Java之集合(二十一)LinkedTransferQueue
转载请注明源出处:http://www.cnblogs.com/lighten/p/7505355.html
1.前言
本章介绍无界的阻塞队列LinkedTransferQueue,JDK7才提供了这个类,所以这个类具备了一些一般队列不具有的特性。此队列也是基于链表的,对于所有给定的生产者都是先入先出的。注意,该队列的size方法和ConcurrentLinkedQueue一样不是常量时间。由于队列的实现,其需要遍历队列才能计算出队列的大小,这期间队列发生的改变,遍历的结果会不正确。bulk操作并不保证原子性,比如迭代器迭代的时候执行addAll()方法,迭代器可能只能看到部分新加的元素。
2.LinkedTransferQueue
2.1 TransferQueue接口
这个是JDK7才定义的一个节点,LinkedTransferQueue实现了这个接口,其新特性也就与之有关。通常阻塞队里中,生产者放入元素,消费者使用元素,这两个部分是分离的。这里的分离意思如下:厨师做好了菜放在柜台上,服务员端走,厨师是不需要管有没有人取走做的菜,服务员也不需要管厨师有没有做好菜,没做好菜阻塞就行了。上面就是个人所说的分离的意思。TransferQueue接口定义的相关内容就是厨师会知道做好的菜有没有被取走。

1.tryTransfer(E):将元素立刻给消费者。准确的说就是立刻给一个等待接收元素的线程,如果没有消费者就会返回false,而不将元素放入队列。
2.transfer(E):将元素给消费者,如果没有消费者就会等待。
3.tryTransfer(E,long,TimeUnit):将元素立刻给消费者,如果没有就等待指定时间。给失败返回false。
4.hasWaitingConsumer():返回当前是否有消费者在等待元素。
5.getWaitingConsumerCount():返回等待元素的消费者个数。
2.2 设计原理
Dual Queues是该队列的基础理论。此队列不进存放数据节点,也会存放请求节点。当一个线程试图放入一个数据节点,正好遇到一个请求数据的结点,会立刻匹配并移除该数据节点,对于请求节点入队列也是一样的。Blocking Dual Queues阻塞所有未匹配的线程,直到有匹配的线程出现。
一个先入先出的dual queue实现是无锁队列算法M&S的变体。其包含两个指向字段:head指向一个匹配的结点,然后依次指向未匹配的结点,如果不为空。tail指向最后一个节点,或者null,如果队列为空。例如下图是一个包含四个元素的队列结构:
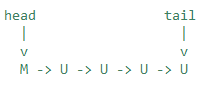
M&S算法易于扩展和保持(通过CAS)这些头部和尾指针。在dual队列中,节点需要自动维护匹配状态。所以这里需要一些必要的变量:对于数据模式,匹配需要将一个item字段通过CAS从非null的数据转成null,反之对于请求模式,需要从null变成data。一旦一个节点匹配了,其状态将不再改变。因此通常安排元素链表的前缀是0个或多个匹配节点,而后跟随0个或多个未匹配节点。如果不关心时间或空间的效率,通过从头指针开始遍历队列放入取出操作都是对的。CAS操作第一个未匹配节点匹配时的item,在下一个字段追加后一个节点。然而这是一个糟糕的想法,虽然其确实有好处,不需对head或tail进行原子更新。
LinkedTransferQueue采取了一种折中的方案,介于实时更新head/tail和不更新head/tail之间的方法。该方法对有时候需要额外的遍历去定位第一个或最后一个未匹配的结点和减少开销及队列结点的竞争更新这两个方面进行了权衡。例如,一个可能出现的队列快照如下图:

slack(head位置和第一个未匹配的结点的最大距离,尾结点类似)的最佳值是一个经验问题,发现在1~3之间在大部分平台是最佳的值。更大的值会增加内存命中开销和长遍历链表的风险,更小的值则会增加CAS的竞争开销。
具体实现:使用一个基础的threshold来更新,slack为2。所以在当前位置超过第一个或最后一个节点2个距离以上的时候就会更新head/tail。出入队列操作都是通过xfer方法完成的,只需要不同的参数来表示操作。
其它的内容通过代码详细介绍。
2.3 数据结构

上图是一个基本的数据结构:
MP表示是否是多核处理器;
FRONT_SPINS当一个节点目前是队列的第一个等待者,在多核处理器上自旋的次数2n。
CHAINED_SPINS当一个节点先于另一个明显自旋的结点阻塞时自旋的次数。

上图是Node节点的基本结构,next就是下一个节点了,isData表示是请求还是数据节点,另外两个字段就是对应不同模式要存储的值了。Node的基本操作如下:
casNext:CAS更新当前结点next的字段
casItem:CAS更新当前结点的item字段
forgetNext:CAS设置当前结点的next字段为自身
forgetContents:CAS设置item字段为自身,waiter为null
isMatched:是否是匹配了的结点
isUnmatchedRequest:是否是未匹配的请求节点
cannotPrecede:当该节点是未匹配节点却与当前的结点类型不符的时候,返回true。意思就是当前都是请求节点,数据节点应该立刻被消耗,未匹配的结点应该是同一种节点。
tryMatchData:数据节点尝试匹配
2.4 基本操作
存入一个元素:该队列的put、offer和offer(E,timeout,unit)方法所调用的都是同一个方法。


不允许放入的数据为空,放入操作的模式是ASYNC。从头指针处开始死循环,当前结点p没有被匹配,数据节点不能匹配直接跳出循环,不进行匹配,后面会进入how!=NOW的判断,创建新节点,尝试追加到队列尾。如果可以匹配就替换P节点的值,失败意味着被其它线程抢先了,继续循环,成功了意味着这两个匹配成功,可能需要更新头结点。q=p且p!=h的循环意味着已经跳过了一个元素,n又取了q.next,p又是当前被匹配了的结点,这就意味着前面有2个match的结点:head和p。达到slack为2的条件,更新头结点,并遗弃之前的head。不需要更新头结点的时候直接跳出循环。匹配完成之后就是唤醒p结点的waiter(如果p是请求节点的话)返回item。

队列尾追加节点操作如上图,从尾结点开始,
如果当前结点p为null,头结点也是null,初始化队列,设置头结点,返回s追加节点。
如果该节点不能放入队列,返回null。
如果p.next不为空,意味着当前结点不是尾结点,重新找到尾结点,继续循环。
如果p节点在设置的时候被插队了,继续找其下一个循环
如果成功了,p!=t,且tail也不等于t。意味着有尾结点后面又追加了2个节点,slack>=2更新尾结点。返回p节点。

取出都是消费者data为null,poll的模式是NOW,有时间限制就是TIMED,take方法使用的是SYNC。回到xfer方法,我们可以知道:其先找到第一个未匹配的元素进行匹配,匹配了不管什么模式都是直接返回,没匹配就要根据模式来了,先是how!=NOW才会有额外操作,所以poll取出就是NOW,取不到那就是没准备好,直接返回就可以了。其它三种模式没匹配到都会尝试追加该节点,没追加上肯定是模式不匹配,意味着可以匹配的,重新循环。如果不是ASYNC模式,那就是带有时间或异步的模式,需要等待。
以上就是整个类的设计思路了,分成四种模式:NOW就是立刻返回不追加元素到末尾,ASYNC就是同步需要添加元素到队列尾,TIMED用于有时间限制的操作,SYNC用于无时间限制无限等待的操作。awaitMatch方法不再进行介绍,就是等到指定时间。size方法和getWaitingConsumerCount方法都是遍历链表,超过Integer.MAX_VALUE就返回这个值,区别就是该链表是处于什么模式而已。其它的方法不再描述,上面是基本的操作。
3.使用例子
@Test
public void testTransfer() {
LinkedTransferQueue<Integer> queue = new LinkedTransferQueue<>();
new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(500); // 再改成1500
System.out.println(Thread.currentThread().getName()+"-"+queue.take());
System.out.println(Thread.currentThread().getName()+"-"+queue.take());
System.out.println(Thread.currentThread().getName()+"-"+queue.take());
} catch (InterruptedException e1) {
e1.printStackTrace();
}
}
},"consumer").start();
new Thread(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"-"+queue.tryTransfer(1));
try {
System.out.println(Thread.currentThread().getName()+"-等待2被消耗:"+queue.tryTransfer(2, 1, TimeUnit.SECONDS));
queue.transfer(3);
System.out.println(Thread.currentThread().getName()+"-"+"等到3被消费:true");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},"prodcuer").start();
try {
System.in.read();
} catch (IOException e) {
e.printStackTrace();
}
}

更改1500毫秒之后:

Java之集合(二十一)LinkedTransferQueue的更多相关文章
- Java设计模式(二十一):职责链模式
职责链模式(Chain Of Responsibility Pattern) 职责链模式(Chain Of Responsibility Pattern):属于对象的行为模式.使多个对象都有机会处理请 ...
- Java从零开始学二十一(集合List接口)
一.List接口 List是Collection的子接口,里面可以保存各个重复的内容,此接口的定义如下: public interface List<E> extends Collecti ...
- Java基础(二十一)集合(3)List集合
一.List接口 List集合为列表类型,列表的主要特征是以线性方式存储对象. 1.实例化List集合 List接口的常用实现类有ArrayList和LinkedList,根据实际需要可以使用两种方式 ...
- Java并发(二十一):线程池实现原理
一.总览 线程池类ThreadPoolExecutor的相关类需要先了解: (图片来自:https://javadoop.com/post/java-thread-pool#%E6%80%BB%E8% ...
- Java进阶专题(二十一) 消息中间件架构体系(3)-- Kafka研究
前言 Kafka 是一款分布式消息发布和订阅系统,具有高性能.高吞吐量的特点而被广泛应用与大数据传输场景.它是由 LinkedIn 公司开发,使用 Scala 语言编写,之后成为 Apache 基金会 ...
- Java笔记(二十一) 动态代理
动态代理 一.静态代理 代理的背后一般至少有一个实际对象,代理的外部功能和实际对象一般是一样的, 用户与代理打交道,不直接接触实际对象.代理存在的价值: 1)节省成本比较高的实际对象创建开销,按需延迟 ...
- Java之集合(二十六)ConcurrentSkipListMap
转载请注明源出处:http://www.cnblogs.com/lighten/p/7542578.html 1.前言 一个可伸缩的并发实现,这个map实现了排序功能,默认使用的是对象自身的compa ...
- Java之集合(二十三)SynchronousQueue
转载请注明源出处:http://www.cnblogs.com/lighten/p/7515729.html 1.前言 本章介绍阻塞队列SynchronousQueue.之前介绍过LinkedTran ...
- Java之集合(二)ArrayDeque
转载请注明源出处:http://www.cnblogs.com/lighten/p/7283928.html 1.前言 上章讲解了Java中的集合接口和相关实现抽象类,本章开始介绍一些具体的实现类,第 ...
随机推荐
- MAC安装远程工具Securecrt的破解方式(详细有图)
想要实现mac的远程连接功能,本来想使用终端的,但是终端的很多功能是欠佳的,所以决定安装一款,像windows的xshell一样好的软件,所以选择了这款Securecrt. 首先准备两个东西,一个是S ...
- Python 字典(Dictionary) keys()方法
Python 字典(Dictionary) keys() 函数以列表返回一个字典所有的键. 语法 keys()方法语法: dict.keys() 参数 NA. 返回值 返回一个字典所有的键. 实例 以 ...
- (dp)Tickets --HDU --1260
链接: http://acm.hdu.edu.cn/showproblem.php?pid=1260 http://acm.hust.edu.cn/vjudge/contest/view.action ...
- 20155320 2016-2017-2 《Java程序设计》第五周学习总结
20155320 2016-2017-2 <Java程序设计>第五周学习总结 教材学习内容总结 错误处理 java中所有错误都会被打包为对象,可以通过try catch 代表错误的对象后做 ...
- noip第9课作业
1. 打印乘法表 [问题描述] 用for循环实现输出1至9的乘法表 [样例输出] 1*1=1 1*2=2 2*2=4 1*3=3 2*3=6 3*3=9 1*4=4 2*4=8 3*4=12 4 ...
- 使用jetty-maven-plugin运行maven多项目
1.准备工作 org.eclipse.jetty jetty-maven-plugin 9.2.11.v20150529 jdk 1.7 maven 3.1 2.采用maven管理多项目 ...
- 权限管理系统系列之WCF通信
目录 权限管理系统系列之序言 首先说下题外话,有些园友看了前一篇[权限管理系统系列之序言]博客加了QQ群(186841119),看了我写的权限管理系统的相关文档(主要是介绍已经开发的功能),给出了一 ...
- RandomForest in Spark MLLib
决策树类模型 ml中的classification和regression主要基于以下几类: classification:决策树及其相关的集成算法,Logistics回归,多层感知模型: regres ...
- linux系统编程之管道(二):管道读写规则
一,管道读写规则 当没有数据可读时 O_NONBLOCK disable:read调用阻塞,即进程暂停执行,一直等到有数据来到为止. O_NONBLOCK enable:read调用返回-1,errn ...
- MVC下使用Areas
(一) 为什么要分离 MVC项目各部分职责比较清晰,相比较ASP.NET Webform而言,MVC项目的业务逻辑和页面展现较好地分离开来,这样的做法有许多优点,比如可测试,易扩展等等.但是在实际的开 ...