《C# 爬虫 破境之道》:第二境 爬虫应用 — 第五节:小总结带来的优化与重构
在上一节中,我们完成了一个简单的采集示例。本节呢,我们先来小结一下,这个示例可能存在的问题:
- 没有做异常处理
- 没有做反爬应对策略
- 没有做重试机制
- 没有做并发限制
- ……
呃,看似平静的表面下还是隐藏着不少杀机的……
但本节不打算对付上述问题,而是先关注一个隐藏更深的问题,这个问题,可能会牵扯很多人(包括我☹,不包括我☺,包括我☹,不包括我☺)的编程习惯问题。
这里提出一个突出的问题,就是堆栈溢出的问题。
首先,我们以上一节的示例为例,解析一下造成的原因,下图演示了一个内容采集的游走路径,也就是调用过程:

可以看出,方法之间存在着比较明显的依赖关系,也就是说,只有下一级方法执行完毕了,上一级方法才能完成执行,虽然其间,有部分异步方法,但总体来说,还是会有依赖存在。这就造成了堆栈积压,也就是一个方法没有执行完,另一个方法又压入栈中,然后又压入一个,又一个……又一个……最终,就会导致堆栈溢出。
示例的场景应当说是最为简单的,这种依赖还不算严重,但如果量级上来的话,也会是不小的一张关系网,而且被压入堆栈的,不仅仅是这几个方法所占的空间,还有可能会导致这个方法所涉及的类的实例以及其内部一些其他资源都无法被释放,而系统又不得不“保留”这张网,GC也拿它毫无办法(因为引用表都在)。再如果场景更复杂一些,可能一个验证码所需的依赖关系就要比本示例更为严重,再加上后续的流程层级多一些,再加上持久化等处理器的引入、分支结构的增加等等,相应的场景越复杂,耦合度就会越来越高,那对系统的影响将是毁灭性的。
相通的理论,有兴趣的同学,可以查询“递归所带来的问题”,以了解更多。而且这个问题的存在,可不是仅仅存在于爬虫系统中,它存在于我们日常编写的每一行代码中。它与语言无关、与业务无关,稍有不慎,就会留下这么个坑。很可怕,这也是为什么要专门拿出一节来说这个问题。
那么,是什么造成了这种耦合呢?其实,这也是由于“正常”的思维方式所引发的。拿示例来说,我们需要得到书籍列表,才能得到书籍ID,需要得到书籍ID,才能拼接出书籍章节列表的链接,需要得到书籍ID和章节ID,才能拼接出章节内容的链接,所以,理所当然的,就产生了依赖。
另外,当我们在Start方法和Analize方法内部发生错误时,最简单的“重试”方案时什么,就是再次执行Start方法嘛,好么,这种重试,有可能是1次,也有可能是N次,碰到服务器挂掉了,那么就会是永无休止的重试。这种情况造成的堆栈积压可要比一般的N级树带来的毁灭性更大。
了解了问题的严重性以及产生的原因,然后,我们尝试给出一个解决方案,解决这个问题的关键,就在于如何能够打破这个方法间的耦合。
这里,我们举一个生活中的栗子,假设,我是一个轻奢份子,自己不做饭,饿了,就下馆子,这样,我就对馆子产生了依赖,从出门去吃饭的那一刻起,我就无法再享受我的宽屏显示器带来的舒适感了,而外卖小哥的出现,有效的缓解了我的病症,下完单,足不出户,就可以继续抱着显示器写文章了。不用关心小哥什么时候去商家取的餐,也不用操心小哥先送谁的后送谁的,就专心写文章,等餐到了,就开吃,完活。
是不是闻到了“异步”的味道?
其实,我们的示例中,已经使用异步解决了从Start到Analize的耦合,那么从Analize到下一个Start之间甚至是发生错误时的重试呢,我们尝试使用另一种方法 —— 队列。
我们把采集列表页中的每一页,看作一个单独的任务,丢到队列里;
我们把采集每一本书的章节列表,看作一个单独的任务,丢到队列里;
我们把采集每一本书的每一个章节内容,看作一个单独的任务,丢到队列里;
当队列中的任务被执行,又没有执行成功时,就把这个任务再次丢到队列里;(重试)
队列中的任务都是散列的,之间都没有依赖关系,队列可以采用先进先出(FIFO)或后进先出(LIFO)原则来执行,问题不大。这样就可以有效避免了之前提出的堆栈溢出的问题。同时,我们还可以通过控制队列的大小,来限制并发量,一石二鸟:)再加上进入时间为度,还可以对并发频率做限制,一箭三雕:)
好了,既然已经有了解决方案,那么就来对我们的爬虫框架进行一次重构吧:)
第一步,我们在爬虫框架中新创建一个小蚂蚁的领队(LeaderAnt)类:
namespace MikeWare.Core.Components.CrawlerFramework
{
using System;
using System.Collections.Concurrent;
using System.Collections.Generic;
using System.Threading;
using System.Threading.Tasks; public class LeaderAnt : Ant
{
public virtual ConcurrentQueue<JobContext> Queue { get; set; }
private ManualResetEvent mre = new ManualResetEvent(false);
//private List<WorkerAnt> workers = new List<WorkerAnt>(); public void Work()
{
JobContext context = null; do
{
if (Queue.TryDequeue(out context))
{
CreateWorker(context).Work(context);
}
} while (!mre.WaitOne());
} private WorkerAnt CreateWorker(JobContext context)
{
return
new WorkerAnt()
{
AntId = (uint)Math.Abs(DateTime.Now.ToString("yyyyMMddHHmmssfff").GetHashCode()),
OnJobStatusChanged = (sender, args) =>
{
//Console.WriteLine($"{args.EventAnt.AntId} said: {args.Context.JobName} entered status '{args.Context.JobStatus}'.");
switch (args.Context.JobStatus)
{
case TaskStatus.Created:
//if (string.IsNullOrEmpty(args.Context.JobName))
//{
// Console.WriteLine($"Can not execute a job with no name.");
// args.Cancel = true;
//}
//else
// Console.WriteLine($"{args.EventAnt.AntId.ToString("000000000")} said: job {args.Context.JobName} created.");
break;
case TaskStatus.Running:
//if (null != args.Context.Memory)
// Console.WriteLine($"{args.EventAnt.AntId} said: {args.Context.JobName} already downloaded {args.Context.Memory.Length} bytes.");
break;
case TaskStatus.RanToCompletion:
if (null != args.Context.Buffer && < args.Context.Buffer.Length)
args.Context.Analizer.Analize(this, args.Context);
if (null != args.Context.Watch)
Console.WriteLine($"{args.EventAnt.AntId.ToString("")} said: job {args.Context.JobName} Finished using {(args.Context.Watch.Elapsed.TotalMilliseconds / 100).ToString("000.00")}ms / request ******************** */{Environment.NewLine + Environment.NewLine}");
break;
case TaskStatus.Faulted:
Console.WriteLine($"{args.EventAnt.AntId} said: job {args.Context.JobName} faulted because {args.Message}.");
Queue.Enqueue(args.Context);
break;
case TaskStatus.WaitingToRun:
case TaskStatus.WaitingForChildrenToComplete:
case TaskStatus.Canceled:
case TaskStatus.WaitingForActivation:
default:/* Do nothing on this even. */
break;
}
},
};
}
}
}
领队 -- LeaderAnt 类
在这个类中,声明了一个任务队列(ConcurrentQueue<JobContext> Queue),用来提供一个任务池;
一个干活方法(Work),负责从队列中取出任务,并分配给WorkerAnt,支配工蚁去干活~
一个创建工蚁方法(CreateWorker),负责根据任务上下文创建一只小工蚁;这样,我们就无需在业务层直接与工蚁打交道了,只需要往领队的任务池里丢任务就可以了;
领队在创建工蚁的时候,还指定了一项状态监控功能,当任务失败时,就把任务重新丢回任务池,尝试再次执行该任务:
case TaskStatus.Faulted:
Console.WriteLine($"{args.EventAnt.AntId} said: job {args.Context.JobName} faulted because {args.Message}.");
Queue.Enqueue(args.Context);
break;
第二步,我们在爬虫框架中又新增了一个解析器的抽象类:
namespace MikeWare.Core.Components.CrawlerFramework
{
using System; public abstract class ACrawlerAnalizer
{
public virtual void Analize(LeaderAnt leader, JobContext context) => throw new NotImplementedException();
}
}
解析器类 -- ACrawlerAnalizer
这个类是一个抽象类,只提供了一个抽象方法Analize。主要用于实际业务去实现不同的业务节点的解析器,将关注点分离出去;
还是上一节使用的示例,我们在业务层重新提供了三个解析器类型:
namespace MikeWare.Crawlers.EBooks.Bizs
{
using MikeWare.Core.Components.CrawlerFramework;
using MikeWare.Crawlers.EBooks.Entities;
using System;
using System.Collections.Generic;
using System.Net;
using System.Text;
using System.Text.RegularExpressions; public class BooksListAnalizer : ACrawlerAnalizer
{
private static Encoding encoding = new UTF8Encoding(false);
private static int total_page = -;
private static Regex regex_list = new Regex(@"<li>[^<]+<div.*?更新:(?<updateTime>\d+?-\d+?-\d+?)[^\d].+?<a[^/]+?/Shtml(?<id>\d+?)\.html.+?</li>", RegexOptions.Singleline);
private static Regex regex_page = new Regex(@"<div class=""tspage"">.+?<a href='/s/new/index_(?<totalPage>\d+?).html'>尾页</a>.+?</div>", RegexOptions.Singleline); public override void Analize(LeaderAnt leader, JobContext context)
{
if (null == context.InParams) return; var data = context.Buffer;
if (null == data || == data.Length) return; var content = encoding.GetString(data);
var matches = regex_list.Matches(content);
if (!context.InParams.ContainsKey(Consts.LAST_UPDATE_TIME) || null == context.InParams[Consts.LAST_UPDATE_TIME]) return; if (null != matches && < matches.Count)
{
var lastUpdateTime = DateTime.MinValue;
if (!DateTime.TryParse(context.InParams[Consts.LAST_UPDATE_TIME].ToString(), out lastUpdateTime))
return; var update_time = DateTime.MinValue;
var bookId = ;
foreach (Match match in matches)
{
if (!DateTime.TryParse(match.Groups["updateTime"].Value, out update_time)
|| !int.TryParse(match.Groups["id"].Value, out bookId)) continue; if (update_time > lastUpdateTime)
{
var newContext = new JobContext
{
JobName = "“奇书网-电子书-章节列表”",
Uri = $"http://www.xqishuta.com/du/{bookId / 1000}/{bookId}/",
Method = WebRequestMethods.Http.Get,
InParams = new Dictionary<string, object>(),
Analizer = new BookSectionsListAnalizer(),
};
newContext.InParams.Add(Consts.LAST_UPDATE_TIME, context.InParams[Consts.LAST_UPDATE_TIME]);
newContext.InParams.Add(Consts.BOOK_ID, bookId);
leader.Queue.Enqueue(newContext);
}
else
return;
}
} if (- == total_page)
{
var match = regex_page.Match(content);
if (null != match && match.Success && int.TryParse(match.Groups["totalPage"].Value, out total_page)) ; } var pageIndex = -;
if (!context.InParams.ContainsKey(Consts.PAGE_INDEX) || null == context.InParams[Consts.PAGE_INDEX]
|| !int.TryParse(context.InParams[Consts.PAGE_INDEX].ToString(), out pageIndex)) return; if (pageIndex < total_page)
{
pageIndex++;
var newContext = new JobContext
{
JobName = $"奇书网-最新电子书-列表-第{pageIndex.ToString("")}页",
Uri = $"http://www.xqishuta.com/s/new/index_{pageIndex}.html",
Method = WebRequestMethods.Http.Get,
InParams = new Dictionary<string, object>(),
Analizer = new BooksListAnalizer(),
};
newContext.InParams.Add(Consts.PAGE_INDEX, pageIndex);
newContext.InParams.Add(Consts.LAST_UPDATE_TIME, context.InParams[Consts.LAST_UPDATE_TIME]); leader.Queue.Enqueue(newContext);
}
}
}
}
电子书列表解析器 -- BooksListAnalizer
namespace MikeWare.Crawlers.EBooks.Bizs
{
using MikeWare.Core.Components.CrawlerFramework;
using MikeWare.Crawlers.EBooks.Entities;
using System;
using System.Collections.Generic;
using System.Net;
using System.Text;
using System.Text.RegularExpressions; public class BookSectionsListAnalizer : ACrawlerAnalizer
{
private static Encoding encoding = new UTF8Encoding(false);
private static Regex regex_section_list = new Regex(@"(?<=<div[^>]+>[^<]+<p[^>]+>[^<]+?正文</p>.+?)(<li><a[^\d]+?(?<section_id>\d+?)\.html[^>]*?>(?<section_name>[^<]+?)</a></li>[^<]+?)+?(?=<)", RegexOptions.Singleline);
private static Regex regex_book_info = new Regex(@"<img src=""(?<photo>[^""]+)"" onerror=""[^""]+""/>"
+ @".+?<div class=""info_des"">"
+ @".+?<h1>(?<name>[^<]+)</h1>"
+ @".+?<dl>作 者:(?<author>[^<]+)</dl>"
+ @".+?<dl>最后更新:(?<updateTime>[^<]+)</dl>", RegexOptions.Singleline); public override void Analize(LeaderAnt leader, JobContext context)
{
if (null == context.InParams) return; var data = context.Buffer;
if (null == data || == data.Length)
return; var content = encoding.GetString(data); var bookId = -;
if (!context.InParams.ContainsKey(Consts.BOOK_ID)
|| !int.TryParse(context.InParams[Consts.BOOK_ID].ToString(), out bookId))
return; var book = new Book { Id = bookId };
var book_info_match = regex_book_info.Match(content);
if (null != book_info_match && book_info_match.Success)
{
book.Name = book_info_match.Groups["name"].Value.Trim();
book.Author = book_info_match.Groups["author"].Value.Trim();
book.PhotoUrl = @"http://www.xqishuta.com" + book_info_match.Groups["photo"].Value;
var lastUpdateTime = DateTime.Now;
if (DateTime.TryParse(book_info_match.Groups["updateTime"].Value.Trim(), out lastUpdateTime))
book.LastUpdateTime = lastUpdateTime;
} var matches = regex_section_list.Matches(content);
if (null != matches && < matches.Count)
{
book.Sections = new Dictionary<int, string>();
var section_id = ;
foreach (Match match in matches)
{
if (!int.TryParse(match.Groups["section_id"].Value, out section_id)) continue; if (!book.Sections.ContainsKey(section_id))
book.Sections.Add(section_id, null);
book.Sections[section_id] = match.Groups["section_name"].Value.Trim(); var newContext = new JobContext
{
JobName = $"“奇书网-电子书-{section_id}章节内容”",
Uri = $"http://www.xqishuta.com/du/{book.Id / 1000}/{book.Id}/{section_id}.html",
Method = WebRequestMethods.Http.Get,
InParams = new Dictionary<string, object>(),
Analizer = new BookSectionAnalizer(),
}; newContext.InParams.Add(Consts.LAST_UPDATE_TIME, context.InParams[Consts.LAST_UPDATE_TIME]);
newContext.InParams.Add(Consts.BOOK_ID, bookId);
newContext.InParams.Add(Consts.BOOK_SECTION_ID, section_id);
newContext.InParams.Add(Consts.BOOK, book); leader.Queue.Enqueue(newContext);
}
}
}
}
}
章节列表解析器 -- BookSectionsListAnalizer
namespace MikeWare.Crawlers.EBooks.Bizs
{
using MikeWare.Core.Components.CrawlerFramework;
using MikeWare.Crawlers.EBooks.Entities;
using System.Collections.Generic;
using System.IO;
using System.Text;
using System.Text.RegularExpressions; public class BookSectionAnalizer : ACrawlerAnalizer
{
private static Encoding encoding = new UTF8Encoding(false);
private static Regex regex_section_content = new Regex(@"(?<=<div[^""]+""content1"">)(?<content>.+?)(?=(<p [^<]+</p>)?</div>)", RegexOptions.Singleline);
private static Regex regex_html_tag = new Regex(@"(<(\w+?)[^>]+>[^<>]+?</\2>)|(<(\w+?)[^/>]+/>)|&[^;]+;"); public override void Analize(LeaderAnt leader, JobContext context)
{
if (null == context.InParams) return; var content = encoding.GetString(context.Buffer);
var match = regex_section_content.Match(content); if (null != match && match.Success)
{
if (!context.InParams.ContainsKey(Consts.BOOK) || null == context.InParams[Consts.BOOK])
return; var section_id = -; if (!context.InParams.ContainsKey(Consts.BOOK_SECTION_ID)
|| !int.TryParse(context.InParams[Consts.BOOK_SECTION_ID].ToString(), out section_id))
return; content = regex_html_tag.Replace(match.Groups["content"].Value, string.Empty);
var builder = new StringBuilder();
using (var reader = new StringReader(content))
{
while ( < reader.Peek())
{
var line = reader.ReadLine().Trim();
if (!string.IsNullOrEmpty(line)) builder.AppendLine(line);
}
} var book = context.InParams[Consts.BOOK] as Book;
if (null == book.SectionContents) book.SectionContents = new Dictionary<int, string>(); if (!book.SectionContents.ContainsKey(section_id)) book.SectionContents[section_id] = builder.ToString();
builder.Clear();
} //Console.WriteLine(book.SectionContents[sectionId]);
//Console.WriteLine($"{book.Id} - {sectionId} Finished.");
}
}
}
章节内容解析器 -- BookSectionAnalizer
解析器一方面的职责呢,就是解析下载下来的数据,另一方面呢,也根据解析结果,来拼凑出下一步任务,指定该任务的必要如参和对应的解析器,并丢到任务池中。这样,解析器和下一步任务的执行就解开耦合。
在解析器中也提供了一个修改任务参数的机会,我们甚至可以对任务的参数进行任意的排列组合;
同时,在一个解析器中,也可以产生多个子任务;比如,我们在BooksListAnalizer中,一方面产生了采集书籍章节列表的任务,另一方面呢,又产生了采集翻页的任务;
还有其他一些重构的零碎的小点,就不一一列出了。
这里,在抛出一个小问题,如下图所示:
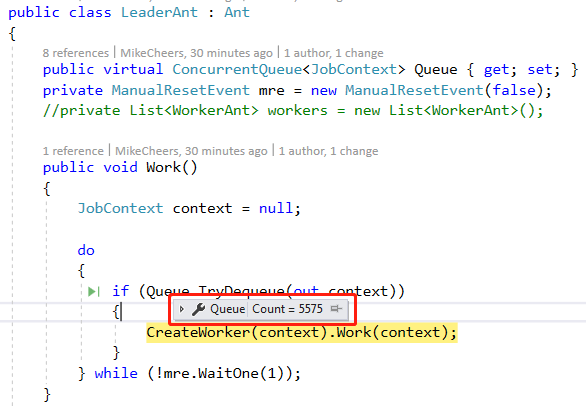
当我们运行几十秒之后,观察一下队列,发现它很长,这是为什么呢,怎么应对呢?我们下节继续,如何制定一些并发策略:)
喜欢本系列丛书的朋友,可以点击链接加入QQ交流群(994761602)【C# 破境之道】
方便各位在有疑问的时候可以及时给我个反馈。同时,也算是给各位志同道合的朋友提供一个交流的平台。
需要源码的童鞋,也可以在群文件中获取最新源代码。
《C# 爬虫 破境之道》:第二境 爬虫应用 — 第五节:小总结带来的优化与重构的更多相关文章
- Python爬虫实践 -- 记录我的第二只爬虫
1.爬虫基本原理 我们爬取中国电影最受欢迎的影片<红海行动>的相关信息.其实,爬虫获取网页信息和人工获取信息,原理基本是一致的. 人工操作步骤: 1. 获取电影信息的页面 2. 定位(找到 ...
- 《C# 爬虫 破境之道》:第二境 爬虫应用 — 第二节:以事件驱动状态、数据处理
续上一节内容,对Web爬虫进行进一步封装,通过委托将爬虫自己的状态变化以及数据变化暴露给上层业务处理或应用程序. 为了方便以后的扩展,我先定义一个蚂蚁抽象类(Ant),并让WorkerAnt(工蚁)继 ...
- 《C# 爬虫 破境之道》:第二境 爬虫应用 — 第一节:HTTP协议数据采集
首先欢迎您来到本书的第二境,本境,我们将全力打造一个实际生产环境可用的爬虫应用了.虽然只是刚开始,虽然路漫漫其修远,不过还是有点小鸡冻:P 本境打算针对几大派生类做进一步深耕,包括与应用的结合.对比它 ...
- 《C# 爬虫 破境之道》:第二境 爬虫应用 — 第三节:处理压缩数据
续上一节内容,本节主要讲解一下Web压缩数据的处理方法. 在HTTP协议中指出,可以通过对内容压缩来减少网络流量,从而提高网络传输的性能. 那么问题来了,在HTTP中,采用的是什么样的压缩格式和机制呢 ...
- 《C# 爬虫 破境之道》:第一境 爬虫原理 — 第二节:WebRequest
本节主要来介绍一下,在C#中制造爬虫,最为常见.常用.实用的基础类 ------ WebRequest.WebResponse. 先来看一个示例 [1.2.1]: using System; usin ...
- 《C# 爬虫 破境之道》:第二境 爬虫应用 — 第四节:小说网站采集
之前的章节,我们陆续的介绍了使用C#制作爬虫的基础知识,而且现在也应该比较了解如何制作一只简单的Web爬虫了. 本节,我们来做一个完整的爬虫系统,将之前的零散的东西串联起来,可以作为一个爬虫项目运作流 ...
- 《C# 爬虫 破境之道》:第二境 爬虫应用 — 第六节:反爬策略研究
之前的章节也略有提及反爬策略,本节,我们就来系统的对反爬.反反爬的种种,做一个了结. 从防盗链说起: 自从论坛兴起的时候,网上就有很多人会在论坛里发布一些很棒的文章,与当下流行的“点赞”“分享”一样, ...
- 《C# 爬虫 破境之道》:第二境 爬虫应用 — 第七节:并发控制与策略
我们在第五节中提到一个问题,任务队列增长速度太快,与之对应的采集.分析.处理速度远远跟不上,造成内存快速增长,带宽占用过高,CPU使用率过高,这样是极度有害系统健康的. 我们在开发采集程序的时候,总是 ...
- 《C# 爬虫 破境之道》:第一境 爬虫原理 — 第六节:第一境尾声
在第一境中,我们主要了解了爬虫的一些基本原理,说原理也行,说基础知识也罢,结果就是已经知道一个小爬虫是如何诞生的了~那么现在,请默默回想一下,在第一境中,您都掌握了哪些内容?哪些还比较模糊?如果还有什 ...
随机推荐
- Linux学习_菜鸟教程_4
Linux远程登录 已经了解了登录流程,学会了用SecureCRT进行操作 Linux文件基本属性 Linux为保护系统安全,对不同的用户,开放不同的文件访问权限. 在linux中,我们可以使用ll或 ...
- linux常用命令,最基础
rmdir keda1/ 6 touch test.java 创建空文件 7 拷贝文件 cp 源文件 目标文件 cp test.java test1.java 8 删除文件rm -r 递归删除 -rf ...
- [转载] Windows系统批处理延迟方法
小贴士:方法四 亲测有效,因为当时对于精确度要求不是很高,所以没有具体测试它的精确度.其他方法没有测过,用到的时候再测吧! 批处理延时启动的几个方法 方法一:ping 缺点:时间精度为1秒,不够精确 ...
- input值
input里面的值为字符串(string)类型,所以用作数的计算的时候需要用Number(mInput.value)进行转换成数值Numbei()类型才可以计算 例如: mInput1.value + ...
- 【转】Java面试题:多继承
招聘和面试对开发经理来说是一个无尽头的工作,虽然有时你可以从HR这边获得一些帮助,但是最后还是得由你来拍板,或者就像另一篇文章“Java 面试题:写一个字符串的反转”所说: 面试开发人员不仅辛苦而且乏 ...
- Java小白集合源码的学习系列:ArrayList
ArrayList源码学习 本文基于JDK1.8版本,对集合中的巨头ArrayList做一定的源码学习,将会参考大量资料,在文章后面都将会给出参考文章链接,本文用以巩固学习知识. ArrayList的 ...
- 匈牙利算法(Kuhn-Munkres)算法
这个算法有点难度,一般比较标准的描述网页上也有相关的描述,我在这里就简单的用十分通俗的语言给大家入个门 主要可以结合https://blog.csdn.net/zsfcg/article/detail ...
- 双指针,BFS与图论(一)
(一)双指针 1.日志统计 小明维护着一个程序员论坛.现在他收集了一份”点赞”日志,日志共有 N 行. 其中每一行的格式是: ts id 表示在 ts 时刻编号 id 的帖子收到一个”赞”. 现在小明 ...
- CentOS7安装MySQL、Tomcat和GitBlit记录
一.安装MySQL 1.安装这个发布包 yum localinstall mysql-community-release-el6-5.noarch.rpm 可以通过下面的命令来确认这个仓库被成功添加: ...
- 初入计科,首次接触C的感受
1 你对计算机科学与技术专业了解是怎样? 答:一开始我对这个专业并无了解,觉得无非是把电脑给学透.经过一周的学习后,我深刻地感觉自己对这个专业深深的误解. 通过翻阅书籍,上网浏览相关信息,我认为该专业 ...