flink---实时项目--day01--1. openrestry的安装 2. 使用nginx+lua将日志数据写入指定文件中 3. 使用flume将本地磁盘中的日志数据采集到的kafka中去
1. openrestry的安装
OpenResty = Nginx + Lua,是⼀一个增强的Nginx,可以编写lua脚本实现⾮非常灵活的逻辑
(1)安装开发库依赖
yum install -y pcre-devel openssl-devel gcc curl
(2)配置yum的依赖源
yum install yum-utils
yum-config-manager --add-repo https://openresty.org/package/centos/openresty.repo
(3)安装OpenResty
yum install openresty
安装过程中出现问题的解决办法
cd /etc/yum.repos.d
yum install wget
wget https://openresty.org/package/centos/openresty.repo
vi openresty.repo
将https改成http(改两个地方)
yum install openresty
(4)openresty的默认安装⽬目录
/usr/local/openresty
(5)启动openresty(Nginx)
/usr/local/openresty/nginx/sbin/nginx
(6)通过浏览器器查看nginx的⻚页⾯面
2. 使用nginx+lua将日志数据写入指定文件中
需求:访问某个地址,nginx页面只显示1*1像素的空图片,然后将日志记录到指定的文件中去
(1)创建存放日志的目录并设置权限
mkdir /logs
chmod o+w /logs
为什么要设置权限呢,因为往logs的access.log文件写日志数据的用户是nobody,如下

(2)vi nginx.conf
location /log.gif{
#伪装成gif文件
default_type 'image/gif';
#关闭access_log
access_log off;
# 使用lua将nginx接受的参数写入到日志文件中
log_by_lua_file 'conf/log.lua';
#返回空图片
empty_gif;
}
(3)在nginx的conf⽬目录下创建⼀一个log.lua⽂文件
vi /usr/local/openresty/nginx/conf/log.lua
log.lua脚本内容如下
-- 引⼊入lua所有解析json的库
local cjson = require "cjson"
-- 获取请求参数列列表
local request_args_tab = ngx.req.get_uri_args()
-- 使⽤用lua的io打开⼀一个⽂文件,如果⽂文件不不存在,就创建,a为append模式
local file = io.open("/logs/access.log", "a")
-- 定义⼀一个json对象
local log_json = {}
-- 将参数的K和V迭代出来,添加到json对象中
for k, v in pairs(request_args_tab) do
log_json[k] = v
end
-- 将json写⼊入到指定的log⽂文件,末尾追加换⾏行行
file:write(cjson.encode(log_json), "\n")
-- 将数据写⼊入
file:flush()
(4)在浏览器上请求feng05/log.gjf,能发现数据写入了/logs/access.log

上诉做法存在一个问题:如果一直往一个⽂件中写入数据,这个日志文件会过大,造成读写效率变低,现在按照小时生成文件
log.lua脚本内容修改如下所示
-- 引⼊入lua⽤用来解析json的库
local cjson = require "cjson"
-- 获取请求参数列列表
local request_args_tab = ngx.req.get_uri_args()
-- 获取当前系统时间
local time = os.date("%Y%m%d%H",unixtime)
-- 使⽤用lua的io打开⼀一个⽂文件,如果⽂文件不不存在,就创建,a为append模式
local path = "/mylog/access-" .. time .. ".log"
local file = io.open(path, "a")
-- 定义⼀一个json对象
local log_json = {}
-- 将参数的K和V迭代出来,添加到json对象中
for k, v in pairs(request_args_tab) do
log_json[k] = v
end
-- 将json写⼊入到指定的log⽂文件,末尾追加换⾏行行
file:write(cjson.encode(log_json), "\n")
-- 将数据写⼊入
file:flush()
这样就会按照时间滚动生成日志文件了
3. 使用flume将本地磁盘中的日志数据采集到的kafka中去
此处数据采集的架构为flume+kafka(taildir+kafkachannel), 这样既能实现负载均衡又能使用高可用
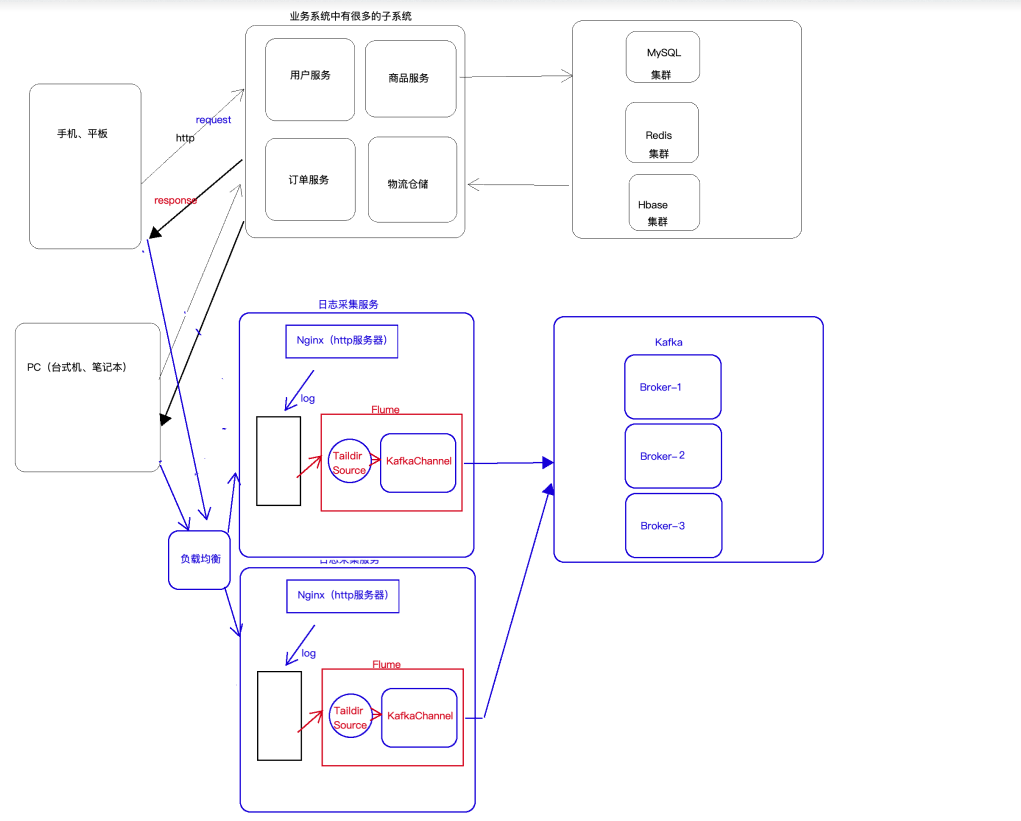
flume采集数据的配置文件如下所示:nginx-kafka.conf


a1.sources = r1
a1.channels = c1 a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /root/taildir_position.json //此处表示taildir采集的记录,即偏移量
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /log/access-.*\.log a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = feng05:9092,feng06:9092,feng07:9092
a1.channels.c1.kafka.topic = access12
a1.channels.c1.parseAsFlumeEvent = false a1.sources.r1.channels = c1
运行flume进行采集,数据即可采集至kafka中,命令如下
/usr/apps/apache-flume-1.9.0-bin/bin/flume-ng agent -n a1 -c conf \
-f myconf/nginx-kafka.conf \
-Dflume.root.logger=INFO,console
/usr/apps/kafka_2.11-2.4.0/bin/kafka-console-consumer.sh --bootstrap-server feng05:9092 --topic access --from-beginning
flink---实时项目--day01--1. openrestry的安装 2. 使用nginx+lua将日志数据写入指定文件中 3. 使用flume将本地磁盘中的日志数据采集到的kafka中去的更多相关文章
- PHP将数据写入指定文件中
首先创建一个空的txt文件,这里我们创建了一个1.txt的空文件. 第一种方法:fwrite函数 <?php $file=fopen('1.txt','rb+'); var_dump(fwrit ...
- 程序一 用记事本建立文件src.dat,其中存放若干字符。编写程序,从文件src.dat中读取数据,统计其中的大写字母、小写字母、数字、其它字符的个数,并将这些数据写入到文件test.dat中。
用记事本建立文件src.dat,其中存放若干字符.编写程序,从文件src.dat中读取数据,统计其中的大写字母.小写字母.数字.其它字符的个数,并将这些数据写入到文件test.dat中. #inclu ...
- Python:将爬取的网页数据写入Excel文件中
Python:将爬取的网页数据写入Excel文件中 通过网络爬虫爬取信息后,我们一般是将内容存入txt文件或者数据库中,也可以写入Excel文件中,这里介绍关于使用Excel文件保存爬取到的网页数据的 ...
- 10.Flink实时项目之订单维度表关联
1. 维度查询 在上一篇中,我们已经把订单和订单明细表join完,本文将关联订单的其他维度数据,维度关联实际上就是在流中查询存储在 hbase 中的数据表.但是即使通过主键的方式查询,hbase 速度 ...
- 1.Flink实时项目前期准备
1.日志生成项目 日志生成机器:hadoop101 jar包:mock-log-0.0.1-SNAPSHOT.jar gmall_mock |----mock_common |----mock ...
- 5.Flink实时项目之业务数据准备
1. 流程介绍 在上一篇文章中,我们已经把客户端的页面日志,启动日志,曝光日志分别发送到kafka对应的主题中.在本文中,我们将把业务数据也发送到对应的kafka主题中. 通过maxwell采集业务数 ...
- 3.Flink实时项目之流程分析及环境搭建
1. 流程分析 前面已经将日志数据(ods_base_log)及业务数据(ods_base_db_m)发送到kafka,作为ods层,接下来要做的就是通过flink消费kafka 的ods数据,进行简 ...
- 4.Flink实时项目之数据拆分
1. 摘要 我们前面采集的日志数据已经保存到 Kafka 中,作为日志数据的 ODS 层,从 kafka 的ODS 层读取的日志数据分为 3 类, 页面日志.启动日志和曝光日志.这三类数据虽然都是用户 ...
- 6.Flink实时项目之业务数据分流
在上一篇文章中,我们已经获取到了业务数据的输出流,分别是dim层维度数据的输出流,及dwd层事实数据的输出流,接下来我们要做的就是把这些输出流分别再流向对应的数据介质中,dim层流向hbase中,dw ...
随机推荐
- 进程间通信消息队列msgsnd执行:Invlid argument——万恶的经验主义
最近在搞进程间通信,首先在我的ubuntu 14.04上写了接口和测试demo,编译和执行都OK,,代码如下: 接口文件ipcmsg.h /* ipcmsg.h */ #ifndef H_MSGIPC ...
- 深入剖析Redis客户端Jedis的特性和原理
一.开篇 Redis作为目前通用的缓存选型,因其高性能而倍受欢迎.Redis的2.x版本仅支持单机模式,从3.0版本开始引入集群模式. Redis的Java生态的客户端当中包含Jedis.Rediss ...
- hash 哈希表 缓存表
系统初始hash表为空,当外部命令执行时,默认会从 PATH路径下寻找该命令,找到后会将这条命令的路径记录到 hash表中,当再次使用该命令时,shell解释器首先会查看hash 表,存在将执行之,如 ...
- 重装系统——联想window 10
大四了,读了四年大学,唉,混的,啥也不会,工作也找不到,真的不知道这大学四年到底干了什么.专业是计算机方向的,但居然,不敢,也不会装电脑系统,大学四年的文件都是乱放的,更那个的是,有些软件卸载不完全, ...
- Springboot 整合RabbitMq ,用心看完这一篇就够了
该篇文章内容较多,包括有rabbitMq相关的一些简单理论介绍,provider消息推送实例,consumer消息消费实例,Direct.Topic.Fanout的使用,消息回调.手动确认等. (但是 ...
- 问题 N: 非洲小孩
题目描述 家住非洲的小孩,都很黑.为什么呢? 第一,他们地处热带,太阳辐射严重. 第二,他们不经常洗澡.(常年缺水,怎么洗澡.) 现在,在一个非洲部落里,他们只有一个地方洗澡,并且,洗澡时间很短,瞬间 ...
- 痞子衡嵌入式:在IAR开发环境下RT-Thread工程函数重定向失效分析
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家分享的是在IAR开发环境下RT-Thread工程函数重定向失效分析. 痞子衡旧文 <在IAR下将关键函数重定向到RAM中执行的方法> ...
- 来了!公开揭密团队成员开发鸿蒙 OpenHarmony 的完整过程(收获官方7000奖金和开发板等,1w字用心总结)
背景 随着 OpenHarmony 组件开发大赛结果公布,我们的团队成员被告知获得了二等奖,在开心之余也想将我们这段时间宝贵的开发经验写下来与大家分享,当我们看到参赛通知的时候已经是 9 月中旬的时候 ...
- LeetCode->链表反转
这是一个很基础的题目.今天处理了一下,不论是以双指针迭代.递归等方法,都能处理,但是也使这个题目更为典型. 剑指 Offer 24. 反转链表 - 力扣(LeetCode) (leetcode-cn. ...
- <C#任务导引教程>练习九
//75,异常情况using System;class Program{ public static void Main() { Console.Write("请输 ...