7.Flink实时项目之独立访客开发
1.架构说明
在上6节当中,我们已经完成了从ods层到dwd层的转换,包括日志数据和业务数据,下面我们开始做dwm层的任务。
DWM 层主要服务 DWS,因为部分需求直接从 DWD 层到DWS 层中间会有一定的计算量,而且这部分计算的结果很有可能被多个 DWS 层主题复用,所以部分 DWD 会形成一层 DWM,我们这里主要涉及业务:
访问UV计算
跳出明细计算
订单宽表
支付宽表
因为实时计算与离线不同,实时计算的开发和运维成本都是非常高的,要结合实际情况考虑是否有必要象离线数仓一样,建一个大而全的中间层。如果没有必要大而全,这时候就需要大体规划一下要实时计算出的指标需求了。把这些指标以主题宽表的形式输出就是我们的 DWS 层。
| 统计主题 | 需求指标 | 输出方式 | 计算来源 | 来源层级 |
|---|---|---|---|---|
| 访客 | pv | 可视化大屏 | page_log直接可求 | dwd |
| uv | 可视化大屏 | 需要用page_log过滤去重 | dwm | |
| 跳出率 | 可视化大屏 | 需要用page_log行为判断 | dwm | |
| 进入页面数 | 可视化大屏 | 需要识别开始访问标识 | dwd | |
| 连续访问时长 | 可视化大屏 | page_log直接可求 | dwd | |
| 商品 | 点击 | 多维分析 | page_log直接可求 | dwd |
| 收藏 | 多维分析 | 收藏表 | dwd | |
| 加入购物车 | 多维分析 | 购物车表 | dwd | |
| 下单 | 可视化大屏 | 订单宽表 | dwm | |
| 支付 | 多维分析 | 支付宽表 | dwm | |
| 退款 | 多维分析 | 退款表 | dwd | |
| 评论 | 多维分析 | 评论表 | dwd | |
| 地区 | pv | 多维分析 | page_log直接可求 | dwd |
| uv | 多维分析 | 需要page_log过滤去重 | dwm | |
| 下单 | 可视化大屏 | 订单宽表 | dwm | |
| 关键词 | 搜索关键词 | 可视化大屏 | page_log直接可求 | dwd |
| 点击商品关键词 | 可视化大屏 | 商品主题下单再次聚合 | dws | |
| 下单商品关键词 | 可视化大屏 | 商品主题下单再次聚合 | dws |
2. 访客UV计算
UV,全称是 Unique Visitor,即独立访客,对于实时计算中,也可以称为 DAU(Daily Active User),即每日活跃用户,因为实时计算中的uv通常是指当日的访客数。那么如何从用户行为日志中识别出当日的访客,那么有两点:
其一,是识别出该访客打开的第一个页面,表示这个访客开始进入我们的应用
其二,由于访客可以在一天中多次进入应用,所以我们要在一天的范围内进行去重
代码,新建任务UniqueVisitApp.java,我们要从kafka的ods层消费数据,主题为:dwd_page_log
package com.zhangbao.gmall.realtime.app.dwm;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.zhangbao.gmall.realtime.utils.MyKafkaUtil;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
/**
* @author: zhangbao
* @date: 2021/9/12 19:51
* @desc: uv 计算
**/
public class UniqueVisitApp {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
//设置并行度
env.setParallelism(4);
//设置检查点
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(60000);
env.setStateBackend(new FsStateBackend("hdfs://hadoop101:9000/gmall/flink/checkpoint/uniqueVisit"));
//指定哪个用户读取hdfs文件
System.setProperty("HADOOP_USER_NAME","zhangbao");
//从kafka读取数据源
String sourceTopic = "dwd_page_log";
String group = "unique_visit_app_group";
FlinkKafkaConsumer<String> kafkaSource = MyKafkaUtil.getKafkaSource(sourceTopic, group);
DataStreamSource<String> kafkaDs = env.addSource(kafkaSource);
//数据转换
SingleOutputStreamOperator<JSONObject> jsonObjDs = kafkaDs.map(obj -> JSON.parseObject(obj));
jsonObjDs.print("jsonObjDs >>>");
try {
env.execute("task uniqueVisitApp");
} catch (Exception e) {
e.printStackTrace();
}
}
}测试从kafka消费数据
启动服务:zk,kf,logger.sh ,hadoop
运行任务:BaseLogTask.java,UniqueVisitApp.java
执行日志生成服务器
查看控制台输出
目前任务执行流程

UniqueVisitApp程序接收到的数据
{
"common": {
"ar": "440000",
"uid": "48",
"os": "Android 11.0",
"ch": "xiaomi",
"is_new": "0",
"md": "Sumsung Galaxy S20",
"mid": "mid_9",
"vc": "v2.1.134",
"ba": "Sumsung"
},
"page": {
"page_id": "login",
"during_time": 4621,
"last_page_id": "good_detail"
},
"ts": 1631460110000
}3. 核心过滤流程
从kafka的ods层取出数据之后,就该做具体的uv处理了。
1.首先用 keyby 按照 mid 进行分组,每组表示当前设备的访问情况
2.分组后使用 keystate 状态,记录用户进入时间,实现 RichFilterFunction 完成过滤
3.重写 open 方法用来初始化状态
4.重写 filter 方法进行过滤
可以直接筛掉 last_page_id 不为空的字段,因为只要有上一页,说明这条不是这个用户进入的首个页面。
状态用来记录用户的进入时间,只要这个 lastVisitDate 是今天,就说明用户今天已经访问过了所以筛除掉。如果为空或者不是今天,说明今天还没访问过,则保留。
因为状态值主要用于筛选是否今天来过,所以这个记录过了今天基本上没有用了,这里 enableTimeToLive 设定了 1 天的过期时间,避免状态过大。
package com.zhangbao.gmall.realtime.app.dwm;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.zhangbao.gmall.realtime.utils.MyKafkaUtil;
import org.apache.flink.api.common.functions.RichFilterFunction;
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
* @author: zhangbao
* @date: 2021/9/12 19:51
* @desc: uv 计算
**/
public class UniqueVisitApp {
public static void main(String[] args) {
//webui模式,需要添加pom依赖
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
// StreamExecutionEnvironment env1 = StreamExecutionEnvironment.createLocalEnvironment();
//设置并行度
env.setParallelism(4);
//设置检查点
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(60000);
env.setStateBackend(new FsStateBackend("hdfs://hadoop101:9000/gmall/flink/checkpoint/uniqueVisit"));
//指定哪个用户读取hdfs文件
System.setProperty("HADOOP_USER_NAME","zhangbao");
//从kafka读取数据源
String sourceTopic = "dwd_page_log";
String group = "unique_visit_app_group";
FlinkKafkaConsumer<String> kafkaSource = MyKafkaUtil.getKafkaSource(sourceTopic, group);
DataStreamSource<String> kafkaDs = env.addSource(kafkaSource);
//数据转换
SingleOutputStreamOperator<JSONObject> jsonObjDs = kafkaDs.map(obj -> JSON.parseObject(obj));
//按照设备id分组
KeyedStream<JSONObject, String> keyByMid = jsonObjDs.keyBy(jsonObject -> jsonObject.getJSONObject("common").getString("mid"));
//过滤
SingleOutputStreamOperator<JSONObject> filterDs = keyByMid.filter(new RichFilterFunction<JSONObject>() {
ValueState<String> lastVisitDate = null;
SimpleDateFormat sdf = null;
@Override
public void open(Configuration parameters) throws Exception {
//初始化时间
sdf = new SimpleDateFormat("yyyyMMdd");
//初始化状态
ValueStateDescriptor<String> lastVisitDateDesc = new ValueStateDescriptor<>("lastVisitDate", String.class);
//统计日活dau,状态数据保存一天,过一天即失效
StateTtlConfig stateTtlConfig = StateTtlConfig.newBuilder(Time.days(1)).build();
lastVisitDateDesc.enableTimeToLive(stateTtlConfig);
this.lastVisitDate = getRuntimeContext().getState(lastVisitDateDesc);
}
@Override
public boolean filter(JSONObject jsonObject) throws Exception {
//上一个页面如果有值,则不是首次访问
String lastPageId = jsonObject.getJSONObject("page").getString("last_page_id");
if(lastPageId != null && lastPageId.length()>0){
return false;
}
//获取用户访问日期
Long ts = jsonObject.getLong("ts");
String mid = jsonObject.getJSONObject("common").getString("mid");
String lastDate = sdf.format(new Date(ts));
//获取状态日期
String lastDateState = lastVisitDate.value();
if(lastDateState != null && lastDateState.length()>0 && lastDateState.equals(lastDate)){
System.out.println(String.format("已访问! mid:%s,lastDate:%s",mid,lastDate));
return false;
}else {
lastVisitDate.update(lastDate);
System.out.println(String.format("未访问! mid:%s,lastDate:%s",mid,lastDate));
return true;
}
}
});
filterDs.print("filterDs >>>");
try {
env.execute("task uniqueVisitApp");
} catch (Exception e) {
e.printStackTrace();
}
}
}注:1.在测试时,发现uv没有数据,所以把BaseLogTask任务的侧输出流改一下,如下图所示:
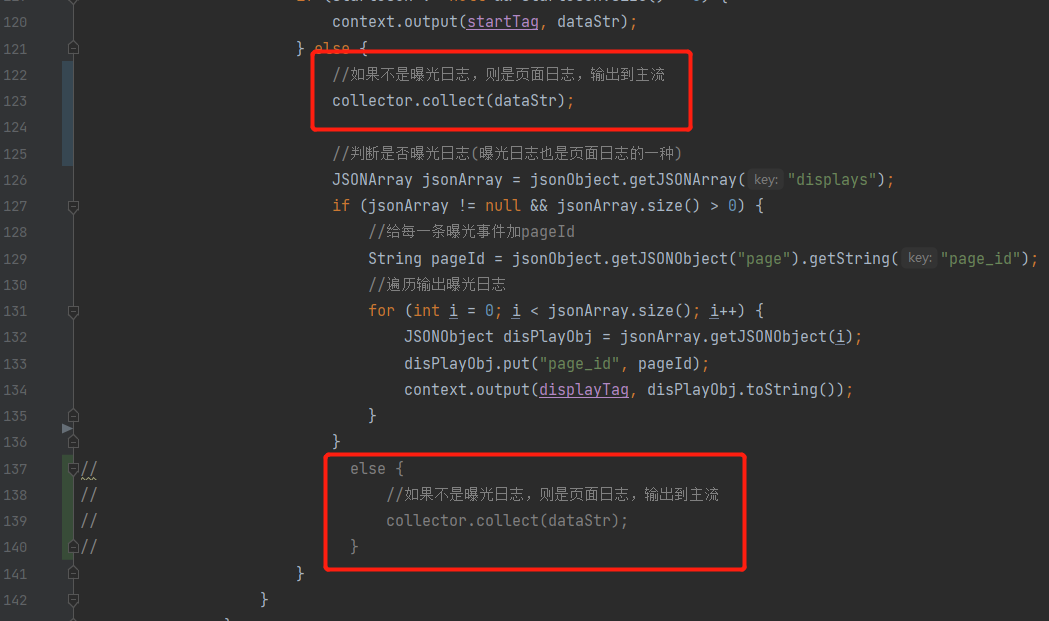
2.webui模式添加pom依赖
<!-- flink webui -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_2.12</artifactId>
<version>1.12.0</version>
</dependency>4. 测试
启动zk,kafka,logger.sh,hdfs,BaseLogTask,UniqueVisitApp
执行流程
模拟生成的日志jar >> nginx >> 日志采集服务 >> kafka(ods) >> baseLogApp(分流) >> kafka(dwd) >> UniqueVisitApp(独立访客) >> dwm_unique_visit
经测试,流程已通。
7.Flink实时项目之独立访客开发的更多相关文章
- PV(访问量)、UV(独立访客)、IP(独立IP) (转)
网站统计中的PV(访问量):UV(独立访客):IP(独立IP)的定义与区别今天使用了雅虎统计,看到里面就有这个,就说说,其实里面的uv大家可能觉得很新奇,但是和站长统计里的独立访客是一样的嘛.---- ...
- 8.Flink实时项目之CEP计算访客跳出
1.访客跳出明细介绍 首先要识别哪些是跳出行为,要把这些跳出的访客最后一个访问的页面识别出来.那么就要抓住几个特征: 该页面是用户近期访问的第一个页面,这个可以通过该页面是否有上一个页面(last_p ...
- 4.Flink实时项目之数据拆分
1. 摘要 我们前面采集的日志数据已经保存到 Kafka 中,作为日志数据的 ODS 层,从 kafka 的ODS 层读取的日志数据分为 3 类, 页面日志.启动日志和曝光日志.这三类数据虽然都是用户 ...
- 5.Flink实时项目之业务数据准备
1. 流程介绍 在上一篇文章中,我们已经把客户端的页面日志,启动日志,曝光日志分别发送到kafka对应的主题中.在本文中,我们将把业务数据也发送到对应的kafka主题中. 通过maxwell采集业务数 ...
- 10.Flink实时项目之订单维度表关联
1. 维度查询 在上一篇中,我们已经把订单和订单明细表join完,本文将关联订单的其他维度数据,维度关联实际上就是在流中查询存储在 hbase 中的数据表.但是即使通过主键的方式查询,hbase 速度 ...
- 3.Flink实时项目之流程分析及环境搭建
1. 流程分析 前面已经将日志数据(ods_base_log)及业务数据(ods_base_db_m)发送到kafka,作为ods层,接下来要做的就是通过flink消费kafka 的ods数据,进行简 ...
- 6.Flink实时项目之业务数据分流
在上一篇文章中,我们已经获取到了业务数据的输出流,分别是dim层维度数据的输出流,及dwd层事实数据的输出流,接下来我们要做的就是把这些输出流分别再流向对应的数据介质中,dim层流向hbase中,dw ...
- 9.Flink实时项目之订单宽表
1.需求分析 订单是统计分析的重要的对象,围绕订单有很多的维度统计需求,比如用户.地区.商品.品类.品牌等等.为了之后统计计算更加方便,减少大表之间的关联,所以在实时计算过程中将围绕订单的相关数据整合 ...
- 11.Flink实时项目之支付宽表
支付宽表 支付宽表的目的,最主要的原因是支付表没有到订单明细,支付金额没有细分到商品上, 没有办法统计商品级的支付状况. 所以本次宽表的核心就是要把支付表的信息与订单明细关联上. 解决方案有两个 一个 ...
随机推荐
- Linux无写权限打zip
opt下tiger.txt没权限得时候可以这样直接用zip打包 zip /tmp/1.zip /opt/tiger.txt
- Android安卓开发-记账本布局
账单页面布局统计页面布局我的页面布局主页面加号记账页面布局.点击记账页面记账类别布局点击收入页面收入类别布局统计页面支出布局统计页面收入布局查询页面布局数据库设计字段一,支出id和收入id分配字段二, ...
- Visualizing and Understanding Convolutional Networks论文复现笔记
目录 Visualizing and Understanding Convolutional Networks 论文复现笔记 Abstract Introduction Approach Visual ...
- python3调用js的库之execjs
执行JS的类库:execjs,PyV8,selenium,node execjs是一个比较好用且容易上手的类库(支持py2,与py3),支持 JS runtime. 1.安装: pip install ...
- Redis哨兵模式高可用解决方案
一.序言 Redis高可用有两种模式:哨兵模式和集群模式,本文基于哨兵模式搭建一主两从三哨兵Redis高可用服务. 1.目标与收获 一主两从三哨兵Redis服务,基本能够满足中小型项目的高可用要求,使 ...
- windows10使用wireshark抓取本机请求包
1.管理员运行cmd 右键左下角windows图标,管理员运行Windows PowerShell 2.输入ipconfg查看本机ip和网关ip 3.执行命令 route add 本机ip mask ...
- Python调用windows下DLL详解 - ctypes库的使用
在python中某些时候需要C做效率上的补充,在实际应用中,需要做部分数据的交互.使用python中的ctypes模块可以很方便的调用windows的dll(也包括linux下的so等文件),下面将详 ...
- Tomcat多实例单应用部署方案 (转)
一.Tomcat部署的场景分析 通常,我们对tomcat部署需求可以分为几种:单实例单应用,单实例多应用,多实例单应用,多实例多应用. 对于第一种场景,如果不要求周期性地维护tomcat版本,一般的做 ...
- Java与网页JSP文件编码的小总结
感谢大佬: https://www.cnblogs.com/yangguoe/p/8467672.html(编码发展史) https://blog.csdn.net/seabiscuityj/arti ...
- shell中的括号(小括号,大括号/花括号)
在这里我想说的是几种shell里的小括号,大括号结构和有括号的变量,命令的用法,如下: 1.${var} 2.$(cmd) 3.()和{} 4.${var:-string},${var:+string ...