使用neo4j-import导入数据及关系
背景

上节我们了解了什么是图数据库,作为研究对象的neo4j的特点,优缺点以及基本的环境搭建。
现在我们要讲存储在csv中的通话记录数据导入到neo4j中去,并且可以通过cql去查询导入的数据及关系
1.选取导入方式
neo4j的导入方式有很多,我大概总结了一下:
- Cypher CREATE 语句,为每一条数据写一个CREATE
- Cypher LOAD CSV 语句,将数据转成CSV格式,通过LOAD CSV读取数据。
- 官方提供的Java API —— Batch Inserter
- 大牛编写的 Batch Import 工具
- 官方提供的 neo4j-import 工具
优缺点对比:
| create语句 | load csv语句 | Batch Inseter | Batch Import | neo4j-import | |
|---|---|---|---|---|---|
| 适用场景 | 1~1w nodes | 1w~10w nodes | 千万以上 nodes | 千万以上 nodes | 千万以上 nodes |
| 速度 | 很慢(1000 nodes/s) | 一般(5000 nodes/s) | 非常快(数万nodes/s) | 非常快(数万nodes/s) | 非常快(数万nodes/s) |
| 优点 | 使用方便,可实时插入。 | 使用方便,可以加载本地 | 远程CSV;可实时插入 | 基于Batch Inserter,可以直接运行编译好的jar包;可以在已存在的数据库中导入数据 | 官方出品,比Batch Import占用更少的资源 |
| 缺点 | 速度慢 | 需要将数据转换成csv | 需要转成CSV;只能在JAVA中使用;且插入时必须停止neo4j | 需要转成CSV;必须停止neo4j | 需要转成CSV;必须停止neo4j;只能生成新的数据库,而不能在已存在的数据库中插入数据 |
可以看出导入的方式有很多,由于我们导入的数据量较大,所以我这里选择的是最后一种 neo4j-import,大家也可以去选择其他的导入方式
neo4j-import 使用
我们打开neo4j-import使用的网站可以看到这样的一段摘要
Super Fast Batch Importer For Huge Datasets LOAD CSV is great for
importing small – medium sized data, i.e. up to the 10M records range.
For large data sets, i.e. in the 100B records range, we have access to
a specialized bulk importer.We want to use it to import similar order data into Neo4j: customers,
orders and contained products.The tool is located in path/to/neo4j/bin/neo4j-import and is used as
follows:
这段话的大致意思是我们使用load csv无法满足我们大数据量的业务需要,所以我们不得不去选择一种新的导入方式,这里我们选择了neo4j-import这种方式,以下是一个导入的例子
bin/neo4j-import --into retail.db --id-type string \
--nodes:Customer customers.csv --nodes products.csv \
--nodes orders_header.csv,orders1.csv,orders2.csv \
--relationships:CONTAINS order_details.csv \
--relationships:ORDERED customer_orders_header.csv,orders1.csv,orders2.csv
例子中的数据结构为:
如果您调用neo4j-import没有参数的脚本,它将列出一个全面的帮助页面。
该--into retail.db显然是目标数据库,其中不能包含现有数据库。
重复--nodes和--relationships参数是同一实体的多个(可能分裂的)csv文件的组,即具有相同的列结构。
每组的所有文件都被视为可以连接成一个大文件。一个标题行的组的第一个文件是必需的,它甚至可能被包含在其中可能比一个多GB的文本文件更易于处理和编辑一个单行文件。也支持压缩文件。
customers.csv直接作为带有:Customer标签的节点导入,属性直接从文件中获取。- 对于从
:LABEL列中获取节点标签的产品也是如此。 - 订单节点取自3个文件,一个标题和两个内容文件。
- 输入
:CONTAINS的order_details.csv订单项关系是通过其ID 来创建的,包含与所包含产品的订单。 - 订单通过再次使用订单csv文件连接到客户,但这次使用不同的标头,其中:IGNORE是不相关的列
这–id-type string表示所有:ID列都包含字母数字值(对仅数字ID进行优化)。
列名用于节点和关系的属性名称,特定列有一些额外的标记
name:ID- 全局id列,通过该列查找节点以便以后重新连接,- 如果保留属性名称,它将不会被存储(临时),这就是–id-type所指的
- 如果你有跨实体的重复id,你必须在括号中提供实体(id-group)
:ID(Order) - 如果您的ID是全球唯一的,您可以将其关闭
- :LABEL - 节点的标签列,多个标签可以用分隔符分隔
:START_ID,:END_ID- 关系文件列,引用节点ID,用于id-groups使用:END_ID(Order):TYPE- 关系型列- 所有其他列都被视为属性,但如果为空或在注释时跳过:IGNORE
- 类型转换可以通过后面添加的名称,例如通过
:INT,:BOOLEAN等
导入通话记录数据
在整理后的csv中我们的通话记录是这样的数据:
phones.csv 记录电话号列表,作为nodes结点
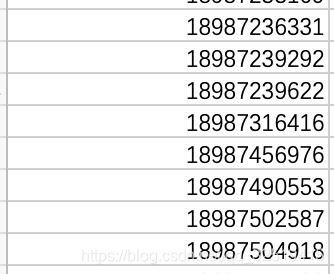
phone_header 标题文件只有一行数据
phone:IDcall.csv 该文件记录通话记录的信息,作为以后关系的建立和关系属性的添加
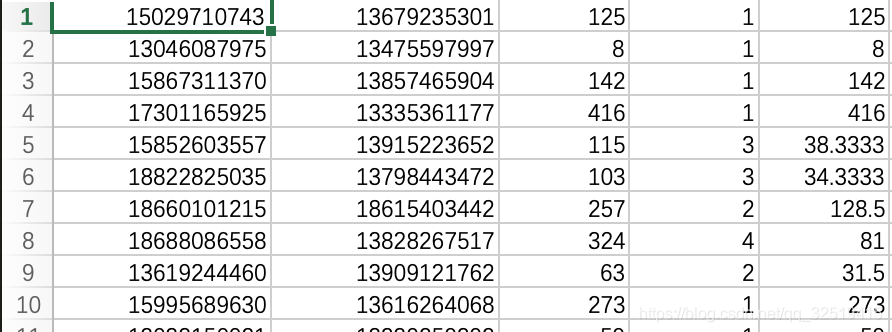
第一行从左到右字段的含义为:
150 **** 0743给136 **** 5301一共打了125分钟时长的电话,打了一次,平均一次125分钟call_header.csv 通话记录头信息

这里的:START_ID指的是关系的起始点,:END_ID指的是关系的终止点
这些csv文件准备好之后,我们写一段shell脚本来执行这些文件。
import()
{
#导入命令
neo4j stop
cd /usr/local/Cellar/neo4j/3.5.0/libexec/data/databases
rm -rf graph.db
cd /Documents/归档/data
neo4j-admin import \
--database=graph.db
--nodes:phone="../phone_header.csv,phones.csv \
--ignore-duplicate-nodes=true \
--ignore-missing-nodes=true \
--relationships:call="../call_header.csv,call.csv"
neo4j start
}
- 这里以防我们新建的数据库已经存在,我们选择删除已有库再进行导入
- 记得要先关闭neo4j
查看结果
导入完成之后我们来打开neo4j浏览器查看一下导入后的结果
我们打开http://localhost:7474/browser/
首先我们先查看一下Database Information
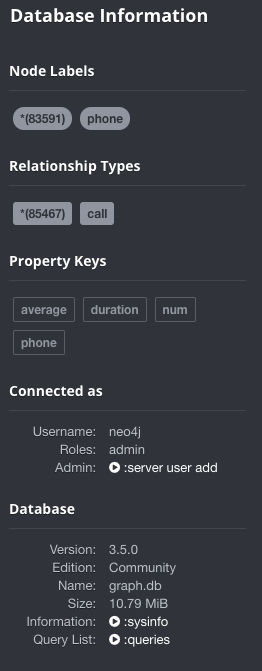
这里我们可以看到已有的结点数,有多少条关系,占用的存储空间等数据库信息
然后我们来查看某个电话号码的交际圈:
match (p:phone{phone:"13825259929"})-[r]->(o) return p,o,r;
- 1

把鼠标移到对应的结点和关系上时,底部便会出现对应的属性
现在我们的数据导入就完成了
接下来我们要用springboot + neo4j +d3来展示某人的通话记录圈。
原文地址:https://blog.csdn.net/qq_32519415/article/details/87942379
使用neo4j-import导入数据及关系的更多相关文章
- neo4j批量导入数据的两种解决方案
neo4j批量导入数据有两种方法,第一种是使用cypher语法中的LOAD CSV,第二种是使用neo4j自带的工具neo4j-admin import. LOAD CSV 导入的文件必须是csv文件 ...
- C# Excel导入数据
表 表的创建脚本 CREATE TABLE [dbo].[TB_PROJECTS_New1]( , ) NOT NULL, ) NULL, ) NULL, , ) NULL, , ) NULL, , ...
- DB2导入数据时乱码问题
1.由于导入import导入数据时乱码,一直找不到解决办法,于是就用load导入 LOAD后,发现某些表检查挂起( 原因码为 "1",所以不允许操作 SQLSTATE=57016 ...
- PHP Excel文件导入数据到数据库
1.php部分(本例thinkphp5.1): 下载PHPExcel了扩展http://phpexcel.codeplex.com/ <?phpnamespace app\admin\contr ...
- 使用neo4j图数据库的import工具导入数据 -方法和注意事项
背景 最近我在尝试存储知识图谱的过程中,接触到了Neo4j图数据库,这里我摘取了一段Neo4j的简介: Neo4j是一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中.它是一个嵌 ...
- Neo4j入门日志(一)导入数据
本文主要来源于: neo4j的官方文档 使用的是neo4j官方提供的导入方式,即使用import,在cmd中进行导入. 1.导入的基本方式 bin/neo4j-admin import --datab ...
- 【neo4j】文件管理路径、数据备份、创建新数据库、导入数据等操作记录
neo4j一般的配置路径如下 一.备份数据 使用neo4j-admin命令. 首先,先找到数据的存储路径,然后关闭数据库. 关闭数据库的语句如下: #切换到/bin目录下 ./neo4j stop 然 ...
- Python来袭,教你用Neo4j构建“复联4”人物关系图谱!
来源商业新知网,原标题:Python来袭,教你用Neo4j构建“复联4”人物关系图谱!没有剧透! 复仇者联盟 之绝对不剧透 漫威英雄们为了不让自己剧透也是使出了浑身解数.在洛杉矶全球首映礼上记者费尽心 ...
- csv导入数据
1.关闭Neo4j服务器进程 2.删除graph.db数据库文件 /data/databases/ rm -rf graph.db 3.重新启动Neo4j服务器 4.数据导入import 5.wi ...
随机推荐
- 廖雪峰Java13网络编程-3其他-1HTTP编程
1.HTTP协议: Hyper Text Transfer Protocol:超文本传输协议 基于TCP协议之上的请求/响应协议 目前使用最广泛的高级协议 * 使用浏览器浏览网页和服务器交互使用的就是 ...
- 淼一淼A+B problem
鲁迅:这可是道难题呢! 鲁迅:我没说过这话,不过确实在理. 某改题毕,但见LOJ之上有数「A+B」之AC记录.余亦尝闻A+B之趣味无穷,遂兴起而码之. 少顷,AC之,吾心所畅. #include< ...
- KNN算法和实现
KNN要用到欧氏距离 KNN下面的缺点很容易使分类出错(比如下面黑色的点) 下面是KNN算法的三个例子demo, 第一个例子是根据算法原理实现 import matplotlib.pyplot as ...
- echarts高级
常用,待续... ♣tooltip自动轮播 ♣ 实现数据自动轮播 原理:其实就是timeline,获取某几段(时间)的数据,然后隐藏timeline ♣ legend自动轮播 ♣ 左侧多字出省略号 f ...
- MyEclipse使用总结——Maven项目如何启动运行发布到tomcat中[转]
前面两篇文章: 新建maven框架的web项目 以及 将原有项目改成maven框架 之后,我们已经有了maven的项目 那么 maven项目到底怎么启动呢 如果我们直接在myeclipse中按以前的启 ...
- Android之FrameLayout帧布局
1.简介 这个布局直接在屏幕上开辟出一块空白的区域,当我们往里面添加控件的时候,会默认把他们放到这块区域的左上角; 帧布局的大小由控件中最大的子控件决定,如果控件的大小一样大的话,那么同一时刻就只能看 ...
- OS -- (python)文件和目录操作方法大全
一.python中对文件.文件夹操作时经常用到的os模块和shutil模块常用方法.1.得到当前工作目录,即当前Python脚本工作的目录路径: os.getcwd()2.返回指定目录下的所有文件和目 ...
- JavaSE_04_JDK1.8新特性Lambda表达式
1.1体验Lambda的更优写法 借助Java 8的全新语法,上述Runnable接口的匿名内部类写法可以通过更简单的Lambda表达式达到等效: 1.2 Lambda标准格式 Lambda省去面向对 ...
- 关于CSS3 animation 属性在ie edge浏览器中不能工作
我想要给div边框加一个闪烁,所以我将css中设置如下 给想要闪烁的div加上blink类 这样在firefox,chrome下是正常显示的,但是在ie下box-shadow属性不能被正常的展现 后 ...
- thinkphp浏览历史功能实现方法
这篇文章主要介绍了thinkphp浏览历史功能实现方法,可实现浏览器的浏览历史功能,是非常实用的技巧,需要的朋友可以参考下 本文实例讲述了thinkphp浏览历史功能实现方法,分享给大家供大家参考.具 ...