Solr系列二:solr-部署详解(solr两种部署模式介绍、独立服务器模式详解、SolrCloud分布式集群模式详解)
一、solr两种部署模式介绍
Standalone Server 独立服务器模式:适用于数据规模不大的场景
SolrCloud 分布式集群模式:适用于数据规模大,高可靠、高可用、高并发的场景
二、独立服务器模式详解
1. 独立服务器模式架构
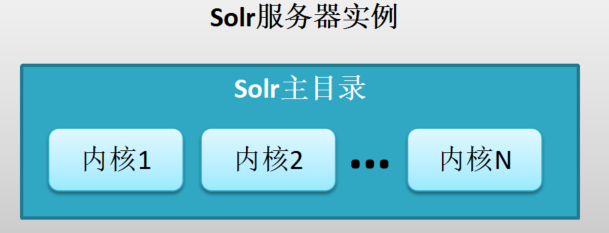
说明:
1、每个solr服务器实例(启动的一个solr服务器进程)都有一个solr主目录(系统变量名为:solr.solr.home)。启动服务器实例时须为实例指定主目录(默认为:server/solr目录)。
2、solr主目录中存放该服务器实例托管的内核。
3、一个solr服务器实例中可托管多个内核。
2.Solr主目录介绍
每个主目录下都有一个solr服务器实例配置文件solr.xml。 solrCloud模式下solr.xml可放置在zk上。
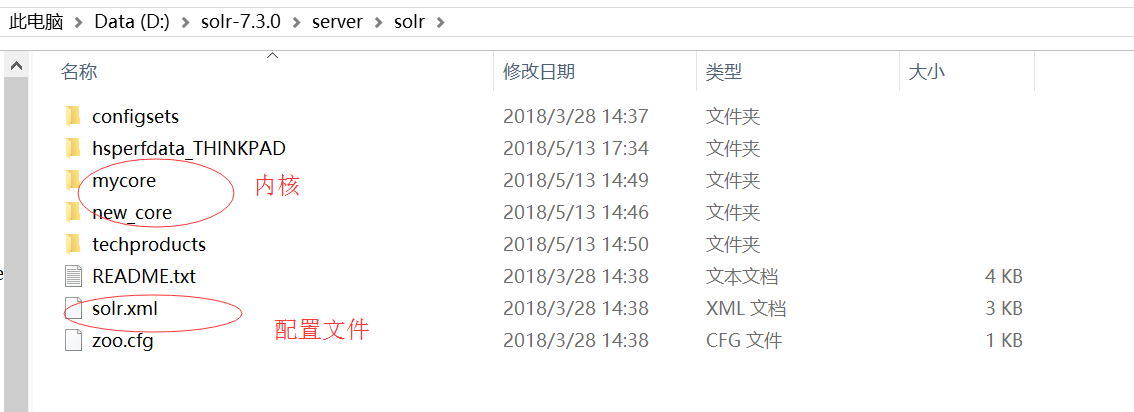
创建一个主目录(复制solr.xml),在它之上启动一个服务实例

启动命令:solr.cmd start -s D:/test/solrhome -p 8984
3. solr命令介绍
启动服务器实例命令:
bin/solr start [options]
bin/solr start -help
bin/solr restart [options]
bin/solr restart -help
注意:重启要用和启动时一样的options
启动时指定solr主目录的命令:solr.cmd start -s D:/test/solrhome -p 8984
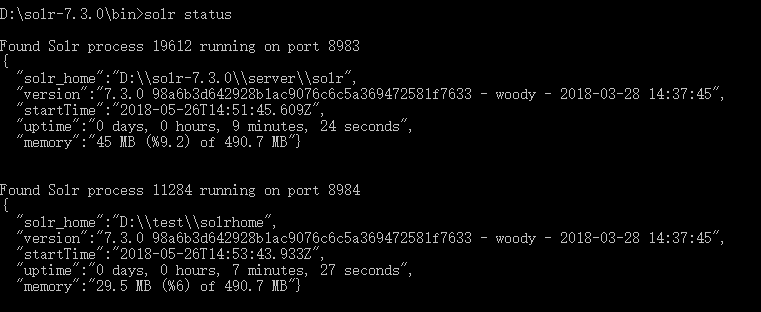
查看本机上运行的solr服务实例的状态:bin/solr status
停止solr服务实例:
bin/solr stop [options]
bin/solr stop -help
停止单个服务:
bin/solr stop –p port
停止所有solr实例:
bin/solr stop -all
4. core 内核详解
4.1 内核以及内核的用途
内核:是在Solr服务器中的具体唯一命名的、可管理和可配置的索引。一台solr服务器可以托管一个或多个内核。
内核的典型用途:区分不同模式的文档
4.2 core 内核管理:
创建内核
bin/solr create [options]
bin/solr create –help
bin/solr create_core [options]
bin/solr create_core -help
示例:
bin/solr create –c mycore –p 8983
-c <name> 内核的名字(必需).
-d <confdir> 内核配置目录。默认_default.
-p <port> 创建命令要发送到的solr服务实例的端口。如未指定则获取本机运行的solr服务实例列表的第一个。
卸载、加载、重载内核
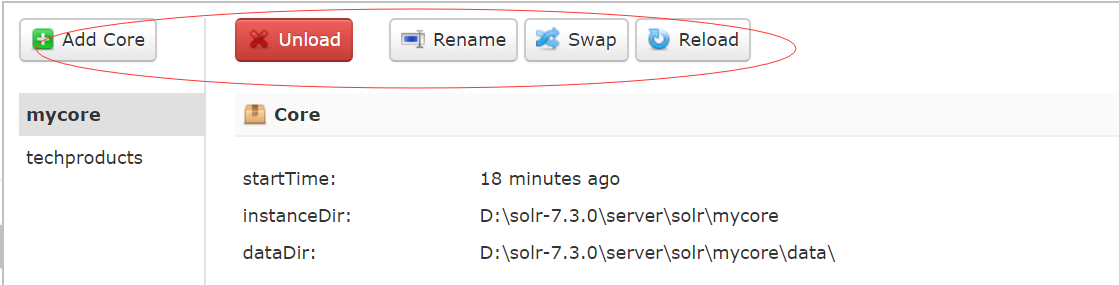
删除内核
bin/solr delete [options]
bin/solr delete -help
示例:
bin/solr delete –c corename –p port
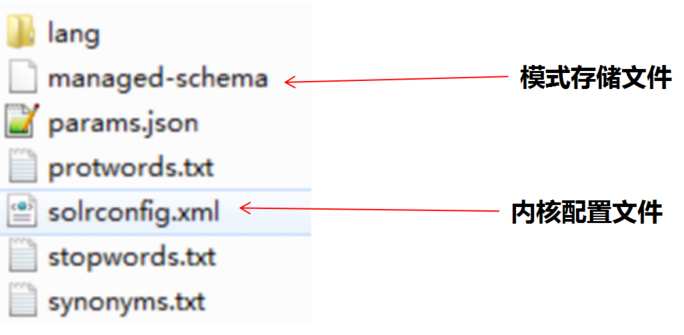
4.3 core 内核目录结构

内核属性文件core.properties的作用:配置内核的一些配置、作为内核的标识在启动solr的时候加载内核
注意:可以看到集群模式下是没有conf目录的,这是因为集群模式的conf是放在zk下给所有的内核使用的
内核配置文件目录
三、SolrCloud分布式集群模式详解
1. 为什么需要分布式集群模式?
源于需求:
1. 索引数据量大
如何存储? 如何保证搜索性能?
2. 如何保证高可靠、高可用?
3. 如何应对高并发、实时响应需求?
索引将被如何存储?
分割成多个片存储到集群的不同节点上,每个分片有备份,存储在集群的不同节点上。
独立服务器上索引叫内核,那集群上索引叫什么?
solrCloud中以 collection(集合)来称呼索引,内核存储的是集合分片(shard)的备份(replication)
2. SolrCloud分布式集群架构

3. 分布式集群模式启动
3.1 启动zookeeper
独立的zookeeper,则需先启动zookeeper
内嵌的zookeeper,则先启动包含zookeeper的solrNode
3.2 启动solrNode
内嵌的zookeeper的第一个solrNode节点服务启动:
bin/solr start –c –p port –s solrhome
其他solr节点的启动:
bin/solr start –c –p port –s solrhome –z zkhost:port
注意:启动的zookeeper实例的端口为 slor实例的端口+1000
4. 分布式集群模式部署练习
在我们的电脑上部署一个两个节点的集群
步骤1:创建两个solr主目录,如
D:\test\solrCloud\node1\solr
D:\test\solrCloud\node2\solr
node1/solr目录下需要zk的配置文件,到D:\solr-7.3.0\server\solr 下拷贝 zoo.cfg
然后到D:\solr-7.3.0\server\solr拷贝solr.xml到两个solr目录下
步骤2:启动第一个内嵌有zk的solrNode
solr.cmd start –c –s D:/test/solrCloud/node1/solr -m 100M
没有指定端口默认8983
-m 100M表示分配100M的内存
步骤3:启动第二个solrNode
solr.cmd start –c –s D:/test/solrCloud/node2/solr -m 100M -p 8984 –z localhost:9983
注意:启动的zookeeper实例的端口为 slor实例的端口+1000
在浏览器输入地址http://localhost:8983/solr查看现在的solr的web控制台有什么变化
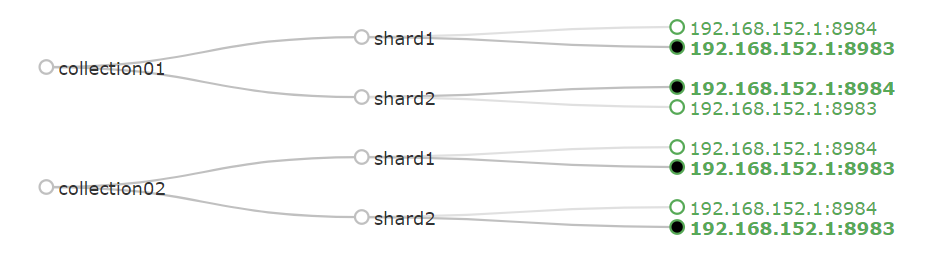
创建集合 collection
集合—分片数2---备份因子2
solr.cmd create –c collection01 –d _default –shards 2 –replicationFactor 2 –p 8983
说明:在8983这个solr实例上使用默认配置_default创建一个集合collection01,这个集合有2个分片,每个分片有2个备份
solr.cmd create –c collection02 –d sample_techproducts_configs –shards 2 –replicationFactor 2 –p 8983
说明:在8983这个solr实例上使用默认配置sample_techproducts_configs创建一个集合collection02,这个集合有2个分片,每个分片有2个备份

创建完成以后就可以在solr的管理页面看到创建的集合了
提交数据到集合collection02中:
Linux/Mac;
solr-7.3.0:$ bin/post -c collection02 example/exampledocs/*
Windows:
java -jar -Dc=collection02 -Dauto example\exampledocs\post.jar example\exampledocs\*
执行完以后就可以在集合的备份内核中看到提交的数据了

Solr系列二:solr-部署详解(solr两种部署模式介绍、独立服务器模式详解、SolrCloud分布式集群模式详解)的更多相关文章
- solr 集群(SolrCloud 分布式集群部署步骤)
SolrCloud 分布式集群部署步骤 安装软件包准备 apache-tomcat-7.0.54 jdk1.7 solr-4.8.1 zookeeper-3.4.5 注:以上软件都是基于 Linux ...
- SolrCloud分布式集群部署步骤
Solr及SolrCloud简介 Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口.用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成 ...
- 170825、SolrCloud 分布式集群部署步骤
安装软件包准备 apache-tomcat-7.0.54 jdk1.7 solr-4.8.1 zookeeper-3.4.5 注:以上软件都是基于 Linux 环境的 64位 软件,以上软件请到各自的 ...
- SolrCloud 分布式集群部署步骤
https://segmentfault.com/a/1190000000595712 SolrCloud 分布式集群部署步骤 solr solrcloud zookeeper apache-tomc ...
- hadoop(二)搭建伪分布式集群
前言 前面只是大概介绍了一下Hadoop,现在就开始搭建集群了.我们下尝试一下搭建一个最简单的集群.之后为什么要这样搭建会慢慢的分享,先要看一下效果吧! 一.Hadoop的三种运行模式(启动模式) 1 ...
- 深入剖析Redis系列: Redis集群模式搭建与原理详解
前言 在 Redis 3.0 之前,使用 哨兵(sentinel)机制来监控各个节点之间的状态.Redis Cluster 是 Redis 的 分布式解决方案,在 3.0 版本正式推出,有效地解决了 ...
- Apache + Tomcat集群配置详解 (1)
一.软件准备 Apache 2.2 : http://httpd.apache.org/download.cgi,下载msi安装程序,选择no ssl版本 Tomcat 6.0 : http://to ...
- Dubbo+zookeeper构建高可用分布式集群(二)-集群部署
在Dubbo+zookeeper构建高可用分布式集群(一)-单机部署中我们讲了如何单机部署.但没有将如何配置微服务.下面分别介绍单机与集群微服务如何配置注册中心. Zookeeper单机配置:方式一. ...
- redis详解(四)-- 高可用分布式集群
一,高可用 高可用(High Availability),是当一台服务器停止服务后,对于业务及用户毫无影响. 停止服务的原因可能由于网卡.路由器.机房.CPU负载过高.内存溢出.自然灾害等不可预期的原 ...
随机推荐
- 此编译单元不包含在frame元数据中指定的factoryClass,无法加载配置的运行时共享库
警告:此编译单元不包含在frame元数据中指定的factoryClass,无法加载配置的运行时共享库.要在没有运行时共享库的情况下进行编译,请将 -static-link-runtime-shared ...
- MyBean - 单实例插件改进和VCL插件的改进
BeanFactory中添加VclOwners:TComponent属性, 在getBean创建VCL插件的时候,Tcomponent.Create(VclOwners) 这样在清理DLL时就会释 ...
- DIOCP开源项目-DIOCP3的LoadRunner11测试报告
昨天有个多年的群友(B3.Locet)用LoadRunner11对DIOCP3做压力测试,说测试的时候出现了大量的10053,10054的报告.昨天晚上下载了个LoadRunner11, 今天捣鼓了下 ...
- Ubuntu首次安装后root权限解锁
在ubuntu系统下,为了安全起见,在安装过程中,系统屏蔽了用户设置root用户.导致很多用户在使用过程中不知道root密码到底是什么. 可以使用如下方法解决: 先解除root锁定,为root用户设置 ...
- java多线程20 : ReentrantLock中的方法 ,公平锁和非公平锁
公平锁与非公平锁 ReentrantLock有一个很大的特点,就是可以指定锁是公平锁还是非公平锁,公平锁表示线程获取锁的顺序是按照线程排队的顺序来分配的,而非公平锁就是一种获取锁的抢占机制,是随机获得 ...
- hdu1198(模拟搜索)
这个题目,比较恶心,思路很是简单,就是模拟的时候有些麻烦......水题 #include<iostream> #include<cstdio> #include<cst ...
- WPF 自定义事件
1.可传参数 namespace DrugInfo { public class ChooseDrugRoutedEventArgs : RoutedEventArgs { public Choose ...
- ILOG JRules 和 WebSphere Process Server 集成概述
ILOG JRules 和 WebSphere Process Server 集成概述 简介 业务流程管理(Business Process Management,BPM)和业务规则管理系统(Busi ...
- Extjs gridpanel 合并单元格
/* * *合并单元格的函数,合并表格内所有连续的具有相同值的单元格.调用方法示例: * *store.on("load",function(){gridSpan(grid,&qu ...
- docker探索-使用docker service管理swarm(十一 )
本文转自:https://www.cnblogs.com/atuotuo/p/6265541.html 1.创建一个 Docker service $ docker service create -- ...