DTD约束与schema约束的不同
本篇笔记了解------Schema约束的语法
------可以参考W3school之Schema教程。
Schema:是基于 XML 的 DTD 替代者,用于描述XML文档结构。支持XML 命名空间-----xmlns--XML namespace的缩写。
XML Schema语言也称作XML Schema定义(XML Schema Definition,XSD)。
因此,schema文件的扩展名为 .xsd,其本身也是个XML文件。
注意:XML Schema是W3c预先规定的一套xml元素和属性创建的,这些元素和属性定义了xml文档的结构和内容模式。
在声明<Schema>文档时,必须以 XML 声明开头,其根节点是<Schema>。
必须在根节点中声明几个属性:
xmlns:xsi="http://www.w3.org/2001/XMLSchema"--表示声明当前XML文件为一个约束文件,Schema中使用的元素和数据类型、属性来自该命名空间。
targetNamespace属性 ------设置该约束文档的唯一标识,一般设置为URL路径---相当于身份证号,通过该属性值能引入约束文件。
elementFormDefault属性:有两个值 qualified 和 unqualified,
当值为qualified时----表示子元素必须使用命名空间前缀---别名
当值为unqualified时----表示子元素不必使用命名空间前缀---别名
Schema文件声明:
<?xml version="1.0" encoding="UTF-8"?>
<schema xmlns="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/company"
elementFormDefault="qualified">
在XML实例文件中引入Schema约束文件:
在XML文件根节点上定义一些属性:
一般把 -instance 修饰的命名空间声明为 xsi ------ xmlns : xsi ="http://www.w3.org/2001/XMLSchema-instance" --表示该xml为实例文件
xmlns:命名空间的前缀 = "targetNamespace属性值"-----相当于引入约束文件,可以引入多个Schema文件。
命名空间的前缀相当于包名,不同包的相同方法名(标签)自然不是同一个。
难理解: xsi:schemaLocation属性:用于声明了目标名称空间的模式文档
xsi:noNamespaceSchemaLocation属性:用于没有目标名称空间的模式文档,属性值是单一值,只是用于指定模式文档的位置。
schemaLocation属性值---------由一对URI组成。第一个URI是命名空间的名字,两个URI之间以空白符分隔,第二个URI给出模式文档.xsd的位置。模式处理器将从这个位置读取模式文档,该模式文档的目标名称空间必须与第一个URI相匹配。XML Schema推荐标准中指出,xsi:schemaLocation属性可以在实例中的任何元素上使用,而不一定是根元素,不过,xsi:schemaLocation属性必须出现在它要验证的任何元素和属性之前,因此在schemaLocation中,所出现的命名空间,必须在之前用xmlns 声明过。
xsi:noNamespaceSchemaLocation属性:用于引用没有目标名称空间的模式文档,其属性值是单一值----用于指定模式文档的位置。
过程理解为:在实例文档中,我们可以多次用xmlns属性引入多个命名空间,但引入的命名空间必须在schemaLocation属性中声明引入的命名空间 和 命名空间来源的地址来有效,这个属性属于-INSTANCE修饰的实例文档的属性,而其中,我们用不同的命名空间前缀来区分命名空间的不同。而不同的命名空间都预先定义了标签和标签的属性、语法规则之类。比如:学生命名空间中设置了name标签,老师命名空间也设置了name标签,那么此时,当两个约束文档被引入到同一个XML实例文档时,如何区分?这个name标签到底要遵循学生命名空间还是老师命名空间呢?通过设置不同的前缀,在使用该标签时,用前缀设定。
也可以反过来理解,只有当schemaLocation属性中的值生效时,之前的xmlns属性才生效。
XML文件:
<?xml version="1.0" encoding="UTF-8"?>
<company xmlns = "http://www.example.org/company"
xmlns:dept="http://www.example.org/department"
xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.example.org/company company.xsd
http://www.example.org/department department.xsd"
>
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
定义一个命名空间-------------xmlns
命名空间的前缀相当于别名----xsi
命名空间URI----http://www.w3.org/2001/XMLSchema-instance
XML文件中允许定义引用多个Schema约束文件,通过命名空间的前缀的不同来区分
XML Schema作用:
定义可出现在文档中的元素
定义可出现在文档中的属性
定义哪些元素是子元素
定义子元素的次序
定义子元素的数目
定义元素和属性的数据类型
定义元素和属性的默认值和固定值
简单元素:仅包含文本,不包含任意其他的元素和属性 --<element name="xxx" type="数据类型" />---Schema有预先定义的数据类型。
复杂元素: 包含子元素或属性的元素
<xs:element name="lastname" type="xs:string"/> //name表示标签的名称---type表示标签值的数据类型
<xs:element name="age" type="xs:integer"/>
XML Schema提供了4种分组结构来指示子元素的顺序:
<sequence>:表示有顺序,要求分组序列中的每个成员在实例文档中出现的顺序与定义的顺序相同。出现的次数由maxOccurs和minOccurs控制。
<all>:使用all定义的元素组,在组中所有的元素成员都可以出现一次或者根本不出现,而且元素能够以任意顺序出现
<choice>:choice分组相当于DTD中的"|",当子元素组合到choice中是,这些元素中只有一个元素必须在实例文档中出现,用于互斥的情况。
<group>分组:group分组是将若干个元素声明归为一组,一以便将他们当做一个组并入复杂类型的定义。
<xsd:element name="电影" type="演员"/>
<xsd:complexType name="演员">
<xsd:sequence>
<xsd:group ref="主演"/>
<xsd:element name="片名" type="类型"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="类型">
<xsd:choice>
<xsd:element name="中文" type="string"/>
<xsd:element name="英文" type="string"/>
</xsd:choice>
</xsd:complexType>
<xsd:group name="主演">
<xsd:sequence>
<xsd:element name="男主演" type="string"/>
<xsd:element name="女主演" type="string"/>
</xsd:sequence>
</xsd:group>
</xsd:schema
声明属性:所有的属性均作为简易类型来声明。
<xs:attribute name="xxx" type="yyy"/>
<!--name指属性名,type指属性数据类型-->
在XML Schema文件中,内置(预先定义)多种数据类型和标签、属性-----------这些可以对内容进行限定,而内容指-----元素(标签)、属性的内容进行限定,如:必须为某类型的值之类。
在XML Schema文件中,可以对复杂和简单元素都进行设置限定,而都预先设置好了标签用来限值。
下面是对复杂类型进行限值------其中包括子元素和属性进行限值
简单元素是没有子元素和属性的-----只对它标签内容进行限值。
<xsd:element name="电影">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="片名" type="xsd:string"/>
<xsd:element name="主演" type="主演类型"/>
<xsd:element name="发行情况">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="编号" type="xsd:integer"/>
<xsd:element name="发行时间" type="xsd:string"/>
<xsd:element name="发行国家" type="xsd:string"/>
<xsd:element name="拷贝数量" type="数量类型"/>
</xsd:sequence>
<xsd:complexType>
</xsd:element>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
<xsd:simpleType name="主演类型">
<xsd:restriction base="xsd:string">
<xsd:minLength value=""/>
<xsd:maxLength value=""/>
</xsd:restriction>
</xsd:simpleType>
<xsd:simpleType name="数量类型">
<xsd:restriction base="xsd:integer">
<xsd:minInclusive value=""/>
<xsd:maxInclusive value=""/>
</xsd:restriction>
</xsd:simpleType>
</xsd:schema>
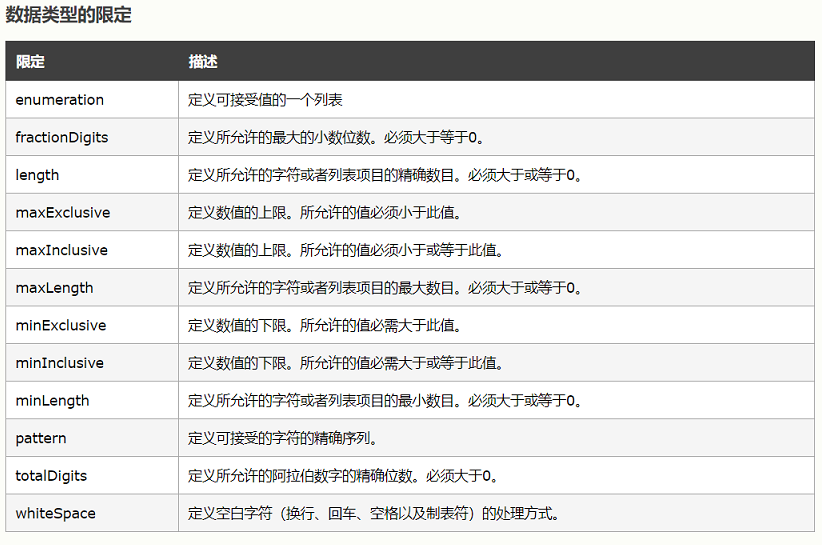
XML Schema中数据类型:
内置的数据类型(built-in data types)
基本的数据类型(Primitive Data Types)
扩展的数据类型(Deriverd Data Types)
用户自定义数据类型(通过simpleType定义)
复杂类型(通过complexType定义)
XML Schema约束与DTD约束相比较:
DTD约束只能引用一个,而Schema约束可以引用多个
DTD的数据类型是有限的,而Schema有多种数据类型,包括自定义数据类型
DTD和xml用的是自己特殊的语法,而schema遵循xml语法
DTD不可以扩展,并且不支持命令空间
DOM和SAX的解析方式更容易解析schema
参考笔记:博主「江湖小妞」-------https://blog.csdn.net/u010161630/article/details/52829371
DTD约束与schema约束的不同的更多相关文章
- DTD约束和Schema约束
DTD约束 什么是DTD? DTD(Document Type Definition),文档类型定义,用来约束XML文档.规定XML文档中元素的名称,子元素的名称及顺序,元素的属性等. DTD约束长什 ...
- 【JAVA与XML、dtd约束、Schema约束】
一.XML. (1)XML:Extensible Markup Language (2)XML是一种标记语言. (3)XML的设计宗旨是传输数据,而不是显示数据. (4)XML标签没有被预定义,即使用 ...
- xml语法、DTD约束xml、Schema约束xml、DOM解析xml
今日大纲 1.什么是xml.xml的作用 2.xml的语法 3.DTD约束xml 4.Schema约束xml 5.DOM解析xml 1.什么是xml.xml的作用 1.1.xml介绍 在前面学习的ht ...
- XML DTD跟SCHEMA约束 语法了解
dtd语法 元素: <!Element 元素名称 数据类型|包含内容> 数据类型: #PCDATA:普通文本 使用的时候一般用()引起来 包含内容: 该元素下可以出现哪些元素, 用()引起 ...
- Schema约束与DTD约束
现将Schema约束与DTD约束实现的一个实例截图出来: 1.DTD 1.1 DTD文件 1.2 DTD实现 2.Schema 2.1 Schema约束 2.2 Schema实现
- xml初步,DTD和Schema约束
XML 可扩展的标记语言(!!!可扩展) 作用 1.存放数据 2.配置文件 语法 文档声明 <?xml version="1.0" encoding="UTF-8& ...
- DTD与Schema约束
1.DTD:(Document Type Definition)是一套为了进行程序间的数据交换而建立的关于标记符的语法 规则.它是标准通用标记语言.2.XML Schema 是基于XML的DTD替代者 ...
- xml——dom&sax解析、DTD&schema约束
dom解析实例: 优点:增删改查一些元素等东西方便 缺点:内存消耗太大,如果文档太大,可能会导致内存溢出 sax解析: 优点:内存压力小 缺点:增删改比较复杂 当我们运行的java程序需要的内存比较大 ...
- schema约束和引入
schema的概述 schema约束同为xml文件的约束模式语言之一, 最大的作用是为了验证xml文件的规范性的. 是为了解决dtd约束不够的问题, 相应的他的配置就变得比较复杂 schema本身就是 ...
随机推荐
- Codeforces Round #258 (Div. 2)E - Devu and Flowers
题意:n<20个箱子,每个里面有fi朵颜色相同的花,不同箱子里的花颜色不同,要求取出s朵花,问方案数 题解:假设不考虑箱子的数量限制,隔板法可得方案数是c(s+n-1,n-1),当某个箱子里的数 ...
- 微信开发SDK支持小程序 ,Jeewx-Api 1.3.1 版本发布
JEEWX-API 是一款JAVA版的微信开发SDK,支持微信公众号.小程序.微信企业号.支付宝生活号SDK和微博SDK.你可以基于她 快速的傻瓜化的进行微信开发.支付窗开发和微博开发. 基于jeew ...
- Python学习day41-数据库(1)
figure:last-child { margin-bottom: 0.5rem; } #write ol, #write ul { position: relative; } img { max- ...
- js 属性的遍历
引自:http://es6.ruanyifeng.com/#docs/object 属性的遍历 ES6 一共有5种方法可以遍历对象的属性. (1)for...in for...in循环遍历对象自身的和 ...
- 2019-3-16-win10-uwp-鼠标移动到图片上切换图片
title author date CreateTime categories win10 uwp 鼠标移动到图片上切换图片 lindexi 2019-03-16 14:43:46 +0800 201 ...
- hdu6277
hdu6277结论题 #include<iostream> #include<cstdio> #include<queue> #include<algorit ...
- webapp中<meta>与css代码部署
1.页面头部标签申明 <!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml" id="te ...
- python字典的基本操作,以及可变数据类型和不可变数据类型的区分
字典:采用键值对存储数据的数据类型,字典的键必须是不可变的数据类型 补充: 不可变(可哈希)数据类型:str,bool,int,tuple 可变(不可哈希)数据类型:list, dict, set ...
- phalcon常用语法
打印SQL //在config/service.php中注册服务 $di->set( 'profiler', function () { return new \Phalcon\Db\Profi ...
- Windows 10专业版激活(附激活码)
安全密钥:BT6TH-FN8VP-6WGCK-6BM9R-MWRDB(使用有效,在物理机,虚拟机都激活了一次) 六一八期间自己买了配件第一次组了台式机,系统是在123pe下的原版win10,装好机器之 ...