深入浅出 Java Concurrency (21): 并发容器 part 6 可阻塞的BlockingQueue (1)[转]
在《并发容器 part 4 并发队列与Queue简介》节中的类图中可以看到,对于Queue来说,BlockingQueue是主要的线程安全版本。这是一个可阻塞的版本,也就是允许添加/删除元素被阻塞,直到成功为止。
BlockingQueue相对于Queue而言增加了两个操作:put/take。下面是一张整理的表格。
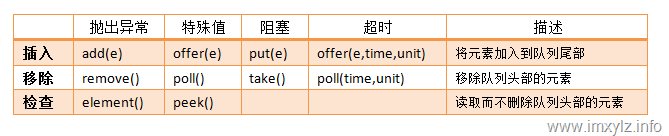 看似简单的API,非常有用。这在控制队列的并发上非常有好处。既然加入队列和移除队列能够被阻塞,这在实现生产者-消费者模型上就简单多了。
看似简单的API,非常有用。这在控制队列的并发上非常有好处。既然加入队列和移除队列能够被阻塞,这在实现生产者-消费者模型上就简单多了。
清单1 是生产者-消费者模型的一个例子。这个例子是一个真实的场景。服务端(ICE服务)接受客户端的请求(accept),请求计算此人的好友生日,然后将计算的结果存取缓存中(Memcache)中。在这个例子中采用了ExecutorService实现多线程的功能,尽可能的提高吞吐量,这个在后面线程池的部分会详细说明。目前就可以理解为new Thread(r).start()就可以了。另外这里阻塞队列使用的是LinkedBlockingQueue。
清单1 一个生产者-消费者例子
package xylz.study.concurrency;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingDeque;public class BirthdayService {
final int workerNumber;
final Worker[] workers;
final ExecutorService threadPool;
static volatile boolean running = true;
public BirthdayService(int workerNumber, int capacity) {
if (workerNumber <= 0) throw new IllegalArgumentException();
this.workerNumber = workerNumber;
workers = new Worker[workerNumber];
for (int i = 0; i < workerNumber; i++) {
workers[i] = new Worker(capacity);
}
//
boolean b = running;// kill the resorting
threadPool = Executors.newFixedThreadPool(workerNumber);
for (Worker w : workers) {
threadPool.submit(w);
}
}Worker getWorker(int id) {
return workers[id % workerNumber];}
class Worker implements Runnable {
final BlockingQueue<Integer> queue;
public Worker(int capacity) {
queue = new LinkedBlockingQueue<Integer>(capacity);
}public void run() {
while (true) {
try {
consume(queue.take());
} catch (InterruptedException e) {
return;
}
}
}void put(int id) {
try {
queue.put(id);
} catch (InterruptedException e) {
return;
}
}
}public void accept(int id) {
//accept client request
getWorker(id).put(id);
}protected void consume(int id) {
//do the work
//get the list of friends and save the birthday to cache
}
}
在清单1 中可以看到不管是put()还是get(),都抛出了一个InterruptedException。我们就从这里开始,为什么会抛出这个异常。
上一节中提到实现一个并发队列有三种方式。显然只有第二种 Lock 才能实现阻塞队列。在锁机制中提到过,Lock结合Condition就可以实现线程的阻塞,这在锁机制部分的很多工具中都详细介绍过,而接下来要介绍的LinkedBlockingQueue就是采用这种方式。
LinkedBlockingQueue 原理
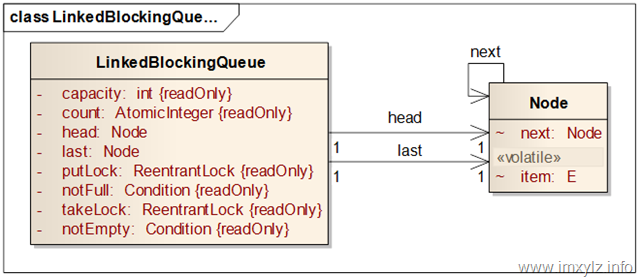 对比ConcurrentLinkedQueue的结构图,LinkedBlockingQueue多了两个ReentrantLock和两个Condition以及用于计数的AtomicInteger,显然这会导致LinkedBlockingQueue的实现有点复杂。对照此结构,有以下几点说明:
对比ConcurrentLinkedQueue的结构图,LinkedBlockingQueue多了两个ReentrantLock和两个Condition以及用于计数的AtomicInteger,显然这会导致LinkedBlockingQueue的实现有点复杂。对照此结构,有以下几点说明:
- 但是整体上讲,LinkedBlockingQueue和ConcurrentLinkedQueue的结构类似,都是采用头尾节点,每个节点指向下一个节点的结构,这表示它们在操作上应该类似。
- LinkedBlockingQueue引入了原子计数器count,这意味着获取队列大小size()已经是常量时间了,不再需要遍历队列。每次队列长度有变更时只需要修改count即可。
- 有了修改Node指向有了锁,所以不需要volatile特性了。既然有了锁Node的item为什么需要volatile在后面会详细分析,暂且不表。
- 引入了两个锁,一个入队列锁,一个出队列锁。当然同时有一个队列不满的Condition和一个队列不空的Condition。其实参照锁机制前面介绍过的生产者-消费者模型就知道,入队列就代表生产者,出队列就代表消费者。为什么需要两个锁?一个锁行不行?其实一个锁完全可以,但是一个锁意味着入队列和出队列同时只能有一个在进行,另一个必须等待其释放锁。而从ConcurrentLinkedQueue的实现原理来看,事实上head和last (ConcurrentLinkedQueue中是tail)是分离的,互相独立的,这意味着入队列实际上是不会修改出队列的数据的,同时出队列也不会修改入队列,也就是说这两个操作是互不干扰的。更通俗的将,这个锁相当于两个写入锁,入队列是一种写操作,操作head,出队列是一种写操作,操作tail。可见它们是无关的。但是并非完全无关,后面详细分析。
在没有揭示入队列和出队列过程前,暂且猜测下实现原理。
根据前面学到的锁机制原理结合ConcurrentLinkedQueue的原理,入队列的阻塞过程大概是这样的:
- 获取入队列的锁putLock,检测队列大小,如果队列已满,那么就挂起线程,等待队列不满信号notFull的唤醒。
- 将元素加入到队列尾部,同时修改队列尾部引用last。
- 队列大小加1。
- 释放锁putLock。
- 唤醒notEmpty线程(如果有挂起的出队列线程),告诉消费者,已经有了新的产品。
对比入队列,出队列的阻塞过程大概是这样的:
- 获取出队列的锁takeLock,检测队列大小,如果队列为空,那么就挂起线程,等待队列不为空notEmpty的唤醒。
- 将元素从头部移除,同时修改队列头部引用head。
- 队列大小减1。
- 释放锁takeLock。
- 唤醒notFull线程(如果有挂起的入队列线程),告诉生产者,现在还有空闲的空间。
下面来验证上面的过程。
入队列过程(put/offer)
清单2 阻塞的入队列过程
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
int c = -1;
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
putLock.lockInterruptibly();
try {
try {
while (count.get() == capacity)
notFull.await();
} catch (InterruptedException ie) {
notFull.signal(); // propagate to a non-interrupted thread
throw ie;
}
insert(e);
c = count.getAndIncrement();
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
if (c == 0)
signalNotEmpty();
}
清单2 描述的是入队列的阻塞过程。可以看到和上面描述的入队列的过程基本相同。但是也有以下几个问题:
- 如果在入队列的时候线程被中断,那么就需要发出一个notFull的信号,表示下一个入队列的线程能够被唤醒(如果阻塞的话)。
- 入队列成功后如果队列不满需要补一个notFull的信号。为什么?队列不满的时候其它入队列的阻塞线程难道不知道么?有可能。这是因为为了减少上下文切换的次数,每次唤醒一个线程(不管是入队列还是出队列)都是只随机唤醒一个(notify),而不是唤醒所有的(notifyall())。这会导致其它阻塞的入队列线程不能够即使处理队列不满的情况。
- 如果队列不为空并且可能有一个元素的话就唤醒一个出队列线程。这么做说明之前队列一定为空,因为在加入队列之后队列最多只能为1,那么说明未加入之前是0,那么就可能有被阻塞的出队列线程,所以就唤醒一个出队列线程。特别说明的是为什么使用一个临时变量c,而不用count。这是因为读取一个count的开销比读取一个临时一个变量大,而此处c又能够完成确认队列最多只有一个元素的判断。首先c默认为-1,如果加入队列后获取原子计数器的结果为0,说明之前队列为空,不可能消费(出队列),也不可能入队列,因为此时锁还在当前线程上,那么加入一个后队列就不为空了,所以就可以安全的唤醒一个消费(出对立)线程。
- 入队列的过程允许被中断,所以总是抛出InterruptedException 异常。
针对第2点,特别补充说明下。本来这属于锁机制中条件队列的范围,由于没有应用场景,所以当时没有提。
前面提高notifyall总是比notify更可靠,因为notify可能丢失通知,为什么不适用notifyall呢?
先解释下notify丢失通知的问题。
notify丢失通知问题
假设线程A因为某种条件在条件队列中等待,同时线程B因为另外一种条件在同一个条件队列中等待,也就是说线程A/B都被同一个Conditon.await()挂起,但是等待的条件不同。现在假设线程B的线程被满足,线程C执行一个notify操作,此时JVM从Conditon.await()的多个线程(A/B)中随机挑选一个唤醒,不幸的是唤醒了A。此时A的条件不满足,于是A继续挂起。而此时B仍然在傻傻的等待被唤醒的信号。也就是说本来给B的通知却被一个无关的线程持有了,真正需要通知的线程B却没有得到通知,而B仍然在等待一个已经发生过的通知。
如果使用notifyall,则能够避免此问题。notifyall会唤醒所有正在等待的线程,线程C发出的通知线程A同样能够收到,但是由于对于A没用,所以A继续挂起,而线程B也收到了此通知,于是线程B正常被唤醒。
既然notifyall能够解决单一notify丢失通知的问题,那么为什么不总是使用notifyall替换notify呢?
假设有N个线程在条件队列中等待,调用notifyall会唤醒所有线程,然后这N个线程竞争同一个锁,最多只有一个线程能够得到锁,于是其它线程又回到挂起状态。这意味每一次唤醒操作可能带来大量的上下文切换(如果N比较大的话),同时有大量的竞争锁的请求。这对于频繁的唤醒操作而言性能上可能是一种灾难。
如果说总是只有一个线程被唤醒后能够拿到锁,那么为什么不使用notify呢?所以某些情况下使用notify的性能是要高于notifyall的。
如果满足下面的条件,可以使用单一的notify取代notifyall操作:
相同的等待者,也就是说等待条件变量的线程操作相同,每一个从wait放回后执行相同的逻辑,同时一个条件变量的通知至多只能唤醒一个线程。
也就是说理论上讲在put/take中如果使用sinallAll唤醒的话,那么在清单2 中的notFull.singal就是多余的。
出队列过程(poll/take)
再来看出队列过程。清单3 描述了出队列的过程。可以看到这和入队列是对称的。从这里可以看到,出队列使用的是和入队列不同的锁,所以入队列、出队列这两个操作才能并行进行。
清单3 阻塞的出队列过程
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();
try {
try {
while (count.get() == 0)
notEmpty.await();
} catch (InterruptedException ie) {
notEmpty.signal(); // propagate to a non-interrupted thread
throw ie;
}x = extract();
c = count.getAndDecrement();
if (c > 1)
notEmpty.signal();
} finally {
takeLock.unlock();
}
if (c == capacity)
signalNotFull();
return x;
}
为什么有异常?
有了入队列、出队列的过程后再来回答前面的几个问题。
为什么总是抛出InterruptedException 异常? 这是很大一块内容,其实是Java对线程中断的处理问题,希望能够在系列文章的最后能够对此开辟单独的篇章来谈谈。
在锁机制里面也是总遇到,这是因为,Java里面没有一种直接的方法中断一个挂起的线程,所以通常情况下等于一个处于WAITING状态的线程,允许设置一个中断位,一旦线程检测到这个中断位就会从WAITING状态退出,以一个InterruptedException 的异常返回。所以只要是对一个线程挂起操作都会导致InterruptedException 的可能,比如Thread.sleep()、Thread.join()、Object.wait()。尽管LockSupport.park()不会抛出一个InterruptedException 异常,但是它会将当前线程的的interrupted状态位置上,而对于Lock/Condition而言,当捕捉到interrupted状态后就认为线程应该终止任务,所以就抛出了一个InterruptedException 异常。
又见volatile
还有一个不容易理解的问题。为什么Node.item是volatile类型的?
起初我不大明白,因为对于一个进入队列的Node,它的item是不变,当且仅当出队列的时候会将头结点元素的item 设置为null。尽管在remove(o)的时候也是设置为null,但是那时候是加了putLock/takeLock两个锁的,所以肯定是没有问题的。那么问题出在哪?
我们知道,item的值是在put/offer的时候加入的。这时候都是有putLock锁保证的,也就是说它保证使用putLock锁的读取肯定是没有问题的。那么问题就只可能出在一个不适用putLock却需要读取Node.item的地方。
peek操作时获取头结点的元素而不移除它。显然他不会操作尾节点,所以它不需要putLock锁,也就是说它只有takeLock锁。清单4 描述了这个过程。
清单4 查询队列头元素过程
public E peek() {
if (count.get() == 0)
return null;
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
Node<E> first = head.next;
if (first == null)
return null;
else
return first.item;
} finally {
takeLock.unlock();
}
}
清单4 描述了peek的过程,最后返回一个非null节点的结果是Node.item。这里读取了Node的item值,但是整个过程却是使用了takeLock而非putLock。换句话说putLock对Node.item的操作,peek()线程可能不可见!
清单5 队列尾部加入元素
private void insert(E x) {
last = last.next = new Node<E>(x);
}
清单5 是入队列offer/put的一部分,这里关键在于last=new Node<E>(x)可能发生重排序。Node构造函数是这样的:Node(E x) { item = x; }。在这一步里面我们可能得到以下一种情况:
- 构建一个Node对象n;
- 将Node的n赋给last
- 初始化n,设置item=x
在执行步骤2 的时候一个peek线程可能拿到了新的Node n,这时候它读取item,得到了一个null。显然这是不可靠的。
对item采用volatile之后,JMM保证对item=x的赋值一定在last=n之前,也就是说last得到的一个是一个已经赋值了的新节点n。这就不会导致读取空元素的问题的。
出对了poll/take和peek都是使用的takeLock锁,所以不会导致此问题。
删除操作和遍历操作由于同时获取了takeLock和putLock,所以也不会导致此问题。
总结:当前仅当元素加入队列时读取此元素才可能导致不一致的问题。采用volatile正式避免此问题。
附加功能
BlockingQueue有一个额外的功能,允许批量从队列中异常元素。这个API是:
int drainTo(Collection<? super E> c, int maxElements); 最多从此队列中移除给定数量的可用元素,并将这些元素添加到给定 collection 中。
int drainTo(Collection<? super E> c); 移除此队列中所有可用的元素,并将它们添加到给定 collection 中。
清单6 描述的是最多移除指定数量元素的过程。由于批量操作只需要一次获取锁,所以效率会比每次获取锁要高。但是需要说明的,需要同时获取takeLock/putLock两把锁,因为当移除完所有元素后这会涉及到尾节点的修改(last节点仍然指向一个已经移走的节点)。
由于迭代操作contains()/remove()/iterator()也是获取了两个锁,所以迭代操作也是线程安全的。
清单6 批量移除操作
public int drainTo(Collection<? super E> c, int maxElements) {
if (c == null)
throw new NullPointerException();
if (c == this)
throw new IllegalArgumentException();
fullyLock();
try {
int n = 0;
Node<E> p = head.next;
while (p != null && n < maxElements) {
c.add(p.item);
p.item = null;
p = p.next;
++n;
}
if (n != 0) {
head.next = p;
assert head.item == null;
if (p == null)
last = head;
if (count.getAndAdd(-n) == capacity)
notFull.signalAll();
}
return n;
} finally {
fullyUnlock();
}
}
深入浅出 Java Concurrency (21): 并发容器 part 6 可阻塞的BlockingQueue (1)[转]的更多相关文章
- 深入浅出 Java Concurrency (23): 并发容器 part 8 可阻塞的BlockingQueue (3)[转]
在Set中有一个排序的集合SortedSet,用来保存按照自然顺序排列的对象.Queue中同样引入了一个支持排序的FIFO模型. 并发队列与Queue简介 中介绍了,PriorityQueue和Pri ...
- 深入浅出 Java Concurrency (22): 并发容器 part 7 可阻塞的BlockingQueue (2)[转]
在上一节中详细分析了LinkedBlockingQueue 的实现原理.实现一个可扩展的队列通常有两种方式:一种方式就像LinkedBlockingQueue一样使用链表,也就是每一个元素带有下一个元 ...
- 《深入浅出 Java Concurrency》—并发容器 ConcurrentMap
(转自:http://blog.csdn.net/fg2006/article/details/6404226) 在JDK 1.4以下只有Vector和Hashtable是线程安全的集合(也称并发容器 ...
- 深入浅出 Java Concurrency (16): 并发容器 part 1 ConcurrentMap (1)[转]
从这一节开始正式进入并发容器的部分,来看看JDK 6带来了哪些并发容器. 在JDK 1.4以下只有Vector和Hashtable是线程安全的集合(也称并发容器,Collections.synchro ...
- 深入浅出 Java Concurrency (27): 并发容器 part 12 线程安全的List/Set[转]
本小节是<并发容器>的最后一部分,这一个小节描述的是针对List/Set接口的一个线程版本. 在<并发队列与Queue简介>中介绍了并发容器的一个概括,主要描述的是Queue的 ...
- 深入浅出 Java Concurrency (17): 并发容器 part 2 ConcurrentMap (2)[转]
本来想比较全面和深入的谈谈ConcurrentHashMap的,发现网上有很多对HashMap和ConcurrentHashMap分析的文章,因此本小节尽可能的分析其中的细节,少一点理论的东西,多谈谈 ...
- 深入浅出 Java Concurrency (25): 并发容器 part 10 双向并发阻塞队列 BlockingDeque[转]
这个小节介绍Queue的最后一个工具,也是最强大的一个工具.从名称上就可以看到此工具的特点:双向并发阻塞队列.所谓双向是指可以从队列的头和尾同时操作,并发只是线程安全的实现,阻塞允许在入队出队不满足条 ...
- 深入浅出 Java Concurrency (26): 并发容器 part 11 Exchanger[转]
可以在对中对元素进行配对和交换的线程的同步点.每个线程将条目上的某个方法呈现给 exchange 方法,与伙伴线程进行匹配,并且在返回时接收其伙伴的对象.Exchanger 可能被视为 Synchro ...
- 深入浅出 Java Concurrency (20): 并发容器 part 5 ConcurrentLinkedQueue[转]
ConcurrentLinkedQueue是Queue的一个线程安全实现.先来看一段文档说明. 一个基于链接节点的无界线程安全队列.此队列按照 FIFO(先进先出)原则对元素进行排序.队列的头部 是队 ...
随机推荐
- 763 Hex Conversion
原题网址:http://www.lintcode.com/zh-cn/problem/hex-conversion/ Given a decimal number n and an integer k ...
- 软件-开发软件:Android Studio
ylbtech-软件-开发软件:Android Studio Android Studio 是谷歌推出的一个Android集成开发工具,基于IntelliJ IDEA. 类似 Eclipse ADT, ...
- System.Web.HttpCookie.cs
ylbtech-System.Web.HttpCookie.cs 1.程序集 System.Web, Version=4.0.0.0, Culture=neutral, PublicKeyToken= ...
- day 81 Vue学习二之vue结合项目简单使用、this指向问题
Vue学习二之vue结合项目简单使用.this指向问题 本节目录 一 阶段性项目流程梳理 二 vue切换图片 三 vue中使用ajax 四 vue实现音乐播放器 五 vue的计算属性和监听器 六 ...
- PAT甲级——A1128 N Queens Puzzle【20】
The "eight queens puzzle" is the problem of placing eight chess queens on an 8 chessboard ...
- 华为-eNSP模拟器路由器无法正常启动一直显示“#”
问题项如截图: 解决方案: 1. 打开自己电脑的控制面板 -->> 系统和安全 -->> Windows Defender防火墙 (运行应用通过Windows防火墙) 2 .找 ...
- C#查找List 某一段数据
public void SelectData() { List<int> r = new List<int>(); r.Add(); r.Add(); r.Add(); r.A ...
- angularJS ng-repeat="item in XXX track by $index"问题记录
参考:https://blog.csdn.net/lunhui1994_/article/details/80236315 问题:项目中对数据做了分页效果,理想是:当页数大于6时,隐藏>6的页数 ...
- java_缓冲流(字节输入流)
/** * java.iko.BufferedInputStream extends InputStream * BufferedInputStream:字节缓冲输入流 * 构造方法: * Buffe ...
- C#の单例模式
版本一: /// <summary>/// A simple singleton class implements./// </summary>public sealed cl ...