基于python2+selenium3+pytest4的UI自动化框架
环境:Python2.7.10, selenium3.141.0, pytest4.6.6, pytest-html1.22.0, Windows-7-6.1.7601-SP1
特点:
- 二次封装了selenium,编写Case更加方便。
- 采用PO设计思想,一个页面一个Page.py,并在其中定义元素和操作方法;在TestCase中直接调用页面中封装好的操作方法操作页面。
- 一次测试只启动一次浏览器,节约时间提高效率(适合公司业务的才是最好的)。
- 增强pytest-html报告内容,加入失败截图、用例描述列、运行日志。
- 支持命令行参数。
- 支持邮件发送报告。
目录结构:
- config
- config.py:存放全局变量,各种配置、driver等
- drive:各浏览器驱动文件,如chromedriver.exe
- file
- download:下载文件夹
- screenshot:截图文件夹
- upload:上传文件夹
- page_object:一个页面一个.py,存放页面对象、操作方法
- base_page.py:基础页面,封装了selenium的各种操作
- hao123_page.py:hao123页面
- home_page.py:百度首页
- news_page.py:新闻首页
- search_page.py:搜索结果页
- report:
- report.html:pytest-html生成的报告
- test_case
- conftest.py:pytest特有文件,在里面增加了报告失败截图、用例描述列
- test_home.py:百度首页测试用例
- test_news.py:新闻首页测试用例
- test_search.py:搜索结果页测试用例
- util:工具包
- log.py:封装了日志模块
- mail.py:封装了邮件模块,使用发送报告邮件功能需要先设置好相关配置,如用户名密码
- run.py:做为运行入口,封装了pytest运行命令;实现所有测试用例共用一个driver;实现了运行参数化(结合Jenkins使用);log配置初始化;可配置发送报告邮件。
代码实现:
# coding=utf-8 import os def init():
global _global_dict
_global_dict = {} # 代码根目录
root_dir = os.getcwd() # 存放程序所在目录
_global_dict['root_path'] = root_dir
# 存放正常截图文件夹
_global_dict['screenshot_path'] = "{}\\file\\screenshot\\".format(root_dir)
# 下载文件夹
_global_dict['download_path'] = "{}\\file\\download\\".format(root_dir)
# 上传文件夹
_global_dict['upload_path'] = "{}\\file\\upload\\".format(root_dir)
# 存放报告路径
_global_dict['report_path'] = "{}\\report\\".format(root_dir) # 保存driver
_global_dict['driver'] = None # 设置运行环境网址主页
_global_dict['site'] = 'https://www.baidu.com/'
# 运行环境,默认preview,可设为product
_global_dict['environment'] = 'preview' def set_value(name, value):
"""
修改全局变量的值
:param name: 变量名
:param value: 变量值
"""
_global_dict[name] = value def get_value(name, def_val='no_value'):
"""
获取全局变量的值
:param name: 变量名
:param def_val: 默认变量值
:return: 变量存在时返回其值,否则返回'no_value'
"""
try:
return _global_dict[name]
except KeyError:
return def_val
config.py
定义了全局的字典,用来存放全局变量,其key为变量名,value为变量值,可跨文件、跨用例传递参数。
其中set_value、get_value分别用来存、取全局变量。
# coding=utf-8 import logging
import time
import config.config as cf class Logger(object):
"""封装的日志模块""" def __init__(self, logger, cmd_level=logging.DEBUG, file_level=logging.DEBUG):
try:
self.logger = logging.getLogger(logger)
self.logger.setLevel(logging.DEBUG) # 设置日志输出的默认级别
'''pytest报告可以自动将log整合进报告,不用再自己单独设置保存
# 日志输出格式
fmt = logging.Formatter(
'%(asctime)s[%(levelname)s]\t%(message)s')
# 日志文件名称
curr_time = time.strftime("%Y-%m-%d %H.%M.%S")
log_path = cf.get_value('log_path')
self.log_file = '{}log{}.txt'.format(log_path, curr_time)
# 设置控制台输出
sh = logging.StreamHandler()
sh.setFormatter(fmt)
sh.setLevel(cmd_level)
# 设置文件输出
fh = logging.FileHandler(self.log_file)
fh.setFormatter(fmt)
fh.setLevel(file_level)
# 添加日志输出方式
self.logger.addHandler(sh)
self.logger.addHandler(fh)
'''
except Exception as e:
raise e def debug(self, msg):
self.logger.debug(msg) def info(self, msg):
self.logger.info(msg) def error(self, msg):
self.logger.error(msg) def warning(self, msg):
self.logger.warning(msg)
log.py
封装的log模块
# coding=utf-8 import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from email.header import Header
import config.config as cf def send_mail(sendto):
"""
发送邮件
:param sendto:收件人列表,如['22459496@qq.com']
"""
mail_host = 'smtp.sohu.com' # 邮箱服务器地址
username = 'test@sohu.com' # 邮箱用户名
password = 'test' # 邮箱密码
receivers = sendto # 收件人 # 创建一个带附件的实例
message = MIMEMultipart()
message['From'] = Header(u'UI自动化', 'utf-8')
message['subject'] = Header(u'UI自动化测试结果', 'utf-8') # 邮件标题
message.attach(MIMEText(u'测试结果详见附件', 'plain', 'utf-8'))# 邮件正文
# 构造附件
report_root = cf.get_value('report_path') # 获取报告路径
report_file = 'report.html' # 报告文件名称
att1 = MIMEText(open(report_root + report_file, 'rb').read(), 'base64', 'utf-8')
att1["Content-Type"] = 'application/octet-stream'
att1["Content-Disposition"] = 'attachment; filename={}'.format(report_file)
message.attach(att1) try:
smtp = smtplib.SMTP()
smtp.connect(mail_host, 25) # 25为 SMTP 端口号
smtp.login(username, password)
smtp.sendmail(username, receivers, message.as_string())
print u'邮件发送成功'
except Exception, e:
print u'邮件发送失败'
raise e
mail.py
封装的邮件模块,报告HTML文件会做为附件发送,这里需要把最上面的4个变量全改成你自己的。
# coding=utf-8 from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
import os
import inspect
import config.config as cf
import logging
import time log = logging.getLogger('szh.BasePage') class BasePage(object):
def __init__(self):
self.driver = cf.get_value('driver') # 从全局变量取driver def split_locator(self, locator):
"""
分解定位表达式,如'css,.username',拆分后返回'css selector'和定位表达式'.username'(class为username的元素)
:param locator: 定位方法+定位表达式组合字符串,如'css,.username'
:return: locator_dict[by], value:返回定位方式和定位表达式
"""
by = locator.split(',')[0]
value = locator.split(',')[1]
locator_dict = {
'id': 'id',
'name': 'name',
'class': 'class name',
'tag': 'tag name',
'link': 'link text',
'plink': 'partial link text',
'xpath': 'xpath',
'css': 'css selector',
}
if by not in locator_dict.keys():
raise NameError("wrong locator!'id','name','class','tag','link','plink','xpath','css',exp:'id,username'")
return locator_dict[by], value def wait_element(self, locator, sec=30):
"""
等待元素出现
:param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如'css,.username'
:param sec:等待秒数
"""
by, value = self.split_locator(locator)
try:
WebDriverWait(self.driver, sec, 1).until(lambda x: x.find_element(by=by, value=value),
message='element not found!!!')
log.info(u'等待元素:%s' % locator)
return True
except TimeoutException:
return False
except Exception, e:
raise e def get_element(self, locator, sec=60):
"""
获取一个元素
:param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如'css,.username'
:param sec:等待秒数
:return: 元素可找到返回element对象,否则返回False
"""
if self.wait_element(locator, sec):
by, value = self.split_locator(locator)
print by, value
try:
element = self.driver.find_element(by=by, value=value)
log.info(u'获取元素:%s' % locator)
return element
except Exception, e:
raise e
else:
return False def get_elements(self, locator):
"""
获取一组元素
:param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如'css,.username'
:return: elements
"""
by, value = self.split_locator(locator)
try:
elements = WebDriverWait(self.driver, 60, 1).until(lambda x: x.find_elements(by=by, value=value))
log.info(u'获取元素列表:%s' % locator)
return elements
except Exception, e:
raise e def open(self, url):
"""
打开网址
:param url: 网址连接
"""
self.driver.get(url)
log.info(u'打开网址:%s' % url) def clear(self, locator):
"""
清除元素中的内容
:param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如'css,.username'
"""
self.get_element(locator).clear()
log.info(u'清空内容:%s' % locator) def type(self, locator, text):
"""
在元素中输入内容
:param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如'css,.username'
:param text: 输入的内容
"""
self.get_element(locator).send_keys(text)
log.info(u'向元素 %s 输入文字:%s' % (locator, text)) def enter(self, locator):
"""
在元素上按回车键
:param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如'css,.username'
"""
self.get_element(locator).send_keys(Keys.ENTER)
log.info(u'在元素 %s 上按回车' % locator) def click(self, locator):
"""
在元素上单击
:param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如'css,.username'
"""
self.get_element(locator).click()
log.info(u'点击元素:%s' % locator) def right_click(self, locator):
"""
鼠标右击元素
:param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如'css,.username'
"""
element = self.get_element(locator)
ActionChains(self.driver).context_click(element).perform()
log.info(u'在元素上右击:%s' % locator) def double_click(self, locator):
"""
双击元素
:param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如'css,.username'
"""
element = self.get_element(locator)
ActionChains(self.driver).double_click(element).perform()
log.info(u'在元素上双击:%s' % locator) def move_to_element(self, locator):
"""
鼠标指向元素
:param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如'css,.username'
"""
element = self.get_element(locator)
ActionChains(self.driver).move_to_element(element).perform()
log.info(u'指向元素%s' % locator) def drag_and_drop(self, locator, target_locator):
"""
拖动一个元素到另一个元素位置
:param locator: 要拖动元素的定位
:param target_locator: 目标位置元素的定位
"""
element = self.get_element(locator)
target_element = self.get_element(target_locator)
ActionChains(self.driver).drag_and_drop(element, target_element).perform()
log.info(u'把元素 %s 拖至元素 %s' % (locator, target_locator)) def drag_and_drop_by_offset(self, locator, xoffset, yoffset):
"""
拖动一个元素向右下移动x,y个偏移量
:param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如'css,.username'
:param xoffset: X offset to move to
:param yoffset: Y offset to move to
"""
element = self.get_element(locator)
ActionChains(self.driver).drag_and_drop_by_offset(element, xoffset, yoffset).perform()
log.info(u'把元素 %s 拖至坐标:%s %s' % (locator, xoffset, yoffset)) def click_link(self, text):
"""
按部分链接文字查找并点击链接
:param text: 链接的部分文字
"""
self.get_element('plink,' + text).click()
log.info(u'点击连接:%s' % text) def alert_text(self):
"""
返回alert文本
:return: alert文本
"""
log.info(u'获取弹框文本:%s' % self.driver.switch_to.alert.text)
return self.driver.switch_to.alert.text def alert_accept(self):
"""
alert点确认
"""
self.driver.switch_to.alert.accept()
log.info(u'点击弹框确认') def alert_dismiss(self):
"""
alert点取消
"""
self.driver.switch_to.alert.dismiss()
log.info(u'点击弹框取消') def get_attribute(self, locator, attribute):
"""
返回元素某属性的值
:param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如'css,.username'
:param attribute: 属性名称
:return: 属性值
"""
value = self.get_element(locator).get_attribute(attribute)
log.info(u'获取元素 %s 的属性值 %s 为:%s' % (locator, attribute, value))
return value def get_ele_text(self, locator):
"""
返回元素的文本
:param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如'css,.username'
:return: 元素的文本
"""
log.info(u'获取元素 %s 的文本为:%s' % (locator, self.get_element(locator).text))
return self.get_element(locator).text def frame_in(self, locator):
"""
进入frame
:param locator: 定位方法+定位表达式组合字符串,如'css,.username'
"""
e = self.get_element(locator)
self.driver.switch_to.frame(e)
log.info(u'进入frame:%s' % locator) def frame_out(self):
"""
返回主文档
"""
self.driver.switch_to.default_content()
log.info(u'退出frame返回默认文档') def open_new_window_by_locator(self, locator):
"""
点击元素打开新窗口,并将句柄切换到新窗口
:param locator: 定位方法+定位表达式组合字符串,如'css,.username'
"""
self.get_element(locator).click()
self.driver.switch_to.window(self.driver.window_handles[-1])
log.info(u'点击元素 %s 打开新窗口' % locator) # old_handle = self.driver.current_window_handle
# self.get_element(locator).click()
# all_handles = self.driver.window_handles
# for handle in all_handles:
# if handle != old_handle:
# self.driver.switch_to.window(handle) def open_new_window_by_element(self, element):
"""
点击元素打开新窗口,并将句柄切换到新窗口
:param element: 元素对象
"""
element.click()
self.driver.switch_to.window(self.driver.window_handles[-1])
log.info(u'点击元素打开新窗口') def js(self, script):
"""
执行JavaScript
:param script:js语句
"""
self.driver.execute_script(script)
log.info(u'执行JS语句:%s' % script) def scroll_element(self, locator):
"""
拖动滚动条至目标元素
:param locator: 定位方法+定位表达式组合字符串,如'css,.username'
"""
script = "return arguments[0].scrollIntoView();"
element = self.get_element(locator)
self.driver.execute_script(script, element)
log.info(u'滚动至元素:%s' % locator) def scroll_top(self):
"""
滚动至顶部
"""
self.js("window.scrollTo(document.body.scrollHeight,0)")
log.info(u'滚动至顶部') def scroll_bottom(self):
"""
滚动至底部
"""
self.js("window.scrollTo(0,document.body.scrollHeight)")
log.info(u'滚动至底部') def back(self):
"""
页面后退
"""
self.driver.back()
log.info(u'页面后退') def forward(self):
"""
页面向前
"""
self.driver.forward()
log.info(u'页面向前') def is_text_on_page(self, text):
"""
返回页面源代码
:return: 页面源代码
"""
if text in self.driver.page_source:
log.info(u'判断页面上有文本:%s' % text)
return True
else:
log.info(u'判断页面上没有文本:%s' % text)
return False def refresh(self):
"""
刷新页面
"""
self.driver.refresh()
log.info(u'刷新页面') def screenshot(self, info='-'):
"""
截图,起名为:文件名-方法名-注释
:param info: 截图说明
"""
catalog_name = cf.get_value('screenshot_path') # 从全局变量取截图文件夹位置
if not os.path.exists(catalog_name):
os.makedirs(catalog_name)
class_object = inspect.getmembers(inspect.stack()[1][0])[-3][1]['self'] # 获得测试类的object
classname = str(class_object).split('.')[1].split(' ')[0] # 获得测试类名称
testcase_name = inspect.stack()[1][3] # 获得测试方法名称
filepath = catalog_name + classname + "@" + testcase_name + info + ".png"
self.driver.get_screenshot_as_file(filepath)
log.info(u'截图:%s.png' % info) def close(self):
"""
关闭当前页
"""
self.driver.close()
self.driver.switch_to.window(self.driver.window_handles[0])
log.info(u'关闭当前Tab') def sleep(self, sec):
time.sleep(sec)
log.info(u'等待%s秒' % sec)
base_page.py
二次封装了selenium常用操作,做为所有页面类的基类。
本框架支持selenium所有的定位方法,为了提高编写速度,改进了使用方法,定义元素时方法名和方法值为一个用逗号隔开的字符串,如:
- xpath定位:i_keyword = 'xpath,//input[@id="kw"]' # 关键字输入框
- id定位:b_search = 'id,su' # 搜索按钮
- 其他定位方法同上,不再一一举例
使用时如上面代码中type()方法,是在如输入框中输入文字,调用时输入type(i_keyword, "输入内容")
type()中会调用get_element()方法,对输入的定位表达式进行解析,并且会等待元素一段时间,当元素出现时立即进行操作。
另外可以看到每个基本操作都加入了日志,下图即是用例运行后报告中记录的日志
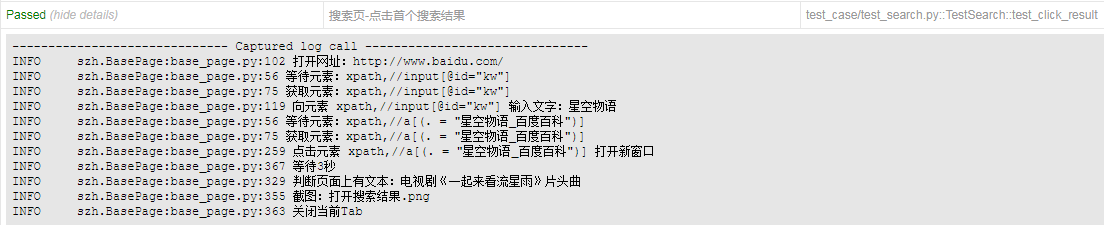
# coding=utf-8 from page_object.base_page import BasePage class SearchPage(BasePage):
def __init__(self, driver):
self.driver = driver # i=输入框, l=链接, im=图片, t=文字控件, d=div, lab=label
# 含_百度百科的搜索结果
l_baike = 'xpath,//a[(. = "星空物语_百度百科")]' # 下一页
b_next_page = 'link,下一页>' # 上一页
b_up_page = 'xpath,//a[(. = "<上一页")]' # 点击搜索结果的百科
def click_result(self):
self.open_new_window_by_locator(self.l_baike)
self.sleep(3) # 点击下一页
def click_next_page(self):
self.click(self.b_next_page)
search_page.py
PO模式中封装的百度的搜索页,继承了上面的BasePage类;每个页面类中上面定义各控件的表达式,下面将页面上的各种操作封装为方法。这样如果在多个用例中调用了控件或操作方法,将来更新维护只需要在页面类中改一下,所有用例就都更新了。
# coding=utf-8 import sys
reload(sys)
sys.setdefaultencoding('utf8')
from page_object.home_page import HomePage
from page_object.search_page import SearchPage
import pytest
import config.config as cf class TestSearch():
"""
pytest:
测试文件以test_开头
测试类以Test开头,并且不能带有__init__方法
测试函数以test_开头
断言使用assert
"""
driver = cf.get_value('driver') # 从全局变量取driver
home_page = HomePage(driver)
search_page = SearchPage(driver) def test_click_result(self):
"""搜索页-点击首个搜索结果"""
try:
self.home_page.open_homepage()
self.home_page.input_keyword(u'星空物语') # 输入关键字
self.search_page.click_result() # 点击百科
assert self.home_page.is_text_on_page(u'电视剧《一起来看流星雨》片头曲') # 验证页面打开
self.home_page.screenshot(u'打开搜索结果')
self.search_page.close() # 关闭百科页面
except Exception, e:
self.home_page.screenshot(u'打开搜索结果失败')
raise e def test_click_next_page(self):
"""搜索页-搜索翻页"""
try:
self.search_page.click_next_page() # 点下一页
assert self.home_page.wait_element(self.search_page.b_up_page) # 上一页出现
self.search_page.scroll_element(self.search_page.b_up_page) # 滚到上一页
self.home_page.screenshot(u'搜索翻页')
except Exception, e:
self.home_page.screenshot(u'搜索翻页失败')
raise e
test_search.py
百度搜索页的测试用例,这里我简单写了2个用例,第1个是搜索后点击首个搜索结果可打开,第2个是搜索结果可翻页。用例中的具体操作均是使用的上面页面类中封装好的操作方法。
# coding=utf-8 import pytest
from py._xmlgen import html
import config.config as cf
import logging log = logging.getLogger('szh.conftest') @pytest.mark.hookwrapper
def pytest_runtest_makereport(item):
"""当测试失败的时候,自动截图,展示到html报告中"""
pytest_html = item.config.pluginmanager.getplugin('html')
outcome = yield
report = outcome.get_result()
extra = getattr(report, 'extra', []) if report.when == 'call' or report.when == "setup":
xfail = hasattr(report, 'wasxfail')
if (report.skipped and xfail) or (report.failed and not xfail):
file_name = report.nodeid.replace("::", "_") + ".png"
driver = cf.get_value('driver') # 从全局变量取driver
screen_img = driver.get_screenshot_as_base64()
if file_name:
html = '<div><img src="data:image/png;base64,%s" alt="screenshot" style="width:600px;height:300px;" ' \
'onclick="window.open(this.src)" align="right"/></div>' % screen_img
extra.append(pytest_html.extras.html(html))
report.extra = extra
report.description = str(item.function.__doc__)#.decode('utf-8', 'ignore') # 不解码转成Unicode,生成HTML会报错
# report.nodeid = report.nodeid.encode("utf-8").decode("unicode_escape") @pytest.mark.optionalhook
def pytest_html_results_table_header(cells):
cells.insert(1, html.th('Description'))
cells.pop() # 删除报告最后一列links @pytest.mark.optionalhook
def pytest_html_results_table_row(report, cells):
cells.insert(1, html.td(report.description))
cells.pop() # 删除报告最后一列links
conftest.py
conftest.py是pytest提供数据、操作共享的文件,其文件名是固定的,不可以修改。
conftest.py文件所在目录必须存在__init__.py文件。
其他文件不需要import导入conftest.py,pytest用例会自动查找
所有同目录测试文件运行前都会执行conftest.py文件
我只在conftest.py中加入了报错截图的功能,如果你有需要在用例前、后执行一些操作,都可以写在这里。
# coding=utf-8 import pytest
import config.config as cf
from util.log import Logger
import argparse
from selenium import webdriver
from util.mail import send_mail def get_args():
"""命令行参数解析"""
parser = argparse.ArgumentParser(description=u'可选择参数:')
parser.add_argument('-e', '--environment', choices=['preview', 'product'], default='preview', help=u'测试环境preview,线上环境product')
args = parser.parse_args()
if args.environment in ('pre', 'preview'):
cf.set_value('environment', 'preview')
cf.set_value('site', 'http://www.baidu.com/')
elif args.environment in ('pro', 'product'):
cf.set_value('environment', 'preview')
cf.set_value('site', 'https://www.baidu.com/')
else:
print u"请输入preview/product"
exit() def set_driver():
"""设置driver"""
# 配置Chrome Driver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--start-maximized') # 浏览器最大化
chrome_options.add_argument('--disable-infobars') # 不提醒chrome正在受自动化软件控制
prefs = {'download.default_directory': cf.get_value('download_path')}
chrome_options.add_experimental_option('prefs', prefs) # 设置默认下载路径
# chrome_options.add_argument(r'--user-data-dir=D:\ChromeUserData') # 设置用户文件夹,可免登陆
driver = webdriver.Chrome('{}\\driver\\chromedriver.exe'.format(cf.get_value('root_path')), options=chrome_options)
cf.set_value('driver', driver) def main():
"""运行pytest命令启动测试"""
pytest.main(['-v', '-s', 'test_case/', '--html=report/report.html', '--self-contained-html']) if __name__ == '__main__':
cf.init() # 初始化全局变量
get_args() # 命令行参数解析
log = Logger('szh') # 初始化log配置
set_driver() # 初始化driver
main() # 运行pytest测试集
cf.get_value('driver').quit() # 关闭selenium driver # 先将util.mail文件send_mail()中的用户名、密码填写正确,再启用发送邮件功能!!!
send_mail(['22459496@qq.com']) # 将报告发送至邮箱
run.py
run.py用来做一些初始化的工作,运行测试,以及测试收尾,具体可以看代码中的注释。
我将浏览器driver的初始化放在了这里,并将driver存入全局变量,这样浏览器只需打开一次即可运行所有的测试。如果你想每个用例都打开、关闭一次浏览器,那可以把定义driver的方法放在conftest.py中。
get_args()是封装的命令行参数解析,方便集成Jenkins时快速定义运行内容。目前只定义了一个环境参数-e, 可设置测试环境preview,线上环境product,你可以根据需要添加更多参数。
调用方法:python run.py -e product
main()封装了pytest的命令行执行模式,你也可以按需修改。
最后放一张运行后的测试报告的截图,我故意将某个用例写错,可以看到,报告中显示了具体的报错信息以及出错时页面的截图
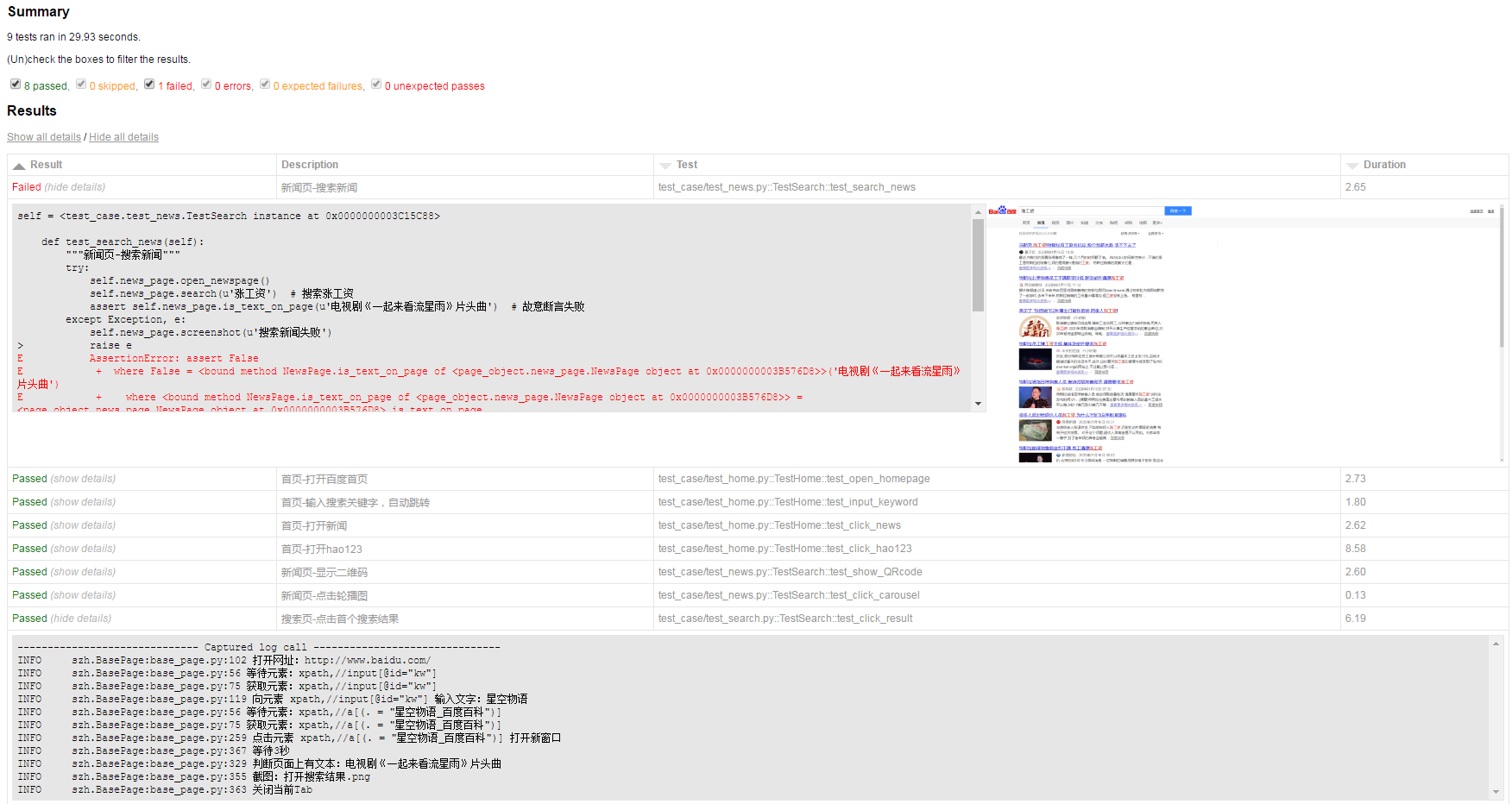
所有代码可去GitHub获取:https://github.com/songzhenhua/selenium_ui_auto
---------------------------------------------------------------------------------
关注微信公众号即可在手机上查阅,并可接收更多测试分享~

基于python2+selenium3+pytest4的UI自动化框架的更多相关文章
- 基于PO和单例设计模式用python+selenium进行ui自动化框架设计
一)框架目录的结构 二)config包当中的config.ini文件主要是用来存项目的绝对路径,是为了后续跑用例和生成测试报告做准备然后目前的配置文件大都会用yaml,ini,excel,还有.py也 ...
- ui自动化笔记 selenium_webdriver,ui自动化框架(web)
Selenium学习笔记 selenium webdriver是业界公认ui自动化测试的标准,其封装的api可以对浏览器的任何地方进行操作 selenium2.0和selenium3.0的区别? 3. ...
- 多测师讲解ui自动化框架设计思想_高级讲师肖sir
UI自动化框架:UI自动化框架可以分为8个模块,conf.data.public.pageobject.testcase.runner.report.log.conf是用来储存系统环境.数据库.邮件的 ...
- UI自动化框架搭建之Python3
UI自动化框架搭建--unittest 使用的代码是Python3版本,与时俱进哈哈 解释一下我的框架目录接口(每个人框架的目录接口不一样,根据实际要求) common目录:公共模块,这个地方可以存放 ...
- ATOMac - 基于Python的Mac应用Ui自动化库
ATOMacTest 一.缘 起 近期工作需要对一款Mac端应用实现常用功能的自动化操作,同事推荐ATOMac这款工具,这几天简单研究了下,同时也发现现网介绍ATOMac的资料非常有限,故在此记录下A ...
- UI 自动化框架设想
测试框架选型: 首先,通过利用TestNG结合csv的使用,将测试用例数据转化为测试代码中的数据,减少了测试人员录入数据和准备数据的工具: 再次,通过对appium的封装,按照面向对象的思想将测试中用 ...
- python+selenium封装UI自动化框架
seleinum框架 框架的思想: 解决我们测试过程中的问题:大量的重复步骤,用自动化来实现 1)配置和程序的分离 2)测试数据和程序的分离 3)不懂编程的人员可以方便使用:使用的 ...
- python2.7+RobotFramework的UI自动化环境搭建
robotFramework是一种比较常见的自动化测试框架,此篇记录环境搭建 目录 1.软件准备 2.执行安装 1.软件准备 python-2.7.15.amd64.msi ...
- 我写的UI自动化框架
---------------------------------------------------------------------------------------------------- ...
随机推荐
- AcWing 220. 最大公约数 | 欧拉函数
传送门 题目描述 给定整数N,求1<=x,y<=N且GCD(x,y)为素数的数对(x,y)有多少对. GCD(x,y)即求x,y的最大公约数. 输入格式 输入一个整数N 输出格式 输出一个 ...
- 20.java-JDBC连接mysql数据库详解
1.JDBC介绍 jdbc(java database connectivity)为java开发者使用数据库提供了统一的编程接口,它由一组java类和接口组成. JDBC需要用到的类和接口有: Dri ...
- Java操作Jxl实现数据交互。三部曲——《第一篇》
Java操作Jxl实现.xsl及.xsls两种数据表格进行批量导入数据到SQL server数据库. 本文实现背景Web项目:前台用的框架是Easyui+Bootstrap结合使用,需要引入相应的Js ...
- cogs 728. [网络流24题] 最小路径覆盖问题 匈牙利算法
728. [网络流24题] 最小路径覆盖问题 ★★★☆ 输入文件:path3.in 输出文件:path3.out 评测插件时间限制:1 s 内存限制:128 MB 算法实现题8-3 最 ...
- 「 从0到1学习微服务SpringCloud 」04服务消费者Ribbon+RestTemplate
系列文章(更新ing): 「 从0到1学习微服务SpringCloud 」01 一起来学呀! 「 从0到1学习微服务SpringCloud 」02 Eureka服务注册与发现 「 从0到1学习微服务S ...
- react元素获取e时,点击target为空的现象
今天呢,学习react过程中,我要获取一个元素的e, checkAll=(e)=>{ console.log(e) console.log(e.target) } render() { retu ...
- [mvc>actionResult] 封装一个操作方法的结果并用于代表该操作方法执行框架级操作
- FluentData 学习 第一弹
地址: http://fluentdata.codeplex.com/ 前世: FluentData 我们公司用的一个增删改查的里面的持久层.之前还不知道 这个持久层叫FluentData. 某天看 ...
- jenkins集成jmeter-进阶篇
1.gitlab自动触发jenkins构建 1⃣️安装插件: 2⃣️新建工程,设置git url,build when a change is pushed auto.sh /bin/sh echo ...
- C#反射与特性(四):实例化类型
目录 1,实例化类型 1.1 Activator.CreateInstance() 1.2 ConstructorInfo.Invoke() 2,实例化委托 3,实例化泛型类型 3.1 实例化泛型 3 ...