linux页缓存
2017-04-25
本节就聊聊页缓存这个东西……
一、概述
页缓存是一个相对独立的概念,其根本目的是为了加速对后端设备的IO效率,比如文件的读写。页缓存顾名思义是以页为单位的,目前我能想到的在两个地方页缓存的作用比较明显。1、在文件的读写中。2、在普通进程的匿名映射区操作中。在文件的读写中,进程对一个文件发起读请求,如果没哟对应的物理内存页,则内核处理程序首先在页缓存中查找,如果找到直接返回。如果没找到,那么再分配空间,把内容从文件读入内存,插入页缓存,并返回,这里读操作虽然是一个页面发生的未命中,但是很大程度上会读取多个连续页面到内存中,只不过返回调用指定页面,因为实际情况中,很少仅仅需要读取一个页面,这样后续如果在需要访问还是需要进行磁盘IO,磁盘寻道时间往往比读取时间还要长,为了提高IO效率,就有了上述的预读机制。。2、在普通进程的匿名映射中,比如进程申请的比较大的堆空间(大于128kb的都是利用MMAP映射的),这些空间的内容如果在一段时间内没被释放 且在一段时间内没被访问,则有可能被系统内存管理器交换到外存以腾出更多的物理内存空间。下次在进程访问该内容,根据页表查找发现物理页面不在内存,则需要调用缺页异常处理程序。异常处理程序判断该页时被换出到外存,那么首先也是在页缓存中找,如果找到就返回;否则,从交换分区或者交换文件中把对应的文件读入内存。这里所说的页缓存和1中描述的页缓存是一类缓存,但是并不是一个,1中的页缓存是文件系统相关的,在磁盘上对应着具体的文件;在页面回收的时候需要回写到磁盘即同步一下;而2中的页缓存其实是一种交换缓存,在页面回收的时候只能是换出到交换分区或者交换文件,不存在同步的操作。
二、管理结构描述
还记得之前在分析文件系统的时候,发现inode结构中有个address_space字段,每个文件关键一个address_space, 该结构管理文件映射的所有物理页面。在其中有个radix_tree_root字段,表示基数树的根即radix tree.页缓存正是通过这种数据结构管理的。
struct radix_tree_root {
unsigned int height;
gfp_t gfp_mask;
struct radix_tree_node __rcu *rnode;
};
结构比较简单,height表示树的高度;gfp_mask记录了从哪个内存域分配内存;rnode表示树的节点,不过树的根和节点是不同的数据结构,节点是radix_tree_node
struct radix_tree_node {
unsigned int height; /* Height from the bottom */
unsigned int count;
union {
struct radix_tree_node *parent; /* Used when ascending tree */
struct rcu_head rcu_head; /* Used when freeing node */
};
void __rcu *slots[RADIX_TREE_MAP_SIZE];
unsigned long tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS];
};
height表示该节点到树根的高度,count表示节点中已经使用的数组项的数目;slots是一个指向一个数组的指针,数组中每一项都可以是叶子节点或者中间节点。叶子节点一般就是page结构,而中间节点仍然是node节点。tags是一个二维数组,表示该节点的可能关联的页的属性,主要有下面几个
#define PAGECACHE_TAG_DIRTY 0 页当前是脏的
#define PAGECACHE_TAG_WRITEBACK 1 页当前正在回写
#define PAGECACHE_TAG_TOWRITE 2
每个node关联的slots数组有RADIX_TREE_MAP_SIZE个表项,tags二维数组是一个RADIX_TREE_MAX_TAGS行、RADIX_TREE_TAG_LONGS列的数组。
#ifdef __KERNEL__
#define RADIX_TREE_MAP_SHIFT (CONFIG_BASE_SMALL ? 4 : 6)
#else
#define RADIX_TREE_MAP_SHIFT 3 /* For more stressful testing */
#endif
#define RADIX_TREE_MAP_SIZE (1UL << RADIX_TREE_MAP_SHIFT)
#define RADIX_TREE_MAX_TAGS 3
#define RADIX_TREE_TAG_LONGS ((RADIX_TREE_MAP_SIZE + BITS_PER_LONG - 1) / BITS_PER_LONG)
根据上述信息,RADIX_TREE_MAP_SHIFT多数指的4或者6,即RADIX_TREE_MAP_SIZE基本上是16或者64。不过我们这里为了方便介绍,取RADIX_TREE_MAP_SHIFT为3,即RADIX_TREE_MAP_SIZE为8.
这里虽然也是树状结构,但是其相对于二叉树或者三叉树就随意多了,可以认为仅仅是广义上的树。下面以向缓存中添加一个页为例,介绍下整个处理流程。
/*
* Per-cpu pool of preloaded nodes
*/
struct radix_tree_preload {
int nr;
struct radix_tree_node *nodes[RADIX_TREE_PRELOAD_SIZE];
};
起始函数为static inline int add_to_page_cache(struct page *page,struct address_space *mapping, pgoff_t offset, gfp_t gfp_mask),该函数锁定了页面之后就调用了add_to_page_cache_locked函数。
int add_to_page_cache_locked(struct page *page, struct address_space *mapping,
pgoff_t offset, gfp_t gfp_mask)
{
int error; VM_BUG_ON(!PageLocked(page));
VM_BUG_ON(PageSwapBacked(page)); error = mem_cgroup_cache_charge(page, current->mm,
gfp_mask & GFP_RECLAIM_MASK);
if (error)
goto out; error = radix_tree_preload(gfp_mask & ~__GFP_HIGHMEM);
if (error == ) {
page_cache_get(page);
page->mapping = mapping;
page->index = offset; spin_lock_irq(&mapping->tree_lock);
error = radix_tree_insert(&mapping->page_tree, offset, page);
if (likely(!error)) {
mapping->nrpages++;
__inc_zone_page_state(page, NR_FILE_PAGES);
spin_unlock_irq(&mapping->tree_lock);
trace_mm_filemap_add_to_page_cache(page);
} else {
page->mapping = NULL;
/* Leave page->index set: truncation relies upon it */
spin_unlock_irq(&mapping->tree_lock);
mem_cgroup_uncharge_cache_page(page);
page_cache_release(page);
}
radix_tree_preload_end();
} else
mem_cgroup_uncharge_cache_page(page);
out:
return error;
}
该函数中首先进行的是cgroup统计,这点不是本文重点,忽略。然后调用了radix_tree_preload函数,该函数检查CPU的radix_tree_node 缓存池是否充足,如果不充足就填充,正常情况是返回0的。进入if判断,首先对page结构做些设置,然后获取了mapping->tree_lock自旋锁。保证操作的一致性。调用radix_tree_insert函数把page插入到mapping->page_tree指向的radix树中。如果插入成功,返回0。插入成功后增加mapping page数目,释放锁。否则插入失败就对page进行释放。释放其实就是减少引用,等下次内存管理器扫描空闲内存时对其进行回收。发现最后还调用了下page_cache_release函数,该函数仅仅实现了启用抢占的功能,在radix_tree_preload函数中禁用了内核抢占。
现在我们自己说说radix_tree_insert函数
int radix_tree_insert(struct radix_tree_root *root,
unsigned long index, void *item)
{
struct radix_tree_node *node = NULL, *slot;
unsigned int height, shift;
int offset;
int error; BUG_ON(radix_tree_is_indirect_ptr(item)); /* Make sure the tree is high enough. */
if (index > radix_tree_maxindex(root->height)) {
/*尝试扩展树,以满足条件*/
error = radix_tree_extend(root, index);
if (error)
return error;
}
/*radix_tree_node最低一位表示是间接指针还是直接指针*/
slot = indirect_to_ptr(root->rnode); height = root->height;
//RADIX_TREE_MAP_SHIFT 3
shift = (height-) * RADIX_TREE_MAP_SHIFT; offset = ; /* uninitialised var warning */
while (height > ) {
if (slot == NULL) {//需要扩充树
/* Have to add a child node. */
if (!(slot = radix_tree_node_alloc(root)))
return -ENOMEM;
slot->height = height;
slot->parent = node;
if (node) {
rcu_assign_pointer(node->slots[offset], slot);
node->count++;
} else
rcu_assign_pointer(root->rnode, ptr_to_indirect(slot));
} /* Go a level down */
offset = (index >> shift) & RADIX_TREE_MAP_MASK;
node = slot;
slot = node->slots[offset];
shift -= RADIX_TREE_MAP_SHIFT;
height--;
} if (slot != NULL)
return -EEXIST; if (node) {
node->count++;//增加计数
rcu_assign_pointer(node->slots[offset], item);//设置指向
BUG_ON(tag_get(node, , offset));
BUG_ON(tag_get(node, , offset));
} else {
rcu_assign_pointer(root->rnode, item);
BUG_ON(root_tag_get(root, ));
BUG_ON(root_tag_get(root, ));
} return ;
}
函数包含三个参数,radix树的根,插入的位置索引,插入项目的指针,以插入page来讲,这里就是指向page结构的指针。radix_tree_node地址的最后一位表示该node连接的是node还是item。如果为1表明连接的还是node。潜意识里不管是node还是item,其地址都至少应该是2字节对齐的。函数首先对item进行了验证,看是否是二字节对齐的。然后判断index是否超过了当前树容纳的最大索引。最大值可以由树高确定,如果index超过了最大额度,则调用radix_tree_extend函数尝试扩展树,扩展失败就返回错误,关于这点最后会详细介绍。通过这里的判断,就获取树根指向的首个radix_tree_node。树高height,位置偏移shift。进入while循环,条件是height大于0.循环中首先判断slot==NULL,意味着根据height还没遍历到末尾,已经没有中间节点了,所以这就需要重新分配孩子节点,直到height减小到0;相反,如果一切顺利,就一层一层往下寻找,直到height=0;此时node为最终找到的radix_tree_node,offset为在node数组中的下标,接下来就可以设置指向了。下面以三层的radix tree为例,走下这个流程,如图所示
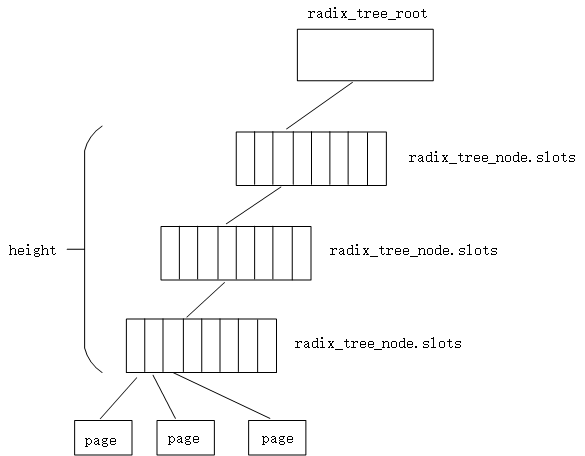
咱们不考虑根据height定位node遇到中间节点为NULL的情况。图中初始状态,slot为root->rnode;height=3;shift=6;循环里面执行如下图

出了循环,node应该就是最终定位的radix_tree_node节点,根据偏移项offset,可定位具体的项目。注意这里如图中所说,此时slot是L1层的节点指针,如果slot不为NULL,则表示index对应的slot已经有了映射页面,不需要再次添加物理页面了,否则把item设置到node->slots[offset],并增加node的使用项目计数。前思后想还是没想到node为NULL的情况,如果有知道的朋友可以说明下,谢谢!
下面看下验证index是否在树中的函数,系统用一个数组height_to_maxindex记录height对应的maxindex,看下参考代码
static __init void radix_tree_init_maxindex(void)
{
unsigned int i; for (i = ; i < ARRAY_SIZE(height_to_maxindex); i++)
height_to_maxindex[i] = __maxindex(i);
} static __init unsigned long __maxindex(unsigned int height)
{
unsigned int width = height * RADIX_TREE_MAP_SHIFT;
int shift = RADIX_TREE_INDEX_BITS - width; if (shift < )
return ~0UL;
if (shift >= BITS_PER_LONG)
return 0UL;
return ~0UL >> shift;
}
#define RADIX_TREE_INDEX_BITS (8 /* CHAR_BIT */ * sizeof(unsigned long))
后者是初始化该数组的代码,关键在于前两行,还是按照前面的约定,RADIX_TREE_MAP_SHIFT看做3,后者根体系结构相关,31位下unsigned long是4个字节,RADIX_TREE_INDEX_BITS 为32。最后通过把全1右移得到结果,很是巧妙。还是按照三层来算

下面看扩展radix树的函数radix_tree_extend
static int radix_tree_extend(struct radix_tree_root *root, unsigned long index)
{
struct radix_tree_node *node;
struct radix_tree_node *slot;
unsigned int height;
int tag; /* Figure out what the height should be. */
height = root->height + ;
while (index > radix_tree_maxindex(height))
height++; if (root->rnode == NULL) {
root->height = height;
goto out;
} do {
unsigned int newheight;
if (!(node = radix_tree_node_alloc(root)))
return -ENOMEM; /* Propagate the aggregated tag info into the new root */
for (tag = ; tag < RADIX_TREE_MAX_TAGS; tag++) {
if (root_tag_get(root, tag))
tag_set(node, tag, );
} /* Increase the height. */
newheight = root->height+;
node->height = newheight;//从底部开始计算的高度
node->count = ;
node->parent = NULL;
slot = root->rnode;
if (newheight > ) {
slot = indirect_to_ptr(slot);
slot->parent = node;
}
node->slots[] = slot;
node = ptr_to_indirect(node);
rcu_assign_pointer(root->rnode, node);
root->height = newheight;
} while (height > root->height);
out:
return ;
}
该函数实现逻辑挺简单,首先尝试height+1,如果不能还不能满足条件,持续对height++,直到满足条件。接下来就是一个循环,以height>root->height为条件。所以这里实际上是填充指定height到root->height路径上空缺的节点。具体的填充过程没什么好讲的,只是注意这里的插入实际上类似于链表的头插法,即每次都从根节点插入。且节点的height是从下往上计算的。还有一点就是填充虽然达到了指定的高度,但是并不是填充了所有路径的节点,即并没有形成满树,仅仅是单条路径。因此在根据index插入item的时候,很有可能遇见路径上的节点为NULL,那么就需要重新填充、。
radix树的组织方式基本就是这样,其他的操作很类似就不在重复介绍。
参考:
linux 3.10.1源码
http://blog.csdn.net/joker0910/article/details/8250085
linux页缓存的更多相关文章
- Linux页快速缓存与回写机制分析
參考 <Linux内核设计与实现> ******************************************* 页快速缓存是linux内核实现的一种主要磁盘缓存,它主要用来降低 ...
- Linux内核入门到放弃-页缓存和块缓存-《深入Linux内核架构》笔记
内核为块设备提供了两种通用的缓存方案. 页缓存(page cache) 块缓存(buffer cache) 页缓存的结构 在页缓存中搜索一页所花费的时间必须最小化,以确保缓存失效的代价尽可能低廉,因为 ...
- linux 中的页缓存和文件 IO
本文所述是针对 linux 引入了虚拟内存管理机制以后所涉及的知识点.linux 中页缓存的本质就是对于磁盘中的部分数据在内存中保留一定的副本,使得应用程序能够快速的读取到磁盘中相应的数据,并实现不同 ...
- 工作于内存和文件之间的页缓存, Page Cache, the Affair Between Memory and Files
原文作者:Gustavo Duarte 原文地址:http://duartes.org/gustavo/blog/post/what-your-computer-does-while-you-wait ...
- linux清除缓存
linux清除缓存:需要root权限$ sync$ echo 3 >/proc/sys/vm/drop_caches 上面的echo 3 是清理所有缓存 echo 0 是不释放缓存 echo 1 ...
- Linux 文件缓存 (一)
缓存印象 缓存给人的感觉就是可以提高程序运行速度,比如在桌面环境中,第一次打开一个大型程序可能需要10秒,但是关闭程序后再次打开可能只需5秒了.这是因为运行程序需要的代码.数据文件在操作系统中得到了缓 ...
- Linux 文件系统缓存dirty_ratio与dirty_background_ratio两个参数区别
文件系统缓存dirty_ratio与dirty_background_ratio两个参数区别 (2014-03-16 17:54:32) 转载▼ 标签: linux 文件系统缓存 cache dirt ...
- linux清理缓存cache
Linux服务器有自己先进的内存管理机制,有时候会发现我们系统的buff/cache内存占用会越来越高,操作系统也有卡顿的情况,遇到这种情况,不妨试试下面的方法. 步骤一:我们先使用free -m查看 ...
- Linux ARP缓存配置和状态查看命令
查看Linux ARP缓存老化时间 cat /proc/sys/net/ipv4/neigh/eth0/base_reachable_time同目录下还有一个文件gc_stale_time,官方解释如 ...
随机推荐
- json中把非json格式的字符串转换成json对象再转换成json字符串
JSON.toJson(str).toString()假如key和value都是整数的时候,先转换成jsonObject对象,再转换成json字符串
- cocos2dx对所有子节点设置透明度
看到cocos2dx2.2.5发布了,修复了输入框的bug,于是我们的项目也升级到了2.2.5, 升级过程还是比较顺利,没想到后来发现设置透明度无效了. 经过调试发现要调用一下setCascadeOp ...
- https 单向双向认证说明_数字证书, 数字签名, SSL(TLS) , SASL_转
转自:https 单向双向认证说明_数字证书, 数字签名, SSL(TLS) , SASL 因为项目中要用到TLS + SASL 来做安全认证层. 所以看了一些网上的资料, 这里做一个总结. 1. 首 ...
- Java编译后产生class文件的命名规则
今天刚好有同学问了下Java编译后产生的.class文件名的问题,虽然一直都在使用Java做开发,但是之前对编译后产生的.class文件名的规范也基本没做了解过,也真的是忏愧啊!今天无论如何都要总结下 ...
- 关于Unity中的几何体,材质和FBX模型
一.创建几何体的类型 1: 创建平面 Plane;2: 创建立方体 Cube;3: 创建球体 Sphere;4: 创建胶囊体 Capsule;5: 创建圆柱体 Cylinder;6: 3D文字 3D ...
- Merging an upstream repository into your fork
1. Check out the branch you wish to merge to. Usually, you will merge into master. $ git checkout ma ...
- COCOS2D-X多层单点触摸分发处理方案?
如今的问题是点击button的时候,会触发底层的触摸事件,怎么不触发底层的触摸事件啊?
- python_cookies
1.将cookies保存到变量中,然后打印cookie中的值 #coding:utf-8 #将cookies保存到变量中,然后打印cookie中的值 import urllib2 import coo ...
- Using XSLT and Open XML to Create a Word 2007 Document
Summary: Learn how to transform XML data into a Word 2007 document by starting with an existing docu ...
- ASP.NET MVC5 新特性:Attribute路由使用详解
1.什么是Attribute路由?怎么样启用Attribute路由? 微软在 ASP.NET MVC5 中引入了一种新型路由:Attribute路由,顾名思义,Attribute路由是通过Attrib ...