Hadoop中的java基本类型的序列化封装类
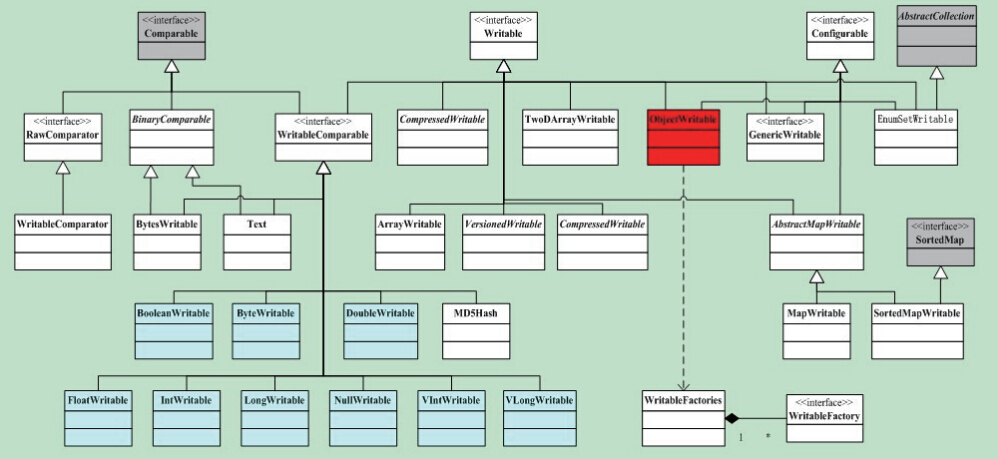
Hadoop将很多Writable类归入org.apache.hadoop.io包中,在这些类中,比较重要的有Java基本类、Text、Writable集合、ObjectWritable等,重点介绍Java基本类
1. Java基本类型的Writable封装
目前Java基本类型对应的Writable封装如下表所示。所有这些Writable类都继承自WritableComparable。也就是说,它们是可比较的。同时,它们都有get()和set()方法,用于获得和设置封装的值。
Java基本类型对应的Writable封装
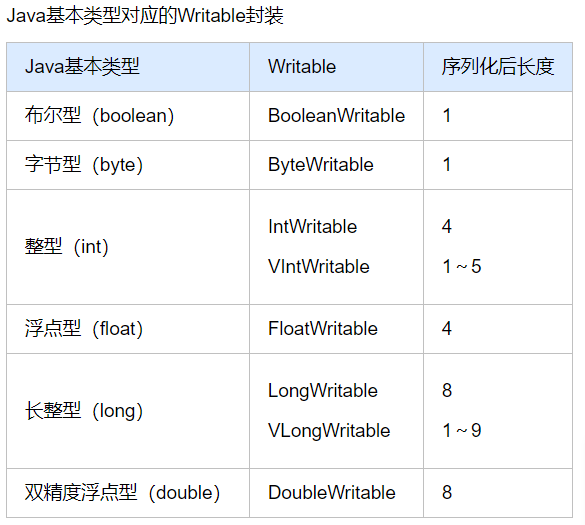
在表中,对整型(int和long)进行编码的时候,有固定长度格式(IntWritable和LongWritable)和可变长度格式(VIntWritable和VLongWritable)两种选择。固定长度格式的整型,序列化后的数据是定长的,而可变长度格式则使用一种比较灵活的编码方式,对于数值比较小的整型,它们往往比较节省空间。同时,由于VIntWritable和VLongWritable的编码规则是一样的,所以VIntWritable的输出可以用VLongWritable读入。下面以VIntWritable为例,说明Writable的Java基本类封装实现。代码如下:
public class VIntWritable implements WritableComparable {
private int value;
……
// 设置VIntWritable的值
public void set(int value) { this.value = value; }
// 获取VIntWritable的值
public int get() { return value; }
public void readFields(DataInput in) throws IOException {
value = WritableUtils.readVInt(in);
}
public void write(DataOutput out) throws IOException {
WritableUtils.writeVInt(out, value);
}
……
}
首先,每个Java基本类型的Writable封装,其类的内部都包含一个对应基本类型的成员变量value,get()和set()方法就是用来对该变量进行取值/赋值操作的。而Writable接口要求的readFields()和write()方法,VIntWritable则是通过调用Writable工具类中提供的readVInt()和writeVInt()读/写数据。方法readVInt()和writeVInt()的实现也只是简单调用了readVLong()和writeVLong(),所以,通过writeVInt()写的数据自然可以通过readVLong()读入。
writeVLong ()方法实现了对整型数值的变长编码,它的编码规则如下:
如果输入的整数大于或等于–112同时小于或等于127,那么编码需要1字节;否则,序列化结果的第一个字节,保存了输入整数的符号和后续编码的字节数。符号和后续字节数依据下面的编码规则(又一个规则):
如果是正数,则编码值范围落在–113和–120间(闭区间),后续字节数可以通过–(v+112)计算。
如果是负数,则编码值范围落在–121和–128间(闭区间),后续字节数可以通过–(v+120)计算。
后续编码将高位在前,写入输入的整数(除去前面全0字节)。代码如下:
public final class WritableUtils {
public stati cvoid writeVInt(DataOutput stream, int i) throws IOException
{
writeVLong(stream, i);
}
/**
* @param stream保存系列化结果输出流
* @param i 被序列化的整数
* @throws java.io.IOException
*/
public static void writeVLong(DataOutput stream, long i) throws……
{
//处于[-112, 127]的整数
if (i >= - && i <= ) {
stream.writeByte((byte)i);
return;
}
//计算情况2的第一个字节
int len = -;
if (i < ) {
i ^= -1L;
len = -;
}
long tmp = i;
while (tmp != ) {
tmp = tmp >> ;
len--;
}
stream.writeByte((byte)len);
len = (len < -) ? -(len + ) : -(len + );
//输出后续字节
for (int idx = len; idx != ; idx--) {
int shiftbits = (idx - ) * ;
long mask = 0xFFL << shiftbits;
stream.writeByte((byte)((i & mask) >> shiftbits));
}
}
}
原文链接:https://www.cnblogs.com/wuyudong/p/hadoop-writable.html
Hadoop中的java基本类型的序列化封装类的更多相关文章
- hadoop中实现java网络爬虫
这一篇网络爬虫的实现就要联系上大数据了.在前两篇java实现网络爬虫和heritrix实现网络爬虫的基础上,这一次是要完整的做一次数据的收集.数据上传.数据分析.数据结果读取.数据可视化. 需要用到 ...
- restframework中根据请求的类型修改序列化类
只要在视图中重写get_serializer_class方法就可以,用if对请求的类型进行判断 def get_serializer_class(self): if self.action == &q ...
- Java中Enum类型的序列化(转)
在Java中,对Enum类型的序列化与其他对象类型的序列化有所不同,今天就来看看到底有什么不同.下面先来看下在Java中,我们定义的Enum在被编译之后是长成什么样子的. Java代码: Java代码 ...
- Hadoop中序列化与Writable接口
学习笔记,整理自<Hadoop权威指南 第3版> 一.序列化 序列化:序列化是将 内存 中的结构化数据 转化为 能在网络上传输 或 磁盘中进行永久保存的二进制流的过程:反序列化:序列化的逆 ...
- hadoop中的序列化
此文已由作者肖凡授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 最近在学习hadoop,发现hadoop的序列化过程和jdk的序列化有很大的区别,下面就来说说这两者的区别都有 ...
- hadoop中典型Writable类详解
本文地址:http://www.cnblogs.com/archimedes/p/hadoop-writable.html,转载请注明源地址. Hadoop将很多Writable类归入org.apac ...
- hadoop 中对Vlong 和 Vint的压缩方法
hadoop 中对java的基本类型进行了writeable的封装,并且所有这些writeable都是继承自WritableComparable的,都是可比较的:并且,它们都有对应的get() 和 s ...
- 一脸懵逼学习Hadoop中的序列化机制——流量求和统计MapReduce的程序开发案例——流量求和统计排序
一:序列化概念 序列化(Serialization)是指把结构化对象转化为字节流.反序列化(Deserialization)是序列化的逆过程.即把字节流转回结构化对象.Java序列化(java.io. ...
- hadoop中的序列化与Writable接口
本文地址:http://www.cnblogs.com/archimedes/p/hadoop-writable-interface.html,转载请注明源地址. 简介 序列化和反序列化就是结构化对象 ...
随机推荐
- laravel中redis数据库的简单使用
1.简介 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s . 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Set ...
- Spring学习笔记-Spring之旅-01
使用Spring简化JAVA开发 Spring的四种关键策略: ●基于POJO的轻量级和最小侵入式编程: ●通过依赖注入(DI)和面向接口实现松耦合: ●基于切面(AOP)和惯例进行声明式编程. ●通 ...
- Python-Django学习笔记(三)-Model模型的编写以及Oracle数据库的配置
Django使用的 MTV 设计模式(Models.Templates.Views) 因此本节将围绕这三部分并按照这个顺序来创建第一个页面 模型层models.py 模型是数据唯一而且准确的信息来源. ...
- Wannafly Camp 2020 Day 1A 期望逆序对 - 概率期望
分类讨论即可 #include <bits/stdc++.h> using namespace std; #define int long long const int N = 5005; ...
- 根据JSON的值设置radio选中状态
说明:页面有一组单选按钮radio,现在页面发送请求得到一组json数据,包括radio的值. 需要根据JSON中的值绑定radio的选中状态> <table class="ta ...
- SpringBoot框架---配置
1.更改tomcat的端口号: application.properties 配置文件中, server.port=9090 2.设置上下文路径: server.servlet.context-pat ...
- 并查集路径压缩优化 UnionFind PathCompression(C++)
/* * UnionFind.h * 有两种实现方式,QuickFind和QuickUnion * QuickFind: * 查找O(1) * 合并O(n) * QuickUnion:(建议使用) * ...
- Centos7在防火墙中添加访问端口
1. 查看jenkins启动状态命令:systemctl status Jenkins 保证jenkins启动,此处的状态为正在运行 2. 查看防火墙状态命令:systemct ...
- js - 子节点
子节点数量:this.wdlgLossInfo.childNodes.length
- docker使用nginx实现ssl(https)反向代理其他容器应用
安装nginx容器 搜索nginx镜像 docker search nginx 拉取最新版nginx docker pull nginx:latest 运行容器 docker run --name=n ...