【sklearn】网格搜索 from sklearn.model_selection import GridSearchCV
GridSearchCV用于系统地遍历模型的多种参数组合,通过交叉验证确定最佳参数。
1.GridSearchCV参数
# 不常用的参数
- pre_dispatch
没看懂
- refit
- 默认为True
- 在参数搜索参数后,用最佳参数的结果fit一遍全部数据集
- iid
- 默认为True
- 各个样本fold概率分布一致,误差估计为所有样本之和
# 常用的参数
- cv
- 默认为3
- 指定fold个数,即默认三折交叉验证
- verbose
- 默认为0
- 值为0时,不输出训练过程;值为1时,偶尔输出训练过程;值>1时,对每个子模型都输出训练过程
- n_jobs
- cpu个数
- 值为-1时,使用全部CPU;值为1时,使用1个CPU;值为2时,使用2个CPU
- estimator
- 分类器
- param_grid
- 参数范围,值为列表/字典
- scoring
- 准确度评价标准,socring参数选择链接
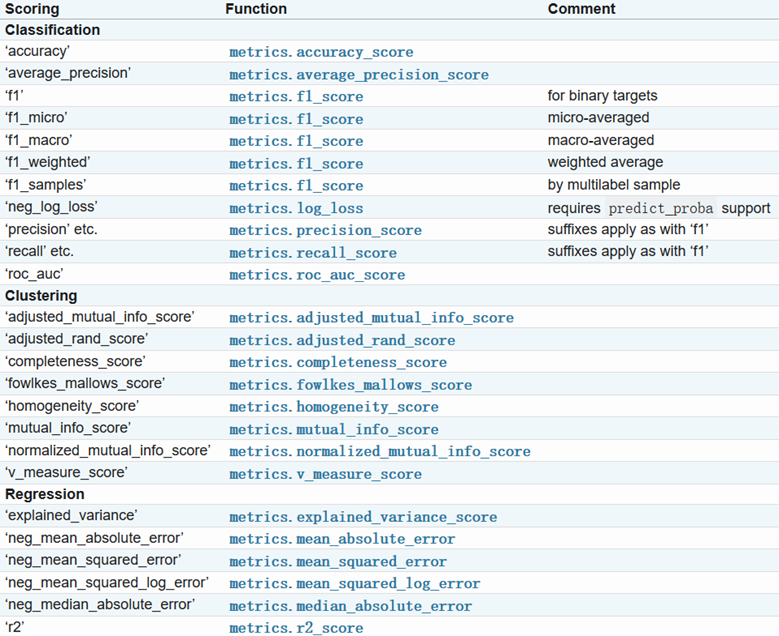
2.常用属性
- best_score_
- 最佳模型下的分数
- best_params_
- 最佳模型参数
- grid_scores_
- 模型不同参数下交叉验证的平均分
- cv_results_ 具体用法
- 模型不同参数下交叉验证的结果
- best_estimator_
- 最佳分类器
注:grid_scores_在sklearn0.20版本中将被删除。使用cv_results_替代
3.常用函数
- score(x_test,y_test)
- 最佳模型在测试集下的分数
4.例子
1 # -*- coding: utf-8 -*-
2 """
3 # 数据:20类新闻文本
4 # 模型:svc
5 # 调参:gridsearch
6 """
7 ### 加载模块
8 import numpy as np
9 import pandas as pd
10
11 ### 载入数据
12 from sklearn.datasets import fetch_20newsgroups # 20类新闻数据
13 news = fetch_20newsgroups(subset='all') # 生成20类新闻数据
14
15 ### 数据分割
16 from sklearn.cross_validation import train_test_split
17 X_train, X_test, y_train, y_test = train_test_split(news.data[:300],
18 news.target[:300],
19 test_size=0.25, # 测试集占比25%
20 random_state=33) # 随机数
21 ### pipe-line
22 from sklearn.feature_extraction.text import TfidfVectorizer # 特征提取
23 from sklearn.svm import SVC # 载入模型
24 from sklearn.pipeline import Pipeline # pipe_line模式
25 clf = Pipeline([('vect', TfidfVectorizer(stop_words='english', analyzer='word')),
26 ('svc', SVC())])
27
28 ### 网格搜索
29 from sklearn.model_selection import GridSearchCV
30 parameters = {'svc__gamma': np.logspace(-1, 1)} # 参数范围(字典类型)
31
32 gs = GridSearchCV(clf, # 模型
33 parameters, # 参数字典
34 n_jobs=1, # 使用1个cpu
35 verbose=0, # 不打印中间过程
36 cv=5) # 5折交叉验证
37
38 gs.fit(X_train, y_train) # 在训练集上进行网格搜索
39
40 ### 最佳参数在测试集上模型分数
41 print("best:%f using %s" % (gs.best_score_,gs.best_params_))
42
43 ### 测试集下的分数
44 print("test datasets score" % gs.score(X_test, y_test))
45
46 ### 模型不同参数下的分数
47 # 方式一(0.20版本将删除)
48 print(gs.grid_scores_)
49
50 # 方式二(0.20推荐的方式)
51 means = gs.cv_results_['mean_test_score']
52 params = gs.cv_results_['params']
53
54 for mean, param in zip(means,params):
55 print("%f with: %r" % (mean,param))
【sklearn】网格搜索 from sklearn.model_selection import GridSearchCV的更多相关文章
- 机器学习笔记——模型调参利器 GridSearchCV(网格搜索)参数的说明
GridSearchCV,它存在的意义就是自动调参,只要把参数输进去,就能给出最优化的结果和参数.但是这个方法适合于小数据集,一旦数据的量级上去了,很难得出结果.这个时候就是需要动脑筋了.数据量比较大 ...
- GridSearchCV网格搜索得到最佳超参数, 在K近邻算法中的应用
最近在学习机器学习中的K近邻算法, KNeighborsClassifier 看似简单实则里面有很多的参数配置, 这些参数直接影响到预测的准确率. 很自然的问题就是如何找到最优参数配置? 这就需要用到 ...
- 使用GridSearchCV进行网格搜索微调模型
import numpy as np import pandas as pd from sklearn.feature_extraction.text import TfidfVectorizer f ...
- 调参必备---GridSearch网格搜索
什么是Grid Search 网格搜索? Grid Search:一种调参手段:穷举搜索:在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果.其原理就像是在数组里找最 ...
- 机器学习:使用scikit-learn库中的网格搜索调参
一.scikit-learn库中的网格搜索调参 1)网格搜索的目的: 找到最佳分类器及其参数: 2)网格搜索的步骤: 得到原始数据 切分原始数据 创建/调用机器学习算法对象 调用并实例化scikit- ...
- Python机器学习笔记 Grid SearchCV(网格搜索)
在机器学习模型中,需要人工选择的参数称为超参数.比如随机森林中决策树的个数,人工神经网络模型中隐藏层层数和每层的节点个数,正则项中常数大小等等,他们都需要事先指定.超参数选择不恰当,就会出现欠拟合或者 ...
- 网格搜索与K近邻中更多的超参数
目录 网格搜索与K近邻中更多的超参数 一.knn网格搜索超参寻优 二.更多距离的定义 1.向量空间余弦相似度 2.调整余弦相似度 3.皮尔森相关系数 4.杰卡德相似系数 网格搜索与K近邻中更多的超参数 ...
- 机器学习算法中的网格搜索GridSearch实现(以k-近邻算法参数寻最优为例)
机器学习算法参数的网格搜索实现: //2019.08.031.scikitlearn库中调用网格搜索的方法为:Grid search,它的搜索方式比较统一简单,其对于算法批判的标准比较复杂,是一种复合 ...
- 【笔记】KNN之网格搜索与k近邻算法中更多超参数
网格搜索与k近邻算法中更多超参数 网格搜索与k近邻算法中更多超参数 网络搜索 前笔记中使用的for循环进行的网格搜索的方式,我们可以发现不同的超参数之间是存在一种依赖关系的,像是p这个超参数,只有在 ...
随机推荐
- 数据结构实习 Problem H 迷宫的最短路径
数据结构实习 Problem H 迷宫的最短路径 题目描述 设计一个算法找一条从迷宫入口到出口的最短路径. 输入 迷宫的行和列m n 迷宫的布局 输出 最短路径 样例输入 6 8 0 1 1 1 0 ...
- linux:将job放在后台执行的方法
本文转自http://www.ibm.com/developerworks/cn/linux/l-cn-nohup/ 我自己在工作需要远程连到公司的开发机,在开发机上运行程序时,一旦退出终端就会导致运 ...
- Moment.js的一些用法
前记:项目开发用到了日历插件(Pikaday.js),同时也用到了Moment.js(日期处理类库) 1.subtract:减去,下面代码的意思是减去1天 this.yestdayStr = mome ...
- 安装 inotify-tools
摘要 inotify-tools, 是一款google出的用于监控文件系统的软件. 一.软件下载地址官方站点地址:http://inotify-tools.sourceforge.net/仓库地址:h ...
- Entity Framework教程及文章传送门
Entity Framework视频教程http://www.iqiyi.com/playlist296844502.html Model-Code First做法講解與教學 (ASP.net MVC ...
- 对于"第一次创业者"应该给什么样的建议
转:其实我创业也不是很成功(目前属于第二次).目前为止,基本保证家里足够温饱和足够温馨,偶尔奢侈,但是我坚持走技术路线,不做土豪(因为做不了). 我创业的口号是:成全别人,累死自己!! 有人问 ...
- 24.Java中atomic包中的原子操作类总结
1. 原子操作类介绍 在并发编程中很容易出现并发安全的问题,有一个很简单的例子就是多线程更新变量i=1,比如多个线程执行i++操作,就有可能获取不到正确的值,而这个问题,最常用的方法是通过Synchr ...
- 第七天 Linux用户管理、RHEL6.5及RHEL7.2 root密码破解、RHEL6.5安装vmware tools
1.Linux用户管理 Linux系统中,存在三种用户 A.超级用户:root 最高权限,至高无上 在windows中 administrator是可以登录的最高权限,但是,system权限最高,不能 ...
- HDU 5699 二分+线性约束
http://acm.hdu.edu.cn/showproblem.php?pid=5699 此题满足二分性质,关键在于如何判断当前的时间值可以满足所有的运送方案中的最长的时间. 对于每一次枚举出的k ...
- Matlab 一些函数
max(A,[],dim):dim取1或2.dim取1时,该函数和max(A)完全相同:dim取2时,该函数返回一个列向量,其第i个元素是A矩阵的第i行上的最大值.