Elasticsearch核心技术(2)--- 基本概念(Index、Type、Document、集群、节点、分片及副本、倒排索引)
Elasticsearch核心技术(2)--- 基本概念
这篇博客讲到基本概念包括: Index、Type、Document。集群,节点,分片及副本,倒排索引。
一、Index、Type、Document
1、Index
index:索引是文档(Document)的容器,是一类文档的集合。
索引这个词在 ElasticSearch 会有三种意思:
1)、索引(名词)
类比传统的关系型数据库领域来说,索引相当于SQL中的一个数据库(Database)。索引由其名称(必须为全小写字符)进行标识。
2)、索引(动词)
保存一个文档到索引(名词)的过程。这非常类似于SQL语句中的 INSERT关键词。如果该文档已存在时那就相当于数据库的UPDATE。
3)、倒排索引
关系型数据库通过增加一个B+树索引到指定的列上,以便提升数据检索速度。索引ElasticSearch 使用了一个叫做 倒排索引 的结构来达到相同的目的。
2、Type
Type 可以理解成关系数据库中Table。
之前的版本中,索引和文档中间还有个类型的概念,每个索引下可以建立多个类型,文档存储时需要指定index和type。从6.0.0开始单个索引中只能有一个类型,
7.0.0以后将将不建议使用,8.0.0 以后完全不支持。
弃用该概念的原因:
我们虽然可以通俗的去理解Index比作 SQL 的 Database,Type比作SQL的Table。但这并不准确,因为如果在SQL中,Table 之前相互独立,同名的字段在两个表中毫无关系。
但是在ES中,同一个Index 下不同的 Type 如果有同名的字段,他们会被 Luecence 当作同一个字段 ,并且他们的定义必须相同。所以我觉得Index现在更像一个表,
而Type字段并没有多少意义。目前Type已经被Deprecated,在7.0开始,一个索引只能建一个Type为_doc
3、Document
Document Index 里面单条的记录称为Document(文档)。等同于关系型数据库表中的行。
我们来看下一个文档的源数据
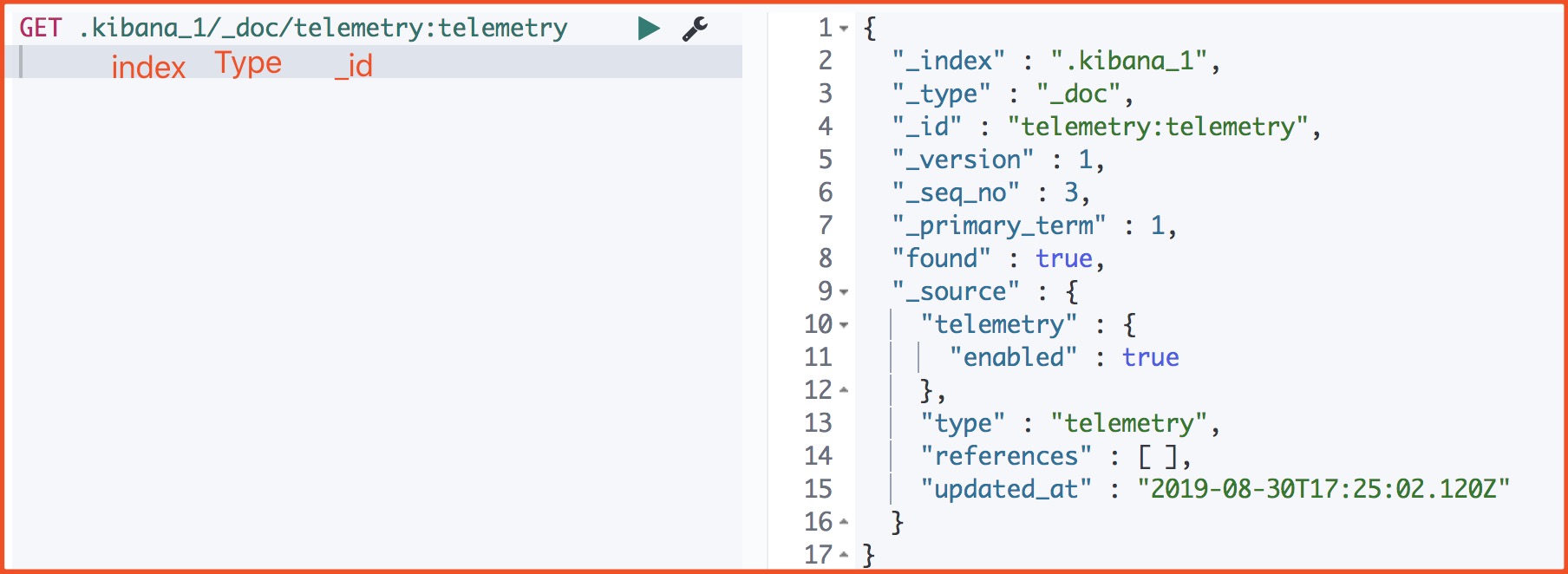
_index 文档所属索引名称。
_type 文档所属类型名。
_id Doc的主键。在写入的时候,可以指定该Doc的ID值,如果不指定,则系统自动生成一个唯一的UUID值。
_version 文档的版本信息。Elasticsearch通过使用version来保证对文档的变更能以正确的顺序执行,避免乱序造成的数据丢失。
_seq_no 严格递增的顺序号,每个文档一个,Shard级别严格递增,保证后写入的Doc的_seq_no大于先写入的Doc的_seq_no。
primary_term primary_term也和_seq_no一样是一个整数,每当Primary Shard发生重新分配时,比如重启,Primary选举等,_primary_term会递增1
found 查询的ID正确那么ture, 如果 Id 不正确,就查不到数据,found字段就是false。
_source 文档的原始JSON数据。
二、集群,节点,分片及副本
1、集群
ElasticSearch集群实际上是一个分布式系统,它需要具备两个特性:
1)高可用性
a)服务可用性:允许有节点停止服务;
b)数据可用性:部分节点丢失,不会丢失数据;
2)可扩展性
随着请求量的不断提升,数据量的不断增长,系统可以将数据分布到其他节点,实现水平扩展;
一个集群中可以有一个或者多个节点;
集群健康值
green:所有主要分片和复制分片都可用yellow:所有主要分片可用,但不是所有复制分片都可用red:不是所有的主要分片都可用
当集群状态为 red,它仍然正常提供服务,它会在现有存活分片中执行请求,我们需要尽快修复故障分片,防止查询数据的丢失;
2、节点(Node)
1)节点是什么?
a)节点是一个ElasticSearch的实例,其本质就是一个Java进程;
b)一台机器上可以运行多个ElasticSearch实例,但是建议在生产环境中一台机器上只运行一个ElasticSearch实例;
Node 是组成集群的一个单独的服务器,用于存储数据并提供集群的搜索和索引功能。与集群一样,节点也有一个唯一名字,默认在节点启动时会生成一个uuid作为节点名,
该名字也可以手动指定。单个集群可以由任意数量的节点组成。如果只启动了一个节点,则会形成一个单节点的集群。
3、分片
Primary Shard(主分片)
ES中的shard用来解决节点的容量上限问题,,通过主分片,可以将数据分布到集群内的所有节点之上。
它们之间关系
一个节点对应一个ES实例;
一个节点可以有多个index(索引);
一个index可以有多个shard(分片);
一个分片是一个lucene index(此处的index是lucene自己的概念,与ES的index不是一回事);
主分片数是在索引创建时指定,后续不允许修改,除非Reindex
一个索引中的数据保存在多个分片中(默认为一个),相当于水平分表。一个分片便是一个Lucene 的实例,它本身就是一个完整的搜索引擎。我们的文档被存储和索引到分片内,
但是应用程序是直接与索引而不是与分片进行交互。
Replica Shard(副本)
副本有两个重要作用:
1、服务高可用:由于数据只有一份,如果一个node挂了,那存在上面的数据就都丢了,有了replicas,只要不是存储这条数据的node全挂了,数据就不会丢。因此分片副本不会与
主分片分配到同一个节点;
2、扩展性能:通过在所有replicas上并行搜索提高搜索性能.由于replicas上的数据是近实时的(near realtime),因此所有replicas都能提供搜索功能,通过设置合理的replicas
数量可以极高的提高搜索吞吐量
分片的设定
对于生产环境中分片的设定,需要提前做好容量规划,因为主分片数是在索引创建时预先设定的,后续无法修改。
分片数设置过小
导致后续无法增加节点进行水平扩展。
导致分片的数据量太大,数据在重新分配时耗时;
分片数设置过大
影响搜索结果的相关性打分,影响统计结果的准确性;
单个节点上过多的分片,会导致资源浪费,同时也会影响性能;
三、倒排索引
ES的搜索功能是基于lucene,而lucene搜索的基本原理就是倒叙索引,倒序排序的结果跟分词的类型有关。
举例
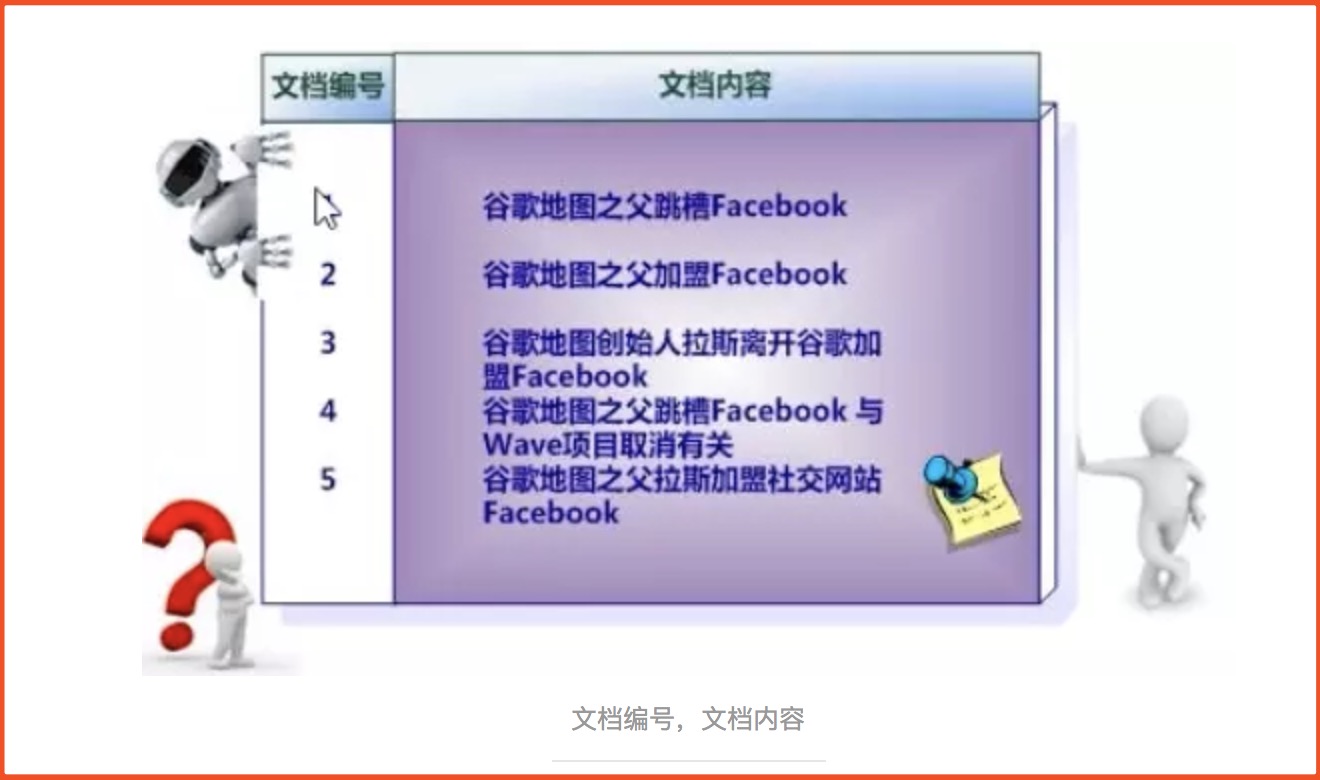
1、假设文档集合包含五个文档,毎个文档内容如图所示,在图中最左端一栏是每个文档对应的文挡编号。
如图(盗图)
2、首先要用分词系统将文挡自动切分成单词序列,记录下哪些文挡包含这个单词,在如此处理结束后,我们可以得到最简单的倒排索引。
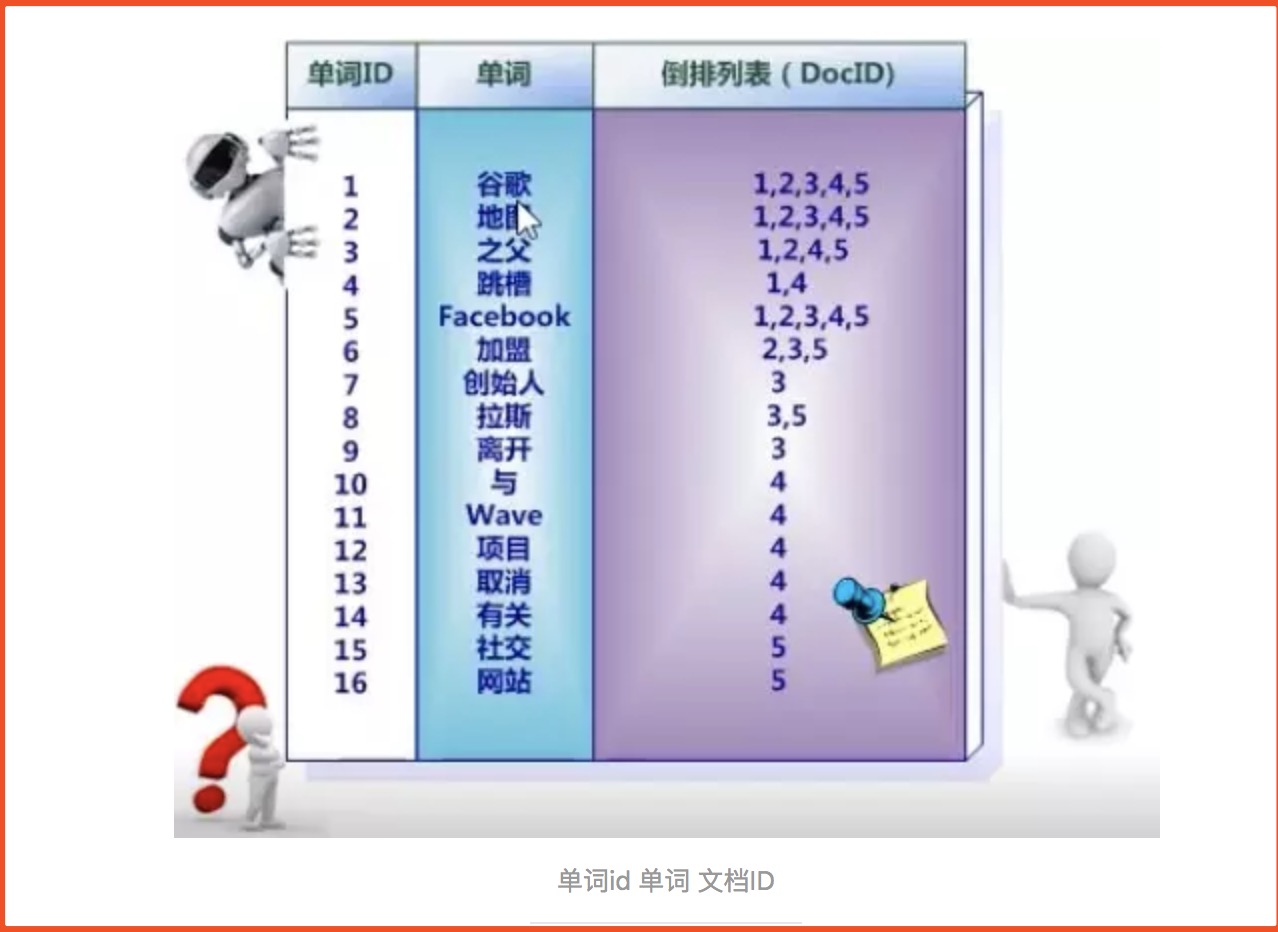
3、索引系统还可以记录除此之外的更多信息,下图还记载了单词频率信息。文档中的句子被划分为一个个term(term 用来表示一个单词或词语,取决于使用的分词方式),
倒叙索引中存储着term,term的出现频率(tf,term frequency)和出现位置(倒叙索引中的单词是按顺序排列的,这张图没有体现出来),请注意这里的文档内容是document
中的一个字段,也就是说每个被索引了的字段都有自己的倒叙索引

一次简单的搜索流程
假设我们搜索谷歌地图之父,搜索流程会是这样
- 分词,分词插件将句子分为3个term
谷歌,地图,之父 - 将这3个term拿到倒叙索引中去查找(会很高效,比如二分查找),如果匹配到了就拿对应的文档id,获得文档内容
但是,如何确定结果顺序?
这里要引入_score的概念,对于term的匹配,lucene会对其打分,得分越高,排名越靠前.这里要介绍几个相关的概念
- TF(term frequency),词频,term在当前document中出现的频率,一个term在当前document中出现5次要比出现1次更相关,打分也会更高
- IDF(inverse doucment frequency),逆向文档频率,term在所有document中出现的频率,这个频率越高,该term对应的分值越低
- 字段长度归一值,简单来说就是字段越短,字段的权重越高, 比如 term `我`在匹配 `我123`和`我123456`时,`我123`的得分会更高.
参考
1、Elasticsearch核心技术与实战---阮一鸣(eBay Pronto平台技术负责人
我相信,无论今后的道路多么坎坷,只要抓住今天,迟早会在奋斗中尝到人生的甘甜。抓住人生中的一分一秒,胜过虚度中的一月一年!(8)
Elasticsearch核心技术(2)--- 基本概念(Index、Type、Document、集群、节点、分片及副本、倒排索引)的更多相关文章
- Elasticsearch之重要核心概念(cluster(集群)、shards(分配)、replicas(索引副本)、recovery(据恢复或叫数据重新分布)、gateway(es索引的持久化存储方式)、discovery.zen(es的自动发现节点机制机制)、Transport(内部节点或集群与客户端的交互方式)、settings(修改索引库默认配置)和mappings)
Elasticsearch之重要核心概念如下: 1.cluster 代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的.es的一个概念就是 ...
- 实例展示elasticsearch集群生态,分片以及水平扩展.
elasticsearch用于构建高可用和可扩展的系统.扩展的方式可以是购买更好的服务器(纵向扩展)或者购买更多的服务器(横向扩展),Elasticsearch能从更强大的硬件中获得更好的性能,但是纵 ...
- 集群节点Elasticsearch升级
集群节点Elasticsearch升级 操作流程 1.首先执行Elasticsearch-1.2.2集群的索引数据备份 2.关闭elasticsearch-1.2.2集群的recovery.compr ...
- Elasticsearch集群节点配置详解
注意:如果是在局域网中运行elasticsearch集群也是很简单的,只要cluster.name设置一致,并且机器在同一网段下,启动的es会自动发现对方,组成集群. 2.elasticsearch- ...
- elasticsearch 口水篇(5)es分布式集群初探
es有很多特性,分布式.副本集.负载均衡.容灾等. 我们先搭建一个很简单的分布式集群(伪),在同一机器上配置三个es,配置分别如下: cluster.name: foxCluster node.nam ...
- k8s重要概念及部署k8s集群(一)--技术流ken
重要概念 1. cluster cluster是 计算.存储和网络资源的集合,k8s利用这些资源运行各种基于容器的应用. 2.master master是cluster的大脑,他的主要职责是调度,即决 ...
- ElasticSearch优化系列一:集群节点规划
节点职责单一,各司其职 elasticSearch的配置文件中有2个参数:node.master和node.data.这两个参 数搭配使用时,能够帮助提供服务器性能. 数据节点node.master: ...
- elasticsearch 7.2 集群节点配置
conf/elasticsearch.yml对其修改,在下面添加修改: 主节点的配置 http.cors.enabled: true http.cors.allow-origin: "*&q ...
- k8s重要概念及部署k8s集群(一)
k8s介绍 Kubernetes(k8s)是Google开源的容器集群管理系统(谷歌内部:Borg).在Docker技术的基础上,为容器化的应用提供部署运行.资源调度.服务发现和动态伸缩等一系列完整功 ...
随机推荐
- sql server还原数据库(请选择用于还原的备份集)
还原数据库的时候明明选择了备份集,还是提示未选择还原的备份集 后来查了下,是因为我本地有两个数据库(2008R2和2014),对应的两个数据库实例.而还原bak是sqlserver2014的备份,我默 ...
- 【杂谈】Hash表与平衡树
hash表与平衡树查询数据的时间复杂度是多少? hash表为O(1),平衡树为O(logn) 这个时间复杂度是如何得出的? 时间复杂度是按照最糟糕的情况来的.但即使是最糟糕的情况,hash表也只需要计 ...
- javascript基础学习第三天
☞ 命名法: 小驼峰命名法 和 大驼峰命名法(帕斯卡命名法) 变量命名规则:遵循小驼峰命名法 [变量名第一个字母小写后面每一个单词的首字母大写] var userNameAge; 函数命名规则:遵循帕 ...
- Shiro权限管理框架(二):Shiro结合Redis实现分布式环境下的Session共享
首发地址:https://www.guitu18.com/post/2019/07/28/44.html 本篇是Shiro系列第二篇,使用Shiro基于Redis实现分布式环境下的Session共享. ...
- Python 之父撰文回忆:为什么要创造 pgen 解析器?
花下猫语: 近日,Python 之父在 Medium 上开通了博客,并发布了一篇关于 PEG 解析器的文章(参见我翻的 全文译文).据我所知,他有自己的博客,为什么还会跑去 Medium 上写文呢?好 ...
- 【转】解决eclipse连接不到genymotion的问题
(1)很多朋友在使用genymotion开发安卓应用程序的时候,会遇见完全正确的安装但是在运行的时候仍然找不到,genymotion上的设备,在打开的devices上找不到如下图所示: (2)解决的方 ...
- 【Android】未引入包问题
Mac 上配置 Android 开发环境,遇到了下面问题: /Users/***/Documents/SVN/Android/***/1.0.3/res/values/styles.xml:21: e ...
- unimrcp-voice-activity语音检测
研究 unimrcp有一段时间了,其中unimrcp voice acitve的算法,是遭到大家频繁吐槽.今天我们简单的介绍一下unimrcp voice activity 的这个简单粗暴的算法: u ...
- Apache ActiveMQ任意文件写入漏洞(CVE-2016-3088)复现
Apache ActiveMQ任意文件写入漏洞(CVE-2016-3088)复现 一.漏洞描述 该漏洞出现在fileserver应用中,漏洞原理:ActiveMQ中的fileserver服务允许用户通 ...
- Android使用com.google.android.cameraview.CameraView进行拍照
import android.Manifest;import android.annotation.SuppressLint;import android.content.Context;import ...