mysql(2):索引
索引基础
索引介绍
定义
索引是满足某种特定查找算法的数据结构。这些数据结构会以某种方式指向数据,从而实现高效查找。
优势
提高了查询速度
劣势
降低更新表的速度,因为更新表时,MySQL不仅要保存数据,还要保存索引文件。
建立索引会占用磁盘空间的索引文件。
索引分类
主键索引
根据主键pk_column(length)建立索引,不允许重复,不允许空值。
ALTER TABLE 'table_name' ADD PRIMARY KEY pk_index('col');
唯一索引UNIQUE
用来建立索引的列的值必须是唯一的,允许空值。
ALTER TABLE 'table_name' ADD UNIQUE INDEX index_name('col');
普通索引
用普通列构建的索引,没有任何限制。
ALTER TABLE 'table_name' ADD INDEX index_name('col');
组合索引
用多个列组合构建的索引,这多个列中的值不允许有空值。
ALTER TABLE 'table_name' ADD INDEX index_name('col1','col2','col3');
遵循“最左前缀”原则,把最常用作为检索或排序的列放在最左,依次递减,组合索引相当于建立了col1,[col1,col2],[col1,col2,col3]三个索引,而col2或者col3是不能使用索引的。
全文索引FULLTEXT
用大文本对象的列构建的索引。
ALTER TABLE 'table_name' ADD FULLTEXT INDEX ft_index('col');
空间索引SPATIAL
支持空间数据格式。
ALTER TABLE 'table_name' ADD SPATIAL KEY index_name('col');
索引使用
索引创建
CREATE INDEX indexName ON tableName(columnName(length));
ALTER table tableName ADD INDEX indexName(columnName)
CREATE TABLE tableName(
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
INDEX [indexName] (username(length))
);
索引删除
DROP INDEX [indexName] ON tableName;
索引查看
SHOW INDEX FROM table_name;
索引原理分析
索引存储结构
B树与B+树
平衡多叉树。
B树非叶节点和叶节点都存有数据。
B+树叶子节点存放着所有的数据。
B+树索引在数据库中有一个特点是高扇出性,因此,在数据库中,B+树的高度一般都在24层,也就是说查找某一键值的行记录时,最多只需要24次IO。
B+树索引可以分为聚集索引(clustered index)和非聚集索引。
非聚集索引(MyISAM)
MyISAM存储引擎表是堆表,行数据的存储按照插入顺序存放。
非聚集索引叶子节点并不包含行记录的全部数据,而是键值和书签。书签指向数据行的位置。
非聚集索引的存在不影响数据的组织,因此每张表上可以有多个非聚集索引。
聚集索引(InnoDB)
InnoDB存储引擎表是索引组织表,即表中数据按照主键顺序存放。(否则会频繁的引起页分裂,严重影响性能。)
聚集索引就是按照每张表的主键构造一棵B+树,因此每张表只能由一个聚集索引。
数据页上存放的是完整的每行的记录,非数据页中存放的仅仅是键值和偏移量。由于聚集索引存储的是数据本身,因此聚集索引会占用更多的空间。
聚集索引的顺序就是数据的物理存储顺序。
聚集索引对于主键的排序查找和范围查找速度非常快。(添加指向相邻叶节点的指针)
MyISAM vs. InnoDB
| MyISAM | InnoDB | |
|---|---|---|
| 索引类型 | 非聚簇 | 聚簇 |
| 支持事务 | 是 | 否 |
| 支持表锁 | 是 | 是 |
| 支持行锁 | 否 | 是(默认) |
| 支持外键 | 否 | 是 |
| 支持全文索引 | 是 | 是(5.6以后支持) |
| 适用操作类型 | 大量select下使用 | 大量insert、delete和update下使用 |
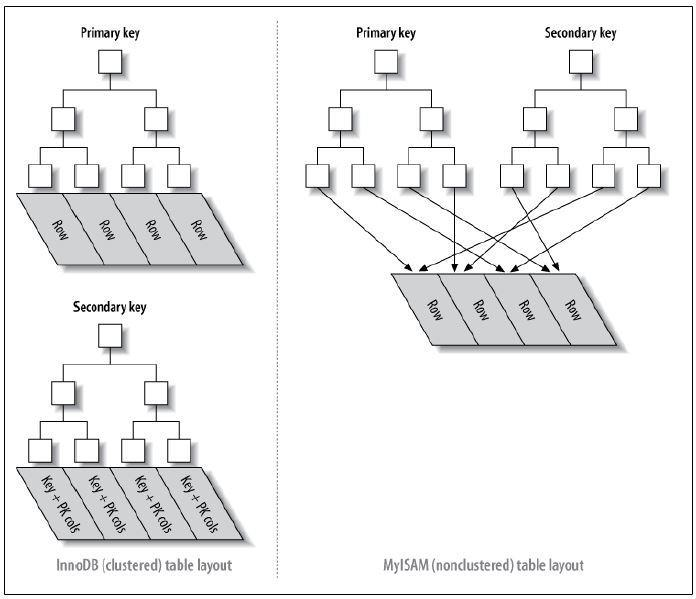
InnoDB:主索引和辅助索引
MyISAM(不支持聚集索引):主索引和辅助索引
索引使用场景
使用索引情况
- 主键自动建立唯一索引;
- 经常作为查询条件在WHERE或者ORDER BY 语句中出现的列要建立索引;
- 查询中与其他表关联的字段,外键关系建立索引;
- 高并发条件下倾向组合索引;
- 用于聚合函数的列可以建立索引。
不使用索引情况
- 经常增删改的列不要建立索引;
- 有大量重复的列不建立索引;
- 表记录太少不要建立索引。
索引失效分析
- 在组合索引中不能有列的值为NULL,如果有,那么这一列对组合索引就是无效的。
- 在一个SELECT语句中,索引只能使用一次,如果在WHERE中使用了,那么在ORDER BY中就不要用了。
- LIKE操作中,'%aaa%'不会使用索引,也就是索引会失效,但是‘aaa%’可以使用索引。
- 在索引的列上使用表达式或者函数会使索引失效,例如:select * from users where YEAR(add_date)<2007,将在每个行上进行运算,这将导致索引失效而进行全表扫描,因此我们可以改成:select * from users where add_date<’2007-01-01′。其它通配符同样,也就是说,在查询条件中使用正则表达式时,只有在搜索模板的第一个字符不是通配符的情况下才能使用索引。
- 在查询条件中使用不等于,包括<、>和!=会导致索引失效。特别的是如果对主键索引使用!=则不会使索引失效,如果对主键索引或者整数类型的索引使用<或者>不会使索引失效。(如果占总记录的比例很小的话,也不会失效)
- 在查询条件中使用IS NOT NULL会导致索引失效(IS NULL不会导致索引失效)
- 字符串不加单引号会导致索引失效。更准确的说是类型不一致会导致失效。
- 在查询条件中使用OR连接多个条件会导致索引失效,除非OR链接的每个条件都加上索引,这时应该改为两次查询,然后用UNION ALL连接起来。
- 如果排序的字段使用了索引,那么select的字段也要是索引字段,否则索引失效。特别的是如果排序的是主键索引则select * 也不会导致索引失效。
- 尽量不要包括多列排序,如果一定要,最好为这队列构建组合索引;
查看执行计划
explain查看执行计划
EXPLAIN SELECT * FROM `user`
JOIN `post` ON `user`.id = `post`.uid
WHERE user.`created` < '2018-10-01 00:00:00' AND `post`.status = 1;
结果:
| id | select _type | table | type | possible _keys | key | key _len | ref | rows | Extra |
|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | user | range | PRIMARY, idx_created | idx_created | 7 | null | 19440 | Using index condition; Using where; Using temporary; Using filesort |
| 1 | SIMPLE | post | ref | idx_uid, idx_status | idx_uid | 8 | user.id | 1 | Using where |
参数说明
id: 查询的唯一标识
table: 查询的表
可能是数据库中的表/视图,也可能是 FROM 中的子查询
possible_keys: 可能使用的索引
key: 最终使用的key
key_len: 查询索引使用的字节数。通常越少越好。
ref: 查询的列或常量
rows: 需要扫描的行数,估计值。通常越少越好。
select_type参数分析:查询的类型
- simple:简单查询,不包含子查询和union
- primary:包含子查询时的最外层查询;使用union时的第一个查询
- subquery:子查询
- dependent subquery:依赖外层查询的子查询
- union:包含union的查询中非第一个查询
- dependent union:依赖外层查询的union
- derived:用于from中的子查询
type参数分析:访问类型/搜索数据的方法
- null:优化过程中分解语句,执行时不用访问表或索引。[从一个索引列里选取最小值可以通过单独索引查找完成]
- system:表只有一行记录(等于系统表)。[const特例]
- const:查询优化,并转换为一个常量时,使用这些类型访问。[将主键置于where列表中,MySQL就能将该查询转换为一个常量]
- eq_ref:使用唯一索引,对于每个索引键值,表中只有一条记录匹配。[多表连接中使用primary key或者 unique key作为关联条件]
- ref:使用非唯一索引扫描、唯一索引的前缀扫描,返回匹配某个单独值的记录行
- range:索引范围扫描,返回匹配值域的行。[①between;②where子句里带有<, >查询;③in()]
- index:全索引扫描,只遍历索引树
- all:全表扫描, 遍历全表以找到匹配的行
extra参数分析:额外的信息
- using index:无需回表查询,从索引中即可获得信息。[可以加快查询速度]
- using where:服务器层对存储引擎返回的数据进行了过滤。
- using index condition:新特性,索引条件推送。服务器层将不能直接使用索引的查询条件(如like)推送给存储引擎,从而避免在服务器层进行过滤。[减少了不必要的IO操作,只能用在二级索引上]
- ICP的理解:将原来在server层进行的table filter中可以进行index filter的部分,在引擎层面使用index filter进行处理,不再需要回表进行table filter。[见下文where条件的提取]
- using filesort:查询时执行了排序操作而无法使用索引排序。虽然名称为'file'但操作可能是在内存中执行的,取决是否有足够的内存进行排序。[可能是order by和group by语句的结果,考虑优化查询]
- using temporary:用临时表保存中间结果,常用于group by和order by操作中。[说明查询需要优化]
- not exists:优化left join,一旦找到了匹配left join标准的行就停止搜索。
- using join buffer:使用了连接缓存。
- Block Nested Loop块嵌套循环连接
- Batched Key Access批量索引连接
- select tables optimized away:在没有group by子句的情况下,使用某些聚合函数(min, max)来访问存在索引的某个字段时,或者对于MyISAM存储引擎优化count(*)操作,不必等到执行阶段再进行计算,查询执行计划生成的阶段即完成优化。
- distinct:优化distinct操作,在找到第一匹配的元组后即停止找同样值的动作。
where条件提取
create table t1 (a int primary key, b int, c int, d int, e varchar(20));
create index idx_t1_bcd on t1(b, c, d);
insert into t1 values (4,3,1,1,’d’);
insert into t1 values (1,1,1,1,’a’);
insert into t1 values (8,8,8,8,’h’):
insert into t1 values (2,2,2,2,’b’);
insert into t1 values (5,2,3,5,’e’);
insert into t1 values (3,3,2,2,’c’);
insert into t1 values (7,4,5,5,’g’);
insert into t1 values (6,6,4,4,’f’);
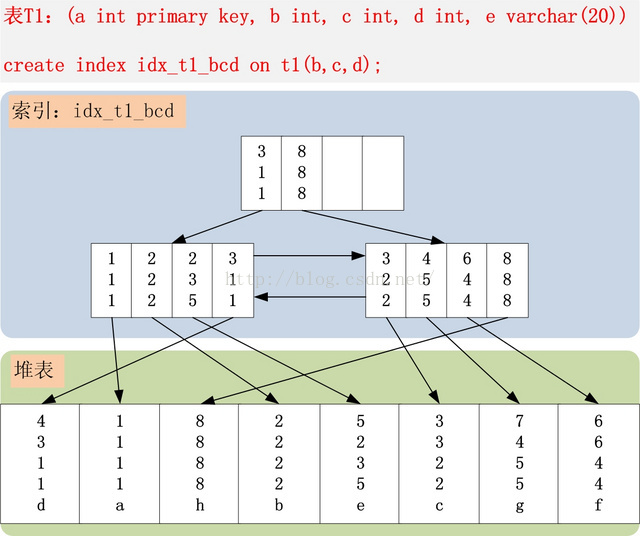
idx_t1_bcd索引,首先按照b字段排序,b字段相同,则按照c字段排序,以此类推。记录在索引中按照[b,c,d]排序,但是在堆表上是乱序的,不按照任何字段排序。
考虑以下的一条SQL:
select * from t1 where b >= 2 and b < 8 and c > 1 and d != 4 and e != 'a';
1,此SQL,覆盖索引idx_t1_bcd上的哪个范围?
起始范围:记录[2,2,2]是第一个需要检查的索引项。b >= 2,c > 1
终止范围:记录[8,8,8]是第一个不需要检查的记录,而之前的记录均需要判断。b < 8
2,在确定了查询的起始、终止范围之后,SQL中还有哪些条件可以使用索引idx_t1_bcd过滤?
c > 1 and d != 4
3,在确定了索引中最终能够过滤掉的条件之后,还有哪些条件是索引无法过滤的?
e != 'a'
总结出一套放置于所有SQL语句而皆准的where查询条件的提取规则:
- Index Key (First Key & Last Key):定位索引的起始范围和终止范围
- Index Filter:过滤索引查询范围中不满足查询条件的记录
- Table Filter:回表读取满足Table Filter中查询条件的完整记录
MySQL 5.6中引入的ICP(Index Condition Pushdown),是将Index Filter Push Down到索引层面进行过滤的。
在MySQL 5.6之前,并不区分Index Filter与Table Filter,统统将Index First Key与Index Last Key范围内的索引记录,回表读取完整记录,然后返回给MySQL Server层进行过滤。
而在MySQL 5.6之后,Index Filter与Table Filter分离,Index Filter下降到InnoDB的索引层面进行过滤,减少了回表与返回MySQL Server层的记录交互开销,提高了SQL的执行效率。
mysql(2):索引的更多相关文章
- 【夯实Mysql基础】MySQL性能优化的21个最佳实践 和 mysql使用索引
本文地址 分享提纲: 1.为查询缓存优化你的查询 2. EXPLAIN 你的 SELECT 查询 3. 当只要一行数据时使用 LIMIT 1 4. 为搜索字段建索引 5. 在Join表的时候使用相当类 ...
- MySQL中索引和优化的用法总结
1.什么是数据库中的索引?索引有什么作用? 引入索引的目的是为了加快查询速度.如果数据量很大,大的查询要从硬盘加载数据到内存当中. 2.InnoDB中的索引原理是怎么样的? InnoDB是Mysql的 ...
- MySQL 联合索引详解
MySQL 联合索引详解 联合索引又叫复合索引.对于复合索引:Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分.例如索引是key index (a,b,c ...
- Mysql复合索引
当Mysql使用索引字段作为条件时,如果该索引是复合索引,必须使用该索引中的第一个字段作为条件才能保证系统使用该索引,否则该索引不会被使用,并且应尽可能地让索引顺序和字段顺序一致
- 如何正确建立MYSQL数据库索引
索引是快速搜索的关键.MySQL索引的建立对于MySQL的高效运行是很重要的.下面介绍几种常见的MySQL索引类型. 在数据库表中,对字段建立索引可以大大提高查询速度.假如我们创建了一个 mytabl ...
- mysql高性能索引策略
转载说明:http://www.nyankosama.com/2014/12/19/high-performance-index/ 1. 引言 随着互联网时代地到来,各种各样的基于互联网的应用和服务进 ...
- MySQL创建索引语法
1.介绍: 所有mysql索引列类型都可以被索引,对来相关类使用索引可以提高select查询性能,根据mysql索引数,可以是最大索引与最小索引,每种存储引擎对每个表的至少支持16的索引.总索引长度为 ...
- mysql使用索引优化查询效率
索引的概念 索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针.更通俗的说,数据库索引好比是一本书前面的目录,能加快数据库的查询速度.在没 ...
- Mysql中索引的 创建,查看,删除,修改
创建索引 MySQL创建索引的语法如下: ? 1 2 3 CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name [USING index_type] ON ...
- mysql 联合索引(转)
http://blog.csdn.net/lmh12506/article/details/8879916 mysql 联合索引详解 联合索引又叫复合索引.对于复合索引:Mysql从左到右的使用索引中 ...
随机推荐
- c++编程之内存模型
我们在编程的时候,无可避免要申明变量,在这个变量可以是在()中,可以在{}中,也可以直接在外面,也可以用new的方式.那么当我们在申明变量的时候,实质上我们所做的工作是:关联了一个内存模型! 上代码: ...
- Java设计模式(三)简单工厂模式
定义与类型 定义:由一个工厂对象决定创建出哪一种产品类的实例 类型:创建型,但不属于GOF23种设计模式 适用场景 工厂类负责创建的对象比较少 客户端(应用层)只知道传入工厂类的参数,对于如何创建对象 ...
- Cobalt Strike配置及简单使用
前言 CS分为客户端与服务端,服务端是一个,客户端可以有多个,非常适合团队协同作战,多个攻击者可以同时连接到一个团队服务器上,共享攻击资源与目标信息和sessions,可模拟APT做模拟对抗,进行内网 ...
- P1522 牛的旅行
P1522 牛的旅行 Cow Tours 提交 11.44k 通过 4.97k 时间限制 1.00s 内存限制 125.00MB 题目提供者洛谷 难度提高+/省选- 历史分数100 提交记录 查看题解 ...
- 服务器的公网ip 和内网ip
原文地址:https://zhidao.baidu.com/question/814783729071869532.html 服务器公网ip 可以用于域名解析ip,服务器远程登录ip,是最主要的服务器 ...
- [转]从实例谈OOP、工厂模式和重构
有了翅膀才能飞,欠缺灵活的代码就象冻坏了翅膀的鸟儿.不能飞翔,就少了几许灵动的气韵.我们需要给代码带去温暖的阳光,让僵冷的翅膀重新飞起来.结合实例,通过应用OOP.设计模式和重构,你会看到代码是怎样一 ...
- poj1042题解
h [1,16] hours all_v=h*12 intervals n [2,25] lakes fi inital intervals fi-di*v v [0,all_v) 题意,做每件事情的 ...
- Virtual DOM(八)
Virtual DOM 这个概念相信大部分人都不会陌生,它产生的前提是浏览器中的 DOM 是很“昂贵"的,为了更直观的感受,我们可以简单的把一个简单的 div 元素的属性都打印出来,如图所示 ...
- C++ log4cpp使用(转)
参考文章: 1.常用C++库(1)日志库 https://blog.csdn.net/qilimi1053620912/article/details/87378707 2.一步步入门log4cpp ...
- 刷题76. Minimum Window Substring
一.题目说明 题目76. Minimum Window Substring,求字符串S中最小连续字符串,包括字符串T中的所有字符,复杂度要求是O(n).难度是Hard! 二.我的解答 先说我的思路: ...