第七章:网络优化与正则化(Part2)
文章相关
7.3 参数初始化
神经网络的参数学习是一个非凸优化问题.当使用梯度下降法来进行优化网络参数时,参数初始值的选取十分关键,关系到网络的优化效率和泛化能力.
梯度下降法需要在开始训练时给每一个参数赋一个初始值。
- 初始化为0 : 对称权重问题 所有参数为 0 $\longrightarrow$ 神经元的输出相同 $\longrightarrow$ BP梯度相同 $\longrightarrow$ 参数更新相同 $\longrightarrow$ 参数相同
- 初始化太小:梯度消失,使得Sigmoid型激活函数丟失非线性的能力
- 初始化太大:梯度爆炸,使得Sigmoid型激活函数变得饱和
参数初始化的方式通常有以下三种:
- 预训练初始化:不同的参数初始值会收敛到不同的局部最优解.虽然这些局部最优解在训练集上的损失比较接*,但是它们的泛化能力差异很大.一个好的初始值会使得网络收敛到一个泛化能力高的局部最优解.通常情况下,一个已经在大规模数据上训练过的模型可以提供一个好的参数初始值,这种初始化方法称为预训练初始化(Pre-trained Initialization).预训练任务可以为监督学习或无监督学习任务.由于无监督学习任务更容易获取大规模的训练数据,因此被广泛采用.预训练模型在目标任务上的学习过程也称为精调(Fine-Tuning).
- 随机初始化:在线性模型的训练(比如感知器和 Logistic 回归)中,我们一般将参数全部初始化为 0.但是这在神经网络的训练中会存在一些问题.因为如果参数都为 0,在第一遍前向计算时,所有的隐藏层神经元的激活值都相同;在反向传播时,所有权重的更新也都相同,这样会导致隐藏层神经元没有区分性.这种现象也称为对称权重现象.为了打破这个*衡,比较好的方式是对每个参数都随机初始化(Random Initialization),使得不同神经元之间的区分性更好.
- 固定值初始化:对于一些特殊的参数,我们可以根据经验用一个特殊的固定值来进行初始化.比如偏置(Bias)通常用 0 来初始化,但是有时可以设置某些经验值以提高优化效率.在 LSTM 网络的遗忘门中,偏置通常初始化为 1或 2,使得时序上的梯度变大.对于使用 ReLU 的神经元,有时也可以将偏置设为 0.01,使得 ReLU 神经元在训练初期更容易激活,从而获得一定的梯度来进行误差反向传播.
虽然预训练初始化通常具有更好的收敛性和泛化性,但是灵活性不够,不能 在目标任务上任意地调整网络结构.因此,好的随机初始化方法对训练神经网络模型来说依然十分重要.这里我们介绍三类常用的随机初始化方法:基于固定方差的参数初始化、基于方差缩放的参数初始化和正交初始化方法.
7.3.1 基于固定方差的参数初始化
一种最简单的随机初始化方法是从一个固定均值(通常为 0)和方差 $^2$ 的分布中采样来生成参数的初始值.基于固定方差的参数初始化方法主要有以下两种:
- 高斯分布初始化:使用一个高斯分布 $\mathcal{N}\left(0, \sigma^{2}\right)$ 对每个参数进行随机初始化.
- 均匀分布初始化:在一个给定的区间 $[-r, r]$ 内采用均匀分布来初始化参数.假设随机变量 $$在区间 $[, ]$ 内均匀分布,则其方差为
$\operatorname{var}(x)=\frac{(b-a)^{2}}{12}$
因此, 若使用区间为 $[-r, r]$ 的均匀分布来采样, 并满足 $\operatorname{var}(x)=\sigma^{2}$ 时, 则 $r$ 的取值为
$r=\sqrt{3 \sigma^{2}}$
方差
$D(X)=E\{[X-E(X)]^2\}$
$=E\{X^2-2XE(X)+[E(X)]^2\}$
$=E(X^2)-2E(X)E(X)+[E(X)]^2$
$=E(X^2)-[E(X)]^2$均匀分布
设 $X \sim U(a, b)$,其密度函数为
$f(x)=\left\{\begin{array}{c} \frac{1}{b-a}, a<x<b \\ 0, \text { 其他 } \end{array}\right.$
$E(X)=\int_{a}^{b} x \cdot f(x) d x=\int_{a}^{b} \frac{x}{b-a} \cdot d x=\int_{a}^{b} \frac{1}{2(b-a)} d x^{2}=\frac{1}{2(b-a)}\left(b^{2}-a^{2}\right)=\frac{a+b}{2}$
$D(X)=E\left((E(X)-X)^{2}\right)=E\left(E^{2}(X)-2 X \cdot E(X)+X^{2}\right)=E\left(X^{2}\right)-E^{2}(X)$
$=\int_{a}^{b} x^{2} \cdot f(x) d x-\left(\frac{a+b}{2}\right)^{2}$
$=\int_{a}^{b} \frac{x^{2}}{b-a} d x-\left(\frac{a+b}{2}\right)^{2}=\int_{a}^{b} \frac{1}{3(b-a)} d x^{3}-\left(\frac{a+b}{2}\right)^{2}=\frac{1}{3} \frac{b^{3}-a^{3}}{(b-a)}-\left(\frac{a+b}{2}\right)^{2}$
$=\frac{a^{2}+a b+b^{2}}{3}-\left(\frac{a+b}{2}\right)^{2}=\frac{4 a^{2}+4 a b+4 b^{2}-3 a^{2}-6 a b-3 b^{2}}{12}=\frac{a^{2}-2 a b+b^{2}}{12}$
$=\frac{(a-b)^{2}}{12}$
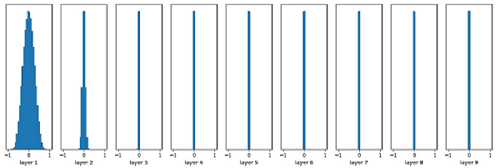
在基于固定方差的随机初始化方法中,比较关键的是如何设置方差 $^2$ .如果参数范围取的太小,一是会导致神经元的输出过小,经过多层之后信号就慢慢消 失了;二是还会使得 Sigmoid 型激活函数丢失非线性的能力.以 Sigmoid 型函数 为例,在 $0$ 附*基本上是*似线性的.这样多层神经网络的优势也就不存在了.如果参数范围取的太大,会导致输入状态过大.对于 Sigmoid 型激活函数来说,激活值变得饱和,梯度接*于 $0$,从而导致梯度消失问题.
为了降低固定方差对网络性能以及优化效率的影响,基于固定方差的随机 初始化方法一般需要配合逐层归一化来使用.
7.3.2 基于方差缩放的参数初始化
要高效地训练神经网络,给参数选取一个合适的随机初始化区间是非常重 要的.一般而言,参数初始化的区间应该根据神经元的性质进行差异化的设置. 如果一个神经元的输入连接很多,它的每个输入连接上的权重就应该小一些, 以避免神经元的输出过大(当激活函数为 ReLU 时)或过饱和(当激活函数为 Sigmoid 函数时).
初始化一个深度网络时,为了缓解梯度消失或爆炸问题,我们尽可能保持每个神经元的输入和输出的方差一致,根据神经元的连接数量来自适应地调整初始化分布的方差,这类方法称为方差缩放(Variance Scaling).

7.3.2.1 Xavier 初始化
假设在一个神经网络中, 第 $l$ 层的一个神经元 $ a^{(l)}$ , 其接收前一层的 $ M_{l-1}$ 个 神经元的输出 $ a_{i}^{(l-1)}$, $1 \leq i \leq M_{l-1}$ ,
$a^{(l)}=f\left(\sum \limits _{i=1}^{M_{l-1}} w_{i}^{(l)} a_{i}^{(l-1)}\right)$
其中 $f(\cdot)$ 为激活函数, $w_{i}^{(l)}$ 为参数, $M_{l-1}$ 是第 $l-1$ 层神经元个数. 为简单起见, 这里令激活函数 $f(\cdot)$ 为恒等函数, 即 $f(x)=x $.
假设 $w_{i}^{(l)}$ 和 $a_{i}^{(l-1)}$ 的均值都为 $0$ , 并且互相独立, 则 $ a^{(l)} $ 的均值为
$\mathbb{E}\left[a^{(l)}\right]=\mathbb{E}\left[\sum \limits _{i=1}^{M_{l-1}} w_{i}^{(l)} a_{i}^{(l-1)}\right]=\sum \limits _{i=1}^{M_{l-1}} \mathbb{E}\left[w_{i}^{(l)}\right] \mathbb{E}\left[a_{i}^{(l-1)}\right]=0$
$a^{(l)} $的方差为
$\begin{aligned} \operatorname{var}\left(a^{(l)}\right) &=\operatorname{var}\left(\sum_{i=1}^{M_{l-1}} w_{i}^{(l)} a_{i}^{(l-1)}\right) \\ &=\sum_{i=1}^{M_{l-1}} \operatorname{var}\left(w_{i}^{(l)}\right) \operatorname{var}\left(a_{i}^{(l-1)}\right) \\ &=M_{l-1} \operatorname{var}\left(w_{i}^{(l)}\right) \operatorname{var}\left(a_{i}^{(l-1)}\right) . \end{aligned}$
也就是说, 输入信号的方差在经过该神经元后被放大或缩小了 $M_{l-1} \operatorname{var}\left(w_{i}^{(l)}\right) $ 倍. 为了使得在经过多层网络后, 信号不被过分放大或过分减弱, 我们尽可能保持每个神经元的输入和输出的方差一致. 这样 $M_{l-1} \operatorname{var}\left(w_{i}^{(l)}\right)$ 设为 1 比较合理,即
$\operatorname{var}\left(w_{i}^{(l)}\right)=\frac{1}{M_{l-1}}$
同理, 为了使得在反向传播中, 误差信号也不被放大或缩小,需要将 $w_{i}^{(l)}$ 的 方差保持为
$\operatorname{var}\left(w_{i}^{(l)}\right)=\frac{1}{M_{l}}$
作为折中,同时考虑信号在前向和反向传播中都不被放大或缩小,可以设置
$\operatorname{var}\left(w_{i}^{(l)}\right)=\frac{2}{M_{l-1}+M_{l}}$
在计算出参数的理想方差后, 可以通过高斯分布或均匀分布来随机初始化参数.
- 若采用高斯分布来随机初始化参数, 连接权重 $w_{i}^{(l)} $ 可以按 $\mathcal{N}\left(0, \frac{2}{M_{l-1}+M_{l}}\right) $ 的高斯分布进行初始化.
- 若采用区间为 $[-r, r]$ 的均匀分布来初始化 $w_{i}^{(l)} $, 则 $r$ 的 取值为 $\sqrt{\frac{6}{M_{l-1}+M_{l}}} $.
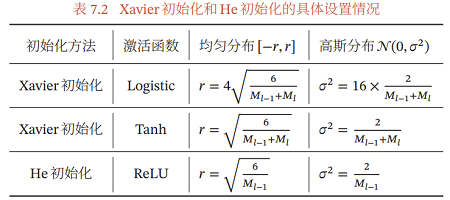
虽然在 $\mathrm{Xavier}$ 初始化中我们假设激活函数为恒等函数, 但是 $\mathrm{Xavier }$ 初始代也适用于 $\mathrm{Logistic}$ 函数和 $\mathrm{Tanh}$ 函数. 这是因为神经元的参数和输入的绝对值通常比较小,处于激活函数的线性区间. 这时 $\mathrm{Logistic}$ 函数和 $\mathrm{Tanh }$函数可以*似为线性函数.
由于 $\mathrm{Logistic}$ 函数在线性区间的斜率约为 0.25 , 因此其参数初始化的方差约为 $16 \times \frac{2}{M_{l-1}+M_{l}} $. 在实际应用中,使用 $\mathrm{Logistic}$ 函数或 $\mathrm{Tanh}$ 函数的神经层 通常将方差 $\frac{2}{M_{l-1}+M_{l}}$ 乘以一个缩放因子 $\rho$ .
解释:$\mathrm{Logistic}$ 函数
$a^{(l)} =\frac{1}{16}M_{l-1} \operatorname{var}\left(w_{i}^{(l)}\right) \operatorname{var}\left(a_{i}^{(l-1)}\right)$
则
$\operatorname{var}\left(w_{i}^{(l)}\right)=\frac{16}{M_{l-1}}$
$\operatorname{var}\left(w_{i}^{(l)}\right)=\frac{16}{M_{l}}$
故
$\operatorname{var}\left(w_{i}^{(l)}\right)=\frac{2 \times 16}{M_{l-1}+M_{l}}$
补充
$\text { 1. } D(C)=E\left\{[C-E(C)]^{2}\right\}=0 $
$\text { 2. } D(C X)=E\left\{[C X-E(C X)]^{2}\right\}=C^{2} E\left\{[X-E(X)]^{2}\right\}=C^{2} D(X) $
$\text { 3. } D(X+C)=E\left\{[X+C-E(X+C)]^{2}\right\}=E\left\{[X-E(X)]^{2}\right\}=D(X) $
$\text { 4. } D(X \pm Y)=E\left\{[(X \pm Y)-E(X \pm Y)]^{2}\right\}=E\left\{[(X-E(X)) \pm(Y-E(Y))]^{2}\right\} $
$\quad \quad=E\left\{(X-E(X))^{2}\right\}+E\left\{(Y-E(Y))^{2}\right\} \pm 2 E\{[X-E(X)][Y-E(Y)]\}$
7.3.2.2 He初始化
当第 $l$ 层神经元使用 $\operatorname{ReLU}$ 激活函数时,通常有一半的神经元输出为 $0$ , 因此 其分布的方差也*似为使用恒等函数时的一半. 这样,只考虑前向传播时, 参数 $w_{i}^{(l)}$ 的理想方差为
$\operatorname{var}\left(w_{i}^{(l)}\right)=\frac{2}{M_{l-1}}$
其中 $M_{l-1} $是第 $l-1$ 层神经元个数.
因此当使用 ReLU 激活函数时,
- 若采用高斯分布来初始化参数 $w_{i}^{(l)}$ , 其方差为 $\frac{2}{M_{l-1}}$ ;
- 若采用区间为 $ [-r, r] $ 的均匀分布来初始化参数 $w_{i}^{(l)} $ , 则 $ r=\sqrt{\frac{6}{M_{l-1}}} $.
这种初始化方法称为 He初始化[He et al., 2015].
表7.2给出了Xavier初始化和 He初始化的具体设置情况.
7.3.3 正交初始化
上面介绍的两种基于方差的初始化方法都是对权重矩阵中的每个参数进行独立采样.由于采样的随机性,采样出来的权重矩阵依然可能存在梯度消失或梯度爆炸问题.
假设一个 $$ 层的等宽线性网络(激活函数为恒等函数)为
$\boldsymbol{y}=\boldsymbol{W}^{(L)} \boldsymbol{W}^{(L-1)} \cdots \boldsymbol{W}^{(1)} \boldsymbol{x}$
其中 $ \boldsymbol{W}^{(l)} \in \mathbb{R}^{M \times M}(1 \leq l \leq L) $ 为神经网络的第 $l$ 层权重矩阵. 在反向传播中, 误差项 $\delta$ 的反向传播公式为 $\delta^{(l-1)}=\left(\boldsymbol{W}^{(l)}\right)^{\top} \delta^{(l)} $.
为了避免梯度消失或梯度爆炸问题,我们希望误差项在反向传播中具有范数保持性$ ( Norm-Preserving )$, 即 $\left\|\delta^{(l-1)}\right\|^{2}=\left\|\delta^{(l)}\right\|^{2}=\left\|\left(\boldsymbol{W}^{(l)}\right)^{\top} \delta^{(l)}\right\|^{2} $.
如果我们以均值为 $0$ 、方差为 $\frac{1}{M} $ 的高斯分布来随机生成权重矩阵 $\boldsymbol{W}^{(l)} $中每个元素的初始值,那么当 $M \rightarrow \infty$ 时,范数保持性成立.但是当 不足够大时,这种对每个参数进行独立采样的初始化方式难以保证范数保持性.
因此,一种更加直接的方式是将 $ ()$ 初始化为正交矩阵,即 $ () ( () )^T = $,这种方法称为正交初始化(Orthogonal Initialization)[Saxe et al., 2014].
正交初始化的具体实现过程可以分为两步:
- 用均值为 0、方差为 1 的高斯分布初始化一个矩阵;
- 将这个矩阵用奇异值分解得到两个正交矩阵,并使用其中之一作为权重矩阵.
根据正交矩阵的性质,这个线性网络在信息的前向传播过程和误差的反向 传播过程中都具有范数保持性,从而可以避免在训练开始时就出现梯度消失或 梯度爆炸现象.
当在非线性神经网络中应用正交初始化时, 通常需要将正交矩阵乘以一个 缩放系数 $\rho$ . 比如当激活函数为 $\operatorname{ReLU}$ 时,激活函数在 $0$ 附*的*均梯度可以*似 为 $0.5$ . 为了保持范数不变,缩放系数 $\rho$ 可以设置为 $\sqrt{2}$ .
• 用均值为 0 、方差为 1 的高斯分布初始化一个矩阵;
• 将这个矩阵用奇异值分解得到两个正交矩阵,并使用其中之一作为权重矩阵。
7.4 数据预处理
一般而言,样本特征由于来源以及度量单位不同,它们的尺度(Scale)(即 取值范围)往往差异很大.以描述长度的特征为例,当用“米”作单位时令其值为 $$,那么当用“厘米”作单位时其值为 $100$.不同机器学习模型对数据特征尺度的敏感程度不一样.
如果一个机器学习算法在缩放全部或部分特征后不影响它的学习和预测,我们就称该算法具有尺度不变性(Scale Invariance).比如线性分类器是尺度不变的,而最*邻分类器就是尺度敏感的.当我们计算不同样本之间的欧氏距离时,尺度大的特征会起到主导作用.因此,对于尺度敏感的模型,必须先对样本进行预处理,将各个维度的特征转换到相同的取值区间,并且消除不同特征之间的相关性,才能获得比较理想的结果.
从理论上,神经网络应该具有尺度不变性,可以通过参数的调整来适应不同特征的尺度. 但尺度不同的输入特征会增加训练难度. 假设一个只有一层的网络 $y=\tanh \left(w_{1} x_{1}+w_{2} x_{2}+b\right) $, 其中 $x_{1} \in[0,10], x_{2} \in[0,1]$ . 之前我们提到 tanh 函数的导数在区间 $ [-2,2]$ 上是敏感的,其余的导数接*于 0 。因此,如果 $ w_{1} x_{1}+w_{2} x_{2}+b$ 过大或过小,都会导致梯度过小,难以训练。 为了提高训练效率,我们需要使 $ w_{1} x_{1}+w_{2} x_{2}+b$ 在 $ [-2,2]$ 区间,因此需要将 $ w_{1}$ 设得小一点,比如在 $ [-0.1,0.1]$ 之间。可以想象,如果数据维数很多时,我们很难这样精心去选择每一 个参数。因此,如果每一个特征的尺度相似,比如 $ [0,1] $ 或者 $ [-1,1]$,我们就不太需要区别对待每一个参数,从而减少人工干预。
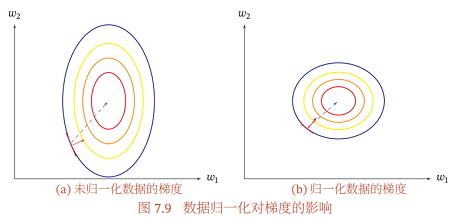
除了参数初始化比较困难之外,不同输入特征的尺度差异比较大时,梯度下降法的效率也会受到影响。图7.9给出了数据归一化对梯度的影响。其中, 图7.9a为未归一化数据的等高线图。尺度不同会造成在大多数位置上的梯度方向并不是最优的搜索方向。当使用梯度下降法寻求最优解时,会导致需要很多次迭 代才能收敛。如果我们把数据归一化为相同尺度,如图7.9b所示,大部分位置的梯度方向*似于最优搜索方向。这样,在梯度下降求解时,每一步梯度的方向都 基本指向最小值,训练效率会大大提高.
归一化(Normalization)方法泛指把数据特征转换为相同尺度的方法,比如把数据特征映射到 $[0, 1]$ 或 $[−1, 1]$ 区间内,或者映射为服从均值为 0、方差为 1 的标准正态分布.归一化的方法有很多种,比如之前我们介绍的 Sigmoid 型函数 等都可以将不同尺度的特征挤压到一个比较受限的区间.这里,我们介绍几种在神经网络中经常使用的归一化方法.
最小最大值归一化 $\quad$ ( Min-Max Normalization ) 是一种非常简单的归一化方法,通过缩放将每一个特征的取值范围归一到 $[0,1]$ 或 $[-1,1]$ 之间. 假设有 $N$ 个样本 $\left\{\boldsymbol{x}^{(n)}\right\}_{n=1}^{N}$ , 对于每一维特征 $x$ , 归一化后的特征为
$\hat{x}^{(n)}=\frac{x^{(n)}-\min _{n}\left(x^{(n)}\right)}{\max _{n}\left(x^{(n)}\right)-\min _{n}\left(x^{(n)}\right)}$
其中 $\min (x)$ 和 $\max (x)$ 分别是特征 $x$ 在所有样本上的最小值和最大值.
标准化 $\quad$ ( Standardization ) 也叫Z值归一化 ( Z-Score Normalization ), 来源于统计上的标准分数. 将每一个维特征都调整为均值为 0 , 方差为 1 . 假设有 $ N$ 个样本 $\left\{\boldsymbol{x}^{(n)}\right\}_{n=1}^{N}$ , 对于每一维特征 $ x$ , 我们先计算它的均值和方差:
$\begin{aligned} \mu &=\frac{1}{N} \sum_{n=1}^{N} x^{(n)} \\ \sigma^{2} &=\frac{1}{N} \sum_{n=1}^{N}\left(x^{(n)}-\mu\right)^{2} \end{aligned} $
然后,将特征 $x^{(n)}$ 减去均值,并除以标准差,得到新的特征值 $\hat{x}^{(n)} $:
$\hat{x}^{(n)}=\frac{x^{(n)}-\mu}{\sigma}$
其中标准差 $\sigma$ 不能为 $0$。 如果标准差为 $0 $, 说明这一维特征没有任何区分性, 可以直接删掉.
白化 $\quad$ (Whitening)是一种重要的预处理方法,用来降低输入数据特征之间的冗余性。输入数据经过白化处理后,特征之间相关性较低,并且所有特征具有相同的方差.白化的一个主要实现方式是使用主成分分析(Principal Compo- nent Analysis,PCA)方法去除掉各个成分之间的相关性。
- PCA白化:先PCA进行基转换,降低数据的相关性,再对每个输入特征进行缩放(除以各自的特征值的开方),以获得单位方差。此时的协方差矩阵为单位矩阵。
- ZCA白化:ZCA白化只是在PCA白化的基础上做了一个逆映射操作,使数据转换为原始基下,使得白化之后的数据更加的接*原始数据。
图7.10给出了标准归一化和 PCA 白化的比较.

预处理策略 depends on 应用场景
- 自然灰度图像:均值消减->PCS/ZCA白化
- 彩色图像:简单缩放->PCA/ZCA白化
- 音频 (MFCC/频谱图):特征标准化->PCA/ZCA 白化
- MNIST 手写数字:简单缩放/逐样本均值消减(->PCA/ZCA 白化)
7.5 逐层归一化
逐层归一化(Layer-wise Normalization)是将传统机器学习中的数据归一化方法应用到深度神经网络中,对神经网络中隐藏层的输入进行归一化,从而使得网络更容易训练.
逐层归一化可以有效提高训练效率的原因有以下几个方面:
- 更好的尺度不变性:在深度神经网络中,一个神经层的输入是之前神经层的输出。给定一个神经层 $$,它之前的神经层 $ (1, ⋯ , − 1) $ 的参数变化会导 致其输入的分布发生较大的改变。当使用随机梯度下降来训练网络时,每次参数更新都会导致该神经层的输入分布发生改变。越高的层,其输入分布会改变得越明显.就像一栋高楼,低楼层发生一个较小的偏移,可能会导致高楼层较大的偏移。从机器学习角度来看,如果一个神经层的输入分布发生了改变,那么其参数需要重新学习,这种现象叫作内部协变量偏移(Internal Covariate Shift)。为了缓解这个问题,我们可以对每一个神经层的输入进行归一化操作,使其分布保持稳定。把每个神经层的输入分布都归一化为标准正态分布,可以使得每个神经层对其输入具有更好的尺度不变性。不论低层的参数如何变化,高层的输入保持相对稳定。另外,尺度不变性可以使得我们更加高效地进行参数初始化以及超参选择。
- 更*滑的优化地形:逐层归一化一方面可以使得大部分神经层的输入处于不饱和区域,从而让梯度变大,避免梯度消失问题;另一方面还可以使得神经网络的优化地形(Optimization Landscape)更加*滑,以及使梯度变得更加稳定,从而允许我们使用更大的学习率,并提高收敛速度 [Bjorck et al., 2018; Santurkar et al., 2018].
下面介绍几种比较常用的逐层归一化方法:批量归一化、层归一化、权重归一化和局部响应归一化.
7.5.1 批量归一化
批量归一化(Batch Normalization,BN)方法 [Ioffe et al., 2015] 是一种有效的逐层归一化方法,可以对神经网络中任意的中间层进行归一化操作。
对于一个深度神经网络,令第 $l$ 层的净输入为 $\boldsymbol{z}^{(l)}$ ,神经元的输出为 $\boldsymbol{a}^{(l)} $,即
$\boldsymbol{a}^{(l)}=f\left(\boldsymbol{z}^{(l)}\right)=f\left(\boldsymbol{W} \boldsymbol{a}^{(l-1)}+\boldsymbol{b}\right)$
其中 $f(\cdot)$ 是激活函数,$\boldsymbol{W}$ 和 $\boldsymbol{b}$ 是可学习的参数。
为了提高优化效率, 就要使得净输入 $ \boldsymbol{z}^{(l)}$ 的分布一致, 比如都归一化到标准正态分布。虽然归一化操作也可以应用在输入 $ \boldsymbol{a}^{(l-1)}$ 上,但归一化 $\boldsymbol{z}^{(l)}$ 更加有利于优化。 因此,在实践中归一化操作一般应用在仿射变换(Affine Transformation ) $\boldsymbol{W} \boldsymbol{a}^{(l-1)}+\boldsymbol{b}$ 之后、激活函数之前.
利用第7.4节中介绍的数据预处理方法对 $ \boldsymbol{z}^{(l)} $ 进行归一化。相当于每一层都进行一次数据预处理。从而加速收敛速度、但是逐层归一化需要在中间层进行操作, 要求效率比较高,因此复杂度比较高的白化方法就不太合适。为了提高归一化效率,一般使用标准化将净输入 $\boldsymbol{z}^{(l)} $ 的每一维都归一到标准正态分布。
利用第7.4节中介绍的数据预处理方法对 $\boldsymbol{z}^{(l)} $ 进行归一化,相当于每一层都进行一次数据预处理,从而加速收敛速度。但是逐层归一化需要在中间层进行操作,要求效率比较高,因此复杂度比较高的白化方法就不太合适。 为了提高归一化效率,一般使用标准化将净输入 $\boldsymbol{z}^{(l)}$ 的每一维都归一到标准正态分布。
$\hat{\boldsymbol{z}}^{(l)}=\frac{\boldsymbol{z}^{(l)}-\mathbb{E}\left[\boldsymbol{z}^{(l)}\right]}{\sqrt{\operatorname{var}\left(\boldsymbol{z}^{(l)}\right)+\epsilon}}$
其中 $\mathbb{E}\left[\boldsymbol{z}^{(l)}\right]$ 和 $\operatorname{var}\left(\boldsymbol{z}^{(l)}\right) $是指当前参数下, $\boldsymbol{z}^{(l)}$ 的每一维在整个训练集上的期望和方差。因为目前主要的优化算法是基于小批量的随机梯度下降法,所以准确地计算 $ \boldsymbol{z}^{(l)}$ 的期望和方差是不可行的。因此, $ \boldsymbol{z}^{(l)} $ 的期望和方差通常用当前小批量样本集的均值和方差*似估计。
给定一个包含 $K$ 个样本的小批量样本集合,第 $ l$ 层神经元的净输入$\boldsymbol{z}^{(1, l)},\cdots, \boldsymbol{z}^{(K, l)}$ 的均值和方差为
$\begin{aligned} \mu_{\mathcal{B}} &=\frac{1}{K} \sum_{k=1}^{K} \boldsymbol{z}^{(k, l)} \\ \boldsymbol{\sigma}_{\mathcal{B}}^{2} &=\frac{1}{K} \sum_{k=1}^{K}\left(\boldsymbol{z}^{(k, l)}-\boldsymbol{\mu}_{\mathcal{B}}\right) \odot\left(\boldsymbol{z}^{(k, l)}-\boldsymbol{\mu}_{\mathcal{B}}\right) . \end{aligned}$
对净输入 $\boldsymbol{z}^{(l)}$ 的标准归一化会使得其取值集中到 $0$ 附*,如果使用 $\mathrm{Sigmoid} $ 型激活函数时,这个取值区间刚好是接*线性变换的区间,减弱了神经网络的非线性性质。因此,为了使得归一化不对网络的表示能力造成负面影响,可以通过一个附加的缩放和*移变换改变取值区间。
$\begin{aligned} \hat{\boldsymbol{z}}^{(l)} &=\frac{\boldsymbol{z}^{(l)}-\boldsymbol{\mu}_{\mathcal{B}}}{\sqrt{\sigma_{\mathcal{B}}^{2}+\epsilon}} \odot \gamma+\beta \\ & \triangleq \mathrm{BN}_{\gamma, \boldsymbol{\beta}}\left(\boldsymbol{z}^{(l)}\right) \end{aligned}$
其中 $\gamma$ 和 $\beta$ 分别代表缩放和*移的参数向量。从最保守的角度考虑,可以通过标准归一化的逆变换来使得归一化后的变量可以被还原为原来的值。当$\gamma=\sqrt{\sigma_{\mathcal{B}}^{2}}$ , $\beta=\mu_{\mathcal{B}}$ 时, $\hat{\boldsymbol{z}}^{(l)}=\boldsymbol{z}^{(l)} $。
批量归一化操作可以看作一个特殊的神经层,加在每一层非线性激活函数之前,即
$\boldsymbol{a}^{(l)}=f\left(\mathrm{~B} \mathrm{~N}_{\gamma, \boldsymbol{\beta}}\left(\boldsymbol{z}^{(l)}\right)\right)=f\left(\mathrm{BN}_{\gamma, \boldsymbol{\beta}}\left(\boldsymbol{W} \boldsymbol{a}^{(l-1)}\right)\right)$
其中因为批量归一化本身具有*移变换,所以仿射变换 $\boldsymbol{W} \boldsymbol{a}^{(l-1)} $ 不再需要偏置参数。
这里要注意的是,每次小批量样本的 $\mu_{\mathcal{B}}$ 和方差 $\sigma_{\mathcal{B}}^{2}$ 是净输入 $\boldsymbol{z}^{(l)}$ 的函数,而不是常量。 因此在计算参数梯度时需要考虑 $\mu_{\mathcal{B}} $ 和 $\sigma_{\mathcal{B}}^{2} $ 的影响。当训练完成时, 用 整个数据集上的均值 $\mu $和方差 $\sigma$ 来分别代替每次小批量样本的 $\mu_{\mathcal{B}}$ 和方差 $\sigma_{\mathcal{B}}^{2}$。在 实践中,$\mu_{\mathcal{B}}$ 和 $\sigma_{\mathcal{B}}^{2}$ 也可以用移动*均来计算。
值得一提的是,逐层归一化不但可以提高优化效率,还可以作为一种隐形的正则化方法。在训练时,神经网络对一个样本的预测不仅和该样本自身相关,也和同一批次中的其他样本相关。由于在选取批次时具有随机性,因此使得神经网 络不会“过拟合”到某个特定样本,从而提高网络的泛化能力 [Luo et al., 2018]。
7.5.2 层归一化
批量归一化是对一个中间层的单个神经元进行归一化操作,因此要求小批量样本的数量不能太小,否则难以计算单个神经元的统计信息.此外,如果一个神经元的净输入的分布在神经网络中是动态变化的,比如循环神经网络,那么就无法应用批量归一化操作。
层归一化(Layer Normalization)[Ba et al., 2016] 是和批量归一化非常类似的方法。和批量归一化不同的是,层归一化是对一个中间层的所有神经元进行归一化。
$\mu^{(l)}=\frac{1}{M_{l}} \sum \limits _{i=1}^{M_{l}} z_{i}^{(l)}$
$\sigma^{(l)^{2}}=\frac{1}{M_{l}} \sum \limits_{i=1}^{M_{l}}\left(z_{i}^{(l)}-\mu^{(l)}\right)^{2}$
其中 $_$ 为第 $$ 层神经元的数量。
层归一化定义为
$\hat{\boldsymbol{z}}^{(l)}=\frac{\boldsymbol{z}^{(l)}-\mu^{(l)}}{\sqrt{{\sigma}^{(l)^{2}}+\epsilon}} \odot \gamma+\beta$
$\triangleq \mathrm{L} \mathrm{N}_{\gamma, \beta}\left(\boldsymbol{z}^{(l)}\right)$
其中 $\gamma$ 和 $\beta$ 分别代表缩放和*移的参数向量,和 $\boldsymbol{z}^{(l)}$ 维数相同。
循环神经网络中的层归一化:层归一化可以应用在循环神经网络中,对循环神经层进行归一化操作。假设在时刻 $t$ , 循环神经网络的隐藏层为 $ \boldsymbol{h}_{t}$ , 其层归一化的 更新为
$\boldsymbol{z}_{t}=\boldsymbol{U} \boldsymbol{h}_{t-1}+\boldsymbol{W} \boldsymbol{x}_{t} $
$\boldsymbol{h}_{t}=f\left(\mathrm{LN}_{\boldsymbol{\gamma}, \boldsymbol{\beta}}\left(\boldsymbol{z}_{t}\right)\right)$
其中输入为 $\boldsymbol{x}_{t}$ 为第 $t$ 时刻的输入, $\boldsymbol{U}$ 和 $\boldsymbol{W} $ 为网络参数。
在标准循环神经网络中, 循环神经层的净输入一般会随着时间慢慢变大或变小,从而导致梯度爆炸或消失。 而层归一化的循环神经网络可以有效地缓解这种状况.
层归一化和批量归一化整体上是十分类似的,差别在于归一化的方法不同。对于 $K$ 个样本的一个小批量集合 $\boldsymbol{Z}^{(l)}=\left[\boldsymbol{z}^{(1, l)} ; \cdots ; \boldsymbol{z}^{(K, l)}\right] $,层归一化是对矩阵 $\boldsymbol{Z}^{(l)}$ 的每一列进行归一化,而批量归一化是对每一行进行归一化。一般而言,批量归一化是一种更好的选择。 当小批量样本数量比较小时,可以选择层归一化。
7.5.3 权重归一化
权重归一化 ( Weight Normalization ) [Salimans et al., 2016] 是对神经网络的连接权重进行归一化,通过再参数化 ( Reparameterization ) 方法, 将连接权重分解为长度和方向两种参数。假设第 $l$ 层神经元 $\boldsymbol{a}^{(l)}=f\left(\boldsymbol{W} \boldsymbol{a}^{(l-1)}+\boldsymbol{b}\right)$,我们将 $\boldsymbol{W} $ 再参数化为
$\boldsymbol{W}_{i,:}=\frac{g_{i}}{\left\|\boldsymbol{v}_{i}\right\|} \boldsymbol{v}_{i}, \quad 1 \leq i \leq M_{l}$
其中 $ \boldsymbol{W}_{i}$ 表示权重 $ \boldsymbol{W}$ 的第 $ i$ 行, $ M_{l} $ 为神经元数量。 新引入的参数 $ g_{i}$ 为标量,$ \boldsymbol{v}_{i}$ 和 $ \boldsymbol{a}^{(l-1)}$ 维数相同。
由于在神经网络中权重经常是共享的,权重数量往往比神经元数量要少,因此权重归一化的开销会比较小。
7.5.4 局部响应归一化
局部响应归一化 ( Local Response Normalization,LRN ) [Krizhevsky et al., 2012] 是一种受生物学启发的归一化方法,通常用在基于卷积的图像处理上. 假设一个卷积层的输出特征映射 $\boldsymbol{Y} \in \mathbb{R}^{M^{\prime} \times N^{\prime} \times P}$ 为三维张量,其中每个切片矩阵 $ \boldsymbol{Y}^{p} \in \mathbb{R}^{M^{\prime} \times N^{\prime}} $ 为一个输出特征映射, $ 1 \leq p \leq P$ .
局部响应归一化是对邻*的特征映射进行局部归一化.
$\begin{aligned} \hat{\boldsymbol{Y}}^{p} &=\boldsymbol{Y}^{p} /\left(k+\alpha \sum_{j=\max \left(1, p-\frac{n}{2}\right)}^{\min \left(P, p+\frac{n} {2}\right)}\left(\boldsymbol{Y}^{j}\right)^{2}\right)^{\beta} \\ & \triangleq \operatorname{LRN}_{n, k, \alpha, \beta}\left(\boldsymbol{Y}^{p}\right) \end{aligned}$
其中除和幂运算都是按元素运算, $ n$, $k$, $\alpha$, $\beta$ 为超参, $ n$ 为局部归一化的特征窗口 大小. 在 $ \mathrm{AlexNet}$ 中,这些超参的取值为 $ n=5$, $k=2$, $\alpha=10 \mathrm{e}^{-4}$, $\beta=0.75$ .
局部响应归一化和层归一化都是对同层的神经元进行归一化. 不同的是,局 部响应归一化应用在激活函数之后, 只是对邻*的神经元进行局部归一化, 并且不减去均值.
局部响应归一化和生物神经元中的侧抑制(lateral inhibition)现象比较类 似,即活跃神经元对相邻神经元具有抑制作用.当使用 ReLU 作为激活函数时,神 经元的活性值是没有限制的,局部响应归一化可以起到*衡和约束作用。如果一 个神经元的活性值非常大,那么和它邻*的神经元就*似地归一化为 0,从而起 到抑制作用,增强模型的泛化能力。最大汇聚也具有侧抑制作用。但最大汇聚是对同一个特征映射中的邻*位置中的神经元进行抑制,而局部响应归一化是对 同一个位置的邻*特征映射中的神经元进行抑制。
7.6 超参数优化
在神经网络中,除了可学习的参数之外,还存在很多超参数。这些超参数对网络性能的影响也很大。不同的机器学习任务往往需要不同的超参数.常见的超参数有以下三类:
- 网络结构,包括神经元之间的连接关系、层数、每层的神经元数量、激 活函数的类型等。
- 优化参数,包括优化方法、学习率、小批量的样本数量等。
- 正则化系数。
超参数优化(Hyperparameter Optimization)主要存在两方面的困难:
- 超参数优化是一个组合优化问题,无法像一般参数那样通过梯度下降方法来优化,也没有一种通用有效的优化方法;
- 评估一组超参数配置(Configuration) 的时间代价非常高,从而导致一些优化方法(比如演化算法(Evolution Algo- rithm))在超参数优化中难以应用.
假设一个神经网络中总共有 $K$ 个超参数,每个超参数配置表示为一个向量 $\boldsymbol{x} \in X, X \subset \mathbb{R}^{K} $ 是超参数配置的取值空间. 超参数优化的目标函数定义为 $f(\boldsymbol{x}): x \rightarrow \mathbb{R}, f(\boldsymbol{x})$ 是衡量一组超参数配置 $\boldsymbol{x}$ 效果的函数, 一般设置为开发集上的错误率. 目标函数 $f(\boldsymbol{x}) $可以看作一个黑盒 ( black-box ) 函数,不需要知道其具体形式. 虽然在神经网络的超参数优化中, $f(\boldsymbol{x})$ 的函数形式已知,但 $f(\boldsymbol{x})$ 不是关于 $\boldsymbol{x} $的连续函数, 并且 $\boldsymbol{x}$ 不同, $f(\boldsymbol{x})$ 的函数形式也不同, 因此无法使用梯度下降等优化方法.
对于超参数的配置,比较简单的方法有网格搜索、随机搜索、贝叶斯优化、动态资源分配和神经架构搜索.
7.6.1 网格搜索
网格搜索 ( Grid Search ) 是一种通过尝试所有超参数的组合来寻址合适一组超参数配置的方法。假设总共有 $K$ 个超参数,第 $k$ 个超参数的可以取 $m_{k}$ 个值. 那么总共的配置组合数量为 $m_{1} \times m_{2} \times \cdots \times m_{K}$。 如果超参数是连续的,可以将超参数离散化,选择几个“经验”值。比如学习率 $\alpha$ , 我们可以设置
$\alpha \in\{0.01,0.1,0.5,1.0\}$
一般而言,对于连续的超参数,我们不能按等间隔的方式进行离散化, 需要根据超参数自身的特点进行离散化。
网格搜索根据这些超参数的不同组合分别训练一个模型,然后测试这些模 型在验证集上的性能,选取一组性能最好的配置。
7.6.2 随机搜索
不同超参数对模型性能的影响有很大差异.有些超参数(比如正则化系数) 对模型性能的影响有限,而另一些超参数(比如学习率)对模型性能影响比较大。在这种情况下,采用网格搜索会在不重要的超参数上进行不必要的尝试。一 种在实践中比较有效的改进方法是对超参数进行随机组合,然后选取一个性能最好的配置,这就是随机搜索(Random Search)[Bergstra et al., 2012]。随机搜索在实践中更容易实现,一般会比网格搜索更加有效。
网格搜索和随机搜索都没有利用不同超参数组合之间的相关性,即如果模型的超参数组合比较类似,其模型性能也是比较接*的。因此这两种搜索方式一般都比较低效。下面我们介绍两种自适应的超参数优化方法:贝叶斯优化和动态资源分配。
7.6.3 贝叶斯优化
贝叶斯优化(Bayesian optimization)[Bergstra et al.,2011;Snoek et al.,2012]是一种自适应的超参数优化方法,根据当前已经试验的超参数组合,来预测下一个可能带来最大收益的组合。
一种比较常用的贝叶斯优化方法为时序模型优化(Sequential Model-Based Optimization,SMBO)[Hutter et al., 2011]。
假设超参数优化的函数 $()$ 服从高斯过程,则 $(()|) $ 为一个正态分布。贝叶斯优化过程是根据已有的 $$ 组试验结果 $\mathcal{H}=\{\boldsymbol{x}_{n}, y_{n}\}_{n=1}^{N}(y_{n}$ 为 $f(\boldsymbol{x}_{n})$ 的观测值 $)$ 来建模高斯过程,并计算 $()$ 的后验分布 $p_{\mathcal{SP}}(f(\boldsymbol{x}) \mid \boldsymbol{x}, \mathcal{H})$。
为了使得 $p_{\mathcal{SP}}(f(\boldsymbol{x}) \mid \boldsymbol{x}, \mathcal{H})$接*其真实分布,就需要对样本空间进行足够多的采样。但是超参数优化中每一个样本的生成成本很高,需要用尽可能少的样本来使得 $p_{\theta}(f(\boldsymbol{x}) \mid \boldsymbol{x}, \mathcal{H})$ 接*于真实分布。因此,需要通过定义一个收益函数(Acquisition Function)$a(x, \mathcal{H})$ 来判断一个样本是否能够给建模$p_{\theta}(f(\boldsymbol{x}) \mid \boldsymbol{x}, \mathcal{H})$ 提供更多的收益。收益越大,其修正的高斯过程会越接*目标函数的真实分布。收益函数来判断一个样本是否能够给建模后验概率提供更多的收益,收益函数的定义有很多种方式,一个常用的是期望改善。

7.6.4 动态资源分配
在超参数优化中,每组超参数配置的评估代价比较高。如果我们可以在较早的阶段就估计出一组配置的效果会比较差,那么我们就可以中止这组配置的评估,将更多的资源留给其他配置。这个问题可以归结为多臂赌博机问题的一个泛化问题:最优臂问题(Best-Arm Problem),即在给定有限的机会次数下,如何玩这些赌博机并找到收益最大的臂。和多臂赌博机问题类似,最优臂问题也是在利用和探索之间找到最佳的*衡。
由于目前神经网络的优化方法一般都采取随机梯度下降,因此我们可以通过一组超参数的学习曲线来预估这组超参数配置是否有希望得到比较好的结果。如果一组超参数配置的学习曲线不收敛或者收敛比较差,我们可以应用早期停止(Early-Stopping)策略来中止当前的训练。
动态资源分配的关键是将有限的资源分配给更有可能带来收益的超参数组合。一种有效方法是逐次减半(Successive Halving)方法 [Jamieson et al., 2016],将超参数优化看作一种非随机的最优臂问题。假设要尝试 $$ 组超参数配置,总共可利用的资源预算(摇臂的次数)为 $$,我们可以通过 $ = ⌈log_2 ( )⌉ − 1 $ 轮逐次减半的方法来选取最优的配置,具体过程如算法7.2所示.

在逐次减半方法中,尝试的超参数配置数量 $$ 十分关键。如果 $$ 越大,得到最佳配置的机会也越大,但每组配置分到的资源就越少,这样早期的评估结果可 能不准确。反之,如果 $$ 越小,每组超参数配置的评估会越准确,但有可能无法 得到最优的配置。因此,如何设置 $$ 是*衡“利用-探索”的一个关键因素。一种 改进的方法是 HyperBand 方法 [Li et al., 2017b],通过尝试不同的 $$ 来选取最优参数。
7.6.5 神经架构搜索
上面介绍的超参数优化方法都是在固定(或变化比较小)的超参数空间 $$ 中进行最优配置搜索,而最重要的神经网络架构一般还是需要由有经验的专家来进行设计。
神经架构搜索(Neural Architecture Search,NAS)[Zoph et al., 2017] 是一个新的比较有前景的研究方向,通过神经网络来自动实现网络架构的设计。一个神经网络的架构可以用一个变长的字符串来描述。利用元学习的思想,神经架构搜索利用一个控制器来生成另一个子网络的架构描述。控制器可以由一个循环神经网络来实现。控制器的训练可以通过强化学习来完成,其奖励信号为生成的子网络在开发集上的准确率。
7.7 网络正则化
7.7.1 L1 和 L2 正则化
$\ell_{1}$ 和 $\ell_{2}$ 正则化是机器学习中最常用的正则化方法,通过约束参数的 $\ell_{1}$ 和 $\ell_{2}$ 范数来减小模型在训练数据集上的过拟合现象。
通过加入 $\ell_{1}$ 和 $\ell_{2}$ 正则化,优化问题可以写为
$\theta^{*}=\underset{\theta}{\arg \min } \frac{1}{N} \sum \limits _{n=1}^{N} \mathcal{L}\left(y^{(n)}, f\left(\boldsymbol{x}^{(n)} ; \theta\right)\right)+\lambda \ell_{p}(\theta)$
其中 $\mathcal{L}(\cdot) $ 为损失函数,$N$ 为训练样本数量, $f(\cdot)$ 为待学习的神经网络,$\theta$ 为其参数,$ \ell_{p}$ 为范数函数,$p$ 的取值通常为 $\{1,2\}$ 代表 $\ell_{1}$ 和 $\ell_{2}$ 范数, $\lambda$ 为正则化系数。
带正则化的优化问题等价于下面带约束条件的优化问题:
$\begin{aligned} \theta^{*}=& \underset{\theta}{\arg \min } \frac{1}{N} \sum \limits _{n=1}^{N} \mathcal{L}\left(y^{(n)}, f\left(\boldsymbol{x}^{(n)} ; \theta\right)\right) \\ \text { s.t. } & \ell_{p}(\theta) \leq 1 \end{aligned}$
$\ell_{1}$ 范数在零点不可导,因此经常用下式来*似:
$\ell_{1}(\theta)=\sum \limits _{d=1}^{D} \sqrt{\theta_{d}^{2}+\epsilon}$
其中$$ 为参数数量,$$ 为一个非常小的常数.
图7.11给出了不同范数约束条件下的最优化问题示例。红线表示函数 $ \ell_{p}= 1$,$\mathcal{F}$ 为函数 $f(\theta)$ 的等高线 ( 为简单起见, 这里用直线表示 )。可以看出, $\ell_{1}$ 范数 的约束通常会使得最优解位于坐标轴上,从而使得最终的参数为稀疏性向量。
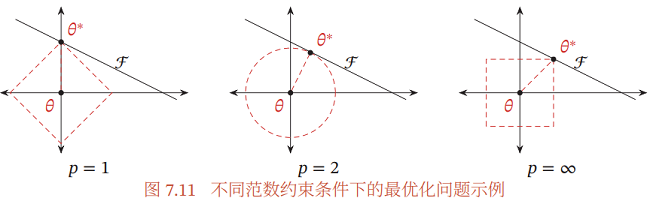
一种折中的正则化方法是同时加入 $\ell_{1}$ 和 $ \ell_{2}$ 正则化,称为弹性网络正则化 ( Elastic Net Regularization ) [Zou et al., 2005],
$\theta^{*}=\underset{\theta}{\arg \min } \frac{1}{N} \sum\limits _{n=1}^{N} \mathcal{L}\left(y^{(n)}, f\left(\boldsymbol{x}^{(n)} ; \theta\right)\right)+\lambda_{1} e_{1}(\theta)+\lambda_{2} \ell_{2}(\theta)$
其中$\lambda_1$ 和 $\lambda_2$ 分别为两个正则化项的系数。
$\ell_2$ 正则化: $\mathrm{L}^{\prime}(\theta)=L(\theta)+\lambda \frac{1}{2}\|\theta\|_{2} \quad \frac{\partial \mathrm{L}^{\prime}}{\partial \theta}=\frac{\partial \mathrm{L}}{\partial \theta}+\lambda \theta$
$\theta^{t+1} \rightarrow \theta^{t}-\alpha \frac{\partial \mathrm{L}^{\prime}}{\partial \theta}=\theta^{t}-\alpha\left(\frac{\partial \mathrm{L}}{\partial \theta}+\lambda \theta^{t}\right)=(1-\alpha \lambda) \theta^{t}-\alpha \frac{\partial \mathrm{L}}{\partial \theta}$
$\ell_1$ 正则化 : $\quad \mathrm{L}^{\prime}(\theta)=L(\theta)+\lambda \frac{1}{2}\|\theta\|_{1} \quad \frac{\partial \mathrm{L}^{\prime}}{\partial \theta}=\frac{\partial \mathrm{L}}{\partial \theta}+\lambda \operatorname{sgn}(\theta)$
$\theta^{t+1} \rightarrow \theta^{t}-\alpha \frac{\partial \mathrm{L}^{\prime}}{\partial \theta}=\theta^{t}-\alpha\left(\frac{\partial \mathrm{L}}{\partial \theta}+\lambda \operatorname{sgn}\left(\theta^{t}\right)\right)=\theta^{t}-\alpha \frac{\partial \mathrm{L}}{\partial \theta}-\alpha \lambda \operatorname{sgn}\left(\theta^{t}\right)$
7.7.2 权重衰减
权重衰减(Weight Decay)是一种有效的正则化方法 [Hanson et al., 1989], 在每次参数更新时,引入一个衰减系数。
$\theta_{t} \leftarrow(1-\beta) \theta_{t-1}-\alpha \mathbf{g}_{t}$
其中 $g_$ 为第 $$ 步更新时的梯度,$$ 为学习率,$$ 为权重衰减系数,一般取值比较小,比如 0.0005。在标准的随机梯度下降中,权重衰减正则化和 $\ell_{2}$ 正则化的效果相同。因此,权重衰减在一些深度学习框架中通过 $\ell_{2}$ 正则化来实现。但是,在较为复杂的优化方法(比如 Adam)中,权重衰减正则化和 $\ell_{2}$ 正则化并不等价[Loshchilov et al., 2017b]。
7.7.3 提前停止
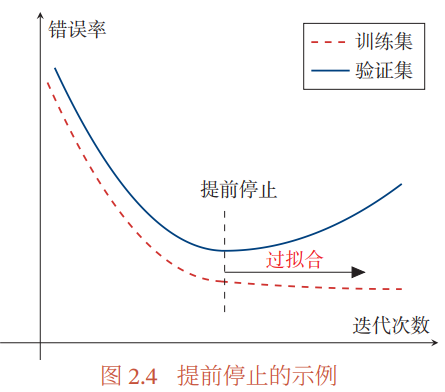
提前停止(Early Stop)对于深度神经网络来说是一种简单有效的正则化方法。由于深度神经网络的拟合能力非常强,因此比较容易在训练集上过拟合。在使用梯度下降法进行优化时,我们可以使用一个和训练集独立的样本集合,称为验证集(Validation Set),并用验证集上的错误来代替期望错误。当验证集上的错误率不再下降,就停止迭代。
然而在实际操作中,验证集上的错误率变化曲线并不一定是图2.4中所示的*衡曲线,很可能是先升高再降低。因此,提前停止的具体停止标准需要根据实际任务进行优化 [Prechelt, 1998]。
7.7.4 丢弃法
当训练一个深度神经网络时, 我们可以随机丢弃一部分神经元 (同时丢弃其对应的连接边)来避免过拟合,这种方法称为丢弃法(Dropout Method) [Srivastava et al., 2014]。 每次选择丢弃的神经元是随机的。 最简单的方法是设置一个固定的概率 $$。对每一个神经元都以概率 $$ 来判定要不要保留。对于 一个神经层 $ = ( + )$,我们可以引入一个掩蔽函数 $mask(⋅)$ 使得 $ = ( mask() + )$。掩蔽函数 $mask(⋅)$ 的定义为
$\operatorname{mask}(\boldsymbol{x})=\left\{\begin{array}{ll} \boldsymbol{m} \odot \boldsymbol{x} & \text { 当训练阶段时 } \\p \boldsymbol{x} & \text { 当测试阶段时 } \end{array}\right.$
其中 $m \in\{0,1\}^{D}$ 是丢弃掩码(Dropout Mask),通过以概率为 $$ 的伯努利分布随机生成。在训练时,激活神经元的*均数量为原来的 $$ 倍。而在测试时,所有的神经元都是可以激活的,这会造成训练和测试时网络的输出不一致。为了缓解这个问题,在测试时需要将神经层的输入 $$ 乘以 $$,也相当于把不同的神经网络做了*均。保留率 $$ 可以通过验证集来选取一个最优的值。一般来讲,对于隐藏层的神经元,其保留率 $ = 0.5$ 时效果最好,这对大部分的网络和任务都比较有效。当 $ = 0.5$ 时,在训练时有一半的神经元被丢弃,只剩余一半的神经元是可以激活的,随机生成的网络结构最具多样性。对于输入层的神经元,其保留率通常设为更接* $1$ 的数,使得输入变化不会太大。对输入层神经元进行丢弃时,相当于 给数据增加噪声,以此来提高网络的鲁棒性。
丢弃法一般是针对神经元进行随机丢弃,但是也可以扩展到对神经元之间的连接进行随机丢弃 [Wan et al., 2013],或每一层进行随机丢弃。图7.12给出了 一个网络应用丢弃法后的示例。
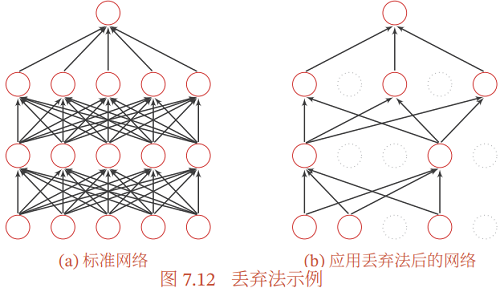
集成学习角度的解释每做一次丢弃,相当于从原始的网络中采样得到一个子网络。如果一个神经网络有 $$ 个神经元,那么总共可以采样出 $2$ 个子网络。每次迭代都相当于训练一个不同的子网络,这些子网络都共享原始网络的参数。那 么,最终的网络可以*似看作集成了指数级个不同网络的组合模型。
贝叶斯学习角度的解释丢弃法也可以解释为一种贝叶斯学习的*似 [Gal et al., 2016a]。用 $ = (; )$ 来表示要学习的神经网络,贝叶斯学习是假设参数 $$ 为随机向量,并且先验分布为 $()$,贝叶斯方法的预测为
$\mathbb{E}_{q(\theta)}[y] =\int_{q} f(\boldsymbol{x} ; \theta) q(\theta) d \theta \approx \frac{1}{M} \sum \limits _{m-1}^{M} f\left(\boldsymbol{x}, \theta_{m}\right)$
其中 $f\left(\boldsymbol{x}, \theta_{m}\right)$ 为第 $m$ 次应用丢弃方法后的网络, 其参数 $\theta_{m}$ 为对全部参数 $\theta$ 的一 次采样。
7.7.4.1 循环神经网络上的丢弃法
当在循环神经网络上应用丢弃法时,不能直接对每个时刻的隐状态进行随 机丢弃,这样会损害循环网络在时间维度上的记忆能力。一种简单的方法是对非时间维度的连接(即非循环连接)进行随机丢失 [Zaremba et al., 2014]。如 图7.13所示,虚线边表示进行随机丢弃,不同的颜色表示不同的丢弃掩码。
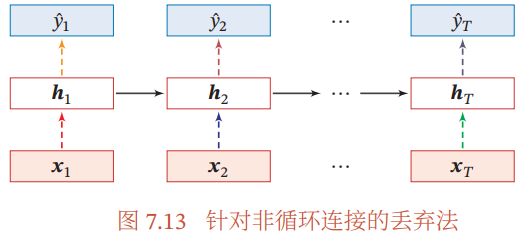
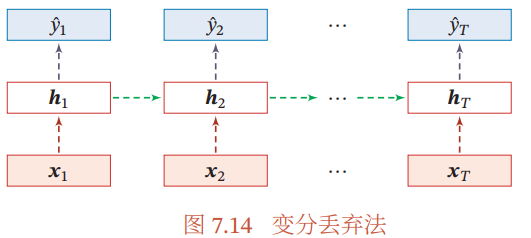
然而根据贝叶斯学习的解释,丢弃法是一种对参数 $$ 的采样。每次采样的参 数需要在每个时刻保持不变。因此,在对循环神经网络上使用丢弃法时,需要对 参数矩阵的每个元素进行随机丢弃,并在所有时刻都使用相同的丢弃掩码。这种方法称为变分丢弃法(Variational Dropout)[Gal et al., 2016b]。图7.14给出了变 分丢弃法的示例,相同颜色表示使用相同的丢弃掩码。
7.7.5 数据增强
深度神经网络一般都需要大量的训练数据才能获得比较理想的效果。在数据量有限的情况下,可以通过数据增强(Data Augmentation)来增加数据量,提 高模型鲁棒性,避免过拟合。目前,数据增强还主要应用在图像数据上,在文本等其他类型的数据上还没有太好的方法。
图像数据的增强主要是通过算法对图像进行转变,引入噪声等方法来增加数据的多样性。增强的方法主要有几种:
- 旋转(Rotation):将图像按顺时针或逆时针方向随机旋转一定角度。
- 翻转(Flip):将图像沿水*或垂直方向随机翻转一定角度。
- 缩放(Zoom In/Out):将图像放大或缩小一定比例。
- *移(Shift):将图像沿水*或垂直方法*移一定步长。
- 加噪声(Noise):加入随机噪声。
7.7.6 标签*滑
在数据增强中,我们可以给样本特征加入随机噪声来避免过拟合。同样,我们也可以给样本的标签引入一定的噪声。假设训练数据集中有一些样本的标签是被错误标注的,那么最小化这些样本上的损失函数会导致过拟合。一种改善的正则化方法是标签*滑(Label Smoothing),即在输出标签中添加噪声来避免模型过拟合 [Szegedy et al., 2016]。
一个样本 $$ 的标签可以用 $one-hot$ 向量表示,即
$ = [0, ⋯ , 0, 1, 0, ⋯ , 0]^T $
这种标签可以看作硬目标(Hard Target)。如果使用 Softmax 分类器并使用交叉熵损失函数,最小化损失函数会使得正确类和其他类的权重差异变得很大。根据 Softmax 函数的性质可知,如果要使得某一类的输出概率接*于 1,其未归一化的得分需要远大于其他类的得分,可能会导致其权重越来越大,并导致过拟合。 此外,如果样本标签是错误的,会导致更严重的过拟合现象。为了改善这种情况,我们可以引入一个噪声对标签进行*滑,即假设样本以 $$ 的概率为其他类。*滑后的标签为
$\tilde{\boldsymbol{y}}=\left[\frac{\epsilon}{K-1}, \cdots, \frac{\epsilon}{K-1}, 1-\epsilon, \frac{\epsilon}{K-1}, \cdots, \frac{\epsilon}{K-1}\right]^{\top} .$
其中 $$ 为标签数量,这种标签可以看作软目标(Soft Target)。标签*滑可以避免模型的输出过拟合到硬目标上,并且通常不会损害其分类能力。
上面的标签*滑方法是给其他 $ − 1$ 个标签相同的概率 $\frac{\epsilon}{K-1}$,没有考虑标签之间的相关性。一种更好的做法是按照类别相关性来赋予其他标签不同的概率。比如先训练另外一个更复杂(一般为多个网络的集成)的教师网络(Teacher Network), 并使用大网络的输出作为软目标来训练学生网络(Student Net- work)。这种方法也称为知识蒸馏(Knowledge Distillation)[Hinton et al., 2015].
-----------------------------------------------完-----------------------------------------------
第七章:网络优化与正则化(Part2)的更多相关文章
- 第七章:网络优化与正则化(Part1)
任何数学技巧都不能弥补信息的缺失. --科尼利厄斯·兰佐斯(Cornelius Lanczos) 匈牙利数学家.物理学家 文章相关 1 第七章:网络优化与正则化(Part1) 2 第七章:网络优化与正 ...
- 精通Web Analytics 2.0 (9) 第七章:失败更快:爆发测试与实验的能量
精通Web Analytics 2.0 : 用户中心科学与在线统计艺术 第七章:失败更快:爆发测试与实验的能量 欢迎来到实验和测试这个棒极了的世界! 如果Web拥有一个超越所有其他渠道的巨大优势,它就 ...
- 《Entity Framework 6 Recipes》中文翻译系列 (38) ------ 第七章 使用对象服务之动态创建连接字符串和从数据库读取模型
翻译的初衷以及为什么选择<Entity Framework 6 Recipes>来学习,请看本系列开篇 第七章 使用对象服务 本章篇幅适中,对真实应用中的常见问题提供了切实可行的解决方案. ...
- 《Entity Framework 6 Recipes》中文翻译系列 (41) ------ 第七章 使用对象服务之标识关系中使用依赖实体与异步查询保存
翻译的初衷以及为什么选择<Entity Framework 6 Recipes>来学习,请看本系列开篇 7-7 标识关系中使用依赖实体 问题 你想在标识关系中插入,更新和删除一个依赖实体 ...
- Java语言程序设计(基础篇) 第七章 一维数组
第七章 一维数组 7.2 数组的基础知识 1.一旦数组被创建,它的大小是固定的.使用一个数组引用变量,通过下标来访问数组中的元素. 2.数组是用来存储数据的集合,但是,通常我们会发现把数组看作一个存储 ...
- objective-c第七章课后练习2
题:改变第七章例子中print方法,增加bool参数,判断如果是YES则对分数进行约简 @interface Fraction : NSObject { //int num,den; } @prope ...
- 读《编写可维护的JavaScript》第七章总结
第七章 事件处理 7.1 典型用法 作者首先给了个我们一个处理事件的方法.看起来也没啥俩样,不过后来给出的优化方法很值得学习: // 不好的写法 function handleClick(even ...
- 第七章 LED将为我们闪烁:控制发光二极管
第七章 LED将为我们闪烁:控制发光二极管 本章我们将会看到一个完整的linux驱动程序,通过linux驱动程序控制LED的四个小灯,通俗的说就是通过向linux驱动程序来控制LED小灯的开关.用到 ...
- Getting Started With Hazelcast 读书笔记(第七章)
第七章 部署策略 Hazelcast具有适应性,能根据不同的架构和应用进行特定的部署配置,每个应用可以根据具体情况选择最优的配置: 数据与应用紧密结合的模式(重点,of就是这种) 胖客户端模式(最好用 ...
随机推荐
- 浅谈Java迭代器
迭代器Iterator 概述: 迭代器(Iterator):它不是一个容器,它是一种用于访问容器的方法,可用于迭代 List.Set和Map等容器. 迭代:一个一个的往外拿. 作用:帮我们遍历或者拿到 ...
- 启动或重启Oracle数据以及监听
(以下均为命令行形式) 1.切换到oracle数据库用户: su - oracle 2.查看数据库的监听状态: lsnrctl status 3.停止监听: lsnrctl stop 4.登陆到ora ...
- 玩转 pyocd
(一) pyocd (1) 什么是pyocd pyocd 是 arm 开发的一个 python 包(python package),该软件包可以使用多种USB调试器对 arm cortex-M 微 ...
- Android WorkManager工作约束,延迟与查询工作
WorkManager工作约束,延迟与查询工作 本文可能会混用"工作"与"任务"这两个词. 本文例子使用Kotlin 准备一个工作类(任务)UploadWork ...
- Redis分布式锁的原理和实现
前言 我们之前聊过redis的,对基础不了解的可以移步查看一下: 几分钟搞定redis存储session共享--设计实现:https://www.cnblogs.com/xiongze520/p/10 ...
- oracle给system用户增加sysdba和sysoper 角色
第一步:先用sys用户登录到数据库 第二步:打开一个sql窗口,输入grant sysoper to system; 点击执行 第三步:等待执行完成之后,再执行grant sysdba to sys ...
- C#设计模式---观察者模式(Observer Pattern)
一.目的 提供一种一对多的关系,当主题发生变化时候,可以通知所有关联的对象. 二.定义 观察者模式定义了一种一对多的依赖关系,让多个观察者对象同时监听某一个主题对象,这个主题对象在状态发生变化时,会通 ...
- Java 数组结构
数组是最常见的一种数据结构,是相同类型的.用一个标识符封装到一起的基本类型数据序列或对象序列.可以用一个统一的数组名和下标来唯一确定数组中的元素.实质上数组是一个简单的线性序列,因此数组访问起来很快. ...
- springmvc框架(Spring SpringMVC, Hibernate整合)
直接干货 model 考虑给用户展示什么.关注支撑业务的信息构成.构建成模型. control 调用业务逻辑产生合适的数据以及传递数据给视图用于呈献: view怎样对数据进行布局,以一种优美的方式展示 ...
- ubuntu下配置JDK的一些坑点
ubuntu下配置JDK的一些坑点 在centos下的JDK配置: 在ubuntu下的话,要修改两个地方: 在/etc/enviornment中配置! 在/etc/profile中配置! 写在最后: ...