分布式ID生成方案
系统唯一ID是设计一个系统的时候常常会遇到的问题,也常常为这个问题而纠结。
生成ID的方法有很多,适应不同的场景、需求以及性能要求。所以有些比较复杂的系统会有多个ID生成的策略。
0. 分布式ID要求
(1)全局唯一性:不能出现重复的ID号,既然是唯一标识,这是最基本的要求;
(2)粗略有序:如果在分布式环境中做到完全有序,需要用到锁等,考虑到性能,采用粗略有序,具体分为秒级有序和毫秒级有序;
(3)可反解:即生成ID服务提供反解方法,这样在存储时就能以十进制存储,省下传统timestamp类字段的占用空间了;
(4)可伸缩:中心发布模式时可以进行集群部署,这样在生成ID里就必须包含机器ID;
(5)趋势递增:在MySQL InnoDB引擎中使用的是聚集索引,由于多数RDBMS使用B-Tree的数据结构来存储索引数据,在主键的选择上我们应该尽量使用有序的主键保证写入性能;
(6)单调递增:保证下一个ID一定大于上一个ID,例如事务版本号,IM增量信息,排序特殊需求;
(7)信息安全:如果ID是连续的,恶意用户的扒取工作就非常容易,直接按照顺序下载指定URL即可,如果是订单号就更危险了
1. 数据库自增长列或字段
针对主库单点,如果有个多个master库,则每个master库设置的起始数字不一样,步长一样(可以使master的个数)。比如:master1生成的是1,4,7,10,master2生成的是2,5,8,11,master3生成的是3,6,9,12。这样就可以有效生成集群中的唯一ID,也可以大大降低ID生成数据库操作的负载。
优点:
(1)最常见的方式,利用数据库,全数据库唯一,简单,代码方便,性能可以接受
(2)数字ID天然排序,对分页或需要排序的结果很有帮助
缺点:
(1)不同数据库语法和实现不同,数据库迁移的时候或多数据库版本支持的时候需要处理
(2)在单个数据库或读写分离或一主多从的情况下,只有一个主库可以生成,有单点故障的风险
(3)在性能达不到要求的情况下,比较难于扩展
(4)如果遇到多个系统需要合并或者涉及到数据迁移会相当痛苦
(5)分表分库的时候有麻烦
2. UUID
优点:
(1)常见的方式,可以利用数据库也可以利用程序生成,一般来说全球唯一,简单,代码方便
(2)生成ID性能非常好,基本不会有性能问题
(3)全球唯一,在遇见数据迁移,系统数据合并或数据库变更等情况下,可以从容应对
缺点:
(1)没有排序,无法保证趋势递增
(2)UUID往往是使用字符串存储,查询的效率比较低
(3)存储空间比较大,如果是海量数据库,就需要存储量的问题
(4)传输数据量大
(5)不可读
3. Redis生成ID
当使用数据库来生成ID性能不够要求的时候,可以尝试用Redis来生成ID。
4. Twitter的snowflake算法
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。其核心思想是:
使用41bit作为毫秒数
10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID)
12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生4096个ID)
最后还有一个符号位,永远是0。
https://github.com/twitter/snowflake
优点:
(1)不依赖数据库,灵活方便,且性能优于数据库
(2)ID按照时间在单机上是递增的
缺点:
(1)在单机上是递增的,但是由于涉及到分布式环境中,每台机器上的时钟不可能完全同步,也许有时候也会出现不是全局递增的情况。
5. 利用zookeeper生成唯一ID
zookeeper主要通过其znode数据版本来生成序列号,可以生成32位和64位的数据版本号,客户端可以使用这个版本号来作为唯一的序列号。
很少会使用zookeeper来生成唯一ID,主要是由于依赖zookeeper,并且是多步调用API,如果在竞争较大的情况下,需要考虑使用分布式锁。因此,性能在高并发的分布式环境中,也不甚理想。
6. MongoDB的ObjectId
MongoDB的ObjectId和snowflake算法类似。它涉及成轻量级,不同的机器都能用全局唯一的同种方法方便地生成它。MongoDB从一开始就设计用来作为分布式数据库,处理多个节点是一个核心要求,使其在分布式环境中要容易生成得多。
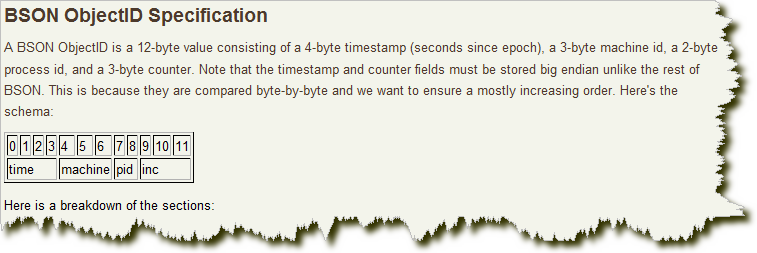
前4个字节是从标准纪元开始的时间戳,单位是秒。时间戳和随后的5个字节组合起来,提供了秒级别的唯一性。由于时间戳在前,意味着ObjectId大致会按照插入的顺序排列。这对于某些方面很有用,如将其作为索引提高效率。这4个字节也隐含了文档创建时间。绝大多数客户端类库都会公开一个方法从ObjectId获取这个信息。
接下来3字节是所在主机的唯一标识符。通常是主机名的散列值,这样就可以确保不同主机生成不同的ObjectId,不产生冲突。
接下来2个字节来自产生ObjectId的进程标识符(PID),为了确保在同一台机器上并发的多个进程产生的ObjectId是唯一的。
前9字节保证了同一秒中不同机器不同进程产生的ObjectId是唯一的,后3字节就是一个自动增加的计数器,确保相同进程同一秒产生的ObjectId也是不一样的。同一秒钟最多允许每个进程拥有16777216个不同的ObjectId。
7. 单点批量ID生成服务
分布式系统之所以难,很重要的原因之一是“没有一个全局时钟,难以保证绝对的时序”,要想保证绝对的时序,还是只能使用单点服务,用本地时钟保证“绝对时序”。数据库写压力大,是因为每次生成ID都访问了数据库,可以使用批量的方式降低数据库写压力。
数据库中只存储当前ID的最大值,例如0。ID生成服务假设每次批量拉取6个ID,服务访问数据库,将当前ID的最大值修改为5,这样应用访问ID生成服务索要ID,ID生成服务不需要每次访问数据库,就能依次派发0,1,2,3,4,5这些ID了,当ID发完后,再将ID的最大值修改为11,就能再次派发6,7,8,9,10,11这些ID了,于是数据库的压力就降低到原来的1/6了。
优点:
(1)保证了ID生成的绝对递增有序
(2)大大的降低了数据库的压力,ID生成可以做到每秒生成几万几十万个
缺点:
(1)服务仍然是单点
(2)如果服务挂了,服务重启起来之后,继续生成ID可能会不连续,中间出现空洞(服务内存是保存着0,1,2,3,4,5,数据库中max-id是5,分配到3时,服务重启了,下次会从6开始分配,4和5就成了空洞,不过这个问题也不大)
(3)虽然每秒可以生成几万几十万个ID,但毕竟还是有性能上限,无法进行水平扩展
改进方法:
单点服务的常用高可用优化方案是“备用服务”,也叫“影子服务”,所以我们能用以下方法优化上述缺点(1)。对外提供的服务是主服务,有一个影子服务时刻处于备用状态,当主服务挂了的时候影子服务顶上。这个切换的过程对调用方是透明的,可以自动完成,常用的技术是vip+keepalived,具体就不在这里展开。
参考资料:
https://www.cnblogs.com/haoxinyue/p/5208136.html
https://tech.meituan.com/MT_Leaf.html
分布式ID生成方案的更多相关文章
- 一种基于Orleans的分布式Id生成方案
基于Orleans的分布式Id生成方案,因Orleans的单实例.单线程模型,让这种实现变的简单,贴出一种实现,欢迎大家提出意见 public interface ISequenceNoGenerat ...
- 搞懂分布式技术12:分布式ID生成方案
搞懂分布式技术12:分布式ID生成方案 ## 转自: 58沈剑 架构师之路 2017-06-25 一.需求缘起 几乎所有的业务系统,都有生成一个唯一记录标识的需求,例如: 消息标识:message-i ...
- 分布式id生成方案总结
本文已经收录自 JavaGuide (60k+ Star[Java学习+面试指南] 一份涵盖大部分Java程序员所需要掌握的核心知识.) 本文授权转载自:https://juejin.im/post/ ...
- 分布式ID生成方案总结整理
目录 1.为什么需要分布式ID? 2.业务系统对分布式ID有什么要求? 3.分布式ID生成方案 3.1 UUID 3.2.数据库自增 3.3.号段模式 3.4. Redis实现 3.4. 雪花算法(S ...
- 分布式ID生成方案汇总
1.目标 1.1.全局唯一 不能出现重复的ID,全局唯一是最基本的要求. 1.2.趋势有序 业务上分页查询需求,排序需求,如果ID直接有序,则不必建立更多的索引,增加查询条件. 而且Mysql Inn ...
- 分布式ID详解(5种分布式ID生成方案)
分布式架构会涉及到分布式全局唯一ID的生成,今天我就来详解分布式全局唯一ID,以及分布式全局唯一ID的实现方案@mikechen 什么是分布式系统唯一ID 在复杂分布式系统中,往往需要对大量的数据和消 ...
- 分布式唯一ID生成方案是什么样的?(转)
一.前言 分布式系统中我们会对一些数据量大的业务进行分拆,如:用户表,订单表.因为数据量巨大一张表无法承接,就会对其进行分库分表. 但一旦涉及到分库分表,就会引申出分布式系统中唯一主键ID的生成问题, ...
- 一线大厂的分布式唯一ID生成方案是什么样的?
本人免费整理了Java高级资料,涵盖了Java.Redis.MongoDB.MySQL.Zookeeper.Spring Cloud.Dubbo高并发分布式等教程,一共30G,需要自己领取.传送门:h ...
- 分库分表的 9种分布式主键ID 生成方案,挺全乎的
<sharding-jdbc 分库分表的 4种分片策略> 中我们介绍了 sharding-jdbc 4种分片策略的使用场景,可以满足基础的分片功能开发,这篇我们来看看分库分表后,应该如何为 ...
随机推荐
- Appium+python自动化14-查看webview上元素(DevTools)
前言 app上webview的页面实际上是启用的chrome浏览器的内核加载的,如何把手机的网页加载到电脑上,电脑的chrome浏览器上有个开发模式DevTools,是可以方便调试的. 一.环境准备 ...
- 负载均衡---在window与linux下配置nginx
最近有些时间,开始接触负载均衡方面的东西,从硬件F5再到Citrix Netscalar.不过因为硬件的配置虽然不复杂,但昂贵的价格也让一般用户望而却步(十几万到几十万),所以只能转向nginx,sq ...
- [Linux] ubuntu server sudo出现sudo:must be setuid root 完美解决办法
1.开机按shift或esc先进行recovery模式 2.选择root命令行模式 3.先执行 #mount -o remount,rw / 这个很重要,网上找的很多资料都不全没有这步造成无法恢复成功 ...
- 嵌入式mp3播放器
分四部分:按键驱动,声卡驱动,Madplay播放器移植,MP3主播放器处理 按键1:播放,按键2:停止,按键3:上一曲,按键4:下一曲 UA1341内核自带声卡驱动 .解压内核: tar zxvf l ...
- iOS:三种数据库的小总结
三种数据库总结:sqlite.FMDB.CoreData 1.sqlite数据库(C语言)需要方法和属性: (1)数据类型: –INTEGER 有符号的整数类型 –REAL 浮点类型 –TEXT ...
- django单表操作 增 删 改 查
一.实现:增.删.改.查 1.获取所有数据显示在页面上 model.Classes.object.all(),拿到数据后,渲染给前端;前端通过for循环的方式,取出数据. 目的:通过classes(班 ...
- ASP.Net生成静态HTML页
动态网页开发技术中,为了降低网站维护的工作量,常常用到动态页面技术.目前因特网上流行的做法是将网站中需要经常更新的数据存放到数据库中,当客户端浏览器向服务器发出HTTP请求时,服务器通过执行.解释某个 ...
- (转)一个非常好的akka教程
akka系列文章目录 akka学习教程(十四) akka分布式实战 akka学习教程(十三) akka分布式 akka学习教程(十二) Spring与Akka的集成 akka学习教程(十一) akka ...
- [RSpec] LEVEL 1: INTRODUCTION
Install RSpec: Describe Lets start writing a specification for the Tweet class. Write a describe blo ...
- UDP Sockets in C#
UDP provides an end-to-end service different from that of TCP. In fact, UDP performs only two functi ...