Python多线程、线程池及实际运用
我们在写python爬虫的过程中,对于大量数据的抓取总是希望能获得更高的速度和效率,但由于网络请求的延迟、IO的限制,单线程的运行总是不能让人满意。因此有了多线程、异步协程等技术。
下面介绍一下python中的多线程及线程池技术,并通过一个具体的爬虫案例实现具体运用。
多线程
先来分析单线程。写两个测试函数
def func1():for i in range(500000):print("func1", i)def func2():for i in range(500000):print("func2", i)
在主函数中调用
if __name__ == "__main__":func1()func2()
当程序执行时,按照主程序中的执行顺序,func1全部运行完毕后才会运行func2,这就是单线程的效果。
接下来测试多线程。
先导包
from threading import Thread
改造主函数
thread1 = Thread(target=func1)thread1.start()thread2 = Thread(target=func2)thread2.start()thread1.join()thread2.join()
这里的thread.join()是阻塞进程,因为这里主函数中没有
执行效果如下:
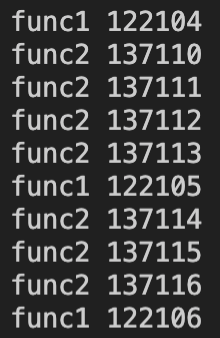
可以看到func1和func2函数分为两个不同的线程同时工作、互不干扰。
线程池
以此类推,如果同时开着20个这样的线程,是否可以同时执行呢?但手动分配这么多线程显然是不可能的,因此引入线程池这一概念,一次开辟一些进程,我们用户直接给线程池提交任务,线程任务的调度交给线程池来完成。这样一来,就能十分方便的分配线程的任务了。
首先导包
from concurrent.futures import ThreadPoolExecutor
改造一下子函数
def func(url):for i in range(1000):print(url)
主函数
if __name__ == "__main__":# 创建线程池with ThreadPoolExecutor(50) as t:for i in range(100):t.submit(func, url=f"线程{i}")print("over")
我们建立一个线程池,分配50个线程,提交100个任务,让他们去自由分配。现有的50个线程先去拿到了1-50这些任务,当谁先完成就去拿到51个任务,以此类推。相当于50个工人一起干活,互不干涉,显然效率较单人更高一些。
再来看运行结果

线程锁
了解了线程池的基本概念之后就可以去改造我们的爬虫了。但是在此之前该需要了解一个线程锁的概念。先看下面这个例子
from threading import Threadnum = 0def add():global numfor i in range(100000):num += 1def minus():global numfor i in range(100000):num -= 1if __name__=="__main__":thread1 = Thread(target=add)thread2 = Thread(target=minus)thread1.start()thread2.start()thread1.join()thread2.join()print(num)
开辟两个线程,一个做自增一个做自减,他们两个同时运行,按常理num最终的值应为0,但实际运行结果是不稳定的。

由于每个线程运行速度极快,因此在他们的临界点都想对全局变量num操作时会出现竞争状态,有可能出现数值丢失、自增失败的情况,因此需要加入线程锁来控制每次只允许有一个线程对全局变量num进行操作。
import threadinglock = threading.Lock()
lock.acquire()num += 1lock.release()
在线程中的关键操作加上线程锁,再跑起来就不会出现竞争状态了。

爬虫实战
要在爬虫中运用到线程池,基本的思路很简单,
1.如何抓取到单个页面的数据
2.上线程池批量抓取
目标:https://www.dydytt.net/html/gndy/dyzz/list_23_1.html
这里仅做线程池的基本实验,具体案例移步这里
先随便写个爬虫拿到第一页的所有电影标题数据
import requestsfrom lxml import etreefilmNameList = []def download(url):global filmNameListresp = requests.get(url)resp.encoding="gb2312"html = etree.HTML(resp.text)filmName = html.xpath('//table[@class="tbspan"]/tr[2]/td[2]/b/a/text()')for each in filmName:filmNameList.append(each)passif __name__=="__main__":url = "https://www.dydytt.net/html/gndy/dyzz/list_23_1.html"download(url)for i in filmNameList:print(i)
非常轻松的拿到了第一页的数据

接下来上线程池
import requestsimport threadingfrom concurrent.futures import ThreadPoolExecutorfrom lxml import etreefilmNameList = []lock = threading.Lock()def download(url):global filmNameListresp = requests.get(url)resp.encoding="gb2312"html = etree.HTML(resp.text)filmName = html.xpath('//table[@class="tbspan"]/tr[2]/td[2]/b/a/text()')for each in filmName:lock.acquire()filmNameList.append(each)lock.release()resp.close()if __name__=="__main__":with ThreadPoolExecutor(5) as t:for i in range(1, 11):url = f"https://www.dydytt.net/html/gndy/dyzz/list_23_{i}.html"t.submit(download, url=url)for i in filmNameList:print(i)print(f"total_len is {len(filmNameList)}")
我们给线程池分配了5个线程,抓了前10页共250条数据。
 ****
****
Python多线程、线程池及实际运用的更多相关文章
- C#多线程--线程池(ThreadPool)
先引入一下线程池的概念: 百度百科:线程池是一种多线程处理形式,处理过程中将任务添加到队列,然后在创建线程后自动启动这些任务.线程池线程都是后台线程.每个线程都使用默认的堆栈大小,以默认的优先级运行, ...
- linux C 多线程/线程池编程 同步实例
在多线程.线程池编程中经常会遇到同步的问题. 1.创建线程 函数原型:int pthread_create(pthread_t *thread, const pthread_attr_t *attr, ...
- Python的线程池实现
# -*- coding: utf-8 -*- #Python的线程池实现 import Queue import threading import sys import time import ur ...
- 【Python】多线程-线程池使用
1.学习目标 线程池使用 2.编程思路 2.1 代码原理 线程池是预先创建线程的一种技术.线程池在还没有任务到来之前,创建一定数量的线程,放入空闲队列中.这些线程都是处于睡眠状态,即均为启动,不消耗 ...
- Python之路【第八篇】python实现线程池
线程池概念 什么是线程池?诸如web服务器.数据库服务器.文件服务器和邮件服务器等许多服务器应用都面向处理来自某些远程来源的大量短小的任务.构建服务器应用程序的一个过于简单的模型是:每当一个请求到达就 ...
- python自定义线程池
关于python的多线程,由与GIL的存在被广大群主所诟病,说python的多线程不是真正的多线程.但多线程处理IO密集的任务效率还是可以杠杠的. 我实现的这个线程池其实是根据银角的思路来实现的. 主 ...
- [python] ThreadPoolExecutor线程池 python 线程池
初识 Python中已经有了threading模块,为什么还需要线程池呢,线程池又是什么东西呢?在介绍线程同步的信号量机制的时候,举得例子是爬虫的例子,需要控制同时爬取的线程数,例子中创建了20个线程 ...
- 《Python》线程池、携程
一.线程池(concurrent.futures模块) #1 介绍 concurrent.futures模块提供了高度封装的异步调用接口 ThreadPoolExecutor:线程池,提供异步调用 P ...
- [python] ThreadPoolExecutor线程池
初识 Python中已经有了threading模块,为什么还需要线程池呢,线程池又是什么东西呢?在介绍线程同步的信号量机制的时候,举得例子是爬虫的例子,需要控制同时爬取的线程数,例子中创建了20个线程 ...
- java多线程--线程池的使用
程序启动一个新线程的成本是很高的,因为涉及到要和操作系统进行交互,而使用线程池可以很好的提高性能,尤其是程序中当需要创建大量生存期很短的线程时,应该优先考虑使用线程池. 线程池的每一个线程执行完毕后, ...
随机推荐
- Nginx配置访问黑名单
目录 一.简介 二.脚本 一.简介 有的时候需要将某些大访问量的ip加入到黑名单中 二.脚本 1.脚本内容为,检测本地并发访问超过15并且是ip地址,则加入nginx黑名单中.其中的53a是deny行 ...
- Apache Log4j 远程代码执行漏洞源码级分析
漏洞的前因后果 漏洞描述 漏洞评级 影响版本 安全建议 本地复现漏洞 本地打印 JVM 基础信息 本地获取服务器的打印信息 log4j 漏洞源码分析 扩展:JNDI 危害是什么? GitHub 项目 ...
- 第44篇-为native方法设置解释执行入口
对于Java中的native方法来说,实际上调用的是C/C++实现的本地函数,由于可能会在Java解释执行过程中调用native方法,或在本地函数的实现过程中调用Java方法,所以当两者相互调用时,必 ...
- LuoguP5238 整数校验器 题解
Content 给定两个整数 \(l,r\),再给定 \(T\) 个整数,请判断对于每个整数 \(x\),是否满足以下要求: \(x\in[l,r]\). \(x\) 格式合法. 数据范围:\(-2^ ...
- re正则表达式:import re ;re.search()
http://www.cnblogs.com/alex3714/articles/5161349.html re模块 常用正则表达式符号 1 2 3 4 5 6 7 8 9 10 11 12 13 1 ...
- Boost Asio要点概述(一)
[注]本文不是boost asio的完整应用讲述,而是仅对其中要点的讲解,主要参考了Boost Asio 1.68的官方文档(https://www.boost.org/doc/libs/1_68_0 ...
- 资源分享 | PyTea:不用运行代码,静态分析pytorch模型的错误
前言 本文介绍一个Pytorch模型的静态分析器 PyTea,它不需要运行代码,即可在几秒钟之内扫描分析出模型中的张量形状错误.文末附使用方法. 本文转载自机器之心 编辑:CV技 ...
- 二叉树c++实现
!!版权声明:本文为博主原创文章,版权归原文作者和博客园共有,谢绝任何形式的 转载!! 作者:mohist --- 欢迎指正--- 二叉树特点: 要么为空树:要么,当前结点的左孩子比当前结点值小,当前 ...
- 【LeetCode】496. Next Greater Element I 解题报告(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 直接遍历查找 字典保存位置 日期 题目地址:http ...
- VR AR MR的未来
VR:VR(Virtual Reality,即虚拟现实,简称VR),是由美国VPL公司创建人拉尼尔(Jaron Lanier)在20世纪80年代初提出的.其具体内涵是:综合利用计算机图形系统和各种现实 ...