第三百三十六节,web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础
第三百三十六节,web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础
在urllib中,我们一样可以使用xpath表达式进行信息提取,此时,你需要首先安装lxml模块,然后将网页数据通过lxml下的etree转化为treedata的形式
urllib库中使用xpath表达式
etree.HTML()将获取到的html字符串,转换成树形结构,也就是xpath表达式可以获取的格式
#!/usr/bin/env python
# -*- coding:utf8 -*-
import urllib.request
from lxml import etree #导入html树形结构转换模块 wye = urllib.request.urlopen('http://sh.qihoo.com/pc/home').read().decode("utf-8",'ignore')
zhuanh = etree.HTML(wye) #将获取到的html字符串,转换成树形结构,也就是xpath表达式可以获取的格式
print(zhuanh)
hqq = zhuanh.xpath('/html/head/title/text()') #通过xpath表达式获取标题 #注意,xpath表达式获取到数据,有时候是列表,有时候不是列表所以要做如下处理
if str(type(hqq)) == "<class 'list'>": #判断获取到的是否是列表
print(hqq)
else:
xh_hqq = [i for i in hqq] #如果不是列表,循环数据组合成列表
print(xh_hqq) #返回 :['【今日爆点】你的专属资讯平台']
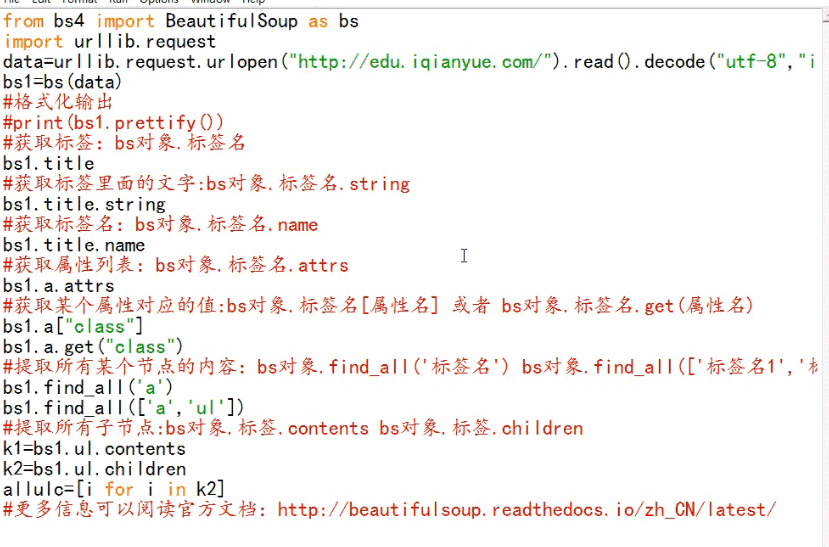
BeautifulSoup基础
BeautifulSoup是获取thml元素的模块
BeautifulSoup-3.2.1版本
第三百三十六节,web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础的更多相关文章
- 十五 web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础
在urllib中,我们一样可以使用xpath表达式进行信息提取,此时,你需要首先安装lxml模块,然后将网页数据通过lxml下的etree转化为treedata的形式 urllib库中使用xpath表 ...
- 第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术、设置用户代理
第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术.设置用户代理 如果爬虫没有异常处理,那么爬行中一旦出现错误,程序将崩溃停止工作,有异常处理即使出现错误也能继续执 ...
- 第三百二十六节,web爬虫,scrapy模块,解决重复ur——自动递归url
第三百二十六节,web爬虫,scrapy模块,解决重复url——自动递归url 一般抓取过的url不重复抓取,那么就需要记录url,判断当前URL如果在记录里说明已经抓取过了,如果不存在说明没抓取过 ...
- 第三百八十六节,Django+Xadmin打造上线标准的在线教育平台—HTML母版继承
第三百八十六节,Django+Xadmin打造上线标准的在线教育平台—HTML母版继承 母板-子板-母板继承 母板继承就是访问的页面继承一个母板,将访问页面的内容引入到母板里指定的地方,组合成一个新页 ...
- 第三百七十六节,Django+Xadmin打造上线标准的在线教育平台—创建用户操作app,在models.py文件生成5张表,用户咨询表、课程评论表、用户收藏表、用户消息表、用户学习表
第三百七十六节,Django+Xadmin打造上线标准的在线教育平台—创建用户操作app,在models.py文件生成5张表,用户咨询表.课程评论表.用户收藏表.用户消息表.用户学习表 创建名称为ap ...
- 第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点
第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点 1.分布式爬虫原理 2.分布式爬虫优点 3.分布式爬虫需要解决的问题
- 第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解
第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解 封装模块 #!/usr/bin/env python # -*- coding: utf- ...
- 第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理—用户代理和ip代理结合应用
第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理 使用IP代理 ProxyHandler()格式化IP,第一个参数,请求目标可能是http或者https,对应设置build_opener ...
- 第三百二十七节,web爬虫讲解2—urllib库爬虫—基础使用—超时设置—自动模拟http请求
第三百二十七节,web爬虫讲解2—urllib库爬虫 利用python系统自带的urllib库写简单爬虫 urlopen()获取一个URL的html源码read()读出html源码内容decode(& ...
随机推荐
- 菜鸟调错(五)——jetty运行时无法保存文件
背景交代: 上一篇博客写的是用jetty和Maven做开发.测试.在使用的过程中遇到一个小问题,就是在jetty启动以后,修改了jsp.xml等文件无法保存. 错误信息: 解决方案: 到Maven库( ...
- lua -- debug
framework.debug 调试支持 ~~ echo 功能同 print. 格式: echo(值, [值, 值, ...]) ~~ printf 按照特定格式输出. 格式: printf(格式字符 ...
- ex:Could not load file or assembly 'System.Web.Helpers, Version=2.0.0.0, Culture=neutral, . 系统找不到指定的文件。
今天写的是一个小程序,采用webfrom 形式,.netframework4.0 项目中调用了System.Web.Helpers下的Json方法. 在本地测试没问题,结果搭建到服务器上,死活运行不正 ...
- sql乘法函数实现方式
sql中有很多聚合函数,例如 COUNT.SUM.MIN 和 MAX. 但是唯独没有乘法函数,而很多朋友开发中缺需要用到这种函数,今天告诉大家一个不错的解决方案 logx+logy=logx*y 这是 ...
- 前端复制粘贴clipBoard.js的使用
<!DOCTYPE html> <html> <head> <title>ClipBoard.js使用:修改HTML</title> < ...
- 如何在Oracle中一次执行多条sql语句 (.net C#)
关键是不能换行,要加上begin ...sql... end; 每个SQL用:隔开,end后面必须加: 以下是拷贝于:http://www.cnblogs.com/teamleader/arc ...
- kill-9导致weblogic无法启动
转载自:http://blog.csdn.net/lykangjia/article/details/17486127?rsv_upd=1 今天单位系统遇到一个问题: Resolve Weblogic ...
- 使用 libvirt创建和管理KVM虚拟机
1. libvirt介绍 Libvirt是一个软件集合,便于使用者管理虚拟机和其他虚拟化功能,比如存储和网络接口管理等等.Libvirt概括起来包括一个API库.一个 daemon(libv ...
- Eigen教程(9)
整理下Eigen库的教程,参考:http://eigen.tuxfamily.org/dox/index.html Eigen并没有为matrix提供直接的Reshape和Slicing的API,但是 ...
- 基于jQuery+CSS3实现人物跳动特效
分享一款基于jQuery+CSS3实现人物跳动特效.这是一款类似gif图片效果的CSS3动画特效代码.效果图如下: 在线预览 源码下载 实现的代码. html代码: <div class=& ...