Amobea读写分离
Amoeba的中文意思是变型虫,Amoeba是一个以MySQL为底层数据存储,并对应用提供MySQL协议接口的proxy。它集中地响应应用的请求,依据用户事先设置的 规则,将SQL请求发送到特定的数据库上执行。基于此可以实现负载均衡、读写分离、高可用性等需求。与MySQL官方的MySQL Proxy相比,作者强调的是amoeba配 置的方便(基于XML的配置文件,用SQLJEP语法书写规则,比基于lua脚本的MySQL Proxy简单);
Amoeba相当于一个SQL请求的路由器,目的是为负载均衡、读写分离、高可用性提供机制,而不是完全实现它们。用户需要结合使用MySQL的 Replication等机制 来实现副本同步等功能。amoeba对底层数据库连接管理和路由实现也采用了可插拨的机制,第三方可以开发更高级的策略类来替代作者的实现。这个程序总体上比较符 合KISS原则的思想。
主要解决:
• 降低数据切分带来的复杂多数据库结构
• 提供切分规则并降低数据切分规则给应用带来的影响
• 降低db 与客户端的连接数
• 读写分离
不足之处:
a)目前还不支持事务
b)暂时不支持存储过程(近期会支持)
c)不适合从amoeba导数据的场景或者对大数据量查询的query并不合适(比如一次请求返回10w以上甚至更多数据的场合)
d)暂时不支持分库分表,amoeba目前只做到分数据库实例,每个被切分的节点需要保持库表结构一致:
Amoeba:阿米巴原虫
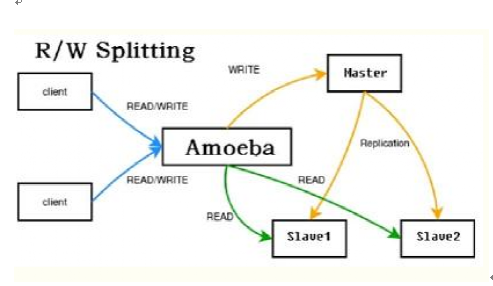
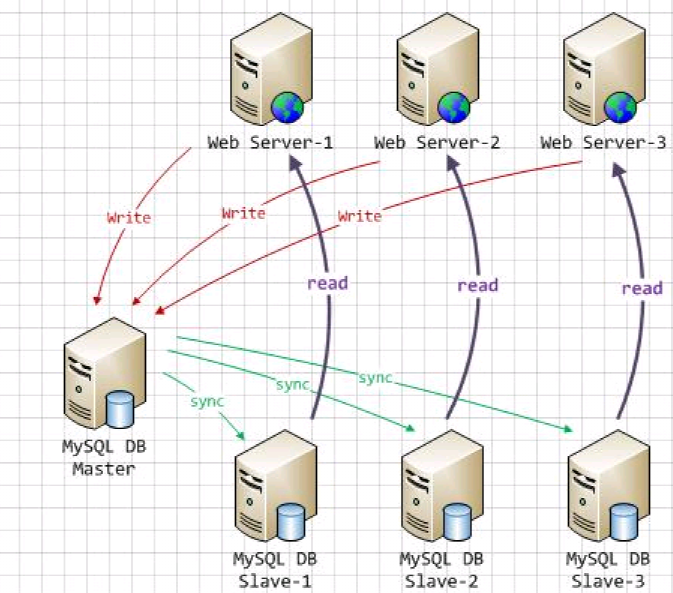
1》环境介绍
master--IP:192.168.100.161
slave---IP:192.168.100.160
Amoeba--IP:192.168.100.214
2》安装JDK
#mkdir /Amoeba
#tar –xvf jdk-7u40-linux-x64.tar.gz -C /Amoeba
# vim /etc/profile
JAVA_HOME=/Amoeba/jdk1.7.0_40
export JAVA_HOME
PATH=$JAVA_HOME/bin:$PATH
export PATH
CLASSPATH=:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$CLASSPATH
export CLASSPATH
3》安装Amoeba #:mkdir /usr/local/amoeba
#:unzip amoeba-mysql-1.3.1-BETA.zip -d /usr/local/amoeba
#:chmod -R +x /usr/local/amoeba/bin/
#java -version
java version "1.7.0_40"
Java(TM) SE Runtime Environment (build 1.7.0_40-b43)
Java HotSpot(TM) 64-Bit Server VM (build 24.0-b56, mixed mode)
4》主从授权,增加用户
mysql-->grant all privileges on *.* to amoeba@'%' identified by 'amoeba123';
mysql-->flush privileges;
5》Amoeba配置介绍
Amoeba For MySQL 的使用非常简单,所有的配置文件都是标准的XML 文件,总共有四个配置文件。分别为:amoeba.xml:主配置文件,配置所有数据源以及 Amoeba 自身的参数设置;实现主从的话配置这个文件就可以了;
rule.xml:配置所有Query 路由规则的信息;
functionMap.xml:配置用于解析Query 中的函数所对应的Java 实现类;
rullFunctionMap.xml:配置路由规则中需要使用到的特定函数的实现类;
6》配置Amoeba IP 与用户
# vim /usr/local/amoeba/conf/amoeba.xml
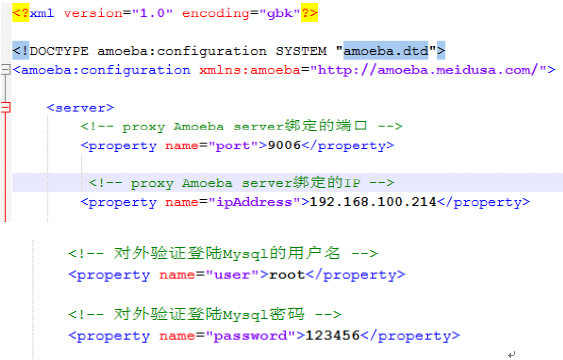
7》Amoeba配置Master基本信息
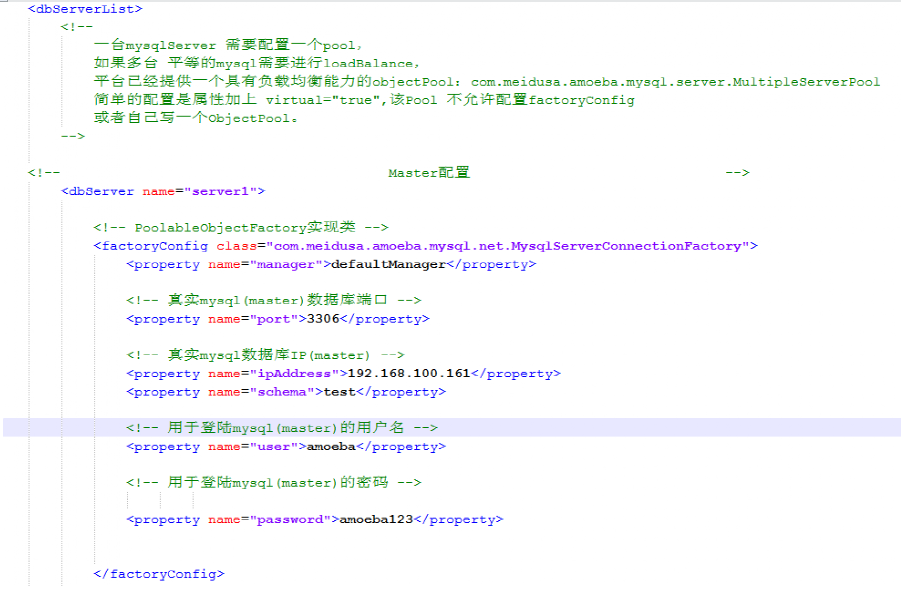

8》Amoeba配置Slave基本信息

9》Master负载配置

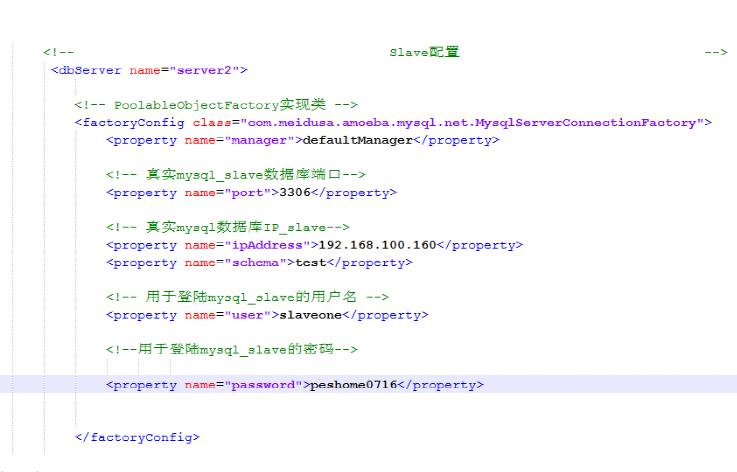
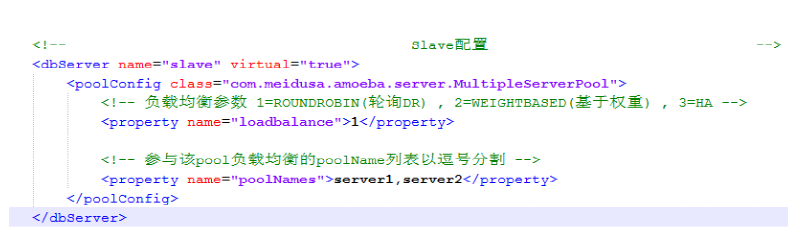
10》Slave负载配置
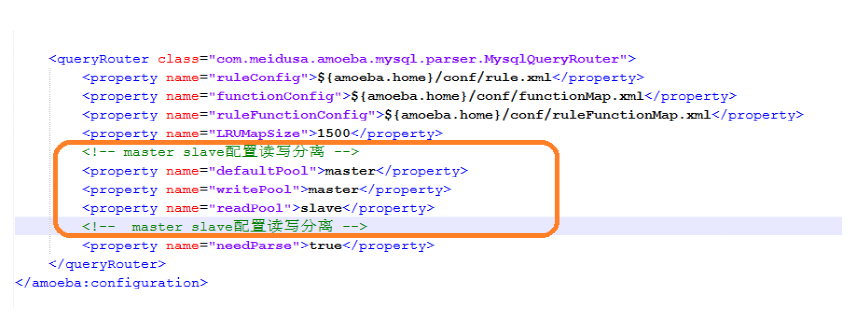
11》最后配置读写分离
启动Amoeba
# cd /usr/local/amoeba/bin
这种启动方便看nohup.log日志.防止提示溢出
#:nohup bash -x amoeba &
常见错误:1
The stack size specified is too small, Specify at least 228k
Error: Could not create the Java Virtual Machine.
Error: A fatal exception has occurred. Program will exit.
解决办法:
# vim /usr/local/amoeba/bin/amoeba
#DEFAULT_OPTS="-server -Xms256m -Xmx256m -Xss128k" 注释
DEFAULT_OPTS="-server -Xms256m -Xmx256m -Xss256k" 增加
常见错误2:
org.xml.sax.SAXParseException; lineNumber: 406; columnNumber: 6; 注释中不允许出现字符串"--"。
解决办法:
后来改了一大通,试了一下午,才发现。我们的注释两边要有空格,才行。
举例<!-- 实体类路径和名 -->
12》测试是否读写分离
1>在(master)主上的test库建立一个alvin的表
Mysql->use test;
Mysql->create table alvin(id int(10),name char(10));

2>在(slave)从上查看test库是否同步了alvin表
Mysql-> use test;
Mysql->show tables;
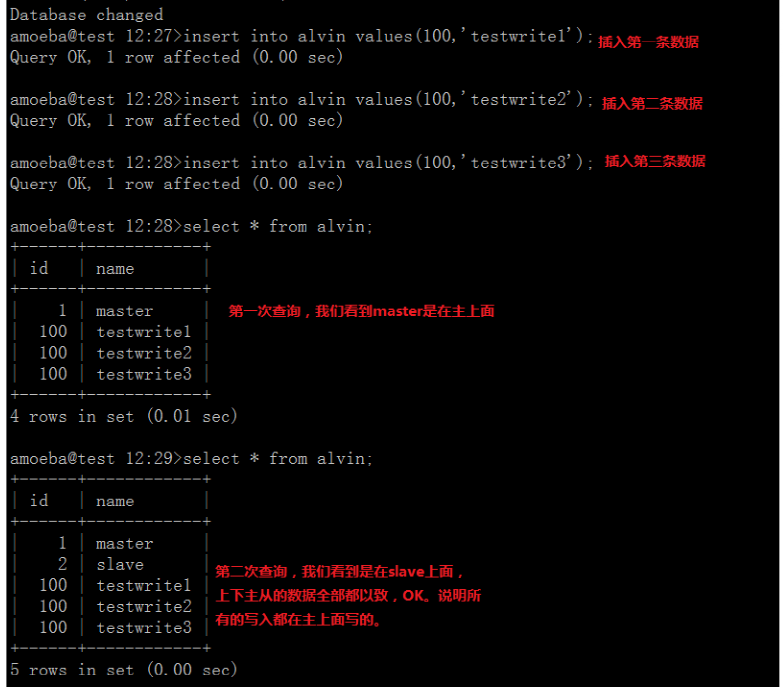
3>在主(master)操作.插入一条数据.
mysql-->insert into alvin values(1,'master');
4>在从(slave)操作,插入一条数据.
mysql-->insert into alvin values(2,'slave');
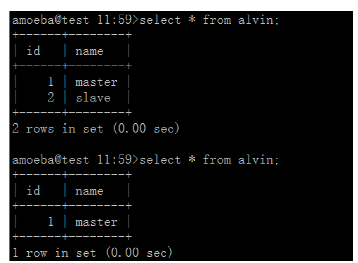
注意因为从同步主的数据。所以这里有2条数据,
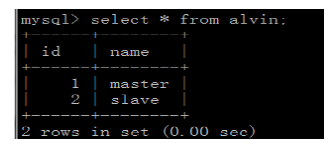
5>在Amoeba机器上操作
在192.168.100.214上面测试,这个密码就是配置文件里面对外的验证密码root 和密码123456

#mysql –u root –p 123456 –h 192.168.100.214 –P 9066
(1) 先验证读:我们配置文件是用的是DR轮询,注意这个IP地址要写:amoeba的IP地址,不是master也不是slave ,是通过amoeba代理登陆192.168.100.214
Mysql->use test;
测试轮询成功,主和从各查询一次。
(2) 验证写:正常来说。如果只有全部写到主里面,两边的数据才会以致。如果其中有一个不一致的话。那么说明写到从里面去了。因为主不会同步从的数据。都是 单向数据传输。
13》常用配置写法:
(1)如果负载多个库,软件会根据你用户授权来决定对哪些库有权限:
grant all privileges on *.* to amoeba@'%' identified by 'amoeba123'; 这里写的是all 那么就是对所有的库有权限(会自动负载所有的库).
上面配置文件的库名test.根据这个语句来决定.如果是all.那么直接用写test来测试.方便一点.
(2)一主一从的负载写法一:
主只写.<property name="poolNames">server1</property>
从只读.<property name="poolNames">server2</property>
(3)一主一从的负载写法:
主负写:<property name="poolNames">server1</property>
主也负责读,从也负责读.比例1:1 第一读.从.第二次读住.循环写的话,只能写主.<property name="poolNames">server1,server2</property>
(4)一主多从的负载写法:
比如.一台主.3台从.在最上面定义了.server1(master) server2(slave1) server3(slave2) server4(slave3)
1主只写:<property name="poolNames">server1</property>
3从负载读 <property name="poolNames">server2,server3,server4</property>
权重:1:1 3台轮询各一次.持续循环
(5)比如我想要.slave1 权重高一点.其它的.2台从.每次读一次.slave1读.2次.
<property name="poolNames">server2,server2,server3,server4</property>
=================================================================
amoeba.xml配置文件
<?xml version="1.0" encoding="gbk"?>
<!DOCTYPE amoeba:configuration SYSTEM "amoeba.dtd">
<amoeba:configuration xmlns:amoeba="http://amoeba.meidusa.com/">
<server>
<!-- proxy server绑定的端口 -->
<property name="port">6006</property>
<!-- proxy server绑定的IP -->
<property name="ipAddress">10.0.2.160</property>
<!-- proxy server net IO Read thread size -->
<property name="readThreadPoolSize">20</property>
<!-- proxy server client process thread size -->
<property name="clientSideThreadPoolSize">30</property>
<!-- mysql server data packet process thread size -->
<property name="serverSideThreadPoolSize">30</property>
<!-- socket Send and receive BufferSize(unit:K) -->
<property name="netBufferSize">128</property>
<!-- Enable/disable TCP_NODELAY (disable/enable Nagle's algorithm). -->
<property name="tcpNoDelay">true</property>
<!-- 对外验证的用户名 -->
<property name="user">root</property>
<!-- 对外验证的密码 -->
<property name="password">123456</property>
<!-- query timeout( default: 60 second , TimeUnit:second) -->
<property name="queryTimeout">60</property>
</server>
<!--
每个ConnectionManager都将作为一个线程启动。
manager负责Connection IO读写/死亡检测
-->
<connectionManagerList>
<connectionManager name="defaultManager" class="com.meidusa.amoeba.net.MultiConnectionManagerWrapper">
<property name="subManagerClassName">com.meidusa.amoeba.net.AuthingableConnectionManager</property>
<!--
default value is avaliable Processors
<property name="processors">5</property>
-->
</connectionManager>
</connectionManagerList>
<dbServerList>
<!--
一台mysqlServer 需要配置一个pool,
如果多台 平等的mysql需要进行loadBalance,
平台已经提供一个具有负载均衡能力的objectPool:com.meidusa.amoeba.mysql.server.MultipleServerPool
简单的配置是属性加上 virtual="true",该Pool 不允许配置factoryConfig
或者自己写一个ObjectPool。
-->
<dbServer name="server1">
<!-- PoolableObjectFactory实现类 -->
<factoryConfig class="com.meidusa.amoeba.mysql.net.MysqlServerConnectionFactory">
<property name="manager">defaultManager</property>
<!-- 真实mysql数据库端口 -->
<property name="port">3306</property>
<!-- 真实mysql数据库IP -->
<property name="ipAddress">10.0.2.159</property>
<property name="schema">test</property>
<!-- 用于登陆mysql的用户名 -->
<property name="user">amoeba</property>
<!-- 用于登陆mysql的密码 -->
<property name="password">amoeba123</property>
</factoryConfig>
<!-- ObjectPool实现类 -->
<poolConfig class="com.meidusa.amoeba.net.poolable.PoolableObjectPool">
<property name="maxActive">200</property>
<property name="maxIdle">200</property>
<property name="minIdle">10</property>
<property name="minEvictableIdleTimeMillis">600000</property>
<property name="timeBetweenEvictionRunsMillis">600000</property>
<property name="testOnBorrow">true</property>
<property name="testWhileIdle">true</property>
</poolConfig>
</dbServer>
<dbServer name="server2">
<!-- PoolableObjectFactory实现类 -->
<factoryConfig class="com.meidusa.amoeba.mysql.net.MysqlServerConnectionFactory">
<property name="manager">defaultManager</property>
<!-- 真实mysql数据库端口 -->
<property name="port">3306</property>
<!-- 真实mysql数据库IP -->
<property name="ipAddress">10.0.2.158</property>
<property name="schema">test</property>
<!-- 用于登陆mysql的用户名 -->
<property name="user">amoeba</property>
<!-- 用于登陆mysql的密码 -->
<property name="password">amoeba123</property>
</factoryConfig>
<!-- ObjectPool实现类 -->
<poolConfig class="com.meidusa.amoeba.net.poolable.PoolableObjectPool">
<property name="maxActive">200</property>
<property name="maxIdle">200</property>
<property name="minIdle">10</property>
<property name="minEvictableIdleTimeMillis">600000</property>
<property name="timeBetweenEvictionRunsMillis">600000</property>
<property name="testOnBorrow">true</property>
<property name="testWhileIdle">true</property>
</poolConfig>
</dbServer>
<dbServer name="master" virtual="true">
<poolConfig class="com.meidusa.amoeba.server.MultipleServerPool">
<!-- 负载均衡参数 1=ROUNDROBIN , 2=WEIGHTBASED , 3=HA -->
<property name="loadbalance">1</property>
<!-- 参与该pool负载均衡的poolName列表以逗号分割 -->
<property name="poolNames">server1</property>
</poolConfig>
</dbServer>
<dbServer name="slave" virtual="true">
<poolConfig class="com.meidusa.amoeba.server.MultipleServerPool">
<!-- 负载均衡参数 1=ROUNDROBIN , 2=WEIGHTBASED , 3=HA -->
<property name="loadbalance">1</property>
<!-- 参与该pool负载均衡的poolName列表以逗号分割 -->
<property name="poolNames">server1,server2</property>
</poolConfig>
</dbServer>
</dbServerList>
<queryRouter class="com.meidusa.amoeba.mysql.parser.MysqlQueryRouter">
<property name="ruleConfig">${amoeba.home}/conf/rule.xml</property>
<property name="functionConfig">${amoeba.home}/conf/functionMap.xml</property>
<property name="ruleFunctionConfig">${amoeba.home}/conf/ruleFunctionMap.xml</property>
<property name="LRUMapSize">1500</property>
<property name="defaultPool">master</property>
<property name="writePool">master</property>
<property name="readPool">slave</property>
<property name="needParse">true</property>
</queryRouter>
</amoeba:configuration>
Amobea读写分离的更多相关文章
- MySQL+Amoeba实现数据库主从复制和读写分离
MySQL读写分离是在主从复制的基础上进一步通过在master上执行写操作,在slave上执行读操作来实现的.通过主从复制,master上的数据改动能够同步到slave上,从而保持了数据的一致性.实现 ...
- 使用Amoeba实现mysql读写分离机制
Amoeba的实用指南 http://docs.hexnova.com/amoeba/ 如何实现mysql读写分离 : 通常来说有两种方式: 1,应用程序层实现 2,中间件层实现 应用层实现 应用层实 ...
- mybatis plugins实现项目【全局】读写分离
在之前的文章中讲述过数据库主从同步和通过注解来为部分方法切换数据源实现读写分离 注解实现读写分离: http://www.cnblogs.com/xiaochangwei/p/4961807.html ...
- Spring aop应用之实现数据库读写分离
Spring加Mybatis实现MySQL数据库主从读写分离 ,实现的原理是配置了多套数据源,相应的sqlsessionfactory,transactionmanager和事务代理各配置了一套,如果 ...
- J2EE 项目读写分离
先回答下 1.为啥要读写分离? 大家都知道最初开始,一个项目对应一个数据库,基本是一对一的,但是由于后来用户及数据还有访问的急剧增多, 系统在数据的读写上出现了瓶颈,为了让提高效率,想读和写不相互影响 ...
- mysql+mycat搭建稳定高可用集群,负载均衡,主备复制,读写分离
数据库性能优化普遍采用集群方式,oracle集群软硬件投入昂贵,今天花了一天时间搭建基于mysql的集群环境. 主要思路 简单说,实现mysql主备复制-->利用mycat实现负载均衡. 比较了 ...
- Spring 实现数据库读写分离
随着互联网的大型网站系统访问量的增高,数据库访问压力方面不断的显现而出,所以许多公司在数据库层面采用读写分离技术,也就是一个master,多个slave.master负责数据的实时更新或实时查询,而s ...
- Nginx 反向代理、负载均衡、页面缓存、URL重写及读写分离详解
转载:http://freeloda.blog.51cto.com/2033581/1288553 大纲 一.前言 二.环境准备 三.安装与配置Nginx 四.Nginx之反向代理 五.Nginx之负 ...
- SQL Server读写分离实现方案简介
读写分离是中型规模应用的数据库系统常见设计方案,通过将数据从主服务器同步到其他从服务器,提供非实时的查询功能,扩展性能并提高并发性. 数据库的读写分离的好处如下: 通过将“读”操作和“写”操作分离到不 ...
随机推荐
- 浅析ECMP等价路由
1.ECMP简介 Equal-CostMultipathRouting,等价多路径.即存在多条到达同一个目的地址的相同开销的路径.当设备支持等价路由时,发往该目的 IP 或者目的网段的三层转发流量就可 ...
- JS的事件流的概念
事件的概念: HTML中与javascript交互是通过事件驱动来实现的,例如鼠标点击事件.页面的滚动事件onscroll等等,可以向文档或者文档中的元素添加事件侦听器来预订事件.想要知道这些事件是在 ...
- Pymol
如何用Pymol做出那些美呆的结构图(基础篇) 2016-10-31 翾园 摘自 BioEngX生化... 阅 1079 转 6 转藏到我的图书馆 微信分享: 摘自微信公众号:BioE ...
- Django学习---路由url,视图,模板,orm操作
Django请求周期 url -> 路由系统 ->函数或者类 -> 返回字符串 或者 模板语言 Form表单提交: 点击提交 -> 进入url系统 -> 执行函数 ...
- Spring实战之切面编程
如果要重用通用功能的话,最常见的面向对象技术是继承(inheritance)或委托(delegation).但是,如果在整个应用中都使用相同的基类,继承往往会导致一个脆弱的对象体系:而使用委托可能需要 ...
- MySQL批量添加表字段
ALTER TABLE custom ADD contacts2 VARCHAR(50) NOT NULL DEFAULT '' COMMENT '客户联系人2',ADD phone2 VARCHAR ...
- Scanner和BufferReader之区别
在Java SE6中我们可知道一个非常方便的输入数据的类Scanner,位于java.util包中,这个Scanner的具体用法为Scanner in = new Scanner(System.in) ...
- 【312】◀▶ arcpy 常用函数说明
其他常用的 ArcPy 函数说明 序号 类名称 功能说明 语法 & 举例 01 RefreshActiveView ====<<<< Description ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 15—Anomaly Detection异常检测
Lecture 15 Anomaly Detection 异常检测 15.1 异常检测问题的动机 Problem Motivation 异常检测(Anomaly detection)问题是机器学习算法 ...
- Linux实战教学笔记27:Nginx详细讲解
前言:nginx的特点 本节主要对Nginx Web服务软件进行介绍,涉及Nginx的基础,特性,配置部署,优化,以及企业中的日常运维管理和应用.作为HTTP服务软件的后起之秀,Nginx与它的老大哥 ...