Kubernetes的资源管理
本节讲解为一个pod配置资源的预期使用量和最大使用量。通过设置这两组参数,可以确保pod公平地使用Kubernetes集群资源,同时也影响着整个集群pod的调度方式。
1.为pod中的容器申请资源
创建一个pod时,可以指定容器对CPU和内存的资源请求量(即requests),以及资源限制量(即limits)。它们并不在pod里定义,而是针对每个容器单独指定。pod对资源的请求量和限制量是它所包含的所有容器的请求量和限制量之和。
1.1 创建包含资源requests的pod
看一个示例pod的定义,只有一个容器,为其指定CPU和内存的资源请求量,如下代码所示。
#代码14.1 定义了资源requests的pod:requests-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: requests-pod
spec:
containers:
- image: busybox
command: ["dd", "if=/dev/zero", "of=/dev/null"]
name: main
resources:
requests:
cpu: 200m #容器申请200毫核(一个CPU核心时间的1/5)
memory: 10Mi #容器申请10MB内存
在pod manifest中,声明了一个容器需要1/5核(200毫核)的CPU才能正常运行。换句话说,五个同样的pod(或容器)可以足够快地运行在一个CPU核上。
当不指定CPU requests时,表示并关心系统为容器内的进分配了多少CPU时间。在最坏情况下进程可能根本分不到CPU时间(当其他进程对CPU求量很大时会发生)。这对一些时间不敏感、低优先级的batch jobs没有问题,但对于处理用户请求的容器这样配置显然不太合适。
在pod spec里,同时为容器申请了10MB的内存,说明我期望容器内的进程最大消耗10MB的RAM。它们可能实际占用较小,但在正常情况下我们并不希望它们占用超过这个值。在本章后面将看到如果超过会发生什么。
现在运行pod。当pod启动时,可以通过在容器中运行top命令快速查看进程的CPU使用,如下面的代码所示。
#代码14.2 查看容器内CPU和内存的使用情况
$ kubectl exec -it requests-pod top
Mem: 1288116K used, 760368K free, 9196K shrd, 25748K buff, 814840K cached
CPU: 9.1% usr 42.1% sys 0.0% nic 48.4% idle 0.0% io 0.0% irq 0.2% sirq Load average: 0.79 0.52 0.29 2/481 10
PID PPID USER STAT VSZ %VSZ CPU %CPU COMMAND
1 0 root R 1192 0.0 1 50.2 dd if /dev/zero of /dev/null
7 0 root R 1200 0.0 0 0.0 top
在容器内执行dd命令会消耗尽可能多的CPU,但因为它是单线程运行所以最多只能跑满一个核,而MinikubeVM拥有两个核,这就是为什么top命令显示进程只占用了50%CPU的原因。
对于两核来说,50%显然就是指一个核,说明容器实际使用量超过了在pod定义中申请的200毫核。这是符合预期的,因为requests不会限制容器可以使用的CPU数量。这里需要指定CPU限制实现这一点,稍后会进行尝试,不过首先看看在pod中指定资源requests对pod调度的影响。
1.2 资源requests如何影响调度
通过设置资源requests指定了pod对资源需求的最小值。调度器在将pod调度到节点的过程中会用到该信息。每个节点可分配给pod的CPU和内存数量都是一定的。调度器在调度时只考虑那些未分配资源量满足pod需求量的节点。如果节点的未分配资源量小于pod需求量,这时节点没有能力提供pod对资源需求的最小量,因此Kubernetes不会将该pod调度到这个节点。
调度器如何判断一个pod是否适合调度到某个节点
这里比较重要而且会令人觉得意外的是,调度器在调度时并不关注各类资源在当前时刻的实际使用量,而只关心节点上部署的所有pod的资源申请量之和。尽管现有pods的资源实际使用量可能小于它的申请量,但如果使用基于实际资源消耗量的调度算法将打破系统为这些己部署成功的pods提供足够资源的保证。
假设节点上部署了三个pod(podA、podB、podC)。它们共申请了节点80%的CPU和60%的内存资源。那么podD将无法调度到这个节点上,因为它25%的CPUrequests大于节点未分配的20%CPU。而实际上,这与当前三个pods仅使用70%的CPU没有什么关系。
调度器如何利用pod requests为其选择最佳节点
在调度中,调度器首先会对节点列表进行过滤,排除那些不满足需求的节点,然后根据预先配置的优先级函数对其余节点进行排序。其中有两个基于资源请求量的优先级排序函数:LeastRequestedPriority和MostRequestedPriority。前者优先将pod调度到请求量少的节点上(也就是拥有更多未分配资源的节点),而后者相反,优先调度到请求量多的节点(拥有更少未分配资源的节点)。但是,正如刚刚解释的,它们都只考虑资源请求量,而不关注实际使用资源量。
调度器只能配置一种优先级函数。你可能在想为什么有人会使用MostRequestedPriority函数。毕竟如果有一组节点,通常会使其负载平均分布,但是在随时可以增加或删除节点的云基础设施上运行时并非如此。配置调度器使用MostRequestedPriority函数,可以在为每个pod提供足量CPU/内存资源的同时,确保Kubernetes使用尽可能少的节点。通过使pod紧凑地编排,一些节点可以保持空闲并可随时从集群中移除。由于通常会按照单个节点付费,这样便可以节省一笔开销。
查看节点资源总量
来看看调度器的行为。现在将部署另一个资源请求量是之前4倍的pod。 但在这之前,先看看什么是节点资源总量。因为调度器需要知道每个节点拥有多少CPU和内存资源,Kubelet会向API服务器报告相关数据,并通过节点资源对外提供访问,可以使用kubectl describe命令进行查看,如以下代码清单所示。
#代码 14.3节点的资源总量和可分配资源
$ kubectl describe nodes
Name: minikube
Capacity: #节点的资源总量
cpu: 2
memory: 204848Ki
pods: 110
Allocatable: #可分配给pod的资源量
cpu: 2
memory: 1946084Ki
pods: 11
命令的输出展示了节点可用资源相关的两组数量:节点资源总量和可分配资源量。资源总量代表节点所有的资源总和,包括那些可能对pod不可用的资源。有些资源会为Kubernetes或者系统组件预留。调度器的决策仅仅基于可分配资源量。
单节点的minikube集群运行于2核的VM之上,同时从上面的例子中可以看到节点没有预留资源,全部CPU都可以分配给pod。因此,调度器再调度另一个申请了800毫核的pod是没有问题的。
运行这个pod。可以使用示例代码中的YAML文件,或者简单地执行以下命令:
$ kubectl run requests-pod-2 --image=busybox --restart Never --requests='cpu=800m,memory=20Mi' -- dd if=/dev/zero of=/dev/null
pod "requests-pod-2" created
来看看是否被调度成功:
$ kubectl get po requests-pod-2
NAME READY STATUS RESTARTS AGE
requests-pod-2 1/1 Running 0 3m
创建一个不适合任何节点的pod
现在部署了两个pod,共申请了1000毫核CPU。所以应该还剩下1核可供其他pod使用,是吧?因此再部署一个资源申请量为1核的pod。使用与前面类似的命令:
$ kubectl run requests-pod-3 --image=busybox --restart Never --requests='cpu=1,memory=20Mi' -- dd if=/dev/zero of=/dev/null
pod "requests-pod-2" created
注意:这次指定CPU请求量为1核(cpu=l)而不是1000毫核(cpu=l000m)。
到目前为止一切顺利,pod被API服务器接收(当pod不合法时API服务器会拒绝该pod的创建请求)
$ kubectl get po requests-pod-3
NAME READY STATUS RESTARTS AGE
requests-pod-3 0/1 Pending 0 4m
尽管等了好一会,pod依然卡在Pending状态,可以通过describe命令查看一下出现这种情况的详细原因,如以下代码清单所示。
#代码14.4 使用kubectl describe pod查看为什么pod卡在Pending状态
$ kubectl describe po requests-pod-3
Name: requests-pod-3
NameSpace: default
Node: / #没有与该pod关联的节点
Conditions:
Type: Status
PodScheduled: False #pod没有调度成功
Events:
Warning FailedScheduling No nodes are available that match all of the following predicated::Insufficient cpu(1). #CPU资源不足导致调度失败
从命令的输出可以看出单节点集群没有足够的CPU,pod不适合任何节点因此没有被成功调度。但是为什么呢?这三个pod的CPUrequests总和是2000毫核也就是2核,我们的节点正好可以提供,是哪里出了问题呢?
查明pod没有被调度成功的原因
可以通过检查节点资源找出为什么pod没有成功调度。再次执行kubectl describe node命令并仔细地检查输出。
#代码14.5 使用 kubecl describe node 检查节点已分配资源
$ kubectl describe node
Name: minikube
Non-terminated Pod (7 in total)
Namespace Name CPU Requ CPU Lim Mem Req Mem Lim
--------- ---- -------- ------- ------- --------
default requests-pod 200m(10%) 0(0%) 10Mi(0%) 0(0%)
default requests-pod-2 800m(40%) 0(0%) 20Mi(1%) 0(0%)
kube-system dflt-http-b... 10m(0%) 10m(0%) 20Mi(1%) 20Mi(1%)
kube-system kube-addon-... 5m(0%) 0(0%) 50Mi(2%) 0(0%)
kube-system kube-dns-26... 260m(13%) 0(0%) 110Mi(5%) 170Mi(8%)
kube-system kubernetes-... 0(0%) 0(0%) 0(0%) 0(0%)
kube-system nginx-ingre... 0(0%) 0(0%) 0(0%) 0(0%)
Allocated resources:
(Total limits may be over 100 percent,i.e., overcommitted.)
CPU Requests CPU Limits Memory Requests Memory Limits
------------ ---------- --------------- -------------
1275m(63%) 10m(0%) 210Mi(11%) 190Mi(9%)
在列表的左下角可以看到共有1275毫核己经被运行的pod申请,比先前部署的两个pod申请量多了275毫核。看来有些东西吃掉了额外的CPU资源。
我们可以在上面的列表中找到罪魁祸首。在kube-system命名空间内有三个pod明确申请了CPU。这些pod加上我们的两个pod,只剩下725毫核可用。第三个pod需要1000毫核,调度器不会将其调度到这个节点上,因为这将导致节点超卖。
释放资源让pod正常调度
只有当节点资源释放后(比如删除之前两个pod中的一个)pod才会调度上来。如果删除第二个pod,调度器将获取到删除通知, 并在第二个pod成功终止后立即调度第三个pod。这在下面的代码清单中可以看到。
#代码14.6 删除另一个pod后看到pod已正常调度
$ kubectl delete po requests-pod-2
pod "requests-pod-2" deleted
$ kubectl get po
NAME READY STATUS RESTARTS AGE
requests-pod 1/1 Running 0 2h
requests-pod-2 1/1 Terminating 0 1h
requests-pod-3 0/1 Pending 0 1h
$ kubectl get po
NAME READY STATUS RESTARTS AGE
requests-pod 1/1 Running 0 2h
requests-pod-3 1/1 Running 0 1h
在以上所有例子中,也指定了内存申请量,不过它并没有对调度产生影响, 因为节点拥有足够多的内存来容纳所有pod的需求。调度器处理CPU和内存requests的方式没有什么不同,但与内存requests相反的是,pod的CPU requests在其运行时也扮演着一个角色,将在下文中了解这一点。
1.3 CPU requests如何影响CPU时间分配
现在有两个pod运行在集群中(暂且不理会那些系统pod,因为它们大部分时间都是空闲的)。一个请求了200毫核,另一个是前者的5倍。在本章开始,说到Kubernetes会将requests资源和limits资源区别对待。我们还没有定义任何limits,因此每个pod分别可以消耗多少CPU并没有做任何限制。那么假设每个pod内的进程都尽情消耗CPU时间,每个pod最终能分到多少CPU时间呢?
CPU requests不仅仅在调度时起作用,它还决定着剩余(未使用)的CPU时间如何在pod之间分配。因为第一个pod请求了200毫核,另一个请求了 1000毫核,所以未使用的CPU将按照1:5的比例来划分给这两个pod。如果两个pod都全力使用CPU,第一个pod将获得16.7%的CPU时间,另一个将获得83.3%的CPU时间。
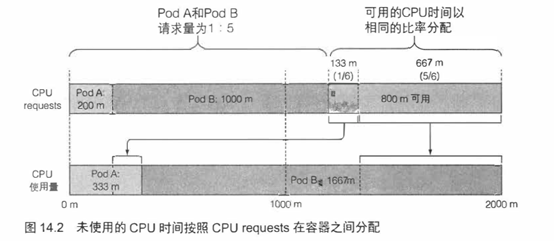
另一方面,如果一个容器能够跑满CPU,而另一个容器在该时段处于空闲状态,那么前者将可以使用整个CPU时间(当然会减掉第二个容器消耗的少量时间)。毕竟当没有其他人使用时提高整个CPU的利用率也是有意义的,对吧?当然,第二个容器需要CPU时间的时候就会获取到,同时第一个容器会被限制回来。
1.4 定义和申请自定义资源
Kubernetes允许用户为节点添加属于自己的自定义资源,同时支持在pod资源requests里申请这种资源。因为目前是一个alpha特性,所以不打算描述其细节,而只会简短地介绍一下。
首先,需要通过将自定义资源加入节点API对象的capacity属性让Kubernetes知道它的存在。这可以通过执行HTTP的PATCH请求来完成。资源名称可以是不以kubernetes.io域名开头的任意值,例如example.org/my-resource,数量必须是整数(例如不能设为100m,因为0.1不是整数;但是可以设置为1000m、2000m,或者简单地设为1和2)。这个值将自动从capacity字段复制到allocatable字段。
然后,创建pod时,只要简单地在容器spec的resources.requests字段下,或者像之前例子那样使用带--requests参数的kubectl run命令来指定自定义资源名称和申请量,调度器就可以确保这个pod只能部署到满足自定义资源申请量的节点,同时每个已部署的pod会减少节点的这类可分配资源数量。
一个自定义资源的例子就是节点上可用的GPU单元数量。如果pod需要使用GPU,只要简单指定其requests,调度器就会保证这个pod只能调度到至少拥有一个未分配GPU单元的节点上。
2.限制容器的可用资源
设置pod的容器资源申请量保证了每个容器能够获得它所需要资源的最小量。现在看看容器可以消耗资源的最大量。
2.1 设置容器可使用资源量的硬限制
之前看到当其他进程处于空闲状态时容器可以被允许使用所有CPU资源。但是可能想防止一些容器使用超过指定数量的CPU,而且经常会希望限制容器的可消耗内存数量。
CPU是一种可压缩资源,意味着可以在不对容器内运行的进程产生不利影响的同时,对其使用量进行限制。而内存明显不同——是一种不可压缩资源。一旦系统为进程分配了一块内存,这块内存在进程主动释放之前将无法被回收。这就是为什么需要限制容器的最大内存分配量的根本原因。
如果不对内存进行限制,工作节点上的容器(或者pod)可能会吃掉所有可用内存,会对该节点上所有其他pod和任何新调度上来的pod(记住新调度的pod是基于内存的申请量而不是实际使用量的)造成影响。单个故障pod或恶意pod几乎可以导致整个节点不可用。
创建一个带有资源limits的pod
为了防止这种情况发生,Kubernetes允许用户为每个容器指定资源limits(与设置资源requests几乎相同)。以下代码清单展示了一个包含资源limits的pod描述文件示例。
#代码14.7 —个包含CPU和内存硬限制的pod: limited-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: limited-pod
spec:
containers:
- image: busybox
command: ["dd", "if=/dev/zero", "of=/dev/null"]
name: main
resources:
limits:
cpu: 1 #这个容器予许最大使用1核CPU
memory: 20Mi #这个容器予许最大使用20MB内存
这个pod的容器包含了CPU和内存资源limits配置。容器内的进程不允许消耗超过1核CPU和20MB内存。
注意:因为没有指定资源requests,它将被设置为与资源limits相同的值。
可超卖的limits
与资源requests不同的是,资源limits不受节点可分配资源量的约束。所有limits的总和允许超过节点资源总量的100% (见图14.3)。换句话说,资源limits可以超卖。如果节点资源使用量超过100% ,—些容器将被杀掉,这是一个很重要的结果。

会在后面pod的Qos等级中介绍决定杀掉哪些容器,不过只要单个容器尝试使用比自己制定的limits更多的资源也可以被杀掉。
2.2 超过limits
当容器内运行的进程尝试使用比限额更多的资源时会发生什么呢?
己经了解了CPU是可压缩资源,当进程不等待IO操作时消耗所有的CPU时间是非常常见的。正如所知道的,对一个进程的CPU使用率可以进行限制,因此当为一个容器设置CPU限额时,该进程只会分不到比限额更多的CPU而已。
而内存却有所不同。当进程尝试申请分配比限额更多的内存时会被杀掉(这个容器被OOMKilled了,00M是Out Of Memory的缩写)。如果pod的重启策略为Always或OnFailure,进程将会立即重启,因此用户可能根本察觉不到它被杀掉。但是如果它继续超限并被杀死,Kubernetes会再次尝试重启,并开始增加下次重启的间隔时间。这种情况下用户会看到pod处于CrashLoopBackOff状态:
$ kubectl get po
NAME READY STATUS RESTARTS AGE
memoryhog 0/1 CrashLoopBackOff 3 1m
CrashLoopBackOff状态表示Kubelet还没有放弃,它意味着在每次崩溃之后,Kubelet就会增加下次重启之前的间隔时间。第一次崩溃之后,Kubelet立即重启容器,如果容器再次崩溃,Kubelet会等待10秒钟后再重启。随着不断崩溃,延迟时间也会按照20、40、80、160秒以几何倍数增长,最终收敛在300秒。一旦间隔时间达到300秒,Kubelet将以5分钟为间隔时间对容器进行无限重启,直到容器正常运行或被删除。
要定位容器crash的原因,可以通过查看pod日志以及kubectl describe pod命令:
#代码14.8 通过kubectl describe pod查看容器终止的原因
$ kubectl describe pod
Name: memoryhog
Containers:
main:
...
State: Terminated
Reason: OOMKilled
Exit Code: 137
Started: Tue, 27 Dec 2016 14:55:53 +0100
Finished: Tue, 27 Dec 2016 14:55:58 +0100
Last State: Terminated
Reason: OOMKilled
Exit Code: 137
Started: Tue, 27 Dec 2016 14:55:37 +0100
Finished: Tue, 27 Dec 2016 14:55:50 +0100
Ready: False
OOMKilled状态告诉我们容器因为内存不足而被系统杀掉了。上例中,容器实际上己经超过了内存限额而被立即杀死。
讨论一下,当第一次开始为他们的容器指定限制时,大多数用户会被警惕。
因此,如果不希望容器被杀掉,重要的一点就是不要将内存limits设置得很低。而容器有时即使没有超限也依然会被OOMKilled。具体原因在<pod Qos等级介绍>,而现在就讨论一下在大多数用户首次指定limits时需要警惕的地方。
2.3 容器中的应用如何看待limits
首先部署代码14.7的pod。
在容器内运行top命令。命令的输出显示在下面的代码清单中。
#代码14.9 在有CPU/内存限制的容器内运行top命令
$ kubectl exec -it limited-pod top
Mem: 1450980K used, 597504K free, 22012K shrd, 65876K buff, 857552K cached
CPU: 10.0% usr 40.0% sys 0.0% nic 50.0% idle 0.0% io 0.0% irq 0.0% sirq
Load average: 0.17 1.19 2.47 4/503 10
PID PPID USER STAT VSZ %VSZ CPU %CPU COMMAND
1 0 root R 1192 0.0 1 49.9 dd if /dev/zero of /dev/null
5 0 root R 1192 0.0 0 0.0 top
首先提醒一下,这个pod的CPU限额是500毫核,内存限额是20MiB。现在仔细审视一下top命令的输出。看看有什么奇怪之处吗?
查看used和free内存量,这些数值远超出为容器设置的20MiB限额。同样地,设置了CPU限额为1核,即使使用的dd命令通常会消耗所有可用的CPU资源,但主进程似乎只用到了50%。所以究竟发生了什么呢?
在容器内看到的始终是节点的内存,而不是容器本身的内存
即使为容器设置了最大可用内存的限额,top命令显示的是运行该容器的节点的内存数量,而容器无法感知到此限制。
这对任何通过查看系统剩余可用内存数量,并用这些信息来决定自己该使用多少内存的应用来说具有非常不利的影响。
对于Java程序来说这是个很大的问题,尤其是不使用-Xmx选项指定虚拟机的最大堆大小时,JVM会将其设置为主机总物理内存的百分值。在Kubernetes开发集群运行Java容器化应用(比如在笔记本电脑上运行)时,因为内存limits和笔记本电脑总内存差距不是很大,这个问题还不太明显。
但是如果pod部署在拥有更大物理内存的生产系统中,JVM将迅速超过预先配置的内存限额,然后被OOM杀死。
也许你觉得可以简单地设置-Xmx选项就可以解决这个问题,那么你就错了,很遗憾。-Xmx选项仅仅限制了堆大小,并不管其他off-heap内存。好在新版本的Java会考虑到容器limits以缓解这个问题。
容器内同样可以看到节点所有的CPU核
与内存完全一样,无论有没有配置CPU limits,容器内也会看到节点所有的CPU。将CPU限额配置为1,并不会神奇地只为容器暴露一个核。CPU limits做的只是限制容器使用的CPU时间。
因此如果一个拥有1核CPU限额的容器运行在64核CPU上,只能获得1/64 的全部CPU时间。而且即使限额设置为1核,容器进程也不会只运行在一个核上,不同时刻,代码还是会在多个核上执行。
上面的描述没什么问题,对吧?虽然一般情况下如此,但在一些情况下却是灾难。
一些程序通过查询系统CPU核数来决定启动工作线程的数量。同样在开发环境的笔记本电脑上运行良好,但是部署在拥有更多数量CPU的节点上,程序将快速启动大量线程,所有线程都会争夺(可能极其)有限的CPU时间。同时每个线程通常都需要额外的内存资源,导致应用的内存用量急剧增加。
不要依赖应用程序从系统获取的CPU数量,你可能需要使用Downward API将CPU限额传递至容器并使用这个值。也可以通过cgroup系统直接获取配置的CPU限制,请查看下面的文件:
/sys/fs/cgroup/cpu/cpu.cfs_quota_us
/sys/fs/cgroup/cpu/cpu.cfs_period_us
3.了解pod QoS等级
前面己经提到资源limits可以超卖,换句话说,一个节点不一定能提供所有pod所指定的资源limits之和那么多的资源量。
假设有两个pod,podA使用了节点内存的90%, podB突然需要比之前更多的内存,这时节点无法提供足量内存,哪个容器将被杀掉呢?应该是podB吗?因为节点无法满足它的内存请求。或者应该是podA吗?这样释放的内存就可以提供给podB了。
显然,这要分情况讨论。Kubernetes无法自己做出正确决策,因此就需要一种方式,可以通过这种方式可以指定哪种pod在该场景中优先级更高。Kubernetes将pod划分为3种QoS等级:
- BestEffort(优先级最低)
- Burstable
- Guaranteed(优先级最高)
3.1 定义pod的QoS等级
你也许希望这个等级会通过一个独立的字段分配,但并非如此。QoS等级来源于pod所包含的容器的资源requests和limits的配置。下面介绍分配QoS等级的方法。
为pod分配BestEffort等级
最低优先级的QoS等级是BestEffort。会分配给那些没有(为任何容器)设置任何requests和limits的pod。前面章节创建的pod都是这个等级。在这个等级运行的容器没有任何资源保证。在最坏情况下,它们分不到任何CPU时间,同时在需要为其他pod释放内存时,这些容器会第一批被杀死。不过因为BestEffort pod没有配置内存limits,当有充足的可用内存时,这些容器可以使用任意多的内存。
为pod分配Guaranteed等级
与Burstable相对的是Guaranteed等级,会分配给那些所有资源request和limits相等的pod。对于一个Guaranteed级别的pod,有以下几个条件:
- CPU和内存都要设置requests和limits
- 每个容器都需要设置资源量
- 它们必须相等(每个容器的每种资源的requests和limits必须相等)
因为如果容器的资源requests没有显式设置,默认与limits相同,所以只设置所有资源(pod内每个容器的每种资源)的限制量就可以使pod的QoS等级为Guaranteed。这些Pod的容器可以使用它所申请的等额资源,但是无法消耗更多的资源(因为它们的limits和requests相等)。
为pod分配Burstable等级
Burstable QoS等级介于BestEffort和Guaranteed之间。其他所有的pod都属于这个等级。包括容器的requests和limits不相同的单容器pod,至少有一个容器只定义了requests但没有定义limits的pod,以及一个容器的request limits相等,但是另一个容器不指定requests或limits的pod。Burstable pod可以获得它们所申请的等额资源,并可以使用额外的资源(不超过limits)。
requests和limits之间的关系如何定义QoS等级
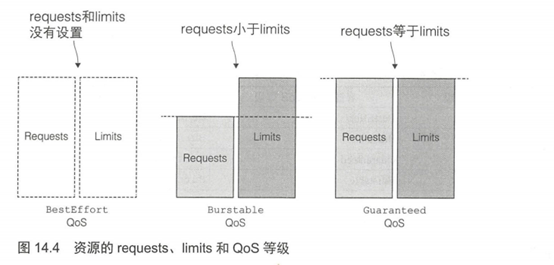
考虑一个pod应该属于哪个QoS等级足以令人脑袋快速运转,因为它涉及多个容器、多种资源,以及requests和limits之间所有可能的关系。如果一开始从容器级别考虑QoS(尽管它并不是容器的属性,而是pod的属性),然后从容器QoS推导出pod QoS,这样可能更容易理解。
单个容器的QoS等级表
表14.1显示了基于资源requests和limits如何为单个容器定义QoS等级。对于单容器pod,容器的QoS等级也适用于pod。
|
表14.1基于资源请求量和限制量的单容器pod的QoS等级 |
||
|
CPU requests vs.limits |
内存 requests vs.limits |
容器的QoS等级 |
|
未设置 |
未设置 |
BestEffort |
|
未设置 |
Requests < Limits |
Burstable |
|
未设置 |
Requests < Limits |
Burstable |
|
Requests < Limits |
未设置 |
Burstable |
|
Requests < Limits |
Requests < Limits |
Burstable |
|
Requests < Limits |
Requests = Limits |
Burstable |
|
Requests = Limits |
Requests = Limits |
Guaranteed |
注意:如果设置了requests而没有设置limits,参考表中requests小于limits那一 行。如果设置了limits,requests默认与limits相等,因此参考request等于limits那一行。
多容器pod的QoS等级
对于多容器pod,如果所有的容器的QoS等级相同,那么这个等级就是pod的QoS等级。如果至少有一个容器的QoS等级与其他不同,无论这个容器是什么等级,这个pod的QoS等级都是Burstable等级。表14.2展示了pod的QoS等级与其中两个容器的QoS等级之间的对应关系。多容器pod可以对此进行简单扩展。
|
表14.2 由容器的QoS等级推导出pod的QoS等级 |
||
|
容器1的Qos等级 |
容器2的Qos等级 |
Pod的QoS容器 |
|
BestEffort |
BestEffort |
BestEffort |
|
BestEffort |
Burstable |
Burstable |
|
BestEffort |
Guaranteed |
Burstable |
|
Burstable |
Burstable |
Burstable |
|
Burstable |
Guaranteed |
Burstable |
|
Guaranteed |
Guaranteed |
Guaranteed |
注意:运行kubectl describe pod以及通过pod的YAML/JSON描述的status.qosClass字段都可以查看pod的QoS等级。
已经解释了如何划分QoS等级,但是依然需要了解在一个超卖的系统中如何确定哪个容器先被杀掉。
3.2 内存不足时哪个进程会被杀死
在一个超卖的系统,QoS等级决定着哪个容器第一个被杀掉,这样释放出的资源可以提供给高优先级的pod使用。BestEffort等级的pod首先被杀掉,其次是Burstable pod,最后是Guaranteed pod。Guaranteed pod只有在系统进程需要内存时才会被杀掉。
了解QoS等级的优先顺序
请看图14.5中的例子。假设两个单容器的pod,第一个属于BestEffort QoS等级,第二个属于Burstable等级。当节点的全部内存己经用完,还有进程尝试申请更多的内存时,系统必须杀死其中一个进程(甚至包括尝试申请额外内存的进程)以兑现内存分配请求。这种情况下,BestEffort等级运行的进程会在Burstable等级的进程之前被系统杀掉。
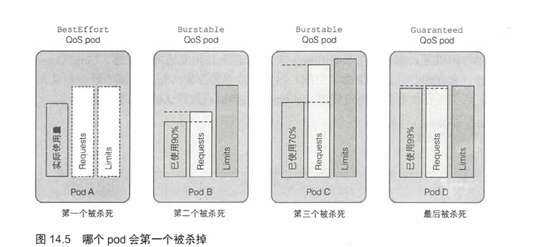
显然,BestEffort pod的进程会在Guaranteed pod的进程之前被杀掉。同样地,Burstable pod的进程也先于Guaranteed pod的进程被杀掉。但如果只有两个Burstable pod会发生什么呢?很明显需要选择一个优先于另一个的进程。
如何处理相同QoS等级的容器
每个运行中的进程都有一个称为OutOfMemory(OOM)分数的值。系统通过比较所有运行进程的OOM分数来选择要杀掉的进程。当需要释放内存时,分数最高的进程将被杀死。
OOM分数由两个参数计算得出:进程己消耗内存占可用内存的百分比,与一个基于pod QoS等级和容器内存申请量固定的OOM分数调节因子。对于两个属于Burstable等级的单容器的pod,系统会杀掉内存实际使用量占内存申请量比例更高的pod。这就是图14.5中使用了内存申请量90%的podB在podC(只使用了70%)之前被杀掉的原因,尽管podC比podB使用了更多兆字节的内存。
这说明不仅要注意requets和limits之间的关系,还要留心requests和预期实际消耗内存之间的关系。
4.为命名空间中的pod设置默认的requests和limits
己经了解到如何为单个容器设置资源requests和limits。如果不做限制,这个容器将处于其他所有设置了requests和limits的容器的控制之下。换句话说,为每个容器设置requests和limits是一个很好的实践。
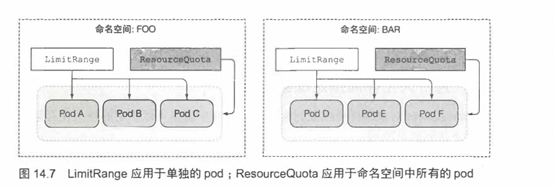
4.1 LimitRange资源简介
用户可以通过创建一个LimitRange资源来避免必须配置每个容器。LimitRange资源不仅允许用户(为每个命名空间)指定能给容器配置的每种资源的最小和最大限额,还支持在没有显式指定资源request时为容器设置默认值。
LimitRange资源被LimitRanger准入控制插件控制。API服务器接收到带有pod描述信息的POST请求时,LimitRanger插件对pod spec进行校验。如果校验失败,将直接拒绝。因此,LimitRange对象的一个广泛应用场景就是阻止用户创建大于单个节点资源量的pod。如果没有LimtRange,API服务器将欣然接收pod创建请求,但永远无法调度成功。
LimitRange资源中的limis应用于同一个命名空间中每个独立的pod、容器,或者其他类型的对象。它并不会限制这个命名空间中所有pod可用资源的总量,总量是通过ResourceQuota对象指定的。
4.2 LimitRange 对象的创建
看一下LimitRange的全貌,然后单独解释每个属性的作用。下面的代码展示了一个LimitRange资源的完整定义。
#代码14.10 LimitRange资源: limits.yaml
apiVersion: v1
kind: LimitRange
metadata:
name: example
spec:
limits:
- type: Pod #指定整个pod的资源limits
min: #pod中所有容器的CPU和内存的请求量之和的最小值
cpu: 50m
memory: 5Mi
max: #pod中所有容器的CPU和内存的请求量之和的最大值
cpu: 1
memory: 1Gi
- type: Container #指定容器的资源限制
defaultRequest: #容器没有指定CPU或内存请求量时设置的默认值
cpu: 100m
memory: 10Mi
default: #容器没有指定limits时设置的默认值
cpu: 200m
memory: 100Mi
min: #容器的CPU和内存的资源request和limits的最小值和最大值
cpu: 50m
memory: 5Mi
max:
cpu: 1
memory: 1Gi
maxLimitRequestRatio: #每种资源requests与limits的最大比值
cpu: 4
memory: 10
- type: PersistentVolumeClaim #limitRange还可以指定请求PVC存储容量的最小值和最大值
min:
storage: 1Gi
max:
storage: 10Gi
正如在上面例子中看到的,整个pod资源限制的最小值和最大值是可以配置的。它应用于pod内所有容器的requests和limits之和。
在更低一层的容器级别,用户不仅可以设置最小值和最大值,还可以为没有显式指定的容器设置资源requests(defaultRequest)和limits(default)的默认值。
除了最小值、最大值和默认值,用户甚至可以设置limits和requests的最大比例。 上面示例中设置了maxLimitRequestRatio为4,表示容器的CPUlimits不能超过CPUrequests的4倍。因此,对于一个申请了200毫核的容器,如果它的CPU限额设置为801毫核或者更大就无法创建。而对于内存,这个比例设为了10。
正如在pod中为容器声明CPU和内存一样,用户也可以声明指定大小的持久化存储。
这个例子只使用一个LimitRange对象,其中包含了对所有资源的限制,而如果希望按照类型进行组织,也可以将其分割为多个对象(例如一个用于pod限制,一个用于容器限制,一个用于PVC限制)。多个LimitRange对象的限制会在校验pod或PVC合法性时进行合并。
由于LimitRange对象中配置的校验(和默认值)信息在API服务器接收到新的pod或PVC创建请求时执行,如果之后修改了限制,己经存在的pod和PVC将不会再次进行校验,新的限制只会应用于之后创建的pod和PVC。
4.3 强制进行限制
在设置了限制的情况下,尝试创建一个CPU申请量大于LimitRange允许值的pod。可以在代码库中找到pod的YAML。下面的代码清单仅展示与本节讨论相关的部分。
#代码14.11 一个 CPU requests 超过限制的pod: limits-pod-too-big.yaml
resources:
resources:
cpu: 2
这个pod的容器需要2核CPU,大于之前LimitRange中设置的最大值。创建pod时会返回以下结果:
$ kubectl create -f limits-pod-too-big.yaml
Error from server (Forbidden): error when creating "limits-pod-too-big.yaml":
pods "too-big” is forbidden:[
maximum cpu usage per Pod is 1, but request is 2,
maximum cpu usage per Container is 1, but request is 2.]
为了看起来更清晰,所以输出结果稍微做了修改。服务器返回错误信息的好处是它列出了这个pod被拒绝的所有原因,而不仅仅是第一个错误。正如从结果看到的,pod被拒绝的原因有两个:为容器申请了2核的CPU,但是容器的最大CPU请求量限制为1核,在Pod级别也是同样的原因,pod整体可以请求2核的CPU,但是允许申请的最大值是l核(如果这是一个多容器pod,即使每个单独容器的请求量少于最大CPU请求量,所有容器请求量的总和仍然需要少于2核才能符合最大CPU请求量的限制)。
4.4 应用资源requests和limits的默认值
现在再看看如果不指定资源requests和limits,Kubernetes如何为其设置默认值,部署以下代码.
#代码 /Chapter03/kubia-manual.yaml
apiVersion: v1
kind: Pod
metadata:
name: kubia-manual
spec:
containers:
- image: luksa/kubia
name: kubia
ports:
- containerPort: 8080
protocol: TCP
在设置LimitRange对象之前,所有pod创建后都不包含资源requests或limits,但现在通过describe确认一下刚刚创建的kubia-manual pod:
#代码清单14.12 检查自动应用于pod的limits
$ kubectl describe po kubia-manual
Name: kubia-manual
Containers:
kubia:
Limits:
cpu: 200m
memory: 100Mi
Requests:
cpu: 100m
memory: 10Mi
容器的requests和limits与LimitRange对象中设置的一致。如果在另一个命名空间中指定不同的LimitRange,那么这个命名空间中创建的pod就会拥有不同的requests和limits。这样管理员就可以为每个命名空间的pod配置资源的默认值、最小值和最大值。如果使用命名空间来区分不同团队,或是区分开发、测试、交付准备,以及生产环境的pod都运行在相同的Kubernetes集群中,那么在每个命名空间中定义不同的LimitRange就可以确保只在特定的命名空间中可以创建资源需求大的pod,而在另一些命名空间中只能创建资源需求小的pod。
但需要记住的是,LimitRange中配置的limits只能应用于单独的pod或容器。 用户仍然可以创建大量的pod吃掉集群所有可用资源。LimitRange并不能防止这个问题,而相反,将在下文了解的ResourceQuota对象可以做到这点。
5.限制命名空间中的可用资源总量
LimitRange只应用于单独的pod,而同时也需要一种手段可以限制命名空间中的可用资源总量。这通过创建一个ResourceQuota对象来实现。
5.1 ResourceQuota资源介绍
ResourceQuota的接纳控制插件会检查将要创建的pod是否会引起总资源量超出ResourceQuota。如果那样,创建请求会被拒绝。因为资源配额在pod创建时进行检查,所以ResourceQuota对象仅仅作用于在其后创建的pod—一并不影响已经存在的pod。
资源配额限制了一个命名空间中pod和PVC存储最多可以使用的资源总量。同时也可以限制用户允许在该命名空间中创建pod、PVC, 以及其他API对象的数量,因为到目前为止处理最多的资源是CPU和内存,下面就来看看如何为这两种资源指定配额。
为CPU和内存创建ResourceQuota
限制命名空间中所有pod允许使用的CPU和内存总量可以通过创建ResourceQuota对象来实现,下面的代码清单。
#代码14.13 CPU和内存的ResourceQuota资源:memory: quota-cpu-memory.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: cpu-and-mem
spec:
hard:
requests.cpu: 400m
requests.memory: 200Mi
limits.cpu: 600m
limits.memory: 500Mi
上面代码为CPU和内存分别定义了requests和limits总量,而不是简单地为每种资 源只定义一个总量。需要注意到与LimitRange对比,结构有一些不同。这里所有资源的requests和limits都定义在一个字段下。
这个ResourceQuota设置了命名空间中所有pod最多可申请的CPU数量为400毫核,limits最大总量为600毫核。对于内存,设置所有requests最大总量为200MiB,limits为 500MiB。
与LimitRange—样,ResourceQuota对象应用于它所创建的那个命名空间,但不同的是,后者可以限制所有pod资源requests和limits的总量,而不是每个单独的pod或者容器,如图14.7所示。
查看配额和配额使用情况
将ResourceQuota对象提交至API服务器之后,可以执行kubectl describe 命令查看当前配额己经使用了多少,如以下代码清单所示。
#代码 14.14 使用kubectl describe quota查看配额
$ kubectl describe quota
Name: cpu-and-mem
Namespace: default
Resource Used Hard
--------- ---- ----
limits.cpu 200m 600m
limits.memory 100Mi 500Mi
requests.cpu 100m 400m
requests.memory 10Mi 200Mi
因为只运行了kubia-manual pod,所以Used列与这个pod的requests和limits使用了一些。如果再运行其他pod,它们的requests和limits值会增加至己使用量中。
与ResourceQuota同时创建LimitRange
需要注意的一点是,创建ResourceQuota时往往还需要随之创建一个LimitRange对象。在上一节己经配置了LimitRange,但是假设没有配置,kubia-manual pod将无法成功创建,因为它没有指定任何资源requests和limits。看一下这种情况会发生什么:
$ kubectl create -f ../Chapter03/kubia-manual.yaml
Error from server (Forbidden): error when creating "../Chapter03/kubi-manual.yaml":pods "kubia-manual" is forbidden: failed quota: cpu-and-mem: must specify limits.cpu,limits.memory,requests.cpu,requests.memory
因此,当特定资源(CPU或内存)配置了(requests或limits)配额,在pod中必须为这些资源(分别)指定requests或limits,否则API服务器不会接收该pod的创建请求。
5.2 为持久化存储指定配额
ResourceQuota对象同样可以限制某个命名空间中最多可以声明的持久化存储总量,如下代码:
代码14.15 为存储配置ResourceQuota:quota-storage.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: storage
spec:
hard:
requests.storage: 500Gi #可声明存储总量
ssd.storageclass.storage.k8s.io/requests.storage: 300Gi #StorageClassssd的可申请的存储量
standard.storageclass.storage.k8s.io/requests.storage: 1Ti
在这个例子中,Namespace中所有可申请的PVC总量被限制为500GiB(通过配额对象中的requests.storage)。PVC可以申请一个特定StorageClass、动态提供的PV(PersistentVolume)。这就是为什么Kubernetes同样允许单独为每个StorageClass提供定义存储配额的原因。上面的示例限制了可声明的SSD存储(以ssd命名的StorageClass)的总量为300GiB。低性能的HDD存储(StorageClass standrad)限制为1TiB。
5.3 限制可创建对象的个数
资源配额同样可以限制单个命名空间中的pod、ReplicationController、Service以及其他对象的个数。集群管理员可以根据比如付费计划限制用户能够创建的对象个数,同时也可以用来限制公网IP或者Service可使用的节点端口个数。
下面的代码清单展示了一个限制对象个数的ResourceQuota定义:
#代码14.16 —个限制了资源最大个数的ResourceQuota : quota-object-count.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: objects
spec:
hard: #这个命名空间最多创建10个pod、5个RC、10个Secret、10个ConfigMap、4个PVC
pods: 10
replicationcontrollers: 5
secrets: 10
configmaps: 10
persistentvolumeclaims: 5
services: 5 #最多创建5个Service,其中最多1个LB类型和2个NodePort类型
services.loadbalancers: 1
services.nodeports: 2
ssd.storageclass.storage.k8s.io/persistentvolumeclaims: 2 #最多声明2个StorageClass为ssd的PVC
上面的例子允许用户在一个命名空间中最多创建10个pod,无论是手动创建还是通过ReplicationController、ReplicaSet、DaemonSet或者Job创建的。同时限制了ReplicationController最大个数为 5,Service最大个数为 5,其中LoadBalancer类型最多1个,NotPort类型最多2个。与通过指定每个StorageClass来限制存储资源的申请总量类似,PVC的个数同样可以按照StorageClass来限制。
对象个数配额目前可以为以下对象配置:
- pod
- ReplicationController
- Secret
- ConfigMap
- Persistent Volume Claim
- Service(通用),以及两种特定类型的Service,比如LoadBalancer Service(services.loadbalancers)和NodePortService(services,nodeports)
最后,甚至可以为ResourceQuota对象本身设置对象个数配额。其他对象的个数,比如ReplicaSet、Job、Deployment、Ingress等暂时不能限制(但是最新的k8s版本可能已经可以实现了,因此请参考最新文档获取更多信息)。
5.4 为特定的pod状态或者QoS等级指定配额
目前为止我们创建的Quota应用于所有的pod,不管pod的当前状态和QoS等级如何。但是Quota可以被一组quota scopes限制。目前配额作用范围共有4种:BestEffort、 NotBestEffort、Termination和NotTerminating。
BestEffort和NotBestEffort范围决定配额是否应用于BestEffort QoS等级或者其他两种等级(Burstable和Guaranteed)的pod。
其他两个范围(Terminating和NotTerminating)的名称或许有些误导作用,实际上并不应用于处在(或不处在)停止过程中的pod。我们尚未讨论过这个问题,但可以为每个pod指定被标记为Failed,然后真正停止之前还可以运行多长时间。这是通过在pod spec中配置activeDeadlineSeconds来实现的。该属性定义了一个pod从开始尝试停止的时间到其被标记为Failed然后真正停止之前,允许其在节点上继续运行的秒数。Terminating配额作用范围应用于这些配置了activeDeadlineSeconds的pod,而NotTerminating应用于那些没有指定该配置的pod。
创建ResourceQuota时,可以为其指定作用范围。目标pod必须与配额中配置的所有范围相匹配。另外,配额的范围也决定着配额可以限制的内容。BestEffort范围只允许限制pod个数,而其他3种范围除了pod个数,还可以限制CPU/内存的requests和limits。
例如,如果只想将配额应用于BestEffort、NotTerminating的pod,可 以创建如以下代码清单所示的ResourceQuota对象。
#代码 14.17 为BestEffort/NotTerminating pod 设置 ResourceQuota:quota-scoped.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: besteffort-notterminating-pods
spec:
scopes: #这个quota只会应用于拥有BestEffortQoS,以及没有设置有效期的pod上
- BestEffort
- NotTerminating
hard:
pods: 4 #这样的pod只予许存在4个
这个配额允许最多创建4个属于BestEffort QoS等级,并没有设置active deadline的pod。如果配额针对的是NotBestEffort pod,我们便可以指定requests.cpu,requests.memory,limits.cpu和limits.memory。
6.小结
1.空闲的CPU时间根据容器的CPU requests来分配。
2.如果容器使用过量的CPU, 系统不会杀死这个容器,但如果使用过量的内存会被杀死。
3.在一个overcommited的系统,容器同样可以被杀死以释放内存给更重要的pod,这基于pod的QoS等级和实际内存用量。
4.可以通过LimtRange对象为单个pod的资源requests和limits定义最小值、最大值和默认值。
5.可以通过ResourceQuota对象限制一个命名空间中所有pod的可用资源数量。
Kubernetes的资源管理的更多相关文章
- [Kubernetes]资源模型与资源管理
作为 Kubernetes 的资源管理与调度部分的基础,需要从它的资源模型说起. 资源管理模型的设计 我们知道,在 Kubernetes 里面, Pod 是最小的原子调度单位,这就意味着,所有和调度和 ...
- 基于Python+Django的Kubernetes集群管理平台
➠更多技术干货请戳:听云博客 时至今日,接触kubernetes也有一段时间了,而我们的大部分业务也已经稳定地运行在不同规模的kubernetes集群上,不得不说,无论是从应用部署.迭代,还是从资源调 ...
- 程序员修神之路--kubernetes是微服务发展的必然产物
菜菜哥,我昨天又请假出去面试了 战况如何呀? 多数面试题回答的还行,但是最后让我介绍微服务和kubernetes的时候,挂了 话说微服务和kubernetes内容确实挺多的 那你给我大体介绍一下呗 可 ...
- Kubernetes自动伸缩pod-HPA
在运维中,虽然能预先知道负载何时会飙升,或者如果负载的变化是较长时间内逐渐发生的,手动扩容也是可以接受的,但指望靠人工干预来处理突发而不可预测的流量增长,仍然不够理想. 幸运的是,Kubernetes ...
- [置顶]
kubernetes--资源管理
概念 默认情况下,kubernetes不会限制pod等资源对象使用系统资源,单个pod或者容器可以无限制使用系统资源. kubernetes的资源管理分为资源请求(request)和资源限制(limi ...
- 云原生的弹性 AI 训练系列之三:借助弹性伸缩的 Jupyter Notebook,大幅提高 GPU 利用率
Jupyter Notebooks 在 Kubernetes 上部署往往需要绑定一张 GPU,而大多数时候 GPU 并没有被使用,因此利用率低下.为了解决这一问题,我们开源了 elastic-jupy ...
- JuiceFS 在理想汽车的使用和展望
理想汽车是中国新能源汽车制造商,设计.研发.制造和销售豪华智能电动汽车,于 2015 年 7 月创立,总部位于北京,已投产的自有生产基地位于江苏常州,通过产品创新及技术研发,为家庭用户提供安全及便捷的 ...
- Kubernetes资源管理
目录贴:Kubernetes学习系列 1.资源模型 虛拟化技术是云计算平台的基础,其目标是对计算资源进行整合或划分,这是云计算管理平台中的关键技术.虚拟化技术为云计算管理乎台的资源管理提供了资源调配上 ...
- 第18 章 : Kubernetes 调度和资源管理
Kubernetes 调度和资源管理 这节课主要讲三部分的内容: Kubernetes 的调度过程: Kubernetes 的基础调度能力(资源调度.关系调度): Kubernetes 高级调度能力( ...
随机推荐
- CSS层叠性
比较id,类,标签的数量 谁多就谁在上面 255个类的权重等于一个id 当权重一样时,以后设置的为准 通过继承而来的,权重为0 !important (设置权重无限大)可以影响权重,但只能影响选中的, ...
- Android面试必问!View 事件分发机制,看这一篇就够了!
在 Android 开发当中,View 的事件分发机制是一块很重要的知识.不仅在开发当中经常需要用到,面试的时候也经常被问到. 如果你在面试的时候,能把这块讲清楚,对于校招生或者实习生来说,算是一块不 ...
- [Python] 爬虫系统与数据处理实战 Part.1 静态网页
爬虫技术基础 HTTP/HTTPS(7层):应用层,浏览器 SSL:加密层,传输层.应用层之间 TCP/IP(4层):传输层 数据在传输过程中是加密的,浏览器显示的是解密后的数据,对爬虫没有影响 中间 ...
- 运维常用shell脚本一(系统指标巡检、自动创建用户、跳板机)
一.系统指标巡检脚本 #!/bin/bash menu(){ cat <<EOF +---------------------------------------------+ | 日常巡 ...
- Linux服务之nginx服务篇四(配置https协议访问)
一.配置nginx支持https协议访问 编译安装nginx的时候需要添加相应的模块--with-http_ssl_module和--with-http_gzip_static_module(可通过/ ...
- C# DeepClone 深拷贝
常规利用反射进行克隆 public static T CloneModel<T>(T oModel) { var oRes = default(T); var oType = typeof ...
- Linux(CentOS7)下安装jdk1.8
Linux(CentOS7) 下安装 jdk1.8 操作过程. 一.检查是否自带jdk rpm -qa|grep java 如果存在则用下面命令删除,xxx yyy zzz代表查询出来的自带jdk名称 ...
- C# 将DLL制作CAB包并在浏览器下载,自动安装。(Activex)(包括ie打开cab包一直弹出用户账户控制,确定之后无反应的解决办法。)
制作Activex程序网上有很多方法我就不说了,我的业务主要做的就是将DLL打包成CAB供浏览器下载. 下面制作证书,以及制作cab包需要用到一些工具.我将工具包上传到自己的博客园里了,以供大家下载. ...
- TensorFlow多元线性回归实现
多元线性回归的具体实现 导入需要的所有软件包: 因为各特征的数据范围不同,需要归一化特征数据.为此定义一个归一化函数.另外,这里添加一个额外的固定输入值将权重和偏置结合起来.为此定义函数 appe ...
- CloudHub概述
CloudHub概述 CloudHub CloudHub是cloudcore的一个模块,是Controller和Edge端之间的中转.它同时支持基于websocket的连接以及QUIC协议访问.Edg ...