HBase学习笔记(四)—— 架构模型
1、HBase的数据模型
在逻辑上,HBase 的数据模型同关系型数据库很类似,数据存储在一张表中,有行有列。
但从 HBase 的底层物理存储结构(K-V)来看,HBase 更像是一个 multi-dimensional map。
1.1 HBase 逻辑结构
先从一个逻辑结构模型图开始看起:

之前介绍了一些HBase的数据模型的概念,现在来系统的梳理一下:
- Table(表):一个表由一个或者多个列族构成。数据的属性。比如:name、age、TTL(超时时间)等等都在列族里边定义。定义完列族的表是个空表,只有添加了数据行以后,表才有数据。
- Column Family(列族):在HBase里,可以将多个列组合成一个列族。建表的时候不用创建列,因为列是可增减变化的,非常灵活。唯一需要确定的就是列族,也就是说一个表有几个列族是一开始就定好的。此外表的很多属性,比如数据过期时间、数据块缓存以及是否使用压缩等都是定义在列族上的,而不是定义在表上或者列上。这一点与以往的关系型数据库有很大的差别。列族存在的意义是:HBase会把相同列族的列尽量放在同一台机器上,所以说想把某几个列放在一台服务器上,只需要给他们定义相同的列族。
- Row(行):一个行包含多个列,这些列通过列族来分类。行中的数据所属的列族从该表所定义的列族中选取,不能选择这个表中不存在的列族。由于HBase是一个面向列存储的数据库,所以一个行中的数据可以分布在不同的服务器上。
- RowKey(行键):rowkey和MySQL数据库的主键比起来简单很多,rowkey必须要有,如果用户不指定的话,会有默认的。rowkey完全由是用户指定的一串不重复的字符串,另外,rowkey按照字典序排序。一个rowkey对应的是一行数据!!!
- Region:Region就是一段数据的集合。之前提到过高表的概念,把高表进行水平切分,假设分成两部分,那么这就形成了两个Region。注意一下Region的几个特性:
- Region不能跨服务器,一个RegionServer可以有多个Region。
- 数据量小的时候,一个Region可以存储所有的数据;但是当数据量大的时候,HBase会拆分Region。
- 当HBase在进行负载均衡的时候,也有可能从一台RegionServer上把Region移动到另一服务器的RegionServer上。
- Region是基于HDFS的,它的所有数据存取操作都是调用HDFS客户端完成的。
- RegionServer:RegionServer就是存放Region的容器,直观上说就是服务器上的一个服务。负责管理维护Region,详细情况后边再说!~~
1.2 HBase 物理存储结构
以上是一个基本的逻辑结构,底层的物理存储结构才是重中之重的内容,看下图,并且将尝试换个角度解释上边的几个概念:
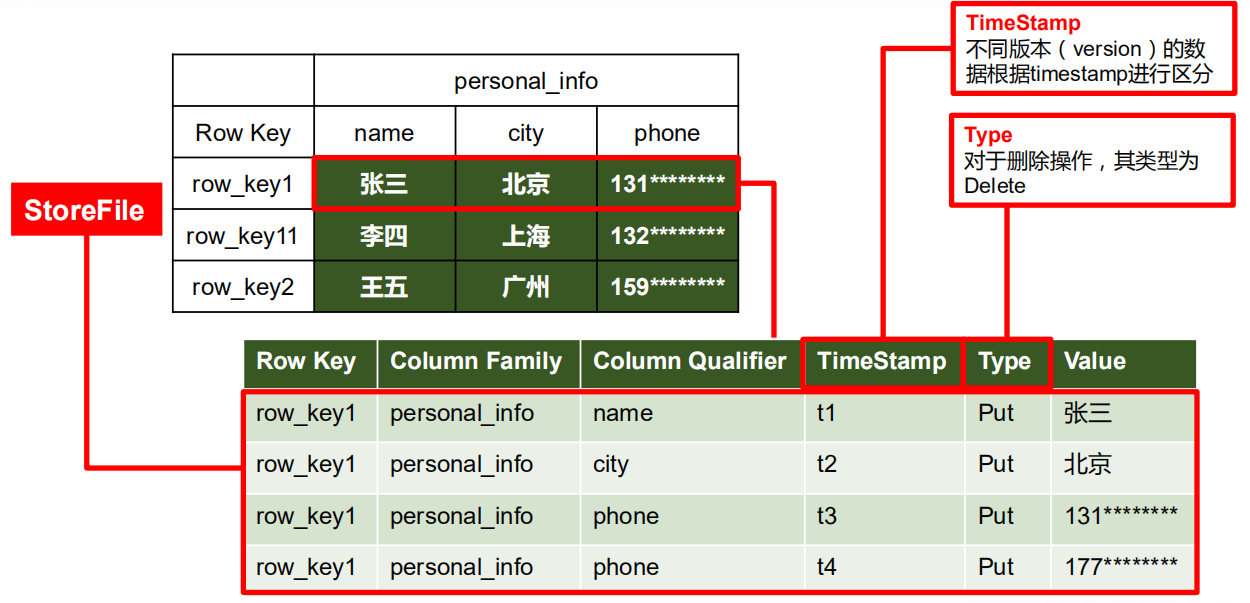
具体来说:
- NameSpace:命名空间,类似于关系型数据库的 DatabBase 概念,每个命名空间下有多个表。HBase有两个自带的命名空间,分别是 hbase 和 default,hbase 中存放的是 HBase 内置的表,default 表是用户默认使用的命名空间。
- Row:HBase 表中的每行数据都由一个 RowKey 和多个 Column(列)组成,数据是按照 RowKey 的字典顺序存储的,并且查询数据时只能根据 RowKey 进行检索,所以 RowKey 的设计十分重要。
- Column:列,HBase 中的每个列都由 Column Family(列族)和 Column Qualifier(列限定符)进行限 定,例如 info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义。
- TimeStamp:时间戳,用于标识数据的不同版本(version),每条数据写入时,如果不指定时间戳,系统会自动为其加上该字段,其值为写入 HBase 的时间。
- Cell:单元格,由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元。cell 中的数据是没有类型的,全部是字节码形式存贮。
2、HBase与关系型数据库的对比
传统关系型数据库的表结构图如下:

其中每行都是不可分割的,也正是体现了数据库第一范式的原子性,也就是说三个列必须在一起,而且要被存储在同一台服务器上,甚至是同一个文件里面。
HBase的表架构如图所示:
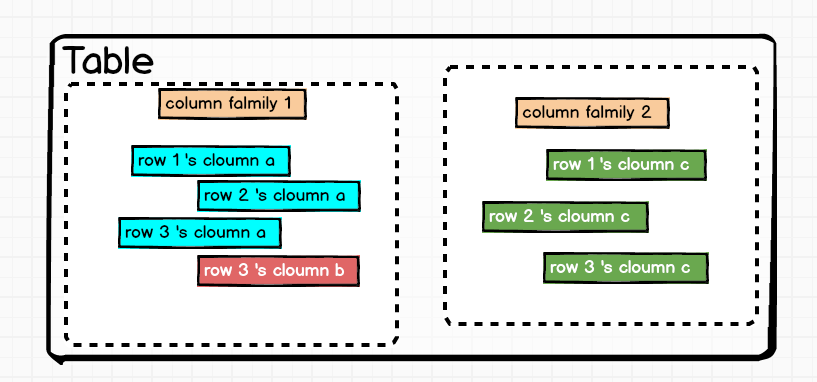
HBase的每一个行都是离散的,因为列族的存在,所以一个行里卖弄不同的列甚至被分配到了不同的服务器上。行的概念被减弱到了一个抽象的存在。在实体上,把多个列定义为一个行的关键词rowkey,也就是行这个概念在HBase中的唯一体验。
HBase的存储语句中必须精确的写出要将数据存放到哪个单元格,单元格由表:列族:行:列来唯一确定。用人话说就是要写清楚数据要被存储在哪个表的哪个列族的哪个行的哪个列。如果一行有10列,那么存储一行的数据就需要写明10行的语句。
3、HBase是怎样存储数据的
如果上边所有的概念还是不甚清楚,那么接下来的架构深入探索将会让你有一个更透彻的理解。
HBase是一个数据库,那么数据肯定是以某种实体形式存储在硬盘上的,先来看一下HBase是怎样存储数据的。使用"显微镜"逐步放大HBase的架构,从最宏观的Master和RegionServer结构一直到最小的单元格Cell。一边使用图示直观的感受,一边配上文字解释说明!!
3.1 宏观架构
宏观架构图示如下:
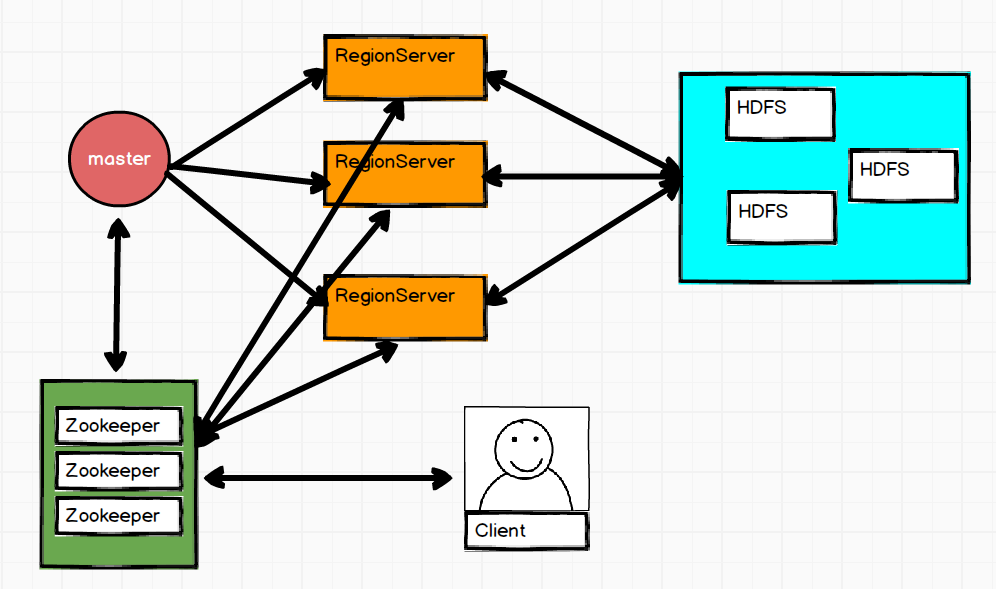
从这张图上可以看到是一个HBase集群由一个Master(也可配置成多个,HA)和多个RegionServer组成,之后再详细介绍RegionServer的架构。上面的图示说明了HBase的服务器角色构成,下边给出具体的介绍:
- Master:负责启动的时候分配Region到具体的RegionServer,执行各种管理操作,比如Region的分割与合并。在HBase中,master的角色地位比其他类型的集群弱很多。数据的读写操作与他没有关系,它挂了之后,集群照样运行。具体的原因后边后详细介绍。但是master也不能宕机太久,有很多必要的操作,比如创建表、修改列族配置,以及更重要的分割与合并都需要它的操作。
- RegionServer:RegionServer就是一台机器,在它上边有多个region。我们读写的数据就存储在Region中。
- Region:它是表拆分出来的一部分,HBase是一个会自动切片的数据库。当数据库过高时,就会进行拆分。
- HDFS:HBase的数据存储是基于HDFS的,它是真正承载数据的载体。
- Zookeeper:在本集群中负责存储hbase:meata的位置存储信息,客户端在写数据时需要先读取元数据信息。
3.2 RegionServer
在宏观架构图的最后一个RegionServer中可以看到 ,它的内部是多个Region的集合:
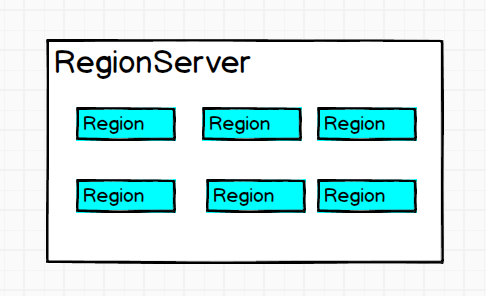
现在我们放大一下这个RegionServer的内部架构:
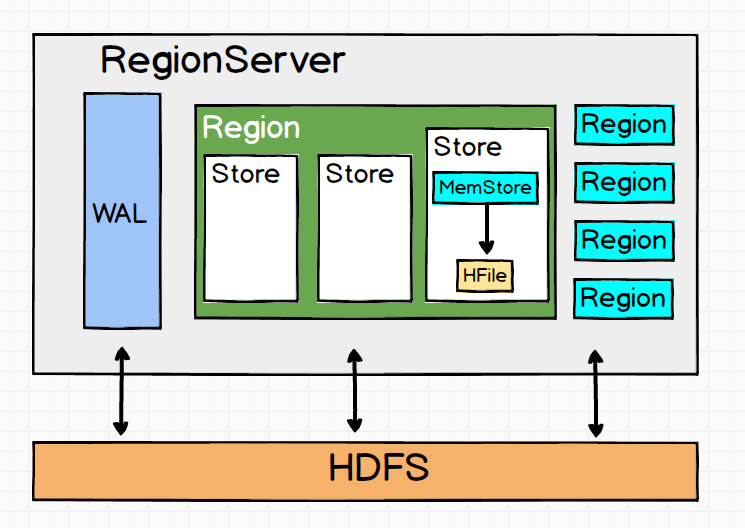
ok,从这幅图中我们可以看到一个RegionServer包含一下几个部分,详细说一说:
- 一个WAL:WAL时Write-Ahead Log的缩写,翻译为预写入日志。从名字大概也能猜出它的作用,当操作到达Region的时候,HBase先把操作写入到WAL中,然后把数据放入到基于内存实现的MemStore中,等到一定的时机再把数据刷写形成HFile文件,存储到HDFS上。WAL是一个保险机制,数据再写到MemStore之前被,先写到WAL中,这样如果在刷写过程中出现事故,可以从WAL恢复数据。
- 多个Region:Region已经多次提到了,它就时是数据库的一部分,每一个Region都有起始的rowkey和结束的rowkey,代表了它存储的row的范围。
3.3 Region
我们再放大Region的内部结构:
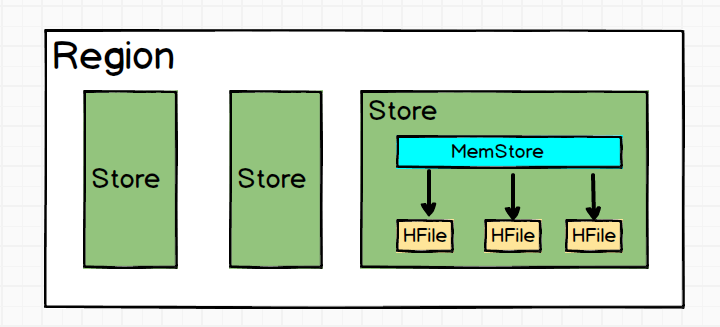
从图中可以看的出来,一个Region包含
- 多个Store:一个Region有多个Store,其实一个Store就是对应一个列族的数据,如图就有三个列族。再从最后一个Store中我们又可以看出,Store是由MemStore和HFile组成的,后边会有详细说明。
3.4 WAL
预写入日志就是设计来解决宕机之后的操作恢复问题的,WAL是保存在HDFS上的持久化文件。数据到达Region的时候,先写入WAL,然后被加载到MemStore中。这样就算Region宕机了,操作没来得及执行持久化,也可以再重启的时候从WAL加载操作并执行。
3.4.1 如何启用WAL?
WAL是默认开启的,也可以手动关闭它,这样增删改操作会快一点。但是这样做牺牲的是数据的安全性,所以不建议关闭。
关闭方法:
Mutation.setDurability(Durability.SKIP_WAL)
3.4.2 异步写入WAL
如果不惜通过关闭WAL来提高性能的话,还可以考虑一下折中的方案:异步写入WAL。
正常情况下,客户端提交的put、delete、append操作来到Region的时候,先调用HDFS的客户端写到WAL中。哪怕只有一个改动,也会调用HDFS的接口来写入数据。可以想象到,这种方式尽可能的保证了数据的安全性,代价这种方式频繁的消耗资源。
如果不想关闭WAL,又不想每次都耗费那么大的资源,每次改动都调用HDFS客户端,可以选择异步的方式写入WAL:
Mutation.setDurability(Durability.ASYNC_WAL)
这样设定以后,Region会等到条件满足的时候才将操作写到WAL。这里的条件指的是搁多久,写一次,默认的时间间隔是1s。
如果异步写入数据的时候出错了怎么办呢?比如客户端的操作现在在Region内存中,由于时间间隔未到1s,操作还没来得及写入到WAL,Region挂了(邪门不?就差那么一丢丢不到1s)。出错了是没有任何事务可以保证的。
3.4.3 WAL滚动
之前学习过MapReduce的shuffle机制,所以猜得到WAL是一个唤醒的滚动日志数据结构,因为这种结构不会导致占用的空间持续变大,而且写入效率也最高。
通过wal日志切换,这样可以避免产生单独的过大的wal日志文件,这样可以方便后续的日志清理(可以将过期日志文件直接删除)另外如果需要使用日志进行恢复时,也可以同时解析多个小的日志文件,缩短恢复所需时间。
WAL的检查间隔由hbase.regionserver.logroll.period定义,默认值是一个小时。检查的内容是把当前WAL中的操作跟实际持久化到HDFS上的操作做比较,看哪些操作已经被持久化了,如果已经被持久化了,该WAL就会被移动到HDFS上的.oldlogs文件夹下。
一个WAL实例包含多个WAL文件。WAL文件的最大数量可以手动通过参数配置。
其它的触发滚动的条件是:
- WAL的大小超过了一定的阈值。
- WAL文件所在的HDFS文件块快要满了。
3.4.4 WAL归档和删除
归档:WAL创建出来的文件都会放在/hbase/.log下,在WAL文件被定为归档时,文件会被移动到/hbase/.oldlogs下
删除:判断:是否此WAL文件不再需要,是否没有被其他引用指向这个WAL文件
会引用此文件的服务:
- TTL进程:该进程会保证WAL文件一直存活直到达到hbase.master.logcleaner.ttl定义的超时时间(默认10分钟)为止。
- 备份(replication)机制:如果你开启了HBase的备份机制,那么HBase要保证备份集群已经完全不需要这个WAL文件了,才会删除这个WAL文件。这里提到的replication不是文件的备份数,而是0.90版本加入的特性,这个特性用于把一个集群的数据实时备份到另外一个集群。如果你的手头就一个集群,可以不用考虑这个因素。
只有当该WAL文件没有被以上两种情况引用的时候,才会被系统彻底清除掉。
3.5 Store
解释完了WAL,放大一下Store的内部架构:
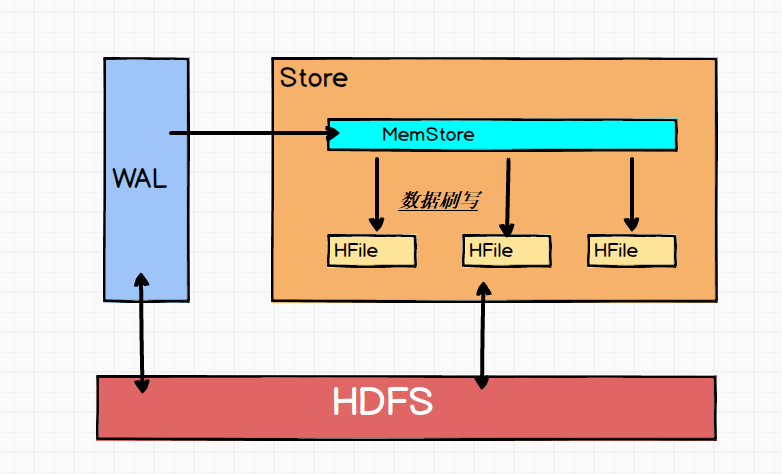
Store有两个重要的部分:
- MemStore:每个Store都有一个MemStore实例。数据写入到WAL之后就会被放入MemStore中。MemStore是内存的存储对象,只有到达一定的时机才会被刷写到HFile中去。什么时机呢?后边详细说明,这篇笔记主要记录架构方面的内容。
- HFile:在Store中有多个HFile,每次刷写都会形成一个HFile文件落盘在HDFS上。HFile直接跟HDFS打交道,它是数据存储的实体。
这里提出一点疑问:
客户端的操作到达Region时,先将数据写到WAL中,而WAL是存储在HDFS上的。所以就相当于数据已经持久化了,那么为什么还要从WAL加载到MemStore中,再刷写形成HFile存到HDFS上呢?
简单的说就是:数据进入HFile之前就已经被持久化了,为什么还要放入MemStore?
这是因为HDFS支持文件的创建、追加、删除,但是不能修改。对于一个数据库来说,数据的顺序是非常重要的。第一次WAL的持久化是为了保证数据的安全性,无序的。再读取到MemStore中,是为了排序后存储。所以MemStore的意义在于维持数据按照rowkey的字典序排列,而不是做一个缓存提高写入效率。
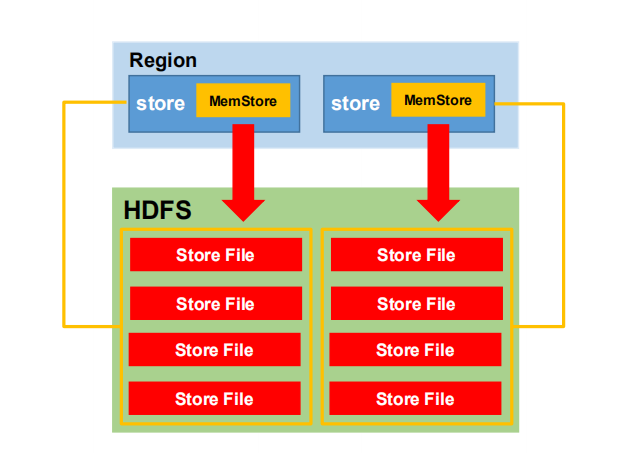
补一张图,对比着来看,关于MemStore刷写:
参考资料:
[1] 李海波. 大数据技术之HBase
[2] 杨曦. HBase不睡觉书
HBase学习笔记(四)—— 架构模型的更多相关文章
- HBASE学习笔记(四)
这两天把要前几天的知识点回顾一下,接下来我会用自己对知识点的理解来写一些东西 一.知识点回顾 1.hbase集群启动:$>start-hbase.sh ===>hbase-daemon.s ...
- SpringMVC 学习笔记(四) 处理模型数据
Spring MVC 提供了下面几种途径输出模型数据: – ModelAndView: 处理方法返回值类型为 ModelAndView时, 方法体就可以通过该对象加入模型数据 – Map及Model: ...
- C#可扩展编程之MEF学习笔记(四):见证奇迹的时刻
前面三篇讲了MEF的基础和基本到导入导出方法,下面就是见证MEF真正魅力所在的时刻.如果没有看过前面的文章,请到我的博客首页查看. 前面我们都是在一个项目中写了一个类来测试的,但实际开发中,我们往往要 ...
- ArcGIS模型构建器案例学习笔记-字段处理模型集
ArcGIS模型构建器案例学习笔记-字段处理模型集 联系方式:谢老师,135-4855-4328,xiexiaokui@qq.com 由四个子模型组成 子模型1:判断字段是否存在 方法:python工 ...
- 官网实例详解-目录和实例简介-keras学习笔记四
官网实例详解-目录和实例简介-keras学习笔记四 2018-06-11 10:36:18 wyx100 阅读数 4193更多 分类专栏: 人工智能 python 深度学习 keras 版权声明: ...
- ensorflow学习笔记四:mnist实例--用简单的神经网络来训练和测试
http://www.cnblogs.com/denny402/p/5852983.html ensorflow学习笔记四:mnist实例--用简单的神经网络来训练和测试 刚开始学习tf时,我们从 ...
- Java IO学习笔记四:Socket基础
作者:Grey 原文地址:Java IO学习笔记四:Socket基础 准备两个Linux实例(安装好jdk1.8),我准备的两个实例的ip地址分别为: io1实例:192.168.205.138 io ...
- HBase学习(四) 二级索引 rowkey设计
HBase学习(四) 一.HBase的读写流程 画出架构 1.1 HBase读流程 Hbase读取数据的流程:1)是由客户端发起读取数据的请求,首先会与zookeeper建立连接2)从zookeepe ...
- IOS学习笔记(四)之UITextField和UITextView控件学习
IOS学习笔记(四)之UITextField和UITextView控件学习(博客地址:http://blog.csdn.net/developer_jiangqq) Author:hmjiangqq ...
- java之jvm学习笔记四(安全管理器)
java之jvm学习笔记四(安全管理器) 前面已经简述了java的安全模型的两个组成部分(类装载器,class文件校验器),接下来学习的是java安全模型的另外一个重要组成部分安全管理器. 安全管理器 ...
随机推荐
- 学linux内核与学linux操作系统有什么区别!?
linux内核包括:进程管理,存储管理,IO管理,文件系统等功能.linux操作系统则是linux内核再加上像shell或图形界面和其他的实用软件,比内核庞大的多.建议先学shell命令和linux下 ...
- 基于LIVE555的RTSP QoS实现
如何从OnDemandServerMediaSubsession类以及继承类对象中获取RTCP信息(句柄) OnDemandServerMediaSubsession.cpp void StreamS ...
- linux下oracle查询中文乱码
export NLS_LANG=AMERICAN_AMERICA.UTF8
- torch.optim优化算法理解之optim.Adam()
torch.optim是一个实现了多种优化算法的包,大多数通用的方法都已支持,提供了丰富的接口调用,未来更多精炼的优化算法也将整合进来. 为了使用torch.optim,需先构造一个优化器对象Opti ...
- 有什么类方法或是函数可以查看某个项目的Laravel版本的?
查看composer.json文件: "require": { "php": ">=7.0.0", "fideloper/p ...
- jq常用动画fade slide
https://www.cnblogs.com/sandraryan/ hide(); <div class="box">big box</div> $(' ...
- POJ 2488 深搜dfs、
题意:模拟国际象棋中马的走棋方式,其实和中国象棋的马走的方式其实是一样的,马可以从给定的方格棋盘中任意点开始,问是否能遍历全部格子,能的话输出字典序最小的走棋方式,否则输出impossible 思路: ...
- Native memory allocation (mmap) failed to map 142606336 bytes for committing reserved memory.
这里写链接内容 问题描述 Java程序运行过程中抛出java.lang.OutOfMemoryError: unable to create new native thread,如下所示: [java ...
- 查看laravel版本
方法1: 使用php artisan --version ,只要能看懂这个命令的人一定已经具有初步的Laravel知识.再介绍一种不需要命令,直接去文件中去查看的方法. 方法2: 在项目文件中找ven ...
- windows服务器运维日常--防火墙打开后ping不通
1. 打开防火墙,有利于安全 2. 添加80端口,支持互联网访问:添加3389端口,以支持远程桌面连接 3. 发现开了防火墙之后,ping不通网址www.mjywxy.xin 4. 查找资料和测试发现 ...