HBase的Scan
HBase的Scan和Get不同,前者获取数据是串行,后者则是并行;是不是有种大跌眼镜的感觉?
Scan有四种模式:scan,(Table)snapScan,(Table)scanMR,snapshotscanMR;前面两个是串行玩;后面两个是放置到MapReduce中玩;其中性能最好的就是SnapshotScanMR;
首先解释一下什么是snapshort,snapshot是HBase数据表元数据的一个快照,是的,不包括数据;有一点概念要建立清楚,HBase的数据的存储并不是HBase管理,而是HDFS;其实关系型数据库的存储也是OSFS管理的。HBase的设计就是一旦数据写入了,就不改变了,改变操作(update,delete)并不是修改HFile,而是填充墓碑文件而已;所以快照尤其价值,比如可以快速拷贝一个HBase表(只是拷贝表结构,重用原始表的HDFS数据)。
刚才讲的snapshot在scan里面也有应用场景,就是snapshotscan以及snapshortscanMR;注意MR的scan模式就不再是最上面提到的串行查询,而是并行查询;底层机制是Map-reduce;所以就下来而言,MR是要高的;毕竟是多个region查询。
接着,就是ScanAPI的设计:
1. 业务调用HBase Client,HBaseClient首先是查找缓存是否还有数据,如果有则返回数据;
2. 如果没有数据,则通过向RegionServer继续请求下面的100条记录;
3. 作为服务器端接收到next请求之后,将会通过查询BlockCache→HFile→Memstore流程来一行一行的返回数据。
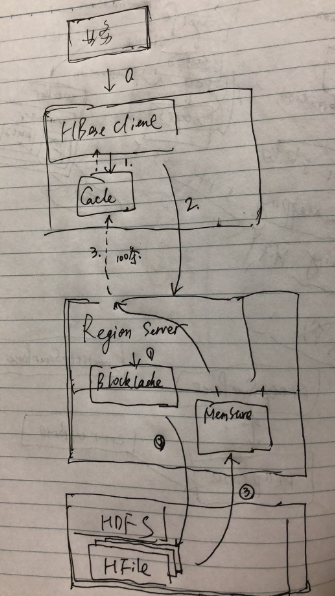
这种API的调用模式(每次返回100条)目的是避免网络资源以及HBase Client端内存资源发生压力;所以可以看到,scanAPI其实只是适合于少量数据的处理;
那么对于海量数据的查询怎么处理呢?就是上面提到的MR;MR整体分为两种:TableScanMR(对应的处理类:TableMapReduceUtil.initTableMapperJob)以及SnapshotScanMR(对应处理类:TableMapReduceUtil.initSnapshotMapperJob),下面两张图表示了在架构上面的差异:

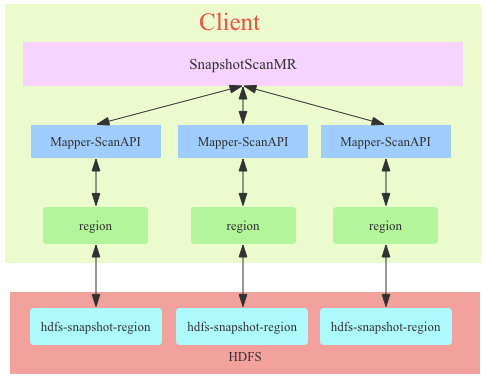
可以看到,模式很类似,都是在client中通过多线程模式进行并行处理;但是snapshotscanMR不再和region server交互,而是直接在客户端和HDFS交互;这样设计的好处即使减轻了Region Server的压力;但是需要事先和Region Server交互,获取snapshot的信息,即HBase的元数据信息(表结构以及hdfs存储信息),这样,就可以跳过region server直接和hdfs地址交互;但是snapshot有一个缺点:实时性不够;可能最近的一些数据的修改没有在snapshot中体现出来。可能会读到一些脏数据(删除更新数据仍然存在,只不过在墓碑记录而已,当然如果merge过后就没了),可能读不到一些最新数据。
参考:
http://hbasefly.com/2017/10/29/hbase-scan-3/
http://blog.cloudera.com/blog/2013/03/introduction-to-apache-hbase-snapshots/
HBase的Scan的更多相关文章
- Hbase 客户端Scan
Hbase 客户端Scan 标签(空格分隔): Hbase HBase扫描操作Scan 1 介绍 扫描操作的使用和get()方法类似.同样,和其他函数类似,这里也提供了Scan类.但是由于扫描工作方式 ...
- HBase shell scan 模糊查询
0.进入hbase shell ./hbase shell help help "get" #查看单独的某个命令的帮助 1. 一般命令 status 查看状态 version 查看 ...
- hbase查询,scan详解
一.shell 查询 hbase 查询相当简单,提供了get和scan两种方式,也不存在多表联合查询的问题.复杂查询需通过hive创建相应外部表,用sql语句自动生成mapreduce进行.但是这种简 ...
- HBase shell scan 过滤器用法总结
比较器: 前面例子中的regexstring:2014-11-08.*.binary:\x00\x00\x00\x05,这都是比较器.HBase的filter有四种比较器: (1)二进制比较器:如’b ...
- hbase的查询scan功能注意点(setStartRow, setStopRow)
来自http://hi.baidu.com/7636553/blog/item/982beb17713bc004972b43ee.html hbase的scan查询功能注意项: Scan scan = ...
- PySpark操作HBase时设置scan参数
在用PySpark操作HBase时默认是scan操作,通常情况下我们希望加上rowkey指定范围,即只获取一部分数据参加运算.翻遍了spark的python相关文档,搜遍了google和stackov ...
- HBase最佳实践之Scan
一.简介 HBase中Scan从大的层面来看主要有三种常见用法:ScanAPI.TableScanMR以及SnapshotScanMR.三种用法的原理不尽相同,扫描效率当然相差甚远,最重要的是这几种用 ...
- HBase scan setBatch和setCaching的区别
HBase的查询实现只提供两种方式: 1.按指定RowKey获取唯一一条记录,get方法(org.apache.hadoop.hbase.client.Get) 2.按指定的条件获取一批记录,scan ...
- HBase scan setBatch和setCaching的区别【转】
转自:http://blog.csdn.net/caoli98033/article/details/44650497 HBase的查询实现只提供两种方式: 1.按指定RowKey获取唯一一条记录,g ...
随机推荐
- C# 中的时间(DataTime)
在做报表或查询的时候,常常会预设一些可选的日期范围,如本周.本月.本年等,利用 C# 内置的DateTime基本上都可以实现这些功能. 当前时间: DateTime dt = DateTime.Now ...
- 处理Oracle EBS R12登录首页跳转出现unexpected error问题(转)
原文地址: 处理Oracle EBS R12登录首页跳转出现unexpected error问题 经上网搜索,造成此问题的问题有很多,如内存不足.系统参数配置不当.程序代码.系统表空间不足等原因.查询 ...
- OAF Sample Code(转)
原文地址: OAF Sample Code
- sort中的比较函数compare
sort中的比较函数compare要声明为静态成员函数或全局函数,不能作为普通成员函数,否则会报错: invalid use of non-static member function 因为:非静态成 ...
- spark出现task不能序列化错误的解决方法 org.apache.spark.SparkException: Task not serializable
import org.elasticsearch.cluster.routing.Murmur3HashFunction; import org.elasticsearch.common.math.M ...
- css实现椭圆
先实现个简单点的,用css实现一个圆,ok,直接上代码: .circle{ width: 100px; height:100px; background: red; border-radius: 50 ...
- C++:线程(std::thread)
1.创建一个线程 创建线程比较简单,使用std的thread实例化一个线程对象就创建完成了,示例: #include <iostream> #include <thread> ...
- Jena RDF API
1. jena 简单使用 RDF可以用简单的图示:包括节点以及连接节点的带有箭头的线段来理解. 这个例子中,资源 http://.../JohnSmith 表示一个人.这个人的全名是 John Sm ...
- 1.6 C++异常处理(try和catch)
参考: http://www.weixueyuan.net/view/6332.html 注意: throw 抛出异常,catch 捕获异常, try 尝试捕获异常. 在程序设计过程中,我们总是希 ...
- MyEclipse WebSphere开发教程:安装和更新WebSphere 6.1, JAX-WS, EJB 3.0(七)
[周年庆]MyEclipse个人授权 折扣低至冰点!立即开抢>> [MyEclipse最新版下载] MyEclipse支持Java EE技术(如JAX-WS和EJB 3.0),它们以功能包 ...