初识python 之 爬虫:使用正则表达式爬取“糗事百科 - 文字版”网页数据
初识python 之 爬虫:使用正则表达式爬取”古诗文“网页数据 的兄弟篇。
详细代码如下:
#!/user/bin env python
# author:Simple-Sir
# time:2019/8/1 14:50
# 爬取糗事百科(文字)网页数据 import requests,re
URLHead = 'https://www.qiushibaike.com' def getHtml(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
respons = requests.get(url,headers=headers)
html = respons.text
return html
def getInfos(url):
html = getHtml(url)
authors = re.findall(r'<h2>\n(.*?)\n</h2>',html,re.DOTALL) # 获取作者
author_sex_lvl = re.findall(r'<div class="articleGender (.*?)Icon">(\d*?)</div>',html,re.DOTALL) # 获取作者性别、等级
author_sex = [] # 性别
author_lvl = [] # 等级
for i in author_sex_lvl:
author_sex.append(i[0])
author_lvl.append(i[1]) contentHerf = re.findall(r'<a href="(/article.*?)".*?class="contentHerf"',html,re.DOTALL)[1:] # 获取“详细页”href
cont = [] # 内容
for contentUrl in contentHerf:
contentHerf_all = URLHead + contentUrl
contentHtml = getHtml(contentHerf_all) # 详细页html
contents = re.findall(r'<div class="content">(.*?)</div>',contentHtml,re.DOTALL)
content_br = re.sub(r'<br/>','',contents[0]) # 剔除</br>标签
content = re.sub(r'\\xa0','',content_br)
cont.append(content)
infos = []
for i in zip(authors,author_sex,author_lvl,cont):
author,sex,lvl,text=i
info ={
'作者':author,
'性别': sex,
'等级': lvl,
'内容': text
}
infos.append(info)
return infos def main():
page = int(input('您想获取前几页的数据?\n'))
for i in range(1,page+1):
url = 'https://www.qiushibaike.com/text/page/{}'.format(i)
print('正在爬取第{}页数据:'.format(i))
for t in getInfos(url):
print(t)
print('第{}页数据已爬取完成。'.format(i))
print('所有数据已爬取完成!') if __name__ == '__main__':
main()
爬取糗事百科(文字)网页数据
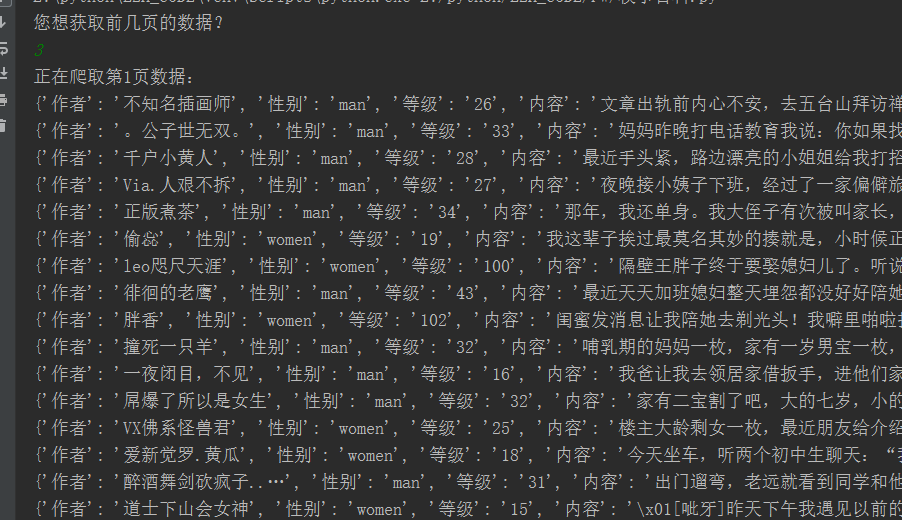
执行结果:

初识python 之 爬虫:使用正则表达式爬取“糗事百科 - 文字版”网页数据的更多相关文章
- python+正则提取+ip代理爬取糗事百科文字信息
很多网站都有反爬措施,最常见的就是封ip,请求次数过多服务器会拒绝连接,如图: 在程序中设置一个代理ip,可有效的解决这种问题,代码如下: # 需要的库 import requests import ...
- python_爬虫一之爬取糗事百科上的段子
目标 抓取糗事百科上的段子 实现每按一次回车显示一个段子 输入想要看的页数,按 'Q' 或者 'q' 退出 实现思路 目标网址:糗事百科 使用requests抓取页面 requests官方教程 使用 ...
- 爬取糗事百科热门段子的数据并保存到本地,xpath的使用
和之前的爬虫类博客的爬取思路基本一致: 构造url_list,因为糗事百科的热门栏目默认是13页,所以这个就简单了 遍历发送请求获取响应 提取数据,这里用的是xpath提取,用的是Python的第三方 ...
- 芝麻HTTP:Python爬虫实战之爬取糗事百科段子
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- python 爬虫实战1 爬取糗事百科段子
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 本篇目标 抓取糗事百科热门段子 过滤带有图片的段子 实现每按一次回车显示一个段子的发布时间,发布人 ...
- Python爬虫实战之爬取糗事百科段子
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- Python爬虫实战之爬取糗事百科段子【华为云技术分享】
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- 2019基于python的网络爬虫系列,爬取糗事百科
**因为糗事百科的URL改变,正则表达式也发生了改变,导致了网上许多的代码不能使用,所以写下了这一篇博客,希望对大家有所帮助,谢谢!** 废话不多说,直接上代码. 为了方便提取数据,我用的是beaut ...
- 21天打造分布式爬虫-Spider类爬取糗事百科(七)
7.1.糗事百科 安装 pip install pypiwin32 pip install Twisted-18.7.0-cp36-cp36m-win_amd64.whl pip install sc ...
随机推荐
- VueAPI 2 (生命周期钩子函数)
所有的生命周期钩子自动绑定 this 上下文到实例中,因此你可以访问数据,对属性和方法进行运算.这意味着你不能使用箭头函数来定义一个生命周期方法. beforeCreate 在实例初始化之后,此时还不 ...
- python中numpy库ndarray多维数组的的运算:np.abs(x)、np.sqrt(x)、np.modf(x)等
numpy库提供非常便捷的数组运算,方便数据的处理. 1.数组与标量之间可直接进行运算 In [45]: aOut[45]:array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ ...
- pipeline脚本管理
目录 一.代码仓库 二.远程拉取 一.代码仓库 1.使用gitlab做pipeline脚本的存储,新建一个仓库 2.新建文件,把代码放进去 脚本名可以按照规律填写,环境_应用名_类型,例如:test_ ...
- Nginx模块之limit_conn & limit_req
limit_conn模块 生效阶段:NGX_HTTP_PREACCESS_PHASE阶段 生效范围:全部worker进程(基于共享内存),进入preaccess阶段前不生效,限制的有效性取决于key的 ...
- 新一代Java程序员必学的Docker容器化技术基础篇
Docker概述 **本人博客网站 **IT小神 www.itxiaoshen.com Docker文档官网 Docker是一个用于开发.发布和运行应用程序的开放平台.Docker使您能够将应用程序与 ...
- MySQL获取对应时间
一.查询当前时间包含年月日 SELECT CURDATE(); SELECT CURRENT_DATE(); 二.查询当前时间包含年月日时分秒 SELECT NOW(); SELECT SYSDATE ...
- CF1110A Parity 题解
Content 求下面式子的奇偶性,其中 \(a_i,k,b\) 会在输入中给定. \[\sum\limits_{i=1}^k a_i\cdot b^{k-i} \] 数据范围:\(2\leqslan ...
- navicat模型分享方法
一. 查看模型保存路径选中模型如:<app-订单模型>,点击右键,对象信息,可以看到文件位置:C:\Users\Administrator\Documents\Navicat\Premiu ...
- Vue2使用Axios发起请求教程详细
当你看到该文章时希望你已知晓什么是跨域请求以及跨域请求的处理,本文不会赘述 本文后台基于Springboot2.3进行搭建,Controller中不会写任何业务逻辑仅用于配合前端调试 Controll ...
- windows(Linux)创建”内网穿透“工具(通过自定义域名访问部署于内网的 web 服务,可以用于调试微信支付,支付宝支付,微信公众号等开发项目)
此方法需要自有服务器和域名,如果没有这些的开发者, 可以参考钉钉提供的内网穿透方式:https://www.cnblogs.com/pxblog/p/13862376.html 一.准备工作 1.域名 ...