第二十四篇 -- Cache学习
Cache存储器
电脑中为高速缓冲存储器,是位于CPU和主存储器DRAM(Dynamic Random Access Memory)之间,规模较小,但速度很高的存储器,通常由SRAM(Static Random Access Memory 静态存储器)组成。它是位于CPU与内存间的一种容量较小但速度很高的存储器。CPU的速度远高于内存,当CPU直接从内存中存取数据时要等待一定时间周期,而Cache则可以保存CPU刚用过或循环使用的一部分数据,如果CPU需要再次使用该部分数据时可从Cache中直接调用,这样就避免了重复存取数据,减少了CPU的等待时间,因而提高了系统的效率。Cache又分为L1Cache(一级缓存)和L2Cache(二级缓存),L1Cache主要是集成在CPU内部,而L2Cache集成在主板上或是CPU上。
代码
/*
* 代码思路:创建一个连续内存块,进行连贯、大量、随机的有意义访问,要保证整块内存尽可能全部放入cache。当
* 内存被整块放入cache中时,访问速度会明显加快,直到有一个时间跳跃点,消耗时间增多,则这个跳跃点的存储容* 量大小即为cache大小
*/
#include <iostream>
#include <random>
#include <ctime>
#include <algorithm> #define KB(x) ((size_t)(x) << 10) using namespace std; int main()
{
// 需要测试的数组的大小
vector<size_t> sizes_KB;
for (int i = 1; i < 18; i++)
{
sizes_KB.push_back(1 << i);
}
random_device rd;
// 伪随机数算法,计算更快,占用内存更少
mt19937 gen(rd()); for (size_t size : sizes_KB)
{
// 离散均匀分布类
uniform_int_distribution<> dis(0, KB(size) - 1);
// 创建连续内存块
vector<char> memory(KB(size));
// 在内存中填入内容
fill(memory.begin(), memory.end(), 1); int dummy = 0; // 在内存上进行大量的随机访问并计时
clock_t begin = clock();
// 1<<25:将1左移25位,进行大量随机访问
for (int i = 0; i < (1 << 25); i++)
{
dummy += memory[dis(gen)];
}
clock_t end = clock(); // 输出
double elapsed_secs = double(end - begin) / CLOCKS_PER_SEC;
cout << size << " KB, " << elapsed_secs << "secs, dummy:" << dummy << endl;
}
}
运行结果:

测试结果并未看出什么,如果按照链接的跳跃点也是在1024kb,不过我电脑的大小是8M。
想要知道各级缓存的大小,可以查看任务管理器。
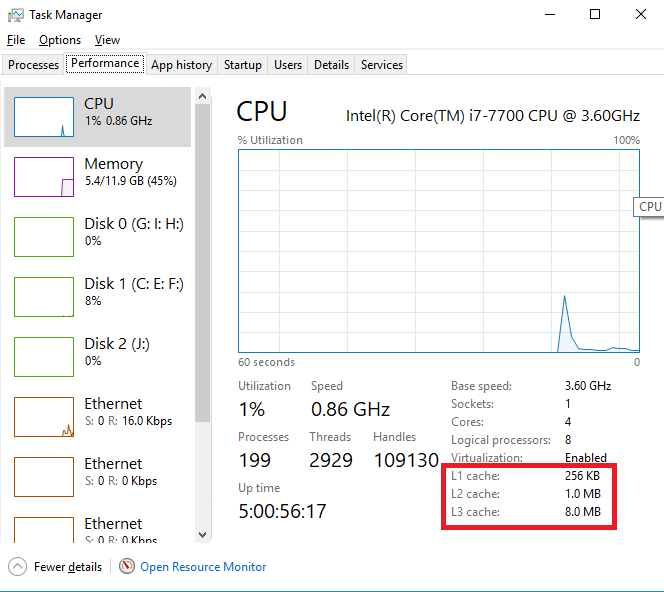
可以看到三级缓存是8M。怎么获取Cache的大小,可以使用CPUID命令,查看相应CPU的datasheet,但是会区分Intel和AMD,Intel的看CPUID的Spec,AMD的看CPU的datasheet就行了,里面会有CPUID命令。
然后用CPUID得到L1cache是64kb,L2cache是256kb,L3cache是8M。看起来和任务管理器里面的不一样,L1cache和L2cache明显有差异。那么到底谁对谁错呢,于是继续研究下去,使用了cpu-z的工具查看,仿佛明白了一点点。这个工具上显示的结果也是64,256,8192,貌似和CPUID命令得到的结果是一样的,然后仔细看了下去,翻到Cache那一页,发现L1cache和L2cache后面还有x4的字样,突然想到之前在哪篇文章里好像看到过CPU的每一个核里都会有cache,然后看了一下这个CPU的核数,刚好是四核。好像可以解释了,但是为什么L3没有x4呢,虽然有一定的猜测,但是还不确定,L1,L2,L3,L4级数越高,离CPU越远,会不会是L1,L2正好集成在CPU上,而L3集成在CPU外部呢,也是有这种可能的,不过目前还没有依据。
存储器是分层次的,离CPU越近的存储器。速度越快,每字节的成本越高,同时容量也因此越小。寄存器速度最快,离CPU最近,成本最高,所以个数容量有限,其次是高速缓存(缓存也是分级,有L1,L2等缓存),再次是主存(普通内存),再次是本地磁盘。
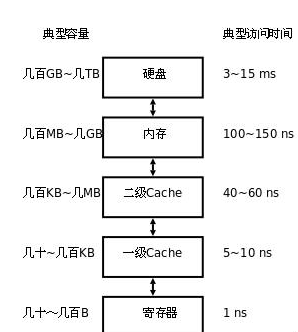
寄存器的速度最快,可以在一个时钟周期内访问,其次是高速缓存,可以在几个时钟周期内访问,普通内存可以在几十个或几百个时钟周期内访问。
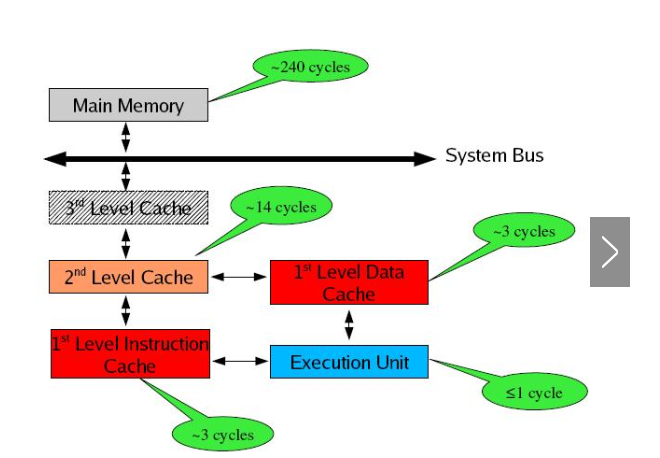
存储器分级,利用的是局部性原理。我们可以以经典的阅读书籍为例。我在读的书,捧在手里(寄存器),我最近频繁阅读的书,放在书桌上(缓存),随时取来读。当然书桌上只能放有限几本书。我更多的书放在书架上(内存)。如果书架上没有的书,就去图书馆(磁盘)。我要读的书如果手里没有,那么去书桌上找,如果书桌上没有,去书架上找,如果书架上没有,去图书馆找。可以对应寄存器没有,则从缓存中取,缓存中没有,则从内存中取到缓存,如果内存中没有,则先从磁盘读入内存,再读入缓存,再读入寄存器。
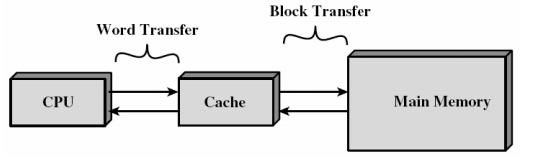
cache分成多个组,每个组分成多个行,linesize是cache的基本单位,从主存向cache迁移数据都是按照linesize为单位替换的。比如linesize为32Byte,那么迁移必须一次迁移32Byte到cache。这个linesize比较容易理解,想想我们前面书的例子,我们从书架往书桌搬书必须以书为单位,肯定不能把书撕了以页为单位。书就是linesize。当然了现实生活中每本书页数不同,但是同个cache的linesize总是相同的。
所谓8路相连(8-way set associative) 的含义是指,每个组里面有8个行。
我们知道,cache的容量要远远小于主存,主存和cache肯定不是一一对应的,那么主存中的地址和cache的映射关系是怎样的呢?
拿到一个地址,首先是映射到一个组里面去。如何映射?取内存地址的中间几位来映射。
举例来说,data cache:32-KB,8-way set associative,64-byte line size
Cache总大小为32KB,8路组相连(每组有8个line),每个line的大小linesize为64Byte,OK,我们可以很轻易的算出一共有32K/8/64 = 64个组。
对于32位的内存地址,每个line有2^6 = 64Byte,所以地址的[0,5]区分line中的那个字节。一共有64个组。我们取内存地址中间6位来hash查找地址属于哪个组。即内存地址的[6,11]位来确定属于64组的哪一个组。组确定了之后,[12,31]的内存地址与组中8个line挨个比对,如果[12,31]位与某个line一致,并且这个line为有效,那么缓存命中。
cache分成三类:
1. 直接映射高速缓存,即每个组只有一个line,选中组之后不需要和组中的每个line比对,因为只有一个line。
2. 组相联高速缓存,这个就是我们前面介绍的cache。S个组,每个组E个line。
3. 全相联高速缓存,只有一个组,就是全相联。不用hash来确定组,直接挨个比对高位地址,来确定是否命中。可以想见这种方式不适合大的缓存。想想看,如果4M的大缓存,linesize为32Byte,采用全相联的话,就意味着4*1024*1024/32 = 128K个line挨个比较,来确定是否命中,这是多要命的事情。高速缓存立马成了低速缓存了。
描述一个cache需要以下参数:
1. cache的分级,L1 cache,L2 cache,L3 cache,级别越低,离CPU越近
2. cache的容量
3. cache的linesize
4. cache每组的行个数。
组的个数完全可以根据上面的参数计算出来,所以没有列出来。
Intel手册中用这样的句子来描述cache:
8-MB L3 Cache, 16-way set associative, 64-byte line size
如何获取cache的参数呢,需要用CPU指令,当eax为0x2的时候,cpuid指令获取到cache的参数。当然,具体的还是得看相应的spec,才会知道应该传什么值到什么寄存器,以及从什么寄存器里面读值出来,以及有效位是哪几位。
第二十四篇 -- Cache学习的更多相关文章
- 第二十四篇 jQuery 学习6 删除元素
jQuery 学习6 删除元素 上节课我们做了添加元素,模拟的是楼主发的文章,路人评论,那么同学们这节课学了删除之后,去之前的代码上添加一个删除,模拟一个楼主删除路人的评论. jQuery的删除方 ...
- SpringBoot第二十四篇:应用监控之Admin
作者:追梦1819 原文:https://www.cnblogs.com/yanfei1819/p/11457867.html 版权声明:本文为博主原创文章,转载请附上博文链接! 引言 前一章(S ...
- Python之路【第二十四篇】:Python学习路径及练手项目合集
Python学习路径及练手项目合集 Wayne Shi· 2 个月前 参照:https://zhuanlan.zhihu.com/p/23561159 更多文章欢迎关注专栏:学习编程. 本系列Py ...
- Android UI开发第二十四篇——Action Bar
Action bar是一个标识应用程序和用户位置的窗口功能,并且给用户提供操作和导航模式.在大多数的情况下,当你需要突出展现用户行为或全局导航的activity中使用action bar,因为acti ...
- 【转】Android UI开发第二十四篇——Action Bar
Action bar是一个标识应用程序和用户位置的窗口功能,并且给用户提供操作和导航模式.在大多数的情况下,当你需要突出展现用户行为或全局导航的activity中使用action bar,因为acti ...
- 第二十六篇 jQuery 学习8 遍历-父亲兄弟子孙元素
jQuery 学习8 遍历-父亲兄弟子孙元素 jQuery遍历,可以理解为“移动”,使用“移动”还获取其他的元素. 什么意思呢?老师举一个例子: 班上30位同学,我是新来负责教这个班学生的老师 ...
- 第二十五篇 jQuery 学习7 获取并设置 CSS 类
jQuery 学习7 获取并设置 CSS 类 jQuery动态控制页面,那么什么是动态呢?我们就说一下静态,静态几乎又纯html+css完成,就是刷新页面之后,不会再出现什么变动,一个实打实的静态 ...
- Python之路【第二十四篇】Python算法排序一
什么是算法 1.什么是算法 算法(algorithm):就是定义良好的计算过程,他取一个或一组的值为输入,并产生出一个或一组值作为输出.简单来说算法就是一系列的计算步骤,用来将输入数据转化成输出结果. ...
- 第二十四篇-用VideoView制作一个简单的视频播放器
使用VideoView播放视频,视频路径有三种: 1. SD卡中 2. Android的资源文件中 3. 网络视频 第一种,SD卡中的方法. 路径写绝对路径,如果不能播放,可以赋予读取权限. 效果图: ...
随机推荐
- 实验4、Flask基于Blueprint & Bootstrap布局的应用服务
1. 实验内容 模块化工程内容能够更好的与项目组内成员合作,Flask Blueprint提供了重要的模块化功能,使得开发过程更加清晰便利.此外,Flask也支持Bootstrap的使用. 2. 实验 ...
- 源码级别理解 Redis 持久化机制
文章首发于公众号"蘑菇睡不着",欢迎来访~ 前言 大家都知道 Redis 是一个内存数据库,数据都存储在内存中,这也是 Redis 非常快的原因之一.虽然速度提上来了,但是如果数据 ...
- SpringBoot面试题 (史上最全、持续更新、吐血推荐)
文章很长,建议收藏起来,慢慢读! 疯狂创客圈为小伙伴奉上以下珍贵的学习资源: 疯狂创客圈 经典图书 : <Netty Zookeeper Redis 高并发实战> 面试必备 + 大厂必备 ...
- 【题解】poj 3254 Corn Fields
题目描述 农场主John新买了一块长方形的新牧场,这块牧场被划分成M行N列(1 ≤ M ≤ 12; 1 ≤ N ≤ 12),每一格都是一块正方形的土地.John打算在牧场上的某几格里种上美味的玉米,供 ...
- javascript之一切都是对象
在学习的过程中,我们常常能听到这样一句话:一切皆是对象.那么这句话该如何理解呢?首先,我们要明确对象的概念.要明白除了基本数据类型都是对象. typeof操作符是大家经常使用的,我们常用它来检测给定变 ...
- LVS-NAT模式的实现
一.架构如下: 二.安装过程 1.配置"互联网"服务器 1.1.修改服务器ip为192.168.10.101/24 [root@internet ~]# ip a 1: lo: & ...
- CentOS-yum安装Nginx
查看系统版本 $ cat /etc/redhat-release Nginx 不在默认的 yum 源中,使用官网的 yum 源 $ rpm -ivh http://nginx.org/packages ...
- cache之guava
本文主要记录guava_cache的学习心得! 缓存是什么?为何要用缓存呢? 先参考下图! 这是一张小白图!简单形容了一个普普通通的服务端请求的处理模型! 当一个request请求通过网络不远千里的来 ...
- 欧拉函数&筛法 模板
https://blog.csdn.net/Lytning/article/details/24432651 记牢通式 =x((p1-1)/p1) * ((p2-1)/p2)....((pn-1 ...
- 1shell变量的作用域
Shell 局部变量 Shell 全局变量 shell全局变量的易错点 linux shell中./a.sh , sh a.sh , source a.sh, . ./a.sh的区别 Shell 环境 ...