tair介绍以及配置
简介
tair 是淘宝自己开发的一个分布式 key/value 存储引擎. tair 分为持久化和非持久化两种使用方式. 非持久化的 tair 可以看成是一个分布式缓存. 持久化的 tair 将数据存放于磁盘中. 为了解决磁盘损坏导致数据丢失, tair 可以配置数据的备份数目, tair 自动将一份数据的不同备份放到不同的主机上, 当有主机发生异常, 无法正常提供服务的时候, 其于的备份会继续提供服务.
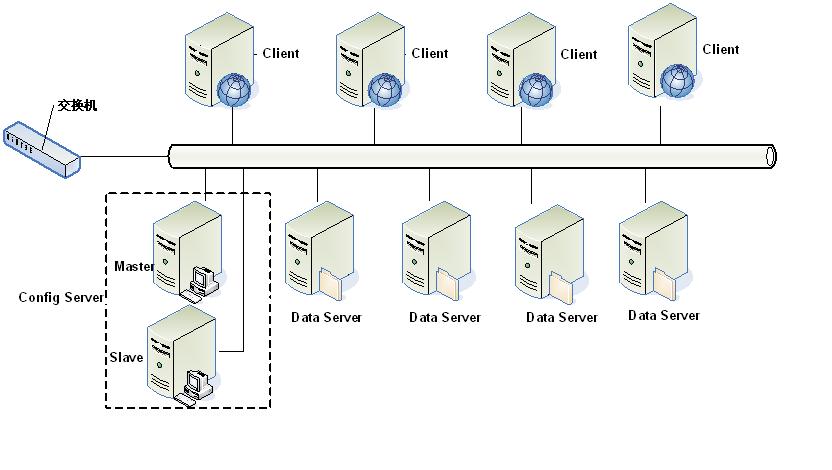
tair 的总体结构
tair 作为一个分布式系统, 是由一个中心控制节点和一系列的服务节点组成. 我们称中心控制节点为config server. 服务节点是data server. config server 负责管理所有的data server, 维护data server的状态信息. data server 对外提供各种数据服务, 并以心跳的形式将自身状况汇报给config server. config server是控制点, 而且是单点, 目前采用一主一备的形式来保证其可靠性. 所有的 data server 地位都是等价的.
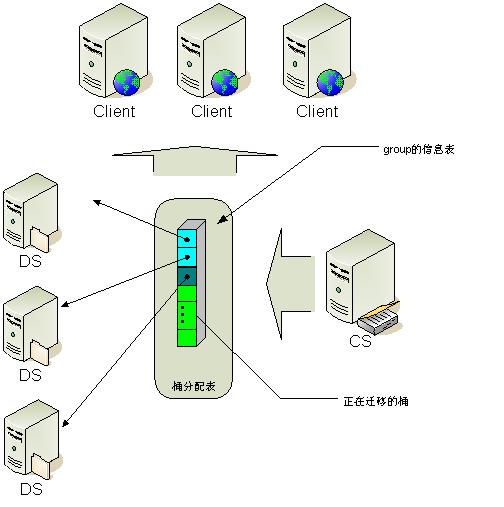
tair 的负载均衡算法是什么
tair 的分布采用的是一致性哈希算法, 对于所有的key, 分到Q个桶中, 桶是负载均衡和数据迁移的基本单位. config server 根据一定的策略把每个桶指派到不同的data server上. 因为数据按照key做hash算法, 所以可以认为每个桶中的数据基本是平衡的. 保证了桶分布的均衡性, 就保证了数据分布的均衡性.
增加或者减少data server的时候会发生什么
当有某台data server故障不可用的时候, config server会发现这个情况, config server负责重新计算一张新的桶在data server上的分布表, 将原来由故障机器服务的桶的访问重新指派到其它的data server中. 这个时候, 可能会发生数据的迁移. 比如原来由data server A负责的桶, 在新表中需要由 B负责. 而B上并没有该桶的数据, 那么就将数据迁移到B上来. 同时config server会发现哪些桶的备份数目减少了, 然后根据负载情况在负载较低的data server上增加这些桶的备份. 当系统增加data server的时候, config server根据负载, 协调data server将他们控制的部分桶迁移到新的data server上. 迁移完成后调整路由. 当然, 系统中可能出现减少了某些data server 同时增加另外的一些data server. 处理原理同上. 每次路由的变更, config server都会将新的配置信息推给data server. 在客户端访问data server的时候, 会发送客户端缓存的路由表的版本号. 如果data server发现客户端的版本号过旧, 则会通知客户端去config server取一次新的路由表. 如果客户端访问某台data server 发生了不可达的情况(该 data server可能宕机了), 客户端会主动去config server取新的路由表.
发生迁移的时候data server如何对外提供服务
当迁移发生的时候, 我们举个例子, 假设data server A 要把 桶 3,4,5 迁移给data server B. 因为迁移完成前, 客户端的路由表没有变化, 客户端对 3, 4, 5 的访问请求都会路由到A. 现在假设 3还没迁移, 4 正在迁移中, 5已经迁移完成. 那么如果是对3的访问, 则没什么特别, 跟以前一样. 如果是对5的访问, 则A会把该请求转发给B,并且将B的返回结果返回给客户, 如果是对4的访问, 在A处理, 同时如果是对4的修改操作, 会记录修改log.当桶4迁移完成的时候, 还要把log发送到B, 在B上应用这些log. 最终A B上对于桶4来说, 数据完全一致才是真正的迁移完成. 当然, 如果是因为某data server宕机而引发的迁移, 客户端会收到一张中间临时状态的分配表. 这张表中, 把宕机的data server所负责的桶临时指派给有其备份data server来处理. 这个时候, 服务是可用的, 但是负载可能不均衡. 当迁移完成之后, 才能重新达到一个新的负载均衡的状态.
桶在data server上分布时候的策略
程序提供了两种生成分配表的策略, 一种叫做负载均衡优先, 一种叫做位置安全优先: 我们先看负载优先策略. 当采用负载优先策略的时候, config server会尽量的把桶均匀的分布到各个data server上. 所谓尽量是指在不违背下面的原则的条件下尽量负载均衡. 1 每个桶必须有COPY_COUNT份数据 2 一个桶的各份数据不能在同一台主机上; 位置安全优先原则是说, 在不违背上面两个原则的条件下, 还要满足位置安全条件, 然后再考虑负载均衡. 位置信息的获取是通过 _pos_mask(参见安装部署文档中关于配置项的解释) 计算得到. 一般我们通过控制 _pos_mask 来使得不同的机房具有不同的位置信息. 那么在位置安全优先的时候, 必须被满足的条件要增加一条, 一个桶的各份数据不能都位于相同的一个位置(不在同一个机房). 这里有一个问题, 假如只有两个机房, 机房1中有100台data server, 机房2中只有1台data server. 这个时候, 机房2中data server的压力必然会非常大. 于是这里产生了一个控制参数 _build_diff_ratio(参见安装部署文档). 当机房差异比率大于这个配置值时, config server也不再build新表. 机房差异比率是如何计出来的呢? 首先找到机器最多的机房, 不妨设使RA, data server数量是SA. 那么其余的data server的数量记做SB. 则机房差异比率=|SA – SB|/SA. 因为一般我们线上系统配置的COPY_COUNT是3. 在这个情况下, 不妨设只有两个机房RA和RB, 那么两个机房什么样的data server数量是均衡的范围呢? 当差异比率小于 0.5的时候是可以做到各台data server负载都完全均衡的.这里有一点要注意, 假设RA机房有机器6台,RB有机器3台. 那么差异比率 = 6 – 3 / 6 = 0.5. 这个时候如果进行扩容, 在机房A增加一台data server, 扩容后的差异比率 = 7 – 3 / 7 = 0.57. 也就是说, 只在机器数多的机房增加data server会扩大差异比率. 如果我们的_build_diff_ratio配置值是0.5. 那么进行这种扩容后, config server会拒绝再继续build新表.
tair 的一致性和可靠性问题
分布式系统中的可靠性和一致性是无法同时保证的, 因为我们必须允许网络错误的发生. tair 采用复制技术来提高可靠性, 并且为了提高效率做了一些优化, 事实上在没有错误发生的时候, tair 提供的是一种强一致性. 但是在有data server发生故障的时候, 客户有可能在一定时间窗口内读不到最新的数据. 甚至发生最新数据丢失的情况.
tair提供的客户端
tair 的server端是C++写的, 因为server和客户端之间使用socket通信, 理论上只要可以实现socket操作的语言都可以直接实现成tair客户端. 目前实际提供的客户端有java 和 C++. 客户端只需要知道config server的位置信息就可以享受tair集群提供的服务了.
摘自http://code.taobao.org/p/tair/wiki/intro/
--------------------------------------------------------------------------------------------
安装部署:
一 如何安装tair:
- 确保安装了automake autoconfig 和 libtool,使用automake --version查看,一般情况下已安装
- 获得底层库 tbsys 和 tbnet的源代码:(svn checkout http://code.taobao.org/svn/tb-common-utils/trunk/ tb-common-utils).
- 获得tair源代码:(svn checkout http://code.taobao.org/svn/tair/trunk/ tair).
- 安装boost-devel库,在用rpm管理软件包的os上可以使用rpm -q boost-devel查看是否已安装该库
- 编译安装tbsys和tbnet
- 编译安装tair
- tair 的底层依赖于tbsys库和tbnet库, 所以要先编译安装这两个库:
- 编译安装tair:
export TBLIB_ROOT="/usr/local/tairlib"
yum install svn automake zlib-deve libtool boost-devel -y
svn checkout http://code.taobao.org/svn/tb-common-utils/trunk/ tb-common-utils
svn checkout http://code.taobao.org/svn/tair/trunk/ tair
- 配置文件 configserver.conf
- 配置文件 group.conf
- data server的配置文件

- TAIR> put k1 v1
- put: success
- TAIR> put k2 v2
- put: success
- TAIR> get k2
- KEY: k2, LEN: 2
- 作用:移除指定的(key,data)
说明:输出如下帮助信息
- SYNOPSIS : remove key [area]
- key: 指定想要移除的key。
- area: 指定某个命名空间,默认值为0
TAIR>remove keyname 0
tair介绍以及配置的更多相关文章
- 03_MyBatis基本查询,mapper文件的定义,测试代码的编写,resultMap配置返回值,sql片段配置,select标签标签中的内容介绍,配置使用二级缓存,使用别名的数据类型,条件查询ma
1 PersonTestMapper.xml中的内容如下: <?xmlversion="1.0"encoding="UTF-8"?> < ...
- python学习第二讲,pythonIDE介绍以及配置使用
目录 python学习第二讲,pythonIDE介绍以及配置使用 一丶集成开发环境IDE简介,以及配置 1.简介 2.PyCharm 介绍 3.pycharm 的安装 二丶IDE 开发Python,以 ...
- OSPF协议介绍及配置 (上)
OSPF协议介绍及配置 (上) 一.OSPF概述 回顾一下距离矢量路由协议的工作原理:运行距离矢量路由协议的路由器周期性的泛洪自己的路由表,通过路由的交互,每台路由器都从相邻的路由器学习到路由,并且加 ...
- x-pack 功能介绍及配置传输层安全性(TLS / SSL)
x-pack 功能介绍及配置传输层安全性(TLS / SSL) 学习了:https://blog.csdn.net/wfs1994/article/details/80411047
- mysql多实例介绍及配置
mysql多实例介绍及配置 1.mysql多实例介绍 1.1 什么是mysql多实例 mysql多实例就是在一台机器上开启多个不同的服务端口(如:3306,3307),运行多个MySQL服务进程,通过 ...
- 13.LAMP架构介绍及配置
LAMP架构介绍及配置 LAMP简介与概述 LAMP概述 LAMP架构是目前成熟的企业网站应用模式之一,指的是协同工作的一整套系统和相关软件,能够提供动态Web站点服务及其应用开发环境. LAMP是一 ...
- Rsync原理介绍及配置应用
1.前言 基于LAN或WAN的网络应用之间进行数据传输或者同步非常普遍,比如远程数据镜像.备份.复制.同步,数据下载.上传.共享等等.对此,最简单.直接的做法是对数据进行完全复制.然而,数据在网络上来 ...
- 日志组件logback的介绍及配置使用方法
一.logback的介绍 Logback是由log4j创始人设计的又一个开源日志组件.logback当前分成三个模块:logback-core,logback- classic和logback-acc ...
- LVS 介绍以及配置应用
1.负载均衡集群介绍 1.1.什么是负载均衡集群 负载均衡集群提供了一种廉价.有效.透明的方法,来扩展网络设备和服务器的负载.带宽.增加吞吐量.加强网络数据的处理能力.提高网络的灵活性和可用性 搭建负 ...
随机推荐
- http常用状态码说明
HTTP状态码:每发出一个http请求之后,就会有一个响应,http本身会有一个状态码,来标示这个请求是否成功,常见状态码: 200,2开头的都表示这个请求发送成功,最常见的就是200 300,3开头 ...
- TopCoder客户端安装
参考:https://blog.csdn.net/github_39353095/article/details/76165940 首先,下载 Java 环境. https://www.java.co ...
- Angular 4.0 安装组件
安装组件 ng g componet 组件名
- Android 禁止系统进入深度休眠
在Linux系统中,wake_lock是一直锁机制,只要有驱动占用这个锁,系统就不会进入深度休眠. 获取此锁的方法有两种: 1.在adb中通过指令获取wake_lock,系统就不会进入深度休眠 ech ...
- oracle 无法启动图形界面,no protocol specified
linux 终端启动图形化程序界面时报错:No protocol specified这是因为Xserver默认情况下不允许别的用户的图形程序的图形显示在当前屏幕上. 如果需要别的用户的图形显示在当前屏 ...
- sql distinct 去除重复的字段
居然已经有人写了 那我就直接复制其链接吧
- Jsoncpp 使用方法大全
Json(JavaScript Object Notation )是一种轻量级的数据交换格式.简而言之,Json组织形式就和python中的字典, C/C++中的map一样,是通过key-value对 ...
- 小峰mybatis(5)mybatis使用注解配置sql映射器--动态sql
一.使用注解配置映射器 动态sql: 用的并不是很多,了解下: Student.java 实体bean: package com.cy.model; public class Student{ pri ...
- [UE4]蓝图Get Control Rotation获取人物角色朝向,设置默认人物相机,朝向与controller绑定
具体应用:控制人物移动方向 也可以使用“CombineRotators”将角色控制器Z轴旋转90°,然后再取正面方向,达到跟“Get Right Vector”一样的效果: 设置关联人物朝向使用控制器 ...
- linux下一个监测进程CPU和MEM使用率的shell脚本
#!/bin/bashPID=$1 cpu=`ps --no-heading --pid=$PID -o pcpu`mem=`ps --no-heading --pid=$PID -o pmem`ec ...