Flink State Rescale性能优化
背景
今天我们来聊一聊flink中状态rescale的性能优化。我们知道flink是一个支持带状态计算的引擎,其中的状态分为了operator state和 keyed state两类。简而言之operator state是和key无关只是到operator粒度的一些状态,而keyed state是和key绑定的状态。而Rescale,意味着某个状态节点发生了并发的缩扩。在任务不修改并发重启的情况下,我们只需要按照task,将先前job的各个并发的state handle重新分发处理下载远程的持久化的state文件即可恢复。而发生rescale时,状态的数据分布将发生变化,因此存在一个reshuffle的过程,那么我们就来看看这个rescale的实现是怎么做的,以及其问题和优化手段。
Rescale的实现
2017年社区有一篇博客就比较深入的介绍了Operator 和 keyed state的rescale的实现,感兴趣的话可以去了解下。
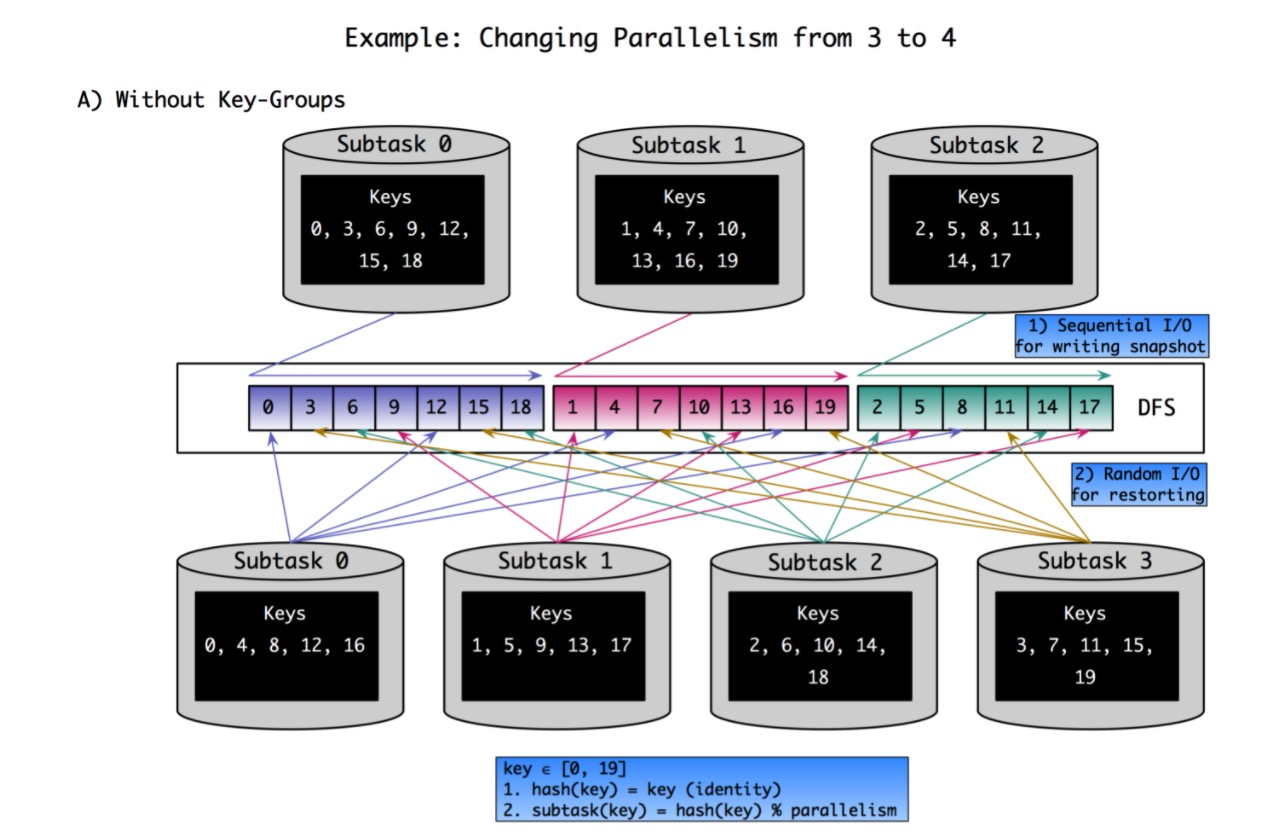
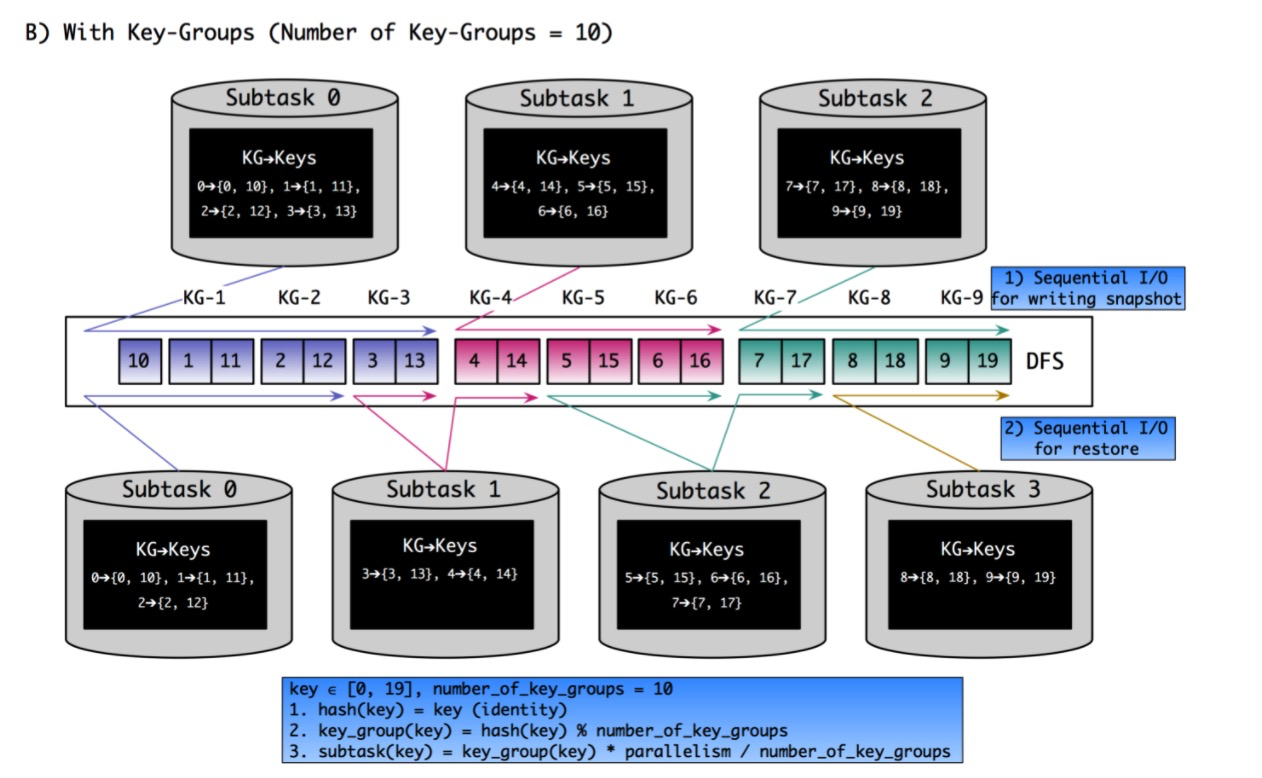
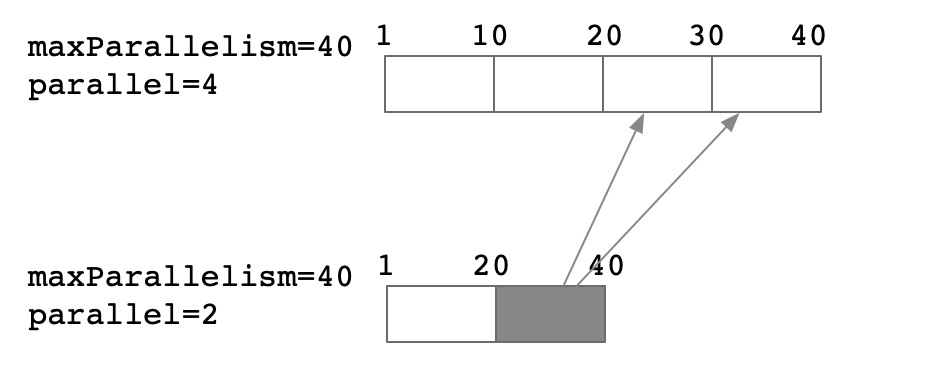
这两张图对比了是否基于keyGroup来划区的一个差别,社区中的版本使用的是基于keygroup的版本实现的,可以看到可以减少对于数据的random的访问。但是从B中我们看到,以rescale后的subtask为例:
- subtask-0: 需要将原先subtask-0的dfs文件下载后将KG-3的数据剔除掉。这里需要剔除的原因是: 虽然我们任务启动后由于keyshuffle的原因,subtask-0不会再接收到KG-3的数据,但是后续如果继续做checkpoint,会导致这部分数据重新被上传到DFS文件中,而如果继续发生rescale,就可能导致和其他subtask-1上的KG-3的数据发生冲突导致数据问题
- subtask-1: 需要download原先subtask-0和subtask-1的数据dfs文件,并将subtask-0中的KG-1和KG-2的数据删除,以及原先subtask-1中的 KG-5 和 KG-6删除,并将其导入到新的RocksDB实例中。
因此我们可以总结出rescale的大致流程中,首先会将当前task所涉及的db文件恢复到本地,并从中挑选出属于当前keygroup的数据重新构建出新的db。
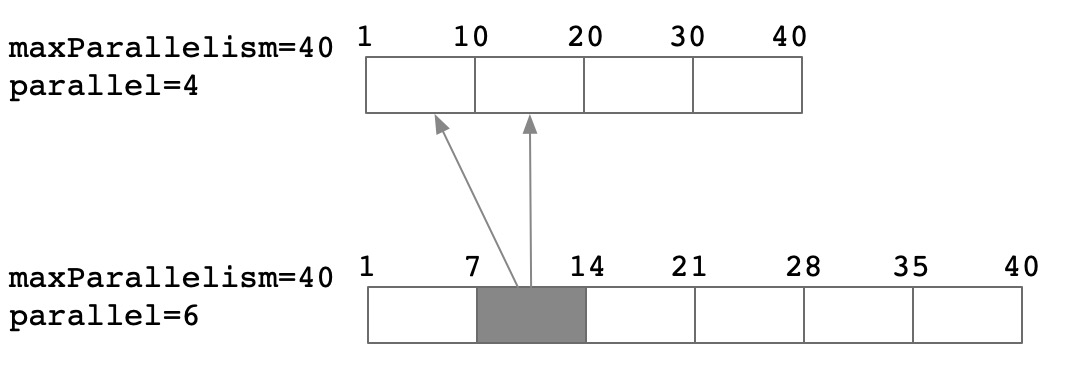
从理论上分析,在不同的并发调整场景下,其rescale的代价也不尽相同
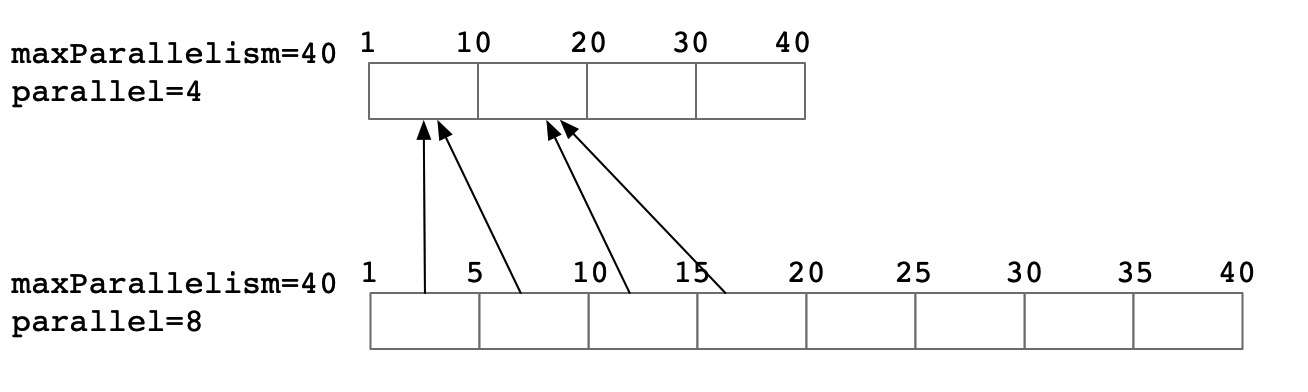
并发翻倍
1.5倍扩并发
并发减半
接下来,我们在代码中确认相关的逻辑(代码基于Flink1.15版本)。
根据stateHandle元信息判断是否是rescale
我们可以看到当restoreStateHandles的数量大于1,或者stateHandle的keyGroupRange和当前task的range不一致时就是rescale的过程

在不是rescale的场景下,恢复的流程只需要将相应IncrementalRemoteKeyedStateHandle对应的文件下载到本地或者是直接使用local recovery中的 IncrementalLocalKeyedStateHandle所对应的本地文件的目录,直接执行 RocksDB.open()就可以将db数据恢复。
initialDB
首先根据keygroup的重叠比较,挑选出和当前keygroup有最大重叠范围的stateHandle作为initial state handle。这样的好处是可以尽可能利用最大重叠部分的数据,减少后续数据遍历的过程。在挑选出initial state handle 创建db之后,首先需要将db中不属于当前的task的keygroup的数据进行遍历删除。
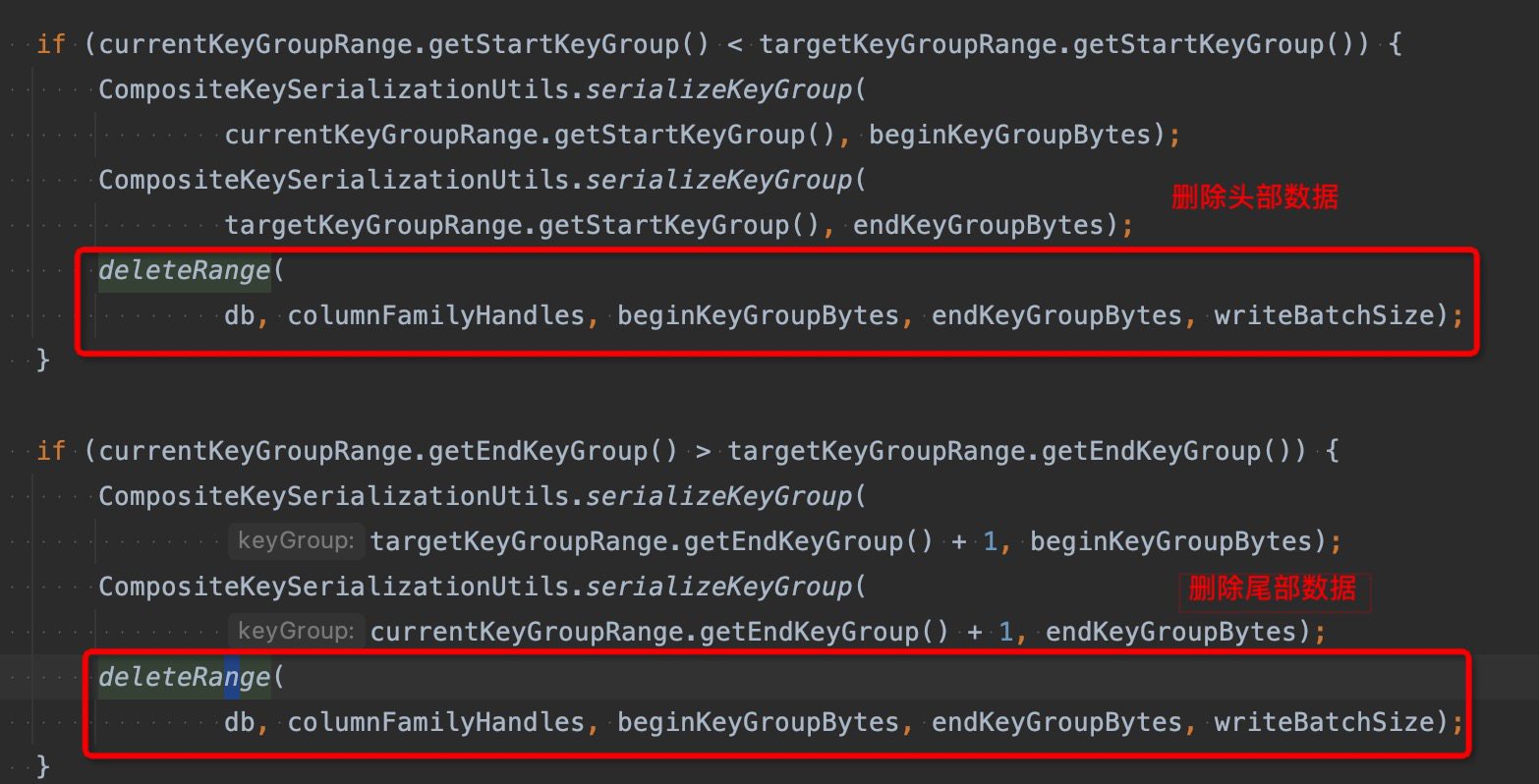
因为flink中存储的keyed state的数据已经按照keygroup作为前缀作为排序,所以只需要删除头部和尾部的数据即可,这样就不用遍历全量的数据。
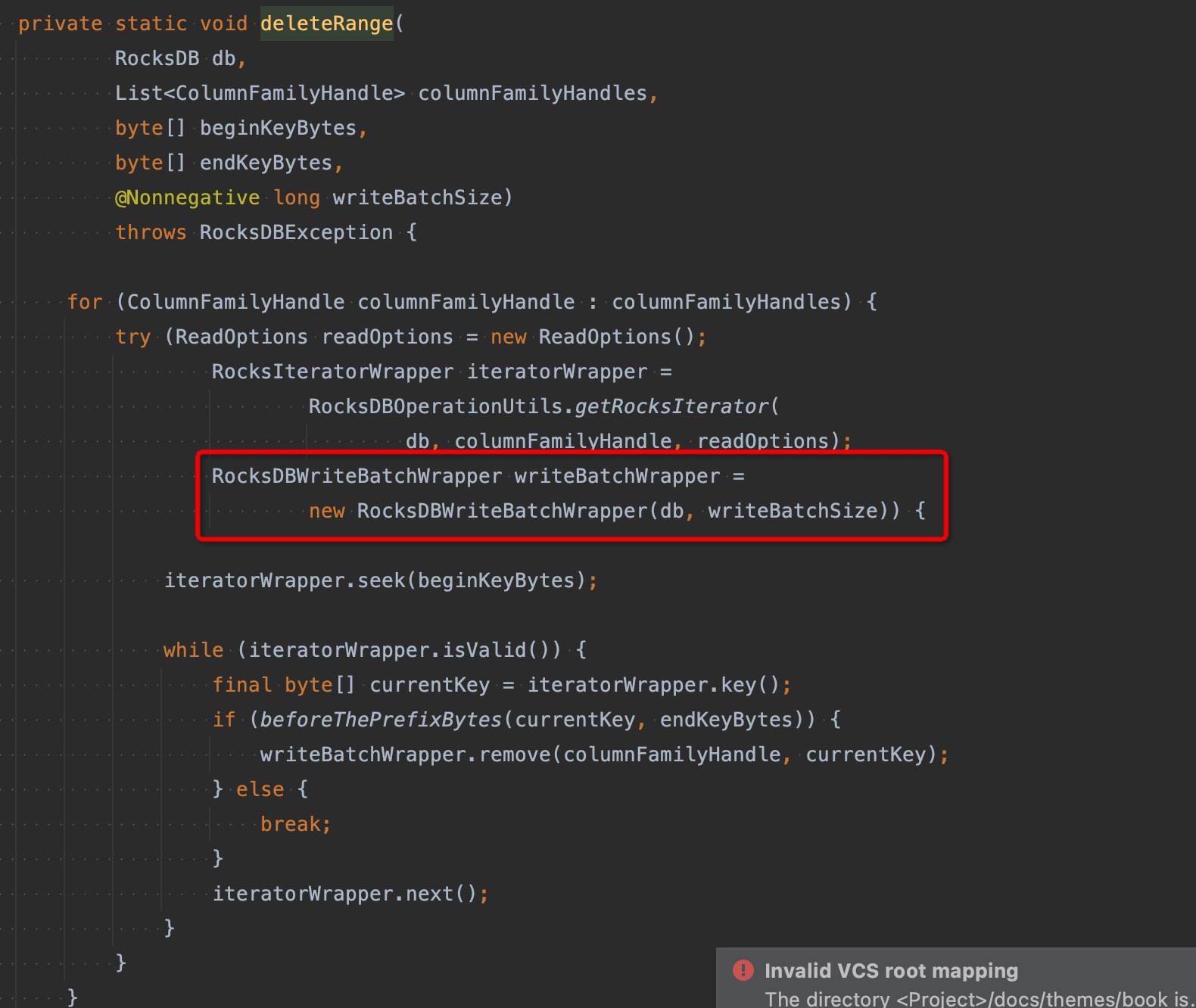
在当前的deleteRange的实现中是依赖遍历db,通过writeBatch的方式进行批量执行删除,这种方式当需要删除的key的基数较大时会比较耗时,并且都会触发io和compaction的开销,而rocksdb提供了deleteRange的接口,可以通过指定start和end key来进行快速的删除,经过测试下来基本只要ms级别就可以完成。参考 FLINK-21321
Bulk load
在完成base db裁剪之后,就需要将其他db的数据导入到base db中,目前的实现还是通过writeBatch来加速写入
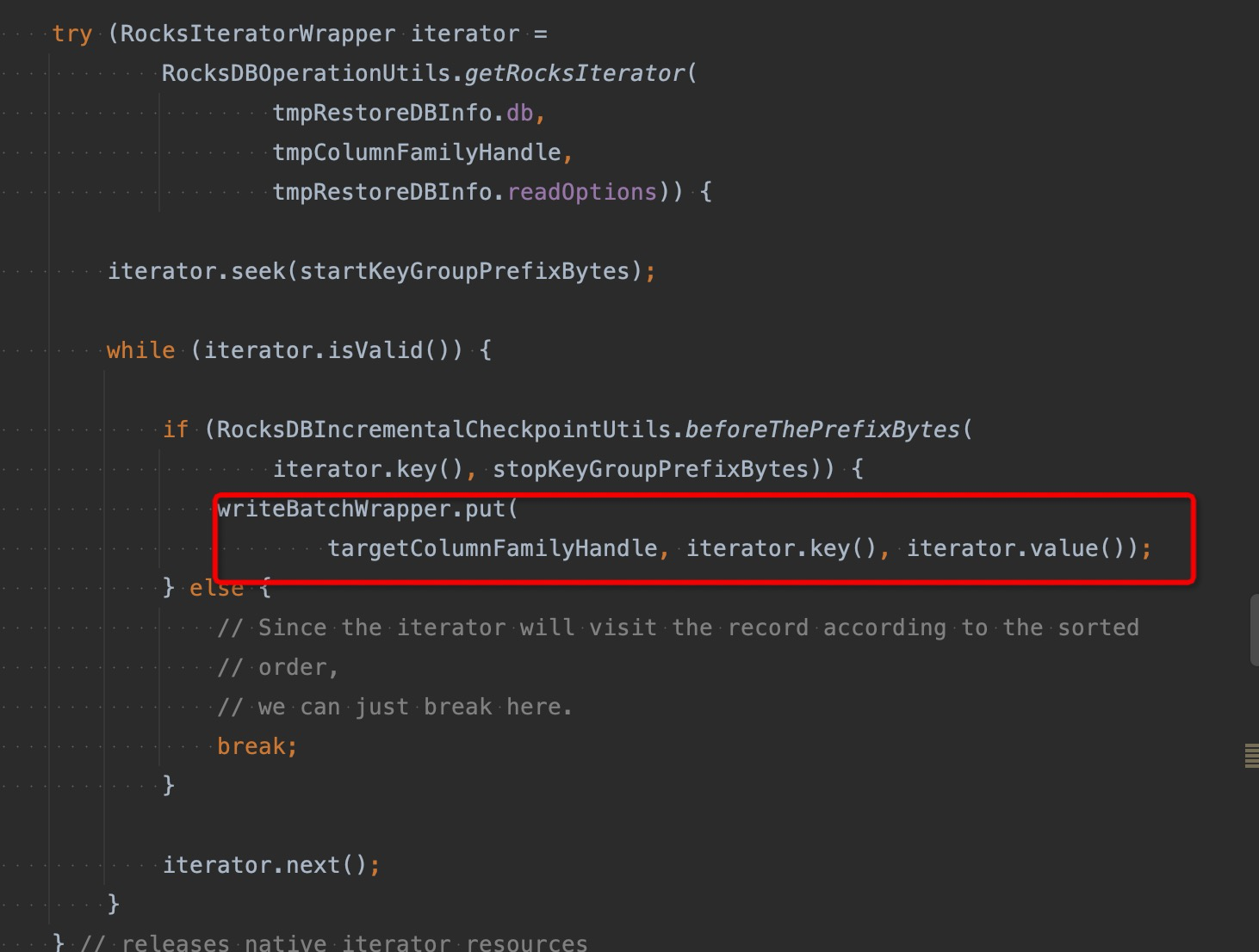
在 FLINK-17971 中作者提供了sst ingest 写入的实现,本质上是利用rocksdb 的sst writer的工具,通过sst writer能直接构建出sst 文件,避免了直接写的过程中的compaction的问题,然后通过 db.ingestExternalFile直接将其导入db中。实际测试的过程中这样的写入性能有2-3倍的提升。
Rescale的优化应该迭代优化了很多次,最开始的实现应该是将所有的statehandle的数据download下来,将其遍历写入新的db,在 FLINK-8790 中首先将其优化成 base db + delete Range + bulk load的方式,后续的两个pr又通过Rocksdb提供的deleteRange + SSTIngest 特性加速。虽然这些优化应用上只有rescale的提速很明显,但是当我们遇到key的基数非常大时,就会出现我们遍历原先的db next调用和 写入的耗时也非常的大,因此rescale的场景可能还需要继续优化。
关于RocksDB中deleteRange和SST Ingest功能笔者也做了一些研究,在后续的文章中会陆续更新出来,敬请期待
参考
https://blog.csdn.net/Z_Stand/article/details/115799605 sst ingest 原理
http://rocksdb.org/blog/2017/02/17/bulkoad-ingest-sst-file.html
https://rocksdb.org/blog/2018/11/21/delete-range.html delete range原理
Flink State Rescale性能优化的更多相关文章
- 《大数据实时计算引擎 Flink 实战与性能优化》新专栏
基于 Flink 1.9 讲解的专栏,涉及入门.概念.原理.实战.性能调优.系统案例的讲解. 专栏介绍 扫码下面专栏二维码可以订阅该专栏 首发地址:http://www.54tianzhisheng. ...
- 第一章-Flink介绍-《Fink原理、实战与性能优化》读书笔记
Flink介绍-<Fink原理.实战与性能优化>读书笔记 1.1 Apache Flink是什么? 在当代数据量激增的时代,各种业务场景都有大量的业务数据产生,对于这些不断产生的数据应该如 ...
- C#中那些[举手之劳]的性能优化
隔了很久没写东西了,主要是最近比较忙,更主要的是最近比较懒...... 其实这篇很早就想写了 工作和生活中经常可以看到一些程序猿,写代码的时候只关注代码的逻辑性,而不考虑运行效率 其实这对大多数程序猿 ...
- Mysql - 性能优化之子查询
记得在做项目的时候, 听到过一句话, 尽量不要使用子查询, 那么这一篇就来看一下, 这句话是否是正确的. 那在这之前, 需要介绍一些概念性东西和mysql对语句的大致处理. 当Mysql Server ...
- MYSQL性能优化的最佳20+条经验
MYSQL性能优化的最佳20+条经验 2009年11月27日 陈皓 评论 148 条评论 131,702 人阅读 今天,数据库的操作越来越成为整个应用的性能瓶颈了,这点对于Web应用尤其明显.关于数 ...
- React 组件性能优化
React组件性能优化 前言 众所周知,浏览器的重绘和重排版(reflows & repaints)(DOM操作都会引起)才是导致网页性能问题的关键.而React虚拟DOM的目的就是为了减少浏 ...
- CentOS 6.5 安全加固及性能优化 (转)
通过修改CentOS 6.5 的系统默认设置,对系统进行安全加固,进行系统的性能优化. 环境: 系统硬件:vmware vsphere (CPU:2*4核,内存2G) 系统版本:Centos-6.5- ...
- Android应用性能优化(转)
人类大脑与眼睛对一个画面的连贯性感知其实是有一个界限的,譬如我们看电影会觉得画面很自然连贯(帧率为24fps),用手机当然也需要感知屏幕操作的连贯性(尤其是动画过度),所以Android索性就把达到这 ...
- EntityFramework之原始查询及性能优化(六)
前言 在EF中我们可以通过Linq来操作实体类,但是有些时候我们必须通过原始sql语句或者存储过程来进行查询数据库,所以我们可以通过EF Code First来实现,但是SQL语句和存储过程无法进行映 ...
随机推荐
- JAVA获取请求链接中所有参数(GET请求)
Enumeration<String> paraNames=request.getParameterNames(); for(Enumeration<String> e=par ...
- 【蓝桥杯】非VIP基础题型训练17题 (Python 题解)
NO.I 基础题型 基础练习汇总 时间 题目 解析 21.12.24 早上 1. A+B问题 练习系统的适应 21.12.24 早上 2. 数组排序 输入输出排序 21.12.24 早上 3. 十六进 ...
- NULL在oracle和mysql索引上的区别
一.问题 oracle的btree索引不存储NULL值,所以用is null或is not null都不会用到索引范围扫描,但是在mysql中也是这样吗? 二.实验 先看看NULL在oracle(11 ...
- Visual Studio Code常用快捷键
说明 以下快捷键适用于windows环境下, Mac请将ctrl替换为command按键: 部分快捷键或不一样. 查看VSCode快捷键定义: settings -> keymaps. 目前使用 ...
- 【LeetCode】479. Largest Palindrome Product 解题报告(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 日期 题目地址:https://leetcode.c ...
- 1065 - Number Sequence &&1070 - Algebraic Problem
1065 - Number Sequence PDF (English) Statistics Forum Time Limit: 2 second(s) Memory Limit: 32 MB ...
- css--深入理解z-index引发的层叠上下文、层叠等级和层叠顺序
前言 在编写css样式代码的时候,我们经常会遇到z-index属性的使用,我们可能只了解z-index能够提高元素的层级,并不知道具体是怎么实现的.本文就来总结一个由z-index 引发的层叠上下文和 ...
- Differential Evolution: A Survey of the State-of-the-Art
@ 目录 概 主要内容 DE/rand/1/bin DE/?/?/? DE/rand/1/exp DE/best/1 DE/best/2 DE/rand/2 超参数的选择 的选择 的选择 的选择 一些 ...
- Web前端浏览器默认样式重置(CSS Tools: Reset CSS)
/* http://meyerweb.com/eric/tools/css/reset/ v2.0 | 20110126 License: none (public domain) */ html, ...
- 使用 JavaScript 中的变量、数据类型和运算符,计算出两个 number 类型的变量与一个 string 类型的变量的和,根据 string 类型处于运算符的不同位置得到不同的结果
查看本章节 查看作业目录 需求说明: 使用 JavaScript 中的变量.数据类型和运算符,计算出两个 number 类型的变量与一个 string 类型的变量的和,根据 string 类型处于运算 ...