配置好Nginx后,通过flume收集日志到hdfs(记得生成本地log时,不要生成一个文件,)
生成本地log最好生成多个文件放在一个文件夹里,特别多的时候一个小时一个文件
配置好Nginx后,通过flume收集日志到hdfs
可参考flume的文件
执行的注意点


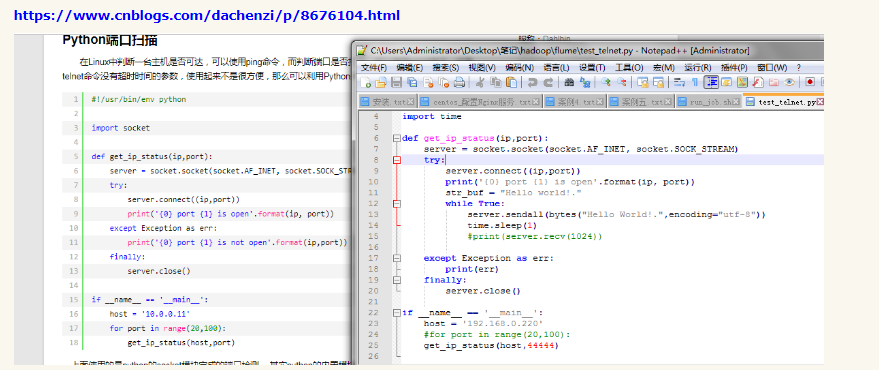


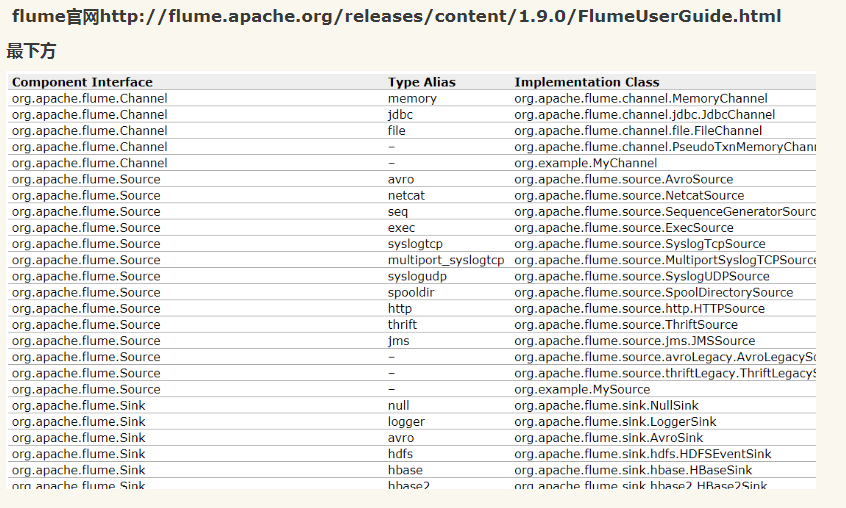
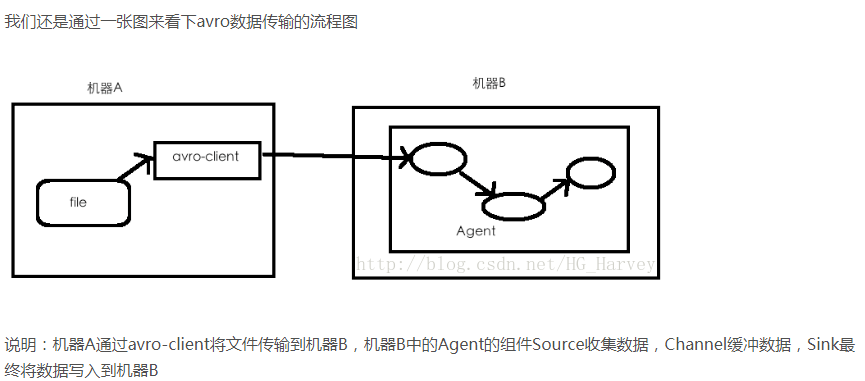
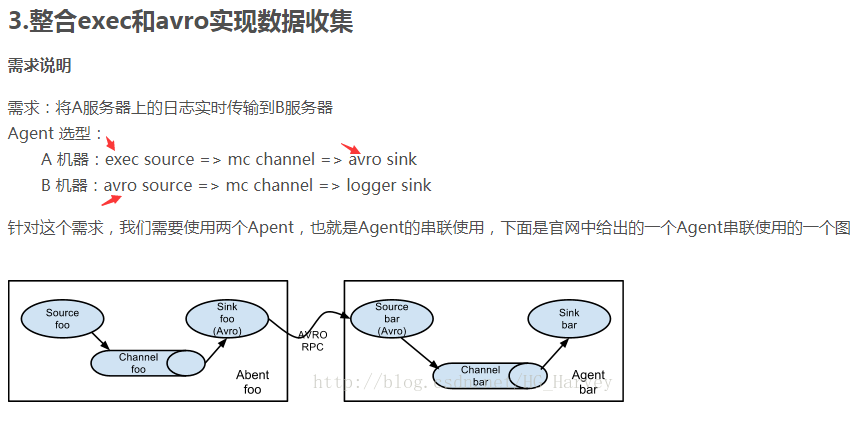
avro和exec联合用法
https://blog.csdn.net/HG_Harvey/article/details/78358304
exec实质是收集文件

spool用法
https://blog.csdn.net/a_drjiaoda/article/details/84954593


或者下面这个代码
名字为
conf/job/project/flume-hdfs.conf
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/data/access.log
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://master:9000/project/log/%Y%m%d
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.rollSize = 10240000
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.callTimeout = 60000
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.idleTimeout = 10
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动hdfs的前提下
start-all.sh
执行
flume-ng agent --conf conf/ --name a1 --conf-file conf/job/project/flume-hdfs.conf
配置好Nginx后,通过flume收集日志到hdfs(记得生成本地log时,不要生成一个文件,)的更多相关文章
- flume收集日志直接sink到oracle数据库
因为项目需求,需要保存项目日志.项目的并发量不大,所以这里直接通过flume保存到oracle 源码地址:https://github.com/jaxlove/fks/tree/master/src/ ...
- 现象:当指定logback的FileNamePattern为日期2020-01-15后,如果有线程不断的往里写log,过了零点文件不会变成下一日2020-01-16,还是会在2020-01-15里继续写 结论:写log的线程不停,文件不会按日子更换。
logback版本:1.1.11 这个是我实验验证的,昨天我配置了一个logback,然后用两个线程不断往里写log,结果发现到了今天2020-01-16日,log文件还是昨天的logbackCfg. ...
- nginx日志切割并使用flume-ng收集日志
nginx的日志文件没有rotate功能.如果你不处理,日志文件将变得越来越大,还好我们可以写一个nginx日志切割脚本来自动切割日志文件.第一步就是重命名日志文件,不用担心重命名后nginx找不到日 ...
- EMQ配置通过nginx反向代理wss和ws
参考:https://www.cnblogs.com/succour/p/6305574.html EMQ官方文档:https://docs.emqx.io/broker/v3/cn/ 一,系统环境及 ...
- nginx 多域名配置 (nginx如何绑定多个域名)
nginx绑定多个域名可又把多个域名规则写一个配置文件里,也可又分别建立多个域名配置文件,我一般为了管理方便,每个域名建一个文件,有些同类域名也可又写在一个总的配置文件里. 一.每个域名一个 ...
- Nginx+Flume+Hadoop日志分析,Ngram+AutoComplete
配置Nginx yum install nginx (在host99和host101) service nginx start开启服务 ps -ef |grep nginx看一下进程 ps -ef | ...
- ELK安装配置及nginx日志分析
一.ELK简介1.组成ELK是Elasticsearch.Logstash.Kibana三个开源软件的组合.在实时数据检索和分析场合,三者通常是配合使用,而且又都先后归于 Elastic.co 公司名 ...
- Flume分布式日志收集系统
1.flume是分布式的日志收集系统,把收集来的数据传送到目的地去.2.flume里面有个核心概念,叫做agent.agent是一个java进程,运行在日志收集节点.通过agent接收日志,然后暂存起 ...
- 基于Flume的日志收集系统方案参考
前言 本文将简单介绍两种基于Flume的日志收集系统可能的架构方案,可根据不同的实际场景参考使用. 方案一 示例图如下: 说明: 每个日志源(http上报.日志文件等)对应一个Agent-c用于收集对 ...
随机推荐
- list接口如何使用
1集合类,在java语言中的java.util包提供了一些集合类,这些集合类又被称作容器. 2区别集合类和数组.(1)数组的长度是固定的,集合的长度是可变的.(2)数组是用来存放基本数据类型的,集合是 ...
- JSP复习(part 3 )
3.4.4 request对象提供了一些用来获取客户信息的方法,利用这些方法,可以获取客户端的IP地址 协议等有关信息 3.5 request对象和response对象相对应,用于响应客户请求,由服务 ...
- Ansible playbooks
Playbook是Ansible的配置,部署和编排语言. 他们可以描述您希望远程系统执行的策略,或一般IT流程中的一组步骤. 如果Ansible modules是您workshop的工具,则playb ...
- conductor APIs
任务和工作流元数据 端点 描述 输入 GET /metadata/taskdefs 获取所有任务定义 N / A GET /metadata/taskdefs/{taskType} 检索任务定义 任务 ...
- 123. Best Time to Buy and Sell Stock III (Array; DP)
Say you have an array for which the ith element is the price of a given stock on day i. Design an al ...
- Js语言的奇怪特性
var a = .3 - 2; console.log(a); a = 0.099999998 而不是0.1,是不是很奇怪?
- 实现Quartz的动态增删改查
1. Maven依赖 <dependency> <groupId>org.quartz-scheduler</groupId> <artifactId> ...
- 7-找了一上午的BUG
#include <iostream>#include <cstring>#include <algorithm>#define MAX 1<<28;u ...
- 5-分西瓜差最小(背包 || dfs)
/* zb立刻下定决心买了一堆西瓜.当他准备把西瓜送给C小加和never的时候,遇到了一个难题,never和C小加不在一块住,只能把西瓜分成两堆给他们,为了对每个人都公平,他想让两堆的重量之差最小 ...
- php下的原生ajax请求
浏览器中为我们提供了一个JS对象XMLHttpRequet,它可以帮助我们发送HTTP请求,并接受服务端的响应. 意味着我们的浏览器不提交,通过JS就可以请求服务器. ajax(Asynchron ...