现在的 Linux 内核和 Linux 2.6 的内核有多大区别?
链接:https://www.zhihu.com/question/35484429/answer/62964898
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2.6 时代跨度非常大,从2.6.0 (2003年12月发布[36]) 到 2.6.39(2011年5月发布), 跨越了 40 个大版本。
3.0(原计划的 2.6.40, 2011年7月发布) 到 3.19(2015年2月发布)。
4.0(2015年4月发布)到4.2(2015年8月底发布)。
总的来说,从进入2.6之后,每个大版本跨度开发时间大概是 2 - 3 个月。2.6.x , 3.x, 4.x,数字的递进并没有非常根本性,非常非常非常引人注目的大变化,但每个大版本中都有一些或大或小的功能改变。主版本号只是一个数字而已。不过要直接从 2.6.x 升级 到 3.x, 乃至 4.x,随着时间间隔增大,出问题的机率当然大很多。
个人觉得 Linux 真正走入严肃级别的高稳定性,高可用性,高可伸缩性的工业级别内核大概是在 2003 年后吧。一是随着互联网的更迅速普及,更多的人使用、参与开发。二也是社区经过11年发展,已经慢慢摸索出一套很稳定的协同开发模式,一个重要的特点是 社区开始使用版本管理工具进入管理,脱离了之前纯粹手工(或一些辅助的简陋工具)处理代码邮件的方式,大大加快了开发的速度和力度。
因此,我汇总分析一下从 2.6.12 (2005年6月发布,也就是社区开始使用 git 进行管理后的第一个大版本),到 4.2 (2015年8月发布)这中间共 51个大版本,时间跨度10年的主要大模块的一些重要的变革。
<img src="https://pic1.zhimg.com/50/db55b324b618d42ad656e52f954cc7ec_hd.jpg" data-caption="" data-rawwidth="468" data-rawheight="279" class="origin_image zh-lightbox-thumb" width="468" data-original="https://pic1.zhimg.com/db55b324b618d42ad656e52f954cc7ec_r.jpg">
(感谢知友
提供无水印题图 ;-) )
预计内容目录:
- 调度子系统(scheduling) [已完成]
- 内存管理子系统(memory management) [已完成]
- 中断与异常子系统(interrupt & exception)[填坑中]
- 时间子系统(timer & timekeeping)
- 同步机制子系统(synchronization)
- 块层(block layer)
- 文件子系统(Linux 通用文件系统层VFS, various fs)
- 网络子系统(networking)
- 调试和追踪子系统(debugging, tracing)
- 虚拟化子系统(kvm)
- 控制组(cgroup)
============== 海量正文分割线 ==============
- 调度子系统(scheduling)
概述:Linux 是一个遵循 POSIX 标准的类 Unix 操作系统(然而它并不是 Unix 系统[1]),POSIX 1003.1b 定义了调度相关的一个功能集合和 API 接口[2]。调度器的任务是分配 CPU 运算资源,并以协调效率和公平为目的。效率可从两方面考虑: 1) 吞吐量(throughput) 2)延时(latency)。不做精确定义,这两个有相互矛盾的衡量标准主要体现为两大类进程:一是 CPU 密集型,少量 IO 操作,少量或无与用户交互操作的任务(强调吞吐量,对延时不敏感,如高性能计算任务 HPC), 另一则是 IO 密集型, 大量与用户交互操作的任务(强调低延时,对吞吐量无要求,如桌面程序)。公平在于有区分度的公平,多媒体任务和数值计算任务对延时和限定性的完成时间的敏感度显然是不同的。
为此, POSIX 规定了操作系统必须实现以下调度策略(scheduling policies), 以针对上述任务进行区分调度:
- SCHED_FIFO
- SCHED_RR
这两个调度策略定义了对实时任务,即对延时和限定性的完成时间的高敏感度的任务。前者提
供 FIFO 语义,相同优先级的任务先到先服务,高优先级的任务可以抢占低优先级的任务;后 者提供 Round-Robin 语义,采用时间片,相同优先级的任务当用完时间片会被放到队列尾
部,以保证公平性,同样,高优先级的任务可以抢占低优先级的任务。不同要求的实时任务可
以根据需要用 sched_setscheduler() API 设置策略。
- SCHED_OTHER
此调度策略包含除上述实时进程之外的其他进程,亦称普通进程。采用分时策略,根据动态优
先级(可用 nice() API设置),分配 CPU 运算资源。 注意:这类进程比上述两类实时进程优先
级低,换言之,在有实时进程存在时,实时进程优先调度。
Linux 除了实现上述策略,还额外支持以下策略:
- SCHED_IDLE 优先级最低,在系统空闲时才跑这类进程(如利用闲散计算机资源跑地外文明搜索,蛋白质结构分析等任务,是此调度策略的适用者)
- SCHED_BATCH 是 SCHED_OTHER 策略的分化,与 SCHED_OTHER 策略一样,但针对吞吐量优化
- SCHED_DEADLINE 是新支持的实时进程调度策略,针对突发型计算,且对延迟和完成时间高度敏感的任务适用。
除了完成以上基本任务外,Linux 调度器还应提供高性能保障,对吞吐量和延时的均衡要有好的优化;要提供高可扩展性(scalability)保障,保障上千节点的性能稳定;对于广泛作为服务器领域操作系统来说,它还提供丰富的组策略调度和节能调度的支持。
-*-*-*-*-*-*-*-*-*-*-*-*-*-*-* 重要功能和时间点 -*-*-*-*-*-*-*-*-*-*-*-*-*-*-*
目录:
1 抢占支持(preemption)
2 普通进程调度器(SCHED_OTHER)之纠极进化史
3 有空时再跑 SCHED_IDLE
4 吭哧吭哧跑计算 SCHED_BATCH
5 十万火急,限期完成 SCHED_DEADLINE
6 普通进程的组调度支持(Fair Group Scheduling)
7 实时进程的组调度支持(RT Group Scheduling)
8 组调度带宽控制(CFS bandwidth control)
9 极大提高体验的自动组调度(Auto Group Scheduling)
10 基于调度域的负载均衡
11 更精确的调度时钟(HRTICK)
12 自动 NUMA 均衡(Automatic NUMA balancing)
13 CPU 调度与节能
-*-*-*-*-*-*-*-*-*-*-*-*-*-*-* 正文 -*-*-*-*-*-*-*-*-*-*-*-*-*-*-*
1 抢占支持(preemption): 2.6 时代开始支持(首次在2.5.4版本引入[37], 感谢知友
考证! 关于 Linux 版本规则,可看我文章[4]).
可抢占性,对一个系统的调度延时具有重要意义。2.6 之前,一个进程进入内核态后,别的进程无法抢占,只能等其完成或退出内核态时才能抢占, 这带来严重的延时问题,2.6 开始支持内核态抢占。
2 普通进程调度器(SCHED_OTHER)之纠极进化史:
Linux 一开始,普通进程和实时进程都是基于优先级的一个调度器, 实时进程支持 100 个优先级,普通进程是优先级小于实时进程的一个静态优先级,所有普通进程创建时都是默认此优先级,但可通过 nice() 接口调整动态优先级(共40个). 实时进程的调度器比较简单,而普通进程的调度器,则历经变迁[5]:
2.1 O(1) 调度器: 2.6 时代开始支持(2002年引入)。顾名思义,此调度器为O(1)时间复杂度。该调度器修正之前的O(n) 时间复杂度调度器,以解决扩展性问题。为每一个动态优先级维护队列,从而能在常数时间内选举下一个进程来执行。
2.2 夭折的 RSDL(The Rotating Staircase Deadline Scheduler)调度器, 2007 年 4 月提出,预期进入 2.6.22, 后夭折。
O(1) 调度器存在一个比较严重的问题: 复杂的交互进程识别启发式算法 - 为了识别交互性的和批处理型的两大类进程,该启发式算法融入了睡眠时间作为考量的标准,但对于一些特殊的情况,经常判断不准,而且是改完一种情况又发现一种情况。
Con Kolivas (八卦:这家伙白天是个麻醉医生)为解决这个问题提出RSDL(The Rotating Staircase Deadline Scheduler)算法。该算法的亮点是对公平概念的重新思考: 交互式(A)和批量式(B)进程应该是被完全公平对待的,对于两个动态优先级完全一样的 A, B 进程,它们应该被同等地对待,至于它们是交互式与否(交互式的应该被更快调度), 应该从他们对分配给他们的时间片的使用自然地表现出来,而不是应该由调度器自作高明地根据他们的睡眠时间去猜测。这个算法的核心是Rotating Staircase, 是一种衰减式的优先级调整,不同进程的时间片使用方式不同,会让它们以不同的速率衰减(在优先级队列数组中一级一级下降,这是下楼梯这名字的由来), 从而自然地区分开来进程是交互式的(间歇性的少量使用时间片)和批量式的(密集的使用时间片)。具体算法细节可看这篇文章:The Rotating Staircase Deadline Scheduler [LWN.net]
2.3 完全公平的调度器(CFS), 2.6.23(2007年10月发布)
Con Kolivas 的完全公平的想法启发了原 O(1)调度器作者 Ingo Molnar, 他重新实现了一个新的调度器,叫 CFS(Completely Fair Scheduler)。新调度器的核心同样是完全公平性, 即平等地看待所有普通进程,让它们自身行为彼此区分开来,从而指导调度器进行下一个执行进程的选举。
具体说来,此算法基于一个理想模型。想像你有一台无限个 相同计算力的 CPU, 那么完全公平很容易,每个 CPU 上跑一个进程即可。但是,现实的机器 CPU 个数是有限的,超过 CPU 个数的进程数不可能完全同时运行。因此,算法为每个进程维护一个理想的运行时间,及实际的运行时间,这两个时间差值大的,说明受到了不公平待遇,更应得到执行。
至于这种算法如何区分交互式进程和批量式进程,很简单。交互式的进程大部分时间在睡眠,因此它的实际运行时间很小,而理想运行时间是随着时间的前进而增加的,所以这两个时间的差值会变大。与之相反,批量式进程大部分时间在运行,它的实际运行时间和理想运行时间的差距就较小。因此,这两种进程被区分开来。
CFS 的测试性能比 RSDS 好,并得到更多的开发者支持,所以它最终替代了 RSDL 在 2.6.23 进入内核,一直使用到现在。可以八卦的是,Con Kolivas 因此离开了社区,不过他本人否认是因为此事而心生龃龉。后来,2009 年,他对越来越庞杂的 CFS 不满意,认为 CFS 过分注重对大规模机器,而大部分人都是使用少 CPU 的小机器,开发了 BFS 调度器[6], 这个在 Android 中有使用,没进入 Linux 内核。
3 有空时再跑 SCHED_IDLE, 2.6.23(2007年10月发布)
此调度策略和 CFS 调度器在同一版本引入。系统在空闲时,每个 CPU 都有一个 idle 线程在跑,它什么也不做,就是把 CPU 放入硬件睡眠状态以节能(需要特定CPU的driver支持), 并等待新的任务到来,以把 CPU 从睡眠状态中唤醒。如果你有任务想在 CPU 完全 idle 时才执行,就可以用sched_setscheduler() API 设置此策略。
4 吭哧吭哧跑计算 SCHED_BATCH, 2.6.16(2006年3月发布)
概述中讲到 SCHED_BATCH 并非 POSIX 标准要求的调度策略,而是 Linux 自己额外支持的。
它是从 SCHED_OTHER 中分化出来的, 和 SCHED_OTHER 一样,不过该调度策略会让采用策略的进程比 SCHED_OTHER 更少受到 调度器的重视。因此,它适合非交互性的,CPU 密集运算型的任务。如果你事先知道你的任务属于该类型,可以用 sched_setscheduler() API 设置此策略。
在引入该策略后,原来的 SCHED_OTHER 被改名为 SCHED_NORMAL, 不过它的值不变,因此保持 API 兼容,之前的 SCHED_OTHER 自动成为 SCHED_NORMAL, 除非你设置 SCHED_BATCH。
5 十万火急,限期完成 SCHED_DEADLINE, 3.14(2014年3月发布)
此策略支持的是一种实时任务。对于某些实时任务,具有阵发性(sporadic), 它们阵发性地醒来执行任务,且任务有 deadline 要求,因此要保证在 deadline 时间到来前完成。为了完成此目标,采用该 SCHED_DEADLINE 的任务是系统中最高优先级的,它们醒来时可以抢占任何进程。
如果你有任务属于该类型,可以用 sched_setscheduler() 或 sched_setattr() API 设置此策略。
更多可参看此文章:Deadline scheduling: coming soon? [LWN.net]
6 普通进程的组调度支持(Fair Group Scheduling), 2.6.24(2008年1月发布)
2.6.23 引入的 CFS 调度器对所有进程完全公平对待。但这有个问题,设想当前机器有2个用户,有一个用户跑着 9个进程,还都是 CPU 密集型进程;另一个用户只跑着一个 X 进程,这是交互性进程。从 CFS 的角度看,它将平等对待这 10 个进程,结果导致的是跑 X 进程的用户受到不公平对待,他只能得到约 10% 的 CPU 时间,让他的体验相当差。
基于此,组调度的概念被引入[6]。CFS 处理的不再是一个进程的概念,而是调度实体(sched entity), 一个调度实体可以只包含一个进程,也可以包含多个进程。因此,上述例子的困境可以这么解决:分别为每个用户建立一个组,组里放该用户所有进程,从而保证用户间的公平性。
该功能是基于控制组(control group, cgroup)的概念,需要内核开启 CGROUP 的支持才可使用。关于 CGROUP ,以后可能会写。
7 实时进程的组调度支持(RT Group Scheduling), 2.6.25(2008年4月发布)
该功能同普通进程的组调度功能一样,只不过是针对实时进程的。
8 组调度带宽控制(CFS bandwidth control) , 3.2(2012年1月发布)
组调度的支持,对实现多租户系统的管理是十分方便的,在一台机器上,可以方便对多用户进行 CPU 均分.然后,这还不足够,组调度只能保证用户间的公平,但若管理员想控制一个用户使用的最大 CPU 资源,则需要带宽控制.3.2 针对 CFS组调度,引入了此功能[8], 该功能可以让管理员控制在一段时间内一个组可以使用 CPU 的最长时间.
9 极大提高体验的自动组调度(Auto Group Scheduling), 2.6.38(2011年3月发布)
试想,你在终端里熟练地敲击命令,编译一个大型项目的代码,如 Linux内核,然后在编译的同时悠闲地看着电影等待,结果电脑却非常卡,体验一定很不爽.
2.6.38 引入了一个针对桌面用户体验的改进,叫做自动组调度.短短400多行代码[9], 就很大地提高了上述情形中桌面使用者体验,引起不小轰动.
其实原理不复杂,它是基于之前支持的组调度的一个延伸.Unix 世界里,有一个会话(session) 的概念,即跟某一项任务相关的所有进程,可以放在一个会话里,统一管理.比如你登录一个系统,在终端里敲入用户名,密码,然后执行各种操作,这所有进程,就被规划在一个会话里.
因此,在上述例子里,编译代码和终端进程在一个会话里,你的浏览器则在另一个会话里.自动组调度的工作就是,把这些不同会话自动分成不同的调度组,从而利用组调度的优势,使浏览器会话不会过多地受到终端会话的影响,从而提高体验.
该功能可以手动关闭.
10 基于调度域的负载均衡, 2.6.7(2004年6月发布)
计算机依靠并行度来突破性能瓶颈,CPU个数也是与日俱增。最早的是 SMP(对称多处理), 所以 CPU共享内存,并访问速度一致。随着 CPU 个数的增加,这种做法不适应了,因为 CPU 个数的增多,增加了总线访问冲突,这样 CPU 增加的并行度被访问内存总线的瓶颈给抵消了,于是引入了 NUMA(非一致性内存访问)的概念。机器分为若干个node, 每个node(其实一般就是一个 socket)有本地可访问的内存,也可以通过 interconnect 中介机构访问别的 node 的内存,但是访问速度降低了,所以叫非一致性内存访问。Linux 2.5版本时就开始了对 NUMA 的支持[7]。
而在调度器领域,调度器有一个重要任务就是做负载均衡。当某个 CPU 出现空闲,就要从别的 CPU 上调整任务过来执行; 当创建新进程时,调度器也会根据当前负载状况分配一个最适合的 CPU 来执行。然后,这些概念是大大简化了实际情形。
在一个 NUMA 机器上,存在下列层级:
1. 每一个 NUMA node 是一个 CPU socket(你看主板上CPU位置上那一块东西就是一个 socket).
2. 每一个socket上,可能存在两个核,甚至四个核。
3. 每一个核上,可以打开硬件多纯程(HyperThread)。
如果一个机器上同时存在这三人层级,则对调度器来说,它所见的一个逻辑 CPU其实是一人 HyperThread.处理同一个core 中的CPU , 可以共享L1, 乃至 L2 缓存,不同的 core 间,可以共享 L3 缓存(如果存在的话).
基于此,负载均衡不能简单看不同 CPU 上的任务个数,还要考虑缓存,内存访问速度.所以,2.6.7 引入了调度域(sched domain) 的概念,把 CPU 按上述层级划分为不同的层级,构建成一棵树,叶子节点是每个逻辑 CPU, 往上一层,是属于 core 这个域,再往上是属于 socket 这个域,再往上是 NUMA 这个域,包含所有 CPU.
当进行负载均衡时,将从最低一级域往上看,如果能在 core 这个层级进行均衡,那最好;否则往上一级,能在socket 一级进行均衡也还凑合;最后是在 NUMA node 之间进行均衡,这是代价非常大的,因为跨 node 的内存访问速度会降低,也许会得不偿失,很少在这一层进行均衡.
这种分层的做法不仅保证了均衡与性能的平衡,还提高了负载均衡的效率.
关于这方面,可以看这篇文章:Scheduling domains [LWN.net]
11 更精确的调度时钟(HRTICK), 2.6.25(2008年4月发布)
CPU的周期性调度,和基于时间片的调度,是要基于时钟中断来触发的.一个典型的 1000 HZ 机器,每秒钟产生 1000 次时间中断,每次中断到来后,调度器会看看是否需要调度.
然而,对于调度时间粒度为微秒(10^-6)级别的精度来说,这每秒 1000 次的粒度就显得太粗糙了.
2.6.25引入了所谓的高清嘀哒(High Resolution Tick), 以提供更精确的调度时钟中断.这个功能是基于高精度时钟(High Resolution Timer)框架,这个框架让内核支持可以提供纳秒级别的精度的硬件时钟(将会在时钟子系统里讲).
12 自动 NUMA 均衡(Automatic NUMA balancing), 3.8(2013年2月发布)
NUMA 机器一个重要特性就是不同 node 之间的内存访问速度有差异,访问本地 node 很快,访问别的 node 则很慢.所以进程分配内存时,总是优先分配所在 node 上的内存.然而,前面说过,调度器的负载均衡是可能把一个进程从一个 node 迁移到另一个 node 上的,这样就造成了跨 node 的内存访问;Linux 支持 CPU 热插拔,当一个 CPU 下线时,它上面的进程会被迁移到别的 CPU 上,也可能出现这种情况.
调度者和内存领域的开发者一直致力于解决这个问题.由于两大系统都非常复杂,找一个通用的可靠的解决方案不容易,开发者中提出两套解决方案,各有优劣,一直未能达成一致意见.3.8内核中,内存领域的知名黑客 Mel Gorman 基于此情况,引入一个叫自动 NUMA 均衡的框架,以期存在的两套解决方案可以在此框架上进行整合; 同时,他在此框架上实现了简单的策略:每当发现有跨 node 访问内存的情况时,就马上把该内存页面迁移到当前 node 上.
不过到 4.2 ,似乎也没发现之前的两套方案有任意一个迁移到这个框架上,倒是,在前述的简单策略上进行更多改进.
如果需要研究此功能的话,可参考以下几篇文章:
-介绍 3.8 前两套竞争方案的文章:A potential NUMA scheduling solution [LWN.net]
- 介绍 3.8 自动 NUMA 均衡 框架的文章:NUMA in a hurry [LWN.net]
- 介绍 3.8 后进展的两篇文章,细节较多,建议对调度/内存代码有研究后才研读:
NUMA scheduling progress [LWN.net]
NUMA placement problems [LWN.net]
13 CPU 调度与节能
从节能角度讲,如果能维持更多的 CPU 处于深睡眠状态,仅保持必要数目的 CPU 执行任务,就能更好地节约电量,这对笔记本电脑来说,尤其重要.然而这不是一个简单的工作,这涉及到负载均衡,调度器,节能模块的并互,Linux 调度器中曾经有相关的代码,但后来发现问题,在3.5, 3.6 版本中,已经把相关代码删除.整个问题需要重新思考.
在前不久,一个新的 patch 被提交到 Linux 内核开发邮件列表,这个问题也许有了新的眉目,到时再来更新此小节.可阅读此文章:Steps toward power-aware scheduling [LWN.net]
========== 调度子系统 结束分割线 ==========
- 内存管理子系统(memory management)
概述:内存管理子系统,作为 kernel 核心中的核心,是承接所有系统活动的舞台,也是 Linux kernel 中最为庞杂的子系统, 没有之一.截止 4.2 版本,内存管理子系统(下简称 MM)所有平台独立的核心代码(C文件和头文件)达到11万6千多行,这还不包括平台相关的 C 代码, 及一些汇编代码;与之相比,调度子系统的平台独立的核心代码才2万8千多行.
现代操作系统的 MM 提供的一个重要功能就是为每个进程提供独立的虚拟地址空间抽象,为用户呈现一个平坦的进程地址空间,提供安全高效的进程隔离,隐藏所有细节,使得用户可以简单可移植的库接口访问/管理内存,大大解放程序员生产力.
在继续往下之前,先介绍一些 Linux 内核中内存管理的基本原理和术语,方便后文讨论.
- 物理地址(Physical Address): 这就是内存 DIMM 上的一个一个存储区间的物理编址,以字节为单位.
- 虚拟地址(Virtual Address): 技术上来讲,用户或内核用到的地址就是虚拟地址,需要 MMU (内存管理单元,一个用于支持虚拟内存的 CPU 片内机构) 翻译为物理地址.在 CPU 的技术规范中,可能还有虚拟地址和线性地址的区别,但在这不重要.
- NUMA(Non-Uniform Memory Access): 非一致性内存访问.NUMA 概念的引入是为了解决随着 CPU 个数的增长而出现的内存访问瓶颈问题,非一致性内存意为每个 NUMA 节点都有本地内存,提供高访问速度;也可以访问跨节点的内存,但要遭受较大的性能损耗.所以尽管整个系统的内存对任何进程来说都是可见的,但却存在访问速度差异,这一点对内存分配/内存回收都有着非常大的影响.Linux 内核于2.5版本引入对 NUMA的支持[7].
- NUMA node(NUMA节点): NUMA 体系下,一个 node 一般是一个CPU socket(一个 socket 里可能有多个核)及它可访问的本地内存的整体.
- zone(内存区): 一个 NUMA node 里的物理内存又被分为几个内存区(zone), 一个典型的 node 的内存区划分如下:
<img src="https://pic4.zhimg.com/50/b53313b9ef1f062460f90f56bcf6d0b7_hd.jpg" data-caption="" data-rawwidth="237" data-rawheight="157" class="content_image" width="237">
可以看到每个node里,随着物理内存地址的增加,典型地分为三个区:
1. ZONE_DMA: 这个区的存在有历史原因,古老的 ISA 总线外设,它们进行 DMA操作[10] 时,只能访问内存物理空间低 16MB 的范围.所以故有这一区,用于给这些设备分配内存时使用.
2. ZONE_NORMAL: 这是 32位 CPU时代产物,很多内核态的内存分配都是在这个区间(用户态内存也可以在这部分分配,但优先在ZONE_HIGH中分配),但这部分的大小一般就只有 896 MiB, 所以比较局限. 64位 CPU 情况下,内存的访问空间增大,这部分空间就增大了很多.关于为何这部分区间这么局限,且内核态内存分配在这个区间,感兴趣的可以看我之间一个回答[11].
3. ZONE_HIGH: 典型情况下,这个区间覆盖系统所有剩余物理内存.这个区间叫做高端内存区(不是高级的意思,是地址区间高的意思). 这部分主要是用户态和部分内核态内存分配所处的区间.
- 内存页/页面(page): 现代虚拟内存管理/分配的单位是一个物理内存页, 大小是 4096(4KB) 字节. 当然,很多 CPU 提供多种尺寸的物理内存页支持(如 X86, 除了4KB, 还有 2MB, 1GB页支持),但 Linux 内核中的默认页尺寸就是 4KB.内核初始化过程中,会对每个物理内存页分配一个描述符(struct page), 后文描述中可能多次提到这个描述符,它是 MM 内部,也是 MM 与其他子系统交互的一个接口描述符.
- 页表(page table): 从一个虚拟地址翻译为物理地址时,其实就是从一个稀疏哈希表中查找的过程,这个哈希表就是页表.
- 交换(swap): 内存紧缺时, MM 可能会把一些暂时不用的内存页转移到访问速度较慢的次级存储设备中(如磁盘, SSD), 以腾出空间,这个操作叫交换, 相应的存储设备叫交换设备或交换空间.
- 文件缓存页(PageCache Page): 内核会利用空闲的内存, 事先读入一些文件页, 以期不久的将来会用到, 从而避免在要使用时再去启动缓慢的外设(如磁盘)读入操作. 这些有后备存储介质的页面, 可以在内存紧缺时轻松丢弃, 等到需要时再次从外设读入. 典型的代表有可执行代码, 文件系统里的文件.
- 匿名页(Anonymous Page): 这种页面的内容都是在内存中建立的,没有后备的外设, 这些页面在回收时不能简单的丢弃, 需要写入到交换设备中. 典型的代表有进程的栈, 使用 malloc() 分配的内存所在的页等 .
-*-*-*-*-*-*-*-*-*-*-*-*-*-*-* 重要功能和时间点 -*-*-*-*-*-*-*-*-*-*-*-*-*-*-*
下文将按此目录分析 Linux 内核中 MM 的重要功能和引入版本:
目录:
1 内存分配
2 内存去碎片化
3 页表管理
4 页面回收
5 页面写回
6 页面预读
7 大内存页支持
8 内存控制组(Memory Cgroup)支持
9 内存热插拔支持
10 超然内存(Transcendent Memory)支持
11 非易失性内存 (NVDIMM, Non-Volatile DIMM) 支持
12 内存管理调试支持
13 杂项
-*-*-*-*-*-*-*-*-*-*-*-*-*-*-* 正文 -*-*-*-*-*-*-*-*-*-*-*-*-*-*-*
1 内存分配
1.1 页分配器: 伙伴分配器[12] , 古老, 具体时间难考 , 应该是生而有之. orz...
内存页分配器, 是 MM 的一个重大任务, 将内存页分配给内核或用户使用. 内核把内存页分配粒度定为 11 个层次, 叫做阶(order). 第0阶就是 2^0 个(即1个)连续物理页面, 第 1 阶就是 2^1 个(即2个)连续物理页面, ..., 以此类推, 所以最大是一次可以分配 2^10(= 1024) 个连续物理页面.
所以, MM 将所有空闲的物理页面以下列链表数组组织进来:
<img src="https://pic2.zhimg.com/50/1eddf633b4ec562e7bfc4b22fa5375e7_hd.jpg" data-caption="" data-rawwidth="379" data-rawheight="187" class="content_image" width="379">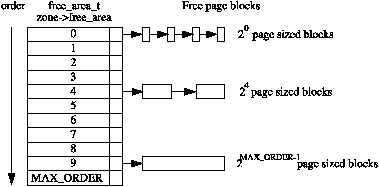
(图片来自Physical Page Allocation)
那伙伴(buddy)的概念从何体现? 体现在释放的时候, 当释放某个页面(组)时, MM 如果发现同一个阶中如果有某个页面(组) 跟这个要释放的页面(组) 是物理连续的, 那就把它们合并, 并升入下一阶(如: 两个 0 阶的页面, 合并后, 变为连续的2页面(组), 即一个1阶页面). 两个页面(组) 手拉手升阶, 所以叫伙伴.
关于NUMA 支持: Linux 内核中, 每个 zone 都有上述的链表数组, 从而提供精确到某个 node 的某个 zone 的伙伴分配需求.
1.2 对象分配器: 内核级别的 malloc 分配器
内核中常见的是经常分配某种固定大小尺寸的对象, 并且对象都需要一定的初始化操作, 这个初始化操作有时比分配操作还要费时, 因此, 一个解决方法是用缓存池把这些对象管理起来, 把第一次分配作初始化; 释放时析构为这个初始状态, 这样能提高效率. 此外, 增加一个缓存池, 把不同大小的对象分类管理起来, 这样能更高效地使用内存 - 试想用固定尺寸的页分配器来分配给对象使用, 则不可避免会出现大量内部碎片. 因此, Linux 内核在页分配器的基础上, 实现了一个对象分配器: slab.
1.2.1 SLAB, 2.0 版本时代(1996年引入)
这是最早引入的对象分配器, SLAB 基于页分配器分配而来的页面(组), 实现自己的对象缓存管理. 它提供预定尺寸的对象缓存, 也支持用户自定义对象缓存, 维护着每个 CPU , 每个 NUMA node 的缓存队列层级, 可以提供高效的对象分配. 同时, 还支持硬件缓存对齐和着色,所谓着色, 就是把不同对象地址, 以缓存行对单元错开, 从而使不同对象占用不同的缓存行,从而提高缓存的利用率并获得更好的性能。
1.2.2 SLUB, 2.6.22(2007年7月发布)
这是第二个对象分配器实现. 引入这个新的实现的原因是 SLAB 存在的一些问题. 比如 NUMA 的支持, SLAB 引入时内核还没支持 NUMA, 因此, 一开始就没把 NUMA 的需求放在设计理念里, 结果导致后来的对 NUMA 的支持比较臃肿奇怪, 一个典型的问题是, SLAB 为追踪这些缓存, 在每个 CPU, 每个 node, 上都维护着对象队列. 同时, 为了满足 NUMA 分配的局部性, 每个 node 上还维护着所有其他 node 上的队列, 这样导致 SLAB 内部为维护这些队列就得花费大量的内存空间, 并且是O(n^2) 级别的. 这在大规模的 NUMA 机器上, 浪费的内存相当可观[13]. 同时, 还有别的一些使用上的问题, 导致开发者对其不满, 因而引入了新的实现.
SLUB 在解决了上述的问题之上, 提供与 SLAB 完全一样的接口, 所以用户可以无缝切换, 而且, 还提供了更好的调试支持. 早在几年前, 各大发行版中的对象分配器就已经切换为 SLUB了.
关于性能, 前阵子为公司的系统切换 SLUB, 做过一些性能测试, 在一台两个 NUMA node, 32 个逻辑 CPU , 252 GB 内存的机器上, 在相同的 workload 测试下, SLUB 综合来说,体现出了比 SLAB 更好的性能和吞吐量.
1.2.3 SLOB, 2.6.16(2006年3月发布)
这是第三个对象分配器, 提供同样的接口, 它是为适用于嵌入式小内存小机器的环境而引入的, 所以实现上很精简, 大大减小了内存 footprint, 能在小机器上提供很不错的性能.
1.3 连续内存分配器(CMA), 3.5(2012年7月发布)
顾名思义,这是一个分配连续物理内存页面的分配器. 也许你会疑惑伙伴分配器不是也能分配连续物理页面吗? 诚然, 但是一个系统在运行若干时间后, 可能很难再找到一片足够大的连续内存了, 伙伴系统在这种情况下会分配失败. 但连续物理内存的分配需求是刚需: 一些比较低端的 DMA 设备只能访问连续的物理内存; 还有下面会讲的透明大页的支持, 也需要连续的物理内存.
一个解决办法就是在系统启动时,在内存还很充足的时候, 先预留一部分连续物理内存页面, 留作后用. 但这有个代价, 这部分内存就无法被作其他使用了, 为了可能的分配需求, 预留这么一大块内存, 不是一个明智的方法.
CMA 的做法也是启动时预留, 但不同的是, 它允许这部分内存被正常使用, 在有连续内存分配需求时, 把这部分内存里的页面迁移走, 从而空出位置来作分配 .
2 内存去碎片化
前面讲了运行较长时间的系统存在的内存碎片化问题, Linux 内核也不能幸免, 因此有开发者陆续提出若干种方法.
2.1 成块回收(Lumpy Reclaim) 2.6.23引入(2007年7月), 3.5移除(2012年7月)
这不是一个完整的解决方案, 它只是缓解这一问题. 所谓回收是指 MM 在分配内存遇到内存紧张时, 会把一部分内存页面回收. 而成块回收[14], 就是尝试成块回收目标回收页相邻的页面,以形成一块满足需求的高阶连续页块。这种方法有其局限性,就是成块回收时没有考虑被连带回收的页面可能是“热页”,即被高强度使用的页,这对系统性能是损伤。
2.2 基于页面可移动性的页面聚类(Page Clustering by Page Mobility) 2.6.23(2007年7月发布)
这个名字是我造的, 有点拗口. 所谓可移动性, 是基于对下列事实的思考: 在去碎片化时,需要移动或回收页面,以腾出连续的物理页面,但可能一颗“老鼠屎就坏了整锅粥”——由于某个页面无法移动或回收,导致整个区域无法组成一个足够大的连续页面块。这种页面通常是内核使用的页面,因为内核使用的页面的地址是直接映射(即物理地址加个偏移就映射到内核空间中),这种做法不用经过页表翻译,提高了效率,却也在此时成了拦路虎。
长年致力于解决内存碎片化的内存领域黑客 Mel Gorman 观察到这个事实, 在经过28个版本[15]的修改后, 他的解决方案进入内核.
Mel Gorman观察到,所有使用的内存页有三种情形:
1.容易回收的(easily reclaimable): 这种页面可以在系统需要时回收,比如文件缓存页,们可以轻易的丢弃掉而不会有问题(有需要时再从后备文件系统中读取); 又比如一些生命周期短的内核使用的页,如DMA缓存区。
2.难回收的(non-reclaimable): 这种页面得内核主动释放,很难回收,内核使用的很多内存页就归为此类,比如为模块分配的区域,比如一些常驻内存的重要内核结构所占的页面。
3. 可移动的(movable): 用户空间分配的页面都属于这种类型,因为用户态的页地址是由页表翻译的,移动页后只要修改页表映射就可以(这也从另一面应证了内核态的页为什么不能移动,因为它们采取直接映射)。
因此, 他修改了伙伴分配器和分配 API, 使得在分配时告知伙伴分配器页面的可移动性: 回收时, 把相同移动性的页面聚类; 分配时, 根据移动性, 从相应的聚类中分配.
聚类的好处是, 结合上述的成块回收方案, 回收页面时,就能保证回收同一类型的; 或者在迁移页面时(migrate page), 就能移动可移动类型的页面,从而腾出连续的页面块,以满足高阶的连续物理页面分配。
关于细节, 可看我之前写的文章:Linux内核中避免内存碎片的方法(1)
2.3 内存紧致化(Memory Compaction) 2.6.35(2010年8月发布)
2.2中讲到页面聚类, 它把相当可移动性的页面聚集在一起: 可移动的在一起, 可回收的在一起, 不可移动的也在一起. 它作为去碎片化的基础. 然后, 利用成块回收, 在回收时, 把可回收的一起回收, 把可移动的一起移动, 从而能空出大量连续物理页面. 这个作为去碎片化的策略.
2.6.35 里, Mel Gorman 又实现了一种新的去碎片化的策略[16], 叫内存紧致化. 不同于成块回收回收相临页面, 内存紧致化则是更彻底, 它在回收页面时被触发, 它会在一个 zone 里扫描, 把已分配的页记录下来, 然后把所有这些页移动到 zone 的一端, 这样这把一个可能已经七零八落的 zone 给紧致化成一段完全未分配的区间和一段已经分配的区间, 这样就又腾出大块连续的物理页面了.
它后来替代了成块回收, 使得后者在3.5中被移除.
3 页表管理
3.1 四级页表 2.6.11(2005年3月发布)
页表实质上是一个虚拟地址到物理地址的映射表, 但由于程序的局部性, 某时刻程序的某一部分才需要被映射, 换句话说, 这个映射表是相当稀疏的, 因此在内存中维护一个一维的映射表太浪费空间, 也不现实. 因此, 硬件层次支持的页表就是一个多层次的映射表.
Linux 一开始是在一台i386上的机器开发的, i386 的硬件页表是2级的(页目录项 -> 页表项), 所以, 一开始 Linux 支持的软件页表也是2级的; 后来, 为了支持 PAE (Physical Address Extension), 扩展为3级; 后来, 64位 CPU 的引入, 3级也不够了, 于是, 2.6.11 引入了四级的通用页表.
关于四级页表是如何适配 i386 的两级页表的, 很简单, 就是虚设两级页表. 类比下, 北京市(省)北京市海淀区东升镇, 就是为了适配4级行政区规划而引入的一种表示法. 这种通用抽象的软件工程做法在内核中不乏例子.
关于四级页表演进的细节, 可看我以前文章: Linux内核4级页表的演进
3.2 延迟页表缓存冲刷 (Lazy-TLB flushing), 极早引入, 时间难考
有个硬件机构叫 TLB, 用来缓存页表查寻结果, 根据程序局部性, 即将访问的数据或代码很可能与刚访问过的在一个页面, 有了 TLB 缓存, 页表查找很多时候就大大加快了. 但是, 内核在切换进程时, 需要切换页表, 同时 TLB 缓存也失效了, 需要冲刷掉. 内核引入的一个优化是, 当切换到内核线程时, 由于内核线程不使用用户态空间, 因此切换用户态的页表是不必要, 自然也不需要冲刷 TLB. 所以引入了 Lazy-TLB 模式, 以提高效率. 关于细节, 可参考[17]
4. 页面回收
/* 从用户角度来看, 这一节对了解 Linux 内核发展帮助不大,可跳过不读; 但对于技术人员来说, 本节可以展现教材理论模型到工程实现的一些思考与折衷, 还有软件工程实践中由简单粗糙到复杂精细的演变过程 */
当 MM 遭遇内存分配紧张时, 会回收页面. 页框替换算法(Page Frame Replacement Algorithm, 下称PFRA) 的实现好坏对性能影响很大: 如果选中了频繁或将马上要用的页, 将会出现 Swap Thrashing 现象, 即刚换出的页又要换回来, 现象就是系统响应非常慢.
4.1 增强的LRU算法 (2.6前引入, 具体时间难考)
教科书式的 PFRA 会提到要用 LRU (Least-Recently-Used) 算法, 该算法思想基于: 最近很少使用的页, 在紧接着的未来应该也很少使用, 因此, 它可以被当作替换掉的候选页.
但现实中, 要跟踪每个页的使用情况, 开销不是一般的大, 尤其是内存大的系统. 而且, 还有一个问题, LRU 考量的是近期的历史, 却没能体现页面的使用频率 - 假设有一个页面会被多次访问, 最近一次访问稍久点了, 这时涌入了很多只会使用一次的页(比如在播放电影), 那么按照 LRU 语义, 很可能被驱逐的是前者, 而不是后者这些不会再用的页面.
为此, Linux 引入了两个链表, 一个 active list, 一个 inactive list , 这两个链表如此工作:
1. inactive list 链表尾的页将作为候选页, 在需要时被替换出系统.
2. 对于文件缓存页, 当第一次被读入时, 将置于 inactive list 链表头。如果它被再次访问, 就把它提升到 active list 链表尾; 否则, 随着新的页进入, 它会被慢慢推到 inactive list 尾巴; 如果它再一次访问, 就把它提升到 active list 链表头.
3. 对于匿名页, 当第一次被读入时, 将置于 active list 链表尾(对匿名页的优待是因为替换它出去要写入交换设备, 不能直接丢弃, 代价更大); 如果它被再次访问, 就把它提升到 active list 链表头,
4. 在需要换页时, MM 会从 active 链表尾开始扫描, 把足够量页面降级到 inactive 链表头, 同样, 默认文件缓存页会受到优待(用户可通过 swappiness 这个用户接口设置权重)。
如上, 上述两个链表按照使用的热度构成了四个层级:
active 头(热烈使用中) > active 尾 > inactive 头 > inactive 尾(被驱逐者)
这种增强版的 LRU 同时考虑了 LRU 的语义: 更近被使用的页在链表头;
又考虑了使用频度: 还是考虑前面的例子, 一个频繁访问的页, 它极有可能在 active 链表头, 或者次一点, 在 active 链表尾, 此时涌入的大量一次性文件缓存页, 只会被放在 inactive 链表头, 因而它们会更优先被替换出去.
4.2 active 与 inactive 链表拆分, 2.6.28(2008年12月)
4.1 中描述过一个用户可配置的接口 : swappiness. 这是一个百分比数(取值 0 -100, 默认60), 当值越靠近100, 表示更倾向替换匿名页; 当值越靠近0, 表示更倾向替换文件缓存页. 这在不同的工作负载下允许管理员手动配置.
4.1 中 规则 4)中说在需要换页时, MM 会从 active 链表尾开始扫描, 如果有一台机器的 swappiness 被设置为 0, 意为完全不替换匿名页, 则 MM 在扫描中要跳过很多匿名页, 如果有很多匿名页(在一台把 swappiness 设为0的机器上很可能是这样的), 则容易出现性能问题.
解决方法就是把链表拆分为匿名页链表和文件缓存页链表[18][19],现在 active 链表分为 active 匿名页链表 和 active 文件缓存页链表了;inactive 链表也如此。 所以, 当 swappiness 为0时,只要扫描 active 文件缓存页链表就够了。
4.3 再拆分出被锁页的链表, 2.6.28(2008年12月)
虽然现在拆分出4个链表了, 但还有一个问题, 有些页被"钉"在内存里(比如实时算法, 或出于安全考虑, 不想含有敏感信息的内存页被交换出去等原因,用户通过 mlock()等系统调用把内存页锁住在内存里). 当这些页很多时, 扫描这些页同样是徒劳的.
所以解决办法是把这些页独立出来, 放一个独立链表. 现在就有5个链表了, 不过有一个链表不会被扫描. [20][21]
4.4 让代码文件缓存页多待一会, 2.6.31(2009年9月发布)
试想, 当你在拷贝一个非常大的文件时, 你发现突然电脑变得反应慢了, 那么可能发生的事情是:
突然涌入的大量文件缓存页让内存告急, 于是 MM 开始扫描前面说的链表, 如果系统的设置是倾向替换文件页的话(swappiness 靠近0), 那么很有可能, 某个 C 库代码所在代码要在这个内存吃紧的时间点(意味扫描 active list 会比较凶)被挑中, 给扔掉了, 那么程序执行到了该代码, 要把该页重新换入, 这就是发生了前面说的 Swap Thrashing 现象了。这体验自然就差了.
解决方法是在扫描这些在使用中的代码文件缓存页时, 跳过它, 让它有多一点时间待在 active 链表上, 从而避免上述问题. [22][23]
4.5 工作集大小的探测, 3.15(2014年6月发布)
一个文件缓存页(代码)一开始进入 inactive 链表表头, 如果它没被再次访问, 它将被慢慢推到 inactive 链表表尾, 最后在回收时被回收走; 而如果有再次访问, 它会被提升到 active 链表尾, 再再次访问, 提升到 active 链表头. 因此, 可以定义一个概念: 访问距离, 它指该页面第一次进入内存到被踢出的间隔, 显然至少是 inactive 链表的长度.
那么问题来了: 这个 inactive 链表的长度得多长? 才能保护该代码页在第二次访问前尽量不被踢出, 以避免 Swap Thrashing 现象.
在这之前内核仅仅简单保证 active 链表不会大于 inactive 链表. 如果进一步思考, 这个问题跟工作集大小相关. 所谓工作集, 就是维持系统所有活动的所需内存页面的最小量. 如果工作集小于等于 inactive 链表长度, 即访问距离, 则是安全的; 如果工作集大于 inactive 链表长度, 即访问距离, 则不可避免有些页要被踢出去.
3.15 就引入了一种算法, 它通过估算访问距离, 来测定工作集的大小, 从而维持 inactive 链表在一个合适长度.[24]
5 页面写回
/* 从用户角度来看, 这一节对了解 Linux 内核发展帮助不大,可跳过不读; 但对于技术人员来说, 本节可以展现教材理论模型到工程实现的一些思考与折衷, 还有软件工程实践中由简单粗糙到复杂精细的演变过程 */
当进程改写了文件缓存页, 此时内存中的内容与后备存储设备(backing device)的内容便处于不一致状态, 此时这种页面叫做脏页(dirty page). 内核会把这些脏页写回到后备设备中. 这里存在一个折衷: 写得太频繁(比如每有一个脏页就写一次)会影响吞吐量; 写得太迟(比如积累了很多个脏页才写回)又可能带来不一致的问题, 假设在写之前系统崩溃, 则这些数据将丢失, 此外, 太多的脏页会占据太多的可用内存. 因此, 内核采取了几种手段来写回:
1) 设一个后台门槛(background threshold), 当系统脏页数量超过这个数值, 用后台线程写回, 这是异步写回.
2) 设一个全局门槛(global threshold), 这个数值比后台门槛高. 这是以防系统突然生成大量脏页, 写回跟不上, 此时系统将扼制(throttle)生成脏页的进程, 让其开始同步写回.
5.1 由全局的脏页门槛到每设备脏页门槛 2.6.24(2008年1月发布)
内核采取的第2个手段看起来很高明 - 扼制生成脏页的进程, 使其停止生成, 反而开始写回脏页, 这一进一退中, 就能把全局的脏页数量拉低到全局门槛下. 但是, 这存在几个微妙的问题:
1. 有可能这大量的脏页是要写回某个后备设备A的, 但被扼制的进程写的脏页则是要写回另一个后备设备B的. 这样, 一个不相干的设备的脏页影响到了另一个(可能很重要的)设备, 这是不公平的.
2. 还有一个更严重的问题出现在栈式设备上. 所谓的栈式设备(stacked device)是指多个物理设备组成的逻辑设备, 如 LVM 或 software RAID 设备上. 操作在这些逻辑设备上的进程只能感知到这些逻辑设备. 假设某个进程生成了大量脏页, 于是, 在逻辑设备这一层, 脏页到达门槛了, 进程被扼制并让其写回脏页, 由于进程只能感知到逻辑设备这一层, 所以它觉得脏页已经写下去了. 但是, 这些脏页分配到底下的物理设备这一层时, 可能每个物理设备都还没到达门槛, 那么在这一层, 是不会真正往下写脏页的. 于是, 这种极端局面造成了死锁: 逻辑设备这一层以为脏页写下去了; 而物理设备这一层还在等更多的脏页以到达写回的门槛.
2.6.24 引入了一个新的改进[25], 就是把全局的脏页门槛替换为每设备的门槛. 这样第1个问题自然就解决了. 第2个问题其实也解决了. 因为现在是每个设备一个门槛, 所以在物理设备这一层, 这个门槛是会比之前的全局门槛低很多的, 于是出现上述问题的可能性也不存在了.
那么问题来了, 每个设备的门槛怎么确定? 设备的写回能力有强有弱(SSD 的写回速度比硬盘快多了), 一个合理的做法是根据当前设备的写回速度分配给等比例的带宽(门槛). 这种动态根据速度调整的想法在数学上就是指数衰减[26]的理念:某个量的下降速度和它的值成比例. 所以, 在这个改进里, 作者引入了一个叫"浮动比例"的库, 它的本质就是一个根据写回速度进行指数衰减的级数. (这个库跟内核具体的细节无关, 感兴趣的可以研究这个代码: [PATCH 19/23] lib: floating proportions [LWN.net]). 然后, 使用这个库, 就可以"实时地"计算出每个设备的带宽(门槛).
5.2 引入更具体扩展性的回写线程 2.6.32(2009年12月发布)
Linux 内核在脏页数量到达一定门槛时, 或者用户在命令行输入 sync 命令时, 会启用后台线程来写回脏页, 线程的数量会根据写回的工作量在2个到8个之间调整. 这些写回线程是面向脏页的, 而不是面向后备设备的. 换句话说, 每个回写线程都是在认领系统全局范围内的脏页来写回, 而这些脏页是可能属于不同后备设备的, 所以回写线程不是专注于某一个设备.
不过随着时间的推移, 这种看似灵巧的方案暴露出弊端.
1. 由于每个回写线程都是可以服务所有后备设备的, 在有多个后备设备, 且回写工作量大时, 线程间的冲突就变得明显了(毕竟, 一个设备同一时间内只允许一个线程写回), 当一个设备有线程占据, 别的线程就得等, 或者去先写别的设备. 这种冲突对性能是有影响的.
2. 线程写回时, 把脏页组成一个个写回请求, 挂在设备的请求队列上, 由设备去处理. 显然,每个设备的处理请求能力是有限的, 即队列长度是有限的. 当一个设备的队列被线程A占满, 新来的线程B就得不到请求位置了. 由于线程是负责多个设备的, 线程B不能在这设备上干等, 就先去忙别的, 以期这边尽快有请求空位空出来. 但如果线程A写回压力大, 一直占着请求队列不放, 那么A就及饥饿了, 时间太久就会出问题.
针对这种情况, 2.6.32为每个后备设备引入了专属的写回线程[27], 换言之, 现在的写回线程是面向设备的. 在写回脏页时, 系统会根据其所属的后备设备, 派发给专门的线程去写回, 从而避免上述问题.
5.3 动态的脏页生成扼制和写回扼制算法 3.1(2011年11月发布), 3.2(2012年1月发布)
本节一开始说的写回扼制算法, 其核心就是谁污染谁治理: 生成脏页多的进程会被惩罚, 让其停止生产, 责成其进行义务劳动, 把系统脏页写回. 在5.1小节里, 已经解决了这个方案的针对于后备设备门槛的一些问题. 但还存在一些别的问题.
1. 写回的脏页的破碎性导致的性能问题. 破碎性这个词是我造的, 大概的意思是, 由于被罚的线程是同步写回脏页到后备设备上的. 这些脏页在后备设备上的分布可能是很散乱的, 这就会造成频繁的磁盘磁头移动, 对性能影响非常大. 而 Linux 存在的一个块层(block layer, 倒数第2个子系统会讲)本来就是要解决这种问题, 而现在写回机制是相当于绕过它了.
2. 系统根据当前可用内存状况决定一个脏页数量门槛, 一到这个门槛值就开始扼制脏页生成. 这种做法太粗野了点. 有时启动一个占内存大的程序(比如一个 kvm), 脏页门槛就会被急剧降低, 就会导致粗暴的脏页生成扼制.
3. 从长远看, 整个系统生成的脏页数量应该与所有后备设备的写回能力相一致. 在这个方针指导下, 对于那些过度生产脏页的进程, 给它一些限制, 扼制其生成脏页的速度. 内核于是设置了一个定点, 在这个定点之下, 内核对进程生成脏页的速度不做限制; 但一超过定点就开始粗暴地限制.
3.1, 3.2 版本中, 来自 Intel 中国的吴峰光博士针对上述问题, 引入了动态的脏页生成扼制和写回扼制算法[27][28]. 其主要核心就是, 不再让受罚的进程同步写回脏页了, 而是罚它睡觉; 至于脏页写回, 会委派给专门的写回线程, 这样就能利用块层的合并机制, 尽可能把磁盘上连续的脏页合并再写回, 以减少磁头的移动时间.
至于标题中的"动态"的概念, 主要有下:
1. 决定受罚者睡多久. 他的算法中, 动态地去估算后备设备的写回速度, 再结合当前要写的脏页量, 从而动态地去决定被罚者要睡的时间.
2. 平缓地修改扼制的门槛. 之前进程被罚的门槛会随着一个重量级进程的启动而走人骤降, 在吴峰光的算法中, 增加了对全局内存压力的评估, 从而平滑地修改这一门槛.
3. 在进程生成脏页的扼制方面, 吴峰光同样采取反馈调节的做法, 针对写回工作量和写回速度, 平缓地(尽量)把系统的脏页生成控制在定点附近.
6 页面预读
/* 从用户角度来看, 这一节对了解 Linux 内核发展帮助不大,可跳过不读; 但对于技术人员来说, 本节可以展现教材理论模型到工程实现的一些思考与折衷, 还有软件工程实践中由简单粗糙到复杂精细的演变过程 */
系统在读取文件页时, 如果发现存在着顺序读取的模式时, 就会预先把后面的页也读进内存, 以期之后的访问可以快速地访问到这些页, 而不用再启动快速的磁盘读写.
6.1 原始的预读方案 (时间很早, 未可考)
一开始, 内核的预读方案如你所想, 很简单. 就是在内核发觉可能在做顺序读操作时, 就把后面的 128 KB 的页面也读进来.
6.2 按需预读(On-demand Readahead) 2.6.23(2007年10月发布)
这种固定的128 KB预读方案显然不是最优的. 它没有考虑系统内存使用状况和进程读取情况. 当内存紧张时, 过度的预读其实是浪费, 预读的页面可能还没被访问就被踢出去了. 还有, 进程如果访问得凶猛的话, 且内存也足够宽裕的话, 128KB又显得太小家子气了.
2.6.23的内核引入了在这个领域耕耘许久的吴峰光的一个按需预读的算法[29]. 所谓的按需预读, 就是内核在读取某页不在内存时, 同步把页从外设读入内存, 并且, 如果发现是顺序读取的话, 还会把后续若干页一起读进来, 这些预读的页叫预读窗口; 当内核读到预读窗口里的某一页时, 如果发现还是顺序读取的模式, 会再次启动预读, 异步地读入下一个预读窗口.
该算法关键就在于适当地决定这个预读窗口的大小,和哪一页做为异步预读的开始. 它的启发式逻辑也非常简单, 但取得不了错的效果. 此外, 对于两个进程在同一个文件上的交替预读, 2.6.24 增强了该算法, 使其能很好地侦测这一行为.
7 大内存页支持
我们知道现代操作系统都是以页面(page)的方式管理内存的. 一开始, 页面的大小就是4K, 在那个时代, 这是一个相当大的数目了. 所以众多操作系统, 包括 Linux , 深深植根其中的就是一个页面是4K大小这种认知, 尽管现代的CPU已经支持更大尺寸的页面(X86体系能支持2MB, 1GB).
我们知道虚拟地址的翻译要经过页表的翻译, CPU为了支持快速的翻译操作, 引入了TLB的概念, 它本质就是一个页表翻译地址结果的缓存, 每次页表翻译后的结果会缓存其中, 下一次翻译时会优先查看TLB, 如果存在, 则称为TLB hit; 否则称为TLB miss, 就要从访问内存, 从页表中翻译. 由于这是一个CPU内机构, 决定了它的尺寸是有限的, 好在由于程序的局部性原理, TLB 中缓存的结果很大可能又会在近期使用.
但是, 过去几十年, 物理内存的大小翻了几番, 但 TLB 空间依然局限, 4KB大小的页面就显得捉襟见肘了. 当运行内存需求量大的程序时, 这样就存在更大的机率出现 TLB miss, 从而需要访问内存进入页表翻译. 此外, 访问更多的内存, 意味着更多的缺页中断. 这两方面, 都对程序性能有着显著的影响.
7.1 HUGETLB支持 (2.6前引入)
如果能使用更大的页面, 则能很好地解决上述问题. 试想如果使用2MB的页(一个页相当于512个连续的4KB 页面), 则所需的 TLB 表项由原来的 512个变成1个, 这将大大提高 TLB hit 的机率; 缺页中断也由原来的512次变为1次, 这对性能的提升是不言而喻的.
然而, 前面也说了 Linux 对4KB大小的页面认知是根植其中的, 想要支持更大的页面, 需要对非常多的核心的代码进行大改动, 这是不现实的. 于是, 为了支持大页面, 有了一个所谓 HUGETLB 的实现.
它的实现是在系统启动时, 按照用户指定需求的最大大页个数, 每个页的大小. 预留如此多个数的大. . 用户在程序中可以使用 mmap() 系统调用或共享内存的方式访问这些大页, 例子网上很多, 或者参考官方文档:hugetlbpage.txt [LWN.net] . 当然, 现在也存在一些用户态工具, 可以帮助用户更便捷地使用. 具体可参考此文章: Huge pages part 2: Interfaces [LWN.net]
这一功能的主要使用者是数据库程序.
7.2 透明大页的支持 2.6.38(2011年3月发布)
7.1 介绍的这种使用大页的方式看起来是挺怪异的, 需要用户程序做出很多修改. 而且, 内部实现中, 也需要系统预留一大部分内存. 基于此, 2.6.38 引入了一种叫透明大页的实现[30]. 如其名字所示, 这种大页的支持对用户程序来说是透明的.
它的实现原理如下. 在缺页中断中, 内核会尝试分配一个大页, 如果失败(比如找不到这么大一片连续物理页面), 就还是回退到之前的做法: 分配一个小页. 在系统内存紧张需要交换出页面时, 由于前面所说的根植内核的4KB页面大小的因, MM 会透明地把大页分割成小页再交换出去.
用户态程序现在可以完成无修改就使用大页支持了. 用户还可以通过 madvice() 系统调用给予内核指示, 优化内核对大页的使用. 比如, 指示内核告知其你希望进程空间的某部分要使用大页支持, 内核会尽可能地满足你.
8 内存控制组(Memory Cgroup)支持 2.6.25(2008年4月发布)
在Linux轻量级虚拟化的实现 container 中(比如现在挺火的Docker, 就是基于container), 一个重要的功能就是做资源隔离. Linux 在 2.6.24中引入了cgroup(control group, 控制组)的资源隔离基础框架(将在最后一个部分详述), 提供了资源隔离的基础.
在2.6.25 中, 内核在此基础上支持了内存资源隔离, 叫内存控制组. 它使用可以在不同的控制组中, 实施内存资源控制, 如分配, 内存用量, 交换等方面的控制.
9 内存热插拔支持
内存热插拔, 也许对于第一次听说的人来说, 觉得不可思议: 一个系统的核心组件, 为何要支持热插拔? 用处有以下几点.
1. 大规模集群中, 动态的物理容量增减, 可以实现更好地支持资源集约和均衡.
2. 大规模集群中, 物理内存出错的机会大大增多, 内存热插拔技术对提高高可用性至关重要.
3. 在虚拟化环境中, 客户机(Guest OS)间的高效内存使用也对热插拔技术提出要求
当然, 作为一个核心组件, 内存的热插拔对从系统固件,到软件(操作系统)的要求, 跟普通的外设热插拔的要求, 不可同日而语. 这也是为什么 Linux 内核对内存热插拔的完全支持一直到近两年才基本完成.
总的来说, 内存热插拔分为两个阶段, 即物理热插拔阶段和逻辑热插拔阶段:
物理热插拔阶段: 这一阶段是内存条插入/拔出主板的过程. 这一过程必须要涉及到固件的支持(如 ACPI 的支持), 以及内核的相关支持, 如为新插入的内存分配管理元数据进行管理. 我们可以把这一阶段分别称为 hot-add / hot-remove.
逻辑热插拔阶段: 这一阶段是从使用者视角, 启用/关闭这部分内存. 这部分的主要从内存分配器方面做的一些准备工作. 我们可以把这一阶段分别称为 online / offline.
逻辑上来讲, 内存插和拔是一个互为逆操作, 内核应该做的事是对称的, 但是, 拔的过程需要关注的技术难点却比插的过程多, 因为, 从无到有容易, 从有到无麻烦:在使用的内存页应该被妥善安置, 就如同安置拆迁户一样, 这是一件棘手的事情. 所以内核对 hot-remove 的完全支持一直推迟到 2013 年.[31]
9.1 内存热插入支持 2.6.15(2006年1月发布)
这提供了最基本的内存热插入支持(包括物理/逻辑阶段). 注意, 此时热拔除还不支持.
9.2 初步的内存逻辑热拔除支持 2.6.24(2008年1月发布)
此版本提供了部分的逻辑热拔除阶段的支持, 即 offline. Offline 时, 内核会把相关的部分内存隔离开来, 使得该部分内存不可被其他任何人使用, 然后再把此部分内存页, 用前面章节说过的内存页迁移功能转移到别的内存上. 之所以说部分支持, 是因为该工作只提供了一个 offline 的功能. 但是, 不是所有的内存页都可以迁移的. 考虑"迁移"二字的含义, 这意味着物理内存地址会变化, 而内存热拔除应该是对使用者透明的, 这意味着, 用户见到的虚拟内存地址不能变化, 所以这中间必须存在一种机制, 可以修改这种因迁移而引起的映射变化. 所有通过页表访问的内存页就没问题了, 只要修改页表映射即可; 但是, 内核自己用的内存, 由于是绕过寻常的逐级页表机制, 采用直接映射(提高了效率), 内核内存页的虚拟地址会随着物理内存地址变动, 因此, 这部分内存页是无法轻易迁移的. 所以说, 此版本的逻辑热拔除功能只是部分完成.
注意, 此版本中, 物理热拔除是还完全未实现. 一句话, 此版本的热拔除功能还不能用.
9.3 完善的内存逻辑热拔除支持 3.8(2013年2月发布)
针对9.2中的问题, 此版本引入了一个解决方案. 9.2 中的核心问题在于不可迁移的页会导致内存无法被拔除. 解决问题的思路是使可能被热拔除的内存不包含这种不可迁移的页. 这种信息应该在内存初始化/内存插入时被传达, 所以, 此版本中, 引入一个 movable_node 的概念. 在此概念中, 一个被 movable_node 节点的所有内存, 在初始化/插入后, 内核确保它们之上不会被分配有不可迁移的页, 所以当热拔除需求到来时, 上面的内存页都可以被迁移, 从而使内存可以被拔除.
9.4 物理热拔除的支持 3.9(2013年4月支持)
此版本支持了物理热拔除, 这包括对内存管理元数据的删除, 跟固件(如ACPI) 相关功能的实现等比较底层琐碎的细节, 不详谈.
在完成这一步之后, 内核已经可以提供基本的内存热插拔支持. 值得一提的是, 内存热插拔的工作, Fujitsu 中国这边的内核开放者贡献了很多 patch. 谢谢他们!
10 超然内存(Transcendent Memory)支持
超然内存(Transcendent Memory), 对很多第一次听见这个概念的人来说, 是如此的奇怪和陌生. 这个概念是在 Linux 内核开发者社区中首次被提出的[32]. 超然内存(后文一律简称为tmem)之于普通内存, 不同之处在于以下几点:
1 tmem 的大小对内核来说是未知的, 它甚至是可变的; 与之相比, 普通内存在系统初始化就可被内核探测并枚举, 并且大小是固定的(不考虑热插拔情形).
2 tmem 可以是稳定的, 也可以是不稳定的, 对于后者, 这意味着, 放入其中的数据, 在之后的访问中可能发现不见了; 与之相比, 普通内存在系统加电状态下一直是稳定的, 你不用担心写入的数据之后访问不到(不考虑内存硬件故障问题).
3 基于以上两个原因, tmem 无法被内核直接访问, 必须通过定义良好的 API 来访问 tmem 中的内存; 与之相比, 普通内存可以通过内存地址被内核直接访问.
初看之下, tmem 这三点奇异的特性, 似乎增加了不必要的复杂性, 尤其是第二条, 更是诡异无用处.
计算机界有句名言: 计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决. tmem 增加的这些间接特性正是为了解决某些问题.
考虑虚拟化环境下, 虚拟机管理器(hypervisor) 需要管理维护各个虚拟客户机(Guest OS)的内存使用. 在常见的使用环境中, 我们新建一台虚拟机时, 总要事先配置其可用的内存大小. 然而这并不十分明智, 我们很难事先确切知道每台虚拟机的内存需求情况, 这难免造成有些虚拟机内存富余, 而有些则捉襟见肘. 如果能平衡这些资源就好了. 事实上, 存在这样的技术, hypervisor 维护一个内存池子, 其中存放的就是这些所谓的 tmem, 它能动态地平衡各个虚拟机的盈余内存, 更高效地使用. 这是 tmem 概念提出的最初来由.
再考虑另一种情形, 当一台机器内存使用紧张时, 它会把一些精心选择的内存页面写到交换外设中以腾出空间. 然而外设与内存存在着显著的读写速度差异, 这对性能是一个不利的影响. 如果在一个超高速网络相连的集群中, 网络访问速度比外设访问速度快, 可不可以有别的想法? tmem 又可以扮演一个重要的中间角色, 它可以把集群中所有节点的内存管理在一个池子里, 从而动态平衡各节点的内存使用, 当某一节点内存紧张时, 写到交换设备页其实是被写到另一节点的内存里...
还有一种情形, 旨在提高内存使用效率.. 比如大量内容相同的页面(全0页面)在池子里可以只保留一份; 或者, tmem 可以考虑对这些页面进行压缩, 从而增加有效内存的使用.
Linux 内核 从 3.X 系列开始陆续加入 tmem 相关的基础设施支持, 并逐步加入了关于内存压缩的功能. 进一步讨论内核中的实现前, 需要对这一问题再进一步细化, 以方便讨论细节.
前文说了内核需要通过 API 访问 tmem, 那么进一步, 可以细化为两个问题.
1. 内核的哪些部分内存可以被 tmem 管理呢? 有两大类, 即前面提到过的文件缓存页和匿名页.
2. tmem 如何管理其池子中的内存. 针对前述三种情形, 有不同的策略. Linux 现在的主要解决方案是针对内存压缩, 提高内存使用效率.
针对这两个问题, 可以把内核对于 tmem 的支持分别分为前端和后端. 前端是内核与 tmem 通讯的接口; 而后端则实现 tmem 的管理策略.
10.1 前端接口之 CLEANCACHE 3.0(2011年7月发布)
前面章节提到过, 内核会利用空闲内存缓存后备外设中的内容, 以期在近期将要使用时不用从缓慢的外设读取. 这些内容叫文件缓存页. 它的特点就是只要是页是干净的(没有被写过), 那么在系统需要内存时, 随时可以直接丢弃这些页面以腾出空间(因为它随时可以从后备文件系统中读取).
然而, 下次内核需要这些文件缓存页时, 又得从外设读取. 这时, tmem 可以起作用了. 内核丢弃时,假如这些页面被 tmem 接收并管理起来, 等内核需要的时候, tmem 把它归还, 这样就省去了读写磁盘的操作, 提高了性能. 3.0 引入的 CLEANCACHE, 作为 tmem 前端接口, hook 进了内核丢弃这些干净文件页的地方, 把这些页面截获了, 放进 tmem 后端管理(后方讲). 从内核角度看, 这个 CLEANCACHE 就像一个魔盒的入口, 它丢弃的页面被吸入这个魔盒, 在它需要时, 内核尝试从这个魔盒中找, 如果找得到, 搞定; 否则, 它再去外设读取. 至于为何被吸入魔盒的页面为什么会找不到, 这跟前文说过的 tmem 的特性有关. 后文讲 tmem 后端时再说.
10.2 前端接口之 FRONTSWAP 3.5(2012年7月发布)
除了文件缓存页, 另一大类内存页面就是匿名页. 在系统内存紧张时, 内核必须要把这些页面写出到外设的交换设备或交换分区中, 而不能简单丢弃(因为这些页面没有后备文件系统). 同样, 涉及到读写外设, 又有性能考量了, 此时又是 tmem 起作用的时候了.
同样, FRONTSWAP 这个前端接口, 正如其名字一样, 在 内核 swap 路径的前面, 截获了这些页面, 放入 tmem 后端管理. 如果后端还有空闲资源的话, 这些页面被接收, 在内核需要这些页面时, 再把它们吐出来; 如果后端没有空闲资源了, 那么内核还是会把这些页面按原来的走 swap 路径写到交换设备中.
10.3 后端之 ZCACHE (没能进入内核主线)
讲完了两个前端接口, 接下来说后端的管理策略. 对应于 CLEANCACHE, 一开始是有一个专门的后端叫 zcache[34], 不过最后被删除了. 它的做法就是把这些被内核逐出的文件缓存页压缩, 并存放在内存中. 所以, zcache 相当于把内存页从内存中的一个地方移到另一个地方, 这乍一看, 感觉很奇怪, 但这正是 tmem 的灵活性所在. 它允许后端有不同的管理策略, 比如在这个情况下, 它把内存页压缩后仍然放在内存中, 这提高了内存的使用. 当然, 毕竟 zcache 会占用一部分物理内存, 导致可用的内存减小. 因此, 这需要有一个权衡. 高效(压缩比, 压缩时间)的压缩算法的使用, 从而使更多的文件页待在内存中, 使得其带来的避免磁盘读写的优势大于减少的这部分内存的代价. 不过, 也因为如此, 它的实现过于复杂, 以至最终没能进入内核主线. 开发者在开始重新实现一个新的替代品, 不过截止至 4.2 , 还没有看到成果.
10.4后端之 ZRAM 3.14(2014年3月发布)
FRONTSWAP 对应的一个后端叫 ZRAM. 值得一提的是, 虽然这个后端实现在 3.14 才进入内核主线, 但其实它早在 2.6.33(2010年2月发布)时就已经进入内核的 staging 分支了, 经过4年的开发优化, 终于成功进入主线. Staging 分支[33] 是在内核源码中的一个子目录, 它是一个独立的分支, 主要维护着独立的 driver 或文件系统, 这些代码未来可能也可能不进入主线.
ZRAM 是一个在内存中的块设备(块设备相对于字符设备而言, 信息存放于固定大小的块中, 支持随机访问, 磁盘就是典型的块设备, 更多将在块层子系统中讲), 因此, 内核可以复用已有的 swap 设备设施, 把这个块设备格式化为 swap 设备. 因此, 被交换出去的页面, 将通过 FRONTSWAP 前端进入到 ZRAM 这个伪 swap 设备中, 并被压缩存放! 当然, 这个ZRAM 空间有限, 因此, 页面可能不被 ZRAM 接受. 如果这种情形发生, 内核就回退到用真正的磁盘交换设备.
10.5 后端之 ZSWAP 3.11(2013年9月发布)
FRONTSWAP 对应的另一个后端叫 ZSWAP[35]. ZSWAP 的做法其实也是尝试把内核交换出去的页面压缩存放到一个内存池子中. 当然, ZSWAP 空间也是有限的. 但同 ZRAM 不同的是, ZSWAP 会智能地把其中一些它认为近期不会使用的页面解压缩, 写回到真正的磁盘外设中. 因此, 大部分情况下, 它能避免磁盘写操作, 这比 ZRAM 不知高明到哪去了.
10.6 一些细节
这一章基本说完了, 但牵涉到后端, 其实还有一些细节可以谈, 比如对于压缩的效率的考量, 会影响到后端实现的选择, 比如不同的内存页面的压缩效果不同(全0页和某种压缩文件占据的内存页的压缩效果显然差距很大)对压缩算法的选择; 压缩后页面的存放策略也很重要, 因为以上后端都存在特殊情况要把页面解压缩写回到磁盘外设, 写回页面的选择与页面的存放策略关系很大. 但从用户角度讲, 以上内容足以, 就不多写了.
关于 tmem, lwn 上的两篇文章值得关注技术细节的人一读:
Transcendent memory in a nutshell [LWN.net]
In-kernel memory compression [LWN.net]
11 非易失性内存 (NVDIMM, Non-Volatile DIMM) 支持
计算机的存储层级是一个金字塔体系, 从塔尖到塔基, 访问速度递减, 而存储容量递增. 从访问速度考量, 内存(DRAM)与磁盘(HHD)之间, 存在着显著的差异(可达到10^5级别[38]). 因此, 基于内存的缓存技术一直都是系统软件或数据库软件的重中之重. 即使近些年出现的新兴的最快的基于PCIe总线的SSD, 这中间依然存在着鸿沟.
<img src="https://pic3.zhimg.com/50/0c0850cde43c84764e65bc24942bc6d3_hd.jpg" data-caption="" data-rawwidth="848" data-rawheight="520" class="origin_image zh-lightbox-thumb" width="848" data-original="https://pic3.zhimg.com/0c0850cde43c84764e65bc24942bc6d3_r.jpg">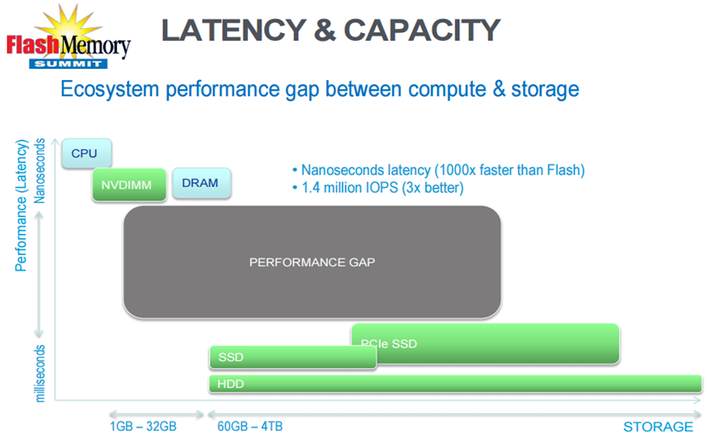
另一方面, 非可易失性内存也并不是新鲜产物. 然而实质要么是一块DRAM, 后端加上一块 NAND FLASH 闪存, 以及一个超级电容, 以在系统断电时的提供保护; 要么就是一块简单的 NAND FLASH, 提供类似 SSD 一样的存储特性. 所有这些, 从访问速度上看, 都谈不上真正的内存, 并且, NAND FLASH 的物理特性, 使其免不了磨损(wear out); 并且在长时间使用后, 存在写性能下降的问题.
2015年算得上闪存技术革命年. 3D NAND FLASH 技术的创新, 以及 Intel 在酝酿的完全不同于NAND 闪存技术的 3D XPoint 内存, 都将预示着填充上图这个性能鸿沟的时刻的临近. 它们不仅能提供更在的容量(TB级别), 更快的访问速度(3D XPoint 按 Intel 说法能提供 ~1000倍快于传统的 NAND FLASH, 5 - 8倍慢于 DRAM 的访问速度), 更持久的寿命.
相应的, Linux 内核也在进行相应的功能支持.
11.1 NVDIMM 支持框架: libnvdimm 4.2(2015年8月30日发布)
2015年4月发布的ACPI 6.0规范[39], 定义了NVDIMM Firmware Interface Table (NFIT), 详细地规定了 NVDIMM 的访问模式, 接口数据规范等细节. 在 Linux 4.2 中, 内核开始支持一个叫 libnvdimm 的子系统, 它实现了 NFIT 的语义, 提供了对 NVDIMM 两种基本访问模式的支持, 一种即内核所称之的 PMEM 模式, 即把 NVDIMM 设备当作持久性的内存来访问; 另一种则提供了块设备模式的访问. 开始奠定 Linux 内核对这一新兴技术的支持.
11.2 DAX 4.0(2015年4月发布)
与这一技术相关的还有另外一个特性值得一提, 那就是 DAX(Direct Access, 直接访问, X 无实义, 只是为了酷).
传统的基于磁盘的文件系统, 在被访问时, 内核总会把页面通过前面所提的文件缓存页(page cache)的缓存机制, 把文件系统页从磁盘中预先加载到内存中, 以提速访问. 然后, 对于新兴的 NVDIMM 设备, 基于它的非易失特性, 内核应该能直接访问基于此设备之上的文件系统的内容, 它使得这一拷贝到内存的操作变得不必要. 4.0 开始引入的 DAX 就是提供这一支持. 截至 4.3, 内核中已经有 XFS, EXT2, EXT4 这几个文件系统实现这一特性.
12 内存管理调试支持
由前面所述, 内存管理相当复杂, 代码量巨大, 而它又是如此重要的一个的子系统, 所以代码质量也要求非常高. 另一方面, 系统各个组件都是内存管理子系统的使用者, 而如果缺乏合理有效的约束, 不正当的内存使用(如内存泄露, 内存覆写)都将引起系统的崩溃, 以至于数据损坏. 基于此, 内存管理子系统引入了一些调试支持工具, 方便开发者/用户追踪,调试内存管理及内存使用中的问题. 本章介绍内存管理子系统中几个重要的调试工具.
12.1 页分配的调试支持 2.5(2003年7月之后发布)
前面提到过, 内核自己用的内存, 由于是绕过寻常的逐级页表机制, 采用直接映射(提高了效率), 即虚拟地址与页面实际的物理地址存在着一一线性映射的关系. 另一方面, 内核使用的内存又是出于各种重要管理目的, 比如驱动, 模块, 文件系统, 甚至 SLAB 子系统也是构建于页分配器之上. 以上二个事实意味着, 相邻的页, 可能被用于完全不同的目的, 而这两个页由于是直接映射, 它们的虚拟地址也是连续的. 如果某个使用者子系统的编码有 bug, 那么它的对其内存页的写操作造成对相邻页的覆写可能性相当大, 又或者不小心读了一个相邻页的数据. 这些操作可能不一定马上引起问题, 而是在之后的某个地方才触发, 导致数据损坏乃至系统崩溃.
为此, 2.5中, 针对 Intel 的 i386 平台, 内核引入了一个 CONFIG_DEBUG_PAGEALLOC 开关, 它在页分配的路径上插入钩子, 并利用 i386 CPU 可以对页属性进行修改的特性, 通过修改未分配的页的页表项的属性, 把该页置为"隐藏". 因此, 一旦不小心访问该页(读或写), 都将引起处理器的缺页异常, 内核将进入缺页处理过程, 因而有了一个可以检查捕捉这种内存破坏问题的机会.
在2.6.30中, 又增加了对无法作处理器级别的页属性修改的体系的支持. 对于这种体系, 该特性是将未分配的页毒化(POISON), 写入特定模式的值, 因而一旦被无意地访问(读或写), 都将可能在之后的某个时间点被发现. 注意, 这种通用的方法就无法像前面的有处理器级别支持的方法有立刻捕捉的机会.
当然, 这个特性是有性能代价的, 所以生产系统中可别用哦.
12.2 SLAB 子系统的调试支持
SLAB 作为一个相对独立的子模块, 一直有自己完善的调试支持, 包括有:
- 对已分配对象写的边界超出的检查
- 对未初始化对象写的检查
- 对内存泄漏或多次释放的检查
- 对上一次分配者进行记录的支持等
12.3 错误注入机制 2.6.20(2007年2月发布)
内核有着极强的健壮性, 能对各种错误异常情况进行合理的处理. 然而, 毕竟有些错误实在是极小可能发生, 测试对这种小概率异常情况的处理的代码实在是不方便. 所以, 2.6.20中内核引入了错误注入机制, 其中跟 MM 相关的有两个, 一个是对页分配器的失败注入, 一个是对 SLAB 对象分配器的失败注入. 这两个注入机制, 可以触发内存分配失败, 以测试极端情况下(如内存不足)系统的处理情况.
12.4 KMEMCHECK - 内存非法访问检测工具 2.6.31(2009年9月发布)
对内存的非法访问, 如访问未分配的内存, 或访问分配了但未初始化的内存, 或访问了已释放了的内存, 会引起很多让人头痛的问题, 比如程序因数据损坏而在某个地方莫名崩溃, 排查非常困难. 在用户态内存检测工具 valgrind 中, 有一个 Memcheck 插件可以检测此类问题. 2.6.31, Linux 内核也引进了内核态的对应工具, 叫 KMEMCHECK.
它是一个内核态工具, 检测的是内核态的内存访问. 主要针对以下问题:
1. 对已分配的但未初始化的页面的访问
2. 对 SLAB 系统中未分配的对象的访问
3. 对 SLAB 系统中已释放的对象的访问
为了实现该功能, 内核引入一个叫影子页(shadow page)的概念, 与被检测的正常数据页一一相对. 这也意味着启用该功能, 不仅有速度开销, 还有很大的内存开销.
在分配要被追踪的数据页的同时, 内核还会分配等量的影子页, 并通过数据页的管理数据结构中的一个 shadow 字段指向该影子页. 分配后, 数据页的页表中的 present 标记会被清除, 并且标记为被 KMEMCHECK 跟踪. 在第一次访问时, 由于 present 标记被清除, 将触发缺页异常. 在缺页异常处理程序中, 内核将会检查此次访问是不是正常. 如果发生上述的非法访问, 内核将会记录下该地址, 错误类型, 寄存器, 和栈的回溯, 并根据配置的值大小, 把该地址附近的数据页和影子页的对应内容, 一并保存到一个缓冲区中. 并设定一个稍后处理的软中断任务, 把这些内容报告给上层. 所有这些之后, 将 CPU 标志寄存器 TF (Trap Flag)置位, 于是在缺页异常后, CPU 又能重新访问这条指令, 走正常的执行流程.
这里面有个问题是, present 标记在第一次缺页异常后将被置位, 之后如果再次访问, KMEMCHECK 如何再次利用该机制来检测呢? 答案是内核在上述处理后还打开了单步调试功能, 所以 CPU 接着执行下一条指令前, 又陷入了调试陷阱(debug trap, 详情请查看 CPU 文档), 在处理程序中, 内核又会把该页的 present 标记会清除.
12.4 KMEMLEAK - 内存泄漏检测工具 2.6.31(2009年9月发布)
内存漏洞一直是 C 语言用户面临的一个问题, 内核开发也不例外. 2.6.31 中, 内核引入了 KMEMLEAK 工具[41], 用以检测内存泄漏. 它采用了标记-清除的垃圾收集算法, 对通过 SLAB 子系统分配的对象, 或通过 vmalloc 接口分配的连续虚拟地址的对象, 或分配的per-CPU对象(per-CPU对象是指每个 CPU 有一份拷贝的全局对象, 每个 CPU 访问修改本地拷贝, 以提高性能)进行追踪, 把指向对象起始的指针, 对象大小, 分配时的栈踪迹(stack trace) 保存在一个红黑树里(便于之后的查找, 同时还会把对象加入一个全局链表中). 之后, KMEMLEAK 会启动一个每10分钟运行一次的内核线程, 或在用户的指令下, 对整个内存进行扫描. 如果某个对象从其起始地址到终末地址内没有别的指针指向它, 那么该对象就被当成是泄漏了. KMEMLEAK 会把相关信息报告给用户.
扫描的大致算法如下:
1. 首先会把全局链表中的对象加入一个所谓的白名单中, 这是所有待查对象. 然后 , 依次扫描数据区(data段, bss段), per-CPU区, 还有针对每个 NUMA 节点的所有页. 另外, 如果用户有指定, 还会描扫所有线程的栈区(之所以这个不是强制扫描, 是因为栈区是函数的活动记录, 变动迅速, 引用可能稍纵即逝). 扫描过程中, 与之前存的红黑树中的对象进行比对, 一旦发现有指针指向红黑树中的对象, 说明该对象仍有人引用 , 没被泄漏, 把它加入一个所谓的灰名单中.
2. 然后, 再扫描一遍灰名单, 即已经被确认有引用的对象, 找出这些对象可能引用的别的所有对象, 也加入灰名单中.
3. 最后剩下的, 在白名单中的, 就是被 KMEMLEAK 认为是泄漏了的对象.
由于内存的引用情况各异, 存在很多特殊情况, 可能存在误报或漏报的情况, 所以 KMEMLEAK 还提供了一些接口, 方便使用者告知 KMEMLEAK 某些对象不是泄露, 某些对象不用检查,等等.
这个工具当然也存在着显著的影响系统性能的问题, 所以也只是作为调试使用.
12.5 KASan - 内核地址净化器 4.0(2015年4月发布)
4.0引入的这个工具[42]可以看作是 KMEMCHECK 工具的替代器, 它的目的也是为了检测诸如释放后访问(use-after-free), 访问越界(out-of-bouds)等非法访问问题. 它比后者更快, 因为它利用了编译器的 Instrument 功能, 也即编译器会在访问内存前插入探针, 执行用户指定的操作, 这通常用在性能剖析中. 在内存的使用上, KASan 也比 KMEMCHECK 有优势: 相比后者1:1的内存使用 , 它只要1:1/8.
总的来说, 它利用了 GCC 5.0的新特性, 可对内核内存进行 Instrumentaion, 编译器可以在访问内存前插入指令, 从而检测该次访问是否合法. 对比前述的 KMEMCHECK 要用到 CPU 的陷阱指令处理和单步调试功能, KASan 是在编译时加入了探针, 因此它的性能更快.
13 杂项
这是最后一章, 讲几个 Linux 内存管理方面的属于锦上添花性质的功能, 它们使 Linux 成为一个更强大, 更好用的操作系统.
13.1 KSM - 内存去重 2.6.32(2009年12月发布)
现代操作系统已经使用了不少共享内存的技术, 比如共享库, 创建新进程时子进程共享父进程地址空间. 而 KSM(Kernel SamePage Merging, 内存同页合并, 又称内存去重), 可以看作是存储领域去重(de-duplication)技术在内存使用上的延伸, 它是为了解决服务器虚拟化领域的内存去重方案. 想像在一个数据中心, 一台物理服务器上可能同时跑着多个虚拟客户机(Guest OS), 并且这些虚拟机运行着很多相同的程序, 如果在物理内存上, 这些程序文本(text)只有一份拷贝, 将会节省相当可观的内存. 而客户机间是相对独立的, 缺乏相互的认知, 所以 KSM 运作在监管机(hypervisor)上.
原理上简单地说, KSM 依赖一个内核线程, 定期地或可手动启动地, 扫描物理页面(通常稳定不修改的页面是合并的候选者, 比如包含执行程序的页面. 用户也可通过一个系统调用给予指导, 告知 KSM 进程的某部份区间适合合并, 见[43]]), 寻找相同的页面并合并, 多余的页面即可释放回系统另为它用. 而剩下的唯一的页面, 会被标为只读, 当有进程要写该页面, 该会为其分配新的页面.
值得一提的是, 在匹配相同页面时, 一种常规的算法是对页面进行哈希, 放入哈希列表, 用哈希值来进行匹配. 最开始 KSM 确定是用这种方法, 不过 VMWare 公司拥有跟该做法很相近的算法专利, 所以后来采用了另一种算法, 用红黑树代替哈希表, 把页面内容当成一个字符串来做内容比对, 以代替哈希比对. 由于在红黑树中也是以该"字符串值"大小作为键, 因此查找两个匹配的页面速度并不慢, 因为大部分比较只要比较开始若干位即可. 关于算法细节, 感兴趣者可以参考这两篇文章:[43], [44].
13.2 HWPoison - 内存页错误的处理 2.6.32(2009年12月发布)
[一开始想把这节放在第12章"内存管理调试支持"中, 不过后来觉得这并非用于主动调试的功能, 所以还是放在此章. ]
随着内存颗粒密度的增大和内存大小的增加, 内存出错的概率也随之增大. 尤其是数据中心或云服务商, 系统内存大(几百 GB 甚至上 TB 级别), 又要提供高可靠的服务(RAS), 不能随随便便宕机; 然而, 内存出错时, 特别是出现多于 ECC(Error Correcting Codes) 内存条所支持的可修复 bit 位数的错误时, 此时硬件也爱莫能助, 将会触发一个 MCE(Machine Check Error) 异常, 而通常操作系统对于这种情况的做法就是 panic (操作系统选择 go die). 但是, 这种粗暴的做法显然是 over kill, 比如出错的页面是一个文件缓存页(page cache), 那么操作系统完全可以把它废弃掉(随后它可以从后备文件系统重新把该页内容读出), 把该页隔离开来不用即是.
这种需求在 Intel 的 Xeon 处理器中得到实现. Intel Xeon 处理器引入了一个所谓 MCA(Machine Check Abort)架构, 它支持包括内存出错的的毒化(Poisoning)在内的硬件错误恢复机制. 当硬件检测到一个无法修复的内存错误时,会把该数据标志为损坏(poisoned); 当之后该数据被读或消费时, 将会触发机器检查(Machine Check), 不同的时, 不再是简单地产生 MCE 异常, 而是调用操作系统定义的处理程序, 针对不同的情况进行细致的处理.
2.6.32 引入的 HWPoison 的 patch, 就是这个操作系统定义的处理程序, 它对错误数据的处理是以页为单位, 针对该错误页是匿名页还是文件缓存页, 是系统页还是进程页, 等等, 多种细致情况采取不同的措施. 关于此类细节, 可看此文章: [45]
13.3 Cross Memory Attach - 进程间快速消息传递 3.2(2012年1月发布)
这一节相对于其他本章内容是独立的. MPI(Message Passing Interface, 消息传递接口) [46] 是一个定义并行编程模型下用于进程间消息传递的一个高性能, 可扩展, 可移植的接口规范(注意这只是一个标准, 有多个实现). 之前的 MPI 程序在进程间共享信息是用到共享内存(shared memory)方式, 进程间的消息传递需要 2 次内存拷贝. 而 3.2 版本引入的 "Cross Memory Attach" 的 patch, 引入两个新的系统调用接口. 借用这两个接口, MPI 程序可以只使用一次拷贝, 从而提升性能.
相关的文章介绍: [47].
========== 内存管理子系统 结束分割线 ==========
- 中断与异常子系统(interrupt & exception)
- 时间子系统(timer & timekeeping)
- 同步机制子系统(synchronization)
- 块层(block layer)
- 文件子系统(Linux 通用文件系统层 VFS, various fs)
- 网络子系统(networking)
- 调试和追踪子系统(debugging, tracing)
- 虚拟化子系统(kvm)
- 控制组(cgroup)
---
引用:
[2] POSIX 关于调度规范的文档: http://nicolas.navet.eu/publi/SlidesPosixKoblenz.pdf
[5] IBM developworks 上有一篇综述文章,值得一读 :Linux 调度器发展简述
[6]CFS group scheduling [LWN.net]
[7]http://lse.sourceforge.net/numa/
[8]CFS bandwidth control [LWN.net]
[9]kernel/git/torvalds/linux.git
[10]DMA模式_百度百科
[11]进程的虚拟地址和内核中的虚拟地址有什么关系? - 詹健宇的回答
[13]The SLUB allocator [LWN.net]
[14]Lumpy Reclaim V3 [LWN.net]
[15]Group pages of related mobility together to reduce external fragmentation v28 [LWN.net]
[16]Memory compaction [LWN.net]
[17]kernel 3.10内核源码分析--TLB相关--TLB概念、flush、TLB lazy模式-humjb_1983-ChinaUnix博客
[18]Toward improved page replacement [LWN.net]
[19]kernel/git/torvalds/linux.git
[20]The state of the pageout scalability patches [LWN.net]
[21]kernel/git/torvalds/linux.git
[22]Being nicer to executable pages [LWN.net]
[23]kernel/git/torvalds/linux.git
[24]Better active/inactive list balancing [LWN.net]
[25]Smarter write throttling [LWN.net]
[26]https://zh.wikipedia.org/wiki/%E6%8C%87%E6%95%B0%E8%A1%B0%E5%87%8F
[27]Flushing out pdflush [LWN.net]
[28]Dynamic writeback throttling [LWN.net]
[29]On-demand readahead [LWN.net]
[30]Transparent huge pages in 2.6.38 [LWN.net]
[31]https://events.linuxfoundation.org/sites/events/files/lcjp13_ishimatsu.pdf
[32]transcendent memory for Linux [LWN.net]
[34]zcache: a compressed page cache [LWN.net]
[35]The zswap compressed swap cache [LWN.net]
[36]Linux-Kernel Archive: Linux 2.6.0
[37]抢占支持的引入时间: https://www.kernel.org/pub/linux/kernel/v2.5/ChangeLog-2.5.4
[38]RAM is 100 Thousand Times Faster than Disk for Database Access
[39] http://www.uefi.org/sites/default/files/resources/ACPI_6.0.pdf
[40]Injecting faults into the kernel [LWN.net]
[41]Detecting kernel memory leaks [LWN.net]
[42]The kernel address sanitizer [LWN.net]
[43]Linux Kernel Shared Memory 剖析
[46]https://www.mcs.anl.gov/research/projects/mpi/
[47]Fast interprocess messaging [LWN.net]
---8<---
更新日志:
- 2015.9.12
o 完成调度器子系统的初次更新, 从早上10点开始写,写了近7小时, 比较累,后面更新得慢的话大家不要怪我(对手指
- 2015.9.19
o 完成内存管理子系统的前4章更新。同样是写了一天,内容太多,没能写完......
- 2015.9.21
o 完成内存管理子系统的第5章"页面写回"的第1小节的更新。
- 2015.9.25
o 更改一些排版和个别文字描述。接下来周末两天继续。
- 2015.9.26
o 完成内存管理子系统的第5, 6, 7, 8章的更新。
- 2015.10.14
o 国庆离网10来天, 未更新。 今天完成了内存管理子系统的第9章的更新。
- 2015.10.16
o 完成内存管理子系统的第10章的更新。
- 2015.11.22
o 这个月在出差和休假, 一直未更新.抱歉! 根据知友
提供的无水印图片和考证资料, 进行了一些小更新和修正. 特此感谢 !
o 完成内存管理子系统的第11章关于 NVDIMM 内容的更新。
- 2016.1.2
o 中断许久, 今天完成了内存管理子系统的第11章关于调试支持内容的更新。
- 2016.2.23
o 又中断许久, 因为懒癌发作Orz... 完成了第二个子系统的所有章节。
收藏感谢收起

LinuxVersions
我要开始搬运了:
2.6.39与3.0两个版本的发布间隔了64天. 那么到底发生了什么?
1. Prominent features
1.1. Btrfs: Automatic defragmentation, scrubbing, performance improvements
Automatic defragmentation
COW (copy-on-write) filesystems have many
advantages, but they also have some disadvantages, for example
fragmentation. Btrfs lays out the data sequentially when files are
written to the disk for first time, but a COW design implies that any
subsequent modification to the file must not be written on top of the
old data, but be placed in a free block, which will cause fragmentation
(RPM databases are a common case of this problem). Aditionally, it
suffers the fragmentation problems common to all filesystems.Btrfs already offers alternatives to fight this
problem: First, it supports online defragmentation using the command
"btrfs filesystem defragment". Second, it has a mount option, -o
nodatacow, that disables COW for data. Now btrfs adds a third option,
the -o autodefrag mount option. This mechanism detects small random
writes into files and queues them up for an automatic defrag process, so
the filesystem will defragment itself while it's used. It isn't suited
to virtualization or big database workloads yet, but works well for
smaller files such as rpm, SQLite or bdb databases. Code: (commit)Scrub
"Scrubbing" is the process of checking the
integrity of the data in the filesystem. This initial implementation of
scrubbing will check the checksums of all the extents in the filesystem.
If an error occurs (checksum or IO error), a good copy is searched for.
If one is found, the bad copy will be rewritten. Code: (commit 1, 2)Other improvements
-File creation/deletion speedup: The performance
of file creation and deletion on btrfs was very poor. The reason is that
for each creation or deletion, btrfs must do a lot of b+ tree
insertions, such as inode item, directory name item, directory name
index and so on. Now btrfs can do some delayed b+ tree insertions or
deletions, which allows to batch these modifications. Microbenchmarks of
file creation have been speed up by ~15%, and file deletion by ~20%.
Code: (commit)-Do not flush csum items of
unchanged file data: speeds up fsync. A sysbench workload doing "random
write + fsync" went from 112.75 requests/sec to 1216 requests/sec. Code:
(commit)-Quasi-round-robin for space
allocation in multidevice setups: the chunk allocator currently always
allocates space on the devices in the same order. This leads to a very
uneven distribution, especially with RAID1 or RAID10 and an uneven
number of devices. Now Btrfs always sorts the devices before allocating,
and allocates the stripes on the devices with the most available space.
Code: (commit)1.2. sendmmsg(): batching of sendmsg() calls
Recvmsg() and sendmsg() are the syscalls used to receive/send data to the network. In 2.6.33, Linux added recvmmsg(),
a syscall that allows to receive in a single call data that would need
multiple recvmsg() calls, improving throughput and latency for a number
of scenarios. Now, a equivalent sendmmsg() syscall has been added. A
microbenchmark saw a 20% improvement in throughput on UDP send and 30%
on raw socket sendCode: (commit)
1.3. XEN dom0 support
Finally, Linux has got Xen dom0 support
1.4. Cleancache
Recommended LWN article: Cleancache and Frontswap
Cleancache is an optional feature that can
potentially increases page cache performance. It could be described as a
memcached-like system, but for cache memory pages. It provides memory
storage not directly accessible or addressable by the kernel, and it
does not guarantee that the data will not vanish. It can be used by
virtualization software to improve memory handling for guests, but it
can also be useful to implement things like a compressed cache.1.5. Berkeley Packet Filter just-in-time filtering
Recommended LWN article: A JIT for packet filters
The Berkeley Packet Filter filtering
capabilities, used by tools like libpcap/tcpdump, are normally handled
by an interpreter. This release adds a simple JIT that generates native
code when filter is loaded in memory (something already done by other
OSes, like FreeBSD). Admin need to enable this feature writting "1" to /proc/sys/net/core/bpf_jit_enableCode: (commit)
1.6. Wake on WLAN support
Wake on Wireless is a feature
to allow the system to go into a low-power state (e.g. ACPI S3 suspend)
while the wireless NIC remains active and does varying things for the
host, e.g. staying connected to an AP or searching for networks. The
802.11 stack has added support for it.1.7. Unprivileged ICMP_ECHO messages
Recommended LWN article: ICMP sockets
This release makes it possible to send ICMP_ECHO
messages (ping) and receive the corresponding ICMP_ECHOREPLY messages
without any special privileges, similar to what is implemented in Mac OS X.
In other words, the patch makes it possible to implement setuid-less
and CAP_NET_RAW-less /bin/ping. Initially this functionality was written
for Linux 2.4.32, but unfortunately it was never made public. The new
functionality is disabled by default, and is enabled at bootup by
supporting Linux distributions, optionally with restriction to a group
or a group range.Code: (commit)
1.8. setns() syscall: better namespace handling
Recommended LWN article: Namespace file descriptors
Linux supports different namespaces for many of
the resources its handles; for example, lightweight forms of
virtualization such as containers or systemd-nspaw
show to the virtualized processes a virtual PID different from the real
PID. The same thing can be done with the filesystem directory
structure, network resources, IPC, etc. The only way to set different
namespace configurations was using different flags in the clone()
syscall, but that system didn't do things like allow to one processes to
access to other process' namespace. The setns() syscall solves that
problem-Code: (commit 1, 2, 3, 4, 5, 6)
1.9. Alarm-timers
Recommended LWN article: Waking systems from suspend
Alarm-timers are a hybrid style timer, similar to
high-resolution timers, but when the system is suspended, the RTC
device is set to fire and wake the system for when the soonest
alarm-timer expires. The concept for Alarm-timers was inspired by the
Android Alarm driver, and the interface to userland uses the POSIX clock
and timers interface, using two new clockids:CLOCK_REALTIME_ALARM and
CLOCK_BOOTTIME_ALARM.2. Driver and architecture-specific changes
All the driver and architecture-specific changes can be found in the Linux_3.0_DriverArch page
3. VFS
Cache xattr security drop check for write: benchmarking on btrfs
showed that a major scaling bottleneck on large systems on btrfs is
currently the xattr lookup on every write, which causes an additional
tree walk, hitting some per file system locks and quite bad scalability.
This is also a problem in ext4, where it hits the global mbcache lock.
Caching this check solves the problem (commit)4. Process scheduler
Increase SCHED_LOAD_SCALE resolution: With this extra resolution,
the scheduler can handle deeper cgroup hiearchies and do better shares
distribution and load balancing on larger systems (especially for low
weight task groups) (commit), (commit)Move the second half of ttwu() to the remote CPU: avoids having
to take rq->lock and doing the task enqueue remotely, saving lots on
cacheline transfers. A semaphore benchmark goes from 647278 worker burns
per second to 816715 (commit)Next buddy hint on sleep and preempt path: a worst-case benchmark
consisting of 2 tbench client processes with 2 threads each running on a
single CPU changed from 105.84 MB/sec to 112.42 MB/sec (commit)5. Memory management
Make mmu_gather preempemtible (commit)
Batch activate_page() calls to reduce zone->lru_lock contention (commit)
tmpfs: implement generic xattr support (commit)
Memory cgroup controller:
6. Networking
Allow setting the network namespace by fd (commit)
Wireless
Allow ethtool to set interface in loopback mode. (commit)
Allow no-cache copy from user on transmit (commit)
ipset: SCTP, UDPLITE support added (commit)
sctp: implement socket option SCTP_GET_ASSOC_ID_LIST (commit), implement event notification SCTP_SENDER_DRY_EVENT (commit)
bridge: allow creating bridge devices with netlink (commit), allow creating/deleting fdb entries via netlink (commit)
batman-adv: multi vlan support for bridge loop detection (commit)
pkt_sched: QFQ - quick fair queue scheduler (commit)
RDMA: Add netlink infrastructure that allows for registration of RDMA clients (commit)
7. File systems
BLOCK LAYER
Submit discard bio in batches in blkdev_issue_discard() - makes discarding data faster (commit)
EXT4
Enable "punch hole" functionality (recommended LWN article) (commit), (commit)
Add support for multiple mount protection (commit)
CIFS
Add support for mounting Windows 2008 DFS shares (commit)
Convert cifs_writepages to use async writes (commit), (commit)
Add rwpidforward mount option that enables a mode when CIFS
forwards pid of a process who opened a file to any read and write
operation (commit)OCFS2
NILFS2
Implement resize ioctl (commit)
XFS
Add online discard support (commit)
8. Crypto
caam - Add support for the Freescale SEC4/CAAM (commit)
padlock - Add SHA-1/256 module for VIA Nano (commit)
s390: add System z hardware support for CTR mode (commit), add System z hardware support for GHASH (commit), add System z hardware support for XTS mode (commit)
s5p-sss - add S5PV210 advanced crypto engine support (commit)
9. Virtualization
User-mode Linux: add earlyprintk support (commit), add ucast Ethernet transport (commit)
xen: add blkback support (commit)
10. Security
Allow the application of capability limits to usermode helpers (commit)
SELinux
11. Tracing/profiling
perf stat: Add -d -d and -d -d -d options to show more CPU events (commit), (commit)
perf stat: Add --sync/-S option (commit)
12. Various core changes
rcu: priority boosting for TREE_PREEMPT_RCU (commit)
ulimit: raise default hard ulimit on number of files to 4096 (commit)
cgroups
kbuild: implement several W= levels (commit)
PM/Hibernate: Add sysfs knob to control size of memory for drivers (commit)
posix-timers: RCU conversion (commit)
coredump: add support for exe_file in core name (commit)
3.19到4.0间隔了63天, 期间究竟发生了什么?:
1. Prominent features
1.1. Arbitrary version change
This release increases the
version to 4.0. This switch from 3.x to 4.0 version numbers is, however,
entirely meaningless and it should not be associated to any important
changes in the kernel. This release could have been 3.20, but Linus
Torvalds just got tired of the old number, made a poll, and changed it. Yes, it is frivolous. The less you think about it, the better.1.2. Live patching
This release introduces
"livepatch", a feature for live patching the kernel code, aimed
primarily at systems who want to get security updates without needing to
reboot. This feature has been born as result of merging kgraft and
kpatch, two attempts by SuSE and Red Hat that where started to replace
the now propietary ksplice. It's relatively simple and minimalistic, as
it's making use of existing kernel infrastructure (namely ftrace) as
much as possible. It's also self-contained and it doesn't hook itself in
any other kernel subsystems.In this release livepatch is not feature
complete, yet it provides a basic infrastructure for function "live
patching" (i.e. code redirection), including API for kernel modules
containing the actual patches, and API/ABI for userspace to be able to
operate on the patches (look up what patches are applied, enable/disable
them, etc). Most CVEs should be safe to apply this way. Only the x86
architecture is supported in this release, others will follow.For more details see the merge commit
Sample live patching module: commit
Code commit
1.3. DAX - Direct Access, for persistent memory storage
Before being read by
programs, files are usually first copied from the disk to the kernel
caches, kept in RAM. But the possible advent of persistent non-volatile
memory that would be also be used as disk changes radically the way the
kernel deals with this process: the kernel cache would become unnecesary
overhead.Linux has had, in fact, support for this kind of setups since 2.6.13.
But the code wasn't maintaned and only supported ext2. In this release,
Linux adds DAX (Direct Access, the X is for eXciting). DAX removes the
extra copy incurred by the buffer by performing reads and writes
directly to the persistent-memory storage device. For file mappings, the
storage device is mapped directly into userspace. Support for ext4 has
been added.Recommended LWN article: Supporting filesystems in persistent memory
Code: commit, commit, commit, commit, commit, commit, commit, commit, commit, commit, commit, commit, commit
1.4. kasan, kernel address sanitizer
Kernel Address sanitizer
(KASan) is a dynamic memory error detector. It provides fast and
comprehensive solution for finding use-after-free and out-of-bounds
bugs. Linux already has the kmemcheck feature, but unlike kmemcheck,
KASan uses compile-time instrumentation, which makes it significantly
faster than kmemcheck.The main idea of KASAN is to use shadow memory to
record whether each byte of memory is safe to access or not, and use
compiler's instrumentation to check the shadow memory on each memory
access. Address sanitizer uses 1/8 of the memory addressable in kernel
for shadow memory and uses direct mapping with a scale and offset to
translate a memory address to its corresponding shadow address.Code: commit, commit, commit, commit, commit
1.5. "lazytime" option for better update of file timestamps
Unix filesystems keep track
of information about files, such as the last time a file was accessed or
modified. Keeping track of this information is very expensive,
specially the time when a file was accessed ("atime"), which encourages
many people to disable it with the mount option "noatime". To alleviate
this problem, the "relatime" mount option was added, the atime is only
updated if the previous value is earlier than the modification time, or
if the file was last accessed more than 24 hours ago. This behaviour,
however, breaks some programs that rely on accurate access time tracking
to work, and it's also against the POSIX standard.In this release, Linux adds another alternative:
"lazytime". Lazytime causes access, modified and changed time updates to
only be made in the cache. The times will only be written to the disk
if the inode needs to be updated anyway for some non-time related
change, if fsync(), syncfs() or sync() are called, or just before an
undeleted inode is evicted from memory. This is POSIX compliant, while
at the same time improving the performance.Recommended LWN article: Introducing lazytime
1.6. Multiple lower layers in overlayfs
In overlayfs, multiple lower
layers can now be given using the the colon (":") as a separator
character between the directory names. For example:
mount -t overlay overlay -olowerdir=/lower1:/lower2:/lower3 /merged
The specified lower directories will be stacked beginning from the
rightmost one and going left. In the above example lower1 will be the
top, lower2 the middle and lower3 the bottom layer. "upperdir=" and
"workdir=" may be omitted, in that case the overlay will be read-only.1.7. Support Parallel NFS server, default to NFS v4.2
Parallel NFS (pNFS) is a part
of the NFS v4.1 standard that allows compute clients to access storage
devices directly and in parallel. The pNFS architecture eliminates the
scalability and performance issues associated with NFS servers deployed
today. This is achieved by the separation of data and metadata, and
moving the metadata server out of the data path.This release adds support for pNFS server, and
drivers for the block layout with XFS support to use XFS filesystems as a
block layout target, and the flexfiles layout.Also, in this release the NFS server defaults to NFS v4.2.
Code: commit, commit, commit, commit, commit, commit
1.8. dm-crypt scalability improvements
This release significantly
increases the dm-crypt CPU scalability performance thanks to changes
that enable effective use of an unbound workqueue across all available
CPUs. A large battery of tests were performed to validate these changes,
summary of results is available hereMerge: commit
2. File systems
XFS
EXT4
Support "readonly" filesystem flag to mark a FS image as
read-only, tunable with tune2fs. It prevents the kernel and e2fsprogs
from changing the image commitBtrfs
Add code to support file creation time commit
NFSv4.1
UBIFS
OCFS2
Add a mount option journal_async_commit on ocfs2 filesystem. When
this feature is opened, journal commit block can be written to disk
without waiting for descriptor blocks, which can improve journal commit
performance. Using the fs_mark benchmark, using journal_async_commit
shows a 50% improvement commitCurrently in case of append O_DIRECT write (block not allocated
yet), ocfs2 will fall back to buffered I/O. This has some
disadvantages. In this version, the direct I/O write doesn't fallback to
buffer I/O write any more because the allocate blocks are enabled in
direct I/O now commit, commit, commitF2FS
Introduce a batched trim commit
Support "norecovery" mount option, which is mostly same as
"disable_roll_forward". The only difference is that "norecovery" should
be activated with read-only mount option. This can be used when user
wants to check whether f2fs is mountable or not without any recovery
process commitAdd F2FS_IOC_GETVERSION ioctl for getting i_generation from
inode, after that, users can list file's generation number by using
"lsattr -v commit3. Block
Ported to blk-multiqueue
blk-multiqueue: Add support for tag allocation policies and make libata use this blk-mq tagging, instead of rolling their own commit, commit
UBI: Implement UBI_METAONLY, a new open mode for UBI volumes, it indicates that only meta data is being changed commit
4. Core (various)
pstore: Add pmsg - user-space accessible pstore object commit
rcu: Optionally run grace-period kthreads at real-time priority.
Recent testing has shown that under heavy load, running RCU's
grace-period kthreads at real-time priority can improve performance and
reduce the incidence of RCU CPU stall warnings commitGDB scripts for debugging the kernel. If you load vmlinux into
gdb with the option enabled, the helper scripts will be automatically
imported by gdb as well, and additional functions are available to
analyze a Linux kernel instance. See Documentation/gdb-kernel-debugging.txt for further details commitRemove CONFIG_INIT_FALLBACK commit
5. Memory management
cgroups: Per memory cgroup slab shrinkers commit
slub: optimize memory alloc/free fastpath by removing preemption on/off commit
Add KPF_ZERO_PAGE flag for zero_page, so that userspace processes
can detect zero_page in /proc/kpageflags, and then do memory analysis
more accurately commitMake /dev/mem an optional device commit
Add support for resetting peak RSS, which can be retrieved from
the VmHWM field in /proc/pid/status, by writing "5" to
/proc/pid/clear_refs commitShow page size in /proc/<pid>/numa_maps as
"kernelpagesize_kB" field to help identifying the size of pages that are
backing memory areas mapped by a given task. This is specially useful
to help differentiating between HUGE and GIGANTIC page backed VMAs commitgeneve: Add Geneve GRO support commit
zsmalloc: add statistics support commit
Incorporate read-only pages into transparent huge pages commit
memcontrol cgroup: Introduce the basic control files to account,
partition, and limit memory using cgroups in default hierarchy mode. The
old interface will be maintained, but a clearer model and improved
workload performance should encourage existing users to switch over to
the new one eventually commitReplace remap_file_pages() syscall with emulation commit
6. Virtualization
KVM: Add generic support for page modification logging, a new
feature in Intel "Broadwell" Xeon CPUs that speeds up dirty page
tracking commitvfio: Add device request interface indicating that the device should be released commit
vmxnet3: Make Rx ring 2 size configurable by adjusting rx-jumbo parameter of ethtool -G commit
virtio_net: add software timestamp support commit
virtio_pci: modern driver commit, add an options to disable legacy driver commit, commit
7. Cryptography
aesni: Add support for 192 & 256 bit keys to AES-NI RFC4106 commit
algif_rng: add random number generator support commit
octeon: add MD5 module commit
qat: add support for CBC(AES) ablkcipher commit
8. Security
SELinux : Add security hooks to the Android Binder that enable
security modules such as SELinux to implement controls over Binder IPC.
The security hooks include support for controlling what process can
become the Binder context manager, invoke a binder transaction/IPC to
another process, transfer a binder reference to another process ,
transfer an open file to another process. These hooks have been included
in the Android kernel trees since Android 4.3 (commit).SMACK: secmark support for netfilter (commit).
Device class for TPM, sysfs files are moved from /sys/class/misc/tpmX/device/ to /sys/class/tpm/tpmX/device/ (commit).
9. Tracing & perf
perf mem: Enable sampling loads and stores simultaneously, it
could only do one or the other before yet there was no hardware
restriction preventing simultaneous collection commitperf tools: Support parameterized and symbolic events. See links for documentation commit, commit
AMD range breakpoints support: breakpoints are
extended to support address range through perf event with initial
backend support for AMD extended breakpoints. For example set write
breakpoint from 0x1000 to 0x1200 (0x1000 + 512): perf record -e
mem:0x1000/512:w commit, commit10. Networking
TCP: Add the possibility to define a per route/destination
congestion control algorithm. This opens up the possibility for a
machine with different links to enforce specific congestion control
algorithms with optimal strategies for each of them based on their
network characteristics commitMitigate TCP "ACK loop" DoS scenarios by rate-limiting outgoing
duplicate ACKs sent in response to incoming "out of window" segments.
For more details, see merge. Code: commit, commit, commit, commitudpv6: Add lockless sendmsg() support, thus allowing multiple threads to send to a single socket more efficiently commit
ipv4: Automatically bring up DSA master network devices, which
allows DSA slave network devices to be used as valid interfaces for e.g:
NFS root booting by allowing kernel IP auto-configuration to succeed on
these interfaces commitipv6: Add sysctl entry(accept_ra_mtu) to disable MTU updates from router advertisements commit
vxlan: Implement supports for the Group Policy VXLAN extension
to provide a lightweight and simple security label mechanism across
network peers based on VXLAN. It allows further mapping to a SELinux
context using SECMARK, to implement ACLs directly with nftables,
iptables, OVS, tc, etc commitvxlan: Add support for remote checksum offload in VXLAN. It is described here. commit
net: openvswitch: Support masked set actions. commit
Infiniband: Add support for extensible query device capabilities verb to allow adding new features commit
Layer 2 Tunneling Protocol (l2tp): multicast notification to the
registered listeners when the tunnels/sessions are
created/modified/deleted commitSUNRPC: Set SO_REUSEPORT socket option for TCP
connections to bind multiple TCP connections to the same source
address+port combination committipc: involve namespace infrastructure commit
802.15.4: introduce support for cca settings commit
Wireless
Add new GCMP, GCMP-256, CCMP-256, BIP-GMAC-128, BIP-GMAC-256, and
BIP-CMAC-256 cipher suites. These new cipher suites were defined in
IEEE Std 802.11ac-2013 commit, commit, commit, commit, commitNew NL80211_ATTR_NETNS_FD which allows to set namespace via nl80211 by fd commit
Support per-TID station statistics commit
Allow usermode to query wiphy specific regdom commit
bridge
Near Field Communication (NFC)
HCI over NCI protocol support (Some secure elements only understand HCI and thus we need to send them HCI frames) commit
NCI NFCEE (NFC Execution Environment, typically an embedded or
external secure element) discovery and enabling/disabling support commit, commit, commit, commit, commit, commit, commitNFC_EVT_TRANSACTION userspace API addition, it is sent through
netlink in order for a specific application running on a secure element
to notify userspace of an event commitTx timestamps are looped onto the error queue on top of an skb.
This mechanism leaks packet headers to processes unless the no-payload
options SOF_TIMESTAMPING_OPT_TSONLY is set. A new sysctl
(tstamp_allow_data) optionally drops looped timestamp with data. This
only affects processes without CAP_NET_RAW commit, commit, commitBluetooth
tc: add BPF-based action. This action provides a possibility to execute custom BPF code commit
net: sched: Introduce connmark action commit
Add Transparent Ethernet Bridging GRO support commit
netdev: introduce new NETIF_F_HW_SWITCH_OFFLOAD feature flag for switch device offloads commit
netfilter: nft_compat: add ebtables support commit
openvswitch: Add support for checksums on UDP tunnels. commit
openvswitch: Support VXLAN Group Policy extension commit
每一个release具体做了什么改动, 请看这里:
LinuxVersions
现在的 Linux 内核和 Linux 2.6 的内核有多大区别?的更多相关文章
- Linux 内核概述 - Linux Kernel
Linux 内核学习笔记整理. Unix unix 已有40历史,但计算机科学家仍认为其是现存操作系统中最大和最优秀的系统,它已成为一种传奇的存在,历经时间的考验却依然声名不坠. 1973 年,在用 ...
- Linux基础系列—Linux内核源码目录结构
/** ****************************************************************************** * @author 暴走的小 ...
- Linux基础系列—Linux体系结构和Linux内核结构
/** ****************************************************************************** * @author 暴走的小 ...
- linux内核学习之二:编译内核
在linux内核学习系列的第一课中讲述了搭建学习环境的过程(http://www.cnblogs.com/xiongyuanxiong/p/3523306.html),环境搭好后,马上就进入到下一环节 ...
- Linux内核设计基础(十)之内核开发与总结
(1)Linux层次结构: (2)Linux内核组成: 主要由进程调度(SCHED).内存管理(MM).虚拟文件系统(VFS).网络接口(NET)和进程间通信(IPC)等5个子系统组成. (3)与Un ...
- 以Qemu模拟Linux,学习Linux内核
文章名称:以Qemu模拟Linux,学习Linux内核作 者:five_cent文章地址:http://www.cnblogs.com/senix/archive/2013/02/21/29 ...
- linux 实现centos7在线升级最新版本内核
Kernel (内核)是操作系统的核心,掌握所有硬件设备的控制权,也就是说,你所希望计算机帮你完成的各项工作,都需要通过内核的帮助才能完成,当然,如果我们想完成的某个功能是内核没有的,则内核不会操控 ...
- 【转帖】Linux的历史----Linux内核剖析(一)
Linux的历史----Linux内核剖析(一) 2015年04月09日 10:51:09 JeanCheng 阅读数:11351更多 所属专栏: Linux内核剖析 版权声明:本文为博主原创文 ...
- Linux内核分析——Linux内核学习总结
马悦+原创作品转载请注明出处+<Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 Linux内核学习总结 一 ...
- Linux新系统的安全优化和内核参数优化
拿到一个新的linux系统需要做的安全和内核优化,主要是为了提升系统安全和提升性能,满足后续的应用需要.这里简单记录一下拿到一个新的系统需要做的一些事情,仅此抛砖引玉,具体可根据自己实际情况进行设置. ...
随机推荐
- runtime error (运行时错误)
比如说: ①除以零 ②数组越界:int a[3]; a[10000000]=10; ③指针越界:int * p; p=(int *)malloc(5 * sizeof(int)); *(p+10000 ...
- Thumbnailator java图片压缩,加水印,批量生成缩略图
地址:http://code.google.com/p/thumbnailator/ 1.指定大小进行缩放 //size(宽度, 高度) /* * 若图片横比200小,高比300小,不变 * 若图片横 ...
- Android NDK: Are you sure your NDK_MODULE_PATH variable is properly defined
遇到问题: Android NDK: jni/Android.mk: Cannot find module with tag 'XXXXXXXXX' in import path Android ND ...
- hdu1227 dp
题意:在一条路上有 n 个站点,并给定了每个站点的坐标,然后想要在 k 个站点旁边分别各建一个补给站,求所有站点到最近的补给站的距离和的最小值. 是的,毫无疑问,显然是 DP 问题,但是这题怎么递推还 ...
- sleep和 wait
- 下载各个版本java (Java Development Kit)
本文介绍怎么样下载各个版本java开发工具包. 方法/步骤 打开官方下载网址:http://www.oracle.com/technetwork/java/javase/downloads/ind ...
- Uboot启动命令使用
1.查看根文件系统中的内容 打断Uboot的启动,默认从SD卡启动,查看根文件系统中/boot下的内容(根文件系统在mmcblk0p1上):=> mmc rescan=> ext4ls m ...
- windows 版nginx 的一些基础知识
nginx的Windows版本使用原生Win32 API(非Cygwin模拟层).当前nginx/Windows只使用select作为通知方法,所以不要期待它有很高的性能和扩展性.鉴于这点和一些已知问 ...
- 根据日期计算星期几----蔡勒(Zeller)公式推导
计算给定日期是星期几,好象是编程都会遇到的问题,最近论坛里也有人提到这个问题,并给出了一个公式: W= (d+2*m+3*(m+1)/5+y+y/4-y/100+y/400 ...
- DOMContentLoaded 和 Load 事件 区别(待补充)
javascript会阻塞dom的解析.当解析过程中遇到<script>标签的时候,便会停止解析过程,转而去处理脚本,如果脚本是内联的,浏览器会先去执行这段内联的脚本,如果是外链的,那么先 ...