python正则元字符的含义
练习的时候使用linux+ipython,ipython安装
python的元字符
# 元字符 :
# . ^ $ * + ? {} [] \ | ()

注:\w还可以匹配下划线和汉字
[ab\d]表示只要匹配该集合中的任一一个表达式都OK
注意并不是按照集合的顺序来匹配的。而是返回第一个符合条件的字符串


注:^$匹配的是行首和行尾, \A\Z匹配的是字符串的首尾【没整没明白】

*? +? ??
首先明确一点,他们必须结合左右的正则进行匹配,左边必须有内容,右边可以没有,即为''
?? =(匹配字符1?)?匹配字符2, 字符1{0,1}+字符2, 字符1出现次数<=1,字符2出现次数>=1
In [149]: re.match(r'\w??\d','123wer123') # 第一个\d即数字之前,\w匹配最少可以一次都不匹配,返回第一个数字
Out[149]: <re.Match object; span=(0, 1), match=''> In [150]: re.match(r'\w??\d','w123wer123') # 第一个\d数字之前,\w最少可以只匹配一次,返回一个字母+第一个数字
Out[150]: <re.Match object; span=(0, 2), match='w1'> In [151]: re.match(r'\w??\d','wx123wer123') # 第一个\d数字之前,\w最少会匹配超过一次,最终匹配失败,返回None In [152]: re.match(r'\w??\d','wxwer') #\d没匹配到,所以最终匹配失败,返回None In [153]: re.match(r'\w??','wxwer') # 在第一个''之前,\w最少可以只匹配0次,最多匹配1次, 非贪婪模式选择最少匹配次数,\w匹配0次,所以返回''
Out[153]: <re.Match object; span=(0, 0), match=''>
*? = 其实可以拆分看 字符1*?字符2,相当于 (字符1*)?字符2, 字符1{0,}+第一个字符2, 字符1次数>=0,字符2出现次数>=1
In [154]: re.match(r'\w*?\d','123wer123') # \w匹配0次,返回第一个数字
Out[154]: <re.Match object; span=(0, 1), match='1'> In [155]: re.match(r'\w*?\d','wx123wer123') # \w匹配2次, 返回2个字母+一个数字
Out[155]: <re.Match object; span=(0, 3), match='wx1'> In [156]: re.match(r'\w*?\d','wxe') # \d没有匹配项,最终匹配失败,返回None In [157]: re.match(r'\w*?','wxe') # 遇到第一个''之前\w可以最多匹配三个,最少可以一次都不匹配,非贪婪模式按\w匹配次数最少的来, \w匹配0次,最终返回''
Out[157]: <re.Match object; span=(0, 0), match=''>
+?=(字符1+)?字符2, 字符1{1,}+第一个字符2, 字符1出现次数>=1,字符2出现次数>=1
In [160]: re.match(r'\w+?\d','%123wer123') # \w匹配0次,最终匹配失败,返回None In [161]: re.match(r'\w+?\d','wsx123wer123') #\w匹配3次,最后返回三个字母+第一个数字
Out[161]: <re.Match object; span=(0, 4), match='wsx1'> In [162]: re.match(r'\w+?\d','wsxwer') # \d匹配0次,最终匹配失败,返回None In [163]: re.match(r'\w+?','wsxwer') # 遇到第一个''之前,\w在这里最多可以匹配6次,最好必须匹配一次,非贪婪模式就是按最少的次数来,所以返回第一个字母+'',即第一个字母
Out[163]: <re.Match object; span=(0, 1), match='w'>
In [165]: re.match(r'w+?\w','wsxwer') # 注意返回的是ws而不是wsxwe,w+表示w可以出现1到多次,ws中w只匹配一次,wsxwe却匹配了2次,非贪婪模式就是捡w匹配次数最少的来,所以返回ws
Out[165]: <re.Match object; span=(0, 2), match='ws'>
看如下示例应该能更好的理解

理解了*?,+?就更好理解了,单独使用同{1},配合后面的表达式使用的时候意味着如果能匹配到后面的表达式则前面无限长匹配,
如果不能匹配到后面一个表达式则只返回匹配到的第一个字符
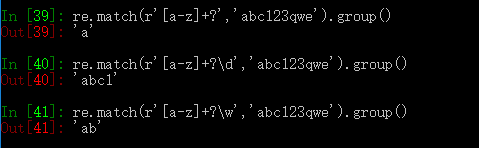

|单独使用只匹配左右紧邻的表达式,可以和()结合使用

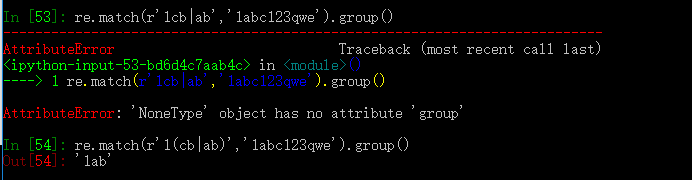
如下示例可以看出分组结合|的妙用, r'1cb|ab' 只能匹配到1cbb和1cab
但是r'1(cb|ab)'则表示匹配1cb和1ab,是把ab和cb当做一个整体
引用编号分组和别名分组,如果分组比较多的时候建议用别名分组

- \元字符 表示匹配元字符本身

- ^ 脱字符,匹配输入字符串的开始的位置
整个字符串的第一个字符

- $ 匹配输入字符串的结束位置
整个字符串结束字符,但如果最后一个是换行符那按照倒数第二个也可以匹配到,当然直接按照换行符也可以匹配到

- \b 表示单词的边界,\B与\b相反


- \d 匹配0~9的数字

- \D 匹配数字以外的字符

- \w 匹配字母或数字或下划线或汉字等

- \W与\w的含义相反,是匹配特殊字符的

- \s 匹配任意的空白符,包括空格,制表符(Tab),换行符等,\S匹配非空白字符

python正则元字符的含义的更多相关文章
- 第11.16节 Python正则元字符“()”(小括号)与组(group)匹配模式
一. 什么是组 关于组匹配模式,Python官网上说得比较简单,也没有这个名词,只有组这个名词,老猿查了比较多的资料和做了相关测试之后才理解. 组匹配模式,就是在匹配的正则表达式中使用小括号" ...
- $ python正则表达式系列(1)——正则元字符
本文主要介绍python中正则表达式的基本用法,做一个初步的认识. 1. 初识 python通过re内置模块来处理正则表达式(regex),底层使用C引擎.一个简单的正则匹配的例子: import r ...
- Python正则式的基本用法
Python正则式的基本用法 1.1基本规则 1.2重复 1.2.1最小匹配与精确匹配 1.3前向界定与后向界定 1.4组的基本知识 2.re模块的基本函数 2.1使用compile加速 2.2 ma ...
- python 正则,常用正则表达式大全
Nginx访问日志匹配 re.compile #re.compile 规则解释,改规则必须从前面开始匹配一个一个写到后面,前面一个修改后面全部错误.特殊标准结束为符号为空或者双引号: 改符号开始 从 ...
- Python正则匹配字母大小写不敏感在读xml中的应用
需要解决的问题:要匹配字符串,字符串中字母的大小写不确定,如何匹配? 问题出现之前是使用字符串比较的方式,比如要匹配'abc',则用语句: if s == 'abc':#s为需要匹配的字符串 prin ...
- 认识python正则模块re
python正则模块re python中re中内置匹配.搜索.替换方法见博客---python附录-re.py模块源码(含re官方文档链接) 正则的应用是处理一些字符串,phthon的博文python ...
- Python正则简单实例分析
Python正则简单实例分析 本文实例讲述了Python正则简单用法.分享给大家供大家参考,具体如下: 悄悄打入公司内部UED的一个Python爱好者小众群,前两天一位牛人发了条消息: 小的测试题: ...
- python 正则使用笔记
python正则使用笔记 def remove_br(content): """去除两边换行符""" content = content.r ...
- Python正则处理多行日志一例
正则表达式基础知识请参阅<正则表达式基础知识>,本文使用正则表达式来匹配多行日志并从中解析出相应的信息. 假设现在有这样的SQL日志: SELECT * FROM open_app WHE ...
随机推荐
- 【巨杉数据库SequoiaDB】巨杉Tech | 巨杉数据库数据高性能数据导入迁移实践
SequoiaDB 一款自研金融级分布式数据库产品,支持标准SQL和分布式事务功能.支持复杂索引查询,兼容 MySQL.PGSQL.SparkSQL等SQL访问方式.SequoiaDB 在分布式存储功 ...
- 计算器程序编写_python
一.计算一串字符串的最终值,相当于eval函数功能: #!/usr/bin/env python # _*_ coding:utf-8 _*_ #Author:chenxz import re def ...
- 论文阅读笔记(五)【CVPR2012】:Large Scale Metric Learning from Equivalence Constraints
由于在读文献期间多次遇见KISSME,都引自这篇CVPR,所以详细学习一下. Introduction 度量学习在机器学习领域有很大作用,其中一类是马氏度量学习(Mahalanobis metric ...
- python常用的正则表达式,持续更新<<
# -*- coding: utf-8 -*- import re str_0 = 'Aqin1012Heheheaaaaaaahehe如何da' def re_str(re_str_0,str_0) ...
- TCP的粘包和拆包问题及解决
前言 TCP属于传输层的协议,传输层除了有TCP协议外还有UDP协议.那么UDP是否会发生粘包或拆包的现象呢?答案是不会.UDP是基于报文发送的,从UDP的帧结构可以看出,在UDP首部采用了16bit ...
- layui时间控件laydate
主要解决点击年份立马关闭控件弹窗实现和控件闪退问题 <div class="date-box"> 日期选择 : <input id="xl-2" ...
- vue小例子-01
1.在components下建一个 2.代码如下: <template> <!--1.业务是开始有一组数据,序号,姓名,性别,年龄,操作(删除) 2.有三个输入框输入姓名,性 ...
- [HAOI2016] 找相同字符 - 后缀数组,单调栈
[HAOI2016] 找相同字符 Description 给定两个字符串,求出在两个字符串中各取出一个子串使得这两个子串相同的方案数.两个方案不同当且仅当这两个子串中有一个位置不同. \(n,m \l ...
- IIS7.5 HTTP 错误 500 调用loadlibraryex失败的解决方法
在IIS7.5打开网页的时候,提示: HTTP 错误 500.0 - Internal Server Error 调用 LoadLibraryEx 失败,在 ISAPI 筛选器 C:\Windows\ ...
- ORA-00928: missing SELECT keyword
问题描述 ORA-00928: missing SELECT keyword 问题原因 未写表名