Attention和Transformer详解
Transformer引入
来源于机器翻译:
Transformer 分为两个部分——编码器(encoders )和解码器(decoders):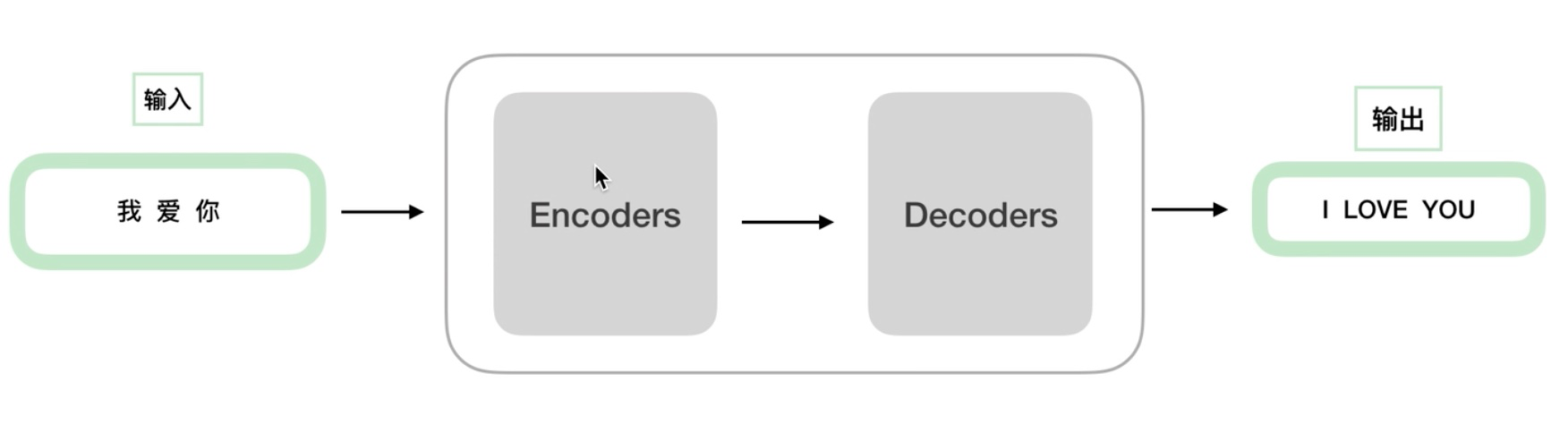
encoders 和 decoders 分解,其中 6 个 encoder 的结构是相同的,但是 6 个 decoder 的参数会独立训练,也就是参数是不同的;decoder 同理:

Transformer 原论文中的图: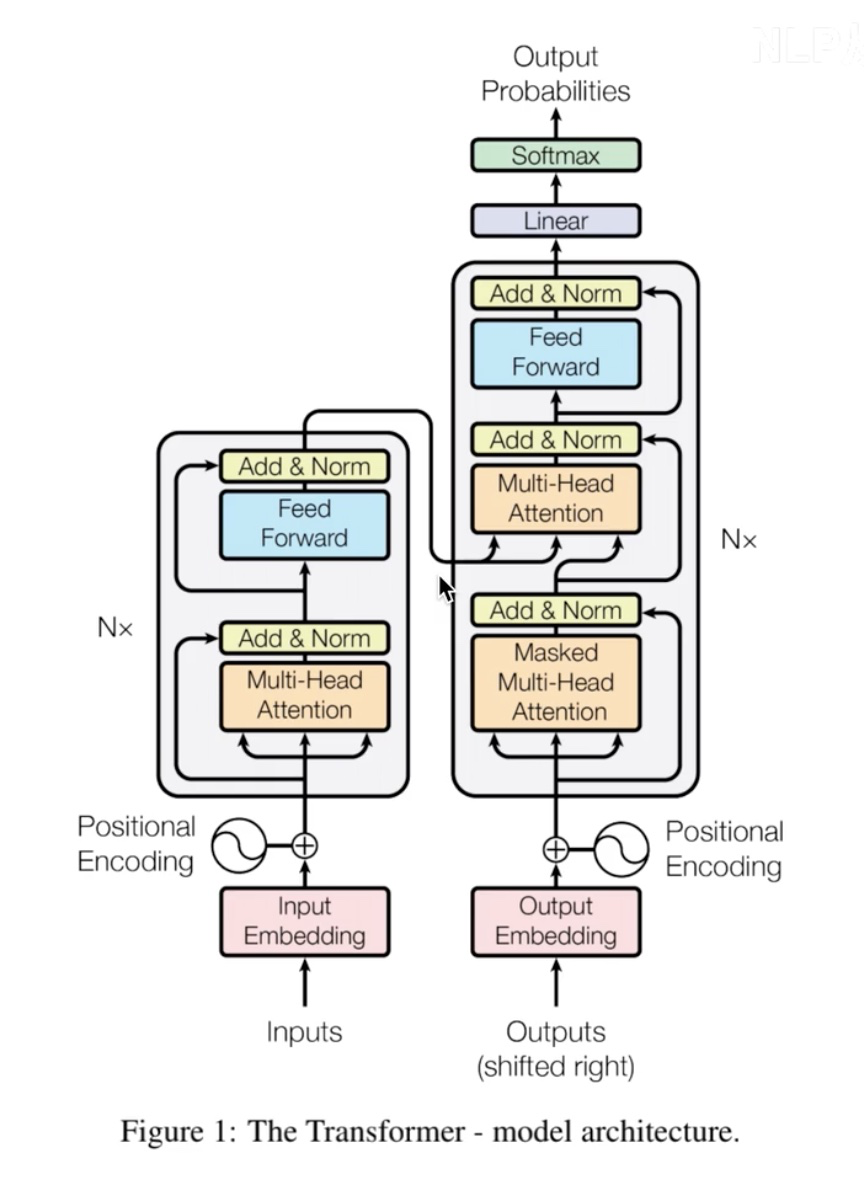
Encoder 详解
encoder 模型: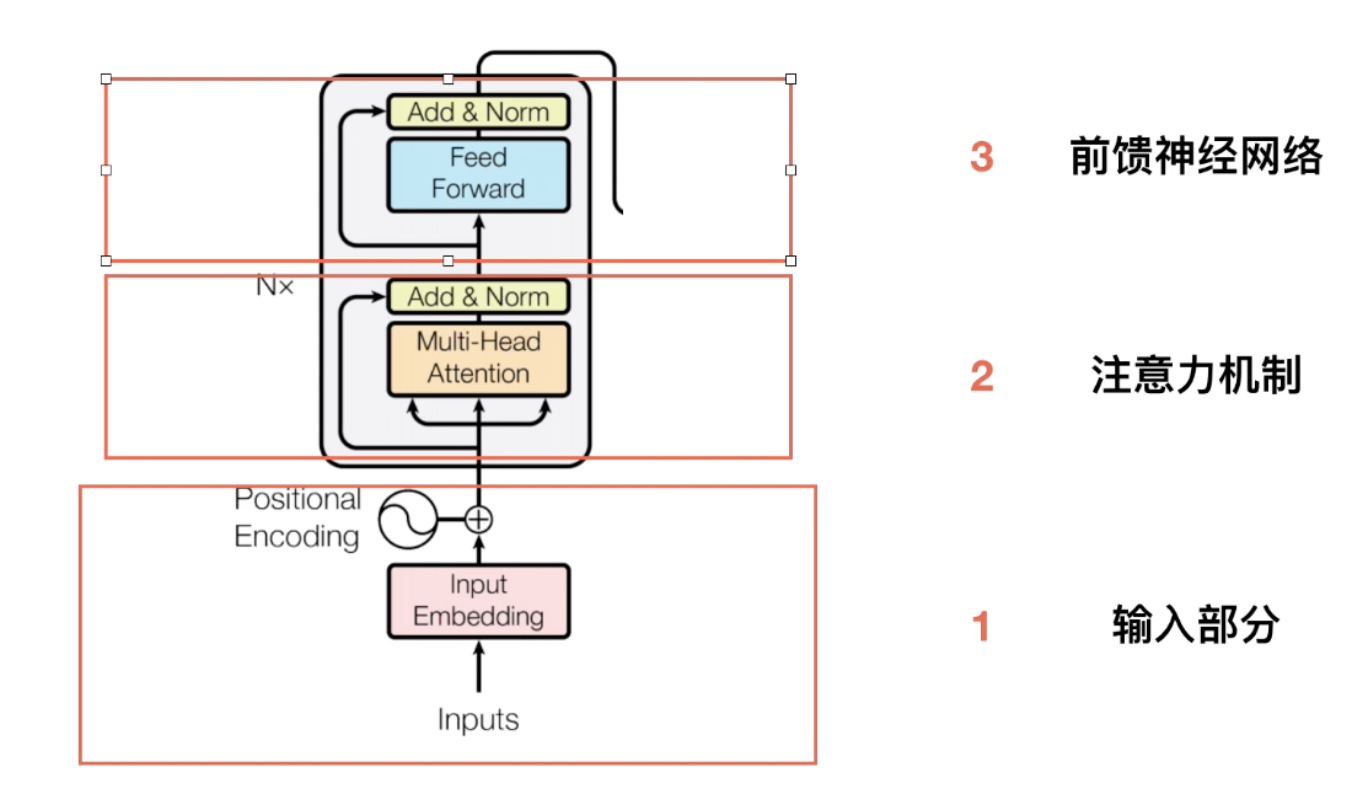
输入部分
Embedding
12 个字对应512 维度的字向量: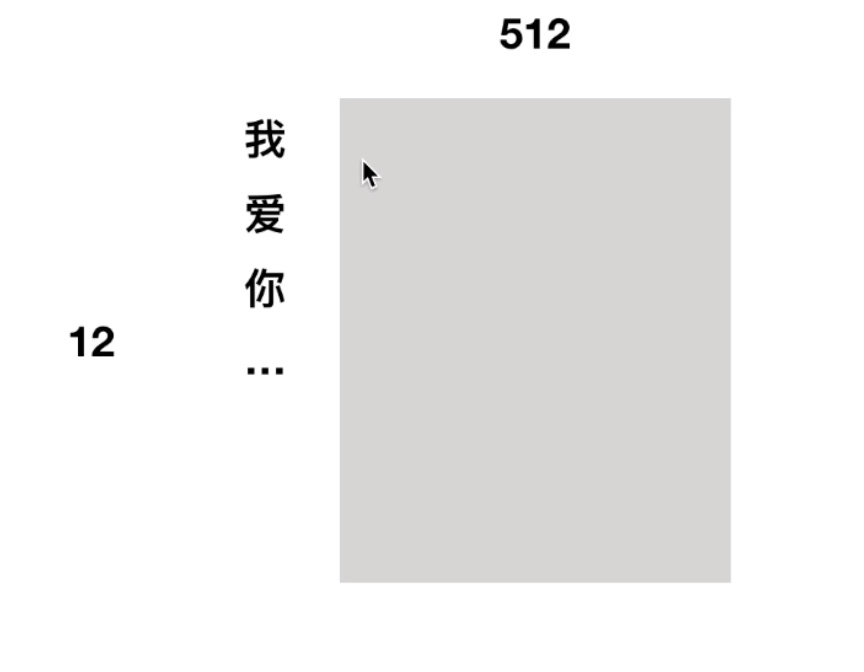
位置嵌入
为什么需要,RNN 中的每个 timestep (箭头左端就是一个 timestep,右端是 3 个 timestep 的集合)共享一套参数 \(u、v、w\),天然的具有持续关系(句子中单词的序列关系),由于后一个 timestep 输入必须得等前一个 timestep 的输出,不具有并行处理的能力,并且由于所有 timestep 共享一套参数,所以会出现梯度消失或梯度爆炸的问题;而对于 attention,具有并行处理的能力,但是并不具有位置信息显示的能力,下面讲到 attention 时会讲到: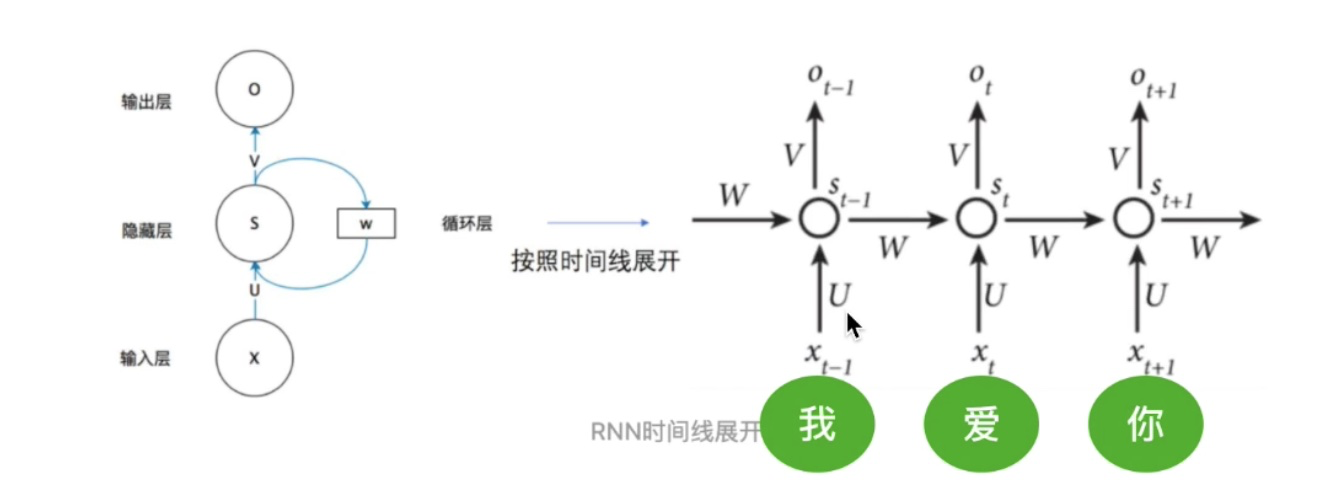
位置编码公式,其中 pos 表示位置、i 表示维度、 \(2i、2i+1\) 表示的是奇偶数(奇偶维度),下图就是偶数位置使用 \(\sin\) 函数,奇数位置使用 \(\cos\) 函数: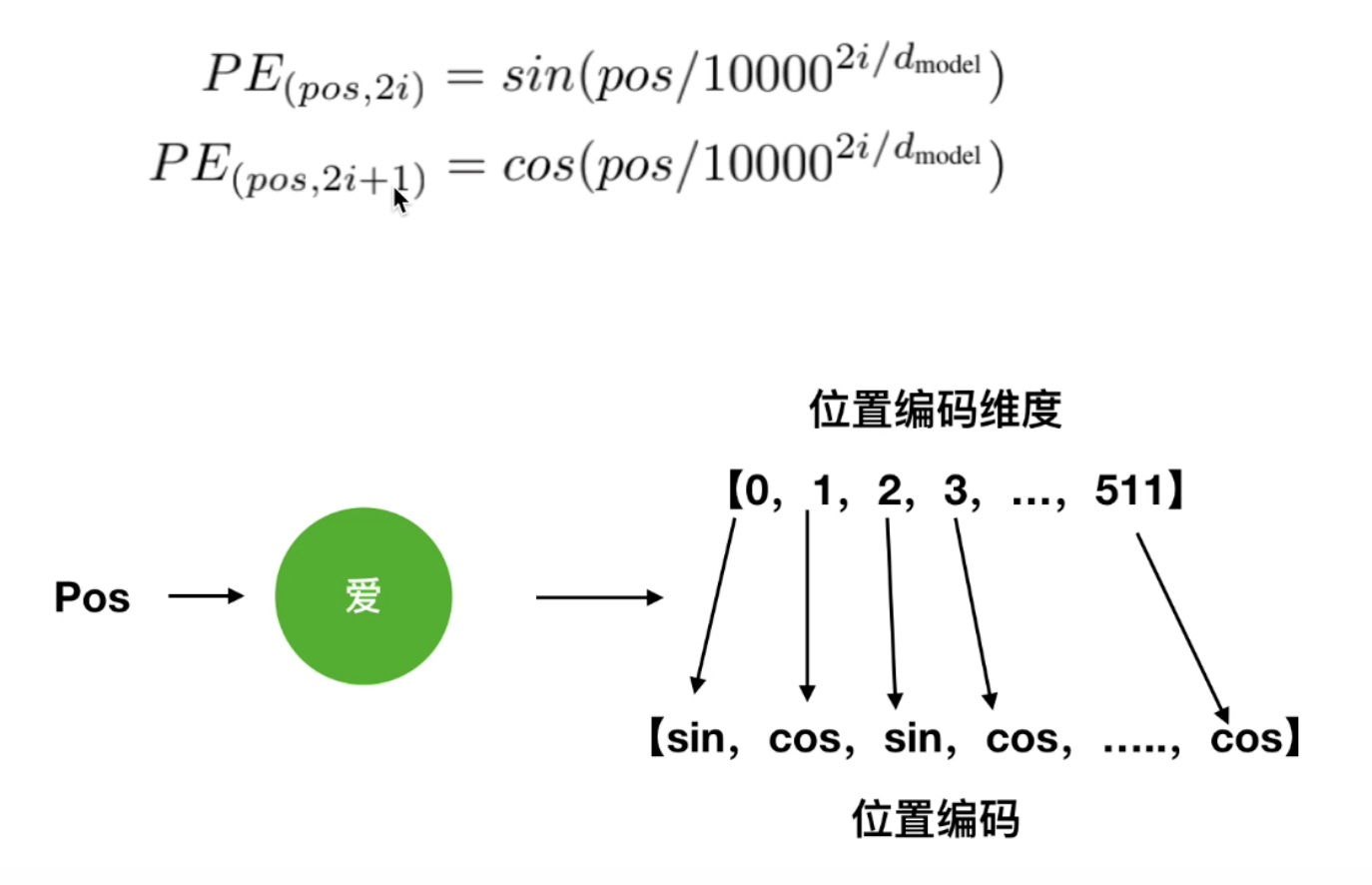
位置编码嵌入单词编码: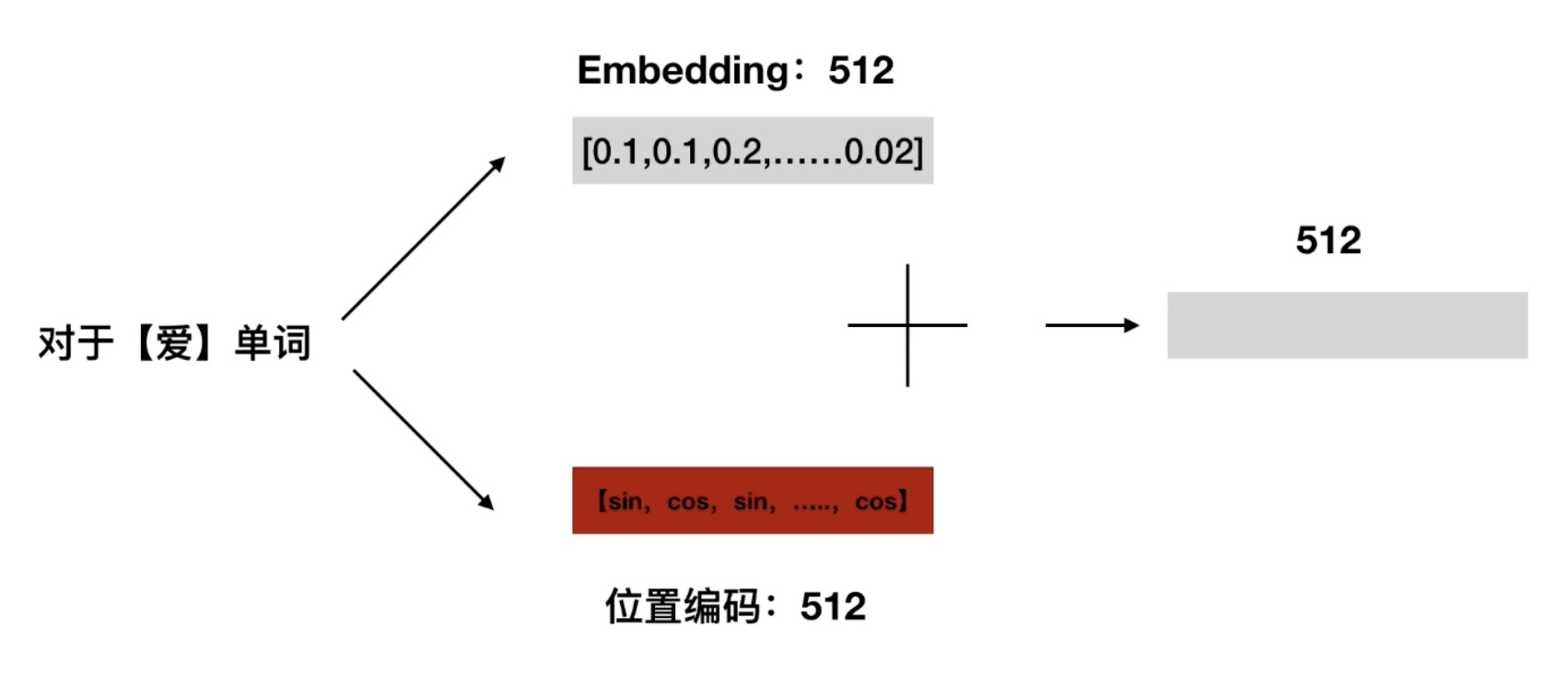
为什么位置嵌入机制有用,我们不要去关心三角函数公式,可以看看 公式(3) 中的第一行,我们做如下的解释,对于 “我爱德” 这一句话,有三个单词,假设序号分别为 1、2、3,假设 \(pos=1=我、k=2=爱、pos+k=3=德\),也就是说 \(pos+k=3\) 位置的位置向量的某一维可以通过 \(pos=1\) 和 \(k=2\) 位置的位置向量的某一维线性组合加以线性表示,通过该线性表示可以得出 “德” 的位置编码信息蕴含了相对于前两个字 “我” 和 “爱” 的位置编码信息:
注意力机制
人类的注意力机制
第一眼会注意什么?红色的地方首先会映入眼帘;其次,我们如果问一句:婴儿在干什么?会怎么观察这幅图:
Attention 计算
Q、K、V 三个矩阵: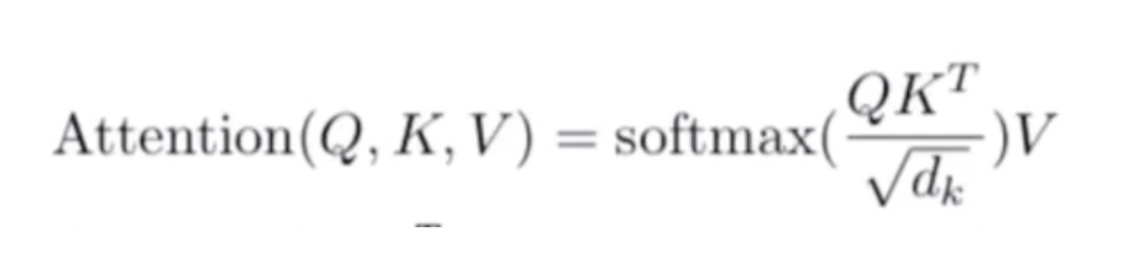
理解上述公式,婴儿和左上、左下…做点乘,点乘的结果是一个向量在另外一个向量上投影的长度,是一个标量,可以获取二者的相似度,相似度越大,则表示二者越靠近,此处就是观察婴儿更关注左上、左下…哪个部分: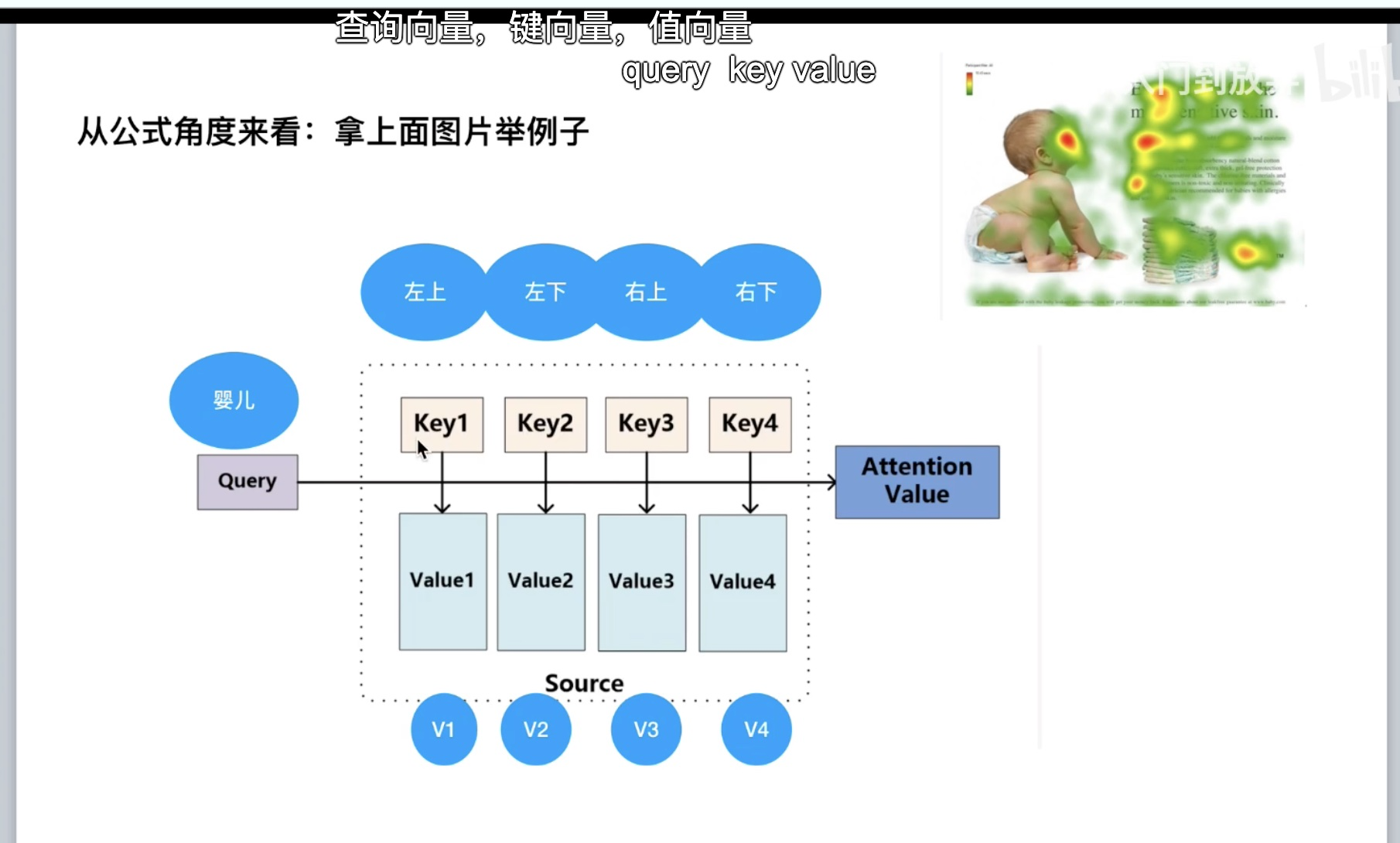
上述公式的更详细解释: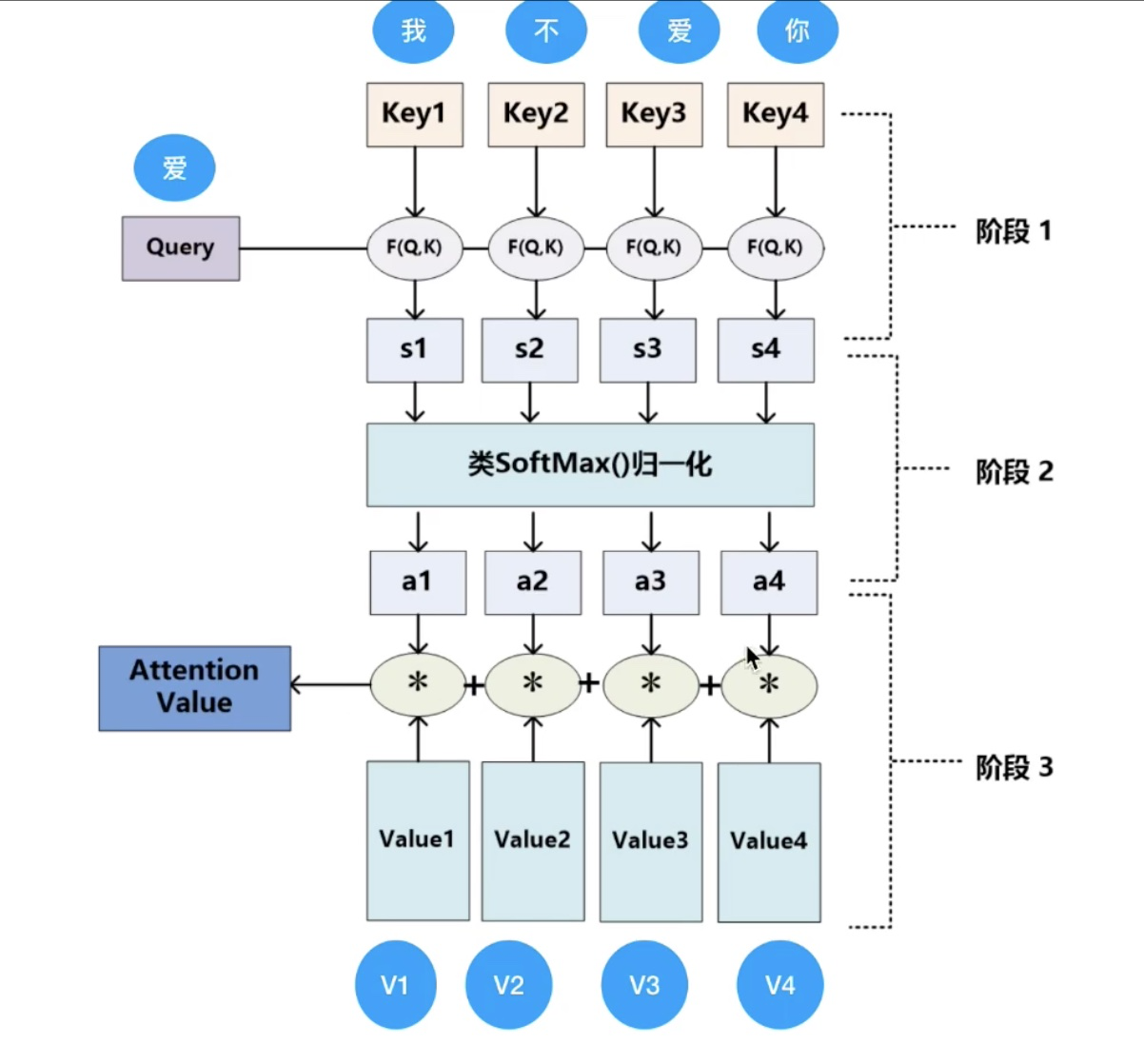
Transformer 中 Q、K、V 的获取,其中 W 是一个随机初始化的参数,在训练过程中会被更新: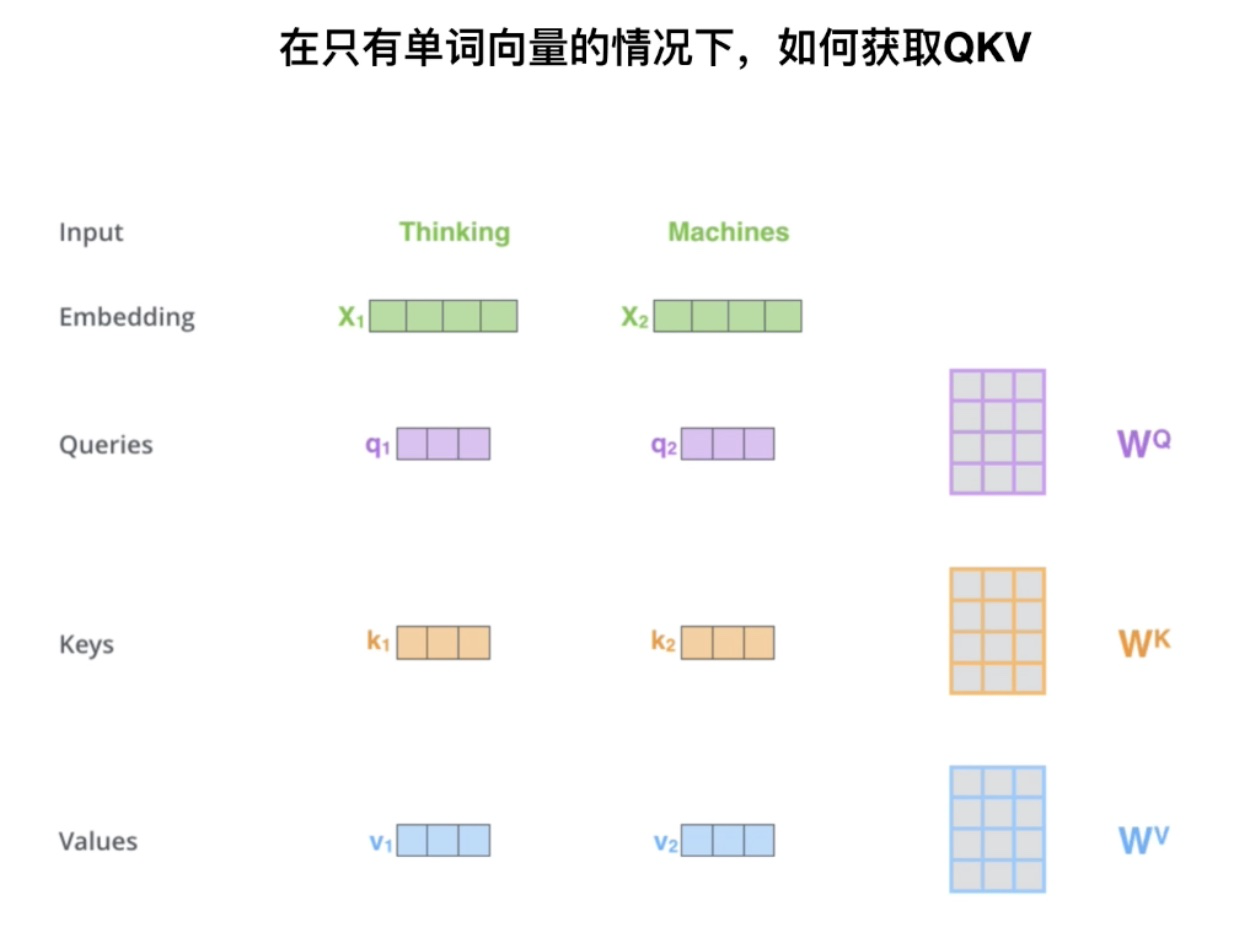
计算 attention 值,其中由于 \(QK^T\) 的值很大时,通过 softmax 的公式可以得知,softmax 的梯度会很小,则会造成梯度消失,有兴趣想具体了解的可以看这个链接:transformer中的attention为什么scaled?。因此有了 \(\frac{QK^T}{\sqrt{d_k}}\),分母为 \(\sqrt{d_k}\) 的原因是为了控制 \(QK^T\) 的方差为 1: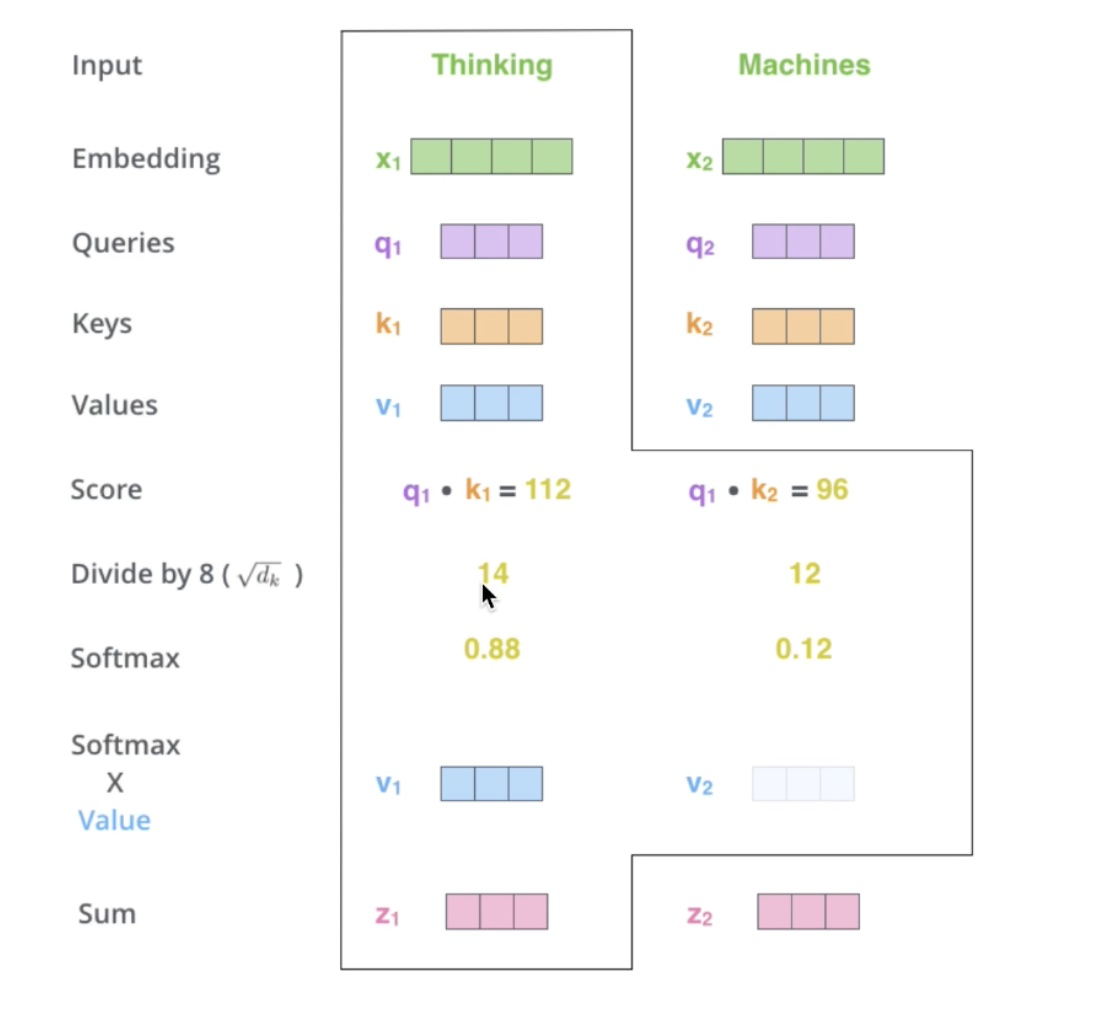
实际代码会使用矩阵的形式,方便并行计算:
多头 Attention 计算
多头 attention,使用多套参数,多套参数相当于把原始信息放到了多个空间中,也就是捕捉了多个信息,对于使用多头 attention 的简单回答就是,多头保证了transformer可以注意到不同子空间的信息,捕捉到更加丰富的特征信息。其实本质上是论文原作者发现这样效果确实好: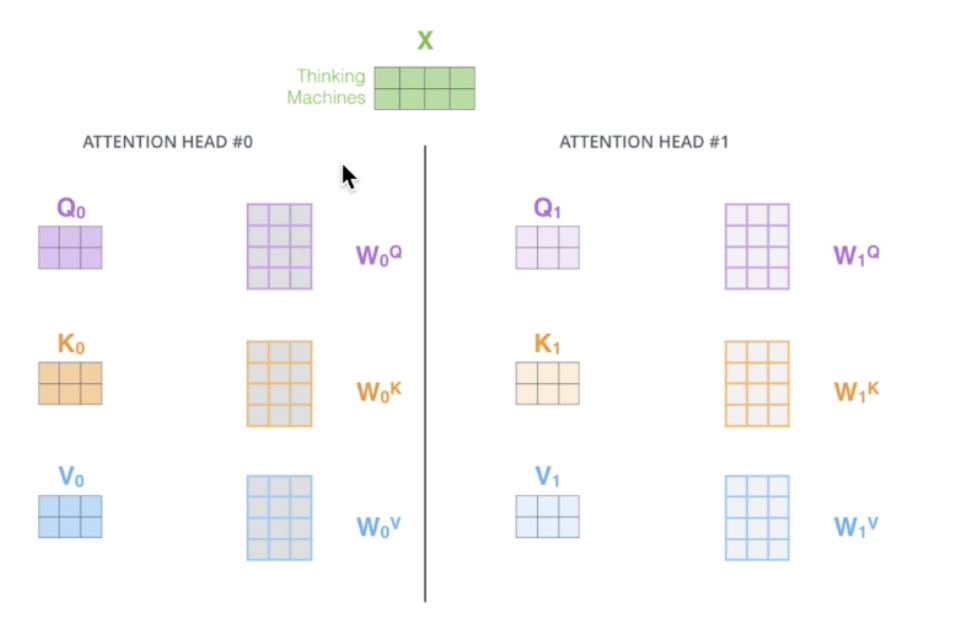
多头信息输出,由于多套参数得到了多个信息,然而我们还是只需要一个信息,因此可以通过某种方法(例如矩阵相乘)把多个信息汇总为一个信息: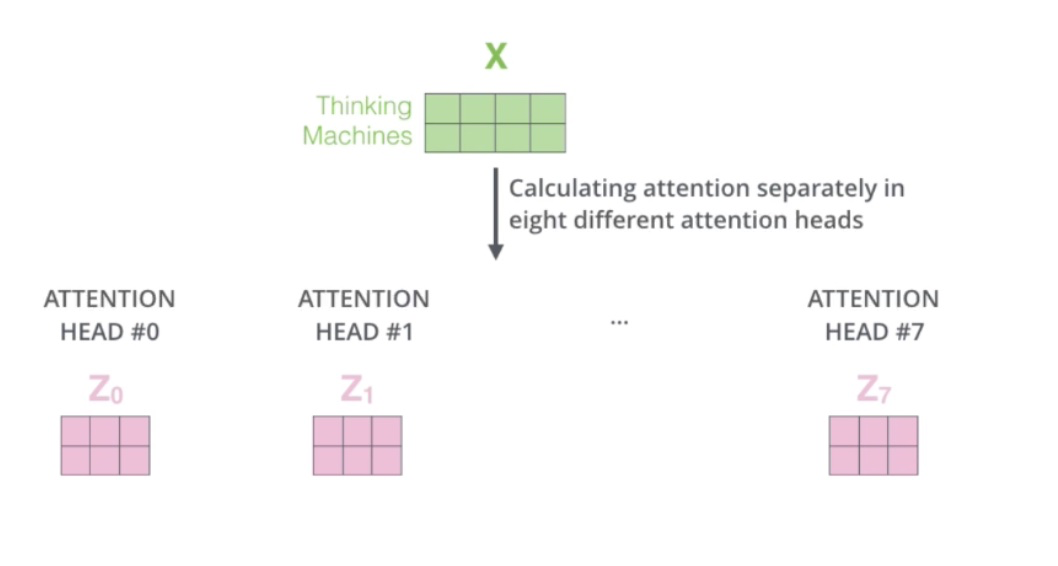
多套信息合并为一个信息: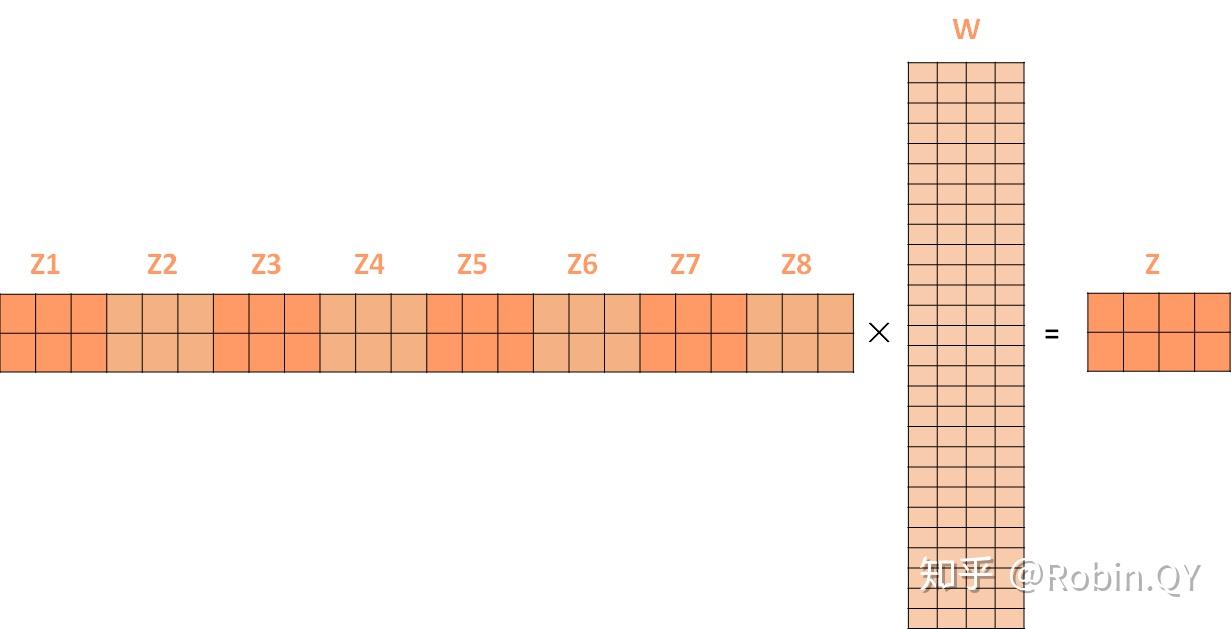
残差及其作用
encoder 详解,其中 \(X+Z\) 为残差的结果: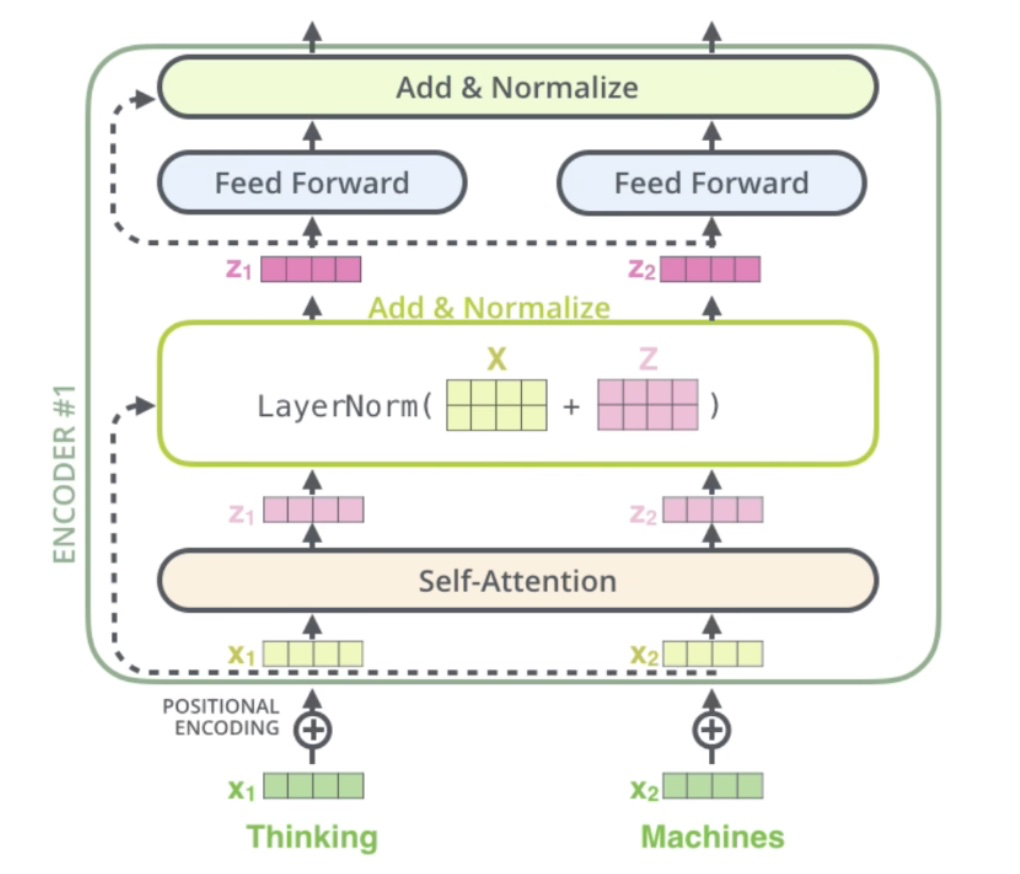
残差网络,把输入原封不动的和元网络处理的结果相加:![]()
残差的作用,没有残差,最后一行公式中括号内没有 1,只有三个连乘项,而这三个连乘项如果很小的话,则可能结果会为 0,而有了残差之后,即括号内有了 1,由此确保了梯度永远不会为 0,则不会出现梯度消失的情况,进而网络深度可以增加: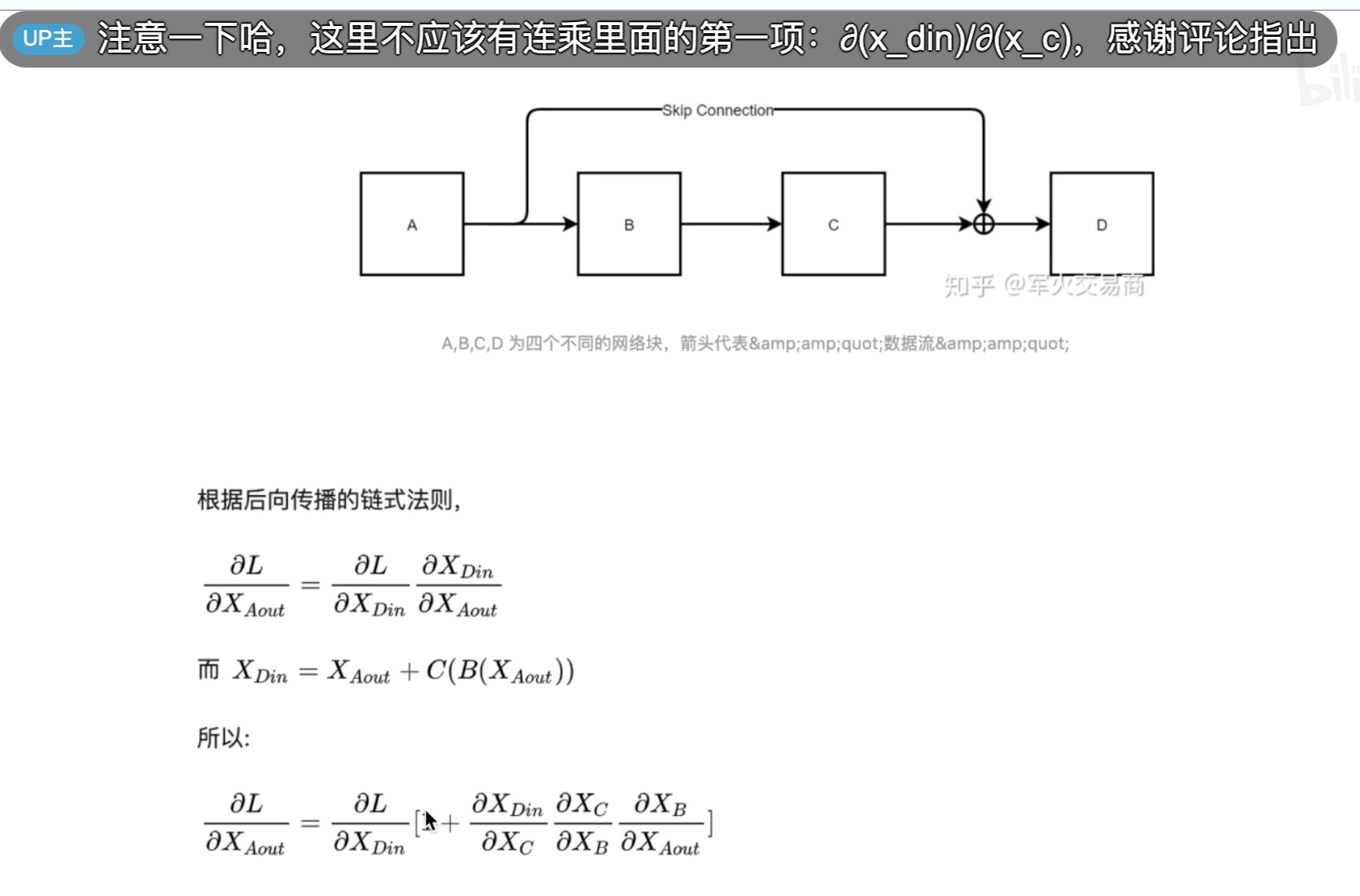
BatchNorm 和 LayerNorm
为什么 LayerNorm 单独对一个样本的所有单词做缩放可以起到效果,9 个句子各 5 个单词、1 个句子 20 个单词,很明显,由于样本长度不一,使用 BN 的效果一定是大打折扣的,而 LN 可以针对每一句话做一个归一化:
对于齐平的句子,BN 和 LN 的区别,BN由于是针对 batch 维度的归一化,是对“我今”、“爱天”……做归一化;LN 是对某一层神经元的输入进行归一化,“我爱中国…”和“今天天气真不错”做归一化:
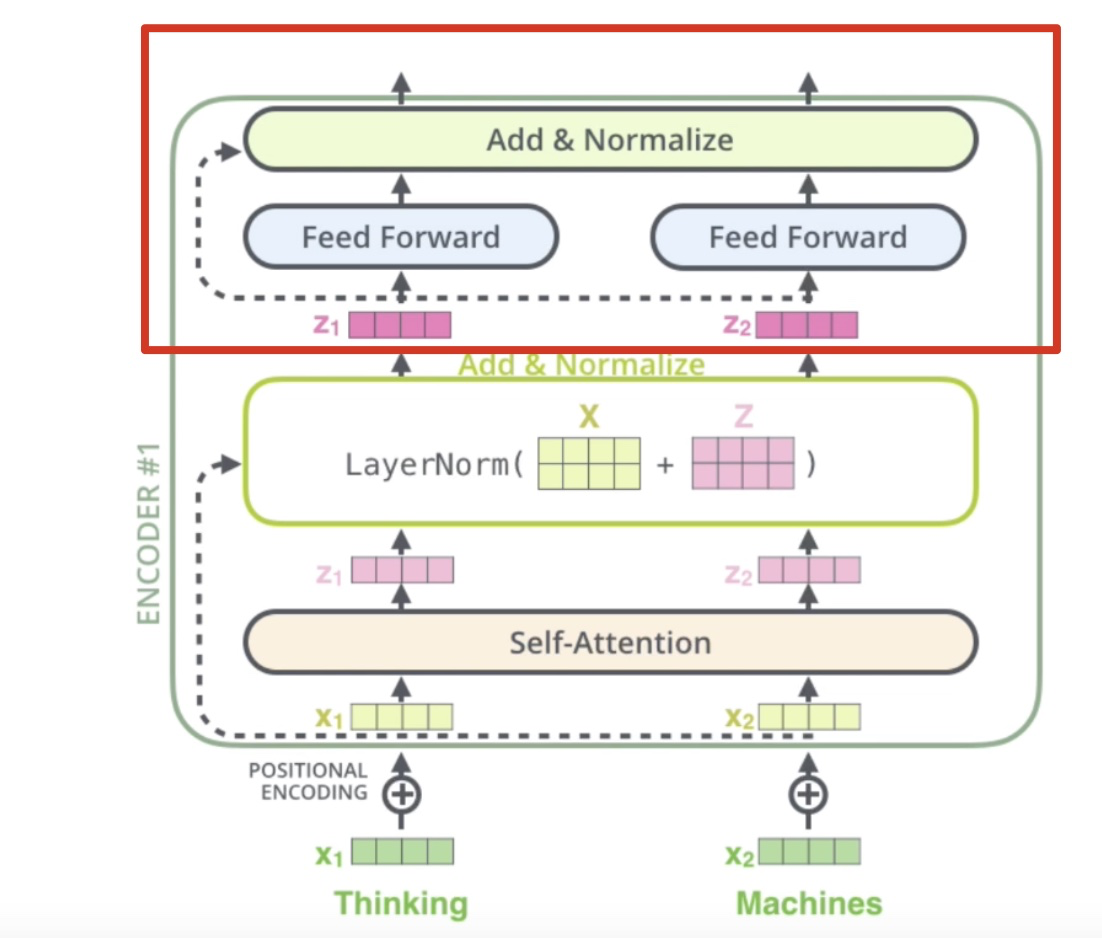
前馈神经网络
每一层经过attention之后,还会有一个FFN,这个FFN的作用就是空间变换。FFN包含了2层linear transformation层,中间的激活函数是ReLu。
其实,FFN的加入引入了非线性(ReLu激活函数),变换了attention output的空间, 从而增加了模型的表现能力。把FFN去掉模型也是可以用的,但是效果差了很多。
Decoder 详解
decoder 模型架构: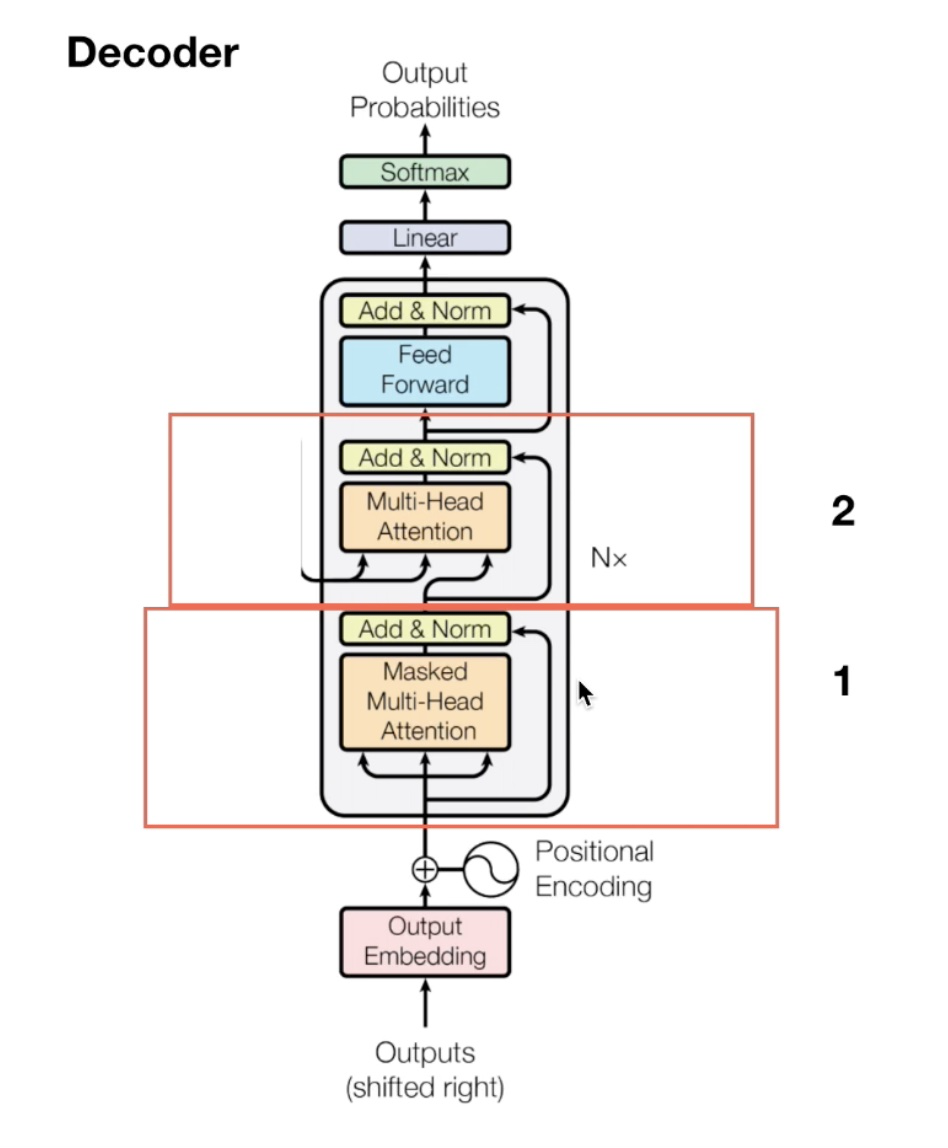
mask 的作用,当预测 you 的时候,我们是看不到 you 后面单词的信息的,也就是 mask 掉 you 和 now: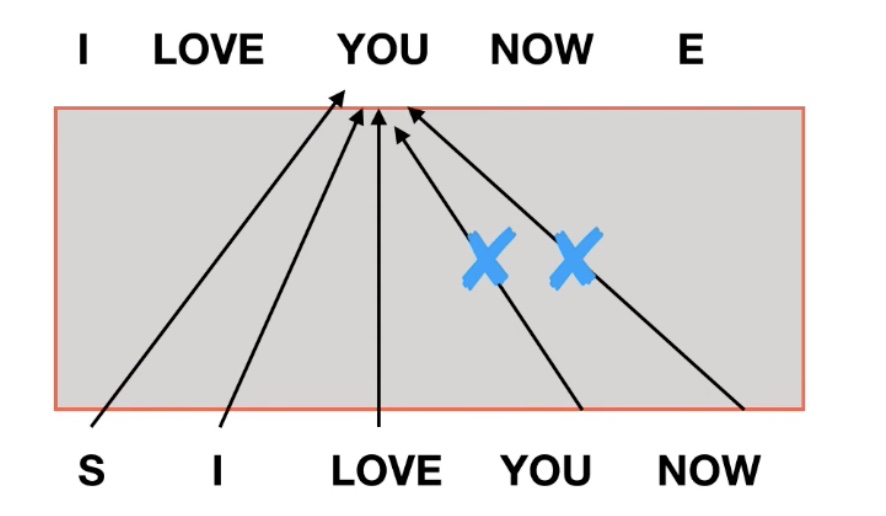
encoder 和 decoder 交互方法: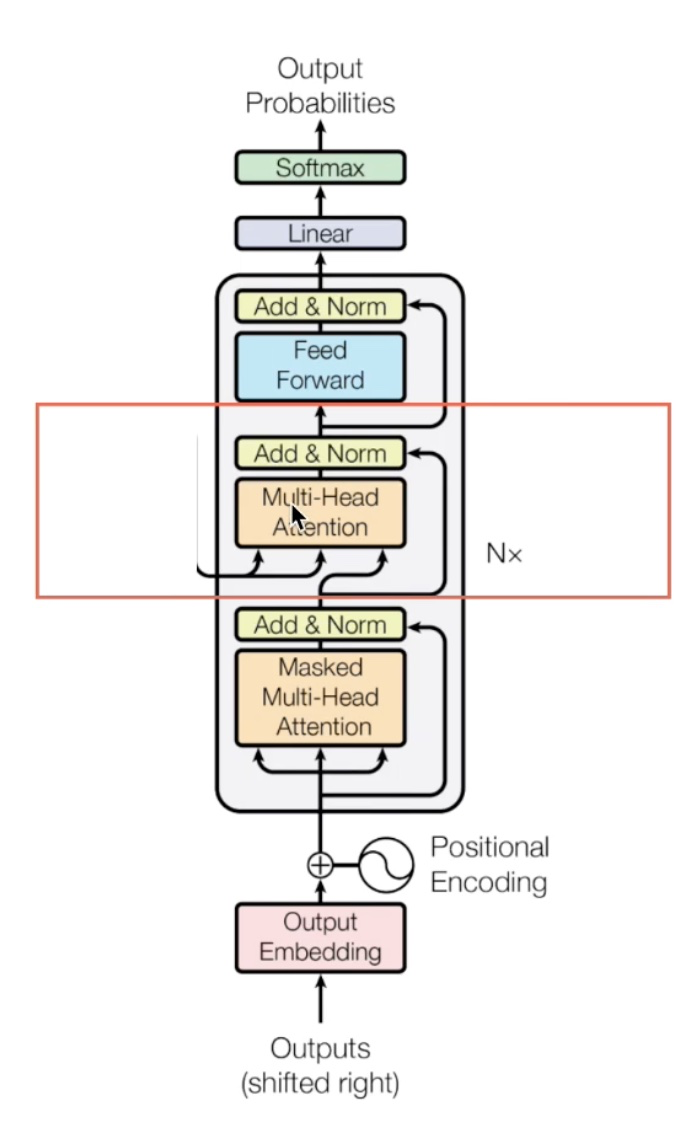
encoder 的输出会给所有的 decoder 提供一定的信息: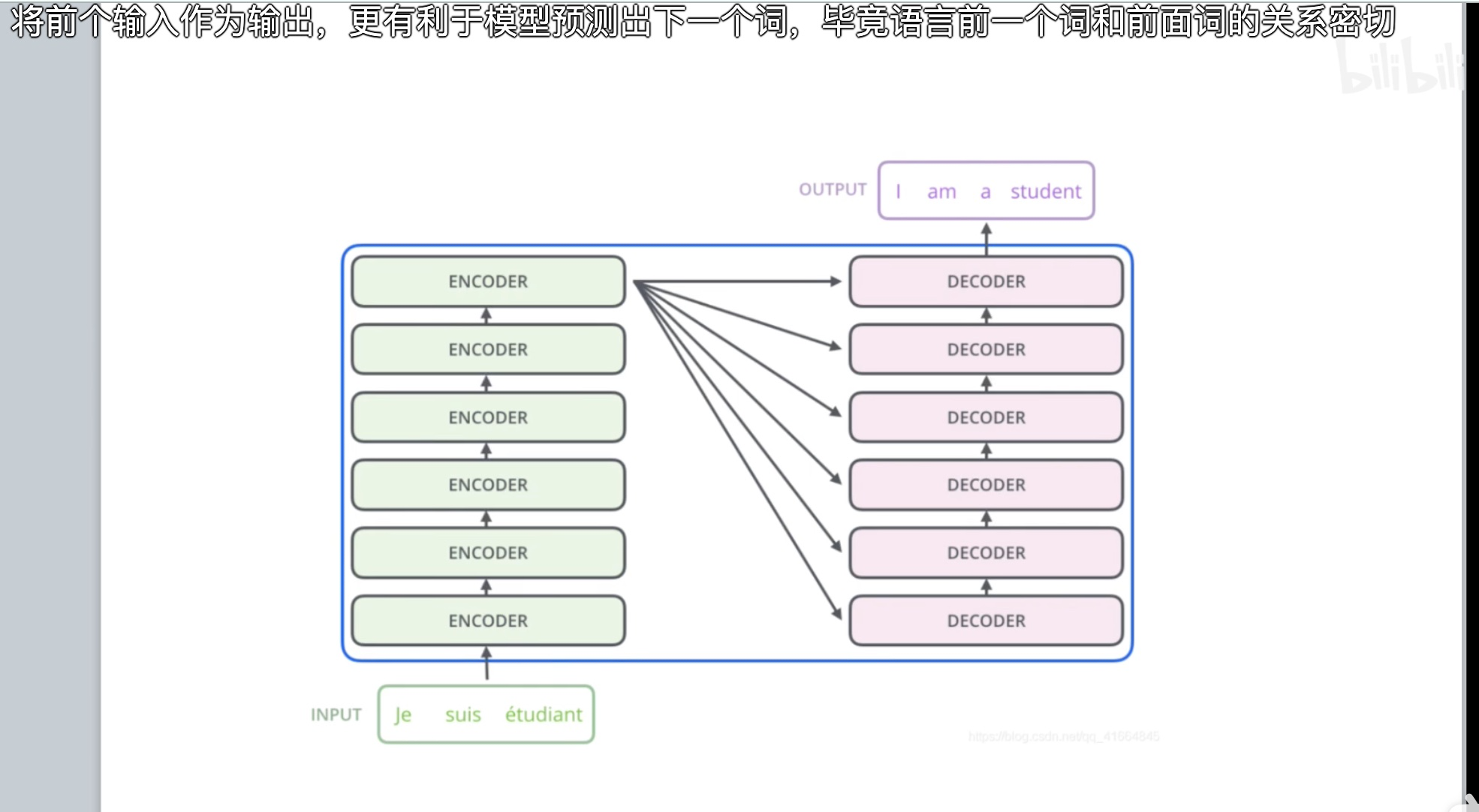
encoder 和 decoder 交互时提供的信息,encoder 生成的 K、V 矩阵,decoder 生成的是 Q 矩阵: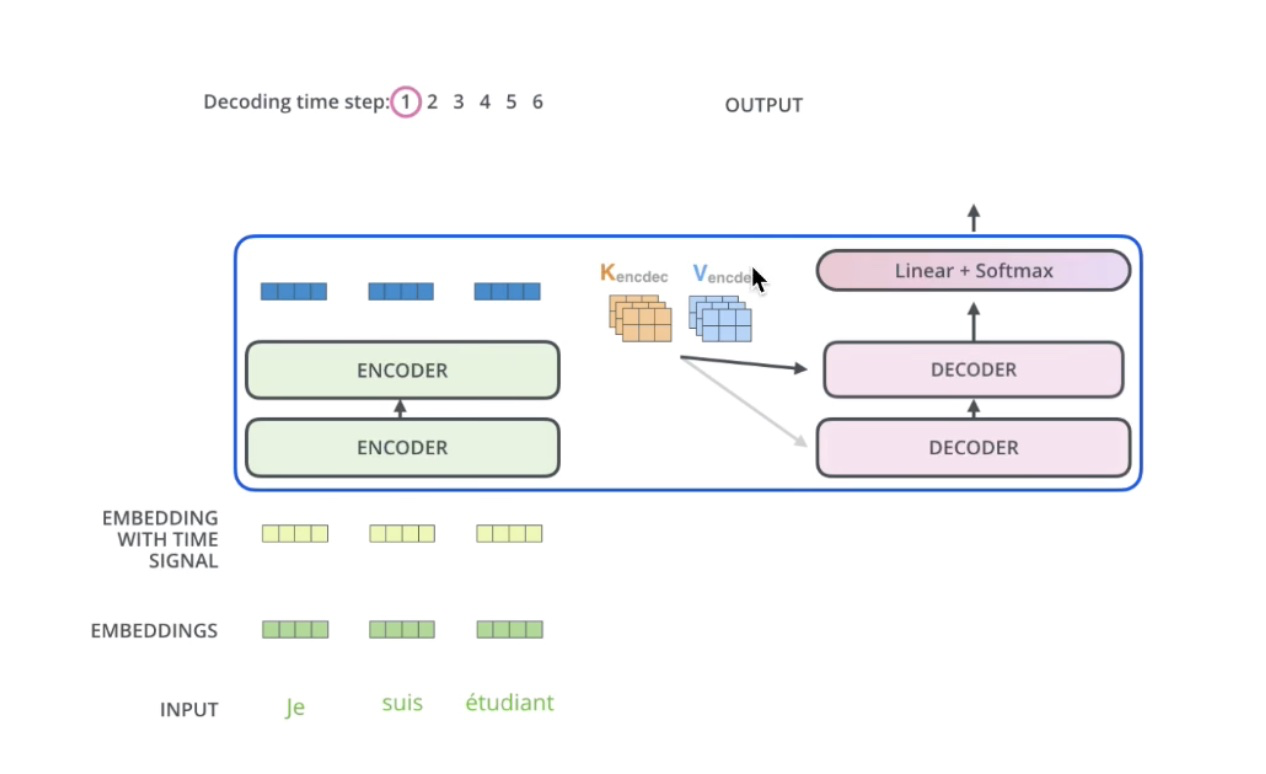
encoder 和 decoder 交互的整个过程: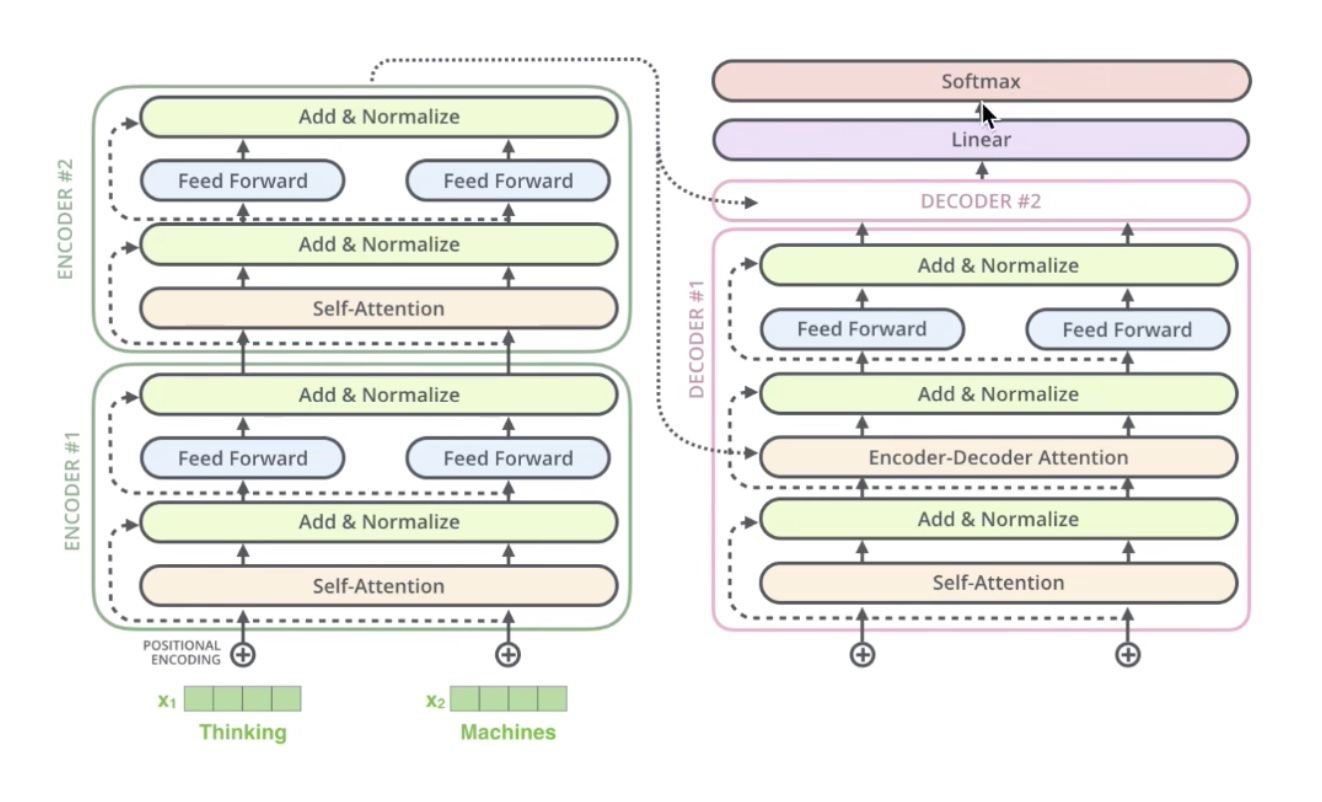
Transformer 最终输出
以上,就讲完了Transformer编码和解码两大模块,那么我们回归最初的问题,将“机器学习”翻译成“machine learing”,解码器输出本来是一个浮点型的向量,怎么转化成“machine learing”这两个词呢?
是个工作是最后的线性层接上一个softmax,其中线性层是一个简单的全连接神经网络,它将解码器产生的向量投影到一个更高维度的向量(logits)上,假设我们模型的词汇表是10000个词,那么logits就有10000个维度,每个维度对应一个惟一的词的得分。之后的softmax层将这些分数转换为概率。选择概率最大的维度,并对应地生成与之关联的单词作为此时间步的输出就是最终的输出啦!!
假设词汇表维度是6,那么输出最大概率词汇的过程如下:
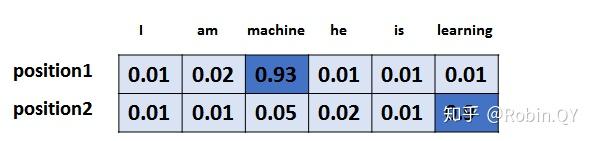
TRM 面试题讲解
RNN、LSTM、Transformer 三者的区别?
- RNN系列的模型时刻隐层状态的计算,依赖两个输入,一个是
时刻的句子输入单词
,另一个是
时刻的隐层状态
的输出,这是最能体现RNN本质特征的一点,RNN的历史信息是通过这个信息传输渠道往后传输的。而RNN并行计算的问题就出在这里,因为
时刻的隐层计算结果,如此下去就形成了所谓的序列依赖关系。
- 很明显,Transformer 中引入 Self Attention 后会更容易捕获句子中长距离的相互依赖的特征,因为如果是 RNN 或者 LSTM,需要依次序序列计算,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来,而距离越远,有效捕获的可能性越小。
- 但是Self Attention在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征。除此外,Self Attention对于增加计算的并行性也有直接帮助作用。这是为何Self Attention逐渐被广泛使用的主要原因。
为什么有缩放因子  ?attention为什么scaled?
?attention为什么scaled?
- 先一句话回答这个问题: 缩放因子的作用是归一化。
- 假设
,
里的元素的均值为0,方差为1,那么
中元素的均值为0,方差为d. 当d变得很大时,
中的元素的方差也会变得很大,如果
的分布会趋于陡峭(分布的方差大,分布集中在绝对值大的区域)。总结一下就是
- 可以看到,数量级对softmax得到的分布影响非常大。在数量级较大时,softmax将几乎全部的概率分布都分配给了最大值对应的标签。如果某一维度的数量级较大,进而会导致 softmax 未来求梯度时会消失。
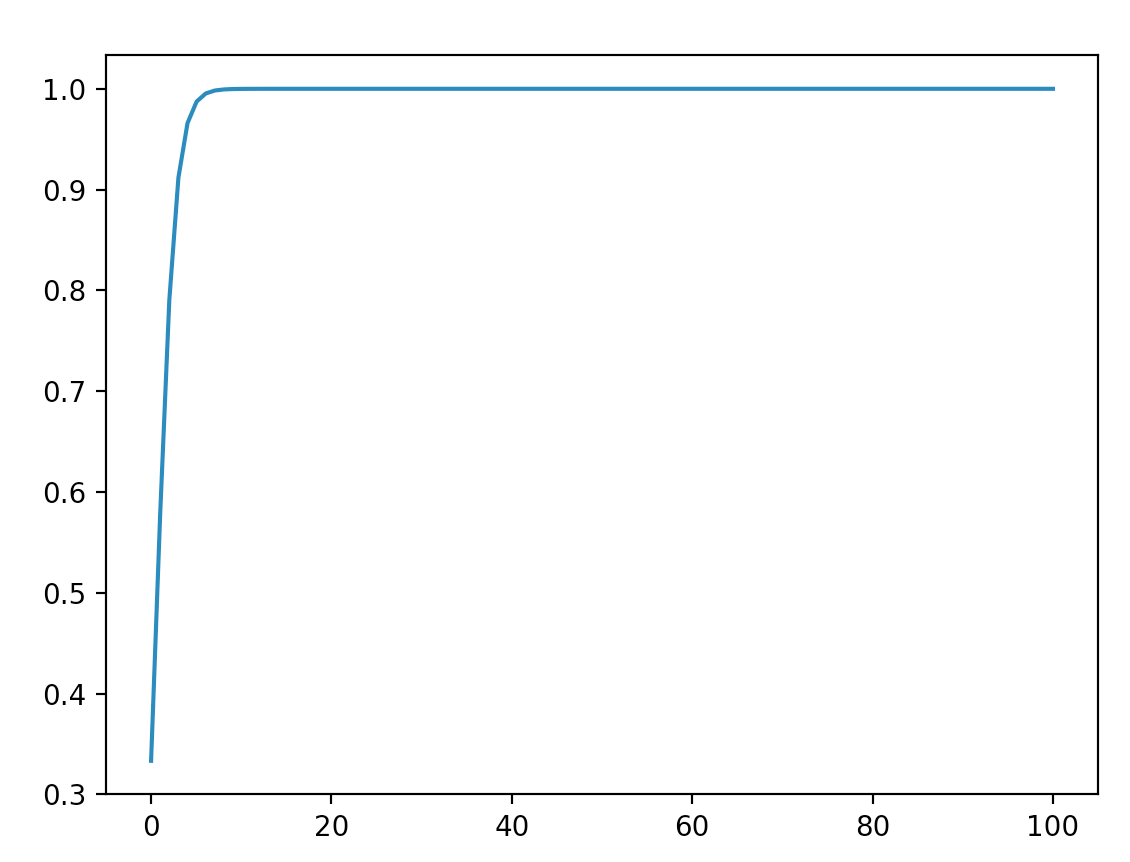
- 可以看到,数量级对softmax得到的分布影响非常大。在数量级较大时,softmax将几乎全部的概率分布都分配给了最大值对应的标签。如果某一维度的数量级较大,进而会导致 softmax 未来求梯度时会消失。
- Transformer 的并行化
- decoders 没有并行化,6 个encoder 之间也没有并行化,encoder 内部的两个子模块也没有并行化,但是 encoder 内部的两个子模块自身是可以并行化的
Decoder端的Mask
Transformer模型属于自回归模型(p.s. 非自回归的翻译模型我会专门写一篇文章来介绍),也就是说后面的token的推断是基于前面的token的。Decoder端的Mask的功能是为了保证训练阶段和推理阶段的一致性。
论文原文中关于这一点的段落如下:
We also modify the self-attention sub-layer in the decoder stack to prevent from attending to subsequent positions. This masking, combined with the fact that the output embeddings are offset by one position, ensures that the predictions for position i can depend only on the known outputs at positions less than i.
在推理阶段,token是按照从左往右的顺序推理的。也就是说,在推理timestep=T的token时,decoder只能“看到”timestep < T的 T-1 个Token, 不能和timestep大于它自身的token做attention(因为根本还不知道后面的token是什么)。为了保证训练时和推理时的一致性,所以,训练时要同样防止token与它之后的token去做attention。
比如我要翻译出来的一句话为“我爱陈有德”的时候,如果没有 mask,当我们在训练阶段,翻译到“爱”的时候,由于没有 mask,“陈有德”三个字对翻译“爱”是有输出贡献的,也就是说训练阶段,模型是基于知道这个时刻后面的单词进行的训练,然而当我们在测试阶段的时候,我们并不知道“爱”后面是什么,也就是说训练阶段不 mask,那么测试阶段会受到一定的影响。(这里要说明,训练阶段我们是知道 ground truth “我爱陈有德” 的,而 decoders 的第一个 output Embedding 就是真实的那个 ground truth “我爱陈有德”,也就是说训练阶段不 mask,那么预测 “爱” 时,“陈有德” 就会有贡献,而在测试阶段,没有 ground truth,decoders 的第一个 output Embedding 是随机的,此时训练阶段和测试阶段就会出现差别)
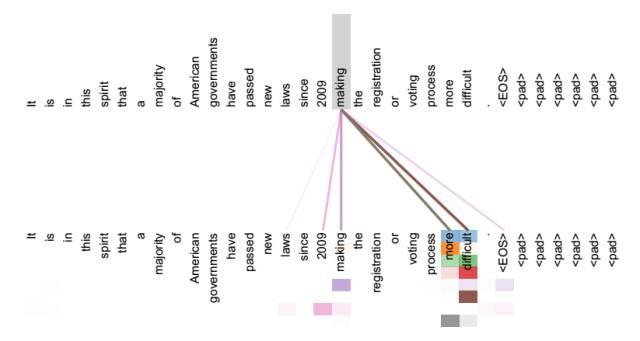
从下图可以看出,预测是一步接着一步的,由于是序列生成过程,所以在时刻 i 的时候,大于 i 的时刻都没有结果,只有小于 i 的时刻有结果,因此需要做Mask
如何 mask
其实就会组成一个word2word的attention map!(加了softmax之后就是一个合为1的权重了)。比如说你的输入是一句话 "i have a dream" 总共4个单词,这里就会形成一张4x4的注意力机制的图:
这样一来,每一个单词就对应每一个单词有一个权重
注意encoder里面是叫self-attention,decoder里面是叫masked self-attention。
这里的masked就是要在做language modelling(或者像翻译)的时候,不给模型看到未来的信息。
mask就是沿着对角线把灰色的区域用0覆盖掉,不给模型看到未来的信息。
详细来说,i作为第一个单词,只能有和i自己的attention。have作为第二个单词,有和i, have 两个attention。 a 作为第三个单词,有和i,have,a 前面三个单词的attention。到了最后一个单词dream的时候,才有对整个句子4个单词的attention。
做完softmax后就像这样,横轴合为1
Layer Normalization (归一化)的作用
Layer Normalization是一个通用的技术,其本质是规范优化空间,加速收敛。当我们使用梯度下降法做优化时,随着网络深度的增加,数据的分布会不断发生变化,假设feature只有二维,那么用示意图来表示一下就是:
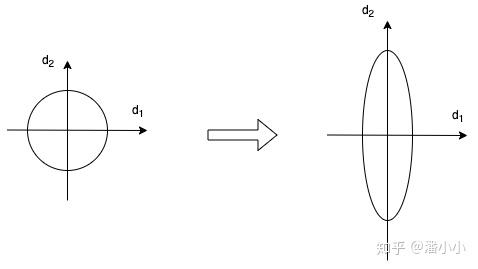
为了保证数据特征分布的稳定性(如左图),我们加入Layer Normalization,这样可以加速模型的优化速度。
Attention和Transformer详解的更多相关文章
- Transformer详解:各个特征维度分析推导
谷歌在文章<Attention is all you need>中提出的transformer模型.如图主要架构:同样为encoder-decoder模式,左边部分是encoder,右边部 ...
- Transformer详解
0 简述 Transformer改进了RNN最被人诟病的训练慢的缺点,利用self-attention机制实现快速并行. 并且Transformer可以增加到非常深的深度,充分发掘DNN模型的特性,提 ...
- Transformer 详解
感谢:https://www.jianshu.com/p/04b6dd396d62 Transformer模型由<Attention is all your need>论文中提出,在seq ...
- Residual Attention Network for Image Classification(CVPR 2017)详解
一.Residual Attention Network 简介 这是CVPR2017的一篇paper,是商汤.清华.香港中文和北邮合作的文章.它在图像分类问题上,首次成功将极深卷积神经网络与人类视觉注 ...
- Attention is all you need 论文详解(转)
一.背景 自从Attention机制在提出之后,加入Attention的Seq2Seq模型在各个任务上都有了提升,所以现在的seq2seq模型指的都是结合rnn和attention的模型.传统的基于R ...
- Transformer各层网络结构详解!面试必备!(附代码实现)
1. 什么是Transformer <Attention Is All You Need>是一篇Google提出的将Attention思想发挥到极致的论文.这篇论文中提出一个全新的模型,叫 ...
- seq2seq模型详解及对比(CNN,RNN,Transformer)
一,概述 在自然语言生成的任务中,大部分是基于seq2seq模型实现的(除此之外,还有语言模型,GAN等也能做文本生成),例如生成式对话,机器翻译,文本摘要等等,seq2seq模型是由encoder, ...
- Transform详解(超详细) Attention is all you need论文
一.背景 自从Attention机制在提出 之后,加入Attention的Seq2 Seq模型在各个任务上都有了提升,所以现在的seq2seq模型指的都是结合rnn和attention的模型.传统的基 ...
- 无所不能的Embedding6 - 跨入Transformer时代~模型详解&代码实现
上一章我们聊了聊quick-thought通过干掉decoder加快训练, CNN-LSTM用CNN作为Encoder并行计算来提速等方法,这一章看看抛开CNN和RNN,transformer是如何只 ...
随机推荐
- springboot——重定向解决刷新浏览器造成表单重复提交的问题(超详细)
原因:造成表单重复提交的原因是当我们刷新浏览器的时候,浏览器会发送上一次提交的请求.由于上一次提交的请求方式为post,刷新浏览器就会重新发送这个post请求,造成表单重复提交. 解决办法: 将请求当 ...
- 五、部署LNMP环境(linux + nginx + mysql + php)
装包(nginx.数据库.php.php调用)---------起服务-----权限 装包: yum -y install gcc openssl-devel pcre-devel zlib-de ...
- 三、DNS子域授权
前提:准备两台虚拟机:父域: www.tedu.cn(虚拟机A)子域:www.bj.tedu.cn(虚拟机B) 一.在两台虚拟机上安装域名解析软件 root@pc207 ~]# yum -y inst ...
- JAVA并行程序基础一
JAVA并行程序基础一 线程的状态 初始线程:线程的基本操作 1. 新建线程 新建线程只需要使用new关键字创建一个线程对象,并且用start() ,线程start()之后会执行run()方法 不要直 ...
- char与varchar2字符类型的区别
1.实验: 1)创建一个表test,包含三个字段,数据类型分别是varchar2,number,char create table test(name varchar2(10),id number(1 ...
- Processing中PImage类和loadImage()、createImage()函数的相关解析
聊一聊Processing中PImage类和loadImage().createImage()函数.因为要借P5做多媒体创意展示,图片是一个很重要的媒体.有必要就图片的获取和展放作总结. 首先 有一点 ...
- C#调用JAVA(二)调用方法
上期我们创建了jar包并放到了unity中,那么我们继续 如果您还没有看上一期请先看上一期,这是链接 C#调用JAVA(一)制作jar包 - 执著GodShadow - 博客园 (cnblogs.co ...
- 15、修改sqldeveloper的JDK路径
15.1.说明: 1.第一次使用Oracle SQL Developer时会提示选择JDK路径(只会在第一次使用时提示), 如果选择了高版本的JDK(1.8)路径,可能会出现了如下两种情况: (1)s ...
- 【转载】CentOS-Docker安装MongoDB(单点)
下载镜像 $ docker pull mongo 创建相关目录 $ mkdir -p /usr/mongo/data /usr/mongo/dump 运行镜像 $ docker run --resta ...
- Springboot整合shardingsphere和druid进行读写分离
最近在使用springboot整合shardingsphere和druid实现mysql数据库读写分离时遇到了一些问题,特此记录一下. 依赖版本 Springboot 2.1.6.RElEASE sh ...