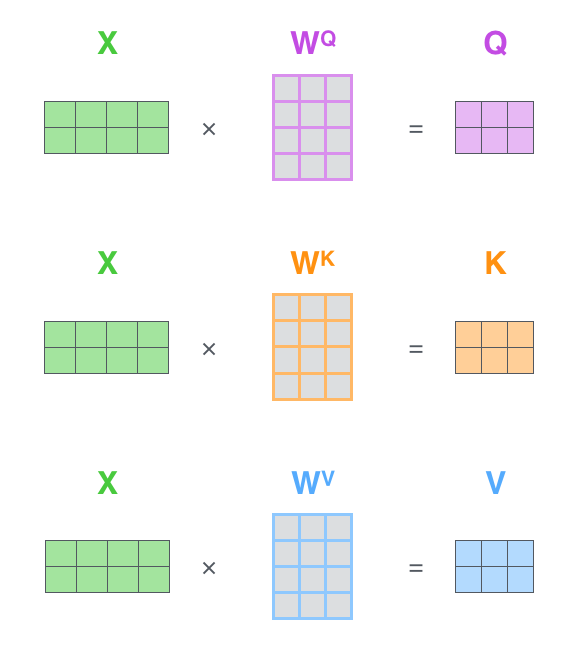
其中 是我们模型训练过程学习到的合适的参数。上述操作即可简化为矩阵形式
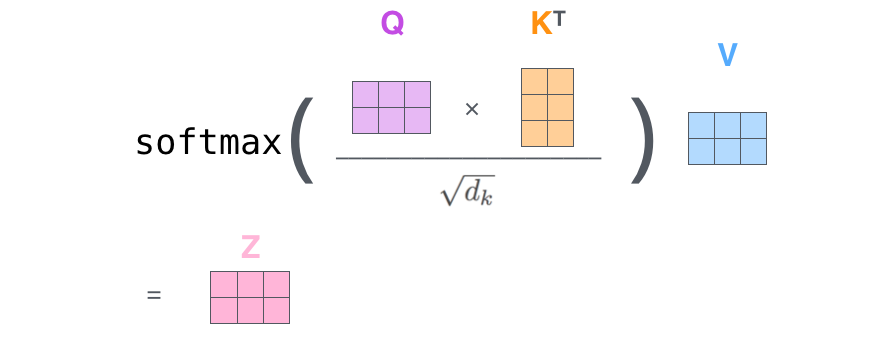
而multihead就是我们可以有不同的Q,K,V表示,最后再将其结果结合起来,如下图所示:
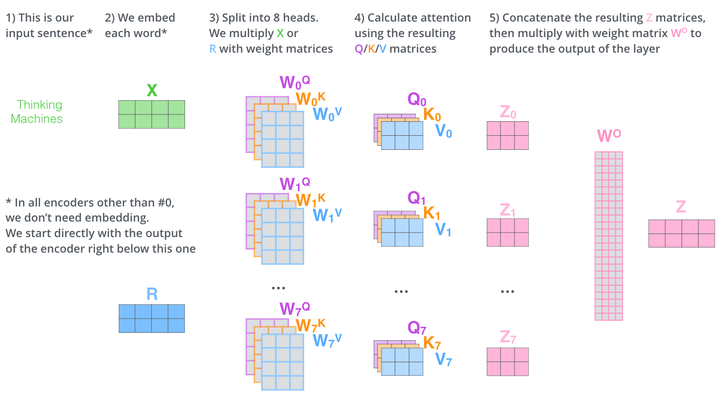
这就是基本的Multihead Attention单元,对于encoder来说就是利用这些基本单元叠加,其中key, query, value均来自前一层encoder的输出,即encoder的每个位置都可以注意到之前一层encoder的所有位置。
对于decoder来讲,我们注意到有两个与encoder不同的地方,一个是第一级的Masked Multi-head,另一个是第二级的Multi-Head Attention不仅接受来自前一级的输出,还要接收encoder的输出,下面分别解释一下是什么原理。
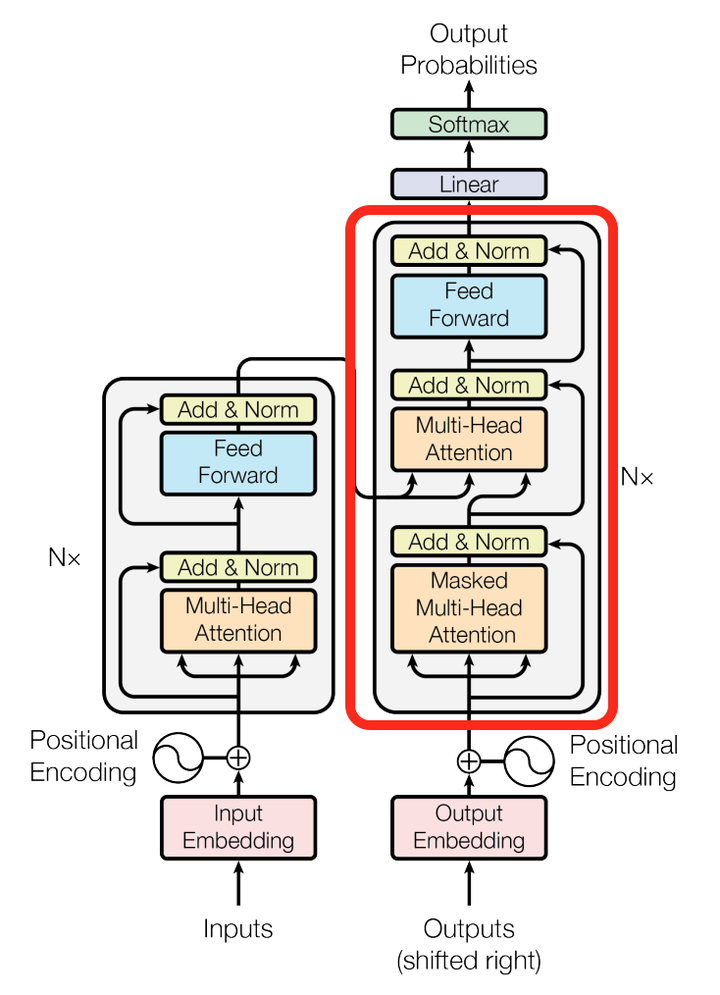
第一级decoder的key, query, value均来自前一层decoder的输出,但加入了Mask操作,即我们只能attend到前面已经翻译过的输出的词语,因为翻译过程我们当前还并不知道下一个输出词语,这是我们之后才会推测到的。
而第二级decoder也被称作encoder-decoder attention layer(类似于seq2seq中的attention),即它的query来自于之前一级的decoder层的输出,但其key和value来自于encoder的输出,这使得decoder的每一个位置都可以attend到输入序列的每一个位置。
总结一下,k和v的来源总是相同的,q在encoder及第一级decoder中与k,v来源相同,在encoder-decoder attention layer中与k,v来源不同。
论文其他细节解读
我们再来看看论文其他方面的细节,一个使position encoding,这个目的是什么呢?注意由于该模型没有recurrence或convolution操作,所以没有明确的关于单词在源句子中位置的相对或绝对的信息,为了更好的让模型学习位置信息,所以添加了position encoding并将其叠加在word embedding上。该论文中选取了三角函数的encoding方式,其他方式也可以。
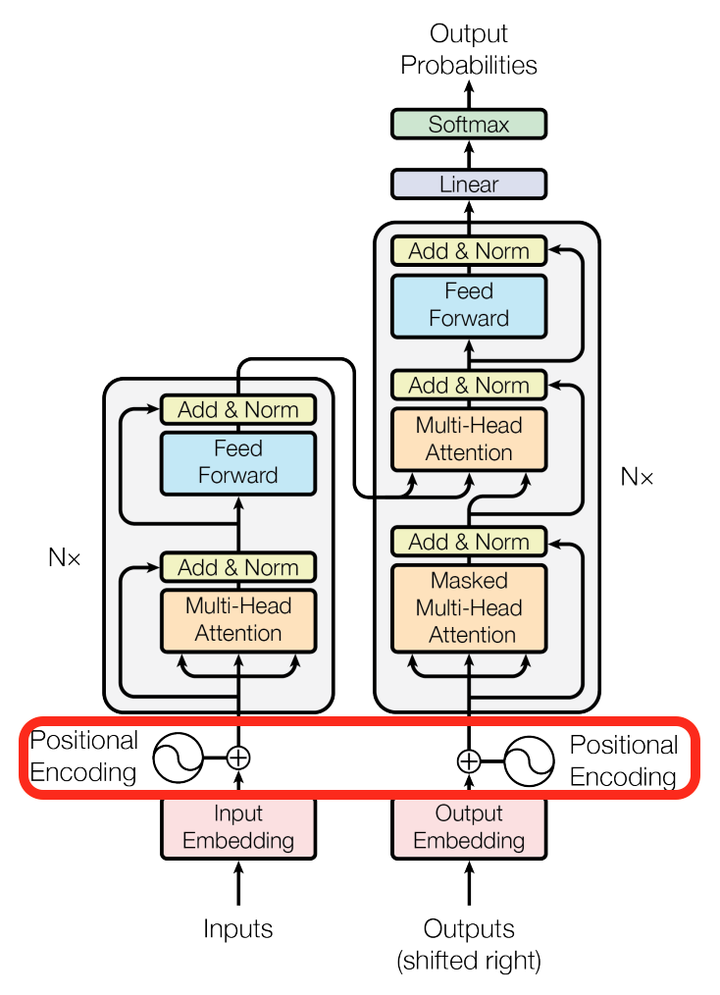
再来看看模型中这些Add & Norm模块的作用。
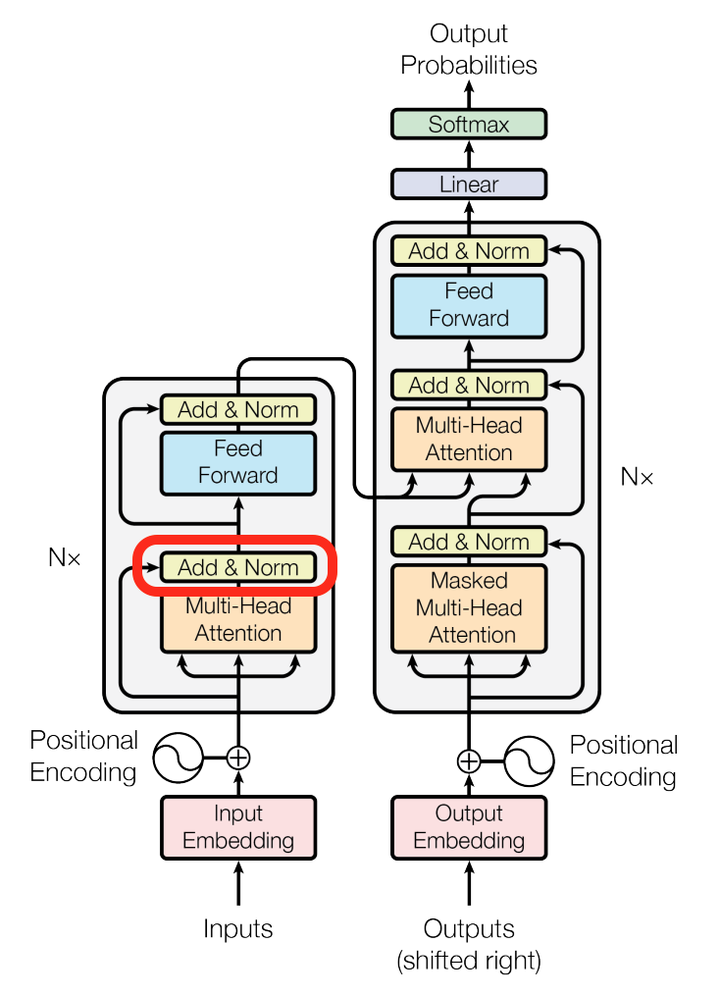
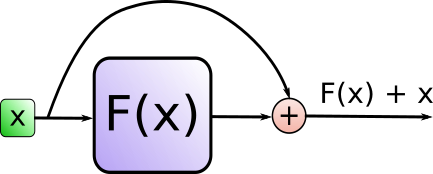
其中Add代表了Residual Connection,是为了解决多层神经网络训练困难的问题,通过将前一层的信息无差的传递到下一层,可以有效的仅关注差异部分,这一方法之前在图像处理结构如ResNet等中常常用到。
而Norm则代表了Layer Normalization,通过对层的激活值的归一化,可以加速模型的训练过程,使其更快的收敛。
Positional Embedding
现在的 Transformer 架构还没有提取序列顺序的信息,这个信息对于序列而言非常重要,如果缺失了这个信息,可能我们的结果就是:所有词语都对了,但是无法组成有意义的语句。
为了解决这个问题。论文使用了 Positional Embedding:对序列中的词语出现的位置进行编码。
在实现的时候使用正余弦函数。公式如下:
其中,pos 是指词语在序列中的位置。可以看出,在偶数位置,使用正弦编码,在奇数位置,使用余弦编码。
从编码公式中可以看出,给定词语的 pos,我们可以把它编码成一个 的向量。也就是说,位置编码的每一个维度对应正弦曲线,波长构成了从
到
的等比数列。
上面的位置编码是绝对位置编码。但是词语的相对位置也非常重要。这就是论文为什么要使用三角函数的原因!
正弦函数能够表达相对位置信息,主要数学依据是以下两个公式:
上面的公式说明,对于词汇之间的位置偏移 k, 可以表示成
和
组合的形式,相当于有了可以表达相对位置的能力。
Self-Attention与Transformer的更多相关文章
- Attention和Transformer详解
目录 Transformer引入 Encoder 详解 输入部分 Embedding 位置嵌入 注意力机制 人类的注意力机制 Attention 计算 多头 Attention 计算 残差及其作用 B ...
- 2. Attention Is All You Need(Transformer)算法原理解析
1. 语言模型 2. Attention Is All You Need(Transformer)算法原理解析 3. ELMo算法原理解析 4. OpenAI GPT算法原理解析 5. BERT算法原 ...
- NLP学习(5)----attention/ self-attention/ seq2seq/ transformer
目录: 1. 前提 2. attention (1)为什么使用attention (2)attention的定义以及四种相似度计算方式 (3)attention类型(scaled dot-produc ...
- [阅读笔记]Attention Is All You Need - Transformer结构
Transformer 本文介绍了Transformer结构, 是一种encoder-decoder, 用来处理序列问题, 常用在NLP相关问题中. 与传统的专门处理序列问题的encoder-deco ...
- Attention & Transformer
Attention & Transformer seq2seq; attention; self-attention; transformer; 1 注意力机制在NLP上的发展 Seq2Seq ...
- RealFormer: 残差式 Attention 层的Transformer 模型
原创作者 | 疯狂的Max 01 背景及动机 Transformer是目前NLP预训练模型的基础模型框架,对Transformer模型结构的改进是当前NLP领域主流的研究方向. Transformer ...
- 对Attention is all you need 的理解
https://blog.csdn.net/mijiaoxiaosan/article/details/73251443 本文参考的原始论文地址:https://arxiv.org/abs/1706. ...
- Paper Reading - Attention Is All You Need ( NIPS 2017 ) ★
Link of the Paper: https://arxiv.org/abs/1706.03762 Motivation: The inherently sequential nature of ...
- [Attention Is All You Need]论文笔记
主流的序列到序列模型都是基于含有encoder和decoder的复杂的循环或者卷积网络.而性能最好的模型在encoder和decoder之间加了attentnion机制.本文提出一种新的网络结构,摒弃 ...
- 【转载】图解Transformer(完整版)!
在学习深度学习过程中很多讲的不够细致,这个讲的真的是透彻了,转载过来的,希望更多人看到(转自-张贤同学-公众号). 前言 本文翻译自 http://jalammar.github.io/illustr ...
随机推荐
- 20155202 2016-2017-2 《Java程序设计》第6周学习总结
20155202 2016-2017-2 <Java程序设计>第6周学习总结 教材学习内容总结 输入输出 数据从来源取出:输入串流 java.io.InputStream 写入目的的:输出 ...
- Scala类型检查与转换
Scala类型检查与转换 isInstanceOf:检查某个对象是否属于某个给定的类. asInstanceOf:将引用转换为子类的引用. classOf:如果想测试p指向的是一个Employee对象 ...
- Get size of all tables in database
http://stackoverflow.com/questions/7892334/get-size-of-all-tables-in-database SELECT t.NAME AS Table ...
- ie下警告console未定义
低版本IE6/7/8/9浏览器没有定义console对象,所以代码会中断执行.自己测试,ie11也没有(打开控制台的情况下可以用) 可以用如下代码完美解决. window.console = wind ...
- Sorted方法排序用法
listA = [3,4,5,3,2,1,] print(sorted(listA)) # [1, 2, 3, 3, 4, 5] listB =["a","z" ...
- 面向对象进阶-类的内置方法 __str__ 、__repr__、__len__、__del__、__call__(三)
# 内置的类方法 和 内置的函数之间有着千丝万缕的联系# 双下方法# obj.__str__ str(obj)# obj.__repr__ repr(obj) # def __str__(self): ...
- 713. Subarray Product Less Than K
Your are given an array of positive integers nums. Count and print the number of (contiguous) subarr ...
- 诸神眷顾的幻想乡(zjoi2015,bzoj3926)(广义后缀自动机)
幽香是全幻想乡里最受人欢迎的萌妹子,这天,是幽香的2600岁生日,无数幽香的粉丝到了幽香家门前的太阳花田上来为幽香庆祝生日. 粉丝们非常热情,自发组织表演了一系列节目给幽香看.幽香当然也非常高兴啦. ...
- tomcat 项目发布方式
1.WEB应用的组成结构 开发web应用时,不同类型的文件有严格的存放规则,否则不仅会使web应用无法访问 还会导致web服务器自动报错. mail:web应用所在目录(该目录自定义) html,js ...
- 牛客第六场 J.Heritage of skywalkert(On求前k大)
题目传送门:https://www.nowcoder.com/acm/contest/144/J 题意:给一个function,构造n个数,求出其中任意两个的lcm的最大值. 分析:要求最大的lcm, ...