Bert模型实现垃圾邮件分类
近日,对近些年在NLP领域很火的BERT模型进行了学习,并进行实践。今天在这里做一下笔记。
本篇博客包含下列内容:
BERT模型简介
概览
BERT模型结构
BERT项目学习及代码走读
项目基本特性介绍
代码走读&要点归纳
基于BERT模型实现垃圾邮件分类
TREC06语料库
基准模型介绍
BERT迁移模型实现
一.BERT模型简介
1.概览
BERT模型的全称是Bidirectional Encoder Representations from Transformer,即Transformer模型的双向编码器。只看名称可能很难看出门道,简单点讲,BERT模型就是一个Word2Vec的进化版,使用词向量对自然语言进行表示,但其模型深度极大,参数也特别的多。以Bert_BASE模型来举例,其包含12个隐藏层,每个隐层维度为768,每层又包含12个attention head,总共有110M个参数,模型参数文件在硬盘上就占据400MB的空间。
BERT是一个预训练模型,即通过半监督学习的方式,在海量的语料库上学习出单词的良好特征表示。其在11个经典NLP任务中都展现出了最佳的性能。Bert模型一共有4个特征:
①预训练:是一个预先训练好的语言模型,所有未来的开发者都可以直接继承使用。
②深度:是一个很深的模型,Bert_BASE的层数是12,Bert_LARGE的层数是24。
③双向Transformer:BERT是在基于Attention原理的Transformer模型上发展而来,通过丢弃 Transformer 中的 Decoder 模块(仅保留Encoder),BERT 具有双向编码能力和强大的特征提取能力。
④自然语言理解:其半监督学习方式,更强调模型对自然语言的理解能力,而不是语言生成。
2.BERT模型结构
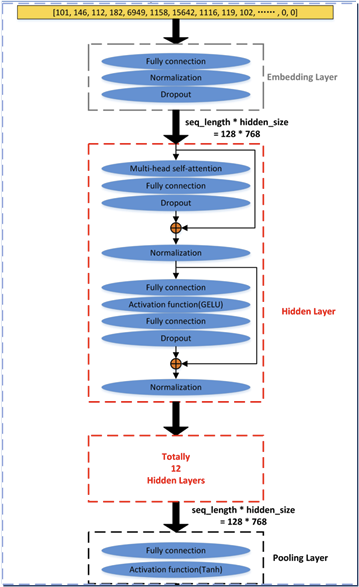
BERT模型的结构图如上所示。以Bert_BASE模型为例:其输入为符合化之后的向量,通过Embedding(嵌入)层,完成一些基本的预处理工作,之后就是由12个隐藏层组成的Transformer模型结构,最后的Pooling(池化)层,完成降维,输出最终结果。
预训练工作:
Bert模型的预训练工作包含2个任务:即掩码语言模型任务和句子对匹配检验任务。
掩码语言模型任务:在训练过程中,从输入句子中屏蔽一些词,然后根据上下文来尝试将这些词进行复原(类似于英语考试的完形填空)。在半监督学习的过程当中,会有15%的词汇被随机屏蔽,其中的80%直接替换为[MASK],10%替换成其他词语,另外10%保持原词汇不变。
句子对匹配检验任务:句子A和句子B一起输入到BERT模型,由BERT模型来判断句子 B 是否是后面的句子 A(True/False)。训练数据是从平行语料中随机抽取两个连续的句子生成的,50%的样本保留抽取的两个句子(True),其余50%样本的第二个句子从语料库中随机抽取(False) .
上述2个任务都是使用维基百科作为训练语料库。
二.BERT项目学习及代码走读
1.项目基本特性介绍
这里以GitHub上的bert-master项目为例(https://github.com/google-research/bert),对BERT模型的源代码进行学习,了解其流程,掌握要点。
bert项目是Google Research最早开源的一个BERT模型项目。第一眼看过去,这个项目还真的挺复杂的,没有直接能运行的demo不说(只有代码,没有示例数据),预训练基准模型也需要另外下载。这里我下载了两个预训练模型存放在bert-master项目中的models文件夹内。基准模型下载地址可以在README.md文件中找到。

英文BERT模型:uncased_L-12_H-768_A-12
(https://storage.googleapis.com/bert_models/2018_10_18/uncased_L-12_H-768_A-12.zip)
中文BERT模型:chinese_L-12_H-768_A-12
(https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip)
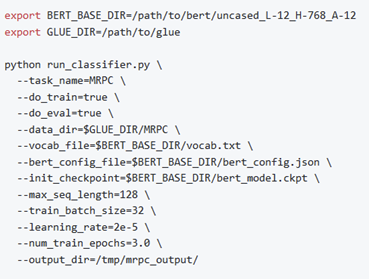
通过阅读README文件,发现BERT模型的main函数在run_classifier.py代码文件中,但其使用也较为复杂,需要在运行run_classifier.py代码时传入大量的参数,README文件中示例如下:
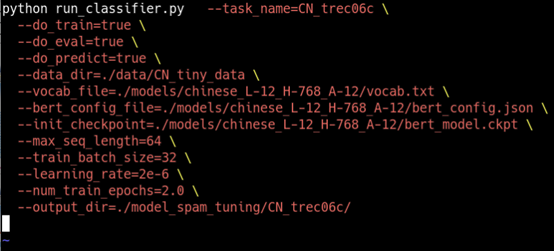
为了简单使用,尽量少的输入参数,制作shell脚本/bat文件,来方便的执行代码。不再对 BERT_BASE_DIR 和 GLUE_DIR 环境变量进行设置,直接将对应的数据位置、基准模型位置的相对路径进行填入即可。
run.sh
run.bat
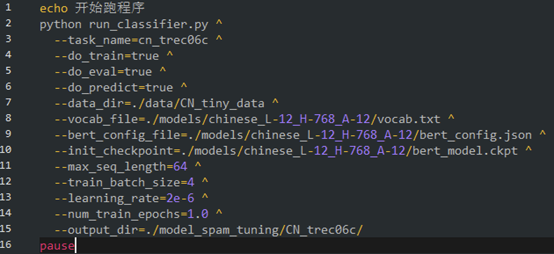
2.代码走读&要点归纳
run_classifier.py
1.样本类
包含InputExample()类和PaddingInputExample()类。规定了BERT模型输入样本的格式和内容,其中PaddingInputExample()类是在样本数量不足的情况下,通常是训练的最后一个batch,填入多个空样本,将样本数量填充至batch_size。
2.数据预处理类
包含DataProcessor()类以及继承该类的各个子类。DataProcessor()类不提供具体的数据预处理方法,需要各子类来编写完成具体的数据预处理方法。代码中自带Xnliprocessor(),MnliProcessor(),MrpcProcessor(),ColaProcessor()四个数据预处理子类,分别对应4种不同的公共数据集。仿照这4种数据预处理子类,我们可以编写自己的数据预处理类,来对自己的数据集进行处理,以适配BERT模型,这些内容会在第三部分具体讲解。
3. convert_single_example()函数
将一个样本(字符串类型),经过符号化等一系列操作,转换成神经网络可以使用的InputFeature(List向量类型)。其中InputFeature包含5部分内容:
input_ids: 即各word的位置序列(在词汇表中的位置) 如[101,123,4342,5423,632,732,....,0]
input_mask: 即word掩码,1为真货,0为序列填充 如[1,1,1,1,1,1,1,...,0]
segment_ids: 即2个句子的标注序列, 如[0,0,0,0,0,0,1,1,1,1,1,1]。对于 segment_ids 如2个句子后还不到最大长度,则后面用0填充。
label_id: 即标签的位置,在 label_list 中的位置。
is_real_example: 是否为真正样本的标记,取值为布尔值。
该样本转换函数主要通过tokenization.py代码中的FullTokenizer()类来完成上述功能。
4. file_based_convert_examples_to_features()函数
将一组样本(由InputFeatures类组成),转化为 tf.train.Example类,并将转换好的样本内容写入文件output_file,包含train.tf_record,eval.tf_record,predict.tf_record 三类文件,与运行程序时的do_train、do_eval、do_predict参数相关联。需要调用上方的convert_single_example()函数。
5. file_based_input_fn_builder()函数
该函数是一个样本迭代器构造函数,最终返回input_fn()函数,该input_fn函数类似一个迭代器,从 train.tf_record / eval.tf_record / predict.tf_record文件中读取数据,按照 batch_size 进行数据的 shuffle(乱序),之后转数据类型为tf.int32,再返回转换后数据。
6. model_fn_builder()函数
该函数是一个模型函数的生成函数,其返回内容model_fn会作为参数传入tf.contrib.tpu.TPUEstimator类中,在初始化该类时加以使用。model_fn_builder()函数的主体内容即model_fn,它通过调用create_model函数,使用modeling.py代码中的BertModel类来创建深度学习网络模型,并完成加载基准BERT模型(init_checkpoint参数),定义optimizer,设置网络训练步骤等操作,最终返回的output_spec为tf.contrib.tpu.TPUEstimatorSpec类对象。
tokenization.py
1. FullTokenizer()类:
该类为符号化类,在run_classifier.py中的convert_single_example()方法中加以使用。主要功能由tokenize()函数进行实现,将字符串转换为由词汇表(vocab.txt)中所包含词汇组成的List。核心为两层嵌套的for循环。外层for循环分割单词,汉字,标点符号,组成一个list;内层for循环尝试将词汇表中不存在的单词分割成多个子串,例如:”unaffable”→[“un”, ”##aff”, ”##able”],可以在保留词根的同时,扩充了词汇的延展性。实在分割不出来的未知词汇用[UNK]代替。
2.符号化支持类:
包括BasicTokenizer类和WordpieceTokenizer类,这两个类负责完成FullTokenizer()类中的具体功能。其中,BasicTokenizer类完成的工作包括去除口音词汇,去除标点符号,判断中文字符,去除间隔符等。WordpieceTokenizer类主要完成最大子字符串搜索功能。
modeling.py
在这个代码文件中,BertModel类来完成整个模型的创建,架构工作。其结构分为嵌入层,编码层(隐藏层),池化层。其这几个层是并列关系,命名空间结构关系如下图:
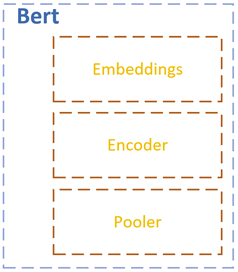
其中,嵌入层的embedding_lookup ()函数,输出最基本的词向量 embeddings,其shape 为 [batch_size,seq_length,hidden_size];编码层embedding_postprocessor 函数,将三个embeddings进行加和,最终输出shape 为[batch_size,seq_length,hidden_size]的tensor;池化层在进行降维操作时,仅取seq_length 维(即第二个维度)的第一个embedding(即第一个token),池化后, 作为输出的变量self.pooled_output的shape为[batch_size,hidden_size]。
需要特别注意的是,transformer_model()函数实现了上文中提到的attention模型。其源论文” Attention is All You Need”可以在https://arxiv.org/abs/1706.03762查看。
三.基于Bert模型实现垃圾邮件分类
在上一期的博客中,使用SVM来完成垃圾邮件分类工作,本期使用BERT来构造迁移模型,以实现垃圾邮件的分类。
1.TREC06语料库
本次实践工作依然使用2006 TREC Public Spam Corpora 语料库,包含2组数据集,即中文数据集trec06c和英文数据集trec06p。这篇博客中以中文数据集trec06c数据集作范例。
在该数据集中,每个邮件以GBK编码单独存储在一个文件内,保存了原始邮件的所有数据,包括发送方邮箱、接收方邮箱地址、邮件发送时间等。邮件示例如下:
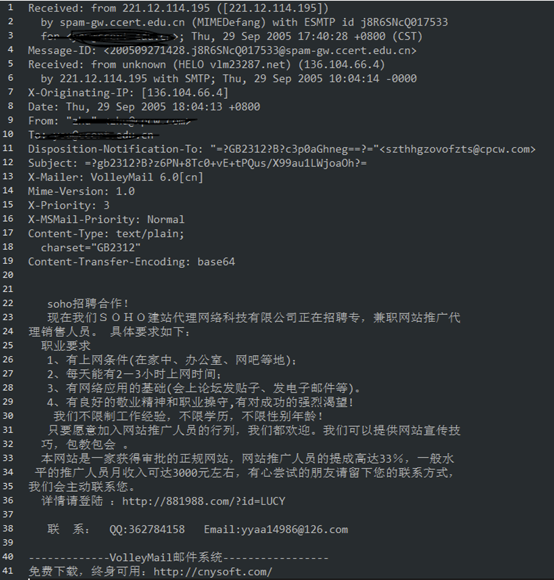
数据集中共包含21766个正样本,42854个负样本,我们根据其样本索引文件(full/index)进行预处理工作,使其正负样本达到1:1的均衡比例,最终得到的索引文件中包含21766个正样本以及21766个负样本。
2.基准模型介绍
这里使用的基准模型是chinese_L-12_H-768_A-12模型,其具体配置参数信息如下:
|
attention_probs_dropout_prob |
0.1 |
|
directionality |
“bidi” |
|
hidden_act |
"gelu" |
|
hidden_dropout_prob |
0.1 |
|
hidden_size |
768 |
|
initializer_range |
0.02 |
|
intermediate_size |
3072 |
|
max_position_embeddings |
512 |
|
num_attention_heads |
12 |
|
num_hidden_layers |
12 |
|
pooler_fc_size |
768 |
|
pooler_num_attention_heads |
12 |
|
pooler_num_fc_layers |
3 |
|
pooler_size_per_head |
128 |
|
pooler_type |
"first_token_transform" |
|
type_vocab_size |
2 |
|
vocab_size |
21128 |
可以看到,BERT模型的词汇表数量是21128,相比上篇博客中的SVM模型(词汇数量95963)要少很多。其原因是Bert模型以单个汉字为基础单位,而SVM模型是以词汇(词组)为基础单位。
3.BERT迁移模型实现
BERT模型并不能够直接判断邮件是否为垃圾邮件,其模型输出也是一个长度为hidden_size的词向量。因此需要使用BERT作为基础模型,然后加入相应的全连接层和激活函数,完成迁移模型,以对邮件进行分类。基于BERT预训练模型已具备自然语言理解能力的情况下,对模型参数进行训练和微调后,即可实现对垃圾邮件进行分类的功能。
使用Bert-master项目制作迁移模型,主要的工作是需要将自己的trec06c数据转换成Bert模型所需要的格式。通过前面对bert-master项目代码进行阅读,发现其数据预处理部分位于run_classifier.py代码中的DataProcessor()类附近,DataProcessor()类为其父类,我们需要编写一个数据预处理子类来对trec06c数据进行处理、转换。数据预处理、转换的流程图如下:

首先读取索引文件,获得索引列表;第二步根据索引列表,读取每一个邮件文件;对每一封邮件进行处理,包括移除头部信息获取正文、字符解码、字符串拼接等操作,将一个邮件文件转换成为一个字符串,并形成Content_List;第四步是对每一个字符串文本内容进行封装,将其转换为InputExample类的对象,并形成Example_List,这是所有样本的集合;最后根据8:1:1的比例,划分训练集(train set)、验证集(dev set)和测试集(test set)。根据上述流程完成CN_trec06c_Processor(DataProcessor)类,其代码如下:
1 # TODO ===============自己的dataProcessor trec06c 数据 原始email,散装数据=====================
2 # 需要继承 DataProcessor,并重新里面的几个数据预处理函数。
3 class CN_trec06c_Processor(DataProcessor):
4 def __init__(self):
5 # 定义一些超参数
6 self.MAX_EMAIL_LENGTH = 400 #最长单个邮件长度
7 def get_email_file(self,base_path,path_list):
8 email_str_list = []
9 for i in range(len(path_list)):
10 with open(base_path + path_list[i][1:],'r',encoding='gbk') as fin:
11 words = ""
12 begin_tag = 0
13 wrong_tag = 0
14 while(True):
15 if wrong_tag > 20 or len(words)>self.MAX_EMAIL_LENGTH:
16 break
17 try:
18 line = fin.readline()
19 wrong_tag = 0
20 except:
21 wrong_tag += 1
22 continue
23 if (not line):
24 break
25 if(begin_tag == 0):
26 if(line=='\n'):
27 begin_tag = 1
28 continue
29 else:
30 words += line.strip() + ' '
31 if len(words)>self.MAX_EMAIL_LENGTH:
32 break
33 if len(words)>=10: # 语句最短长度
34 email_str_list.append(words)
35 return email_str_list
36 def get_all_examples(self):
37 trec06Path = "../../02_SVM_analysis/data/" # trec06c数据位置
38 path_list_spam = []
39 with open(trec06Path+'CN_index_spam','r',encoding='utf-8') as fin:
40 for line in fin.readlines():
41 path_list_spam.append(line.strip())
42 path_list_ham = []
43 with open(trec06Path+'CN_index_ham','r',encoding='utf-8') as fin:
44 for line in fin.readlines():
45 path_list_ham.append(line.strip())
46 # 是否对原始数据长度作裁剪 共 21766 个 正例 21766个 负例
47 path_list_spam = path_list_spam[:100] #这里仅取100个样本进行本机测试
48 path_list_ham = path_list_ham[:100]
49 spam_email_list = self.get_email_file(trec06Path[:-6],path_list_spam)
50 ham_email_list = self.get_email_file(trec06Path[:-6],path_list_ham)
51 print("*****************====================*****************")
52 print("正例样本数量: ",len(ham_email_list))
53 print("反例样本数量: ",len(spam_email_list))
54 with open('model_spam_tuning/CN_trec06c/train_sample_stat.txt','w',encoding='utf-8') as fout:
55 fout.write("正例样本数量: " + str(len(ham_email_list)) + '\n')
56 fout.write("反例样本数量: " + str(len(spam_email_list)) + '\n')
57 print("*****************====================*****************")
58 examples = []
59 for i in range(len(spam_email_list)):
60 guid = "train-%d" % (i) # 从 0 开始
61 # TODO 下方,tokenization.convert_to_unicode() 函数,将byte类数据 decode成为'utf-8'
62 text_a = tokenization.convert_to_unicode(str(spam_email_list[i]))
63 label = '0' # 转int类 是后续的操作,此处仍旧是str 垃圾邮件label为0
64 examples.append(
65 InputExample(guid=guid, text_a=text_a, text_b=None, label=label))
66 for i in range(len(ham_email_list)):
67 guid = "train-%d" % (i+len(spam_email_list)) # 从 垃圾邮件长度 开始向后续
68 # TODO 下方,tokenization.convert_to_unicode() 函数,将byte类数据 decode成为'utf-8'
69 text_a = tokenization.convert_to_unicode(str(ham_email_list[i]))
70 label = '1' # 转int类 是后续的操作,此处仍旧是str 正常邮件label为1
71 examples.append(
72 InputExample(guid=guid, text_a=text_a, text_b=None, label=label))
73 # TODO 还要进行切分 测试集,训练集,验证集
74 return examples
75
76 def get_train_examples(self, data_dir):
77 # train_data_path = os.path.join(data_dir, "cn_train_tiny_tiny.csv") # 训练集 数据文件名称,可以在这里改
78 examples = self.get_all_examples()
79 ex_new = []
80 for i in range(len(examples)):
81 if i%10 != 1 and i%10 != 2: # 8:1:1 切分训练集,验证集,测试集
82 ex_new.append(examples[i])
83 return ex_new
84
85 def get_dev_examples(self, data_dir):
86 """Gets a collection of `InputExample`s for the dev set."""
87 examples = self.get_all_examples()
88 ex_new = []
89 for i in range(len(examples)):
90 if i%10 == 1: # 8:1:1 切分训练集,验证集,测试集
91 ex_new.append(examples[i])
92 return ex_new
93
94 def get_test_examples(self, data_dir):
95 """Gets a collection of `InputExample`s for prediction."""
96 test_set_txt = []
97 test_set_label = []
98 examples = self.get_all_examples()
99 ex_new = []
100 for i in range(len(examples)):
101 if i%10 == 2: # 8:1:1 切分训练集,验证集,测试集
102 ex_new.append(examples[i])
103 test_set_txt.append(examples[i].text_a)
104 test_set_label.append(examples[i].label)
105 with open('model_spam_tuning/CN_trec06c/test_origin.txt','w',encoding='utf-8') as fout:
106 for i in range(len(test_set_label)):
107 fout.write(test_set_label[i]+'\t'+test_set_txt[i]+'\n')
108 return ex_new
109
110 def get_labels(self):
111 """Gets the list of labels for this data set."""
112 return ['0','1']
113 # TODO ===============自己的dataProcessor trec06c 数据=====================
其中,get_email_file()函数读取路径List中所有邮件文件的内容,并完成预处理、筛选工作,返回邮件内容List;get_all_examples()函数分别读取垃圾邮件路径索引List以及正常邮件路径索引List,调用get_email_file()函数获取所有邮件的内容,将格式化为BERT模型所需要的格式,即InputExample()类,包括guid,text_a,text_b,label四个属性。后面get_train_examples(),get_dev_examples(),get_test_examples()三个函数对所有的邮件样本进行划分,分别得到训练集,验证集,测试集。需要注意的是,这三个函数的名称不能随意更动,它们是对父类DataProcessor()中同名方法的具体实现。最后一个函数get_labels()返回标签列表,分几类有返回几种标签,需要注意的是这里的标签仍然是字符串类型。
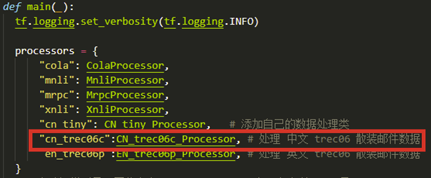
编写完成数据预处理类之后,我们需要给Bert模型添加相应的处理任务,将CN_trec06c_Processor类添加到下方main()函数的processors字典变量中,如下图。需要注意字典的key值必须全部用小写字母。
这时,基于BERT的迁移模型已经构建完毕,使用前面编写好的run.sh(Linux)或run.bat(windows)即可运行run_classifier.py脚本开始训练。由于bert-master项目会将所有的数据样本读入显存进行训练,因此在我本机环境下难以运行(GTX 860、2G显存),仅能运行100个样本。因此,借用一个朋友的云服务器(GTX 1080Ti、10G显存)开展实验。硬件配置&环境配置版本如下:

在超参数配置为下表的情况下,训练了25个epochs,耗时约3个小时。

下图为训练时的输出,可以看出云服务器每秒可以完成120多个样本的训练。

最终得到的结果在模型文件夹的eval_result.txt文件中,最终模型在验证集上的分类准确率达到了99.347%,比之前的SVM模型要准确不少。

而该BERT迁移模型对于测试集的分类结果则在predict_results.tsv文件中。
对于英文邮件建立BERT迁移模型的方法与中文类似,需要完成一个英文邮件的数据预处理类,并将其添加到main()函数的processors字典变量中。代码就不罗列了,最终得到的英文垃圾邮件分类准确率为98.81% 。

Bert模型实现垃圾邮件分类的更多相关文章
- 基于SKLearn的SVM模型垃圾邮件分类——代码实现及优化
一. 前言 由于最近有一个邮件分类的工作需要完成,研究了一下基于SVM的垃圾邮件分类模型.参照这位作者的思路(https://blog.csdn.net/qq_40186809/article/det ...
- Python之机器学习-朴素贝叶斯(垃圾邮件分类)
目录 朴素贝叶斯(垃圾邮件分类) 邮箱训练集下载地址 模块导入 文本预处理 遍历邮件 训练模型 测试模型 朴素贝叶斯(垃圾邮件分类) 邮箱训练集下载地址 邮箱训练集可以加我微信:nickchen121 ...
- Atitit 贝叶斯算法的原理以及垃圾邮件分类的原理
Atitit 贝叶斯算法的原理以及垃圾邮件分类的原理 1.1. 最开始的垃圾邮件判断方法,使用contain包含判断,只能一个关键词,而且100%概率判断1 1.2. 元件部件串联定律1 1.3. 垃 ...
- CNN实现垃圾邮件分类(行大小不一致要补全)
以下是利用卷积神经网络对某一个句子的处理结构图 我们从上图可知,将一句话转化成一个矩阵.我们看到该句话有6个单词和一个标点符号,所以我们可以将该矩阵设置为7行,对于列的话每个单词可以用什么样的数值表示 ...
- 利用朴素贝叶斯(Navie Bayes)进行垃圾邮件分类
贝叶斯公式描写叙述的是一组条件概率之间相互转化的关系. 在机器学习中.贝叶斯公式能够应用在分类问题上. 这篇文章是基于自己的学习所整理.并利用一个垃圾邮件分类的样例来加深对于理论的理解. 这里我们来解 ...
- scikit-learn机器学习(二)逻辑回归进行二分类(垃圾邮件分类),二分类性能指标,画ROC曲线,计算acc,recall,presicion,f1
数据来自UCI机器学习仓库中的垃圾信息数据集 数据可从http://archive.ics.uci.edu/ml/datasets/sms+spam+collection下载 转成csv载入数据 im ...
- 垃圾邮件分类实战(SVM)
1. 数据集说明 trec06c是一个公开的垃圾邮件语料库,由国际文本检索会议提供,分为英文数据集(trec06p)和中文数据集(trec06c),其中所含的邮件均来源于真实邮件保留了邮件的原有格式和 ...
- Hand on Machine Learning第三章课后作业(1):垃圾邮件分类
import os import email import email.policy 1. 读取邮件数据 SPAM_PATH = os.path.join( "E:\\3.Study\\机器 ...
- 检测用户命令序列异常——使用LSTM分类算法【使用朴素贝叶斯,类似垃圾邮件分类的做法也可以,将命令序列看成是垃圾邮件】
通过 搜集 Linux 服务器 的 bash 操作 日志, 通过 训练 识别 出 特定 用户 的 操作 习惯, 然后 进一步 识别 出 异常 操作 行为. 使用 SEA 数据 集 涵盖 70 多个 U ...
随机推荐
- 5分钟让你理解K8S必备架构概念,以及网络模型(下)
写在前面 在这用XMind画了一张导图记录Redis的学习笔记和一些面试解析(源文件对部分节点有详细备注和参考资料,欢迎关注我的公众号:阿风的架构笔记 后台发送[导图]拿下载链接, 已经完善更新): ...
- 使用 vue3 的自定义指令给 element-plus 的 el-dialog 增加拖拽功能
element-plus 提供的 el-dialog 对话框功能非常强大,只是美中不足不能通过拖拽的方式改变位置,有点小遗憾,那么怎么办呢?我们可以通过 vue 的自定义指令来实现一个可以拖拽的对话框 ...
- 如何设计一个高性能 Elasticsearch mapping
目录 前言 mapping mapping 能做什么 Dynamic mapping dynamic=true dynamic=runtime dynamic=false dynamic=strict ...
- 037.Python的UDP语法
UDP语法 1 创建一个socket的UDP对象 import socket #创建对象 socket.SOCK_DGRAM 代表UDP协议 sk = socket.socket(type=socke ...
- Scala 中 object、class 与 trait 的区别
Scala 中 object.class 与 trait 的区别 引言 当你刚入门 Scala,肯定会迫不及待想要编写自己的第一个 Scala 程序.如果你已经在交互模式下敲过 Scala 代码,想必 ...
- Jquery的load加载本地文件出现跨域错误的解决方案"Access to XMLHttpRequest at 'file:///android_asset/web/graph.json' from(Day_46)
博主是通过JS调用本地的一个json文件赋值给变量出现的跨域错误, 网上有大量文章,五花八门的,但总归,一般性此问题基本可通过这三种方法解决: https://blog.csdn.net/qq_418 ...
- Python数学建模-01.新手必读
Python 完全可以满足数学建模的需要. Python 是数学建模的最佳选择之一,而且在其它工作中也无所不能. 『Python 数学建模 @ Youcans』带你从数模小白成为国赛达人. 1. 数学 ...
- 收购公司、孵化(产品)和被收购的20个短篇故事-BI产品的历史
原文地址: 20 short tales of acquiring companies, incubating (ideas into products) and being acquired. | ...
- webpack(2)--webapck自身的配置
上一记介绍了webpack的安装和基本配置,本记将描述webpack自身的配置 一:指定webpack入口以及出口目录以及输出文件 相信读者在看完上一记后会有一点疑惑:为什么运行webpack要配置s ...
- SpringMVC=>解决JSON乱码问题
<!-- 解决JSON乱码问题 --> <mvc:annotation-driven> <mvc:message-converters register-defaults ...