python webdriver 从无到有搭建混合驱动自动化测试框架的过程和总结
一步一步实现混合驱动自动化测试框架的搭建
混合驱动自动化测试框架,是一个非常高级的框架,非常好用,但也很难,不好掌握,需要多练习,就像搭建数据驱动框架一样,需要自己去一点一点的写,一边搭建一边做思路整理,包括遇到的一些问题和处理方法,遇到卡住的地方,就去看下老师是咋处理的,然后结合自己的思路继续写,感觉经过了漫长的时间,终于弄完了,还是把过程和总结列出来,做个笔记,另外也作为一份结果,给自己的付出做个即时反馈和激励~
实现功能:
登录126邮箱,添加联系人,然后发送邮件,带附件
框架结构:
Action:
封装的操作元素的函数,如login,添加联系人。。。
conf:
日志配置文件
定位元素配置文件
数据库配置文件
PageObject:
一个页面是一个类,类的方法可以获取页面上的相关元素
ProjectVar:
工程路径
工程相关的全局变量
TestData:(文件或excel)
测试用例
测试数据
TestScript:
运行测试框架的主程序:入口,主要读取测试数据的文件,记录测试结果。
Util-工具类
读取配置文件
excel工具类
时间类
查找元素的方法
读取定位元素配置文件的方法
日志方法
日志操作
截图
报告模板
思路和目标:
混合驱动模式是指包含数据驱动和关键字驱动,数据驱动就是实现数据和程序的分离,把数据放到配置文件中,关键字驱动模式中的关键字指的是某个动作,说白了就是一个函数的名称,测试程序通过识别出这个关键字来作为方法名,然后去调用这个方法执行相关的操作,关键字驱动的思路就是把方法的名称进行和程序的分离,把方法名放在配置文件中,然后从配置文件中读出函数的名称以及函数对应的参数,组合成函数调用表达式来进行函数的调用;
了解了数据驱动和关键字驱动的原理后,混合驱动就好理解了,就是数据驱动和关键字驱动的联合,既用到数据驱动模式也用到关键字驱动模式,进而可以确定混合驱动的核心就是实现关键字(函数名)、数据(包括函数需要的参数)和程序的分离,让测试人员在文件中维护好关键字和数据信息就可以实现框架程序的运行过程;
了解了这个核心之后,我的目的也就确定了,就是搭建一个测试框架,实现数据和程序的分离,同时也要实现函数名和程序的分离,通过在文件中读取函数名信息(关键字)和数据信息,执行关键字所映射的函数,进行网页元素的各种操作,来实现目标功能。
带着这个思路,我来试着一步一步地实现这个框架的搭建。
步骤1:直接在一个文件中罗列代码实现
新建一个工程hybrid_version2,在该工程下新建一个TestScipts包,在TestScripts包先新建TestScript.py文件
代码:
#encoding=utf-8
#encoding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
#print u"启动浏览器..."
print "start browser..."
#创建Firefox浏览器实例
driver=webdriver.Firefox(executable_path="c:\\geckodriver")
#最大化浏览器窗口
driver.maximize_window()
#print u"启动浏览器成功..."
print "start browser done..."
#print u"访问126邮箱登页。。。"
print "access 126 mail login page..."
driver.get("http://mail.126.com")
#暂停5秒钟,一遍邮箱登录页面加载完成
time.sleep(5)
assert u"126网易免费邮--你的专业电子邮局" in driver.title
print "access 126 mail login page done"
wait=WebDriverWait(driver,30)
wait.until(EC.frame_to_be_available_and_switch_to_it((By.ID,"x-URS-iframe")))
username=driver.find_element_by_xpath("//input[@name='email']")
username.send_keys("xiaxiaoxu1987")
pwd=driver.find_element_by_xpath("//input[@name='password']")
pwd.send_keys("gloryroad")
pwd.send_keys(Keys.RETURN)
print "user login..."
time.sleep(5)
time1=time.time()
driver.switch_to.default_content()
print "total time:",time.time()-time1
assert u"网易邮箱" in driver.title
print "login done"
address_book_link = wait.until(lambda x: x.find_element_by_xpath("//div[text()='通讯录']"))
address_book_link.click()
add_contact_button = wait.until(lambda x: x.find_element_by_xpath("//span[text()='新建联系人']"))
add_contact_button.click()
contact_name = wait.until(lambda x: x.find_element_by_xpath("//a[@title='编辑详细姓名']/preceding-sibling::div/input"))
contact_name.send_keys(u"徐凤钗")
contact_email = wait.until(lambda x: x.find_element_by_xpath("//*[@id='iaddress_MAIL_wrap']//input"))
contact_email.send_keys("593152023@qq.com")
contact_is_star = wait.until(lambda x: x.find_element_by_xpath("//span[text()='设为星标联系人']/preceding-sibling::span/b"))
contact_is_star.click()
contact_mobile = wait.until(lambda x: x.find_element_by_xpath("//*[@id='iaddress_TEL_wrap']//dd//input"))
contact_mobile.send_keys('18141134488')
contact_other_info = wait.until(lambda x: x.find_element_by_xpath("//textarea"))
contact_other_info.send_keys('my wife')
contact_save_button = wait.until(lambda x: x.find_element_by_xpath("//span[.='确 定']"))
contact_save_button.click()
print u"进入首页。。。"
time.sleep(3)
#mainPage=wait.until(EC.visibility_of_element_located((By.XPATH,"//div[.='首页']")))
mainPage=wait.until(EC.visibility_of_element_located((By.XPATH,"//div[.='首页']")))#也好用
#mainPage=wait.until(lambda x: x.find_element(by='xpath', value = "//div[.='首页']"))#好用
#mainPage=driver.find_element_by_xpath("//div[.='首页']")#好用
mainPage.click()
assert u"已发送" in driver.page_source
print u"进入首页成功"
print "write message..."
writeMessage=wait.until(lambda x:x.find_element_by_xpath("//span[text()='写 信']"))
writeMessage.click()
#收件人
receiver=wait.until(lambda x:x.find_element_by_xpath("//div[contains(@id,'_mail_emailinput')]/input"))
receiver.send_keys("367224698@qq.com")
#主题
theme=wait.until(lambda x:x.find_element_by_xpath("//div[@aria-label='邮件主题输入框,请输入邮件主题']/input"))
theme.send_keys(u"测试邮件")
#添加附件
attachment=wait.until(lambda x:x.find_element_by_xpath("//div[@title='点击添加附件']/input[@size='1' and @type='file']"))
attachment.send_keys("d:\\test.txt")
#切入正文iframe
driver.switch_to.frame(driver.find_element_by_xpath("//iframe[@tabindex=1]"))
editBox=driver.find_element_by_xpath('/html/body')
editBox.send_keys(u"发给夏晓旭的一封信")
driver.switch_to.default_content()
#print u"写信完成"
print "write message done"
driver.find_element_by_xpath("//header//span[text()='发送']").click()
#print u"开始发送邮件"
print "start to send email.."
time.sleep(3)
assert u"发送成功" in driver.page_source
#print u"邮件发送成功"
print "send emial done"
driver.quit()
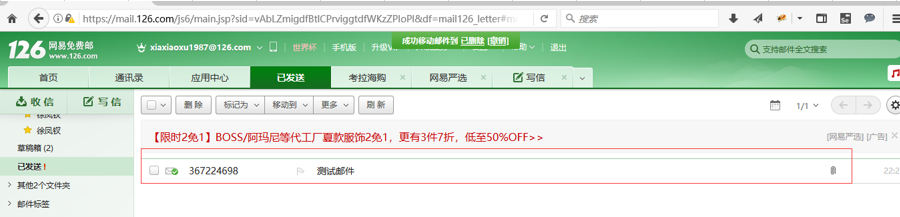
结果:添加联系人、发邮件带附件成功
C:\Python27\python.exe D:/test/hybrid_version2/TestScripts/TestScript.py
start browser...
start browser done...
access 126 mail login page...
access 126 mail login page done
user login...
total time: 0.00800013542175
login done
进入首页。。。
进入首页成功
write message...
write message done
start to send email..
send emial done
Process finished with exit code 0
至此,我在一个文件中实现了登录邮箱、添加联系人、写邮件的功能,现在来看下,下一步需要做什么呢?
如果不考虑关键字驱动的方式,直观感觉是把主要的功能进行封装,例如把登录,添加联系人,写邮件这三个大块封装成函数,然后分别调用这三个函数,但是现在要按照关键字驱动的思路去考虑每一步的优化和封装,关键字驱动的最终实现形式是通过从excel里读出关键字信息,来运行关键字所映射的函数,关键字的设置又依赖于测试用例的设计,测试用例又依赖于需求,测试用例的设计反映了需求中需要验证的测试点,那么关键字的设置就体现了测试用例的步骤,贴一下关键字excel文件来看一下具体形式:
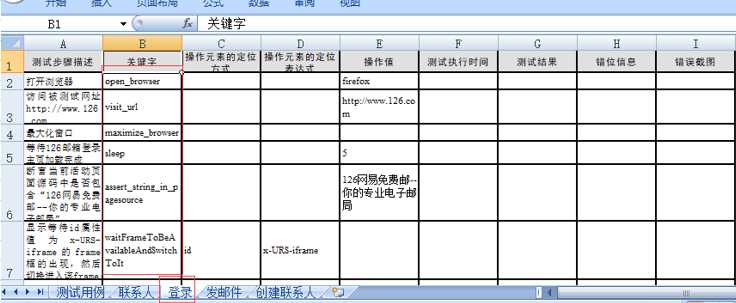
从上图可以看到,关键字的设置就是测试用例具体的步骤,每一个步骤所执行的动作用关键字来标识,这里的动作包括输入、断言、等待等环节,通过程序中和这些动作对应的函数来进行web元素的操作,最终完成测试任务。
通过以上的整理现在可以确定,文件中的关键字和数据的设置就是这个框架的需求,这个测试框架是为了这个文件中的关键字和数据服务的,那搭建这个框架的过程应该是一边进行文件布局、内容的设计,一边进行程序的调试、优化,最终完成一个实现目标功能的测试框架,接下来的封装和优化就需要按照关键字驱动的核心来进行了,说白了,封装是要掌握一个度,这个度就是关键字,关键字的颗粒度有多细,那么封装函数的颗粒度就有多细,这样才会使关键字和函数相互映射。
确定了这个思路后,下面把非关键字指定的工具类先封装一下,方便后续调用。
步骤2:封装查找对象部分 ObjectMap.py
在工程下新建util包,在该包下新建ObjectMap.py文件,封装查找元素的方法
ObjectMap.py:
#encoding=utf-8
from selenium.webdriver.support.ui import WebDriverWait
#获取单个元素对象
def getElement(driver,locatorType,locatorExpression):
wait = WebDriverWait(driver, 20)
try:
element=wait.until(lambda x:x.find_element(by=locatorType,value=locatorExpression))
return element
except Exception,e:
raise e
#获取多个相同页面元素对象,以list返回
def getElements(driver,locatorType,locatorExpression):
wait=WebDriverWait(driver,20)
try:
elements=wait.until(lambda x:x.find_elements(by=locatorType,value=locatorExpression))
return elements
except Exception,e:
raise e
if __name__=='__main__':
#测试代码
from selenium import webdriver
driver=webdriver.Firefox(executable_path='c:\\geckodriver')
driver.get("http://www.baidu.com")
searchBox=getElement(driver,'id','kw')
print searchBox.tag_name
aList=getElements(driver,'tag name','a')
print len(aList)
driver.quit()
结果:ok
C:\Python27\python.exe D:/test/hybrid_version2/util/ObjectMap.py
input
33
Process finished with exit code 0
修改主程序TestCript.py来调用查找元素方法
#encoding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
from util.ObjectMap import *
print "start browser..."
driver=webdriver.Firefox(executable_path="c:\\geckodriver")
driver.maximize_window()
print "start browser done..."
print "access 126 mail login page..."
driver.get("http://mail.126.com")
wait=WebDriverWait(driver,20)
time.sleep(5)
assert u"126网易免费邮--你的专业电子邮局" in driver.title
print "access 126 mail login page done"
wait.until(EC.frame_to_be_available_and_switch_to_it((By.ID,"x-URS-iframe")))
username=getElement(driver,'xpath',"//input[@name='email']")
username.send_keys("xiaxiaoxu1987")
pwd=getElement(driver,'xpath',"//input[@name='password']")
pwd.send_keys("gloryroad")
pwd.send_keys(Keys.RETURN)
print "user login..."
time.sleep(5)
time1=time.time()
driver.switch_to.default_content()
print "total time:",time.time()-time1
assert u"网易邮箱" in driver.title
print "login done"
address_book_link = getElement(driver,'xpath',"//div[text()='通讯录']")
address_book_link.click()
add_contact_button = getElement(driver,'xpath',"//span[text()='新建联系人']")
add_contact_button.click()
contact_name = getElement(driver,'xpath',"//a[@title='编辑详细姓名']/preceding-sibling::div/input")
contact_name.send_keys(u"徐凤钗")
contact_email = getElement(driver,'xpath',"//*[@id='iaddress_MAIL_wrap']//input")
contact_email.send_keys("593152023@qq.com")
contact_is_star = getElement(driver,'xpath',"//span[text()='设为星标联系人']/preceding-sibling::span/b")
contact_is_star.click()
contact_mobile = getElement(driver,'xpath',"//*[@id='iaddress_TEL_wrap']//dd//input")
contact_mobile.send_keys('18141134488')
contact_other_info = getElement(driver,'xpath',"//textarea")
contact_other_info.send_keys('my wife')
contact_save_button = getElement(driver,'xpath',"//span[.='确 定']")
contact_save_button.click()
print u"进入首页。。。"
time.sleep(3)
mainPage=getElement(driver,'xpath',"//div[.='首页']")
mainPage.click()
assert u"已发送" in driver.page_source
print u"进入首页成功"
print "write message..."
writeMessage=getElement(driver,'xpath',"//span[text()='写 信']")
writeMessage.click()
#收件人
receiver=getElement(driver,'xpath',"//div[contains(@id,'_mail_emailinput')]/input")
receiver.send_keys("367224698@qq.com")
#主题
theme=getElement(driver,'xpath',"//div[@aria-label='邮件主题输入框,请输入邮件主题']/input")
theme.send_keys(u"测试邮件")
#添加附件
attachment=getElement(driver,'xpath',"//div[@title='点击添加附件']/input[@size='1' and @type='file']")
attachment.send_keys("d:\\test.txt")
#切入正文iframe
driver.switch_to.frame(getElement(driver,'xpath',"//iframe[@tabindex=1]"))
#正文
editBox=getElement(driver,'xpath','/html/body')
editBox.send_keys(u"发给夏晓旭的一封信")
driver.switch_to.default_content()
#print u"写信完成"
print "write message done"
#点击发送按钮
getElement(driver,'xpath',"//header//span[text()='发送']").click()
print "start to send email.."
time.sleep(3)
assert u"发送成功" in driver.page_source
print "send emial done"
driver.quit()
结果:ok
C:\Python27\python.exe D:/test/hybrid_version2/TestScripts/TestScript.py
start browser...
start browser done...
access 126 mail login page...
access 126 mail login page done
user login...
total time: 0.00999999046326
login done
进入首页。。。
进入首页成功
write message...
write message done
start to send email..
send emial done
Process finished with exit code 0
下面来封装一下excel操作方法,用来后续读写excel使用
步骤3:封装excel方法,进行excel文件的读写
在util包下新建ParseExcel.py文件,把之前自己封装的execl操作拿过来,针对openpyxl 2.5.4版本
ParseExcel.py:
# encoding=utf-8
from openpyxl import load_workbook
from openpyxl.styles import Border, Side, Font
import time
class parseExcel(object):
def __init__(self, excelPath):
self.excelPath = excelPath
self.workbook = load_workbook(excelPath) # 加载excel
self.sheet = self.workbook.active # 获取第一个sheet
self.font = Font(color=None)
self.colorDict = {"red": 'FFFF3030', "green": 'FF008B00'}
# 设置当前要操作的sheet对象,使用index来获取相应的sheet
def get_sheet_by_index(self, sheet_index):
sheet_name = self.workbook.sheetnames[sheet_index]
self.sheet = self.get_sheet_by_name(sheet_name)
return self.sheet
# 获取当前默认sheet的名字
def get_default_sheet(self):
return self.sheet.title
# 设置当前要操作的sheet对象,使用sheet名称来获取相应的sheet
def get_sheet_by_name(self, sheet_name):
self.sheet = self.workbook[sheet_name]
return self.sheet
# 获取默认sheet中最大的行数
def get_max_row_no(self):
return self.sheet.max_row
# 获取默认 sheet 的最大列数
def get_max_col_no(self):
return self.sheet.max_column
# 获取默认sheet的最小(起始)行号
def get_min_row_no(self):
return self.sheet.min_row
# 获取默认sheet的最小(起始)列号
def get_min_col_no(self):
return self.sheet.min_column
# 获取默认 sheet 的所有行对象,
def get_all_rows(self):
return list(self.sheet.iter_rows())
# return list(self.rows)也可以
# 获取默认sheet中的所有列对象
def get_all_cols(self):
return list(self.sheet.iter_cols())
# return list(self.sheet.columns)也可以
# 从默认sheet中获取某一列,第一列从0开始
def get_single_col(self, col_no):
return self.get_all_cols()[col_no]
# 从默认sheet中获取某一行,第一行从0开始
def get_single_row(self, row_no):
return self.get_all_rows()[row_no]
# 从默认sheet中,通过行号和列号获取指定的单元格,注意行号和列号从1开始
def get_cell(self, row_no, col_no):
return self.sheet.cell(row=row_no, column=col_no)
# 从默认sheet中,通过行号和列号获取指定的单元格中的内容,注意行号和列号从1开始
def get_cell_content(self, row_no, col_no):
return self.sheet.cell(row=row_no, column=col_no).value
# 从默认sheet中,通过行号和列号向指定单元格中写入指定内容,注意行号和列号从1开始
# 调用此方法的时候,excel不要处于打开状态
def write_cell_content(self, row_no, col_no, content, font=None):
self.sheet.cell(row=row_no, column=col_no).value = content
self.workbook.save(self.excelPath)
return self.sheet.cell(row=row_no, column=col_no).value
# 从默认sheet中,通过行号和列号向指定单元格中写入当前日期,注意行号和列号从1开始
# 调用此方法的时候,excel不要处于打开状态
def write_cell_current_time(self, row_no, col_no):
time1 = time.strftime("%Y-%m-%d %H:%M:%S")
self.sheet.cell(row=row_no, column=col_no).value = str(time1)
self.workbook.save(self.excelPath)
return self.sheet.cell(row=row_no, column=col_no).value
def save_excel_file(self):
self.workbook.save(self.excelPath)
if __name__ == '__main__':
p = parseExcel(u'D:\\testdata.xlsx')
print u"获取默认行:", p.get_default_sheet()
print u"设置sheet索引为1", p.get_sheet_by_index(1)
print u"获取默认sheet:", p.get_default_sheet()
print u"设置sheet索引为0", p.get_sheet_by_index(0)
print u"获取默认sheet:", p.get_default_sheet()
print u"最大行数:", p.get_max_row_no()
print u"最大列数:", p.get_max_col_no()
print u"最小起始行数:", p.get_min_row_no()
print u"最小起始列数:", p.get_min_col_no()
print u"所有行对象:", p.get_all_rows()
print u"所有列对象:", p.get_all_cols()
print u"获取某一列(2):", p.get_single_col(2)
print u"获取某一行(4):", p.get_single_row(4)
print u"取得行号和列号(2,2)单元格:", p.get_cell(2, 2)
print u"取得行号和列号单元格的内容(2,2)", p.get_cell_content(2, 2)
print u"行号和列号写入内容(11,11):'xiaxiaoxu'", p.write_cell_content(11, 11, 'xiaxiaoxu')
print u"行号和列号写入当前日期(13,13):", p.write_cell_current_time(13, 13)
结果:ok

现在可以进行excel文件的读写操作了,来看下文件中的关键字(步骤函数)指向哪些操作,直接用老师给的excel关键字设计:

文件中需要的关键字去重后一共15个:
open_browser
visit_url
maximize_browser
sleep
assert_string_in_pagesource
waitFrameToBeAvailableAndSwitchToIt
clear
input_string
click
switch_to_default_content
assert_title
waitVisibilityOfElementLocated
paste_string
press_enter_key
close_browser
就是说在登录、添加联系人、发送邮件这个过程中需要最少15个函数来实现,下面就把主程序中实现的整个过程的代码按照这个结构进行封装,基本上每个方法用几行代码就搞定了。
从上边的关键字中可以看到有两个比较特别的方法:paste_string和press_enter_key,paste_string是用在打开附件添加窗进行输入附件路径的,press_enter_key是用来按enter键的,所以这两个是要操作剪贴板和键盘的,先把这两个给搞定。
步骤4:封装剪贴板和键盘操作
在util包下新建clipboard.py和keyboard.py文件
clipboard.py:
#encoding=utf-8
import win32clipboard as w
import win32con
import time
class Clipboard(object):
#模拟Windows设置剪贴板
#读取剪贴板
@staticmethod
def getText():
#打开剪贴板
w.OpenClipboard()
#获取剪贴板中的数据
content=w.GetClipboardData(win32con.CF_TEXT)
#关闭剪贴板
w.CloseClipboard()
#返回剪贴板数据
return content
#设置剪贴板内容
@staticmethod
def setText(aString):
#打开剪贴板
w.OpenClipboard()
#清空剪贴板
w.EmptyClipboard()
#将数据aString写入剪贴板
w.SetClipboardData(win32con.CF_UNICODETEXT,aString)
#关闭剪贴板
w.CloseClipboard()
if __name__=='__main__':
Clipboard.setText(u'hey buddy!')
time.sleep(3)
print Clipboard.getText()
结果:ok
C:\Python27\python.exe D:/test/hybrid_version2/util/keyboard.py
hey buddy!
Process finished with exit code 0
Keyboard.py:
#encoding=utf-8
import win32api
import win32con
class KeyboardKeys(object):
#模拟键盘按键类
VK_CODE={
'enter':0x0D,
'ctrl':0x11,
'v':0x56}
@staticmethod
def keyDown(keyName):
#按下按键
win32api.keybd_event(KeyboardKeys.VK_CODE[keyName],0,0,0)
@staticmethod
def keyUp(keyName):
#释放按键
win32api.keybd_event(KeyboardKeys.VK_CODE[keyName],0,win32con.KEYEVENTF_KEYUP,0)
@staticmethod
def oneKey(key):#对前两个方法的调用
#模拟单个按键
KeyboardKeys.keyDown(key)
KeyboardKeys.keyUp(key)
@staticmethod
def twoKeys(key1,key2):#对前面函数的调用
#模拟两个组合键
KeyboardKeys.keyDown(key1)
KeyboardKeys.keyDown(key2)
KeyboardKeys.keyUp(key2)
KeyboardKeys.keyUp(key1)
if __name__=='__main__':
from util.clipboard import *
from selenium import webdriver
import time
Clipboard.setText(u"hello world")
time.sleep(3)
# driver=webdriver.Firefox(executable_path=r'c:\\geckodriver')
# driver.get('http://www.baidu.com')
# driver.find_element_by_xpath("//input[@id='kw']").click()
# KeyboardKeys.twoKeys("ctrl","v")
KeyboardKeys.twoKeys('ctrl','v')
结果:ok
C:\Python27\python.exe D:/test/hybrid_version2/util/keyboard.py
hello world
Process finished with exit code 0
准备工作差不多了,现在开始封装关键字映射的方法:
open_browser
visit_url
maximize_browser
sleep
assert_string_in_pagesource
waitFrameToBeAvailableAndSwitchToIt
clear
input_string
click
switch_to_default_content
assert_title
waitVisibilityOfElementLocated
paste_string
press_enter_key
close_browser
步骤5:封装关键字对应的方法。
在工程下新建action包,在该包下新建pageAction.py文件用来封装关键字对应的方法
在封装open_browser()函数时发现浏览器驱动文件的路径需要在配置文件中配置一下

在工程下新建config包,在该包下新建config.py存放工程所在目录和数据文件目录
config.py:
#encoding=utf-8
import os
firefoxDriverPath='c:\\geckodriver'
chromeDriverPath='c:\\chromedriver'
ieDriverPath='d:\\IEDriverServer'
#当前工程所在目录的绝对路径
projectPath=os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
#测试数据文件的绝对路径
dataFilePath=projectPath + u"\\testData\\126邮箱创建联系人并发邮件.xlsx"
if __name__ == '__main__':
print projectPath
print dataFilePath
结果:ok
C:\Python27\python.exe D:/test/hybrid_version2/config/config.py
D:\test\hybrid_version2
D:\test\hybrid_version2\testData\126邮箱创建联系人并发邮件.xlsx
Process finished with exit code 0
pageAction.py:
#encoding=utf-8
from util.ObjectMap import *
from util.clipboard import *
from util.keyboard import *
from selenium.webdriver.chrome.options import Options
import time
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from config.config import *
#定义全局driver变量
driver=None
wait=None
#之所以括号中后边写*arg,是因为拼接数据的时候,可能会拼成有参数的,这时候做个容错
#传了参数也不会报错。
def open_browser(browserName,*arg):
global driver,wait
try:
if browserName.lower() == 'firefox':
driver=webdriver.Firefox(executable_path=firefoxDriverPath)#稍后路径放到config文件中
elif browserName.lower() == 'chrome':
#创建chrome浏览器的一个options实例对象
chrome_options=Options()
#添加屏蔽ignore-certificate-errors提示信息的设置参数项
chrome_options.add_experimental_option("excludeSwitches",["ignore-certificate-errors"])
driver=webdriver.Chrome(executable_path=chromeDriverPath, chrome_options=chrome_options)# 稍后把路径放到config文件中
else:#剩余的就是ie了
driver = webdriver.Ie(executable_path=ieDriverPath) # 稍后把路径放到config文件中
#driver对象确定之后,就可以确定wait了
wait=WebDriverWait(driver,20)
except Exception,e:
raise e
def visit_url(url,*arg):
#访问某个网址
global driver
try:
driver.get(url)
except Exception,e:
raise e
def close_browser(*arg):
#关闭浏览器
global driver
try:
driver.quit()
except Exception,e:
raise e
def sleep(seconds,*arg):
try:
time.sleep(int(seconds))
except Exception,e:
raise e
def clear(locatorType,locatorExpression,*arg):
#找到输入框元素对象,然后清楚输入框内容
global driver
try:
getElement(driver,locatorType,locatorExpression).clear()
except Exception,e:
raise e
def input_string(locatorType,locatorExpression,content):
global driver
try:
getElement(driver,locatorType,locatorExpression).send_keys(content)
except Exception,e:
raise e
def click(locatorType,locatorExpression,*arg):
global driver
try:
getElement(driver,locatorType,locatorExpression).click()
except Exception,e:
raise e
def assert_string_in_pagesource(assertString,*arg):
#断言页面源码中是否包含要断言的字符串
global driver
try:
assert assertString in driver.page_source,u"%s not found in page source!"%assertString
except AssertionError,e:
#raise AssertionError(e)
raise e
except Exception,e:
raise e
def assert_title(titleStr,*arg):
#断言页面标题是否是给定的字符串
global driver
try:
assert titleStr in driver.title,u"%s not found in title!" %titleStr
except AssertionError,e:
raise e
except Exception,e:
raise e
def getTitle(*arg):
#获取页面标题
global driver
try:
return driver.title
except Exception,e:
raise e
def getPageSource(*arg):
#获取页面源码,这个没有用到
global driver
try:
return driver.page_source
except Exception,e:
raise e
def switch_to_frame(locatorType,frameLocatorExpression,*arg):
#查找到frame,并切进frame
global driver
try:
driver.switch_to.frame(getElement(driver,locatorType,frameLocatorExpression))
except Exception,e:
print "switch to frame error"
raise e
def switch_to_default_content(*arg):
#切换页面从frame到默认窗口中
global driver
try:
driver.switch_to.default_content()
except Exception,e:
raise e
def paste_string(pasteContent,*arg):
#模拟ctrl + v操作
try:
Clipboard.setText(pasteContent)#Clipboard类的静态函数
#等待2秒,防止剪贴板没设置好内容就粘贴,会失败
time.sleep(2)
KeyboardKeys.twoKeys('ctrl','v')#Keyboardkeys类的静态函数
except Exception,e:
raise e
def press_tab_key(*arg):#没用到
#模拟tab按键
try:
KeyboardKeys.oneKey('tab')
except Exception,e:
raise e
def press_enter_key(*arg):
#模拟enter按键
try:
KeyboardKeys.oneKey('enter')
except Exception,e:
raise e
def maximize_browser():
#窗口最大化
global driver
try:
driver.maximize_window()
except Exception,e:
raise e
def waitFrameToBeAvailableAndSwitchToIt(locatorType,locatorExpression,*arg):
#检查frmae是否存在,存在则切进frame中
global wait
try:
wait.until(EC.frame_to_be_available_and_switch_to_it(locatorType,locatorExpression))
except Exception,e:
raise e
def waitVisibilityOfElementLocated(locatorType,locatorExpression,*arg):
#等待页面元素出现在DOM中并且可见,存在则返回该元素
global wait
try:
element=wait.until(EC.visibility_of_element_located(locatorType,locatorExpression))
return element
except Exception,e:
raise e
if __name__ == '__main__':
from selenium import webdriver
open_browser('firefox')
visit_url('http:\\126.com')
switch_to_frame("id", "x-URS-iframe")
input_string('xpath', "//input[@name='email']","xiaxiaoxu1987")
input_string('xpath', "//input[@name='password']","gloryroad")
click("id","dologin")
结果:ok
C:\Python27\python.exe D:/test/hybrid_version2/action/pageAction.py
Process finished with exit code 0
这一步中,把关键字对应的函数都进行了封装,下面尝试在主程序中把代码都用封装起来的函数来实现。
TestScript.py:
#encoding=utf-8
#encoding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
from util.ObjectMap import *
from action.pageAction import *
print "start browser..."
open_browser('firefox')
maximize_browser()
print "start browser done..."
print "access 126 mail login page..."
visit_url("http://mail.126.com")
sleep(5)
assert_title(u"126网易免费邮--你的专业电子邮局")
print "access 126 mail login page done"
switch_to_frame('id',"x-URS-iframe")
#wait.until(EC.frame_to_be_available_and_switch_to_it((By.ID,"x-URS-iframe")))
input_string('xpath',"//input[@name='email']",'xiaxiaoxu1987')
input_string('xpath',"//input[@name='password']",'gloryroad')
press_enter_key()
#pwd.send_keys(Keys.RETURN)
print "user login..."
sleep(5)
switch_to_default_content()
assert_title(u"网易邮箱")
print "login done"
click('xpath',"//div[text()='通讯录']")
click('xpath',"//span[text()='新建联系人']")
input_string('xpath',"//a[@title='编辑详细姓名']/preceding-sibling::div/input",u"徐凤钗")
input_string('xpath',"//*[@id='iaddress_MAIL_wrap']//input","593152023@qq.com")
click('xpath',"//span[text()='设为星标联系人']/preceding-sibling::span/b")
input_string('xpath',"//*[@id='iaddress_TEL_wrap']//dd//input",'18141134488')
input_string('xpath',"//textarea",'my wife')
click('xpath',"//span[.='确 定']")
print u"进入首页。。。"
sleep(3)
click('xpath',"//div[.='首页']")
assert_string_in_pagesource(u"已发送")
print u"进入首页成功"
print "write message..."
click('xpath',"//span[text()='写 信']")
input_string('xpath',"//div[contains(@id,'_mail_emailinput')]/input","367224698@qq.com")
input_string('xpath',"//div[@aria-label='邮件主题输入框,请输入邮件主题']/input",u"测试邮件")
input_string('xpath',"//div[@title='点击添加附件']/input[@size='1' and @type='file']","d:\\test.txt")
switch_to_frame('xpath',"//iframe[@tabindex=1]")
input_string('xpath','/html/body',u"发给夏晓旭的一封信")
switch_to_default_content()
#print u"写信完成"
print "write message done"
#点击发送按钮
click('xpath',"//header//span[text()='发送']")
print "start to send email.."
time.sleep(3)
assert_string_in_pagesource(u"发送成功")
print "send emial done"
close_browser()
结果:非常好用!
C:\Python27\python.exe D:/test/hybrid_version2/TestScripts/TestScript.py
start browser...
start browser done...
access 126 mail login page...
access 126 mail login page done
user login...
login done
进入首页。。。
进入首页成功
write message...
write message done
start to send email..
send emial done
Process finished with exit code 0
不得不说,封装了函数之后再调用,真的很方便,代码看起来非常整洁、清晰,运行了这个代码,心情都好了。
在上边主程序中调用的一个个的函数其实就是关键字的调用,这个框架最后实现的原理就是从文件中取出关键字和关键字需要的参数,组合成一个表达式,然后运行这个表达式,最后实现的其实就是上面主程序的代码结构,只不过我们把函数的调用通过不同的形式来运行而已
我刚开始搭建这个框架的时候,有一个问题一直很模糊,就是为什么要这样做,为什么要把关键字、数据放在文件中,然后写程序去读这个文件,为啥要通过文件的配置来运行程序,其实站在实际项目测试的角度来看就清楚了,这个框架就好像一辆车,我们可以驾驶这辆车去各种地方,但是我们可能不了解这个车内部的构造是什么,它是怎么工作的,但是只要我们会挂挡、踩油门、打转向等简单的操作,就可以让车按我们的想法去行驶,这个框架也是一样,在代码中我们把相对复杂的逻辑实现了,给测试人员留出一个入口(存关键字和数据的文件),测试人员通过对有限的关键字进行组合、搭配,就可以运行这个框架,实现对目标系统的测试,在文件中对关键字和数据的组合来实现对测试系统的运行和断言以及输出测试结果,就是测试框架带来的好处,它可以重复使用,随意更换输入的数据,更换浏览器,调整关键字顺序等等,好处显而易见。
下面就尝试一下从文件中来读取关键字和数据信息实现用例的执行。
步骤6:修改主程序,在主程序中读取文件中的关键字和数据信息实现登录的功能
再看一下文件的结构:
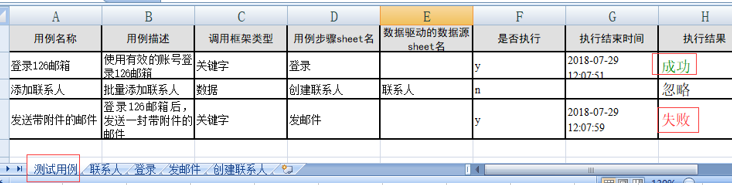
在测试用例sheet中划分了三个用例,分别是登录,创建联系人,发邮件,先看第一条登录的用例,后边是否执行列的y用来标识需要执行,其中”用例步骤sheet名”列的内容指向用例具体步骤的sheet页名称,第一个用例的步骤sheet是登录,在登录sheet页中列出了步骤所对应的关键字(动作),关键字步骤所需要的参数在后边的列,例如定位方式、定位表达式、操作值(关键字函数需要的参数),再后边是测试时间,测试结果等信息。

先来试下从“测试用例”sheet中读取第一条需要执行的用例,实现登录的操作
在TestScript包下新建一个login.py来实现登录
login.py:
#encoding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
from util.ObjectMap import *
from action.pageAction import *
from util.ParseExcel import *
pe=parseExcel(dataFilePath)
pe.get_sheet_by_name(u"测试用例")
print u"当前sheet:",pe.get_default_sheet()
caseRows=pe.get_all_rows()
for idx,row in enumerate(caseRows[1:]):
frameWorkType=row[2].value
caseStepSheet=row[3].value
dataDrivenSourceSheet=row[4].value
ifExecute=row[5].value
if ifExecute.lower() == 'y':
# print u"用例名称:", row[0].value
# print u"用例描述:", row[1].value
# print u"调用框架类型:", frameWorkType
# print u"用例步骤sheet名:", caseStepSheet
# print u"数据驱动的数据源sheet名:", dataDrivenSourceSheet
# print u"是否执行:", ifExecute
if frameWorkType ==u"关键字":
pe.get_sheet_by_name(caseStepSheet)
stepRows=pe.get_all_rows()
for idx1,row1 in enumerate(stepRows[1:]):
caseStepDescripion=row1[0].value
keyWord=row1[1].value
locatorType=row1[2].value
locatorExpression=row1[3].value
operateValue=int(row1[4].value) if isinstance(row1[4].value,long) else row1[4].value
# print u"测试步骤描述:",caseStepDescripion
# print u"关键字:",keyWord
# print u"操作元素的定位方式:",locatorType
# print u"操作元素的定位表达式:",locatorExpression
# print u"操作值:",operateValue
if (locatorType and locatorExpression):
command="%s('%s','%s',u'%s')"%(keyWord,locatorType,locatorExpression.replace("'","\""),operateValue) if operateValue else "%s('%s','%s')"%(keyWord,locatorType,locatorExpression.replace("'","\""))
elif operateValue :
command ="%s(u'%s')"%(keyWord,operateValue)
else:
command="%s()"%keyWord
print caseStepDescripion
print "command:",command
try:
eval(command)
except Exception,e:
raise e
elif frameWorkType == u"数据":
pass
else:
pass #不是y
结果:ok
C:\Python27\python.exe D:/test/hybrid_version2/TestScripts/login.py
当前sheet: 测试用例
打开浏览器
command: open_browser(u'firefox')
访问被测试网址http://www.126.com
command: visit_url(u'http://www.126.com')
最大化窗口
command: maximize_browser()
等待126邮箱登录主页加载完成
command: sleep(u'5')
断言当前活动页面源码中是否包含“126网易免费邮--你的专业电子邮局”
command: assert_string_in_pagesource(u'126网易免费邮--你的专业电子邮局')
显示等待id属性值为x-URS-iframe的frame框的出现,然后切换进入该frame框中
command: switch_to_frame('id','x-URS-iframe')
清除用户名输入框中的缓存用户性
command: clear('xpath','//input[@name="email"]')
输入登录用户名
command: input_string('xpath','//input[@name="email"]',u'xiaxiaoxu1987')
输入登录密码
command: input_string('xpath','//input[@name="password"]',u'gloryroad')
点击登录按钮
command: click('id','dologin')
等待
command: sleep(u'5')
切回默认会话窗体
command: switch_to_default_content()
断言登录成功后的页面标题是否包含“网易邮箱6.0版”关键内容
command: assert_title(u'网易邮箱6.0版')
Process finished with exit code 0
至此,实现了测试用例sheet中的第一条用例的执行,过程包括判断用例是否要执行,识别测试用例需要的步骤sheet是谁,然后进入这个步骤sheet,读取每一行的关键字信息,进行函数的执行,最后这条测试用例就运行完了,下面看下还需要做什么,有什么可以优化,
从用例文件的内容来看,在执行用例之后,需要填写执行结束时间和执行结果:

步骤sheet中,需要记录执行时间,测试结果,错误信息,错误截图,下一步来做这个。

步骤7:记录执行时间、结果、错误信息,错误截图
先来看测试结果,在测试用例sheet中的测试结果是根据它对应的步骤sheet中是否所有的关键字步骤都运行成功来确定的,如果都成功了,那这个用例就成功了,否则就是失败,
在步骤sheet中,每一个关键字函数运行都会有一个结果和时间等信息,先把这两块搞定。
修改程序login.py:
#encoding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
from util.ObjectMap import *
from action.pageAction import *
from util.ParseExcel import *
import traceback
pe=parseExcel(dataFilePath)
pe.get_sheet_by_name(u"测试用例")
print u"当前sheet:",pe.get_default_sheet()
caseRows=pe.get_all_rows()
for idx,row in enumerate(caseRows[1:]):
frameWorkType=row[2].value
caseStepSheet=row[3].value
dataDrivenSourceSheet=row[4].value
ifExecute=row[5].value
if ifExecute.lower() == 'y':
# print u"用例名称:", row[0].value
# print u"用例描述:", row[1].value
# print u"调用框架类型:", frameWorkType
# print u"用例步骤sheet名:", caseStepSheet
# print u"数据驱动的数据源sheet名:", dataDrivenSourceSheet
# print u"是否执行:", ifExecute
if frameWorkType ==u"关键字":
pe.get_sheet_by_name(caseStepSheet)
stepRows=pe.get_all_rows()
totalStepNum=len(stepRows)-1
print "totalStepNum:",totalStepNum
successStepNum=0
for idx1,row1 in enumerate(stepRows[1:]):
caseStepDescripion=row1[0].value
keyWord=row1[1].value
locatorType=row1[2].value
locatorExpression=row1[3].value
operateValue=int(row1[4].value) if isinstance(row1[4].value,long) else row1[4].value
# print u"测试步骤描述:",caseStepDescripion
# print u"关键字:",keyWord
# print u"操作元素的定位方式:",locatorType
# print u"操作元素的定位表达式:",locatorExpression
# print u"操作值:",operateValue
if (locatorType and locatorExpression):
command="%s('%s','%s',u'%s')"%(keyWord,locatorType,locatorExpression.replace("'","\""),operateValue) if operateValue else "%s('%s','%s')"%(keyWord,locatorType,locatorExpression.replace("'","\""))
elif operateValue :
command ="%s(u'%s')"%(keyWord,operateValue)
else:
command="%s()"%keyWord
print caseStepDescripion
print "command:",command
try:
eval(command)
except Exception,e:
pe.write_cell_content(idx1 + 2, 7, u"fail")
pe.write_cell_current_time(idx1 + 2, 6)
pe.write_cell_content(idx1+2,8,traceback.format_exc())
#写入错误截图需要封装函数,返回图片地址
else:#没有报错
successStepNum+=1
print "successStepNum:",successStepNum
pe.write_cell_content(idx1+2,7,u"pass")
pe.write_cell_current_time(idx1+2,6)
if totalStepNum == successStepNum:#此条用例执行成功
pe.get_sheet_by_name(u"测试用例") # 把默认sheet获取到测试用例sheet上
pe.write_cell_content(idx + 2, 8, u"成功") # 在结果列中写入忽略
pe.write_cell_current_time(idx+2,7)#写入执行时间
else:
pe.get_sheet_by_name(u"测试用例") # 把默认sheet获取到测试用例sheet上
pe.write_cell_content(idx + 2, 8, u"失败") # 在结果列中写入忽略
pe.write_cell_current_time(idx + 2, 7) # 写入执行时间
elif frameWorkType == u"数据":
pass
else:#不是y
pe.get_sheet_by_name(u"测试用例")#把默认sheet获取到测试用例sheet上
pe.write_cell_content(idx+2,8,u"忽略")#在结果列中写入忽略
pe.write_cell_content(idx+2,7,"")#清空时间列的值
结果:实现了写结果,写时间,写错误信息
C:\Python27\python.exe D:/test/hybrid_version2/TestScripts/login.py
当前sheet: 测试用例
totalStepNum: 13
打开浏览器
command: open_browser(u'firefox')
successStepNum: 1
访问被测试网址http://www.126.com
command: visit_url(u'http://www.126.com')
successStepNum: 2
最大化窗口
command: maximize_browser()
successStepNum: 3
等待126邮箱登录主页加载完成
command: sleep(u'5')
successStepNum: 4
断言当前活动页面源码中是否包含“126网易免费邮--你的专业电子邮局”
command: assert_string_in_pagesource(u'126网易免费邮--你的专业电子邮局')
successStepNum: 5
显示等待id属性值为x-URS-iframe的frame框的出现,然后切换进入该frame框中
command: switch_to_frame('id','x-URS-iframe1')
switch to frame error
清除用户名输入框中的缓存用户性
command: clear('xpath','//input[@name="email"]1')
输入登录用户名
command: input_string('xpath','//input[@name="email"]',u'xiaxiaoxu1987')
输入登录密码
command: input_string('xpath','//input[@name="password"]',u'gloryroad')
点击登录按钮
command: click('id','dologin')
等待
command: sleep(u'5')
successStepNum: 6
切回默认会话窗体
command: switch_to_default_content()
successStepNum: 7
断言登录成功后的页面标题是否包含“网易邮箱6.0版”关键内容
command: assert_title(u'网易邮箱6.0版')
Process finished with exit code 0
写入错误截图地址这里,需要单独封装一个函数,然后在主程序中调用


在action包下pageAction.py中增加captureScreen方法:
在config.py中增加存放错误截图的路径:
# 异常图片存放目录
screenPicturesDir = projectPath + "\\errorScreenShots\\"
pageAction,py:#增加captureScreen方法
def captureScreen(*arg):
global driver
currentDate=time.strftime("%Y-%m-%d")
currentTime=datetime.now().strftime('%H-%M-%S-%f')#时分秒毫秒
dirName=os.path.join(screenPicturesDir,currentDate)
if not os.path.exists(dirName):
os.makedirs(dirName)
print "dirName:",dirName
screenShotNameAndPath="%s\\%s.png"%(dirName,currentTime)
print "screenPicturesDir:",screenPicturesDir
try:
driver.get_screenshot_as_file(screenShotNameAndPath.replace('\\',r'\\'))
except Exception,e:
raise e
else:
return screenShotNameAndPath
测试代码:
if __name__ == '__main__':
from selenium import webdriver
open_browser('firefox')
visit_url('http:\\126.com')
# switch_to_frame("id", "x-URS-iframe")
# input_string('xpath', "//input[@name='email']","xiaxiaoxu1987")
# input_string('xpath', "//input[@name='password']","gloryroad")
# click("id","dologin")
Print captureScreen()
结果:ok
C:\Python27\python.exe D:/test/hybrid_version2/action/pageAction.py
dirName: D:\test\hybrid_version2\errorScreenShots\2018-07-24
screenPicturesDir: D:\test\hybrid_version2\errorScreenShots\
D:\test\hybrid_version2\errorScreenShots\2018-07-24\22-36-14-430000.png
Process finished with exit code 0
修改login.py,加入截图的处理
#encoding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
from util.ObjectMap import *
from action.pageAction import *
from util.ParseExcel import *
import traceback
pe=parseExcel(dataFilePath)
pe.get_sheet_by_name(u"测试用例")
print u"当前sheet:",pe.get_default_sheet()
caseRows=pe.get_all_rows()
for idx,row in enumerate(caseRows[1:]):
frameWorkType=row[2].value
caseStepSheet=row[3].value
dataDrivenSourceSheet=row[4].value
ifExecute=row[5].value
if ifExecute.lower() == 'y':
# print u"用例名称:", row[0].value
# print u"用例描述:", row[1].value
# print u"调用框架类型:", frameWorkType
# print u"用例步骤sheet名:", caseStepSheet
# print u"数据驱动的数据源sheet名:", dataDrivenSourceSheet
# print u"是否执行:", ifExecute
if frameWorkType ==u"关键字":
pe.get_sheet_by_name(caseStepSheet)
stepRows=pe.get_all_rows()
totalStepNum=len(stepRows)-1
print "totalStepNum:",totalStepNum
successStepNum=0
for idx1,row1 in enumerate(stepRows[1:]):
caseStepDescripion=row1[0].value
keyWord=row1[1].value
locatorType=row1[2].value
locatorExpression=row1[3].value
operateValue=int(row1[4].value) if isinstance(row1[4].value,long) else row1[4].value
# print u"测试步骤描述:",caseStepDescripion
# print u"关键字:",keyWord
# print u"操作元素的定位方式:",locatorType
# print u"操作元素的定位表达式:",locatorExpression
# print u"操作值:",operateValue
if (locatorType and locatorExpression):
command="%s('%s','%s',u'%s')"%(keyWord,locatorType,locatorExpression.replace("'","\""),operateValue) if operateValue else "%s('%s','%s')"%(keyWord,locatorType,locatorExpression.replace("'","\""))
elif operateValue :
command ="%s(u'%s')"%(keyWord,operateValue)
else:
command="%s()"%keyWord
print caseStepDescripion
print "command:",command
try:
eval(command)
except Exception,e:
pe.write_cell_content(idx1 + 2, 7, u"fail")
pe.write_cell_current_time(idx1 + 2, 6)
pe.write_cell_content(idx1+2,8,traceback.format_exc())
pe.write_cell_content(idx1+2,9,captureScreen())
#写入错误截图需要封装函数,返回图片地址
else:#没有报错
successStepNum+=1
print "successStepNum:",successStepNum
pe.write_cell_content(idx1+2,7,u"pass")
pe.write_cell_current_time(idx1+2,6)
if totalStepNum == successStepNum:#此条用例执行成功
pe.get_sheet_by_name(u"测试用例") # 把默认sheet获取到测试用例sheet上
pe.write_cell_content(idx + 2, 8, u"成功") # 在结果列中写入忽略
pe.write_cell_current_time(idx+2,7)#写入执行时间
else:
pe.get_sheet_by_name(u"测试用例") # 把默认sheet获取到测试用例sheet上
pe.write_cell_content(idx + 2, 8, u"失败") # 在结果列中写入忽略
pe.write_cell_current_time(idx + 2, 7) # 写入执行时间
elif frameWorkType == u"数据":
pass
else:#不是y
pe.get_sheet_by_name(u"测试用例")#把默认sheet获取到测试用例sheet上
pe.write_cell_content(idx+2,8,u"忽略")#在结果列中写入忽略
pe.write_cell_content(idx+2,7,"")#清空时间列的值
结果:ok
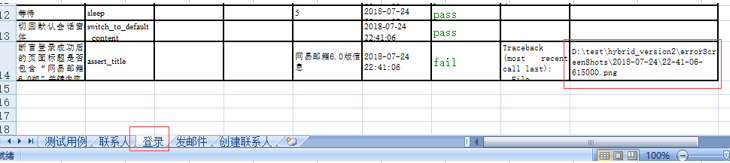
至此,我已经实现了关键字的步骤执行,记录执行时间、结果、错误信息和错误截图信息,下一步,实现数据驱动的执行。
步骤8:实现数据驱动用例的执行
看一下数据驱动对应的用例,数据驱动在这里其实是混合了关键字驱动和数据驱动两部分的,用例步骤sheet名是创建联系人,创建联系人sheet里包含的是关键字信息,以及关键字对应的参数,在执行创建联系人动作的过程中又从联系人sheet中取出需要添加的联系人信息,相当于用关键字执行相关的函数,到联系人sheet里去执行关键字函数所需的数据,所以是关键字驱动和数据驱动的混合模式,说白了,就是在把函数的名称和函数需要的参数分别放在文件中了,我们要做的就是如何正确的从文件中把这些可配置的数据给取出来,组合成正确的表达式来运行,这么做最大的好处是测试人员可以通过文件中数据和关键字的配置就可以运行整个框架,来测试被测系统。
貌似我一直在给自己确认这么做的目的。。。


思路是先在测试用例中,读取出测试步骤的sheet名,需要的数据源sheet名,然后到测试步骤sheet中读取出关键字信息以及参数信息,然后像关键字驱动那样写测试结果,时间信息、错误信息、截图信息等。
在用坐标(如”A1”)的方式获取单元格内容时,发现没有对应的方法,需要在ParseExcel.py中添加一个方法,来实现用坐标取数据:
def get_cell_content_by_coordinate(self,coordinate):
return self.sheet[coordinate].value
测试代码:
print u"通过坐标获取单元格内容(D4):",p.get_cell_content_by_coordinate('D4')
结果:ok
通过坐标获取单元格内容(D4): 5
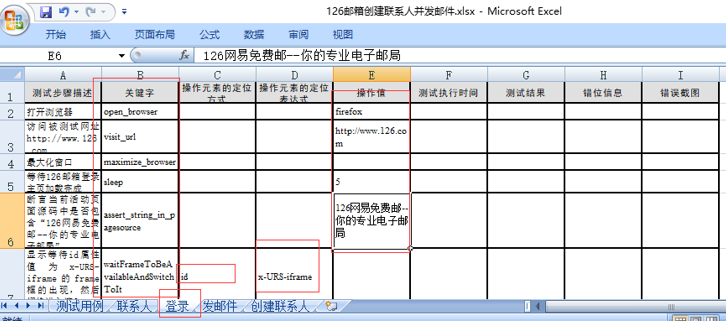
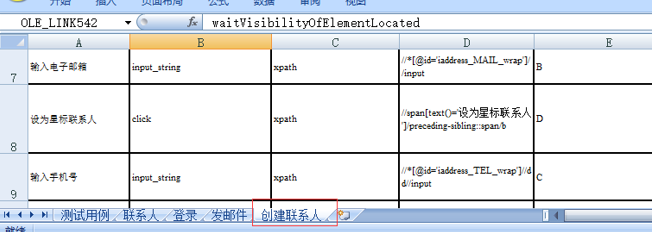
在执行waitVisibilityOfElementLocated这个关键字的时候,发现个问题:
它的第一个参数在文件中设置的是xpath,如图:

但是在pageAction.py中封装这个函数时是这样定义的:
element=wait.until(EC.visibility_of_element_located(locatortype,locatorExpression))
这样在拼接参数执行command的时候,就成了这个样子:
element=wait.until(EC.visibility_of_element_located(‘xpath’,’//span[xx]’))
但是通过EC.后边接期望场景的时候,是跟find_element_by不一样的,而是通过By模块的By.XPATH,By.ID之类的方式来查找元素的,而且没有引号,这就麻烦了,需要把这个方法改造一下,怎么改造呢,要做一个转化,把文件中取出的字符串”xpath”进行一个映射,映射成By.XPATH,可以通过字典的方式,比如:
locatorTypeDict={
"xpath": By.XPATH,
"id": By.ID,
"name": By.NAME,
"css_selector": By.CSS_SELECTOR,
"class_name": By.CLASS_NAME,
"tag_name": By.TAG_NAME,
"link_text": By.LINK_TEXT,
"partial_link_text": By.PARTIAL_LINK_TEXT}
然后element=wait.until(EC.visibility_of_element_located(locatortype,locatorExpression))改成这样:
element=wait.until(EC.visibility_of_element_located((locatorTypeDict[locatorType.lower()],locatorExpression)))
这样转成执行命令的时候就是:
element=wait.until(EC.visibility_of_element_located((By.XPATH, ‘//span[text()="新建联系人"]’)))
这样就符合语法规范了
然后在pageAction.py中修改waitVisibilityOfElementLocated()方法:
def waitVisibilityOfElementLocated(locatorType,locatorExpression,*arg):
#等待页面元素出现在DOM中并且可见,存在则返回该元素
global wait
locatorTypeDict={
"xpath": By.XPATH,
"id": By.ID,
"name": By.NAME,
"css_selector": By.CSS_SELECTOR,
"class_name": By.CLASS_NAME,
"tag_name": By.TAG_NAME,
"link_text": By.LINK_TEXT,
"partial_link_text": By.PARTIAL_LINK_TEXT}
try:
element=wait.until(EC.visibility_of_element_located((locatorTypeDict[locatorType.lower()],locatorExpression)))
return element
except Exception,e:
raise e
if __name__ == '__main__':
from selenium import webdriver
open_browser('firefox')
visit_url('http:\\126.com')
switch_to_frame("id", "x-URS-iframe")
input_string('xpath', '//input[@name="email"]', u'xiaxiaoxu1987')
input_string('xpath', '//input[@name="password"]', u'gloryroad')
click('id', 'dologin')
sleep(u'5')
switch_to_default_content()
click('xpath','//div[text()="通讯录"]')
waitVisibilityOfElementLocated('xpath', '//span[text()="新建联系人"]')
click('xpath', '//span[text()="新建联系人"]')
waitVisibilityOfElementLocated('xpath', '//a[@title="编辑详细姓名"]/preceding-sibling::div/input')
测试结果:ok
C:\Python27\python.exe D:/test/hybrid_version2/action/pageAction.py
Process finished with exit code 0
在测试用例中还有一个方法waitFrameToBeAvailableAndSwitchToIt()也用到了期望场景:EC.visibility_of_element_located()也需要像上边那样处理,写一段locatorTypeDict={…}的定义,然后再在期望方法中查找元素:
locatorTypeDict={
"xpath": By.XPATH,
"id": By.ID,
"name": By.NAME,
"css_selector": By.CSS_SELECTOR,
"class_name": By.CLASS_NAME,
"tag_name": By.TAG_NAME,
"link_text": By.LINK_TEXT,
"partial_link_text": By.PARTIAL_LINK_TEXT}
如果用例中还有其他的期望场景,也要这样重复的写这个字典的定义,那我们就可以把这个字典提出来,作为global的变量存在,然后再函数中像调用driver一样,用global 声明一下就可以了
pageAction.py:
#encoding=utf-8
from util.ObjectMap import *
from util.clipboard import *
from util.keyboard import *
from config.config import *
from selenium.webdriver.chrome.options import Options
import time
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from config.config import *
from selenium import webdriver
from datetime import datetime
from selenium.webdriver import ActionChains
import os
#定义全局driver变量
driver=None
wait=None
locatorTypeDict = {
"xpath": By.XPATH,
"id": By.ID,
"name": By.NAME,
"css_selector": By.CSS_SELECTOR,
"class_name": By.CLASS_NAME,
"tag_name": By.TAG_NAME,
"link_text": By.LINK_TEXT,
"partial_link_text": By.PARTIAL_LINK_TEXT}
def waitFrameToBeAvailableAndSwitchToIt(locatorType,locatorExpression,*arg):
#检查frmae是否存在,存在则切进frame中
global wait
global locatorTypeDict
try:
element = wait.until(
EC.frame_to_be_available_and_switch_to_it((locatorTypeDict[locatorType.lower()], locatorExpression)))
return element
except Exception, e:
raise e
def waitVisibilityOfElementLocated(locatorType,locatorExpression,*arg):
#等待页面元素出现在DOM中并且可见,存在则返回该元素
global wait
global locatorTypeDict
try:
element=wait.until(EC.visibility_of_element_located((locatorTypeDict[locatorType.lower()],locatorExpression)))
return element
except Exception,e:
raise e
其他函数定义省略。。。
在testScript包下新建一个dataAndKeywordDriven.py,把之前的login中关键字驱动的内容拿过来,然后接着写数据驱动的部分
dataAndKeywordDriven.py:
#encoding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
from util.ObjectMap import *
from action.pageAction import *
from util.ParseExcel import *
import traceback
pe=parseExcel(dataFilePath)
pe.get_sheet_by_name(u"测试用例")
print u"当前sheet:",pe.get_default_sheet()
caseRows=pe.get_all_rows()
for idx,row in enumerate(caseRows[1:]):
frameWorkType=row[2].value
caseStepSheet=row[3].value
dataDrivenSourceSheet=row[4].value
ifExecute=row[5].value
if ifExecute.lower() == 'y':
# print u"用例名称:", row[0].value
# print u"用例描述:", row[1].value
# print u"调用框架类型:", frameWorkType
# print u"用例步骤sheet名:", caseStepSheet
# print u"数据驱动的数据源sheet名:", dataDrivenSourceSheet
# print u"是否执行:", ifExecute
if frameWorkType ==u"关键字":
print "-----执行关键字驱动框架-----"
pe.get_sheet_by_name(caseStepSheet)
stepRows=pe.get_all_rows()
totalStepNum=len(stepRows)-1
print "totalStepNum:",totalStepNum
successStepNum=0
for idx1,row1 in enumerate(stepRows[1:]):
caseStepDescripion=row1[0].value
keyWord=row1[1].value
locatorType=row1[2].value
locatorExpression=row1[3].value
operateValue=str(row1[4].value) if isinstance(row1[4].value,long) else row1[4].value
# print u"测试步骤描述:",caseStepDescripion
# print u"关键字:",keyWord
# print u"操作元素的定位方式:",locatorType
# print u"操作元素的定位表达式:",locatorExpression
# print u"操作值:",operateValue
if (locatorType and locatorExpression):
command="%s('%s','%s',u'%s')"%(keyWord,locatorType,locatorExpression.replace("'","\""),operateValue) if operateValue else "%s('%s','%s')"%(keyWord,locatorType,locatorExpression.replace("'","\""))
elif operateValue :
command ="%s(u'%s')"%(keyWord,operateValue)
else:
command="%s()"%keyWord
print caseStepDescripion
print "command:",command
try:
eval(command)
except Exception,e:
pe.write_cell_content(idx1 + 2, 7, u"fail",color='red')
pe.write_cell_current_time(idx1 + 2, 6)
pe.write_cell_content(idx1+2,8,traceback.format_exc())
pe.write_cell_content(idx1+2,9,captureScreen())
#写入错误截图需要封装函数,返回图片地址
else:#没有报错
successStepNum+=1
print "successStepNum:",successStepNum
pe.write_cell_content(idx1+2,7,u"pass",color="green")
pe.write_cell_current_time(idx1+2,6)
pe.write_cell_content(idx1 + 2, 8, "")
pe.write_cell_content(idx1 + 2, 9, "")
if totalStepNum == successStepNum:#此条用例执行成功
pe.get_sheet_by_name(u"测试用例") # 把默认sheet获取到测试用例sheet上
pe.write_cell_content(idx + 2, 8, u"成功",color="green") # 在结果列中写入忽略
pe.write_cell_current_time(idx+2,7)#写入执行时间
else:
pe.get_sheet_by_name(u"测试用例") # 把默认sheet获取到测试用例sheet上
pe.write_cell_content(idx + 2, 8, u"失败",color="red") # 在结果列中写入忽略
pe.write_cell_current_time(idx + 2, 7) # 写入执行时间
elif frameWorkType == u"数据":
print "-----执行数据驱动框架-----"
print u"步骤sheet:",caseStepSheet
print u"数据源sheet",dataDrivenSourceSheet
pe.get_sheet_by_name(dataDrivenSourceSheet)
requiredContactNum = 0
successfullyAddedContactNum=0
isExecuteCol=pe.get_single_col(5)
emailCol=pe.get_single_col(1)
print "isExecuteCol:",isExecuteCol
print "emailCol:",emailCol
pe.get_sheet_by_name(caseStepSheet)
stepRows = pe.get_all_rows()
totalStepNum = len(stepRows) - 1
print "totalStepNum:", totalStepNum
for idx1,cell in enumerate(isExecuteCol[1:]):
if cell.value =='y':
successStepNum = 0
requiredContactNum+=1#记录一次需要添加的联系人
for row in stepRows[1:]:
caseStepDescripion = row[0].value
keyWord = row[1].value
locatorType = row[2].value
locatorExpression = row[3].value
operateValue = str(row[4].value) if isinstance(row[4].value, long) else row[4].value
# print "caseStepDescripion:",caseStepDescripion
# print "keyWord:",keyWord
# print "locatorType:",locatorType
# print "locatorExpression:",locatorExpression
# print "operateValue:",operateValue
if operateValue and operateValue.isalpha():
pe.get_sheet_by_name(dataDrivenSourceSheet)
operateValue=pe.get_cell_content_by_coordinate(operateValue+str(idx1+2))
#print "operateValue:",operateValue
if (locatorType and locatorExpression):
command = "%s('%s','%s',u'%s')" % (
keyWord, locatorType, locatorExpression.replace("'", "\""),
operateValue) if operateValue else "%s('%s','%s')" % (
keyWord, locatorType, locatorExpression.replace("'", "\""))
elif operateValue:
command = "%s(u'%s')" % (keyWord, operateValue)
print caseStepDescripion
print "command:",command
try:
if operateValue != u"否":
eval(command)
except Exception,e:#某个步骤执行失败
print u"执行步骤-%s-失败"%caseStepDescripion
else:#执行步骤成功
print u"执行步骤-%s-成功" % caseStepDescripion
successStepNum +=1
print "successStepNum:", successStepNum
#print "successStepNum:",successStepNum
if totalStepNum == successStepNum:#说明一条联系人添加成功
#写结果
print u"添加联系人-%s-成功"%emailCol[idx1+2].value
successfullyAddedContactNum +=1#记录一次添加一条联系人成功
pe.get_sheet_by_name(dataDrivenSourceSheet)
pe.write_cell_current_time(idx1+2,7)
pe.write_cell_content(idx1+2,8,u"pass",color='green')
else:#说明添加联系人没成功,写fail
print u"添加联系人-%s-失败" % emailCol[idx1 + 2].value
pe.get_sheet_by_name(dataDrivenSourceSheet)
pe.write_cell_current_time(idx1 + 2, 7)
pe.write_cell_content(idx1 + 2, 8, u"fail",color="red")
else: #忽略
pe.get_sheet_by_name(dataDrivenSourceSheet)
pe.write_cell_content(idx1+2,7,'')
pe.write_cell_content(idx1+2,8,u"忽略")
if requiredContactNum == successfullyAddedContactNum:#说明需要添加的联系人和添加成功的联系人数量一样,那这条用例就成功了
pe.get_sheet_by_name(u"测试用例")
pe.write_cell_content(idx+2,8,u"成功",color="green")
pe.write_cell_current_time(idx+2,7)
else:#有联系人添加失败了,用例执行失败,
pe.get_sheet_by_name(u"测试用例")
pe.write_cell_content(idx + 2, 8, u"失败",color="red")
pe.write_cell_current_time(idx + 2, 7)
else:#不是y
pe.get_sheet_by_name(u"测试用例")#把默认sheet获取到测试用例sheet上
pe.write_cell_content(idx+2,8,u"忽略")#在结果列中写入忽略
pe.write_cell_content(idx+2,7,"")#清空时间列的值
结果:ok
C:\Python27\python.exe D:/test/hybrid_version2/TestScripts/dataAndKeywordDriven.py
当前sheet: 测试用例
-----执行关键字驱动框架-----
打印日志部分省略。。。
Process finished with exit code 0
看下excel写入结果情况:


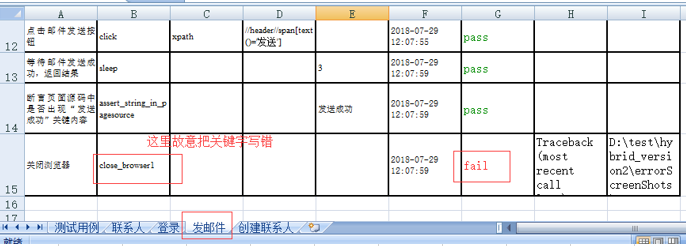
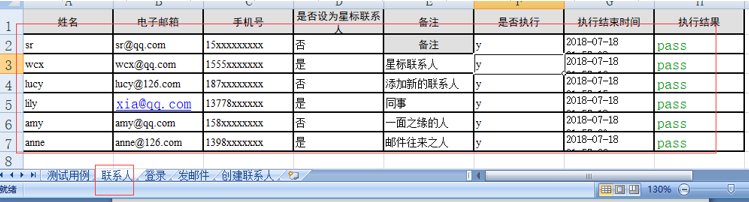
创建联系人,不涉及写入
在这块儿,我把文件中用于上传附件的关键字给改了,不是通过用点击按钮弹窗,然后调用键盘事件粘贴文件路径的方式,因为在实践过程中,发现点击上传附件按钮,始终没办法弹出windows窗口,卡在这儿好久,最后妥协了,换了直接用sendKeys()的方式了。
至此,读取关键字、数据、执行、写入结果都已经可以了,在这一步发费的调试时间是最长的,难点是取出数据要看是否正确,关键字对应的函数是否执行正确,写入文件的结果是否正确,以及判断一条联系人是否添加成功的逻辑,写结果的颜色等等,每一个地方有问题可能都要调试一会儿。
在写入测试结果的时候,需要修改一下ParseExce.py中的write_cell_content方法,把颜色的处理加进去。
def write_cell_content(self, row_no, col_no, content, font=None,color=None):
try:
self.sheet.cell(row=row_no, column=col_no).value = content
if color is not None:
self.sheet.cell(row=row_no, column=col_no).value = content
self.sheet.cell(row=row_no, column=col_no).font=Font(color=self.colorDict[color])
self.workbook.save(self.excelPath)
else:
self.sheet.cell(row=row_no, column=col_no).font = self.font
return self.sheet.cell(row=row_no, column=col_no).value
except Exception,e:
raise e
加入一个color参数,在写入内容的时候,如果指定了颜色,那么就会进行颜色的处理。
从主程序来看,我们直接把关键字驱动,数据驱动的处理和测试结果的写入,都罗列在了一个文件中,代码看起来很长,读起来不太清晰、简洁,下面就试着把可以封装出来的进行封装。
步骤9:封装主程序中的关键字驱动和数据驱动部分功能
在TestScripts包下新建keyWord.py用于封装关键字方法
#encoding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
from util.ObjectMap import *
from action.pageAction import *
from util.ParseExcel import *
import traceback
def keyWordFunction(excelObj,caseStepSheet):
excelObj.get_sheet_by_name(caseStepSheet)
stepRows = excelObj.get_all_rows()
totalStepNum = len(stepRows) - 1
#print "totalStepNum:", totalStepNum
successStepNum = 0
for idx1, row1 in enumerate(stepRows[1:]):
caseStepDescripion = row1[0].value
keyWord = row1[1].value
locatorType = row1[2].value
locatorExpression = row1[3].value
operateValue = str(row1[4].value) if isinstance(row1[4].value, long) else row1[4].value
if (locatorType and locatorExpression):
command = "%s('%s','%s',u'%s')" % (keyWord, locatorType, locatorExpression.replace("'", "\""),
operateValue) if operateValue else "%s('%s','%s')" % (
keyWord, locatorType, locatorExpression.replace("'", "\""))
elif operateValue:
command = "%s(u'%s')" % (keyWord, operateValue)
else:
command = "%s()" % keyWord
print caseStepDescripion
#print "command:", command
try:
eval(command)
except Exception, e:
excelObj.write_cell_content(idx1 + 2, 7, u"fail", color='red')
excelObj.write_cell_current_time(idx1 + 2, 6)
excelObj.write_cell_content(idx1 + 2, 8, traceback.format_exc())
excelObj.write_cell_content(idx1 + 2, 9, captureScreen())
# 写入错误截图需要封装函数,返回图片地址
else: # 没有报错
successStepNum += 1
#print "successStepNum:", successStepNum
excelObj.write_cell_content(idx1 + 2, 7, u"pass", color="green")
excelObj.write_cell_current_time(idx1 + 2, 6)
excelObj.write_cell_content(idx1 + 2, 8, "")
excelObj.write_cell_content(idx1 + 2, 9, "")
if totalStepNum == successStepNum: # 此条用例执行成功
return 1#代表成功
else:
return 0#代表失败
在TestScripts包下新建dataDriven.py用于封装数据驱动方法
#encoding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
from util.ObjectMap import *
from action.pageAction import *
from util.ParseExcel import *
import traceback
def dataDrivenFunction(excelObj,caseStepSheet,dataDrivenSourceSheet):
print u"步骤sheet:", caseStepSheet
print u"数据源sheet", dataDrivenSourceSheet
excelObj.get_sheet_by_name(dataDrivenSourceSheet)
requiredContactNum = 0
successfullyAddedContactNum = 0
isExecuteCol = excelObj.get_single_col(5)
emailCol = excelObj.get_single_col(1)
#print "isExecuteCol:", isExecuteCol
#print "emailCol:", emailCol
excelObj.get_sheet_by_name(caseStepSheet)
stepRows = excelObj.get_all_rows()
totalStepNum = len(stepRows) - 1
#print "totalStepNum:", totalStepNum
for idx1, cell in enumerate(isExecuteCol[1:]):
if cell.value == 'y':
successStepNum = 0
requiredContactNum += 1 # 记录一次需要添加的联系人
for row in stepRows[1:]:
caseStepDescripion = row[0].value
keyWord = row[1].value
locatorType = row[2].value
locatorExpression = row[3].value
operateValue = str(row[4].value) if isinstance(row[4].value, long) else row[4].value
# print "caseStepDescripion:",caseStepDescripion
# print "keyWord:",keyWord
# print "locatorType:",locatorType
# print "locatorExpression:",locatorExpression
# print "operateValue:",operateValue
if operateValue and operateValue.isalpha():
excelObj.get_sheet_by_name(dataDrivenSourceSheet)
operateValue = excelObj.get_cell_content_by_coordinate(operateValue + str(idx1 + 2))
# print "operateValue:",operateValue
if (locatorType and locatorExpression):
command = "%s('%s','%s',u'%s')" % (
keyWord, locatorType, locatorExpression.replace("'", "\""),
operateValue) if operateValue else "%s('%s','%s')" % (
keyWord, locatorType, locatorExpression.replace("'", "\""))
elif operateValue:
command = "%s(u'%s')" % (keyWord, operateValue)
print caseStepDescripion
#print "command:", command
try:
if operateValue != u"否":
eval(command)
except Exception, e: # 某个步骤执行失败
print u"执行步骤-%s-失败" % caseStepDescripion
else: # 执行步骤成功
print u"执行步骤-%s-成功" % caseStepDescripion
successStepNum += 1
#print "successStepNum:", successStepNum
# print "successStepNum:",successStepNum
if totalStepNum == successStepNum:#说明一条联系人添加成功
#写结果
print u"添加联系人-%s-成功"%emailCol[idx1+2].value
successfullyAddedContactNum +=1#记录一次添加一条联系人成功
excelObj.get_sheet_by_name(dataDrivenSourceSheet)
excelObj.write_cell_current_time(idx1+2,7)
excelObj.write_cell_content(idx1+2,8,u"pass",color='green')
else:#说明添加联系人没成功,写fail
print u"添加联系人-%s-失败" % emailCol[idx1 + 2].value
excelObj.get_sheet_by_name(dataDrivenSourceSheet)
excelObj.write_cell_current_time(idx1 + 2, 7)
excelObj.write_cell_content(idx1 + 2, 8, u"fail",color="red")
else: # 忽略
excelObj.get_sheet_by_name(dataDrivenSourceSheet)
excelObj.write_cell_content(idx1 + 2, 7, '')
excelObj.write_cell_content(idx1 + 2, 8, u"忽略")
if requiredContactNum == successfullyAddedContactNum:#说明需要添加的联系人和添加成功的联系人数量一样,那这条用例就成功了
return 1
else:#有联系人添加失败了,用例执行失败,
return 0
在主程序中调用dataDriven方法和keyWord方法
dataAndKeywordDriven.py:
#encoding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
from util.ObjectMap import *
from action.pageAction import *
from util.ParseExcel import *
import traceback
from TestScripts.keyWord import *
from TestScripts.dataDriven import *
pe=parseExcel(dataFilePath)
pe.get_sheet_by_name(u"测试用例")
print u"当前sheet:",pe.get_default_sheet()
caseRows=pe.get_all_rows()
#print "caseRows:",caseRows
for idx,row in enumerate(caseRows[1:]):
frameWorkType=row[2].value
caseStepSheet=row[3].value
dataDrivenSourceSheet=row[4].value
ifExecute=row[5].value
#print "ifExecute",ifExecute
if ifExecute.lower() == 'y':
# print u"用例名称:", row[0].value
# print u"用例描述:", row[1].value
# print u"调用框架类型:", frameWorkType
# print u"用例步骤sheet名:", caseStepSheet
# print u"数据驱动的数据源sheet名:", dataDrivenSourceSheet
# print u"是否执行:", ifExecute
if frameWorkType ==u"关键字":
print "#####执行关键字驱动框架#####"
result =keyWordFunction(pe,caseStepSheet)
print "result:",result
if result:#此条用例执行成功
pe.get_sheet_by_name(u"测试用例") # 把默认sheet获取到测试用例sheet上
pe.write_cell_content(idx + 2, 8, u"成功",color="green") # 在结果列中写入忽略
pe.write_cell_current_time(idx+2,7)#写入执行时间
else:
pe.get_sheet_by_name(u"测试用例") # 把默认sheet获取到测试用例sheet上
pe.write_cell_content(idx + 2, 8, u"失败",color="red") # 在结果列中写入忽略
pe.write_cell_current_time(idx + 2, 7) # 写入执行时间
elif frameWorkType == u"数据":
print "#####执行数据驱动框架#####"
result=dataDrivenFunction(pe,caseStepSheet,dataDrivenSourceSheet)
if result:#说明需要添加的联系人和添加成功的联系人数量一样,那这条用例就成功了
pe.get_sheet_by_name(u"测试用例")
pe.write_cell_content(idx+2,8,u"成功",color="green")
pe.write_cell_current_time(idx+2,7)
else:#有联系人添加失败了,用例执行失败,
pe.get_sheet_by_name(u"测试用例")
pe.write_cell_content(idx + 2, 8, u"失败",color="red")
pe.write_cell_current_time(idx + 2, 7)
else:#不是y
pe.get_sheet_by_name(u"测试用例")#把默认sheet获取到测试用例sheet上
pe.write_cell_content(idx+2,8,u"忽略")#在结果列中写入忽略
pe.write_cell_content(idx+2,7,"")#清空时间列的值
结果:ok
C:\Python27\python.exe D:/test/hybrid_version2/TestScripts/dataAndKeywordDriven.py
当前sheet: 测试用例
#####执行关键字驱动框架#####
打开浏览器
访问被测试网址http://www.126.com
最大化窗口
等待126邮箱登录主页加载完成
断言当前活动页面源码中是否包含“126网易免费邮--你的专业电子邮局”
显示等待id属性值为x-URS-iframe的frame框的出现,然后切换进入该frame框中
清除用户名输入框中的缓存用户性
输入登录用户名
输入登录密码
点击登录按钮
等待
切回默认会话窗体
断言登录成功后的页面标题是否包含“网易邮箱6.0版”关键内容
result: 1
#####执行数据驱动框架#####
步骤sheet: 创建联系人
数据源sheet 联系人
点击“通讯录”链接,进入通讯录页面
执行步骤-点击“通讯录”链接,进入通讯录页面-成功
显示等待“新建联系人”按钮在页面上可见
执行步骤-显示等待“新建联系人”按钮在页面上可见-成功
点击“新建联系人”按钮
执行步骤-点击“新建联系人”按钮-成功
显示等待输入联系人姓名框是否在页面上可见
执行步骤-显示等待输入联系人姓名框是否在页面上可见-成功
输入联系人姓名
执行步骤-输入联系人姓名-成功
输入电子邮箱
执行步骤-输入电子邮箱-成功
设为星标联系人
执行步骤-设为星标联系人-成功
输入手机号
执行步骤-输入手机号-成功
输入联系人备注信息
执行步骤-输入联系人备注信息-成功
点击“确认”按钮保存新联系人
执行步骤-点击“确认”按钮保存新联系人-成功
等待2秒
执行步骤-等待2秒-成功
断言联系人是否成功添加
执行步骤-断言联系人是否成功添加-成功
添加联系人-wcx@qq.com-成功
点击“通讯录”链接,进入通讯录页面
执行步骤-点击“通讯录”链接,进入通讯录页面-成功
显示等待“新建联系人”按钮在页面上可见
执行步骤-显示等待“新建联系人”按钮在页面上可见-成功
点击“新建联系人”按钮
执行步骤-点击“新建联系人”按钮-成功
显示等待输入联系人姓名框是否在页面上可见
执行步骤-显示等待输入联系人姓名框是否在页面上可见-成功
输入联系人姓名
执行步骤-输入联系人姓名-成功
输入电子邮箱
执行步骤-输入电子邮箱-成功
设为星标联系人
执行步骤-设为星标联系人-成功
输入手机号
执行步骤-输入手机号-成功
输入联系人备注信息
执行步骤-输入联系人备注信息-成功
点击“确认”按钮保存新联系人
执行步骤-点击“确认”按钮保存新联系人-成功
等待2秒
执行步骤-等待2秒-成功
断言联系人是否成功添加
执行步骤-断言联系人是否成功添加-成功
添加联系人-amy@qq.com-成功
#####执行关键字驱动框架#####
点击“首页”链接,进入邮箱首页
判断“写信”按钮是否在页面上可见
点击“写信”按钮
输入收件人地址
输入邮件主题
点击“上传附件”链接
显示等待附件上传完成
如果邮件正文的frame框是否可见,切换进该frame中
输入邮件正文
退出邮件正文的frame
点击邮件发送按钮
等待邮件发送成功,返回结果
断言页面源码中是否出现“发送成功”关键内容
关闭浏览器
result: 1
Process finished with exit code 0
至此,我把数据驱动、关键字驱动部分封装成了方法,和主程序进行了分离,但是程序中写入结果的代码比较占篇幅,也比较零散,下面尝试把写结果部分进行下一下封装
步骤10:把写测试结果的功能进行封装
在util包下新建writeResult.py文件:
#encoding=utf-8
from util.ParseExcel import *
from config.config import *
import traceback
from util.ParseExcel import *
from config.config import *
def writeResult(excelObj,sheetName,sheetType,rowNo,result,errorInfo=None,captureScreenPath=None):
colorOfResult = {"pass": "green", "fail": "red", u"成功": "green",u"失败": "red", u"忽略": None, "": None}
print "当前所在sheet:",excelObj.get_default_sheet()
print excelObj, sheetName, sheetType, rowNo, result, errorInfo,captureScreenPath
sheetTypeDict={
"testCase":[testCase_runTime, testCase_testResult],#测试用例sheet名,时间列和结果列的列号
"caseStep":[testStep_runTime, testStep_testResult,testStep_errorInfo,testStep_errorPic],#关键字驱动测试步骤sheet名,时间列和结果列号
"dataSheet":[dataSource_runTime, dataSource_result]}#数据驱动的数据源sheet名,时间、结果列号
try:
excelObj.get_sheet_by_name(sheetName)
if sheetType != "caseStep":#sheetType不是关键字步骤sheet,说明是用例sheet或者数据源sheet
print "sheetType1:",sheetType
print "sheetTypeDict[sheetType][1]:",sheetTypeDict[sheetType][1]
#直接把结果写上去
excelObj.write_cell_content(rowNo, sheetTypeDict[sheetType][1], result, color=colorOfResult[result])
if result != "" and result != u"忽略":
print "result-1:",result
excelObj.write_cell_current_time(rowNo,sheetTypeDict[sheetType][0])
else:#联系人被忽略,时间列清空
print "result-2:", result
excelObj.write_cell_content(rowNo,sheetTypeDict[sheetType][0],"",color=colorOfResult[result])
else :#sheetType是步骤sheet
print "sheetType2:", sheetType
print "result:",result
#先把结果列和时间列给写上
excelObj.write_cell_content(rowNo, sheetTypeDict[sheetType][1], result, color=colorOfResult[result])
excelObj.write_cell_current_time(rowNo, sheetTypeDict[sheetType][0])
if errorInfo and captureScreenPath:#有错误信息和截图信息,把错误信息和截图信息写进去
print "errorInfo:",errorInfo
print "captureScreenPath:",captureScreenPath
excelObj.write_cell_content(rowNo, sheetTypeDict[sheetType][2], errorInfo)
excelObj.write_cell_content(rowNo, sheetTypeDict[sheetType][3], captureScreenPath)
else:#没有截图信息和错误信息,把截图信息和错误信息清空
print "sheetTypeDict[sheetType][3]",sheetTypeDict[sheetType][3]
print "sheetTypeDict[sheetType][2]",sheetTypeDict[sheetType][2]
excelObj.write_cell_content(rowNo, sheetTypeDict[sheetType][3],"")#是成功的,没有错误信息
excelObj.write_cell_content(rowNo, sheetTypeDict[sheetType][2], "")#是成功的,没有截图信息
except Exception,e:
raise e
keyword.py中调用:
#encoding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
from util.ObjectMap import *
from action.pageAction import *
from util.ParseExcel import *
import traceback
from util.writeResult import *
def keyWordFunction(excelObj,caseStepSheet):
excelObj.get_sheet_by_name(caseStepSheet)
stepRows = excelObj.get_all_rows()
totalStepNum = len(stepRows) - 1
#print "totalStepNum:", totalStepNum
successStepNum = 0
for idx1, row1 in enumerate(stepRows[1:]):
caseStepDescripion = row1[testStep_testStepDescribe-1].value
keyWord = row1[testStep_keyWords-1].value
locatorType = row1[testStep_locationType-1].value
locatorExpression = row1[testStep_locatorExpression-1].value
operateValue = str(row1[testStep_operateValue-1].value) if isinstance(row1[testStep_operateValue-1].value, long) else row1[testStep_operateValue-1].value
if (locatorType and locatorExpression):
command = "%s('%s','%s',u'%s')" % (keyWord, locatorType, locatorExpression.replace("'", "\""),
operateValue) if operateValue else "%s('%s','%s')" % (
keyWord, locatorType, locatorExpression.replace("'", "\""))
elif operateValue:
command = "%s(u'%s')" % (keyWord, operateValue)
else:
command = "%s()" % keyWord
print caseStepDescripion
#print "command:", command
try:
eval(command)
except Exception, e:
errorInfo=traceback.format_exc()
captureScreenPath=captureScreen()
writeResult(excelObj, caseStepSheet,"caseStep", idx1 + 2, u"fail",errorInfo=errorInfo,captureScreenPath=captureScreenPath)
else: # 没有报错
successStepNum += 1
writeResult(excelObj, caseStepSheet,"caseStep", idx1 + 2, u"pass")
if totalStepNum == successStepNum: # 此条用例执行成功
return 1#代表成功
else:
return 0#代表失败
dataDriven.py中调用:
#encoding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
from util.ObjectMap import *
from action.pageAction import *
from util.ParseExcel import *
import traceback
from util.writeResult import *
def dataDrivenFunction(excelObj,caseStepSheet,dataDrivenSourceSheet):
print u"步骤sheet:", caseStepSheet
print u"数据源sheet", dataDrivenSourceSheet
excelObj.get_sheet_by_name(dataDrivenSourceSheet)
requiredContactNum = 0
successfullyAddedContactNum = 0
isExecuteCol = excelObj.get_single_col(5)
emailCol = excelObj.get_single_col(1)
excelObj.get_sheet_by_name(caseStepSheet)
stepRows = excelObj.get_all_rows()
totalStepNum = len(stepRows) - 1
#print "totalStepNum:", totalStepNum
for idx1, cell in enumerate(isExecuteCol[1:]):
if cell.value == 'y':
successStepNum = 0
requiredContactNum += 1 # 记录一次需要添加的联系人
for row in stepRows[1:]:
caseStepDescripion = row[testStep_testStepDescribe-1].value
keyWord = row[testStep_keyWords-1].value
locatorType = row[testStep_locationType-1].value
locatorExpression = row[testStep_locatorExpression-1].value
operateValue = str(row[testStep_operateValue-1].value) if isinstance(row[testStep_operateValue-1].value, long) else row[testStep_operateValue-1].value
if operateValue and operateValue.isalpha():
excelObj.get_sheet_by_name(dataDrivenSourceSheet)
operateValue = excelObj.get_cell_content_by_coordinate(operateValue + str(idx1 + 2))
# print "operateValue:",operateValue
if (locatorType and locatorExpression):
command = "%s('%s','%s',u'%s')" % (
keyWord, locatorType, locatorExpression.replace("'", "\""),
operateValue) if operateValue else "%s('%s','%s')" % (
keyWord, locatorType, locatorExpression.replace("'", "\""))
elif operateValue:
command = "%s(u'%s')" % (keyWord, operateValue)
print caseStepDescripion
#print "command:", command
try:
if operateValue != u"否":
eval(command)
except Exception, e: # 某个步骤执行失败
print u"执行步骤-%s-失败" % caseStepDescripion
else: # 执行步骤成功
print u"执行步骤-%s-成功" % caseStepDescripion
successStepNum += 1
#print "successStepNum:", successStepNum
# print "successStepNum:",successStepNum
if totalStepNum == successStepNum:#说明一条联系人添加成功
#写结果
print u"添加联系人-%s-成功"%emailCol[idx1+2].value
successfullyAddedContactNum +=1#记录一次添加一条联系人成功
writeResult(excelObj,dataDrivenSourceSheet,"dataSheet",idx1+2,u"pass",)
else:#说明添加联系人没成功,写fail
print u"添加联系人-%s-失败" % emailCol[idx1 + 2].value
writeResult(excelObj, dataDrivenSourceSheet, "dataSheet", idx1 + 2, u"fail", )
else: # 忽略
writeResult(excelObj, dataDrivenSourceSheet, "dataSheet", idx1 + 2, u"忽略", )
if requiredContactNum == successfullyAddedContactNum:#说明需要添加的联系人和添加成功的联系人数量一样,那这条用例就成功了
return 1
else:#有联系人添加失败了,用例执行失败,
return 0
主程序中调用:
#encoding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
from util.ObjectMap import *
from action.pageAction import *
from util.ParseExcel import *
import traceback
from TestScripts.keyWord import *
from TestScripts.dataDriven import *
from util.writeResult import *
pe=parseExcel(dataFilePath)
caseSheetName=u"测试用例"#测试用例sheet名
pe.get_sheet_by_name(caseSheetName)
print u"当前sheet:",pe.get_default_sheet()
caseRows=pe.get_all_rows()
#print "caseRows:",caseRows
for idx,row in enumerate(caseRows[1:]):
frameWorkType=row[testCase_frameWorkName-1].value
caseStepSheet=row[testCase_testStepSheetName-1].value
dataDrivenSourceSheet=row[testCase_dataSourceSheetName-1].value
ifExecute=row[testCase_isExecute-1].value
#print "ifExecute",ifExecute
if ifExecute.lower() == 'y':
if frameWorkType ==u"关键字":
print "#####执行关键字驱动框架#####"
result =keyWordFunction(pe,caseStepSheet)
print "result:",result
if result:#此条用例执行成功
writeResult(pe,caseSheetName,"testCase",idx+2,u"成功")
else:
writeResult(pe,caseSheetName,"testCase", idx + 2, u"失败")
elif frameWorkType == u"数据":
print "#####执行数据驱动框架#####"
result=dataDrivenFunction(pe,caseStepSheet,dataDrivenSourceSheet)
if result:#说明需要添加的联系人和添加成功的联系人数量一样,那这条用例就成功了
writeResult(pe, caseSheetName,"dataSheet", idx + 2, u"成功")
else:#有联系人添加失败了,用例执行失败,
writeResult(pe, caseSheetName,"dataSheet", idx + 2, u"失败")
else:#不是y
writeResult(pe,caseSheetName, "testCase", idx + 2, u"忽略")
结果:ok




说实话,封装这个写结果的逻辑,大概用了我一个人天的工时,而且很多地方是参考了老师的实现方式,但还是很费劲,感觉要处理的逻辑总是梳理不清楚,而且又不能抄老师的代码,那样就不会形成自己的思路,我先是按照自己的理解一点一点地实现,然后有卡住的地方再去看看老师代码的思路,最终总算按照自己的想法把它实现了。
之前写结果的过程都是在具体的地方罗列了往哪个行哪个列写入具体的值,虽然步骤较多,但是看起来比较直观,好理解,缺点就是重复的代码有点儿多,不利于复用,所以给封装出来,但是封装的时候要考虑的逻辑点较多,简单列一下:
1-要考虑写结果的时候所在的sheet位置,不同sheet页布局不一样,要区分开来做具体的处理,比如用例sheet和数据源sheet结构相同,都有结果列和时间列,可以用相同方式处理,步骤sheet比前两种sheet多了错误信息列和截图信息列,这个可以单独处理一下;
2-在处理用例sheet和数据源sheet时,结果有4种:成功、失败、忽略、空,在结果这一列无非写入这4个结果之一,所以可以直接把结果给写上去,然后针对忽略或者空的情况,把时间这一列给清空掉,因为忽略的case是不用写执行时间的,不为空或者不为忽略的就在执行时间列写入当前的时间,这样用例sheet和数据源sheet就处理完了;
3-然后是步骤sheet,因为步骤sheet是执行的步骤,只有成功和失败两种情况,不存在忽略的情况,区别就是成功时不需要写错误信息和截图信息,失败时要写入,那就先把执行时间和结果列给写上去,然后针对失败的情况写一下错误信息列和截图信息列,这样写结果的逻辑就都覆盖全了;
4-然后一个难点就是怎么区分不同的sheet,怎么把结果写到对应的列上去呢,可以把不同的sheet对应不同的列信息放到一个字典里,key是sheet类型,value是一个列表,用来放需要写结果的列号,然后调用写结果函数时把sheet的类型传进来,然后用切片去取对应的列信息,就可以了;
5-然后是颜色处理,可以把所有可能的结果以及对应的颜色放到一个字典里(key是结果,value是颜色),在写结果的时候,把color的值用字典取一下就可以。
以上5点就是封装写结果要考虑的逻辑,看起来挺简单的,但是我用了好长时间才理清楚,
感觉还是得多练啊,有点像打怪,不多打点怪,经验值还上不去呢~~
在封装写结果方法的过程中,优化了一个地方,之前在读取文件中不同列号的值是直接用数字来写的,我改成用变量的形式,这样好理解一些,也方便维护
在config文件中,把不同sheet中的各个列的序号用变量存起来:
#测试用例sheet中列号信息
testCase_testCaseName = 1
testCase_frameWorkName = 3
testCase_testStepSheetName = 4
testCase_dataSourceSheetName = 5
testCase_isExecute = 6
testCase_runTime = 7
testCase_testResult = 8
#测试步骤对应的文件中后边的关键字的列号
testStep_testStepDescribe = 1
testStep_keyWords = 2
testStep_locationType = 3
testStep_locatorExpression = 4
testStep_operateValue = 5
testStep_runTime = 6
testStep_testResult = 7
testStep_errorInfo = 8
testStep_errorPic = 9
# 数据源表中,是否执行列对应的数字编号
#联系人的sheet
dataSource_isExecute = 6
dataSource_email = 2
dataSource_runTime = 7
dataSource_result = 8
至此,这个混合驱动的框架基本已经搭建完成了,还有一个地方需要优化,就是把程序中打印日志的print语句用日志模块来代替,可以把更多的信息体现在日志中。
步骤11:封装日志模块
在config包下新建Logger.conf文件存日志配置信息
#logger.conf
###############################################
[loggers]
keys=root,example01,example02
[logger_root]
level=DEBUG
handlers=hand01,hand02
[logger_example01]
handlers=hand01,hand02
qualname=example01
propagate=0
[logger_example02]
handlers=hand01,hand03
qualname=example02
propagate=0
###############################################
[handlers]
keys=hand01,hand02,hand03
[handler_hand01]
class=StreamHandler
level=INFO
formatter=form01
args=(sys.stderr,)
[handler_hand02]
class=FileHandler
level=DEBUG
formatter=form01
args=('DataDrivenFrameWork.log', 'a')
[handler_hand03]
class=handlers.RotatingFileHandler
level=INFO
formatter=form01
args=('DataDrivenFrameWork.log', 'a', 10*1024*1024, 5)
###############################################
[formatters]
keys=form01,form02
[formatter_form01]
format=%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s
datefmt=%Y-%m-%d %H:%M:%S
[formatter_form02]
format=%(name)-12s: %(levelname)-8s %(message)s
datefmt=%Y-%m-%d %H:%M:%S
在util包下新建log.py文件,定义日志函数
#encoding=utf-8
import logging
import logging.config
from config.config import *
#读取日志的配置文件
logging.config.fileConfig(projectPath+"\\config\\Logger.conf")
#选择一个日志格式
logger=logging.getLogger("example02")
def error(message):
#打印debug级别的信息
logger.error(message)
def info(message):
#打印info级别的信息
logger.info(message)
def warning(message):
#打印warning级别的信息
logger.warning(message)
if __name__=="__main__":
info("hi")
print "config file
path:",projectPath+"\\config\\Logger.conf"
error("world!")
warning("gloryroad!")
把文件中用print打印日志的地方,换成logging.info(string)的方式
需要注意两个地方,一个是logging.info()函数中只能输入一个参数,如果需要显示逗号相隔的多个信息,可以用模板字符串的方式,另一个是最好使用u’%s’的方式,因为直接用%s的话,如果字符串中要替换的字符有中文,调用logging.info()会报错,会提示没有把所有的字符进行转换。
下面是整个框架的结构:


此时此刻,“总结”已经显得有些苍白无力,知道了原理只是刚刚开始,实践才是硬道理,多练吧,要走的路还很长~~
python webdriver 从无到有搭建混合驱动自动化测试框架的过程和总结的更多相关文章
- python webdriver 从无到有搭建数据驱动自动化测试框架的步骤和总结
一步一步搭建数据驱动测试框架的过程和总结 跟吴老学了搭建自动化数据驱动的框架后,我在自己练习的时候,尝试从简单的程序进行一点一点的扩展和优化,到实现这个数据驱动的框架. 先说一下搭建自动化测试框架的目 ...
- 小白学 Python 爬虫(28):自动化测试框架 Selenium 从入门到放弃(下)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- MAC中在eclipse luna上搭建移动平台自动化测试框架(UIAutomator/Appium/Robotium/MonkeyRunner)关键点记录
这几天因为原来在用的hp laptop的电池坏掉了,机器一不小心就断电,所以只能花时间在自己的macbook pro上重新搭建整套环境,大家都知道搭建环境是个很琐碎需要耐心的事情,特别是当你搭建的安卓 ...
- 接口自动化 [授客]基于python+Testlink+Jenkins实现的接口自动化测试框架V3.0
基于python+Testlink+Jenkins实现的接口自动化测试框架V3.0 by:授客 QQ:1033553122 博客:http://blog.sina.com.cn/ishou ...
- 接口自动化 基于python+Testlink+Jenkins实现的接口自动化测试框架[V2.0改进版]
基于python+Testlink+Jenkins实现的接口自动化测试框架[V2.0改进版] by:授客 QQ:1033553122 由于篇幅问题,,暂且采用网盘分享的形式: 下载地址: [授客] ...
- 基于python+Testlink+Jenkins实现的接口自动化测试框架V3.0
基于python+Testlink+Jenkins实现的接口自动化测试框架V3.0 目录 1. 开发环境2. 主要功能逻辑介绍3. 框架功能简介 4. 数据库的创建 5. 框架模块详细介绍6. Tes ...
- 转:python webdriver 环境搭建
第一节 环境搭建准备工具如下:-------------------------------------------------------------下载 python[python 开发环境]ht ...
- python webdriver 环境搭建详解
学了一个月用java编写selenium driver 测试脚本,也将公司做的系统基本可用的模块做了一次自动化,虽然写的比较简陋,但是基本可用跑一遍,并用testNG生成了测试报告. 学习方式无非是: ...
- 小白学 Python 爬虫(27):自动化测试框架 Selenium 从入门到放弃(上)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
随机推荐
- 解决远程登陆Linux误按ctrl+s锁屏
很多刚从windows转移到linux上来工作的朋友,在用vi/vim编辑文件时,常常会习惯性的按下Ctrl+s来保存文件内容.殊不知这样按下去后面会造成整个终端不响应了,ssh连接还好说,直接关 ...
- Html5游戏框架createJs组件--EaselJS(二)绘图类graphics
有端友问我是否有文档,有确实有,但没有中文的,只有英文的,先提供浏览地址供大家参考学习createJs英文文档. EaselJS其实主要就是createJ ...
- 9.9Dajngo MTV
2018-9-9 14:53:53 mvc框架和 Django的MTV框架 框架参考 :https://www.cnblogs.com/liwenzhou/p/8296964.html 2018-9- ...
- 公司HBase基准性能测试之准备篇
本次测试主要评估线上HBase的整体性能,量化当前HBase的性能指标,对各种场景下HBase性能表现进行评估,为业务应用提供参考. 测试环境 测试环境包括测试过程中HBase集群的拓扑结构.以及需要 ...
- python全栈开发目录
python全栈开发目录 Linux系列 python基础 前端~HTML~CSS~JavaScript~JQuery~Vue web框架们~Django~Flask~Tornado 数据库们~MyS ...
- PL/SQL类的应用
类的定义 直接声明字段类型‘VARCHAR2或NUMBER等’ declare type kingsql_tp1 is record(empno number,ename varchar2(100)) ...
- 学习计划 nginx try_files的作用
之前的nginx配置中,我链接了php和nginx之间是怎么通信和$_SERVER参数的作用. 现在有一个问题,我要配置自己的框架,我需要的参数的是 IP/控制器/方法/参数 但是现在配置的话ngin ...
- less语言特性(二) —— 混合
在 LESS 中我们可以定义一些通用的属性集为一个 class,然后在另一个 class 中去调用这些属性,下面有这样一个 class: 1 2 3 4 .bordered { border-top: ...
- 010-jdk1.8版本新特性二-Optional类,Stream流
1.5.Optional类 1.定义 Optional 类是一个可以为null的容器对象.如果值存在则isPresent()方法会返回true,调用get()方法会返回该对象. Optional 是个 ...
- PAT 1103 Integer Factorization[难]
1103 Integer Factorization(30 分) The K−P factorization of a positive integer N is to write N as the ...