ELK日志分析系统搭建
之前一段时间由于版本迭代任务紧,组内代码质量不尽如人意。接二连三的被测试提醒后台错误之后, 我们决定搭建一个后台日志分析系统, 经过几个方案比较后,选择的相对更简单的ELK方案。
ELK 是Elasticsearch, Logstash,Kibana三个组件的首字母组合,这种方案最初的做法是:使用Logstash 去服务上采集日志文件, 然后做一些过滤处理后发送给 Elasticsearch, 在Elasticsearch中创建相应的索引,由Kibana提供统计分析的页面访问。但是Logstash 本身资源消耗较大,如果把它放到业务系统的服务器上会对系统造成不小的影响,一般的做法采用beats来替代(beats是一个更轻量级的收集器),参考如下图-1,此外也会有在数据量比较大时引入消息队列来环节组件压力。
详细的关于各组件的介绍建议参考Elastic 提供的官方文档

(图-1)
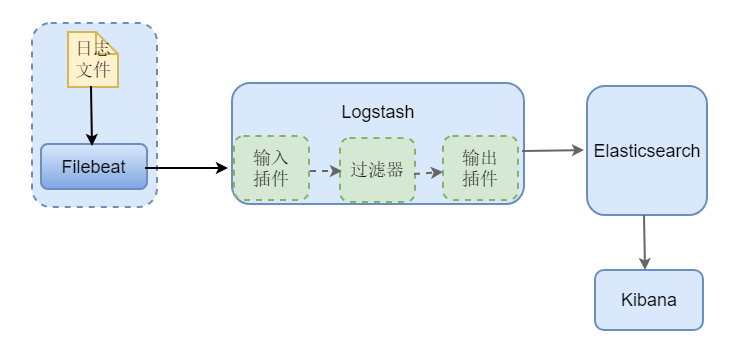
(图-2)
本文将基于上图-2的架构来介绍ELK日志系统的搭建。由于环境限制,这里各组件均部署在同一服务器上。
1)搭建elasticsearch
elasticsearch的下载安装配置在所有组件中相对是最复杂的,但是它依然可以很简单的按照如下几个步骤顺利完成:
① 官网下载地址 :https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.1.1-linux-x86_64.tar.gz
② 解压之后配置 elasticsearch-7.1.1/config/elasticsearch.yml 文件,如下
# ---------------------------------- Cluster -----------------------------------
# 指定集群名
cluster.name: customer-service # ------------------------------------ Node ------------------------------------
# 在集群名为customer-service 的集群下的 node-1 节点
node.name: node-1
# ---------------------------------- Network -----------------------------------
# 开启本质之外的网络访问
network.host: 0.0.0.0
# --------------------------------- Discovery ----------------------------------
# 定义初始主机点
cluster.initial_master_nodes: ["node-1"]
③ 启动elasticsearch (处于安全考虑 elasticsearch 只能非root用户启动,需要将elasticsearch解压文件切换所属用户)
# 解压路径下
./bin/elasticsearch
④ 验证elasticsearch是否启动成功
curl http://localhost:9200
如果看到如下结果,代表启动成功
{
"name" : "node-1",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "tYgc-2l3ThqcEfFKfeWgBQ",
"version" : {
"number" : "7.1.1",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "7a013de",
"build_date" : "2019-05-23T14:04:00.380842Z",
"build_snapshot" : false,
"lucene_version" : "8.0.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
2)Kibana的安装
① 官网下载:https://artifacts.elastic.co/downloads/kibana/kibana-7.1.1-linux-x86_64.tar.gz
② 配置解压路径下的/kibana-7.1.1-linux-x86_64/config/kibana.yml文件:
# 将server.host 改为所有IP, 这样以便不同主机可以访问到kibana页面
server.host: 0.0.0.0
③ 浏览器访问 http://ip:5601 (默认5601端口,可以在kibana.yml中配置) 得到如下页面表示启动成功
(图-3)
3)Filebeat 的安装
① 官方下载:https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.1.1-linux-x86_64.tar.gz
② 配置解压路径下的配置文件 filebeat.yml 如下:
#=========================== Filebeat inputs =============================
filebeat.inputs:
# Each - is an input. Most options can be set at the input level, so
# you can use different inputs for various configurations.
# Below are the input specific configurations.
- type: log # Change to true to enable this input configuration.
enabled: true
# 需要被采集的日志文件的路径
paths:
- /app/applogs/provider/info/dubbo-info.log #----------------------------- Logstash output --------------------------------
output.logstash:
# 指定logstash的地址和端口
hosts: ["127.0.0.1:5044"]
③ 启动 filebeat
# 注意使用root用户登录, 准确的说是注意用户对文件所拥有的权限
# -e 让日志打印到控制台, -c 重新指定启动的配置文件, -d 指定调试选择者器
./filebeat -e -c filebeat.yml -d "publish"
4)Logstash 的安装
① 官网下载:https://artifacts.elastic.co/downloads/logstash/logstash-7.1.1.tar.gz
② 配置logstash,增加customer-service-logstash.yml 的配置文件,文件配置内容如下:
# logstash 输入配置,这里我们采用beat采集日志
input {
beats {
port => ""
}
}
# The filter part of this file is commented out to indicate that it is
# optional.
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
# 此外还可以添加其他过滤器插件
} output {
# 输出到控制台打印
stdout { codec => rubydebug }
# 输出到elasticsearch ,并指定索引名称
elasticsearch {
hosts => [ "127.0.0.1:9200" ]
index => "logstash-customer-service-log"
} }
③ 启动logstash
# -f 从指定路径获取logstash启动的yml配置文件
# --config.reload.automatic 监听配置文件 如果有改动自动加载
bin/logstash -f first-pipeline.conf --config.reload.automatic
所有上述组件配置启动成功后,我们可以到kibana界面, 在侧边栏 management 下按下图-4方式创建 索引模式后,然后在图-5中可以获取到实时的日志记录。
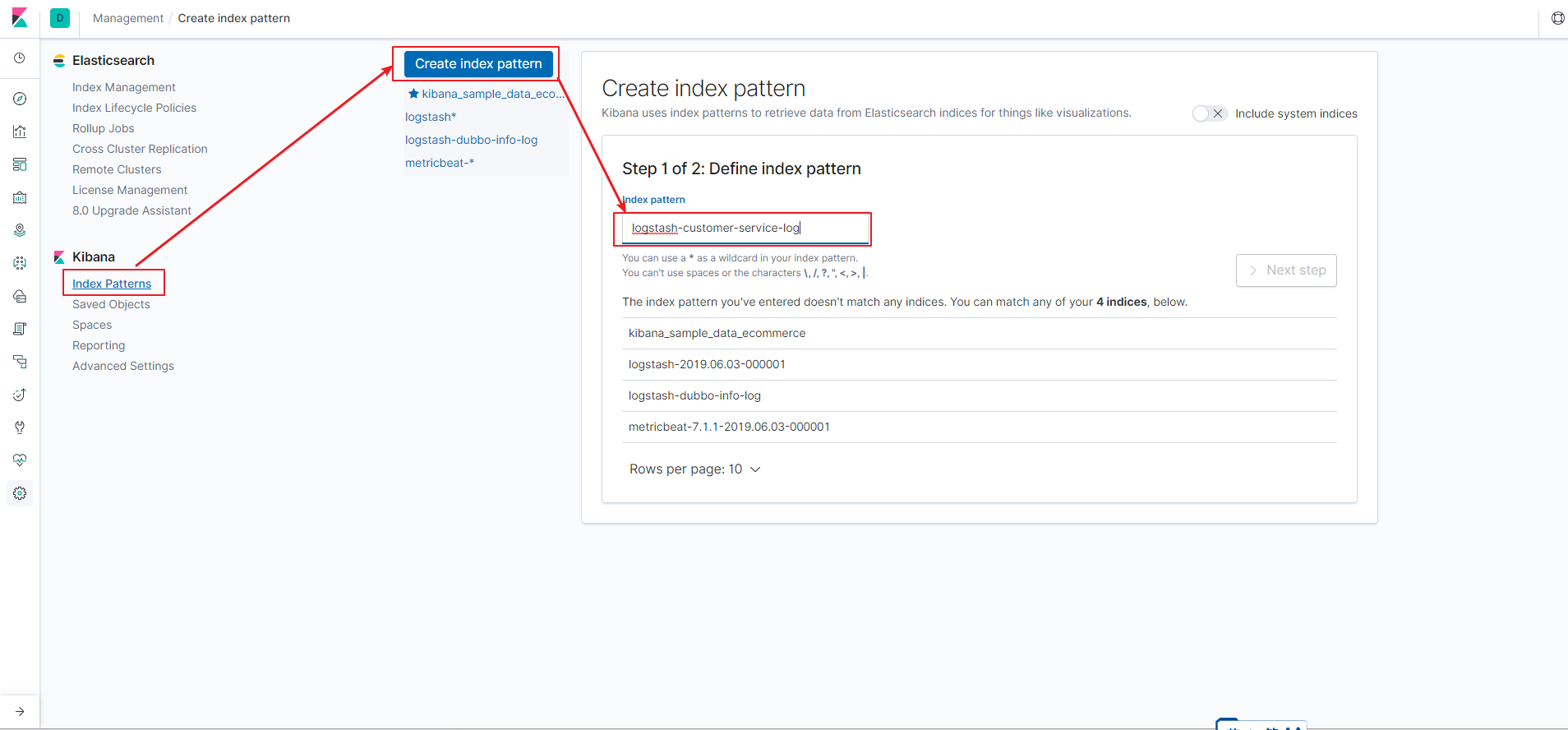
(图-4)
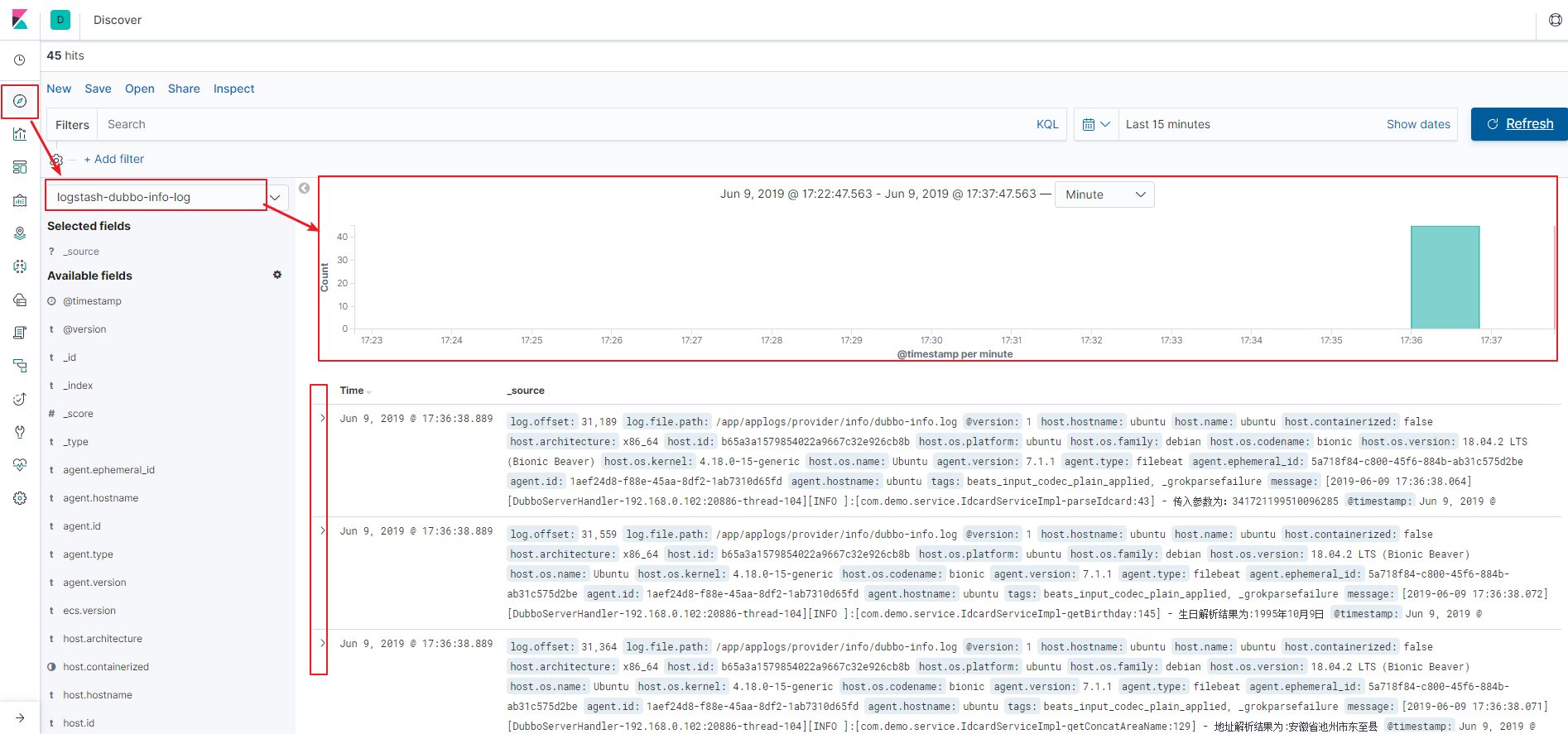
(图-5)
我们在logstash中增加对error级别日志的过滤处理,将这些日志统一放到 logstash-customer-service-error 索引中,然后在 kibana 中创建该索引同名的pattern, 这样在discover页签下可以直观的通过 时间段的筛选来定位error日志,并在下面的 expanded document 下查看日志的具体内容,这样一来就不需要挨个连接到服务器去手动查看日志了。
ELK日志分析系统搭建的更多相关文章
- Rsyslog+ELK日志分析系统搭建总结1.0(测试环境)
因为工作需求,最近在搭建日志分析系统,这里主要搭建的是系统日志分析系统,即rsyslog+elk. 因为目前仍为测试环境,这里说一下搭建的基础架构,后期上生产线再来更新最后的架构图,大佬们如果有什么见 ...
- ELK日志分析系统搭建(转)
摘要: 前段时间研究的Log4j+Kafka中,有人建议把Kafka收集到的日志存放于ES(ElasticSearch,一款基于Apache Lucene的开源分布式搜索引擎)中便于查找和分析,在研究 ...
- CentOs 7.3下ELK日志分析系统搭建
系统环境 为了安装时不出错,建议选择这两者选择一样的版本,本文全部选择5.3版本. System: Centos release 7.3 Java: openjdk version "1.8 ...
- ELK日志分析系统搭建 windows
1 分别下载elk包 下载地址 https://www.elastic.co/cn/downloads 2 将这三个解压到同一个目录下,便于管理 3 elasticsearch不需要修改配置 默认即可 ...
- Rsyslog+ELK日志分析系统
转自:https://www.cnblogs.com/itworks/p/7272740.html Rsyslog+ELK日志分析系统搭建总结1.0(测试环境) 因为工作需求,最近在搭建日志分析系统, ...
- 十分钟搭建和使用ELK日志分析系统
前言 为满足研发可视化查看测试环境日志的目的,准备采用EK+filebeat实现日志可视化(ElasticSearch+Kibana+Filebeat).题目为“十分钟搭建和使用ELK日志分析系统”听 ...
- Docker笔记(十):使用Docker来搭建一套ELK日志分析系统
一段时间没关注ELK(elasticsearch —— 搜索引擎,可用于存储.索引日志, logstash —— 可用于日志传输.转换,kibana —— WebUI,将日志可视化),发现最新版已到7 ...
- 快速搭建ELK7.5版本的日志分析系统--搭建篇
title: 快速搭建ELK7.5版本的日志分析系统--搭建篇 一.ELK安装部署 官网地址:https://www.elastic.co/cn/ 官网权威指南:https://www.elastic ...
- ELK日志分析系统简单部署
1.传统日志分析系统: 日志主要包括系统日志.应用程序日志和安全日志.系统运维和开发人员可以通过日志了解服务器软硬件信息.检查配置过程中的错误及错误发生的原因.经常分析日志可以了解服务器的负荷,性能安 ...
随机推荐
- Notepad++颜色配置
目前看着比较顺眼的notepad++配置,记录如下:
- HZOJ 分组
打了好多个代码. 对于测试点1,11:手动模拟. void QJ1_11() { ) { int tk; ]+a[]))tk=; ; if(tk<=k) { puts("); puts ...
- 如何用JS和HTML 做一个桌面炒股小插件【原创】
首先,使用node-webkit 做环境,废话不多说,直接贴HTML <!DOCTYPE html> <html xmlns="http://www.w3.org/1999 ...
- SQLSTATE[HY000] [2002] 错误
http://www.thinkphp.cn/topic/36194.html 使用tp框架 3.2.3 ,在windows上跑的时候没有任何问题,但是部署到linux系统和是哪个,就会报这个错,不知 ...
- URL的转义和解析
在开始python编程之前我们先来看看一个关与url的知识 在url中会有一些特殊字符,如果你写过cgi程序,并且提交一个表单去调用你的cgi,你会很清楚的 像?name=aiqier&age ...
- Laravel 修改默认日志文件名称和位置
修改默认日志位置 我们平常的开发中可能一直把laravel的日志文件放在默认位置不会有什么影响,但如果我们的项目上线时是全量部署,每次部署都是git中最新的代码,那这个时候每次都会清空我们的日志,显示 ...
- form组件类 钩子函数验证
# 全局钩子 def clean(self): pwd = self.cleaned_data.get("password") re_pwd = self.cleaned_data ...
- 如何在git中删除指定的文件和目录
部分场景中,我们会希望删除远程仓库(比如GitHub)的目录或文件. 具体操作 拉取远程的Repo到本地(如果已经在本地,可以略过) $ git clone xxxxxx 在本地仓库删除文件 $ gi ...
- javaScript 删除事件 弹出确认 取消对话框
javaScript 删除事件 弹出确认 取消对话框 1. <a href="javascript:if(confirm('确实要删除?'))location='http://www. ...
- React 简书
create-react-app jianshu yarn add styled-components -D 利用js写css样式 样式会更高效 https://github.com ...