lucene源码分析(3)facet实例
简单的facet实例
public class SimpleFacetsExample {
private final Directory indexDir = new RAMDirectory();
private final Directory taxoDir = new RAMDirectory();
private final FacetsConfig config = new FacetsConfig();
/** Empty constructor */
public SimpleFacetsExample() {
config.setHierarchical("Publish Date", true);
}
/** Build the example index. */
private void index() throws IOException {
IndexWriter indexWriter = new IndexWriter(indexDir, new IndexWriterConfig(
new WhitespaceAnalyzer()).setOpenMode(OpenMode.CREATE));
// Writes facet ords to a separate directory from the main index
DirectoryTaxonomyWriter taxoWriter = new DirectoryTaxonomyWriter(taxoDir);
Document doc = new Document();
doc.add(new FacetField("Author", "Bob"));
doc.add(new FacetField("Publish Date", "2010", "10", "15"));
indexWriter.addDocument(config.build(taxoWriter, doc));
doc = new Document();
doc.add(new FacetField("Author", "Lisa"));
doc.add(new FacetField("Publish Date", "2010", "10", "20"));
indexWriter.addDocument(config.build(taxoWriter, doc));
doc = new Document();
doc.add(new FacetField("Author", "Lisa"));
doc.add(new FacetField("Publish Date", "2012", "1", "1"));
indexWriter.addDocument(config.build(taxoWriter, doc));
doc = new Document();
doc.add(new FacetField("Author", "Susan"));
doc.add(new FacetField("Publish Date", "2012", "1", "7"));
indexWriter.addDocument(config.build(taxoWriter, doc));
doc = new Document();
doc.add(new FacetField("Author", "Frank"));
doc.add(new FacetField("Publish Date", "1999", "5", "5"));
indexWriter.addDocument(config.build(taxoWriter, doc));
indexWriter.close();
taxoWriter.close();
}
/** User runs a query and counts facets. */
private List<FacetResult> facetsWithSearch() throws IOException {
DirectoryReader indexReader = DirectoryReader.open(indexDir);
IndexSearcher searcher = new IndexSearcher(indexReader);
TaxonomyReader taxoReader = new DirectoryTaxonomyReader(taxoDir);
FacetsCollector fc = new FacetsCollector();
// MatchAllDocsQuery is for "browsing" (counts facets
// for all non-deleted docs in the index); normally
// you'd use a "normal" query:
FacetsCollector.search(searcher, new MatchAllDocsQuery(), 10, fc);
// Retrieve results
List<FacetResult> results = new ArrayList<>();
// Count both "Publish Date" and "Author" dimensions
Facets facets = new FastTaxonomyFacetCounts(taxoReader, config, fc);
results.add(facets.getTopChildren(10, "Author"));
results.add(facets.getTopChildren(10, "Publish Date"));
indexReader.close();
taxoReader.close();
return results;
}
/** User runs a query and counts facets only without collecting the matching documents.*/
private List<FacetResult> facetsOnly() throws IOException {
DirectoryReader indexReader = DirectoryReader.open(indexDir);
IndexSearcher searcher = new IndexSearcher(indexReader);
TaxonomyReader taxoReader = new DirectoryTaxonomyReader(taxoDir);
FacetsCollector fc = new FacetsCollector();
// MatchAllDocsQuery is for "browsing" (counts facets
// for all non-deleted docs in the index); normally
// you'd use a "normal" query:
searcher.search(new MatchAllDocsQuery(), fc);
// Retrieve results
List<FacetResult> results = new ArrayList<>();
// Count both "Publish Date" and "Author" dimensions
Facets facets = new FastTaxonomyFacetCounts(taxoReader, config, fc);
results.add(facets.getTopChildren(10, "Author"));
results.add(facets.getTopChildren(10, "Publish Date"));
indexReader.close();
taxoReader.close();
return results;
}
/** User drills down on 'Publish Date/2010', and we
* return facets for 'Author' */
private FacetResult drillDown() throws IOException {
DirectoryReader indexReader = DirectoryReader.open(indexDir);
IndexSearcher searcher = new IndexSearcher(indexReader);
TaxonomyReader taxoReader = new DirectoryTaxonomyReader(taxoDir);
// Passing no baseQuery means we drill down on all
// documents ("browse only"):
DrillDownQuery q = new DrillDownQuery(config);
// Now user drills down on Publish Date/2010:
q.add("Publish Date", "2010");
FacetsCollector fc = new FacetsCollector();
FacetsCollector.search(searcher, q, 10, fc);
// Retrieve results
Facets facets = new FastTaxonomyFacetCounts(taxoReader, config, fc);
FacetResult result = facets.getTopChildren(10, "Author");
indexReader.close();
taxoReader.close();
return result;
}
/** User drills down on 'Publish Date/2010', and we
* return facets for both 'Publish Date' and 'Author',
* using DrillSideways. */
private List<FacetResult> drillSideways() throws IOException {
DirectoryReader indexReader = DirectoryReader.open(indexDir);
IndexSearcher searcher = new IndexSearcher(indexReader);
TaxonomyReader taxoReader = new DirectoryTaxonomyReader(taxoDir);
// Passing no baseQuery means we drill down on all
// documents ("browse only"):
DrillDownQuery q = new DrillDownQuery(config);
// Now user drills down on Publish Date/2010:
q.add("Publish Date", "2010");
DrillSideways ds = new DrillSideways(searcher, config, taxoReader);
DrillSidewaysResult result = ds.search(q, 10);
// Retrieve results
List<FacetResult> facets = result.facets.getAllDims(10);
indexReader.close();
taxoReader.close();
return facets;
}
/** Runs the search example. */
public List<FacetResult> runFacetOnly() throws IOException {
index();
return facetsOnly();
}
/** Runs the search example. */
public List<FacetResult> runSearch() throws IOException {
index();
return facetsWithSearch();
}
/** Runs the drill-down example. */
public FacetResult runDrillDown() throws IOException {
index();
return drillDown();
}
/** Runs the drill-sideways example. */
public List<FacetResult> runDrillSideways() throws IOException {
index();
return drillSideways();
}
/** Runs the search and drill-down examples and prints the results. */
public static void main(String[] args) throws Exception {
System.out.println("Facet counting example:");
System.out.println("-----------------------");
SimpleFacetsExample example = new SimpleFacetsExample();
List<FacetResult> results1 = example.runFacetOnly();
System.out.println("Author: " + results1.get(0));
System.out.println("Publish Date: " + results1.get(1));
System.out.println("Facet counting example (combined facets and search):");
System.out.println("-----------------------");
List<FacetResult> results = example.runSearch();
System.out.println("Author: " + results.get(0));
System.out.println("Publish Date: " + results.get(1));
System.out.println("Facet drill-down example (Publish Date/2010):");
System.out.println("---------------------------------------------");
System.out.println("Author: " + example.runDrillDown());
System.out.println("Facet drill-sideways example (Publish Date/2010):");
System.out.println("---------------------------------------------");
for(FacetResult result : example.runDrillSideways()) {
System.out.println(result);
}
}
}
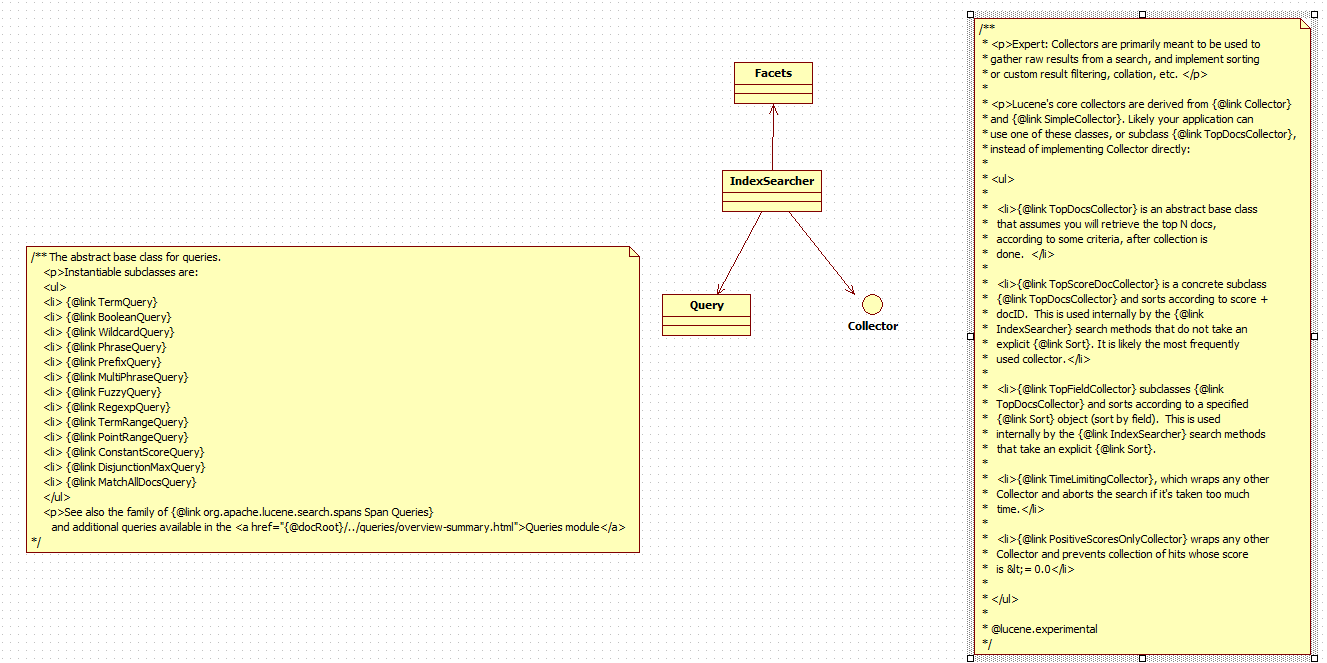
查询及其关系
查询
/** Lower-level search API.
*
* <p>{@link LeafCollector#collect(int)} is called for every matching document.
*
* @throws BooleanQuery.TooManyClauses If a query would exceed
* {@link BooleanQuery#getMaxClauseCount()} clauses.
*/
public void search(Query query, Collector results)
throws IOException {
query = rewrite(query);
search(leafContexts, createWeight(query, results.needsScores(), 1), results);
}
关系
lucene源码分析(3)facet实例的更多相关文章
- Lucene 源码分析之倒排索引(三)
上文找到了 collect(-) 方法,其形参就是匹配的文档 Id,根据代码上下文,其中 doc 是由 iterator.nextDoc() 获得的,那 DefaultBulkScorer.itera ...
- 一个lucene源码分析的博客
ITpub上的一个lucene源码分析的博客,写的比较全面:http://blog.itpub.net/28624388/cid-93356-list-1/
- Vue源码分析(二) : Vue实例挂载
Vue源码分析(二) : Vue实例挂载 author: @TiffanysBear 实例挂载主要是 $mount 方法的实现,在 src/platforms/web/entry-runtime-wi ...
- JVM源码分析-类加载场景实例分析
A类调用B类的静态方法,除了加载B类,但是B类的一个未被调用的方法间接使用到的C类却也被加载了,这个有意思的场景来自一个提问:方法中使用的类型为何在未调用时尝试加载?. 场景如下: public cl ...
- HashMap源码分析和应用实例的介绍
1.HashMap介绍 HashMap 是一个散列表,它存储的内容是键值对(key-value)映射.HashMap 继承于AbstractMap,实现了Map.Cloneable.java.io.S ...
- Stack的源码分析和应用实例
1.Stack介绍 Stack是栈.它的特性是:先进后出(FILO:First In Last Out). java工具包中的Stack是继承于Vector(矢量队列)的,由于Vector是通过数组实 ...
- lucene源码分析的一些资料
针对lucene6.1较新的分析:http://46aae4d1e2371e4aa769798941cef698.devproxy.yunshipei.com/conansonic/article/d ...
- lucene源码分析(1)基本要素
1.源码包 core: Lucene core library analyzers-common: Analyzers for indexing content in different langua ...
- mybatis源码分析(1)——SqlSessionFactory实例的产生过程
在使用mybatis框架时,第一步就需要产生SqlSessionFactory类的实例(相当于是产生连接池),通过调用SqlSessionFactoryBuilder类的实例的build方法来完成.下 ...
随机推荐
- cxgrid动态显示行号
uses cxLookAndFeelPainters; type TMyCxGrid = class(TObject) class procedure DrawIndicatorCell( ...
- jQuery中的AJAX的使用
1.运用ajax()方法,比其它如load().get().post()全局性函数它更多地关注实现过程中的细节:首先要了解其参数列表: url: 要求为String类型的参数,(默认为当前页地址)发送 ...
- ASP.NET Core使用EPPlus操作Excel
1.前言 本篇文章通过ASP.NET Core的EPPlus包去操作Excel(导入导出),其使用原理与NPOI类似,导出Excel的时候不需要电脑上安装office,非常好用 2.使用 新建一个AS ...
- JAVA 从头开始<三>
一.数据类型转换 取反:1变0,0变1 强转 Insteger.toBinaryString(-7); 下面这样写会出错,要用l来接收 为什么byte b 可以接收int类型(而不是10b),大数据类 ...
- CentOS 7 - 安装Eclipse
注意问题:Eclipse官方网站提供的tar文件有可能有问题,我今天下载的一个tar文件,在Windows下解压缩,随后放到CentOS 7里面不行,随后我又重新下载一份,还是不行,最终我下载了另外一 ...
- 940. Distinct Subsequences II
Given a string S, count the number of distinct, non-empty subsequences of S . Since the result may b ...
- webpack快速入门——插件配置:HTML文件的发布
1.把dist中的index.html复制到src目录中,并去掉我们引入的js 2.在webpack.config.js中引入 const htmlPlugin = require('html-web ...
- ubuntu14.0 安装 node v8.11.1(任意版本)
由于众所周知的原因,通过node官网下载速度十分慢,我这里通过淘宝镜像安装 node8.11.1,其他版本同理. node版本淘宝镜像地址:https://npm.taobao.org/mirrors ...
- Jmeter监控系统等资源,ServerAgent端口的本次启动端口修改
默认情况下在下载的ServerAgent下,如果服务是windows系统,则直接启动"startAgent.bat"即可,如果是Linux系统,则直接启动"./start ...
- php的GC机制
在php5.3版本之前, php变量的回收机制只是简单的通过计数来处理(当refcount=0时,会回收内存),但这样会出现一个问题 $a=array("str"); $a[]=& ...