自定义排序及Hadoop序列化
自定义排序
将两列数据进行排序,第一列按照升序排列,当第一列相同时,第二列升序排列。
在map和reduce阶段进行排序时,比较的是k2。v2是不参与排序比较的。如果要想让v2也进行排序,需要把k2和v2组装成新的类,作为k2,才能参与比较。
package sort; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.net.URI; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner; public class SortApp {
static final String INPUT_PATH = "hdfs://chaoren:9000/input";
static final String OUT_PATH = "hdfs://chaoren:9000/out"; public static void main(String[] args) throws Exception {
final Configuration configuration = new Configuration(); final FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH),
configuration);
if (fileSystem.exists(new Path(OUT_PATH))) {
fileSystem.delete(new Path(OUT_PATH), true);
} final Job job = new Job(configuration, SortApp.class.getSimpleName()); // 1.1 指定输入文件路径
FileInputFormat.setInputPaths(job, INPUT_PATH);
// 指定哪个类用来格式化输入文件
job.setInputFormatClass(TextInputFormat.class); // 1.2指定自定义的Mapper类
job.setMapperClass(MyMapper.class);
// 指定输出<k2,v2>的类型
job.setMapOutputKeyClass(NewK2.class);
job.setMapOutputValueClass(LongWritable.class); // 1.3 指定分区类
job.setPartitionerClass(HashPartitioner.class);
job.setNumReduceTasks(1); // 1.4 TODO 排序、分区 // 1.5 TODO (可选)合并 // 2.2 指定自定义的reduce类
job.setReducerClass(MyReducer.class);
// 指定输出<k3,v3>的类型
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(LongWritable.class); // 2.3 指定输出到哪里
FileOutputFormat.setOutputPath(job, new Path(OUT_PATH));
// 设定输出文件的格式化类
job.setOutputFormatClass(TextOutputFormat.class); // 把代码提交给JobTracker执行
job.waitForCompletion(true);
} static class MyMapper extends
Mapper<LongWritable, Text, NewK2, LongWritable> {
protected void map(
LongWritable key,
Text value,
org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, NewK2, LongWritable>.Context context)
throws java.io.IOException, InterruptedException {
final String[] splited = value.toString().split("\t");
final NewK2 k2 = new NewK2(Long.parseLong(splited[0]),
Long.parseLong(splited[1]));
final LongWritable v2 = new LongWritable(Long.parseLong(splited[1]));
context.write(k2, v2);
};
} static class MyReducer extends
Reducer<NewK2, LongWritable, LongWritable, LongWritable> {
protected void reduce(
NewK2 k2,
java.lang.Iterable<LongWritable> v2s,
org.apache.hadoop.mapreduce.Reducer<NewK2, LongWritable, LongWritable, LongWritable>.Context context)
throws java.io.IOException, InterruptedException {
context.write(new LongWritable(k2.first), new LongWritable(
k2.second));
};
} /**
* 问:为什么实现该类? 答:因为原来的v2不能参与排序,把原来的k2和v2封装到一个类中,作为新的k2
*
*/
// WritableComparable:Hadoop的序列化
static class NewK2 implements WritableComparable<NewK2> {
Long first;
Long second; public NewK2() {
} public NewK2(long first, long second) {
this.first = first;
this.second = second;
} public void readFields(DataInput in) throws IOException {
this.first = in.readLong();
this.second = in.readLong();
} public void write(DataOutput out) throws IOException {
out.writeLong(first);
out.writeLong(second);
} /**
* 当k2进行排序时,会调用该方法. 当第一列不同时,升序;当第一列相同时,第二列升序
*/
public int compareTo(NewK2 o) {
final long minus = this.first - o.first;
if (minus != 0) {
return (int) minus;
}
return (int) (this.second - o.second);
} @Override
public int hashCode() {
return this.first.hashCode() + this.second.hashCode();
} @Override
public boolean equals(Object obj) {
if (!(obj instanceof NewK2)) {
return false;
}
NewK2 oK2 = (NewK2) obj;
return (this.first == oK2.first) && (this.second == oK2.second);
}
} }

Hadoop序列化
序列化概念:
序列化:把结构化对象转化为字节流。
反序列化:是序列化的逆过程。即把字节流转回结构化对象。
Hadoop序列化的特点:
1、紧凑:高效使用存储空间。
2、快速:读写数据的额外开销小。
3、可扩展:可透明的读取老格式的数据。
4、互操作:支持多语言的交互。
Hadoop的序列化格式:Writable
Hadoop序列化的作用:
序列化在分布式环境的两大作用:进程间通信,永久存储。
Hadoop节点间通信:
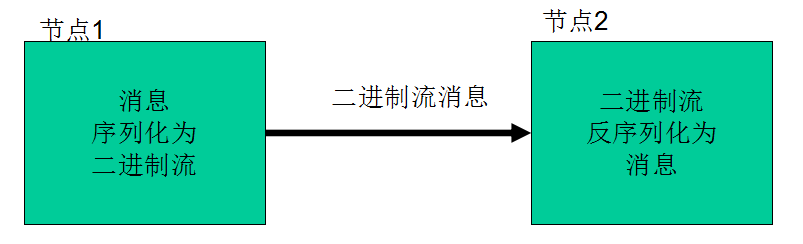
Writable接口
Writable接口,是根据DataInput和DataOutput实现的简单、有效的序列化对象。
MR的任意key和value必须实现Writable接口。
MR的任意key必须实现WritableComparable接口。
自定义Writable类(上面代码中有)
实现Writable:
1、write是把每个对象序列化到输出流。
2、readFields是把输入流字节反序列化。
实现WritableComparable:
Java值对象的比较:一般需要重写toString(),hashCode(),equals()方法。
自定义排序及Hadoop序列化的更多相关文章
- Hadoop学习之路(7)MapReduce自定义排序
本文测试文本: tom 20 8000 nancy 22 8000 ketty 22 9000 stone 19 10000 green 19 11000 white 39 29000 socrate ...
- 2 weekend110的hadoop的自定义排序实现 + mr程序中自定义分组的实现
我想得到按流量来排序,而且还是倒序,怎么达到实现呢? 达到下面这种效果, 默认是根据key来排, 我想根据value里的某个排, 解决思路:将value里的某个,放到key里去,然后来排 下面,开始w ...
- 大数据学习day22------spark05------1. 学科最受欢迎老师解法补充 2. 自定义排序 3. spark任务执行过程 4. SparkTask的分类 5. Task的序列化 6. Task的多线程问题
1. 学科最受欢迎老师解法补充 day21中该案例的解法四还有一个问题,就是当各个老师受欢迎度是一样的时候,其排序规则就处理不了,以下是对其优化的解法 实现方式五 FavoriteTeacher5 p ...
- Hadoop序列化机制及实例
序列化 1.什么是序列化?将结构化对象转换成字节流以便于进行网络传输或写入持久存储的过程.2.什么是反序列化?将字节流转换为一系列结构化对象的过程.序列化用途: 1.作为一种持久化格式. 2.作为一种 ...
- Hadoop(12)-MapReduce框架原理-Hadoop序列化和源码追踪
1.什么是序列化 2.为什么要序列化 3.为什么不用Java的序列化 4.自定义bean对象实现序列化接口(Writable) 在企业开发中往往常用的基本序列化类型不能满足所有需求,比如在Hadoop ...
- Hadoop序列化与Writable接口(二)
Hadoop序列化与Writable接口(二) 上一篇文章Hadoop序列化与Writable接口(一)介绍了Hadoop序列化,Hadoop Writable接口以及如何定制自己的Writable类 ...
- Hadoop序列化与Writable接口(一)
Hadoop序列化与Writable接口(一) 序列化 序列化(serialization)是指将结构化的对象转化为字节流,以便在网络上传输或者写入到硬盘进行永久存储:相对的反序列化(deserial ...
- Hadoop Serialization(third edition)hadoop序列化详解(最新版) (1)
初学java的人肯定对java序列化记忆犹新.最开始很多人并不会一下子理解序列化的意义所在.这样子是因为很多人还是对java最底层的特性不是特别理解,当你经验丰富,对java理解更加深刻之后,你就会发 ...
- Hadoop Serialization hadoop序列化详解(最新版) (1)【java和hadoop序列化比较和writable接口】
初学java的人肯定对java序列化记忆犹新.最开始很多人并不会一下子理解序列化的意义所在.这样子是因为很多人还是对java最底层的特性不是特别理解,当你经验丰富,对java理解更加深刻之后,你就会发 ...
随机推荐
- Ubuntu16.04.2安装Tensorflow
安装aptitude $ sudo apt-get install aptitude 安装python-pip python-dev $ sudo aptitude install python-pi ...
- Docker删除镜像报错
问题描述: 笔者意图删除nginx-file的镜像文件,但通过命令删除镜像时出现报错信息,提示存在多个引用(即一个IMAGE可被多个REPOSITORY引用,故删除会出现失败),如下: [root@k ...
- highCharts使用记录
公司的架构师让我做一个mockup,要用到highCharts,,以前想接触的,没时间学习,也没有用过,正好工作可以用上了,可以边学边做了. 环境 <script src="./js/ ...
- 【mybatis笔记】 resultType与resultMap的区别
序言: 昨天做一个项目,看到很多刚开始用mybatis的同事对于resultType和resultMap的理解与使用含糊不清,这里我试图用最好理解的说法写一写,欢迎大家勘误. 两者异同: 相同点:re ...
- Redis实战(四)CentOS 7上Redis哨兵
什么是哨兵 顾名思义,哨兵的作用就是对Redis的系统的运行情况的监控,它是一个独立进程.它的功能有2个: 1. 监控主数据库和从数据库是否运行正常: 2. 主数据出现故障后自动将从数据库转化为主数据 ...
- 好的MongoDB学习文章链接
1.MongoDB 极简实践入门 2.MongoDB中文社区 3.极客学院Mongodb 教程
- 谈谈动态地加载Jquery库文件的方法
有时候,我们可能不会在网页中<script src="jquery.min.js" 来加载 Jquery 库,可能在用户点击某个按钮后,才去加载 Jquery 库. 好处不用 ...
- 20155301 2016-2017-2 《Java程序设计》第6周学习总结
20155301 2016-2017-2 <Java程序设计>第6周学习总结 教材学习内容总结 1.串流设计,在数据来源与目的地之间,简介两者的是串流对象,在来源于目的地都不知道的情况下, ...
- 20145202马超 2016-2017-2 《Java程序设计》第6周学习总结
20145202马超 2016-2017-2 <Java程序设计>第6周学习总结 教材学习内容总结 进程:是一个正在执行中的程序,每一个进程都有一个执行程序,该顺序是一个执行路径,或者说是 ...
- Python基础入门(一)
1.在线教程 2.Python下载地址,安装步骤,就是next.next... 3.配置环境变量(win8) 电脑 --> 属性 --> 高级系统设置 --> 环境变量,找到系统变量 ...