solr亿万级索引优化实践(四)
本篇是这个系类的最后一篇,但优化方案不仅于此,需要后续的研究与学习,本篇主要从schema设计的角度来做一些实践。
schema.xml 这个文件的作用是定义索引数据中的域的,包括域名称,域类型,域是否索引,是否分词,是否存储,是否标准化,是否存储项向量等等。在solr6中这个文件是存放在zookeeper的/configs节点之下的,在创建新的collection时,solr会根据此节点下的信息生成相应的索引库,其相关的配置信息会同步到solrhome/core目录下的core.properties文件中。同步schema文件的指令语句样例为:
bin/solr zk -upconfig -z 127.0.01:2181 -n conf -d /solrhome/configsets/sample_techproducts_configs/conf
为了改进性能,可以从以下几个方面来着手:
1、对于field元素,我们将所有只用于搜索的,而不需要作为查询结果的field(特别是一些比较大的field)的stored设置为false,这样这个字段的值将不会被存储,但可以被检索,会减少不小的IO开销。我们设计了一个利用solr来做hbase的二级索引架构,可以利用hbase来存储字段信息,充分利用hadoop的大数据特性。
2、能不用copyfield这个元素就不用,这个属性会对字段做双倍存储,显然非常耗性能,好处就是在查询的时候,想要对多个字段进行检索只需要检索一个字段。
3、将一些不需要被检索的字段的index属性,设置成false,这样solr就不会对这个字段进行索引。
5、不使用中文分词器或者使用高亮功能。termPositions termOffsets的值全都设置成false。
6、在测试中发现solr在处理小报文(1K以下)的情况下吞吐量并不理想,当适当增大报文,发现速度可以得到大幅度提高,可以从之前的每个节点10M/S暴涨到30M/S。
但是在很多情况下,我们并不能人为控制报文长度,这个时候,可以通过solr的字段多值来达到目的,即将将多条消息的每个字段的值放到一起,在schema中配置multValued为true。存储到solr中是这个样子的:
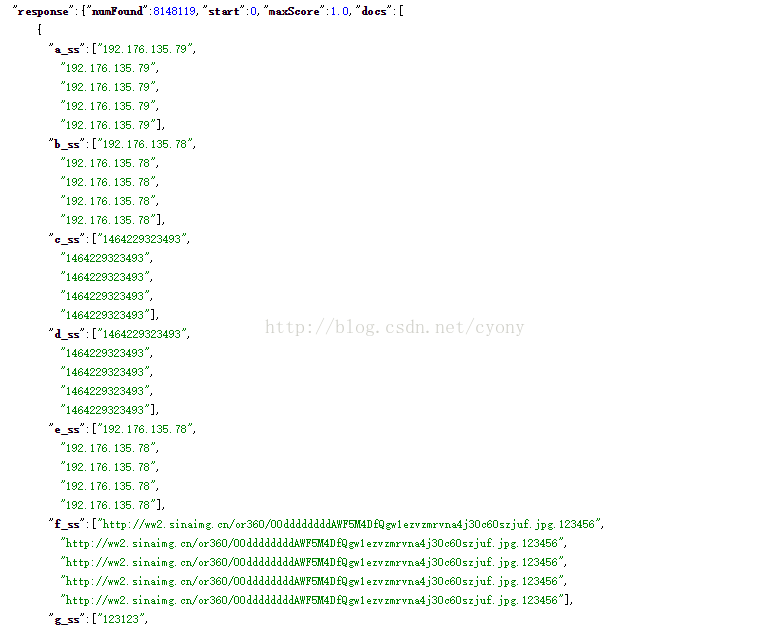
这样速度是可以单台节点达到30M/S甚至更高,但是带来的问题就是查询会变得很复杂,在命中多值中任意一条记录,结果集会带出所有值,在solr中认为这一组数据是一个文档,我们想了很多方案来解决这个问题,比较简单的方法是,在生成文档的时候控制多值字段中,没有重复的值,这样检索结果则会变得精确,缺点就是灵活性太低。另一个方案,是通过对数据做预聚合,管理快照,由于其实现比较复杂,效果也不是很理想,在此就不做过多描述了。
在不追求检索精确度,或者对数据可控的情况下,对于索引速度真的可以带来很大的惊喜。
尾言:solr由于是利用lucene为底层,lucene本身是单机的无法分布式,solr的核心就是引入了分片的机制,在数据规模变得特别庞大的时候各种弊端就显示出来了,无论是建立索引还是查询性能都不尽人意。但通过各种方法的优化与舍弃之后,差不多可以做到水平拓展,线性增长,能够满足大多数的业务场景。但是如果是要对历史数据进行检索的时候,这个历史数据规模又是极其巨量时,solr恐怕是无法承受的。现在兴起了很多列式存储结构以及时间序列的数据库以及仓库,比如driud和tsdb,他们在巨量数据检索时可以带来极高的性能体验。
solr亿万级索引优化实践(四)的更多相关文章
- solr亿万级索引优化实践-自动生成UUID
solr亿万级索引优化实践(三) 原创 2017年03月14日 17:03:09 本篇文章主要介绍下如何从客户端solrJ以及服务端参数配置的角度来提升索引速度. solrJ6.0提供的 ...
- 一个Web报表项目的性能分析和优化实践(四):MySQL建立索引,唯一索引和组合索引
先大致介绍下项目的数据库信息. 数据库A:主要存放的通用的表,如User.Project.Report等. 数据库B.C.D:一个项目对应一个数据库,而且这几个项目的表是完全一样的. 数据库表的特点 ...
- Explain执行计划与索引优化实践
一.何为explain执行计划? 使用explain关键字可以模拟优化器执行SQL语句,从而知道MySQL是如何使用索引来处理你的SQL查询语句以及连接表,可以分析查询语句或是结构的性能瓶颈,帮助我们 ...
- 让Elasticsearch飞起来!——性能优化实践干货
原文:让Elasticsearch飞起来!--性能优化实践干货 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog ...
- 携程App的网络性能优化实践
首先介绍一下携程App的网络服务架构.由于携程业务众多,开发资源导致无法全部使用Native来实现业务逻辑,因此有相当一部分频道基于Hybrid实现.网络通讯属于基础&业务框架层中基础设施的一 ...
- mysql优化之索引优化
Posted by Money Talks on 2012/02/23 | 第一篇 序章第二篇 连接优化第三篇 索引优化第四篇 查询优化第五篇 到实战中去 索引优化 索引优化涉及到几个方面,包括了索引 ...
- 转:携程App的网络性能优化实践
http://kb.cnblogs.com/page/519824/ 携程App的网络性能优化实践 受益匪浅的一篇文章,让我知道网络交互并不是简单的传输和接受数据.真正的难点在于后面的性能优化 下面对 ...
- MySQL高级学习笔记(四):索引优化分析
文章目录 性能下降 SQL慢 执行时间长 等待时间长 查询语句写的烂 查询数据过多 关联了太多的表,太多join 没有利用到索引 单值 复合 服务器调优及各个参数设置(缓冲.线程数等)(不重要DBA的 ...
- Hbase-二级索引 Hbase+Hbase-indexer+solr (CDH)
最近一段时间工作涉及到hbase sql查询和可视化展示的工作,hbase作为列存储,数据单一为二进制数组,本身就不擅长sql查询:而且有hive来作为补充作为sql查询和存储,但是皮皮虾需要低延迟的 ...
随机推荐
- URL的应用
1.对于Android来说,开发应用都会去访问服务器地址,那么就要连网,需要通过URL. 先new一个URL来获取路径,然后利用HttpURLConnection来连接并打开url,并通过get 请求 ...
- nginx服务相关操作
安装目录 和大多软件一样一般安装在 /usr/local/ 目录下 /usr/local/ 命令man Usage: nginx [-?hvVt] [-s signal] [-c filename] ...
- 强大的Java Json工具类
转自: https://blog.csdn.net/u014676619/article/details/49624165 import java.io.BufferedReader; import ...
- (转)函数库调用 VS 系统调用
Linux下对文件操作有两种方式:系统调用(system call)和库函数调用(Library functions).可以参考<Linux程序设计>(英文原版为<Beginning ...
- C语言指针和操作系统的逻辑地址
你在进行C语言指针编程中,可以读取指针变量本身值(&操作),实际上这个值就是逻辑地址,它是相对于你当前进程数据段的地址,不和绝对物理地址相干.只有在Intel实模式下,逻辑地址才和物理地址相等 ...
- drill 集成开源s3 存储minio
drill 支持s3数据的查询,同时新版的通过简单配置就可以实现minio 的集成 测试使用docker 运行drill 参考 https://www.cnblogs.com/rongfenglian ...
- oracel SQL多表查询优化
SQL优化 1.执行路径:ORACLE的这个功能大大地提高了SQL的执行性能并节省了内存的使用:我们发现,单表数据的统计比多表统计的速度完全是两个概念.单表统计可能只要0.02秒,但是2张表联合统计就 ...
- Windows环境下用jwplayer+Nginx搭建视频点播服务器
flv视频可以采用两种方式发布: 一.普通的HTTP下载方式 二.基于Flash Media Server或Red5服务器的rtmp/rtmpt流媒体方式. 多数知名视频网站都采用的是前一种方式. 两 ...
- TensorFlow笔记-01-开篇概述
人工智能实践:TensorFlow笔记-01-开篇概述 从今天开始,从零开始学习TensorFlow,有相同兴趣的同志,可以互相学习笔记,本篇是开篇介绍 Tensorflow,已经人工智能领域的一些名 ...
- webpack 打包性能分析工具
webpack-bundle-analyzer,推荐使用 新版 vue-cli (旧版按照新版的进行配置即可)已经集成该插件,在项目的 package.json 文件中注入如下命令,然后运行(npm ...