利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题
案例代码:
# __author : "J"
# date : 2018-03-06 # 导入需要用到的库文件
import urllib.request
import re
import pymysql # 创建一个类用于获取学校官网的十条标题
class GetNewsTitle: # 构造函数 初始化
def __init__(self):
self.request = urllib.request.Request("http://www.sict.edu.cn/") # 需要爬取的网址
# 利用正则表达式筛选数据
self.my_re = re.compile(
r'学校要闻.*?' +
r'"a2" >(.*?)</a>.*?' +
r'"a2" >(.*?)</a>.*?' +
r'"a2" >(.*?)</a>.*?' +
r'"a2" >(.*?)</a>.*?' +
r'"a2" >(.*?)</a>.*?' +
r'"a2" >(.*?)</a>.*?' +
r'"a2" >(.*?)</a>.*?' +
r'"a2" >(.*?)</a>.*?' +
r'"a2" >(.*?)</a>.*?' +
r'"a2" >(.*?)</a>.*?' +
r'院部简讯') # 创建一个方法
def get_html(self):
try:
response = urllib.request.urlopen(self.request)
# 获取目标网页源码
my_html = response.read().decode('GB2312').replace("\r\n", "")
return my_html
except urllib.request.HTTPError as e:
print(e.code)
print(e.reason)
return # 创建一个函数,利用正则获取指定标题
def get_titles(self, my_html):
news_titles = re.findall(self.my_re, my_html)
return news_titles # 创建一个方法,把获取到的标题存入mysql数据库
def into_mysql(self, titles):
for num in range(10):
connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='******', db='school',
charset='utf8')
cursor = connection.cursor()
sql = "INSERT INTO `newsTitles` (`title`) VALUES ('" + titles[0][num] + "')"
cursor.execute(sql)
connection.commit()
cursor.close()
connection.close() # 执行函数的入口
def start(self):
self.into_mysql(self.get_titles(self.get_html()))
print("存储成功!") # 实例化类
s = GetNewsTitle()
# 调用方法开始执行
s.start()
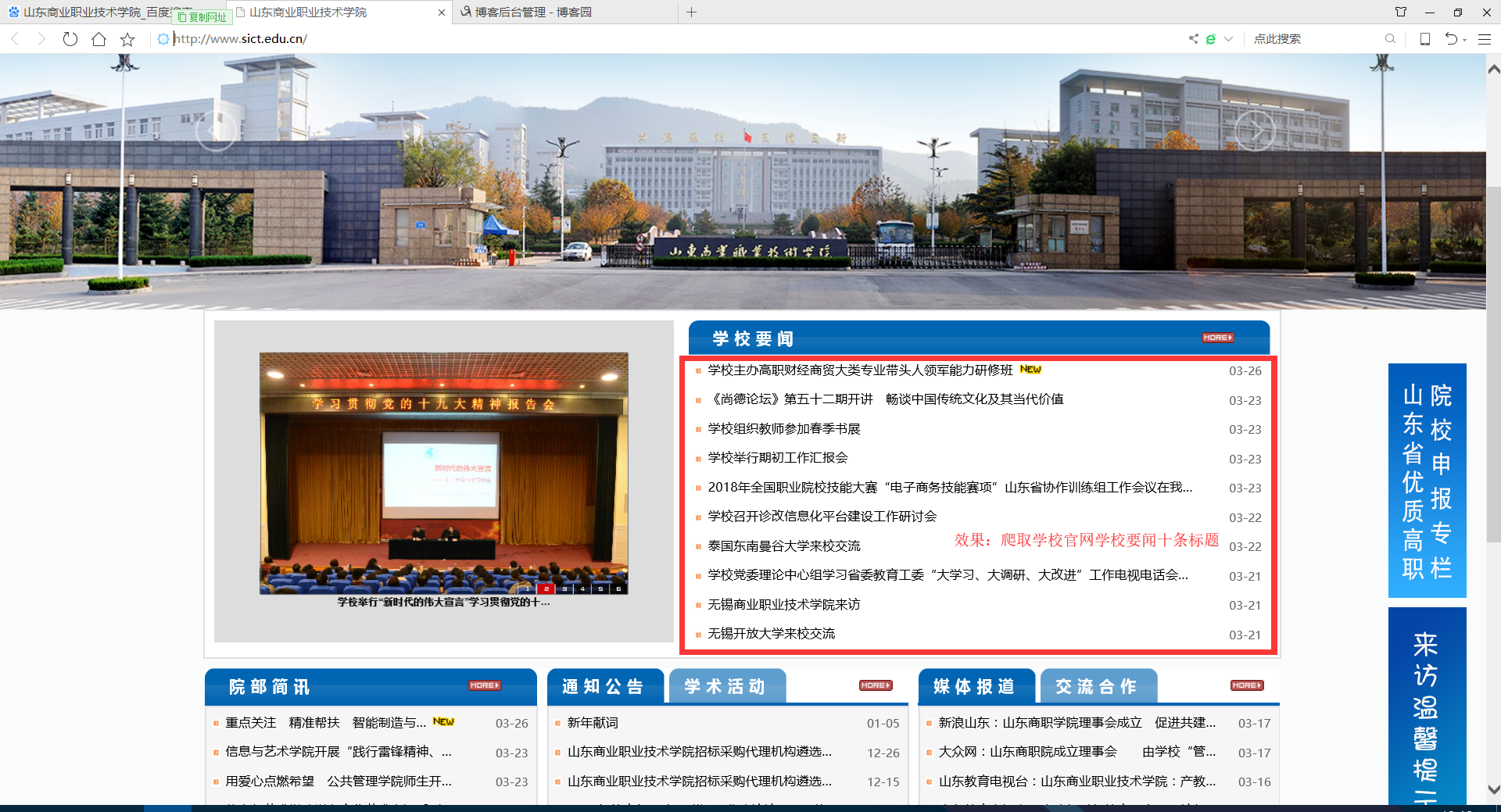
效果:

利用Python网络爬虫爬取学校官网十条标题的更多相关文章
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 如何利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例
前几天给大家分享了利用Python网络爬虫抓取微信朋友圈的动态(上)和利用Python网络爬虫爬取微信朋友圈动态——附代码(下),并且对抓取到的数据进行了Python词云和wordart可视化,感兴趣 ...
- 如何利用Python网络爬虫抓取微信朋友圈的动态(上)
今天小编给大家分享一下如何利用Python网络爬虫抓取微信朋友圈的动态信息,实际上如果单独的去爬取朋友圈的话,难度会非常大,因为微信没有提供向网易云音乐这样的API接口,所以很容易找不到门.不过不要慌 ...
- 利用Python网络爬虫抓取微信好友的所在省位和城市分布及其可视化
前几天给大家分享了如何利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例,感兴趣的小伙伴可以点击链接进行查看.今天小编给大家介绍如何利用Python网络爬虫抓取微信好友的省位和城市,并且将 ...
- 利用Python网络爬虫抓取微信好友的签名及其可视化展示
前几天给大家分享了如何利用Python词云和wordart可视化工具对朋友圈数据进行可视化,利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例,以及利用Python网络爬虫抓取微信好友的所 ...
- 如何用Python网络爬虫爬取网易云音乐歌曲
今天小编带大家一起来利用Python爬取网易云音乐,分分钟将网站上的音乐down到本地. 跟着小编运行过代码的筒子们将网易云歌词抓取下来已经不再话下了,在抓取歌词的时候在函数中传入了歌手ID和歌曲名两 ...
- Python网络爬虫-爬取微博热搜
微博热搜的爬取较为简单,我只是用了lxml和requests两个库 url=https://s.weibo.com/top/summary?Refer=top_hot&topnav=1& ...
- 04 Python网络爬虫 <<爬取get/post请求的页面数据>>之requests模块
一. urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib ...
- python网络爬虫&&爬取网易云音乐
#爬取网易云音乐 url="https://music.163.com/discover/toplist" #歌单连接地址 url2 = 'http://music.163.com ...
随机推荐
- CodeForces 832B Petya and Exam
B. Petya and Exam time limit per test 2 seconds memory limit per test 256 megabytes input standard i ...
- java 内存深度解析
java 中的包括以下几大种的内存区域:1.寄存器 2.stack(栈) 3.heap(堆) 4.数据段 5.常量池 那么相应的内存区域中又存放什么东西(主要介绍 stack heap)? 栈: ...
- matplotlib的下载和安装方法
官网:http://matplotlib.org/ Installation节 Visit the Matplotlib installation instructions. Installing节 ...
- Spark-自定义排序
一.自定义排序规则-封装类 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** ...
- resume 简历
1:uestc社会实践平台,sql,mapper.xml,,图片验证码,读写excel,excel和list,数据库的转化. 2:购物网站,全代码,平台搭建,服务发布,远程数据库连接,前端,搜索,支付 ...
- PHP开启CORS
CORS 定义 Cross-Origin Resource Sharing(CORS)跨来源资源共享是一份浏览器技术的规范,提供了 Web 服务从不同域传来沙盒脚本的方法,以避开浏览器的同源策略,是 ...
- (转)从零开始的Spring Session(一)
Session和Cookie这两个概念,在学习java web开发之初,大多数人就已经接触过了.最近在研究跨域单点登录的实现时,发现对于Session和Cookie的了解,并不是很深入,所以打算写两篇 ...
- find the safest road(弗洛伊德)
http://acm.hdu.edu.cn/showproblem.php?pid=1596 #include <iostream> #include <stdio.h> #i ...
- rsync 配置详解
安装 [root@localhost ~]# yum install -y rsync [root@localhost ~]# systemctl start rsyncd [root@localho ...
- storm并发机制,通信机制,任务提交
一.storm的并发 (1)Workers(JVMs):在一个物理节点上可以运行一个或多个独立的JVM进程.一个Topology可以包含一个或多个worker(并行的跑在不同的物理机上),所以work ...