花授粉优化算法-python/matlab
import numpy as np
from matplotlib import pyplot as plt
import random # 初始化种群
def init(n_pop, lb, ub, nd):
"""
:param n_pop: 种群
:param lb: 下界
:param ub: 上界
:param nd: 维数
"""
p = lb + (ub - lb) * np.random.rand(n_pop, nd)
return p # 适应度函数
def sphere(x):
y = np.sum(x ** 2, 1)
return y def Ackley_1(x):
n, d = x.shape
y = -20 * np.exp(-0.02 * np.sqrt(1 / d * np.sum(x ** 2, 1))) - np.exp(
1 / d * np.sum(np.cos(2 * np.pi * x), 1)) + 20 + np.e
return y def Ackley_2(x):
y = -200 * np.exp(-0.02 * np.sqrt(x[:, 0] ** 2 + x[:, 1] ** 2))
return y def Ackley_3(x):
y = -200 * np.exp(-0.02 * np.sqrt(x[:, 0] ** 2 + x[:, 1] ** 2)) + 5 * np.exp(
np.cos(3 * x[:, 0]) + np.sin(3 * x[:, 1]))
return y def Ackley_4(x, y=0):
_, d = x.shape
for i in range(1, d):
y += np.exp(-0.2 * np.sqrt(x[:, i - 1] ** 2 + x[:, i] ** 2)) + 3 * (
np.cos(2 * x[:, i - 1]) + np.sin(2 * x[:, i]))
return y def Adjiman(x):
y = np.cos(x[:, 0]) * np.sin(x[:, 1]) - x[:, 0] / (x[:, 1] ** 2 + 1)
return y def Alpine(x):
y = np.sum(np.abs(x * np.sin(x) + 0.1 * x), 1)
return y def Alpine2(x):
y = np.prod(np.sqrt(x) * np.sin(x), axis=1)
return y def Bartels(x):
y = np.abs(x[:, 0] ** 2 + x[:, 1] ** 2 + x[:, 0] * x[:, 1]) + np.abs(np.sin(x[:, 0])) + np.abs(np.c
return y def Beale(x):
y = (1.5 - x[:, 0] + x[:, 0] * x[:, 1]) ** 2 + (2.25 - x[:, 0] + x[:, 0] * x[:, 1] ** 2) ** 2 + (
2.625 - x[:, 0] + x[:, 0] * x[:, 1] ** 3) ** 2
return y f_score = sphere # 函数句柄 # Levy飞行Beale
def Levy(nd, beta=1.5):
num = np.random.gamma(1 + beta) * np.sin(np.pi * beta / 2)
den = np.random.gamma((1 + beta) / 2) * beta * 2 ** ((beta - 1) / 2)
sigma_u = (num / den) ** (1 / beta) u = np.random.normal(0, sigma_u ** 2, (1, nd))
v = np.random.normal(0, 1, (1, nd)) z = u / (np.abs(v) ** (1 / beta))
return z def FPA(Max_g, n_pop, Pop, nd, lb, ub, detail): # FPA算法
"""
:param Max_g: 迭代次数
:param n_pop: 种群数目
:param Pop: 花粉配子
:param nd: 维数
:param lb: 下界
:param ub: 上界
:param detail: 显示详细信息
"""
# 计算初始种群中最好个体适应度值
pop_score = f_score(Pop)
g_best = np.min(pop_score)
g_best_loc = np.argmin(pop_score)
g_best_p = Pop[g_best_loc, :].copy() # 问题设置
p = 0.8
best_fit = np.empty((Max_g,))
# 迭代
for it in range(1, Max_g + 1):
for i in range(n_pop):
if np.random.rand() < p:
new_pop = Pop[i, :] + Levy(nd) * (g_best_p - Pop[i, :])
new_pop = np.clip(new_pop, lb, ub) # 越界处理
else:
idx = random.sample(list(range(n_pop)), 2)
new_pop = Pop[i, :] + np.random.rand() * (Pop[idx[1], :] - Pop[idx[0], :])
new_pop = np.clip(new_pop, lb, ub) # 越界处理
if f_score(new_pop.reshape((1, -1))) < f_score(Pop[i, :].reshape((1, -1))):
Pop[i, :] = new_pop
# 计算更新后种群中最好个体适应度值
pop_score = f_score(Pop)
new_g_best = np.min(pop_score)
new_g_best_loc = np.argmin(pop_score) if new_g_best < g_best:
g_best = new_g_best
g_best_p = Pop[new_g_best_loc, :].copy()
best_fit[it - 1] = g_best if detail:
print("----------------{}/{}--------------".format(it, Max_g))
print(g_best)
print(g_best_p) return best_fit, g_best if __name__ == "__main__":
pop = init(30, -100, 100, 2)
fitness, g_best = FPA(1000, 30, pop, 2, -100, 100, True) # 可视化
plt.figure()
# plt.plot(fitness)
plt.semilogy(fitness)
# 可视化
# fig = plt.figure()
# plt.plot(p1, fit)
plt.show()
花授粉算法Matlab代码
% 清屏和工作空间变量
clc
clear
Step 1: 问题定义
npop = 30; % 种群数目
dpop = 2; % 种群维数
ub = 100; % 种群的上界
lb = -100; % 种群的下界
Step 2: 初始化种群
pop = lb + rand(npop, dpop).*(ub - lb); % pop是初始种群
Step 3:适应度函数
fScore = @ sphere
Step 4:Levy飞行
levy = @ Levy
Step 5:计算初始种群最好的适应度值
popScore = fScore(pop);
[bestscore, loc] = min(popScore);
bestpop = pop(loc, :);
Step 6:参数设置
iterMax = 1000; % 最大迭代次数
p = 0.8; % 转换概率
BestScore = ones(iterMax, 1);
Step 7:越界处理
Clip = @ clip; % 越界处理函数
Step 8:迭代
for it=1:iterMax
for i = 1:npop
if rand < p
newpop = pop(i, :) + levy(1, dpop).*(bestpop - pop(i, :)); % 异花授粉
else
idx = randsample(30, 2);
newpop = pop(i, :) + rand*(pop(idx(1), :) - pop(idx(2), :)); % 自花授粉
end
newpop = Clip(newpop, ub, lb); % 越界处理
if fScore(newpop) < fScore(pop(i, :))
pop(i, :) = newpop; % 更新种群
end
end
popScore = fScore(pop);
[newBestScore, Loc] = min(popScore);
if newBestScore < bestscore
bestscore = newBestScore;
bestpop = pop(loc, :);
end
BestScore(it) = bestscore;
disp(['Iteration ' num2str(it) ': Best Cost = ' num2str(bestscore)]);
disp(['Bestpop ' num2str(bestpop)])
end
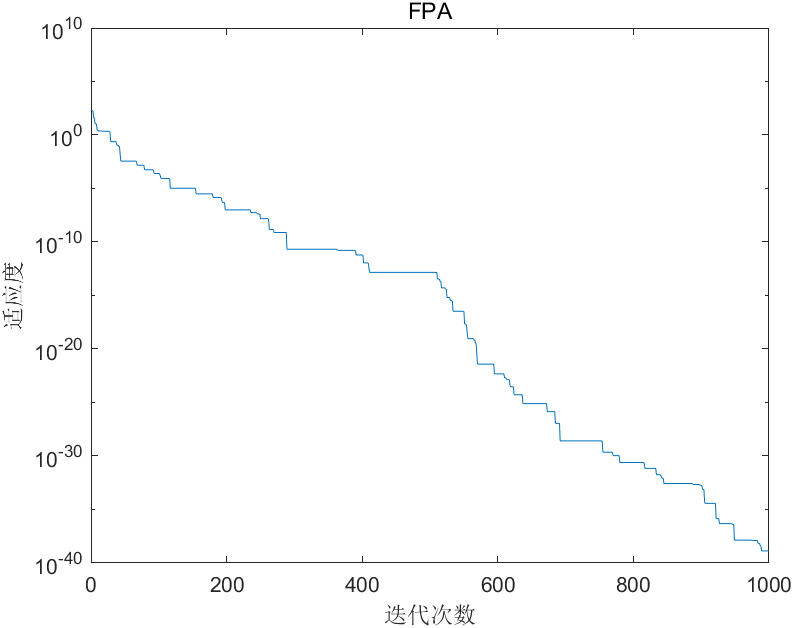
Step 9:可视化
figure
semilogy(BestScore)
% plot(BestScore)
xlim([0 1000])
xlabel('迭代次数')
ylabel('适应度')
title('FPA')
function L=Levy(d)
%% Levy飞行
beta=3/2;
sigma=(gamma(1+beta)*sin(pi*beta/2)/(gamma((1+beta)/2)*beta*2^((beta-1)/2)))^(1/beta);
u=random('normal', 0, sigma, 1, d);
v=random('normal', 0, 1, 1, d);
L=0.01*u./abs(v).^(1/beta);
end
function s=simplebounds(s,Lb,Ub)
%% 越界处理函数
ns_tmp=s;
I=ns_tmp<Lb;
ns_tmp(I)=Lb(I);
J=ns_tmp>Ub;
ns_tmp(J)=Ub(J);
s=ns_tmp;
end
function [y] = Sphere(xx)
%% 目标函数
d = length(xx);
sum = 0;
for ii = 1:d
xi = xx(ii);
sum = sum + xi^2;
end y = sum;
end
花授粉优化算法-python/matlab的更多相关文章
- 群智能优化算法-测试函数matlab源码
群智能优化算法测试函数matlab源代码 global M; creatematrix(2); %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %画ackley图. %%%% ...
- 粒子群优化算法-python实现
PSOIndividual.py import numpy as np import ObjFunction import copy class PSOIndividual: ''' individu ...
- 计算智能(CI)之粒子群优化算法(PSO)(一)
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习.深度学习的知识! 计算智能(Computational Intelligence , ...
- [matlab] 6.粒子群优化算法
粒子群优化(PSO, particle swarm optimization)算法是计算智能领域,除了蚁群算法,鱼群算法之外的一种群体智能的优化算法,该算法最早由Kennedy和Eberhart在19 ...
- 粒子群优化算法PSO及matlab实现
算法学习自:MATLAB与机器学习教学视频 1.粒子群优化算法概述 粒子群优化(PSO, particle swarm optimization)算法是计算智能领域,除了蚁群算法,鱼群算法之外的一种群 ...
- MATLAB粒子群优化算法(PSO)
MATLAB粒子群优化算法(PSO) 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 一.介绍 粒子群优化算法(Particle Swarm Optim ...
- 模拟退火算法SA原理及python、java、php、c++语言代码实现TSP旅行商问题,智能优化算法,随机寻优算法,全局最短路径
模拟退火算法SA原理及python.java.php.c++语言代码实现TSP旅行商问题,智能优化算法,随机寻优算法,全局最短路径 模拟退火算法(Simulated Annealing,SA)最早的思 ...
- 粒子群优化算法对BP神经网络优化 Matlab实现
1.粒子群优化算法 粒子群算法(particle swarm optimization,PSO)由Kennedy和Eberhart在1995年提出,该算法模拟鸟集群飞行觅食的行为,鸟之间通过集体的协作 ...
- 分别使用 Python 和 Math.Net 调用优化算法
1. Rosenbrock 函数 在数学最优化中,Rosenbrock 函数是一个用来测试最优化算法性能的非凸函数,由Howard Harry Rosenbrock 在 1960 年提出 .也称为 R ...
随机推荐
- python实现对象测量
目录: 问题,轮廓找到了,如何去计算对象的弧长与面积(闭合),多边形拟合,几何矩的计算等 (一)对象的弧长与面积 (二)多边形拟合 (三)几何矩的计算 (四)获取图像的外接矩形boundingRect ...
- python实现拉普拉斯图像金字塔
一,定义 二,代码: 要求:拉普拉斯金字塔时,图像大小必须是2的n次方*2的n次方,不然会报错 1 # -*- coding=GBK -*- 2 import cv2 as cv 3 4 5 #高斯金 ...
- [cf1340D]Nastya and Time Machine
记$deg_{i}$为$i$的度数,简单分类讨论可得答案下限为$\max_{i=1}^{n}deg_{i}$ 另一方面,此下限是可以取到的,构造方法较多,这里给一个巧妙一些的做法-- 对其以dfs(儿 ...
- 通过get方法的方式获取配置项信息
这种写法比其他的方法好的一点是,当你需要修改参数名或者参数值的时候,只需要改一个地方就可以了,其他地方根本不用动,面向接口编程. eureka-server.properties archaius.d ...
- KNN算法实现对iris数据集的预测
KNN算法的实现 import pandas as pd from math import dist k = int(input("请输入k值:")) dataTest = pd. ...
- 解决texlive化学式转换镜像经常偶发性进程堆积导致卡顿问题
前言 之前在 使用Python定时清理运行超时的pdflatex僵尸进程 博文中我采用python脚本开启定时任务清理pdflatex僵尸进程,线上4u2G的k8s pod部署了3个,pdflatex ...
- Codeforces 986F - Oppa Funcan Style Remastered(同余最短路)
Codeforces 题面传送门 & 洛谷题面传送门 感谢此题教会我一个东西叫做同余最短路(大雾 首先这个不同 \(k\) 的个数 \(\le 50\) 这个条件显然是让我们对每个 \(k\) ...
- Codeforces 1383D - Rearrange(构造)
Codeforces 题面传送门 & 洛谷题面传送门 一道不算困难的构造,花了一节英语课把它搞出来了,题解简单写写吧( 考虑从大往小加数,显然第三个条件可以被翻译为,每次加入一个元素,如果它所 ...
- Codeforces 497E - Subsequences Return(矩阵乘法)
Codeforces 题目传送门 & 洛谷题目传送门 一道还算不错的矩乘 tea 罢,不过做过类似的题应该就比较套路了-- 首先考虑对于一个固定的序列 \(\{a\}\) 怎样求其本质不同的序 ...
- 在R语言中使用Stringr进行字符串操作
今天来学习下R中字符串处理操作,主要是stringr包中的字符串处理函数的用法. 先导入stringr包,library(stringr),require(stringr),或者stringr::函数 ...