JAVA-JDK1.8-ConCurrentHashMap-源码并且debug说明
概述
在上述的随笔中已经介绍了JDK1.7版本的ConCurrentHashMap源码和测试了,现在这篇随笔主要介绍JDK1.8版本的ConCurrentHashMap,这个版本抛弃了分段锁的实现,直接采用CAS+synchronized保证并发更新的安全性,底层采用数组+链表+红黑树的存储结构。其包含核心静态内部类Node<K,V>[],数组来保存添加到map中的键值对,而在同一个数组位置是通过链表和红黑树的形式来保存的。但是这个数组只有在第一次添加元素的时候才会初始化,否则只初始化一个ConCurrentHashMap对象,还设定了一个sizeCtl变量,这个变量是用来判断对象的一些状态和是否需要扩容。
第一次添加元素的时候,默认初期长度为16,当往map中继续添加元素的时候,通过 hash值跟数组长度取与来决定放在数组的哪个位置,如果出现放在同一个位置的时候,优先以链表的形式存放,在同一个位置的个数又达到了8个以上,如果数 组的长度还小于64的时候,则会扩容数组。如果数组的长度大于等于64了的话,在会将该节点的链表转换成树。
通过扩容数组的方式来把这些节点给分散开。然后将这些元素复制到扩容后的新的数组中,同 一个链表中的元素通过hash值的数组长度位来区分,是还是放在原来的位置还是放到扩容的长度的相同位置去 。在扩容完成之后,如果某个节点的是树,同时现在该节点的个数又小于等于6个了,则会将该树转为链表,取元素的时候,相对来说比较简单,通过计算hash来确定该元素在数组的哪个位置,然后在通过遍历链表或树来判断key和key的hash,取出value值。
首先看一下数据结构的截图:
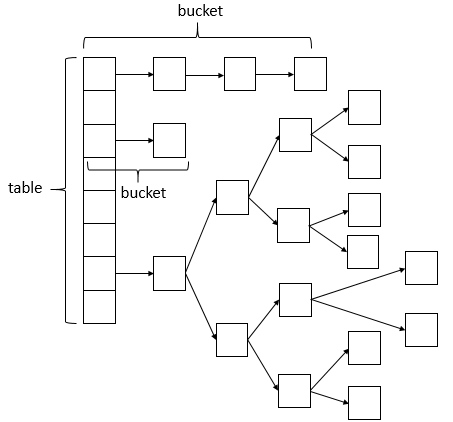
从上图所示:数据结构采用数组+链表+红黑树的方式实现,当链表中的bucket的节点个数超过8个时,会转换为红黑树的数据结构存储,这样设计也相应提高了读取效率。
java8主要做了如下优化:
1,将Segment抛弃掉了,直接采用Node作为table元素。
2,修改时,不再采用ReentrantLock加锁,直接使用内置synchronized加锁,java8内置锁,比之前版本优化好多,相比ReentrantLock,性能并不差。
3,size方法优化,增加了CounterCell内部类,用于并行计算每个bucket的元素数量。
ConCurrentHashMap的几个重要类
Java8中ConCurrentHashMap增加了很多内部类来支持一些操作和优化性能,先介绍几个比较重要的属性。
1 public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>
2 implements ConcurrentMap<K,V>, Serializable {
3 // table最大容量,为2的幂次方
4 private static final int MAXIMUM_CAPACITY = 1 << 30;
5 // 默认table初始容量大小
6 private static final int DEFAULT_CAPACITY = 16;
7 // 默认支持并发更新的线程数量
8 private static final int DEFAULT_CONCURRENCY_LEVEL = 16;
9 // table的负载因子
10 private static final float LOAD_FACTOR = 0.75f;
11 // 链表转换为红黑树的节点数阈值,超过这个值,链表转换为红黑树
12 static final int TREEIFY_THRESHOLD = 8;
13 // 在扩容期间,由红黑树转换为链表的阈值,小于这个值,resize期间红黑树就会转为链表
14 static final int UNTREEIFY_THRESHOLD = 6;
15 // 转为红黑树时,红黑树中节点的最小个数
16 static final int MIN_TREEIFY_CAPACITY = 64;
17 // 扩容时,并发转移节点(transfer方法)时,每次转移的最小节点数
18 private static final int MIN_TRANSFER_STRIDE = 16;
19
20 // 以下常量定义了特定节点类hash字段的值
21 static final int MOVED = -1; // ForwardingNode类对象的hash值
22 static final int TREEBIN = -2; // TreeBin类对象的hash值
23 static final int RESERVED = -3; // ReservationNode类对象的hash值
24 static final int HASH_BITS = 0x7fffffff; // 普通Node节点的hash初始值
25
26 // table数组
27 transient volatile Node<K,V>[] table;
28 // 扩容时,下一个容量大小的talbe,用于将原table元素移动到这个table中
29 private transient volatile Node<K,V>[] nextTable;
30 // 基础计数器
31 private transient volatile long baseCount;
32 // table初始容量大小以及扩容容量大小的参数,也用于标识table的状态
33 // 其有几个值来代表也用来代表table的状态:
34 // -1 :标识table正在初始化
35 // - N : 标识table正在进行扩容,并且有N - 1个线程一起在进行扩容
36 // 正数:初始table的大小,如果值大于初始容量大小,则表示扩容后的table大小。
37 private transient volatile int sizeCtl;
38 // 扩容时,下一个节点转移的bucket索引下标
39 private transient volatile int transferIndex;
40 // 一种自旋锁,是专为防止多处理器并发而引入的一种锁,用于创建CounterCells时使用,
41 // 主要用于size方法计数时,有并发线程插入而计算修改的节点数量,
42 // 这个数量会与baseCount计数器汇总后得出size的结果。
43 private transient volatile int cellsBusy;
44 // 主要用于size方法计数时,有并发线程插入而计算修改的节点数量,
45 // 这个数量会与baseCount计数器汇总后得出size的结果。
46 private transient volatile CounterCell[] counterCells;
47 // 其他省略
48 }
下面是几个重要的核心内部类。
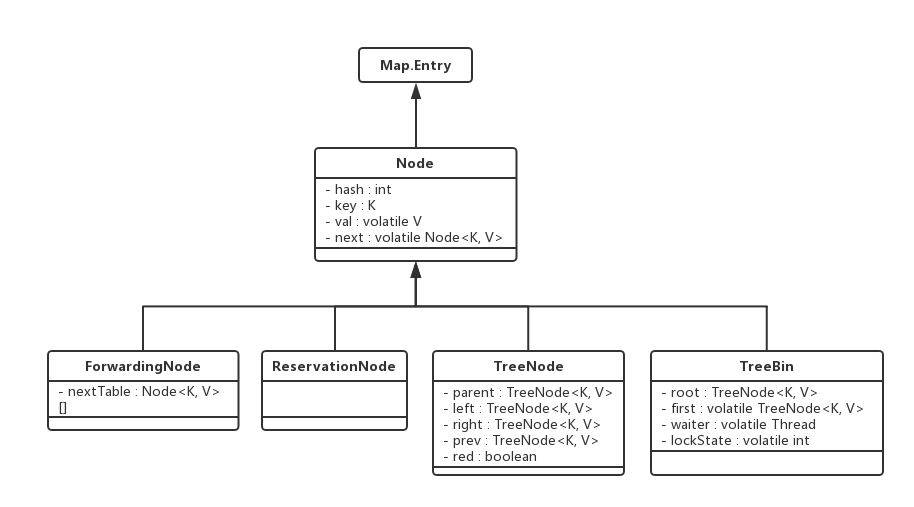
1 static class Node<K,V> implements Map.Entry<K,V> {
2 final int hash;
3 final K key;
4 volatile V val;
5 volatile Node<K,V> next;
6
7 Node(int hash, K key, V val, Node<K,V> next) {
8 this.hash = hash;
9 this.key = key;
10 this.val = val;
11 this.next = next;
12 }
13
14 public final K getKey() { return key; }
15 public final V getValue() { return val; }
16 public final int hashCode() { return key.hashCode() ^ val.hashCode(); }
17 public final String toString(){ return key + "=" + val; }
18 public final V setValue(V value) {
19 throw new UnsupportedOperationException();
20 }
21
22 public final boolean equals(Object o) {
23 Object k, v, u; Map.Entry<?,?> e;
24 return ((o instanceof Map.Entry) &&
25 (k = (e = (Map.Entry<?,?>)o).getKey()) != null &&
26 (v = e.getValue()) != null &&
27 (k == key || k.equals(key)) &&
28 (v == (u = val) || v.equals(u)));
29 }
30
31 /**
32 * Virtualized support for map.get(); overridden in subclasses.
33 */
34 Node<K,V> find(int h, Object k) {
35 Node<K,V> e = this;
36 if (k != null) {
37 do {
38 K ek;
39 if (e.hash == h &&
40 ((ek = e.key) == k || (ek != null && k.equals(ek))))
41 return e;
42 } while ((e = e.next) != null);
43 }
44 return null;
45 }
46 }
(2)TreeBin:内部属性有root,first节点,以及root节点的锁状态变量lockState,这是一个读写锁的状态。用于存放红黑树的root节点,并用读写锁lockState控制在写操作即将要调整树结构前,先让读线程完成读操作。从链表结构调整为红黑树时,table中索引下标存储的即为TreeBin。
1 static final class TreeBin<K,V> extends Node<K,V> {
2 TreeNode<K,V> root;
3 volatile TreeNode<K,V> first;
4 volatile Thread waiter;
5 volatile int lockState;
6 // values for lockState
7 static final int WRITER = 1; // set while holding write lock
8 static final int WAITER = 2; // set when waiting for write lock
9 static final int READER = 4; // increment value for setting read lock
10
11 /**
12 * Tie-breaking utility for ordering insertions when equal
13 * hashCodes and non-comparable. We don't require a total
14 * order, just a consistent insertion rule to maintain
15 * equivalence across rebalancings. Tie-breaking further than
16 * necessary simplifies testing a bit.
17 */
18 static int tieBreakOrder(Object a, Object b) {
19 int d;
20 if (a == null || b == null ||
21 (d = a.getClass().getName().
22 compareTo(b.getClass().getName())) == 0)
23 d = (System.identityHashCode(a) <= System.identityHashCode(b) ?
24 -1 : 1);
25 return d;
26 }
27
28 /**
29 * Creates bin with initial set of nodes headed by b.
30 */
31 TreeBin(TreeNode<K,V> b) {
32 super(TREEBIN, null, null, null);
33 this.first = b;
34 TreeNode<K,V> r = null;
35 for (TreeNode<K,V> x = b, next; x != null; x = next) {
36 next = (TreeNode<K,V>)x.next;
37 x.left = x.right = null;
38 if (r == null) {
39 x.parent = null;
40 x.red = false;
41 r = x;
42 }
43 else {
44 K k = x.key;
45 int h = x.hash;
46 Class<?> kc = null;
47 for (TreeNode<K,V> p = r;;) {
48 int dir, ph;
49 K pk = p.key;
50 if ((ph = p.hash) > h)
51 dir = -1;
52 else if (ph < h)
53 dir = 1;
54 else if ((kc == null &&
55 (kc = comparableClassFor(k)) == null) ||
56 (dir = compareComparables(kc, k, pk)) == 0)
57 dir = tieBreakOrder(k, pk);
58 TreeNode<K,V> xp = p;
59 if ((p = (dir <= 0) ? p.left : p.right) == null) {
60 x.parent = xp;
61 if (dir <= 0)
62 xp.left = x;
63 else
64 xp.right = x;
65 r = balanceInsertion(r, x);
66 break;
67 }
68 }
69 }
70 }
71 this.root = r;
72 assert checkInvariants(root);
73 }
74
75 /**
76 * Acquires write lock for tree restructuring.
77 */
78 private final void lockRoot() {
79 if (!U.compareAndSwapInt(this, LOCKSTATE, 0, WRITER))
80 contendedLock(); // offload to separate method
81 }
82
83 /**
84 * Releases write lock for tree restructuring.
85 */
86 private final void unlockRoot() {
87 lockState = 0;
88 }
89 ....略
90 }
(3)TreeNode:红黑树的节点,存放了父节点,左子节点,右子节点的引用,以及红黑节点标识。
1 static final class TreeNode<K,V> extends Node<K,V> {
2 TreeNode<K,V> parent; // red-black tree links
3 TreeNode<K,V> left;
4 TreeNode<K,V> right;
5 TreeNode<K,V> prev; // needed to unlink next upon deletion
6 boolean red;
7
8 TreeNode(int hash, K key, V val, Node<K,V> next,
9 TreeNode<K,V> parent) {
10 super(hash, key, val, next);
11 this.parent = parent;
12 }
13
14 Node<K,V> find(int h, Object k) {
15 return findTreeNode(h, k, null);
16 }
17
18 /**
19 * Returns the TreeNode (or null if not found) for the given key
20 * starting at given root.
21 */
22 final TreeNode<K,V> findTreeNode(int h, Object k, Class<?> kc) {
23 if (k != null) {
24 TreeNode<K,V> p = this;
25 do {
26 int ph, dir; K pk; TreeNode<K,V> q;
27 TreeNode<K,V> pl = p.left, pr = p.right;
28 if ((ph = p.hash) > h)
29 p = pl;
30 else if (ph < h)
31 p = pr;
32 else if ((pk = p.key) == k || (pk != null && k.equals(pk)))
33 return p;
34 else if (pl == null)
35 p = pr;
36 else if (pr == null)
37 p = pl;
38 else if ((kc != null ||
39 (kc = comparableClassFor(k)) != null) &&
40 (dir = compareComparables(kc, k, pk)) != 0)
41 p = (dir < 0) ? pl : pr;
42 else if ((q = pr.findTreeNode(h, k, kc)) != null)
43 return q;
44 else
45 p = pl;
46 } while (p != null);
47 }
48 return null;
49 }
50 }
(4)ForwardingNode:在调用transfer()方法期间,插入bucket头部的节点,主要用来标识在扩容时元素的移动状态,即是否在扩容时还有并发的插入节点,并保证该节点也能够移动到扩容后的表中。
1 static final class ForwardingNode<K,V> extends Node<K,V> {
2 final Node<K,V>[] nextTable;
3 ForwardingNode(Node<K,V>[] tab) {
4 super(MOVED, null, null, null);
5 this.nextTable = tab;
6 }
7
8 Node<K,V> find(int h, Object k) {
9 // loop to avoid arbitrarily deep recursion on forwarding nodes
10 outer: for (Node<K,V>[] tab = nextTable;;) {
11 Node<K,V> e; int n;
12 if (k == null || tab == null || (n = tab.length) == 0 ||
13 (e = tabAt(tab, (n - 1) & h)) == null)
14 return null;
15 for (;;) {
16 int eh; K ek;
17 if ((eh = e.hash) == h &&
18 ((ek = e.key) == k || (ek != null && k.equals(ek))))
19 return e;
20 if (eh < 0) {
21 if (e instanceof ForwardingNode) {
22 tab = ((ForwardingNode<K,V>)e).nextTable;
23 continue outer;
24 }
25 else
26 return e.find(h, k);
27 }
28 if ((e = e.next) == null)
29 return null;
30 }
31 }
32 }
33 }
(5)ReservationNode:占位节点,不存储任何信息,无实际用处,仅用于computeIfAbsent和compute方法中。
1 static final class ReservationNode<K,V> extends Node<K,V> {
2 ReservationNode() {
3 super(RESERVED, null, null, null);
4 }
5
6 Node<K,V> find(int h, Object k) {
7 return null;
8 }
9 }
其他比较重要的方法
在ConcurrentHashMap中使用了unSafe方法,通过直接操作内存的方式来保证并发处理的安全性,使用的是硬件的安全机制。
1 /*
2 * Volatile access methods are used for table elements as well as
3 * elements of in-progress next table while resizing. All uses of
4 * the tab arguments must be null checked by callers. All callers
5 * also paranoically precheck that tab's length is not zero (or an
6 * equivalent check), thus ensuring that any index argument taking
7 * the form of a hash value anded with (length - 1) is a valid
8 * index. Note that, to be correct wrt arbitrary concurrency
9 * errors by users, these checks must operate on local variables,
10 * which accounts for some odd-looking inline assignments below.
11 * Note that calls to setTabAt always occur within locked regions,
12 * and so in principle require only release ordering, not
13 * full volatile semantics, but are currently coded as volatile
14 * writes to be conservative.
15 */
16 /*
17 * 用来返回节点数组的指定位置的节点的原子操作
18 */
19 @SuppressWarnings("unchecked")
20 static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
21 return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
22 }
23
24 /*
25 * cas原子操作,在指定位置设定值
26 */
27 static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
28 Node<K,V> c, Node<K,V> v) {
29 return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
30 }
31 /*
32 * 原子操作,在指定位置设定值
33 */
34 static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v) {
35 U.putObjectVolatile(tab, ((long)i << ASHIFT) + ABASE, v);
36 }
ConCurrentHashMap构造方法
1 /**
2 * Creates a new, empty map with the default initial table size (16).
3 */
4 public ConcurrentHashMap() {
5 }
6
7 /**
8 * Creates a new, empty map with an initial table size
9 * accommodating the specified number of elements without the need
10 * to dynamically resize.
11 *
12 * @param initialCapacity The implementation performs internal
13 * sizing to accommodate this many elements.
14 * @throws IllegalArgumentException if the initial capacity of
15 * elements is negative
16 */
17 public ConcurrentHashMap(int initialCapacity) {
18 if (initialCapacity < 0)
19 throw new IllegalArgumentException();
20 int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
21 MAXIMUM_CAPACITY :
22 tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
23 this.sizeCtl = cap;
24 }
25
26 /**
27 * Creates a new map with the same mappings as the given map.
28 *
29 * @param m the map
30 */
31 public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
32 this.sizeCtl = DEFAULT_CAPACITY;
33 putAll(m);
34 }
35
36 /**
37 * Creates a new, empty map with an initial table size based on
38 * the given number of elements ({@code initialCapacity}) and
39 * initial table density ({@code loadFactor}).
40 *
41 * @param initialCapacity the initial capacity. The implementation
42 * performs internal sizing to accommodate this many elements,
43 * given the specified load factor.
44 * @param loadFactor the load factor (table density) for
45 * establishing the initial table size
46 * @throws IllegalArgumentException if the initial capacity of
47 * elements is negative or the load factor is nonpositive
48 *
49 * @since 1.6
50 */
51 public ConcurrentHashMap(int initialCapacity, float loadFactor) {
52 this(initialCapacity, loadFactor, 1);
53 }
54
55 /**
56 * Creates a new, empty map with an initial table size based on
57 * the given number of elements ({@code initialCapacity}), table
58 * density ({@code loadFactor}), and number of concurrently
59 * updating threads ({@code concurrencyLevel}).
60 *
61 * @param initialCapacity the initial capacity. The implementation
62 * performs internal sizing to accommodate this many elements,
63 * given the specified load factor.
64 * @param loadFactor the load factor (table density) for
65 * establishing the initial table size
66 * @param concurrencyLevel the estimated number of concurrently
67 * updating threads. The implementation may use this value as
68 * a sizing hint.
69 * @throws IllegalArgumentException if the initial capacity is
70 * negative or the load factor or concurrencyLevel are
71 * nonpositive
72 */
73 public ConcurrentHashMap(int initialCapacity,
74 float loadFactor, int concurrencyLevel) {
75 if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
76 throw new IllegalArgumentException();
77 if (initialCapacity < concurrencyLevel) // Use at least as many bins
78 initialCapacity = concurrencyLevel; // as estimated threads
79 long size = (long)(1.0 + (long)initialCapacity / loadFactor);
80 int cap = (size >= (long)MAXIMUM_CAPACITY) ?
81 MAXIMUM_CAPACITY : tableSizeFor((int)size);
82 this.sizeCtl = cap;
83 }
在以上代码中的17行的构造函数中,是自定义初始化大小的函数,在验证大小合理之后会进一步处理这个值,处理的算法就是第20行代码,其方法源代码:
1 private static final int tableSizeFor(int c) {
2 int n = c - 1;
3 n |= n >>> 1;
4 n |= n >>> 2;
5 n |= n >>> 4;
6 n |= n >>> 8;
7 n |= n >>> 16;
8 return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
9 }
PUT方法
1 /*
2 * 当添加一对键值对的时候,首先会去判断保存这些键值对的数组是不是初始化了,
3 * 如果没有的话就初始化数组
4 * 然后通过计算hash值来确定放在数组的哪个位置
5 * 如果这个位置为空则直接添加,如果不为空的话,则取出这个节点来
6 * 如果取出来的节点的hash值是MOVED(-1)的话,则表示当前正在对这个数组进行扩容,复制到新的数组,则当前线程也去帮助复制
7 * 最后一种情况就是,如果这个节点,不为空,也不在扩容,则通过synchronized来加锁,进行添加操作
8 * 然后判断当前取出的节点位置存放的是链表还是树
9 * 如果是链表的话,则遍历整个链表,直到取出来的节点的key来个要放的key进行比较,如果key相等,并且key的hash值也相等的话,
10 * 则说明是同一个key,则覆盖掉value,否则的话则添加到链表的末尾
11 * 如果是树的话,则调用putTreeVal方法把这个元素添加到树中去
12 * 最后在添加完成之后,会判断在该节点处共有多少个节点(注意是添加前的个数),如果达到8个以上了的话,
13 * 则调用treeifyBin方法来尝试将处的链表转为树,或者扩容数组
14 */
15 final V putVal(K key, V value, boolean onlyIfAbsent) {
16 if (key == null || value == null) throw new NullPointerException();//K,V都不能为空,否则的话跑出异常
17 int hash = spread(key.hashCode()); //取得key的hash值
18 int binCount = 0; //用来计算在这个节点总共有多少个元素,用来控制扩容或者转移为树
19 for (Node<K,V>[] tab = table;;) { //
20 Node<K,V> f; int n, i, fh;
21 if (tab == null || (n = tab.length) == 0)
22 tab = initTable(); //第一次put的时候table没有初始化,则初始化table
23 else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { //通过哈希计算出一个表中的位置因为n是数组的长度,所以(n-1)&hash肯定不会出现数组越界
24 if (casTabAt(tab, i, null, //如果这个位置没有元素的话,则通过cas的方式尝试添加,注意这个时候是没有加锁的
25 new Node<K,V>(hash, key, value, null))) //创建一个Node添加到数组中区,null表示的是下一个节点为空
26 break; // no lock when adding to empty bin
27 }
28 /*
29 * 如果检测到某个节点的hash值是MOVED,则表示正在进行数组扩张的数据复制阶段,
30 * 则当前线程也会参与去复制,通过允许多线程复制的功能,一次来减少数组的复制所带来的性能损失
31 */
32 else if ((fh = f.hash) == MOVED)
33 tab = helpTransfer(tab, f);
34 else {
35 /*
36 * 如果在这个位置有元素的话,就采用synchronized的方式加锁,
37 * 如果是链表的话(hash大于0),就对这个链表的所有元素进行遍历,
38 * 如果找到了key和key的hash值都一样的节点,则把它的值替换到
39 * 如果没找到的话,则添加在链表的最后面
40 * 否则,是树的话,则调用putTreeVal方法添加到树中去
41 *
42 * 在添加完之后,会对该节点上关联的的数目进行判断,
43 * 如果在8个以上的话,则会调用treeifyBin方法,来尝试转化为树,或者是扩容
44 */
45 V oldVal = null;
46 synchronized (f) {
47 if (tabAt(tab, i) == f) { //再次取出要存储的位置的元素,跟前面取出来的比较
48 if (fh >= 0) { //取出来的元素的hash值大于0,当转换为树之后,hash值为-2
49 binCount = 1;
50 for (Node<K,V> e = f;; ++binCount) { //遍历这个链表
51 K ek;
52 if (e.hash == hash && //要存的元素的hash,key跟要存储的位置的节点的相同的时候,替换掉该节点的value即可
53 ((ek = e.key) == key ||
54 (ek != null && key.equals(ek)))) {
55 oldVal = e.val;
56 if (!onlyIfAbsent) //当使用putIfAbsent的时候,只有在这个key没有设置值得时候才设置
57 e.val = value;
58 break;
59 }
60 Node<K,V> pred = e;
61 if ((e = e.next) == null) { //如果不是同样的hash,同样的key的时候,则判断该节点的下一个节点是否为空,
62 pred.next = new Node<K,V>(hash, key, //为空的话把这个要加入的节点设置为当前节点的下一个节点
63 value, null);
64 break;
65 }
66 }
67 }
68 else if (f instanceof TreeBin) { //表示已经转化成红黑树类型了
69 Node<K,V> p;
70 binCount = 2;
71 if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, //调用putTreeVal方法,将该元素添加到树中去
72 value)) != null) {
73 oldVal = p.val;
74 if (!onlyIfAbsent)
75 p.val = value;
76 }
77 }
78 }
79 }
80 if (binCount != 0) {
81 if (binCount >= TREEIFY_THRESHOLD) //当在同一个节点的数目达到8个的时候,则扩张数组或将给节点的数据转为tree
82 treeifyBin(tab, i);
83 if (oldVal != null)
84 return oldVal;
85 break;
86 }
87 }
88 }
89 addCount(1L, binCount); //计数
90 return null;
91 }
初看起来,putVal方法很复杂,但笔者在代码上增加了比较详细的注释,看起来就方便的多啦,总体流程和步骤如下:
1、采用自旋的方式,保证首次put时,当前线程或其他并发put的线程等待table初始化完成后再次重试插入。自旋开始在19行代码,
2、采用自旋的方式,检查当前插入的元素在table中索引下标是否正在执行扩容,如果正在扩容,则帮助进行扩容,完成后,重试插入到新的table中。代码第33行是帮助扩容。
3、插入的table索引下标不为空,则对链表或红黑树的head节点加synchronized锁,再插入或更新。访问入口是Head节点,其他线程访问head,在链表或红黑树插入或修改时必须等待synchronized释放。第46行代码是加锁添加的开始。
4、插入后,如果发现链表节点数大于等于阈值8,调用treeifyBin方法,将链表转换为红黑树结构,提高读写性能。treeifyBin方法内部也同样采用synchronized方式保证线程安全性。也就是代码68行代码
5、插入元素后,会将索引代表的链表或红黑树的最新节点数量更新到baseCount或CounterCell中。代码89行。
putVal方法用到了很多字方法,如下,我们一一来分析:
(1)spread:计算元素的hash值
(2)initTable:初始化table,在首次执行put,computeIfAbsent,computIfPresent,compute,merge方法时调用。
(3)tabAt:用于定位key在table中的索引节点(head节点)。
(4)casTabAt:采用Unsafe的compareAndSwapObject方法,用CAS的方式更新或替换节点。
(5)helpTransfer:帮忙扩容。
(6)treeifyBin:链表转红黑树,实现源码就不分析了,感兴趣的同学可以自行研究下。
(7)addCount:链表或红黑树节点最新数量添加到CounterCell中。
spread方法
计算key的hash值,将key的hashCode的高16位也加入到计算中,避免平凡冲突。如果仅用key的hashCode作为hash值,那么2,4之类的整形key值,只有低4位,那么很容易发生冲突。
1 static final int spread(int h) {
2 return (h ^ (h >>> 16)) & HASH_BITS;
3 }
initTable方法
1 /**
2 * 初始化数组table,
3 * 如果sizeCtl小于0,说明别的数组正在进行初始化,则让出执行权
4 * 如果sizeCtl大于0的话,则初始化一个大小为sizeCtl的数组
5 * 否则的话初始化一个默认大小(16)的数组
6 * 然后设置sizeCtl的值为数组长度的3/4
7 */
8 private final Node<K,V>[] initTable() {
9 Node<K,V>[] tab; int sc;
10 while ((tab = table) == null || tab.length == 0) { //第一次put的时候,table还没被初始化,进入while
11 if ((sc = sizeCtl) < 0) //sizeCtl初始值为0,当小于0的时候表示在别的线程在初始化表或扩展表
12 Thread.yield(); // lost initialization race; just spin
13 else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) { //SIZECTL:表示当前对象的内存偏移量,sc表示期望值,-1表示要替换的值,设定为-1表示要初始化表了
14 try {
15 if ((tab = table) == null || tab.length == 0) {
16 int n = (sc > 0) ? sc : DEFAULT_CAPACITY; //指定了大小的时候就创建指定大小的Node数组,否则创建指定大小(16)的Node数组
17 @SuppressWarnings("unchecked")
18 Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
19 table = tab = nt;
20 sc = n - (n >>> 2);
21 }
22 } finally {
23 sizeCtl = sc; //初始化后,sizeCtl长度为数组长度的3/4
24 }
25 break;
26 }
27 }
28 return tab;
29 }
初始化的步骤如下:
1、自旋检查table是否完成初始化。
2、若发现sizeCtl值为负数,则放弃初始化的竞争,让其他正在初始化的线程完成初始化。
3、如果没有其他线程初始化,则用Unsafe.compareAndSwapInt更新sizeCtl的值为-1,表示table开始被当前线程执行初始化,其他线程禁止执行。
4、初始化:table设置为默认容量大小(元素并未初始化,只是划定了大小),sizeCtl设为下次扩容table的size大小。
5、初始化完成。
整个初始化,用到了sizeCtl和Unsafe.compareAndSwapInt来保证初始化的线程安全性。有没有觉得Doug Lea大神对并发编程的出神入化。
tabAt和casTabAt方法
这两个方法比较简单,都是利用Unsafe的CAS方法保证读取和替换的原子性,保证线程安全。
1 static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
2 return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
3 }
4
5 static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
6 Node<K,V> c, Node<K,V> v) {
7 return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
8 }
疑问解答:为什么table本身明明用了volatile修饰,不直接用table[i]的方式取节点,而非要用Unsafe.getObjectVolatile方法的CAS操作取节点。
答:虽然table本身是volatile类型,但仅仅是指table数组引用本身,而数组中每个元素并不是volatile类型,Unsafe.getObjectVolatile保证了每次从table中读取某个位置链表引用的时候都是从主内存中读取的,如果不用该方法,有可能读的是缓存中已有的该位置的旧数据。
helpTransfer方法
这是一个辅助扩容的方法,能够支持扩容时直接加入到扩容中,其中真正扩容的核心方法是transfer,扩容前,会更新SIZECTL的值,表示并发扩容的线程数,transfer扩容方法太过复杂,本文不做介绍,将在下篇文章中介绍。
1 final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {
2 Node<K,V>[] nextTab; int sc;
3 if (tab != null && (f instanceof ForwardingNode) &&
4 (nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {
5 int rs = resizeStamp(tab.length);
6 while (nextTab == nextTable && table == tab &&
7 (sc = sizeCtl) < 0) {
8 if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
9 sc == rs + MAX_RESIZERS || transferIndex <= 0)
10 break;
11 if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {
12 transfer(tab, nextTab);
13 break;
14 }
15 }
16 return nextTab;
17 }
18 return table;
19 }
20
21 static final int resizeStamp(int n) {
22 return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1));
23 }
addCount方法
1 /**
2 * Adds to count, and if table is too small and not already
3 * resizing, initiates transfer. If already resizing, helps
4 * perform transfer if work is available. Rechecks occupancy
5 * after a transfer to see if another resize is already needed
6 * because resizings are lagging additions.
7 *
8 * @param x the count to add
9 * @param check if <0, don't check resize, if <= 1 only check if uncontended
10 */
11 private final void addCount(long x, int check) {
12 // check,即链表或红黑树的节点数,<0不检查是否正在扩容,
13 // <=1仅检查是否存在竞争,没有竞争则直接返回
14 CounterCell[] as; long b, s;
15 // 如果首次执行addCount,并且尝试用CAS对baseCount计数失败,表示有竞争,则执行如下操作。
16 // 或者非首次addCount,也执行如下的操作
17 if ((as = counterCells) != null ||
18 !U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
19 CounterCell a; long v; int m;
20 boolean uncontended = true;
21 if (as == null || (m = as.length - 1) < 0 ||
22 (a = as[ThreadLocalRandom.getProbe() & m]) == null ||
23 !(uncontended =
24 U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
25 fullAddCount(x, uncontended);
26 return;
27 }
28 if (check <= 1)
29 return;
30 s = sumCount();
31 }
32 if (check >= 0) {
33 Node<K,V>[] tab, nt; int n, sc;
34 while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
35 (n = tab.length) < MAXIMUM_CAPACITY) {
36 int rs = resizeStamp(n);
37 if (sc < 0) {
38 if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
39 sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
40 transferIndex <= 0)
41 break;
42 if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
43 transfer(tab, nt);
44 }
45 else if (U.compareAndSwapInt(this, SIZECTL, sc,
46 (rs << RESIZE_STAMP_SHIFT) + 2))
47 transfer(tab, null);
48 s = sumCount();
49 }
50 }
51 }
52 // sumCount方法
53 final long sumCount() {
54 CounterCell[] as = counterCells; CounterCell a;
55 long sum = baseCount;
56 if (as != null) {
57 for (int i = 0; i < as.length; ++i) {
58 if ((a = as[i]) != null)
59 sum += a.value;
60 }
61 }
62 return sum;
63 }
addCount方法做了如下操作:
1、判断是否首次执行addCount,并判断是否存在竞争关系,如果CAS成功,数量就成功汇总到baseCount中,如果CAS操作失败,则表示有竞争,有其他线程并发插入,则修改的数量会被记录到CounterCell中。
2、BaseCount和CounterCell相加就表示正常无并发下的节点数量和并发插入下的节点数量,table索引下标所代表的链表或红黑树节点的数量就能达到精确计算的效果。
3、在addCount时,还会去检查sizeCtl是否为-N,以确定table是否正在扩容,如果正在扩容,则加入到扩容的操作中。
addCount方法所统计的数值baseCount和counterCells将会被用到size方法中,用于精确计算并发读写情况下table中元素的数量。这种设计多么巧妙,不愧为Doug Lea大神的设计,因此这种设计思路也可以在实际的工作应用中多思考思考,作为很多并发统计问题的解决做设计参考。
size方法
1 public int size() {
2 long n = sumCount();
3 return ((n < 0L) ? 0 :
4 (n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
5 (int)n);
6 }
7 // sumCount方法
8 final long sumCount() {
9 CounterCell[] as = counterCells; CounterCell a;
10 long sum = baseCount;
11 if (as != null) {
12 for (int i = 0; i < as.length; ++i) {
13 if ((a = as[i]) != null)
14 sum += a.value;
15 }
16 }
17 return sum;
18 }
size方法最终执行的是sumCount方法,在sumCount方法中,其实就是将baseCount的数值与CounterCell表中并发情况下插入的节点数量进行汇总累加得到。这个结果也把并发的情况也考虑进去了。看这个方法之前最好先看addCount方法。
GET方法
相比put操作,get操作就显得很简单了。废话少说,直接上源码分析。
1 /*
2 * 相比put方法,get就很单纯了,支持并发操作,
3 * 当key为null的时候回抛出NullPointerException的异常
4 * get操作通过首先计算key的hash值来确定该元素放在数组的哪个位置
5 * 然后遍历该位置的所有节点
6 * 如果不存在的话返回null
7 */
8 public V get(Object key) {
9 Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
10 int h = spread(key.hashCode());
11 if ((tab = table) != null && (n = tab.length) > 0 &&
12 (e = tabAt(tab, (n - 1) & h)) != null) {
13 if ((eh = e.hash) == h) {
14 if ((ek = e.key) == key || (ek != null && key.equals(ek)))
15 return e.val;
16 }
17 else if (eh < 0)
18 return (p = e.find(h, key)) != null ? p.val : null;
19 while ((e = e.next) != null) {
20 if (e.hash == h &&
21 ((ek = e.key) == key || (ek != null && key.equals(ek))))
22 return e.val;
23 }
24 }
25 return null;
26 }
get方法步骤:
1、计算key的hash值,并定位table索引
2、若table索引下元素(head节点)为普通链表,则按链表的形式迭代遍历。13行代码
3、若table索引下元素为红黑树TreeBin节点,则按红黑树的方式查找(find方法)。17行代码。
红黑树的查找方法源码如下:
步骤如下:
1、检查lockState是否为写锁,如果是,则表示有并发写入线程在写入,则按正常的链表方式遍历并查找。
2、如果没有写锁,仅加读锁,然后按红黑树的方式查找(TreeBin.findTreeNode方法)。
1 final Node<K,V> find(int h, Object k) {
2 if (k != null) {
3 for (Node<K,V> e = first; e != null; ) {
4 int s; K ek;
5 if (((s = lockState) & (WAITER|WRITER)) != 0) {
6 if (e.hash == h &&
7 ((ek = e.key) == k || (ek != null && k.equals(ek))))
8 return e;
9 e = e.next;
10 }
11 else if (U.compareAndSwapInt(this, LOCKSTATE, s, s + READER)) {
12 TreeNode<K,V> r, p;
13 try {
14 p = ((r = root) == null ? null : r.findTreeNode(h, k, null));
15 } finally {
16 Thread w;
17 if (U.getAndAddInt(this, LOCKSTATE, -READER) ==
18 (READER|WAITER) && (w = waiter) != null)
19 LockSupport.unpark(w);
20 }
21 return p;
22 }
23 }
24 }
25 return null;
26 }
回答:还记得TreeBin和TreeNode节点和Node节点的继承关系吗?Node本身可以链成一个链表,而TreeBin和TreeNode也继承自Node节点,也自然继承了next属性,同样拥有链表的性质,其实真正在存储时,红黑树仍然是以链表形式存储的,只是逻辑上TreeBin和TreeNode多了支持红黑树的root,first, parent,left,right,red属性,在附加的属性上进行逻辑上的引用和关联,也就构造成了一颗树。这一点有点像LinkedHashMap,里面的节点又是在Table中,各个table中的元素又通过before和after引用进行双向链接,达到各个节点之间在逻辑上互链起来的效果。红黑树的查找遍历如下,其实就是二叉树查找,红黑树是按hash值的大小来构造左子节点和右子节点的,比父节点hash值小放在左边,大则放在右边的:
1 final TreeNode<K,V> findTreeNode(int h, Object k, Class<?> kc) {
2 if (k != null) {
3 TreeNode<K,V> p = this;
4 do {
5 int ph, dir; K pk; TreeNode<K,V> q;
6 TreeNode<K,V> pl = p.left, pr = p.right;
7 if ((ph = p.hash) > h)
8 p = pl;
9 else if (ph < h)
10 p = pr;
11 else if ((pk = p.key) == k || (pk != null && k.equals(pk)))
12 return p;
13 else if (pl == null)
14 p = pr;
15 else if (pr == null)
16 p = pl;
17 else if ((kc != null ||
18 (kc = comparableClassFor(k)) != null) &&
19 (dir = compareComparables(kc, k, pk)) != 0)
20 p = (dir < 0) ? pl : pr;
21 else if ((q = pr.findTreeNode(h, k, kc)) != null)
22 return q;
23 else
24 p = pl;
25 } while (p != null);
26 }
27 return null;
28 }
ConCurrentHashMap的同步机制
前面分析了下ConcurrentHashMap的源码,那么,对于一个映射集合来说,ConcurrentHashMap是如果来做到并发安全,又是如何做到高效的并发的呢?首先是读操作,从源码中可以看出来,在get操作中,根本没有使用同步机制,也没有使用unsafe方法,所以读操作是支持并发操作的。
那么写操作呢?
分析这个之前,先看看什么情况下会引起数组的扩容,扩容是通过transfer方法来进行的。而调用transfer方法的只有trePresize、helpTransfer和addCount三个方法。这三个方法又是分别在什么情况下进行调用的呢?
tryPresize是在treeIfybin和putAll方法中调用,treeIfybin主要是在put添加元素完之后,判断该数组节点相关元素是不是已经超过8个的时候,如果超过则会调用这个方法来扩容数组或者把链表转为树。
helpTransfer是在当一个线程要对table中元素进行操作的时候,如果检测到节点的HASH值为MOVED的时候,就会调用helpTransfer方法,在helpTransfer中再调用transfer方法来帮助完成数组的扩容
addCount是在当对数组进行操作,使得数组中存储的元素个数发生了变化的时候会调用的方法。
所以引起数组扩容的情况如下:
只有在往map中添加元素的时候,在某一个节点的数目已经超过了8个,同时数组的长度又小于64的时候,才会触发数组的扩容。当数组中元素达到了sizeCtl的数量的时候,则会调用transfer方法来进行扩容
那么在扩容的时候,可以不可以对数组进行读写操作呢?
事实上是可以的。当在进行数组扩容的时候,如果当前节点还没有被处理(也就是说还没有设置为fwd节点),那就可以进行设置操作。如果该节点已经被处理了,则当前线程也会加入到扩容的操作中去。
那么,多个线程又是如何同步处理的呢?
在ConcurrentHashMap中,同步处理主要是通过Synchronized和unsafe两种方式来完成的。·在取得sizeCtl、某个位置的Node的时候,使用的都是unsafe的方法,来达到并发安全的目的当需要在某个位置设置节点的时候,则会通过Synchronized的同步机制来锁定该位置的节点。在数组扩容的时候,则通过处理的步长和fwd节点来达到并发安全的目的,通过设置hash值为MOVED当把某个位置的节点复制到扩张后的table的时候,也通过Synchronized的同步机制来保证现程安全。
总结
在jdk1.8中ConCurrentHashMap升级比较复杂,我也是参考了很多资料,感谢网络大神分享。
https://www.cnblogs.com/zerotomax/p/8687425.html
https://www.jianshu.com/p/b7dda385f83d
https://www.jianshu.com/p/85d158455861
JAVA-JDK1.8-ConCurrentHashMap-源码并且debug说明的更多相关文章
- 死磕 java集合之ConcurrentHashMap源码分析(三)
本章接着上两章,链接直达: 死磕 java集合之ConcurrentHashMap源码分析(一) 死磕 java集合之ConcurrentHashMap源码分析(二) 删除元素 删除元素跟添加元素一样 ...
- JDK1.7 ConcurrentHashMap 源码浅析
概述 ConcurrentHashMap是HashMap的线程安全版本,使用了分段加锁的方案,在高并发时有比较好的性能. 本文分析JDK1.7中ConcurrentHashMap的实现. 正文 Con ...
- 死磕 java集合之ConcurrentHashMap源码分析(一)
开篇问题 (1)ConcurrentHashMap与HashMap的数据结构是否一样? (2)HashMap在多线程环境下何时会出现并发安全问题? (3)ConcurrentHashMap是怎么解决并 ...
- JDK1.8 ConcurrentHashMap源码阅读
1. 带着问题去阅读 为什么说ConcurrentHashMap是线程安全的?或者说 ConcurrentHashMap是如何防止并发的? 2. 字段和常量 首先,来看一下ConcurrentHa ...
- 死磕 java集合之ConcurrentHashMap源码分析(二)——扩容
本章接着上一章,链接直达请点我. 初始化桶数组 第一次放元素时,初始化桶数组. private final Node<K,V>[] initTable() { Node<K,V> ...
- 死磕Java之聊聊HashSet源码(基于JDK1.8)
HashSet的UML图 HashSet的成员变量及其含义 public class HashSet<E> extends AbstractSet<E> implements ...
- 死磕Java之聊聊HashMap源码(基于JDK1.8)
死磕Java之聊聊HashMap源码(基于JDK1.8) http://cmsblogs.com/?p=4731 为什么面试要问hashmap 的原理
- Java之ConcurrentHashMap源码解析
ConcurrentHashMap源码解析 目录 ConcurrentHashMap源码解析 jdk8之前的实现原理 jdk8的实现原理 变量解释 初始化 初始化table put操作 hash算法 ...
- java Thread 类的源码阅读(oracle jdk1.8)
java线程类的源码分析阅读技巧: 首先阅读thread类重点关注一下几个问题: 1.start() ,启动一个线程是如何实现的? 2.java线程状态机的变化过程以及如何实现的? 3. 1.star ...
- 并发-ConcurrentHashMap源码分析
ConcurrentHashMap 参考: http://www.cnblogs.com/chengxiao/p/6842045.html https://my.oschina.net/hosee/b ...
随机推荐
- 「Spark从精通到重新入门(二)」Spark中不可不知的动态资源分配
前言 资源是影响 Spark 应用执行效率的一个重要因素.Spark 应用中真正执行 task 的组件是 Executor,可以通过spark.executor.instances 指定 Spark ...
- Sql Server、Oracle、MySQL 日期格式化函数处理
目录 Sql Server Oracle MySql Sql Server CONVERT ( '取数长度' , '时间' , '类型') 查询对应时间: 2021-03-17T19:18:18.00 ...
- MySQL 的日志:binlog
前言:binlog 用于记录数据库执行写入性操作的日志信息,以二进制的形式保留在磁盘中.它是由 Server 层进行记录的,使用任何存储引擎都会产生 binlog. 实验准备 我们通过 Docker ...
- CF475A Bayan Bus 题解
Update \(\texttt{2020.10.6}\) 修改了一些笔误. Content 模拟一个核载 \(34\) 人的巴士上有 \(k\) 个人时的巴士的状态. 每个人都会优先选择有空位的最后 ...
- 如何把Electron做成一个Runtime,让多个应用共享同一个Electron
这个问题涉及到很多知识,而且要想把这个Runtime做好很绕. 下面我就说一下我的思路:(以下内容以Windows平台为基础,Mac平台和Linux平台还得去调查一下,才能确定是否可行) 首先,我们先 ...
- Linux使用docker安装RabbitMQ
拉取镜像 docker pull rabbitmq:management 启动容器 docker run -d --name rabbitmq -e RABBITMQ_DEFAULT_USER=adm ...
- vue使用npm install安装太慢连接不上(设置使用淘宝镜像)
当使用默认的npm install速度太慢时候,可以配置使用淘宝镜像 npm config set registry https://registry.npm.taobao.org
- jQuery Validate验证(判断)某个字段是否通过验证
jQuery Validate 默认只能判断整个表单是否验证通过,但是有时候我们需要对某个字段进行判断 ,可以使用以下方法 var bool=$("整个form表单的ID").va ...
- c++11之 algorithm 算法库新增 minmax_element同时计算最大值和最小值
0.时刻提醒自己 Note: vector的释放 1. minmax_element 功能 寻找范围 [first, last) 中最小和最大的元素. 2. 头文件 #include <algo ...
- 【九度OJ】题目1056:最大公约数 解题报告
[九度OJ]题目1056:最大公约数 解题报告 标签(空格分隔): 九度OJ 原题地址:http://ac.jobdu.com/problem.php?pid=1056 题目描述: 输入两个正整数,求 ...